↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current learning-based video codecs, while promising, face challenges like high computational complexity and suboptimal compression techniques, especially with INR methods. Standard codecs like VVC VTM still outperform the best INR-based approaches due to simple model compression methods. This necessitates improved techniques to fully harness the potential of INR in video compression.
The paper introduces Neural Video Representation Compression (NVRC), a novel INR-based video compression framework that focuses on optimizing representation compression. NVRC achieves this through novel quantization and entropy coding approaches, enabling end-to-end rate-distortion optimization. Furthermore, it hierarchically compresses network, quantization, and entropy model parameters. Experiments demonstrate NVRC’s superiority over conventional and learning-based codecs, achieving a significant coding gain.
Key Takeaways#
Why does it matter?#
This paper is crucial because it presents NVRC, the first INR-based video codec to surpass the performance of VVC VTM, a significant benchmark in video compression. This breakthrough opens new avenues for research in efficient and high-quality video compression, particularly within the burgeoning field of implicit neural representations.
Visual Insights#

This figure compares the visual quality of video frames reconstructed by two different video compression methods: HiNeRV and the proposed NVRC method. The top row shows close-up views of a horse’s head, while the bottom row shows a wider shot of a horse race. For both close-up and wider shots, NVRC produces sharper images than HiNeRV, demonstrating the improved visual quality achieved by the proposed method. The PSNR (Peak Signal-to-Noise Ratio) and bits per pixel (bpp) values are provided for each reconstruction, quantifying the improvement in objective quality and compression efficiency.

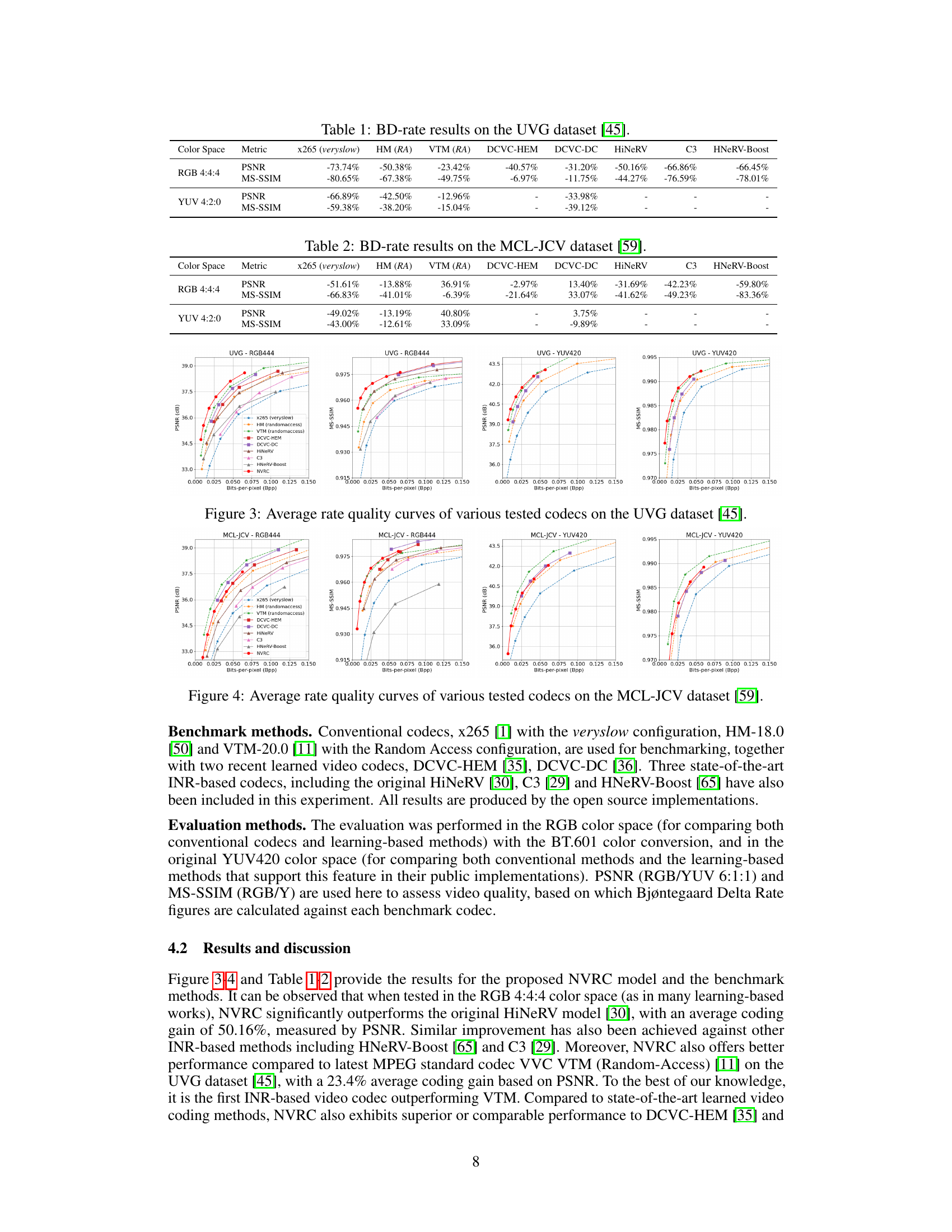
This table presents the BD-rate (Bjøntegaard Delta Rate) results comparing the proposed NVRC video codec with various conventional and learning-based codecs on the UVG dataset. BD-rate is a metric representing the percentage gain in coding efficiency. Negative values indicate that NVRC outperforms the compared codec. The table shows results for both RGB 4:4:4 and YUV 4:2:0 color spaces using PSNR (Peak Signal-to-Noise Ratio) and MS-SSIM (Multi-Scale Structural Similarity Index) as quality metrics.
In-depth insights#
INR-Video Coding#
Implicit Neural Representations (INRs) have emerged as a promising technique in video coding, offering potential advantages over traditional methods. INRs represent video content using neural networks, learning a compact encoding of the video frames. This can lead to reduced storage requirements and faster decoding speeds, particularly beneficial for high-resolution videos. However, challenges remain in areas such as model compression, efficient quantization, and optimizing for rate-distortion trade-offs. Current research focuses on improving these areas, aiming to make INR-based video coding competitive with state-of-the-art techniques like VVC. Key advancements include the development of hierarchical quantization and novel entropy coding methods that enable fully end-to-end optimization. Future research should address further improving compression efficiency, computational complexity at both the encoder and decoder, and robustness to various types of video content.
NVRC Framework#
The NVRC framework represents a novel approach to video compression using implicit neural representations (INRs). Its core innovation lies in end-to-end optimization of the INR, quantization, and entropy models, unlike previous methods that treated these components separately. This holistic optimization significantly improves the rate-distortion performance, achieving gains over state-of-the-art codecs. The framework employs hierarchical compression, reducing overhead by quantizing and coding network parameters, feature grids, and model parameters. Advanced entropy coding techniques, like context-based Gaussian models, leverage redundancy for efficient bitrate allocation. The use of a hierarchical structure and refined training pipeline further enhances efficiency. While demonstrating significant coding gains, computational cost remains a limitation, suggesting that further optimization is needed for practical real-time applications. The success of NVRC highlights the potential of INR-based methods with improved compression strategies.
End-to-End Optim.#
End-to-end optimization in video compression aims to simultaneously optimize all components of the encoding and decoding pipeline within a single training process. This contrasts with traditional methods that optimize individual stages separately, often leading to suboptimal overall performance. A key benefit is the potential for significant improvements in rate-distortion efficiency, as the entire system is trained to jointly minimize distortion while simultaneously minimizing bitrate. This holistic approach enables the discovery of better interactions between components, leveraging the interdependence of different processing stages for enhanced compression. However, the end-to-end approach also introduces significant complexity in training and optimization due to the non-differentiability of certain operations (like quantization). Therefore, careful consideration of the training methodology and loss function design are critical to effectively utilize this approach, requiring sophisticated techniques to handle non-differentiable parts of the pipeline. The challenge lies in balancing model complexity with computational efficiency, which is crucial for practical deployment.
Rate-Distortion Tradeoff#
The rate-distortion tradeoff is a fundamental concept in data compression, representing the balance between achieving low distortion (high fidelity) and using a low bitrate (efficient storage/transmission). In video coding, this means finding the optimal balance between visual quality and file size. A lower bitrate results in smaller file sizes and faster transmission but typically increases the distortion (lower quality). Conversely, minimizing distortion might require a higher bitrate leading to larger files. The goal of any effective compression algorithm, including those based on neural networks (like the Neural Video Representation Compression (NVRC) framework discussed in the paper), is to operate on the Pareto frontier of this tradeoff, finding points where any improvement in one metric necessarily involves a worsening of the other. Effective algorithms cleverly exploit redundancies and patterns in data, thus achieving high compression ratios without significant perceptual loss. The paper’s focus on optimizing the representation itself, rather than just the network architecture, directly addresses the rate-distortion tradeoff by finding more compact representations of video data. Their fully end-to-end optimization methodology further aims to directly control this tradeoff during training, learning the optimal balance simultaneously.
Future Directions#
Future research could explore several promising avenues. Improving the efficiency of the entropy models is crucial, potentially through advanced context modeling or novel quantization techniques that better exploit data redundancy. Another key area is reducing the computational complexity, particularly at the encoder, to enable real-time applications. This might involve exploring more efficient neural architectures, low-precision computation, or more effective model compression strategies. Addressing the latency issue inherent in the current INR-based approach remains a challenge, demanding investigation of techniques that facilitate faster encoding. Finally, extending the framework’s adaptability to handle diverse video content, such as higher resolutions and more complex motion patterns, will broaden the codec’s practicality. Addressing these limitations would significantly enhance the performance and applicability of INR-based video compression.
More visual insights#
More on figures
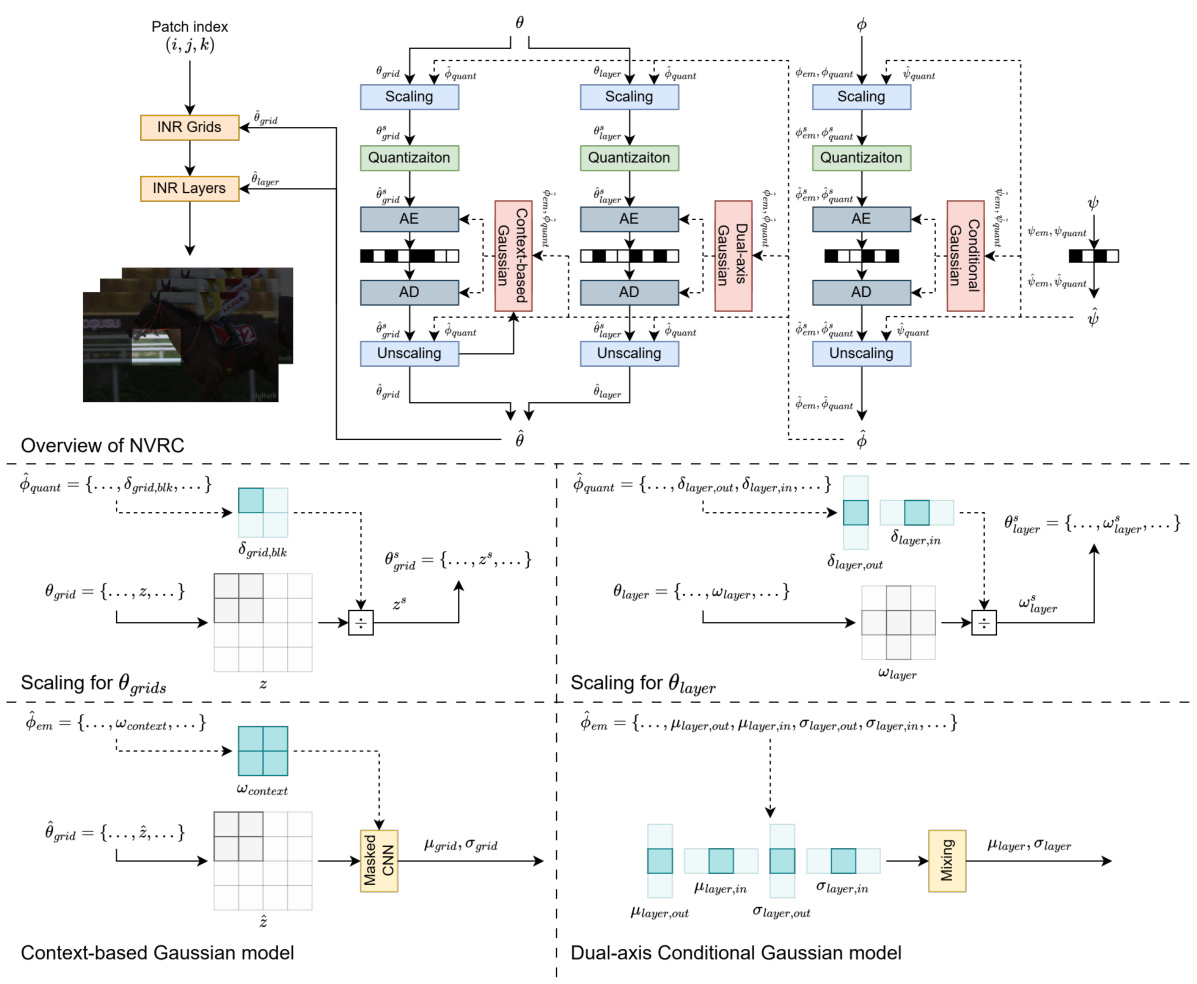
This figure illustrates the hierarchical structure used in NVRC for encoding model parameters. It shows how the feature grids (representing the spatial and temporal aspects of the video) and network layer parameters are encoded separately, but both leverage hierarchical quantization and entropy coding schemes for improved efficiency. For feature grids, per-block quantization scales and a context-based model reduce redundancy and bitrate. For network layer parameters, per-axis quantization scales and a dual-axis conditional Gaussian model are used. The entire process of encoding the parameters for the INR model (feature grids, network layers), and the quantization and entropy models themselves are all optimized together for rate-distortion trade-offs.

This figure compares the rate-distortion performance of NVRC against several other video codecs on the UVG dataset. The graph shows how the PSNR (Peak Signal-to-Noise Ratio), a measure of video quality, changes with bitrate (bits per pixel). Lower bitrates mean better compression, while higher PSNR indicates better quality. The figure helps to visualize how NVRC performs relative to existing methods, such as x265, HM (High Efficiency Video Coding), VTM (Versatile Video Coding), and other learning-based methods.

This figure presents a comparison of the rate-distortion performance of different video codecs on the UVG dataset. The x-axis represents bits per pixel (bpp), a measure of compression efficiency, and the y-axis shows the peak signal-to-noise ratio (PSNR) and multi-scale structural similarity index (MS-SSIM), which are metrics for image quality. The graph displays the performance curves for various codecs, including x265, HM, VTM, DCVC-HEM, DCVC-DC, HiNeRV, C3, HNeRV-Boost, and NVRC. It allows a visual comparison of the rate-distortion trade-off for each codec, showing which codec achieves the best balance of compression and quality for a given bitrate. The results indicate the relative effectiveness of each codec in achieving high compression with minimal loss of visual quality. The comparison is shown for both RGB 4:4:4 and YUV 4:2:0 color spaces, reflecting the different color formats used in video compression.
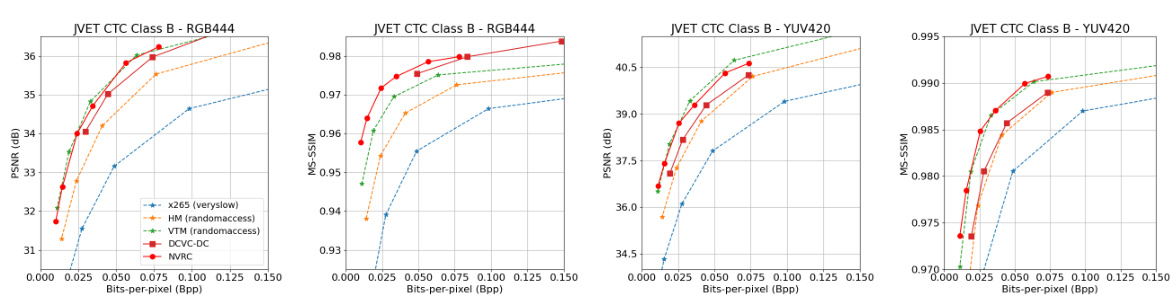
This figure compares the rate-distortion performance of several video codecs on the UVG dataset. The x-axis represents bits per pixel (bpp), and the y-axis shows either PSNR (Peak Signal-to-Noise Ratio) or MS-SSIM (Multi-Scale Structural Similarity Index). The various lines represent different codecs, including x265 (a high-performance general-purpose codec), HM (HEVC Test Model), VTM (VVC Test Model), DCVC-HEM, DCVC-DC (both learning-based codecs), HiNeRV, C3, HNeRV-Boost, and NVRC (the authors’ proposed codec). The curves illustrate how each codec trades off compression rate (bpp) for reconstruction quality (PSNR or MS-SSIM). NVRC’s superior performance compared to others, especially VVC VTM, is clearly visible in both the PSNR and MS-SSIM curves.

This figure shows the breakdown of bits used for different components of the NVRC model at various rate points. The left panel displays the proportion of total bits allocated to feature grids, network layers, and their respective quantization and entropy models. The right panel presents bits-per-parameter for these components across different video sequences, revealing how the bit allocation varies depending on the video content complexity. Sequences with higher motion tend to use more bits for feature grids, as expected.
More on tables

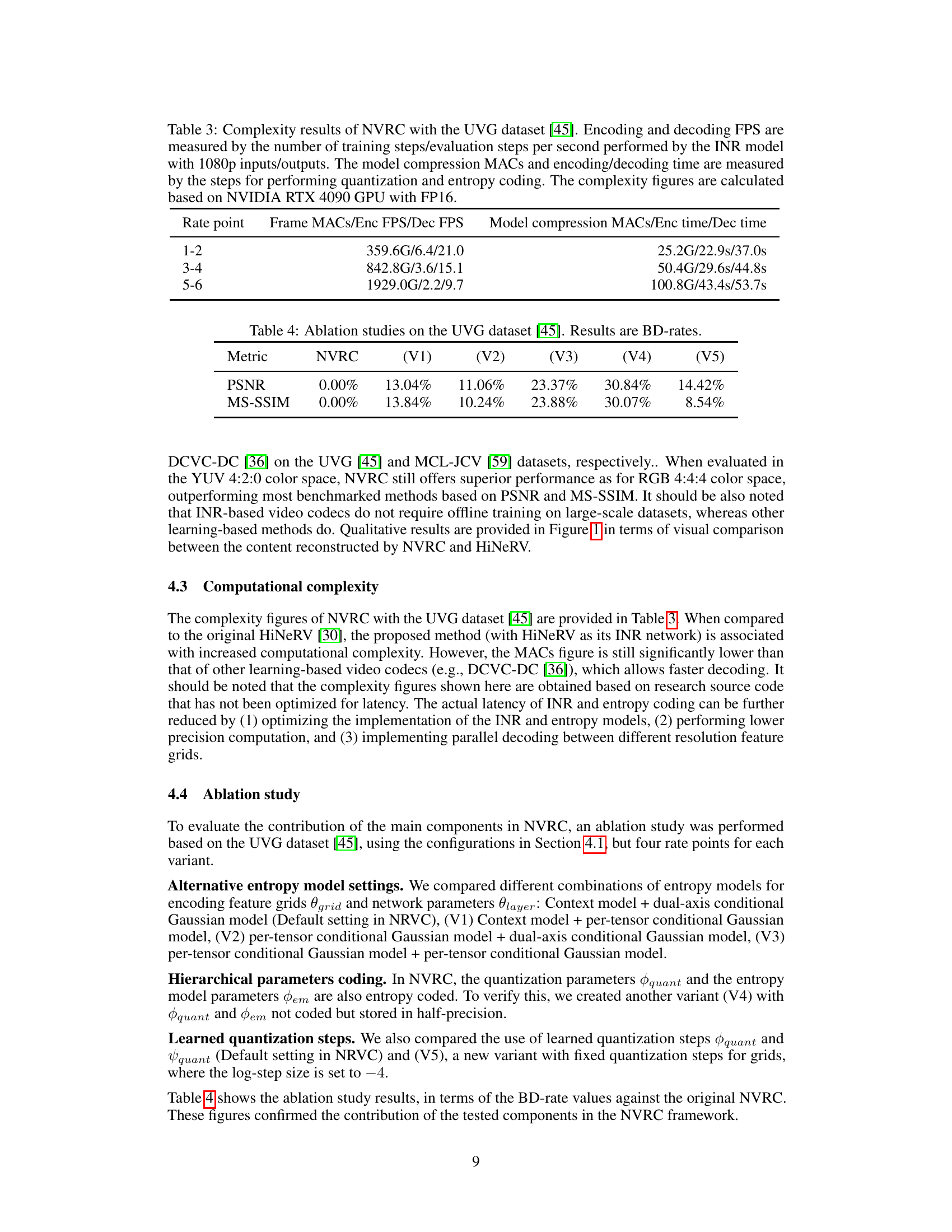
This table presents the computational complexity of the proposed NVRC framework. It breaks down the complexity for different rate points (1-2, 3-4, 5-6) into two main parts: frame processing and model compression. Frame processing complexity is measured by Giga Multiply-Accumulates (GMACs), encoding Frames Per Second (FPS), and decoding FPS. Model compression complexity is also measured in GMACs, as well as encoding and decoding time in seconds. All measurements were performed using an NVIDIA RTX 4090 GPU with FP16 precision.

This table presents the ablation study results on the UVG dataset. It shows the impact of different components in the NVRC framework on the BD-rate (Bjøntegaard Delta Rate), a metric that measures the coding efficiency. The NVRC model (V0) is compared with five variants (V1-V5), where each variant modifies a specific aspect of the framework, such as the entropy model or the quantization strategy. This allows to analyze the contribution of each component to the overall performance.

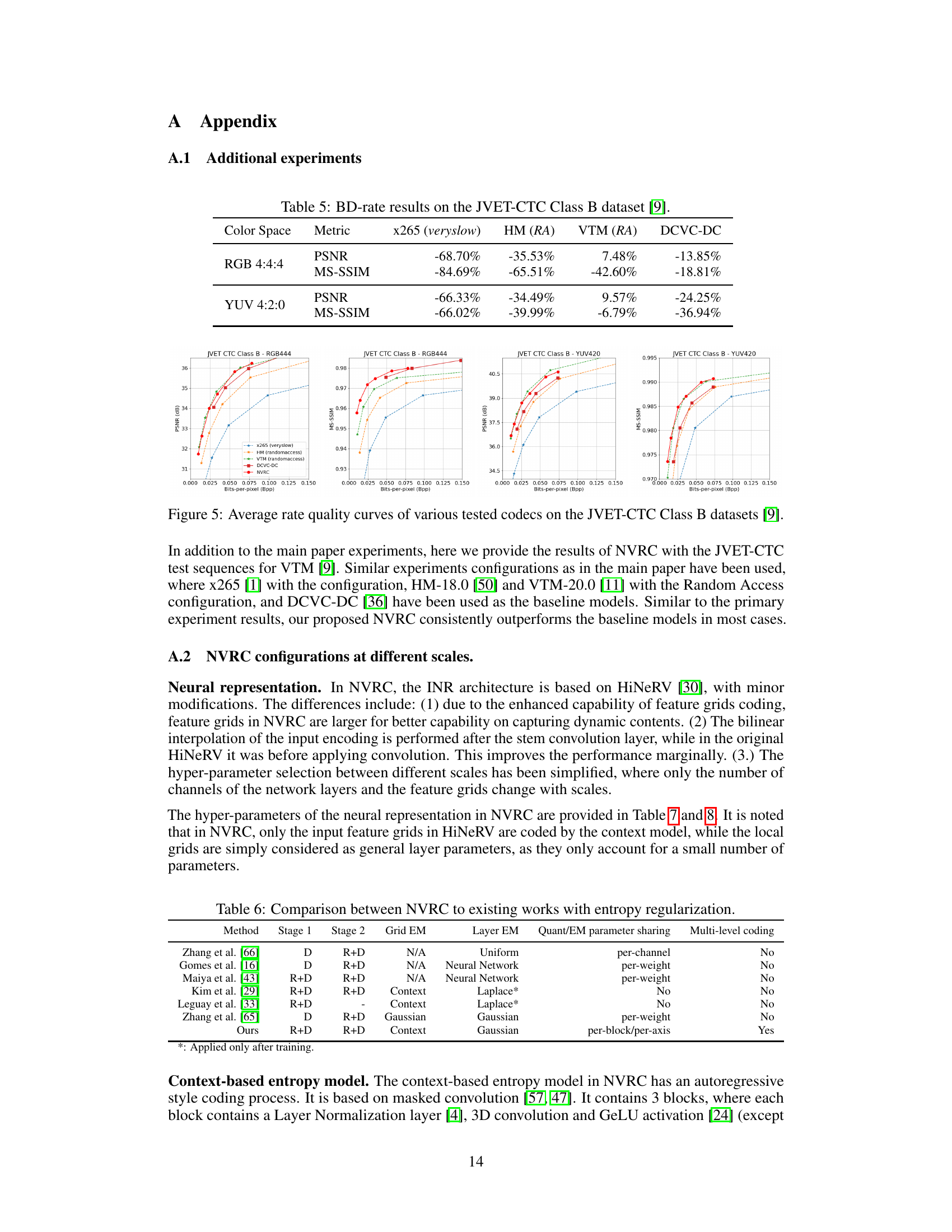
This table presents the BD-rate (Bjøntegaard Delta Rate) results comparing NVRC’s performance against several other video codecs on the JVET-CTC Class B dataset. BD-rate is a metric that quantifies the relative efficiency of different codecs in terms of bitrate savings for a given level of quality. Lower BD-rate values indicate better performance. The results are shown for two color spaces: RGB 4:4:4 and YUV 4:2:0. The metrics used are PSNR (Peak Signal-to-Noise Ratio) and MS-SSIM (Multi-Scale Structural Similarity Index).
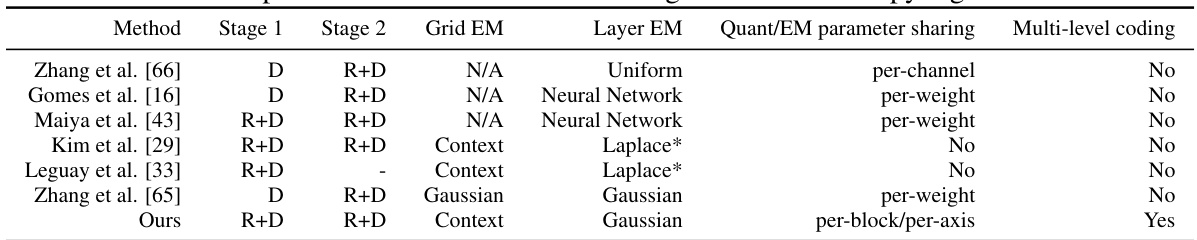
This table compares several key aspects of NVRC against other existing methods that also incorporate entropy regularization in their video compression frameworks. The comparison focuses on the training stages (Stage 1 and Stage 2 optimization objectives), the type of entropy model used for both feature grids and network layer parameters, whether quantization and entropy model parameters are shared across dimensions (parameters sharing), and whether a multi-level coding scheme was employed for improved efficiency.
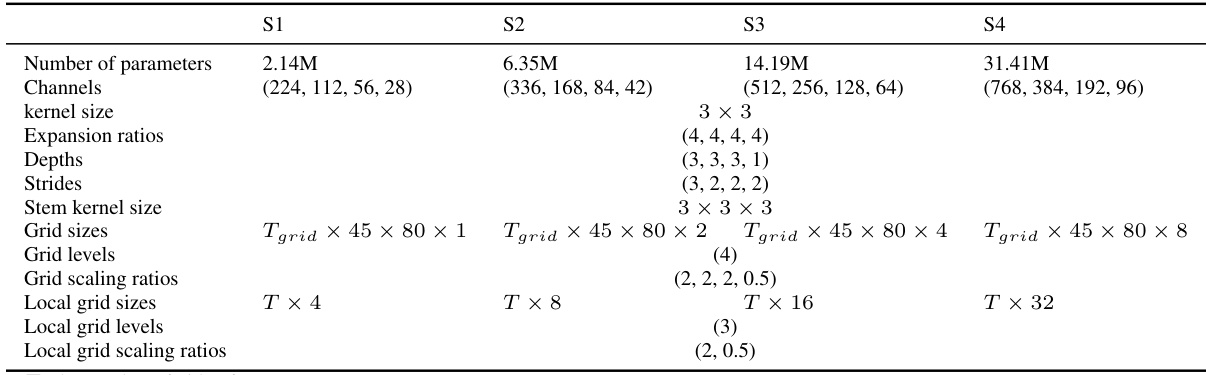
This table details the configurations used for the Neural Video Representation Compression (NVRC) model across four different scales (S1 to S4). For each scale, the table specifies the number of parameters, channel configurations at each layer, kernel size, expansion ratio, depth of each layer, strides, stem kernel size, and grid configurations (sizes, levels, scaling ratios, and local grid configurations). The configurations are optimized for a balance between representation quality and compression efficiency.
Full paper#