↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Visual object tracking, the task of following an object in a video, has seen advancements with Vision-Language (VL) trackers, which use language descriptions to help track objects. However, these VL trackers underperform compared to state-of-the-art visual trackers, largely due to reliance on inaccurate manual textual annotations. This paper tackles this issue.
The proposed ChatTracker leverages Multimodal Large Language Models (MLLMs) to automatically generate and refine language descriptions, significantly improving tracking accuracy. A novel reflection-based prompt optimization module uses feedback from the visual tracker to iteratively improve descriptions, addressing the challenges of ambiguity and inaccuracy in existing approaches. This plug-and-play module can be easily incorporated into existing visual and VL trackers. Experiments demonstrate that ChatTracker achieves performance comparable to existing state-of-the-art methods.
Key Takeaways#
Why does it matter?#
This paper is important because it presents ChatTracker, a novel framework that enhances visual tracking performance by integrating Multimodal Large Language Models (MLLMs). This approach addresses the limitations of existing vision-language trackers, which often rely on inaccurate manual annotations, by leveraging the rich world knowledge of MLLMs to generate higher-quality descriptions. The proposed reflection-based prompt optimization module iteratively refines descriptions using tracking feedback, improving tracking accuracy. This work opens new avenues for research in visual-language tracking and demonstrates the potential of MLLMs in computer vision.
Visual Insights#

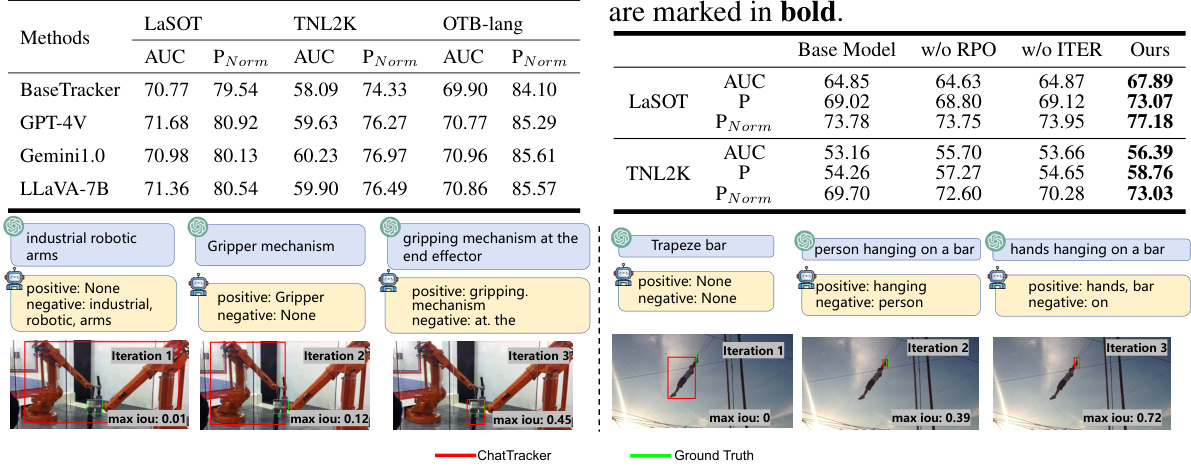
This figure compares two different approaches to generating text descriptions for visual object tracking: manual annotation/GPT-4V (a) and ChatTracker (b). (a) shows that both manual annotations and GPT-4V generated descriptions can be inaccurate or ambiguous, hindering effective tracking. (b) illustrates how ChatTracker uses an iterative refinement process (chatting with a multimodal large language model) to produce higher quality descriptions, thereby improving tracking accuracy.
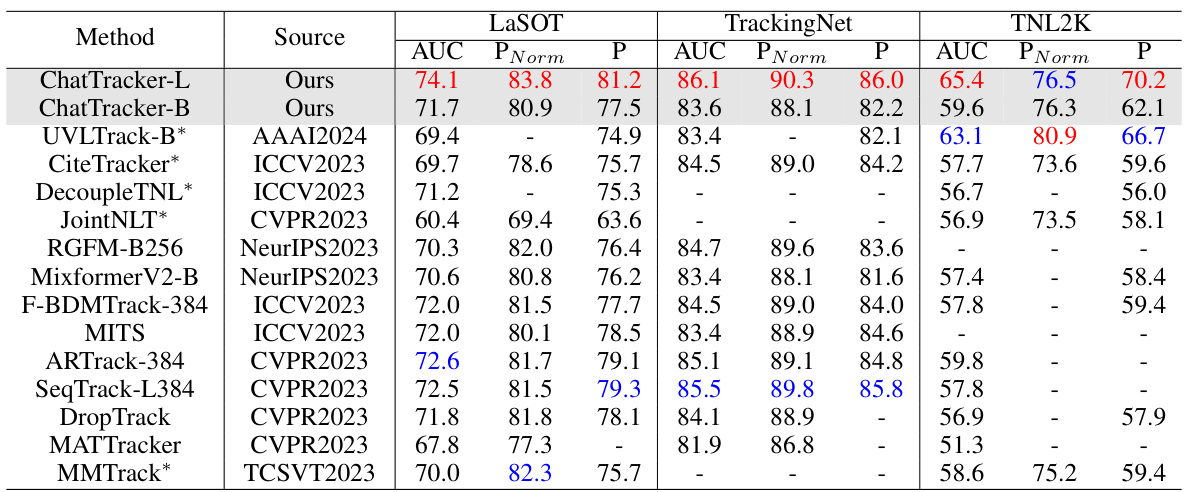
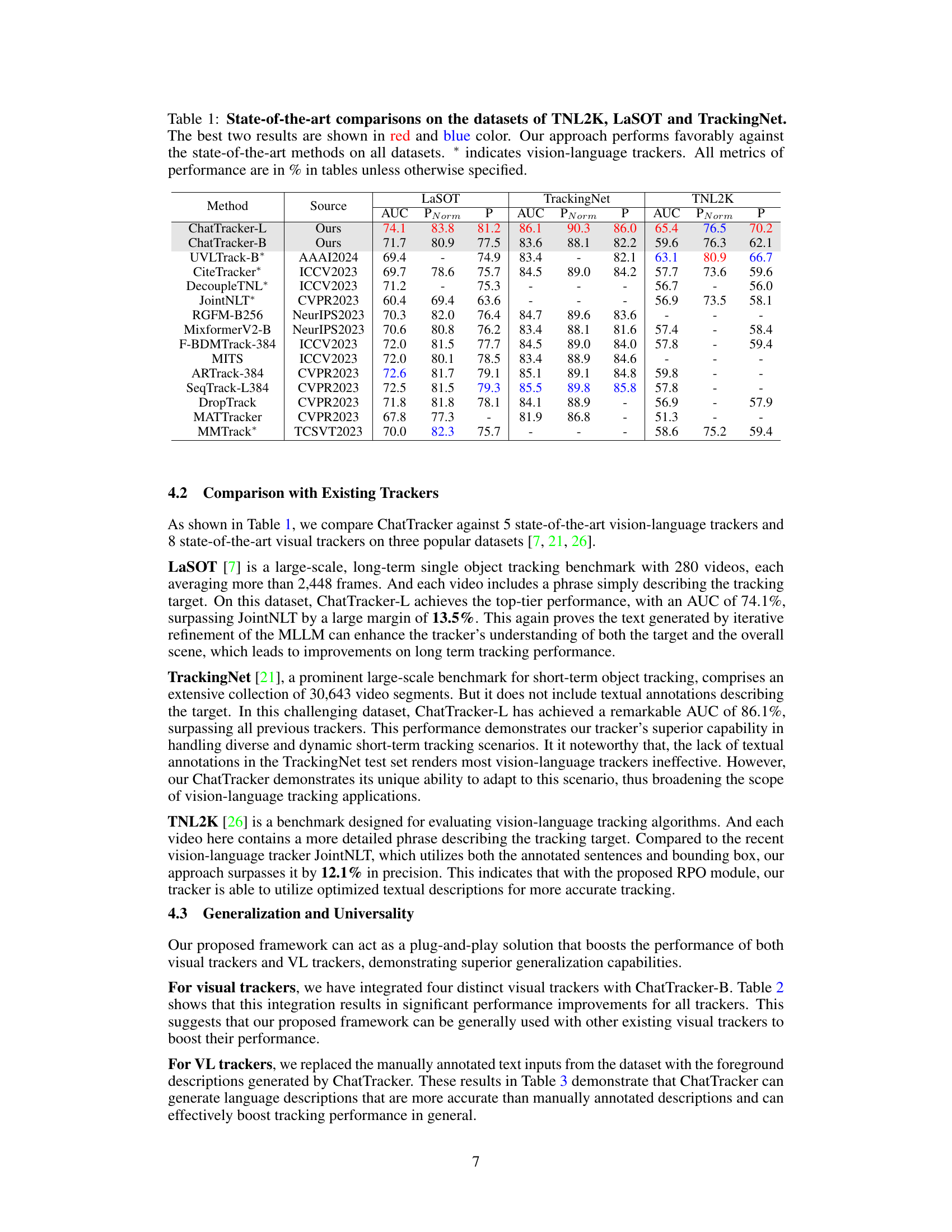
This table presents a comparison of the ChatTracker model’s performance against other state-of-the-art visual and vision-language trackers on three benchmark datasets: TNL2K, LaSOT, and TrackingNet. The results are shown for several metrics (AUC, precision, and normalized precision) and highlight that ChatTracker achieves competitive or superior performance to existing methods.
In-depth insights#
VL Tracking Issues#
Visual-Linguistic (VL) tracking, while promising, faces significant challenges. A core issue is the heavy reliance on manually annotated descriptions, which are often ambiguous and inaccurate. This reliance introduces noise and inconsistencies, hindering performance. Furthermore, current VL trackers struggle to effectively bridge the semantic gap between visual and linguistic modalities, leading to poor target identification. Existing methods often focus on vision-language alignment without adequately addressing the inherent limitations of textual annotations, resulting in suboptimal tracking performance compared to state-of-the-art visual-only trackers. Another critical aspect is the lack of standardized, high-quality datasets with consistent, detailed linguistic annotations. Addressing these limitations requires advancements in both automatic description generation and the design of more robust VL tracking algorithms that can handle ambiguous or incomplete linguistic information more effectively.
MLLM Integration#
The integration of Multimodal Large Language Models (MLLMs) presents a paradigm shift in visual object tracking. By incorporating MLLMs, the system can leverage the wealth of knowledge encoded within these models to generate high-quality language descriptions, enriching the tracker’s understanding beyond visual features alone. This offers a significant advantage over traditional methods that rely on limited, manual annotations, often prone to ambiguity. The core challenge lies in bridging the gap between the MLLM’s abstract representations and the tracker’s concrete visual data. Effective prompt engineering and iterative refinement strategies, as demonstrated by the reflection-based prompt optimization module, prove crucial for generating relevant and accurate textual descriptions. Integration seamlessly enhances performance for both vision-language and visual-only trackers, underscoring the versatility and robustness of this novel approach.
Prompt Optimization#
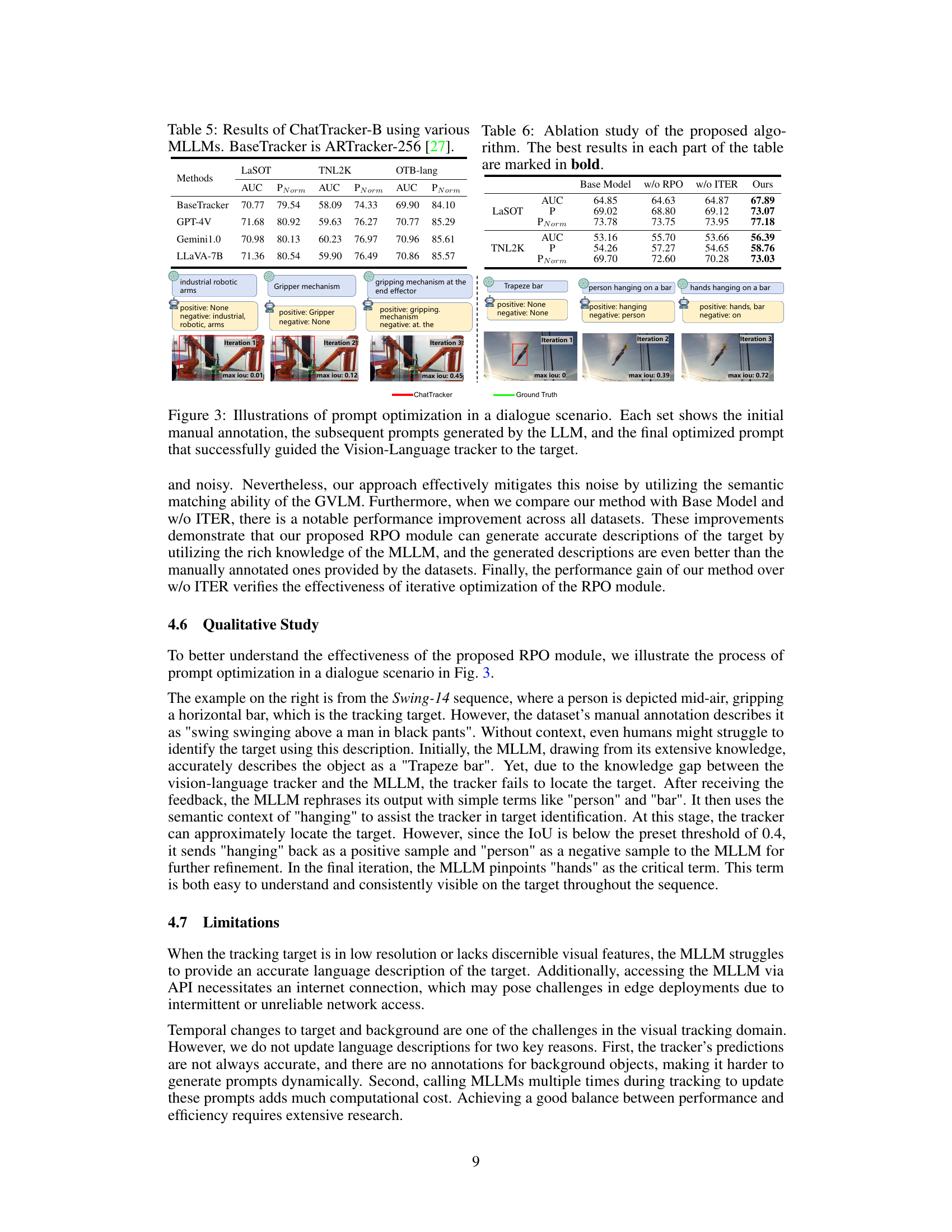
Prompt optimization is a crucial technique in leveraging large language models (LLMs) for specific tasks, and this paper demonstrates its effectiveness in visual object tracking. The core idea is to iteratively refine the prompts given to the MLLM based on feedback from the visual tracker. This iterative process, called reflection-based prompt optimization, addresses two key issues: inaccurate initial descriptions from the MLLM due to its training data and the inherent limitations of LLMs in multi-modal understanding. By using tracking feedback, specifically focusing on IoU scores between predicted and ground truth bounding boxes, the prompt is iteratively adjusted, leading to descriptions that are better aligned with the visual content. The effectiveness of this approach is highlighted by its ability to enhance the performance of both visual and vision-language trackers, demonstrating its versatility and potential for broader applications in multimodal learning and computer vision.
Semantic Tracking#
Semantic tracking, in the context of visual object tracking enhanced by multimodal large language models (MLLMs), represents a significant advancement. It leverages the rich semantic information extracted from MLLM-generated descriptions to improve tracking accuracy and robustness. This approach moves beyond simple visual feature matching by incorporating contextual understanding of the scene and the target object. A key strength lies in the ability to distinguish foreground from background elements accurately, enabling better target localization, even in challenging scenarios with cluttered backgrounds or appearance changes. The integration of semantic cues provides a more resilient tracking system less susceptible to visual distractions or ambiguities. The use of reflection-based prompt optimization further enhances accuracy by iteratively refining descriptions based on tracking feedback, reducing error propagation and improving overall performance. This integration of semantic and visual information shows great potential to significantly improve tracking performance compared to systems relying solely on visual cues. However, challenges remain in managing the inherent limitations of MLLMs, such as hallucinations, and in efficiently integrating this computationally-expensive component into real-time tracking systems.
Future of VL Tracking#
The future of vision-language (VL) tracking hinges on overcoming current limitations such as reliance on manual annotations and addressing the inherent ambiguity in natural language descriptions. Integrating more sophisticated multimodal large language models (MLLMs), as demonstrated by ChatTracker, is crucial. These advanced models can generate higher-quality, more precise language descriptions, improving target identification and tracking accuracy. Furthermore, research should focus on developing more robust methods to handle diverse tracking scenarios including complex backgrounds, occlusions, and significant appearance changes. This may involve developing novel frameworks that seamlessly integrate MLLMs with existing visual tracking algorithms, creating a truly synergistic system that leverages both visual and semantic information. Ultimately, the goal is to achieve a more generalized and robust VL tracking system that approaches the performance of state-of-the-art visual-only trackers, ultimately becoming an indispensable tool across many applications.
More visual insights#
More on figures

This figure illustrates the overall framework of the ChatTracker algorithm, which consists of three main modules: 1) Reflection-based Prompt Optimization Module: This module generates accurate language descriptions of both the foreground and background objects using an iterative refinement process with feedback from a visual language tracker. 2) Semantic Tracking Module: This module leverages the generated descriptions and a visual tracker to create region proposals for the foreground and background areas. 3) Foreground Verification Module: This module selects the most accurate tracking result from the region proposals generated by the Semantic Tracking Module. The diagram shows the data flow between these modules, emphasizing the iterative refinement process in the RPO module and the integration of both language and visual information in the tracking process. While numerical values are shown, they are illustrative and do not precisely reflect the actual implementation.
This figure presents a detailed overview of the ChatTracker algorithm, highlighting its three main modules: Reflection-based Prompt Optimization, Semantic Tracking, and Foreground Verification. The Reflection-based Prompt Optimization module iteratively refines the descriptions of the foreground and background objects using feedback from the visual tracker. The Semantic Tracking module uses the refined descriptions to generate region proposals for both foreground and background. Finally, the Foreground Verification module selects the most accurate tracking result among the proposals.

The figure illustrates the ChatTracker framework, which consists of three main modules. The Reflection-based Prompt Optimization Module refines the initial description of the target object using iterative feedback from a visual tracker and a large language model. This improved description, along with the original image, is input to the Semantic Tracking Module, which generates region proposals for both the foreground and background. Finally, the Foreground Verification Module selects the most accurate tracking result from these proposals, taking into consideration both the foreground and background information. This framework enhances the precision of visual tracking by using large language model descriptions and feedback to improve the accuracy of the generated descriptions.
More on tables

This table presents a comparison of the ChatTracker model’s performance against other state-of-the-art visual and vision-language trackers on three benchmark datasets: TNL2K, LaSOT, and TrackingNet. The results are evaluated using AUC, Precision (P), and Precision normalized (PNorm). The table highlights ChatTracker’s competitive performance, particularly in achieving the best or second-best results on several metrics across datasets. The asterisk (*) indicates that the corresponding method is a vision-language tracker.
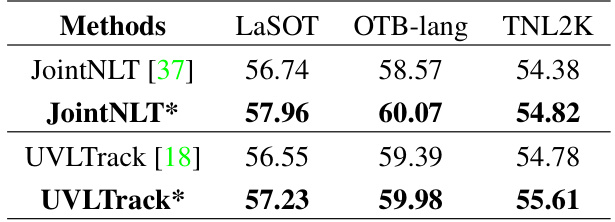
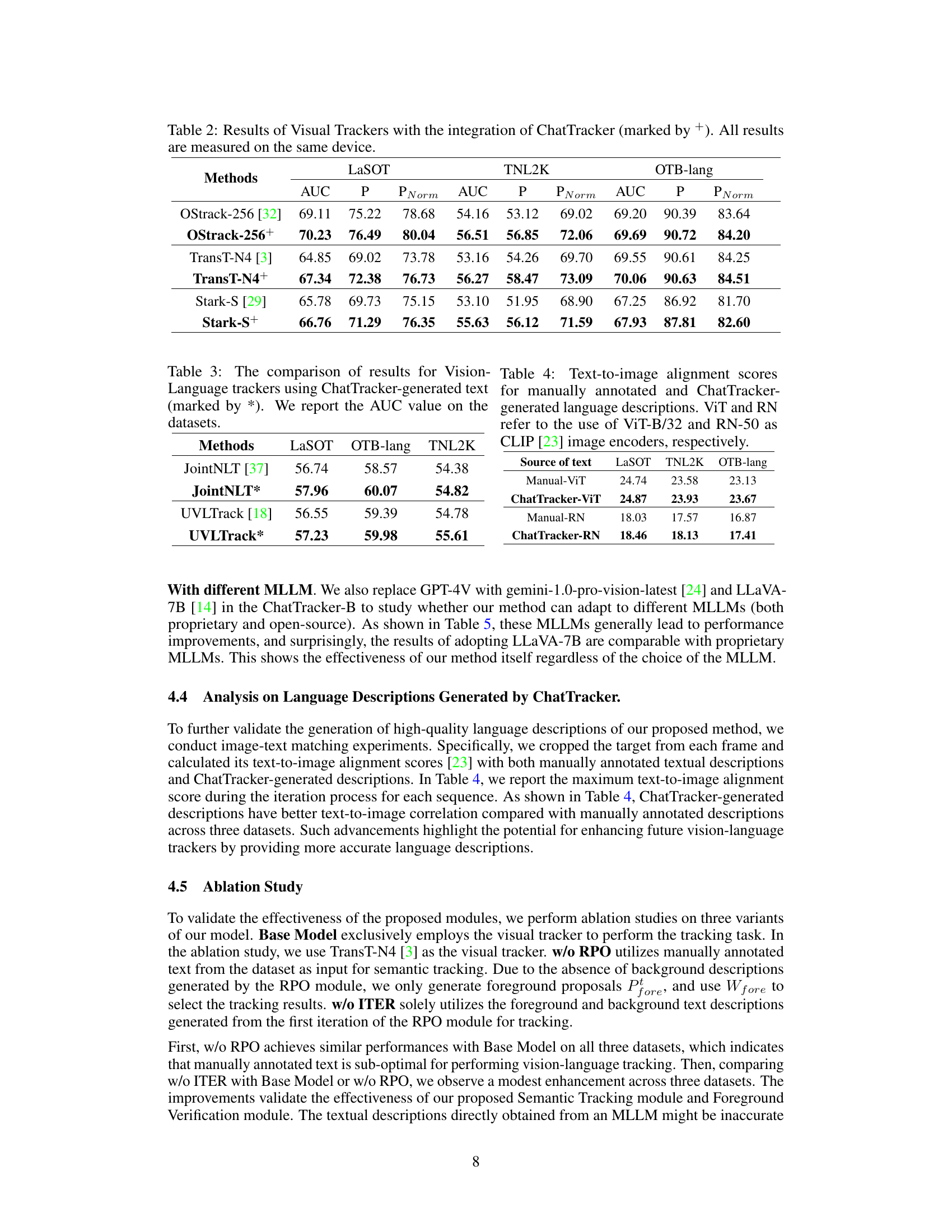
This table compares the Area Under the Curve (AUC) values for several vision-language trackers, both with manually annotated descriptions and with descriptions generated by the ChatTracker model. The purpose is to show how the ChatTracker-generated descriptions improve the performance of existing trackers.
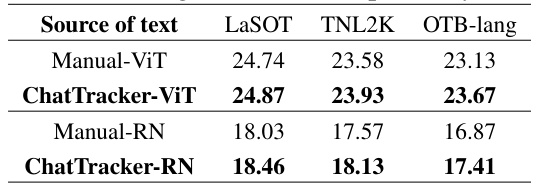
This table presents a comparison of text-to-image alignment scores obtained using two different sources of text descriptions: manually annotated descriptions and descriptions generated by the ChatTracker model. Two different image encoders (ViT-B/32 and RN-50) from the CLIP model were used to compute the alignment scores for each text source on three datasets: LaSOT, TNL2K, and OTB-lang. The scores indicate the degree of alignment between the textual descriptions and the corresponding images, reflecting the quality of the descriptions in terms of accurately capturing the visual features of the target.

This table presents the performance comparison of three different methods on the OTB-lang dataset. The methods being compared are the complete ChatTracker-L (with the Foreground Verification module), a version where a foreground proposal is randomly selected instead of using the verification module, and finally an upper bound representing perfect selection of the proposal with the highest IoU with ground truth. The results show that the Foreground Verification module significantly improves performance compared to random selection, demonstrating its effectiveness.

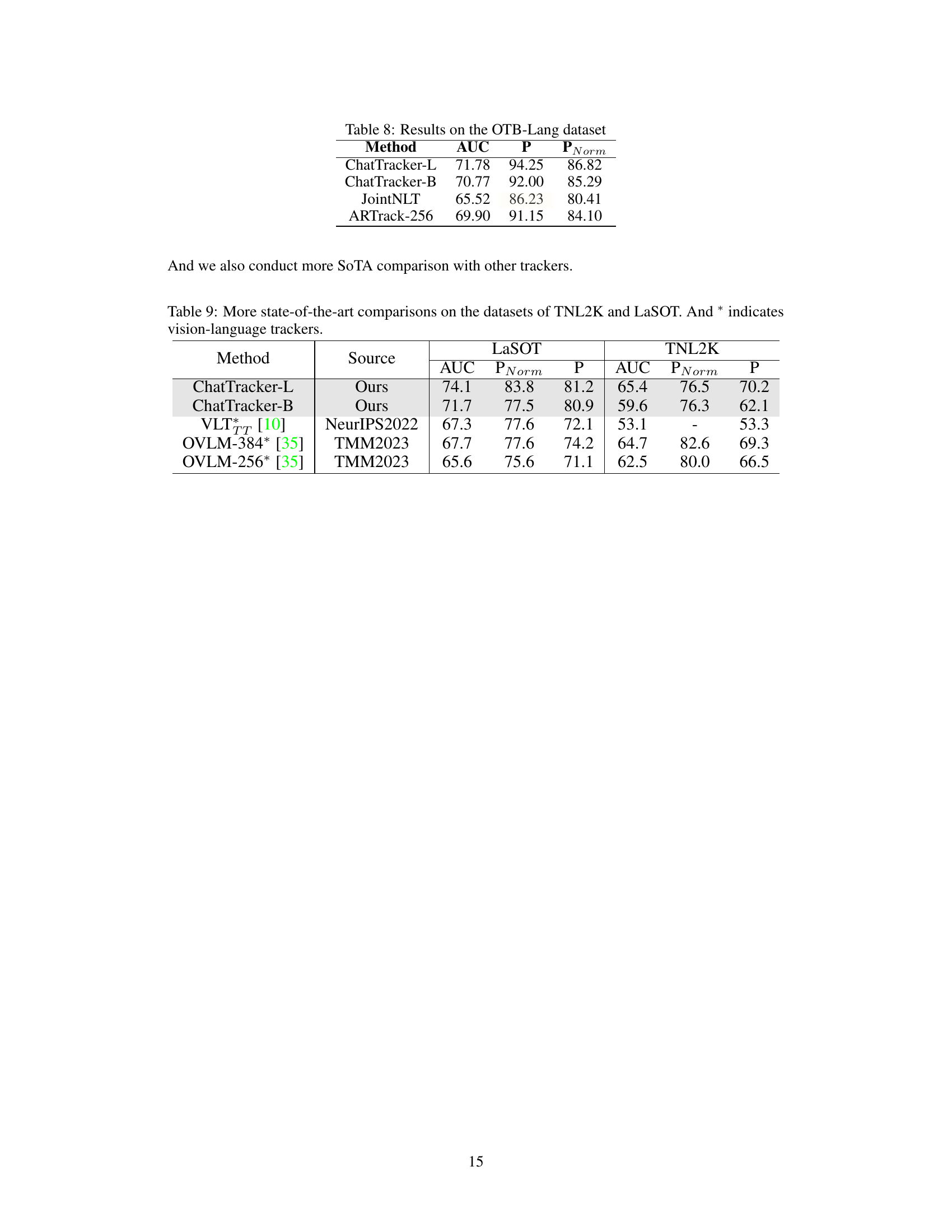
This table presents a comparison of the performance of four different visual trackers on the OTB-Lang dataset. The trackers evaluated are ChatTracker-L, ChatTracker-B, JointNLT, and ARTrack-256. The metrics used to evaluate performance are AUC (Area Under the Curve), Precision (P), and Precision with normalized overlap (PNorm). The table shows that ChatTracker-L achieves the best performance in terms of all three metrics.

This table presents a comparison of the ChatTracker model’s performance against other state-of-the-art visual and vision-language trackers on three benchmark datasets: TNL2K, LaSOT, and TrackingNet. The results are shown in terms of AUC, Precision (P), and Precision normalized (PNorm). The best two performing models for each metric on each dataset are highlighted in red and blue. The table demonstrates that ChatTracker outperforms existing models, especially in the AUC metric.
Full paper#