↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Unsupervised skill discovery aims to enable AI agents to learn reusable skills through autonomous interaction without explicit rewards. Existing methods often struggle in complex environments with many state factors, resulting in simple skills not suitable for complex tasks. These methods primarily focus on encouraging diverse state coverage, neglecting the potential value of skills that induce diverse interactions between state factors.
SkiLD addresses this issue by leveraging state factorization as an inductive bias. It introduces a novel skill learning objective that encourages diverse interactions between state factors, thereby facilitating the discovery of more valuable and reusable skills. Evaluations across various challenging domains show that SkiLD outperforms existing methods, demonstrating its effectiveness in learning semantically meaningful skills with superior downstream task performance.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to unsupervised skill discovery that addresses limitations of existing methods in complex, high-dimensional environments. It leverages state factorization and focuses on diverse interactions between factors. This work offers a new perspective for researchers and opens avenues for improved skill learning in robotics and other complex AI domains.
Visual Insights#
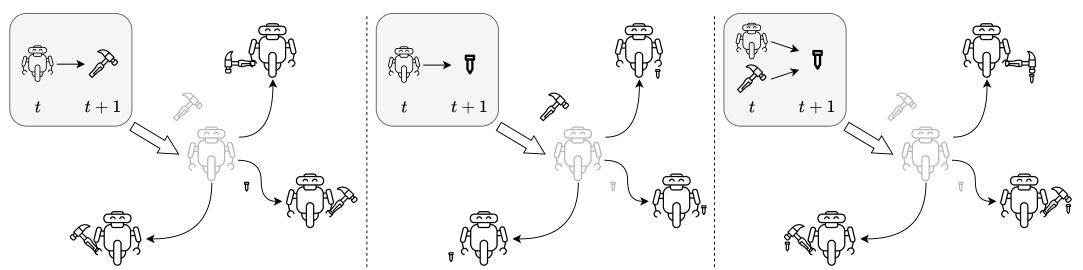
This figure illustrates the core idea behind SkiLD. It contrasts SkiLD with previous methods for unsupervised skill discovery. Prior methods either focus on diverse, but non-interactive states (e.g., moving the robot to different locations without interacting with objects), or on manipulating individual objects in isolation (e.g., picking up a hammer or nail). SkiLD, on the other hand, explicitly learns skills that induce diverse interactions between state factors. The example shown depicts a robot interacting with a hammer and nail—not only picking up each object independently, but also using the hammer to hit the nail. This demonstrates how SkiLD learns more valuable and reusable skills for complex tasks.
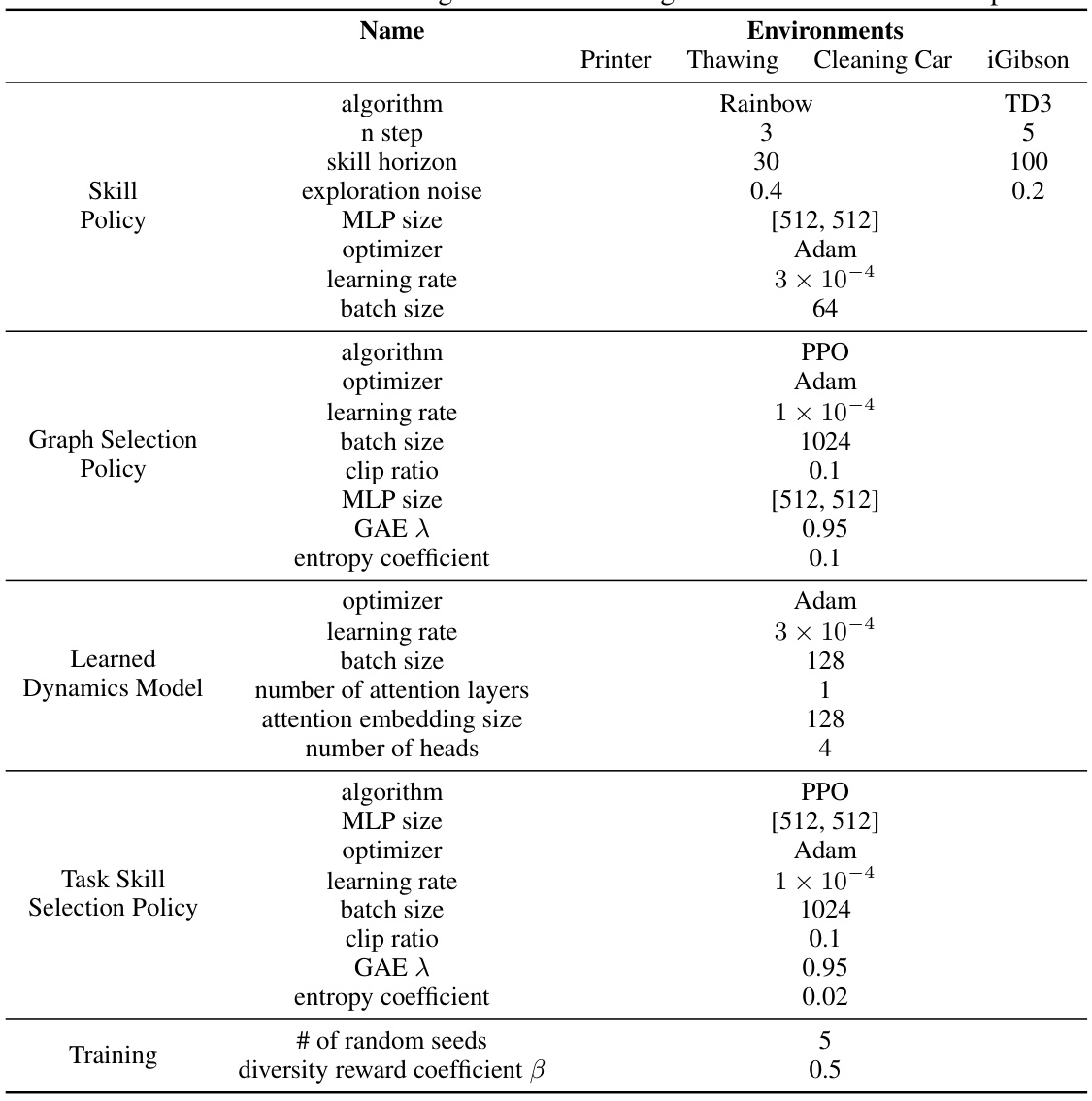
This table presents the hyperparameters used for skill learning and task learning in the experiments. It details settings for the skill policy, graph selection policy, learned dynamics model, and task skill selection policy. Different algorithms (Rainbow, TD3, PPO, Adam) are used, with varying hyperparameters (learning rate, batch size, network sizes, etc.) depending on the environment (Printer, Thawing, Cleaning Car, iGibson) and specific policy.
In-depth insights#
Factorial Skill#
The concept of “Factorial Skills” in the context of reinforcement learning centers on the idea that an agent’s abilities can be broken down into a set of independent, reusable skills. These skills are not isolated actions but rather represent ways the agent interacts with and manipulates factors in the environment. Unlike traditional approaches focusing on reaching diverse states, factorial skills explicitly consider the relationships between state factors. This approach is particularly beneficial in complex settings with numerous interacting objects, where simply maximizing state coverage is inefficient and leads to the discovery of simple, less useful skills. A crucial advantage of this approach is the ability to reuse learned skills to solve downstream tasks, requiring the agent to strategically chain together existing factorial skills. This significantly improves sample efficiency compared to traditional methods. By explicitly encouraging diverse interactions between factors through carefully designed reward functions and policy structures, the learning process becomes more directed and leads to the acquisition of semantically meaningful, composite skills. This factorial skill approach represents a paradigm shift from simply emphasizing state diversity to promoting interactional diversity, leading to more robust and useful skills for complex tasks.
Local Dependency#
The concept of “Local Dependency” in the context of unsupervised skill discovery within factored Markov Decision Processes (MDPs) is a crucial innovation. It addresses the limitations of prior methods which often focus solely on maximizing state diversity without considering the structured interactions within a state. SkiLD leverages local dependencies to guide skill learning, providing a more effective inductive bias. Instead of simply encouraging diverse states, SkiLD explicitly encourages skills that induce diverse interactions between state factors. This is achieved by defining skills not just by the states they reach, but also by the changes in the relationships between state factors they cause. The identification of these local dependencies employs causality-inspired methods, focusing on minimal subsets of state factors that are necessary and sufficient to explain changes in other factors. This approach efficiently addresses the challenge of high-dimensional state spaces often seen in complex environments with many factors, guiding the agent toward learning meaningful skills suitable for downstream tasks. The method efficiently tackles the complexity of factored MDPs, leading to improved performance in downstream task learning compared to approaches relying solely on state coverage.
Hierarchical RL#
Hierarchical Reinforcement Learning (HRL) addresses the challenge of long-horizon tasks in RL by decomposing them into a hierarchy of subtasks. This decomposition simplifies learning, as simpler subtasks are easier to solve individually than the complex original task. HRL methods typically involve two or more levels of control: a high-level policy selecting and sequencing subtasks, and a low-level policy executing the selected subtasks. The choice of subtask decomposition strategy significantly impacts performance, influencing both learning efficiency and the ultimate quality of the learned policy. Different approaches exist, including options frameworks, temporal abstraction, and various forms of hierarchical architectures, each with its own advantages and disadvantages. Key design considerations in HRL involve the balance between high-level planning and low-level execution, efficient credit assignment across levels, and effective exploration in the state space. Furthermore, the ability to reuse skills learned in one hierarchical task for new tasks (transfer learning) is a significant goal and a current research focus within the HRL domain. Combining HRL with other techniques, such as unsupervised skill discovery or causal inference, holds significant potential for improving AI’s ability to learn complex behaviors.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of skill discovery, this would involve removing or disabling specific aspects of the proposed method (e.g., the local dependency graph, the diversity reward) to see how performance changes on downstream tasks. Positive results would demonstrate the importance of the removed component, showing that it’s crucial for achieving high performance. Conversely, if performance doesn’t change significantly after removing a component, it might suggest that component is less crucial than originally thought or that other components compensate for its absence. Careful analysis of ablation study results can uncover unexpected interactions between model parts and refine design choices. For example, a significant drop in performance after removing the dependency graph would highlight its vital role in guiding the agent towards more complex and useful skills, whereas a minor effect would suggest the system is robust and other mechanisms could be contributing substantially. Such insights are invaluable for optimizing model architectures and understanding the underlying skill learning mechanisms.
Future Work#
The paper’s core contribution is a novel skill discovery method, SkiLD, that leverages state factorization and local dependencies to learn more complex and useful skills than existing methods. Future work should focus on expanding SkiLD’s applicability to unfactored state spaces, which is a significant limitation. This requires advancements in disentangled representation learning to extract meaningful factorized information from raw sensory data (images, videos). Another important area is improving the accuracy of local dependency detection. The current reliance on approximate methods, such as pCMI, introduces noise and uncertainty. More robust causal inference techniques could enhance the precision and reliability of SkiLD. Finally, extending SkiLD to handle continuous state and action spaces would broaden its applicability to a wider range of robotic and AI problems. This will likely involve adapting the framework to handle continuous representations and learning effective interaction representations in continuous domains. Further investigation into the scalability of the proposed method to high-dimensional state spaces and more complex environments, alongside rigorous empirical evaluation across various tasks and domains, is critical. This would further validate SkiLD’s generalizability and robustness.
More visual insights#
More on figures
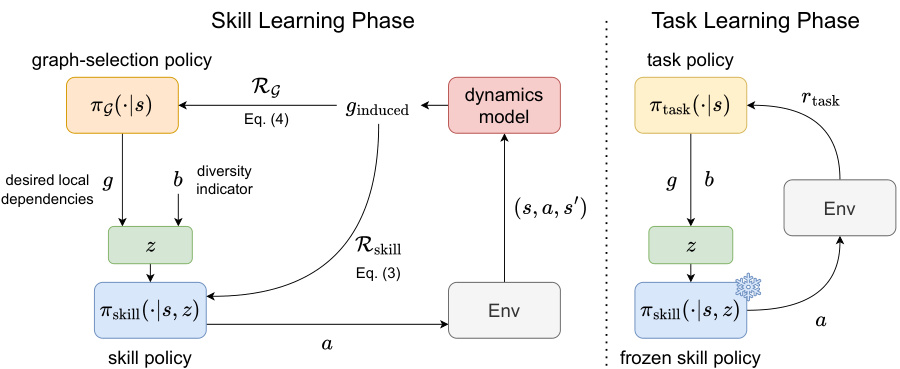
This figure illustrates the two-stage process of SkiLD: skill learning and task learning. In the skill learning phase, a high-level graph selection policy chooses target local dependencies. A low-level skill policy then learns to induce these dependencies using primitive actions. The induced dependency graph is identified by a dynamics model and used to update both policies. In the task learning phase, the skill policy is fixed, and a high-level task policy learns to select skills to maximize the task reward. This shows how SkiLD uses hierarchical reinforcement learning to efficiently discover interaction-rich skills that can be reused for downstream tasks.

This figure shows the three environments used in the experiments: (a) Thawing, (b) Cleaning Car, and (c) Interactive Gibson. Each image provides a visual representation of the environment’s layout and objects. The Thawing environment features a grid-based layout with a refrigerator, sink, and table. The Cleaning Car environment also uses a grid-based layout and shows a car, a sink, a bucket, shelf, rag, and soap. The Interactive Gibson environment depicts a more realistic, 3D kitchen setting, featuring a robot, a knife, peach, sink, and potentially other objects.
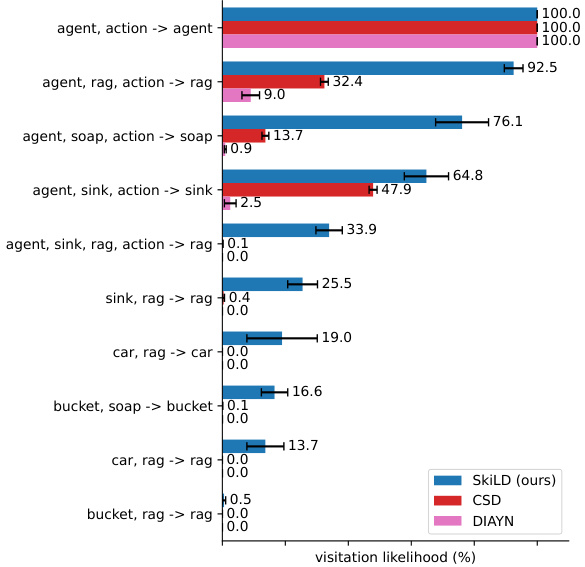
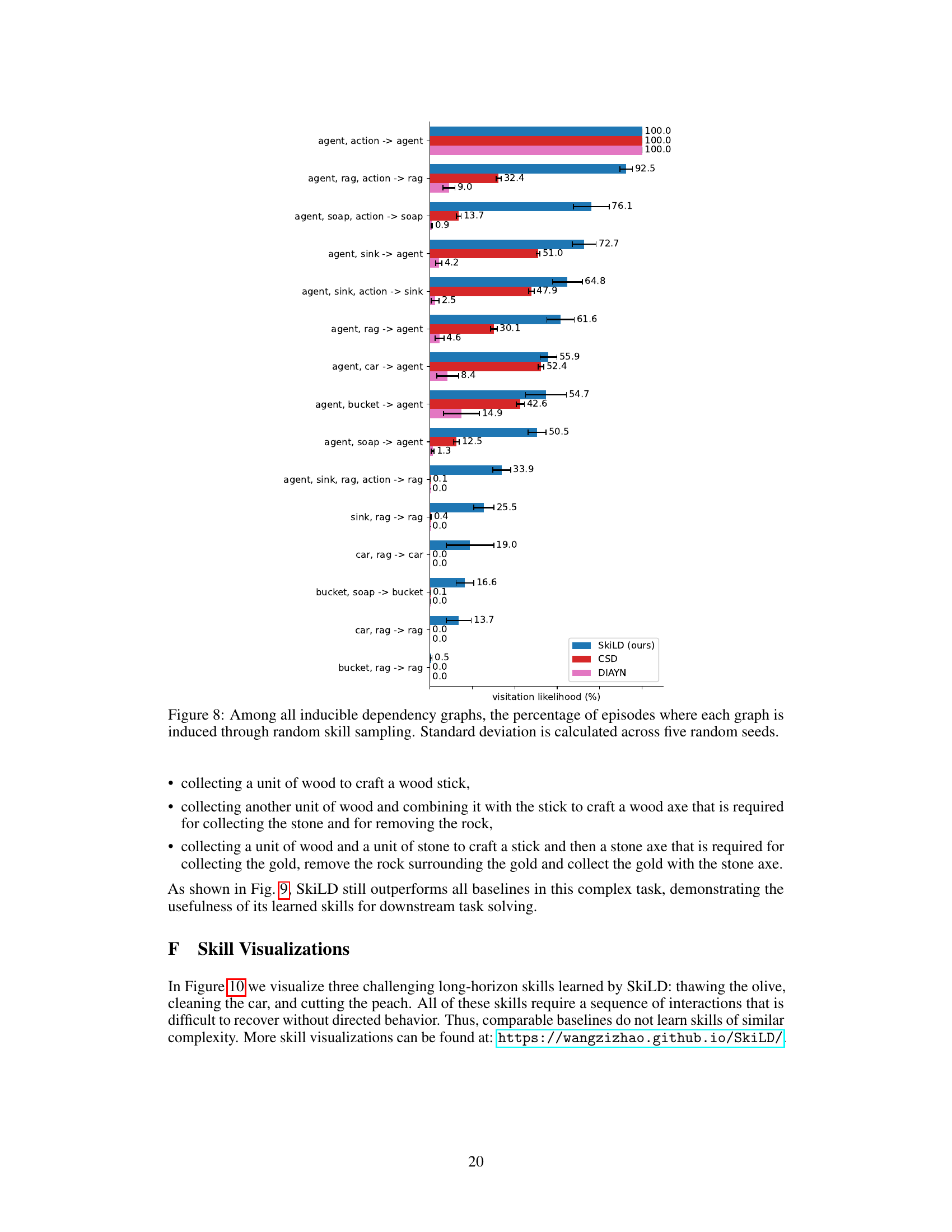
This figure shows the percentage of episodes in which various dependency graphs were induced by randomly sampling skills in the Mini-BH Cleaning Car environment. It compares the performance of SkiLD against two baseline methods, CSD and DIAYN. The results indicate that SkiLD is capable of inducing a broader range of complex, multi-factor interactions (represented by the dependency graphs) compared to the baseline methods which tend to induce simpler interactions.
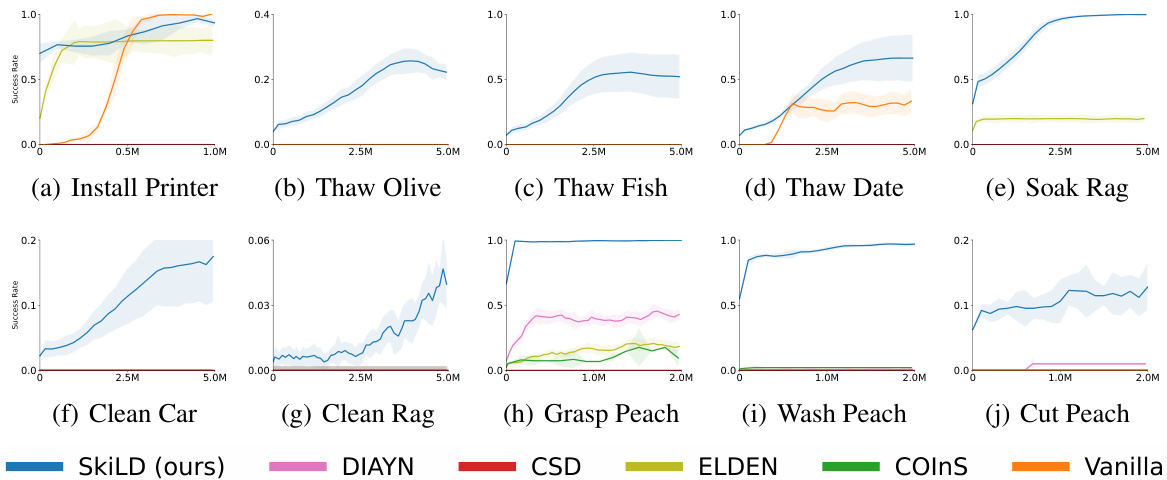
This figure shows the success rate of SkiLD and several baseline methods across ten downstream tasks in two simulated environments (Mini-Behavior and Interactive Gibson). Each task involves a sequence of actions to achieve a goal. The x-axis represents the number of training steps, and the y-axis represents the success rate. The shaded areas represent the standard deviation across five random seeds. SkiLD consistently outperforms the baselines on most tasks, indicating its ability to learn more efficient and effective skills for solving complex, multi-step problems.
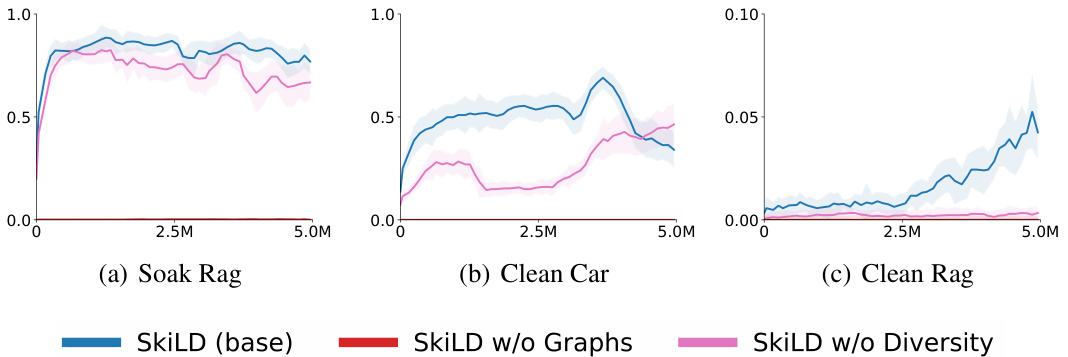
This figure shows the ablation study of SkiLD by removing either the diversity component or the dependency graphs component. The results indicate that both components are crucial for SkiLD’s performance. Removing either one significantly reduces the success rate, especially for more complex tasks like ‘Clean Car’ and ‘Clean Rag’.
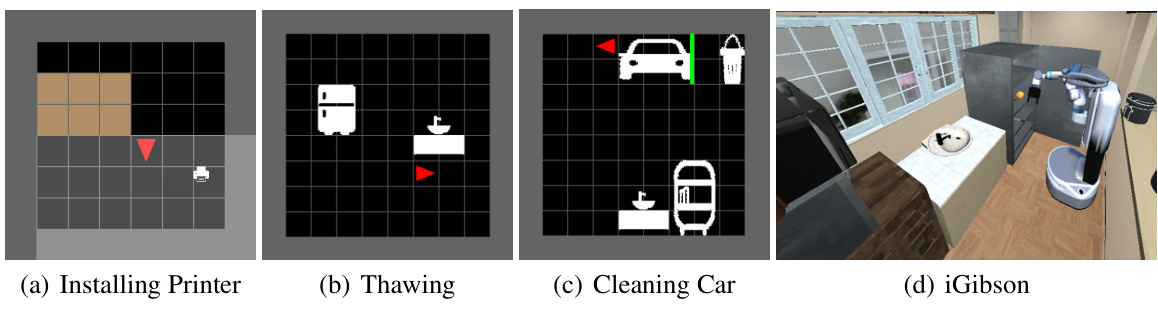
This figure shows four different environments used to evaluate the proposed skill discovery method. (a) shows a simple environment with a printer, table, and agent where the task is to install a printer on the table. (b) shows a thawing environment with a refrigerator, sink, and three objects (fish, olive, and date) to be thawed. (c) shows a cleaning car environment involving a car, sink, bucket, soap, and rag, requiring multiple interactive steps. (d) shows an iGibson kitchen environment, involving a realistic simulation of a robot interacting with a peach, knife, and sink.

This figure shows the percentage of episodes in which certain hard-to-achieve local dependency graphs were induced when randomly sampling skills in the Mini-BH Cleaning Car environment. It compares SkiLD’s performance to two baseline methods, DIAYN and CSD. The graphs represent different interactions (local dependencies) between state factors. SkiLD demonstrates a significantly higher percentage of episodes inducing complex interactions compared to the baselines, highlighting its ability to learn skills that effectively manipulate multiple state factors and induce complex interactions between them.
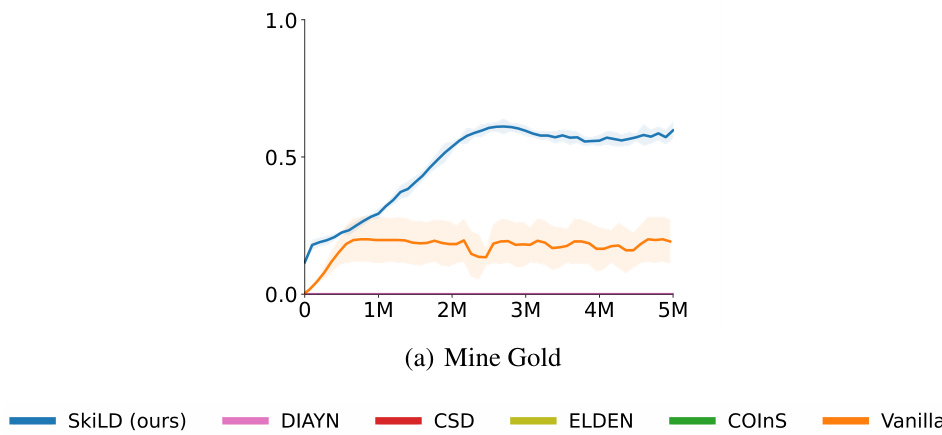
This figure displays the training curves for SkiLD and several baseline methods on a downstream task in a 2D Minecraft environment. The x-axis represents the number of training steps, and the y-axis shows the success rate (mean and standard deviation over 5 random trials). It demonstrates that SkiLD surpasses the other methods in achieving higher success rates and faster convergence.

This figure shows three example long-horizon tasks successfully completed by the proposed SkiLD method. Each column represents a different task: (a) Thawing an olive in Mini-behavior, (b) Cleaning a car in Mini-behavior, and (c) Cutting a peach in the iGibson environment. The images show a sequence of states, illustrating the steps taken by the agent to achieve the task goal. This demonstrates the ability of SkiLD to learn and execute complex, multi-step behaviors that require interaction between multiple objects.
Full paper#