↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) are computationally expensive. Mixture-of-Experts (MoE) models offer a potential solution by dynamically using specialized subnetworks, but they suffer from inefficiencies in inference. This paper introduces Read-ME, a framework that addresses these issues. Read-ME transforms a pre-trained dense LLM into a smaller MoE model, thereby avoiding the high cost of training from scratch. The key to Read-ME’s efficiency is its novel pre-gating router, decoupled from the main model. This allows for system-friendly pre-computation and lookahead scheduling, enabling effective expert-aware batching and caching. The paper demonstrates Read-ME’s superior performance over existing methods.
By separating the gating network, the paper tackles memory management and suboptimal batching in conventional MoE models. Read-ME uses activation sparsity to extract experts from a pre-trained dense model, avoiding costly training from scratch. The pre-gating router facilitates pre-computing, lookahead scheduling, and expert-aware batching, significantly enhancing efficiency. Experimental results show Read-ME outperforms other models on benchmark tasks, demonstrating the effectiveness of this novel framework in creating scalable and efficient LLMs for resource-constrained settings.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language models (LLMs) and system optimization. It provides a novel approach to efficiently deploy and use LLMs in resource-constrained environments, addressing a major bottleneck in current LLM technology. The proposed method offers significant performance improvements, opens new avenues for algorithm-system co-design, and reduces the high costs associated with training large LLMs. Its impact extends to various application domains needing efficient LLM inference, prompting further research into model refactoring and optimization techniques.
Visual Insights#

This figure illustrates the Read-ME framework. A pre-trained dense LLM is refactored into smaller expert models. The figure shows how multiple inference requests are queued and processed by a pre-gating router, which enables expert-aware batching. The timeline demonstrates how tokens are routed to experts and batched, improving efficiency.

This table provides details about the design of the router used in the Read-ME model. It shows the number of layers, heads, vocabulary size, embedding and feature dimensions, MLP intermediate dimension, activation function, positional embedding method, normalization technique, and the total number of parameters in the router. The router is a relatively small component, adding only 18 million parameters to the overall model architecture.
In-depth insights#
MoE Refactoring#
The concept of “MoE Refactoring” centers on transforming existing large language models (LLMs) into more efficient Mixture-of-Experts (MoE) architectures. This avoids the substantial cost and computational resources needed to train MoEs from scratch. Key to this approach is identifying and leveraging activation sparsity within the pre-trained LLM to extract specialized subnetworks (experts). This refactoring process necessitates a careful examination of the routing mechanisms, often revealing redundancies in traditional layer-wise router designs. Consequently, improvements are made by introducing decoupled pre-gating routers, enabling expert-aware batching and lookahead scheduling. Such algorithmic enhancements in conjunction with system-level co-design are crucial to overcome memory management challenges and unlock significant gains in inference speed and efficiency. Ultimately, MoE refactoring presents a powerful strategy for adapting existing LLMs to resource-constrained environments without sacrificing performance, potentially unlocking the benefits of MoE models for a wider range of applications.
Pre-gating Router#
The proposed pre-gating router represents a significant departure from conventional layer-wise routing in Mixture-of-Expert (MoE) models. By decoupling the routing logic from the expert networks and performing pre-computation, it enables expert-aware batching and caching. This is a key advantage, as it addresses the inefficiency of traditional MoEs where expert selection occurs dynamically layer by layer, hindering efficient memory management and batching. The pre-gating approach allows for lookahead scheduling and pre-loading of expert weights, optimizing resource utilization and latency. Moreover, the pre-gating router’s design facilitates system-level optimization, enabling algorithm-system co-design for enhanced efficiency and scalability, unlike conventional MoE implementations. The effectiveness is demonstrated by improved inference performance through efficient prefetching and Belady’s algorithm-inspired caching strategies. Reduced latency and improved tail latency are key results showcasing the impact of this innovative routing mechanism.
Expert Batching#
Efficient batching in Mixture-of-Expert (MoE) models is crucial for performance. Traditional approaches struggle because each token may activate a different subset of experts per layer, leading to inefficient utilization of computational resources and increased latency. Read-ME addresses this with a novel pre-gating mechanism. This allows for lookahead scheduling and expert-aware batching by decoupling the routing decisions from the model’s forward pass. Pre-gating enables the system to predict expert needs before inference and construct optimal batches, reducing both latency and memory footprint. The Read-ME expert-aware batching strategy also leverages Belady’s algorithm for cache management, maximizing cache hit rates. This contrasts sharply with layer-wise routing, where such optimizations are extremely difficult due to the dynamic expert activation. The result is significantly improved inference performance compared to both traditional layer-wise MoE batching and existing methods for efficient LLM serving. Read-ME’s approach significantly reduces the average number of unique experts per batch, allowing better resource allocation and accelerating inference times.
System Co-design#
The paper emphasizes the importance of system-level co-design in addressing the challenges posed by Mixture-of-Experts (MoE) models. It highlights that traditional MoE designs often suffer from misaligned choices between model architecture and system policies, leading to inefficiencies in memory management and batching. The authors advocate for a holistic approach, going beyond algorithmic improvements, to achieve efficient LLM inference. Pre-gating routers, decoupled from the MoE backbone, are proposed to enable system-friendly pre-computing and lookahead scheduling, enhancing expert-aware batching and caching. This co-design strategy, by allowing the system to pre-compute routing paths and load relevant experts before runtime, is crucial for addressing the memory management and token-batching bottlenecks, resulting in a substantial improvement in inference latency.
Future of LLMs#
The future of LLMs is bright, but complex. Efficiency gains will be crucial, moving beyond current limitations in computational resources and memory usage. This will likely involve innovations in model architecture, such as more sophisticated MoE models or novel approaches to sparsity, coupled with system-level co-design optimizing hardware and software interactions. Reducing training costs will also be paramount, potentially through more efficient training algorithms or techniques for leveraging pre-trained models more effectively. Furthermore, research into robustness, safety, and fairness will be vital, addressing biases and potential misuse. Ultimately, enhanced capabilities are anticipated, encompassing improved reasoning, better handling of complex tasks, and increased context windows for more nuanced understanding. These advancements will drive wider adoption across diverse applications, but careful consideration of ethical implications will be essential for responsible development and deployment.
More visual insights#
More on figures

This figure shows the empirical evidence of the redundancy of layer-wise routers in Mixture-of-Experts models. Panel (a) visualizes the transition matrix between the expert selections of consecutive layers, demonstrating a strong correlation and sparsity. Panel (b) shows that the mutual information between consecutive layers’ expert selections is high, further supporting the correlation. Panel (c) provides an overview of the process to fine-tune the router using a distillation loss technique.

This figure illustrates the challenges of effective batching in traditional layer-wise MoE models versus the Read-ME approach. In traditional MoEs, each token in a batch might activate a different set of experts in each layer, leading to inefficient batching. Read-ME, with its pre-gating mechanism, solves this by pre-computing expert assignments for all tokens, enabling expert-aware batching and improved efficiency. The left panel shows the process of forming batches in a traditional layer-wise MoE, demonstrating how varying expert activation leads to difficulties in combining requests efficiently. The center panel shows how the average latency increases linearly with the average number of unique expert IDs per batch. The right panel visually represents how Read-ME’s pre-gating approach allows for the creation of more efficient batches by pre-selecting experts and subsequently batching tokens with similar expert requirements together.

This figure presents a tripartite analysis of latency and temporal locality. The left panel shows a breakdown of single-inference latency for a 124-token generation task, comparing three models: OpenMoE, Llama-2-7b, and Read-ME. The center panel displays latency distributions obtained from a synthetic workload simulating the Chatbot Arena Dataset, highlighting the 95th percentile latency (p95) for Read-ME, compared against decoding-prioritized and prefill-prioritized baselines. Finally, the right panel illustrates temporal locality analysis using Arxiv and RedPajama datasets, contrasting the temporal distances between tokens in Read-ME and Mixtral-8x7B.
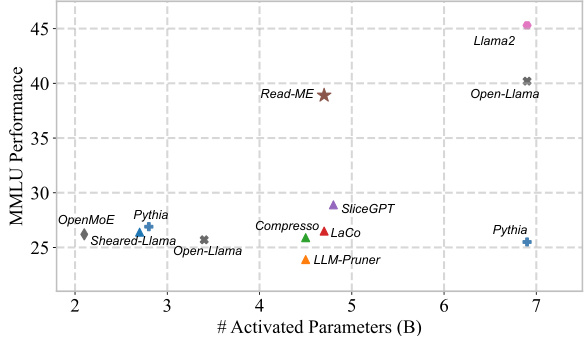
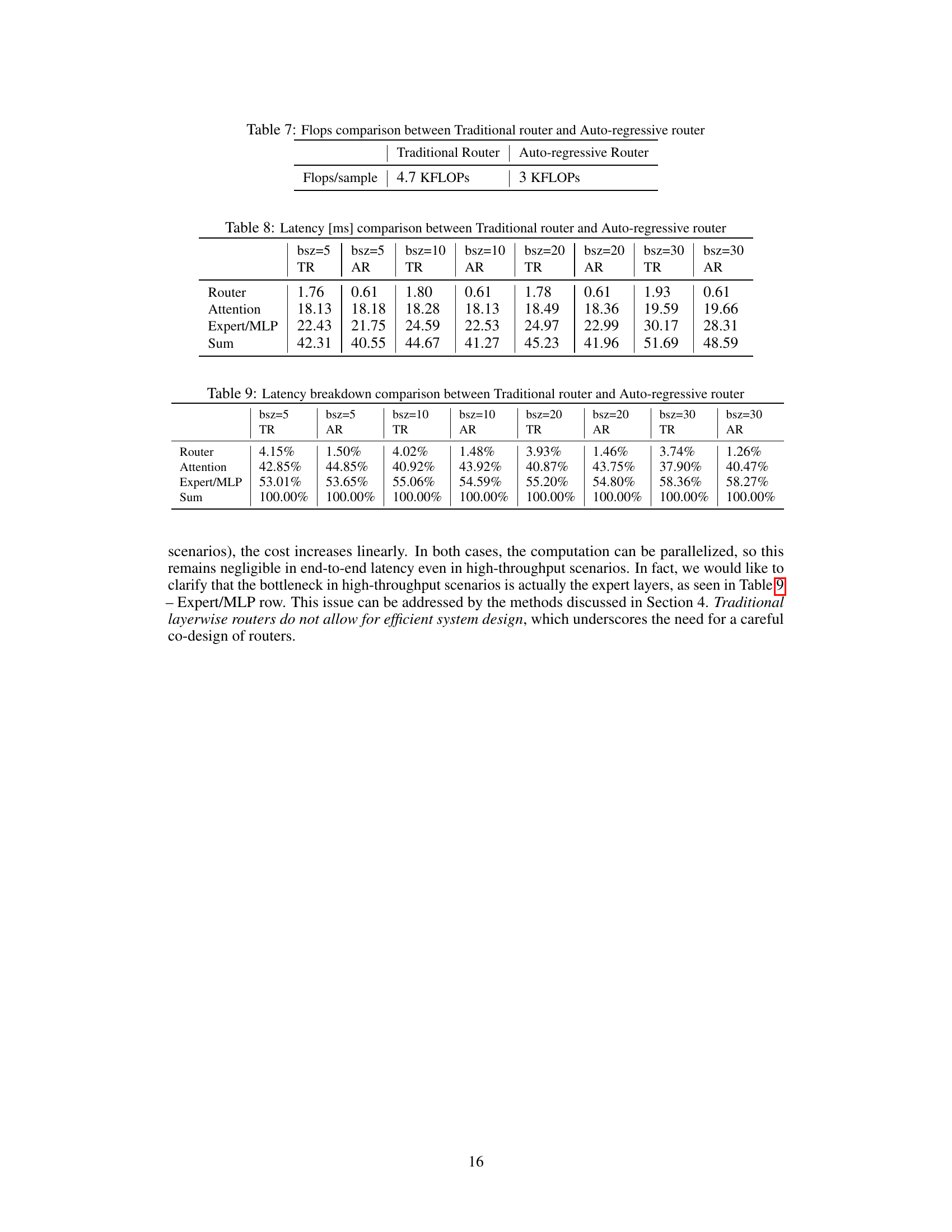
This figure compares the performance of Read-ME against other open-source models and compression techniques on the MMLU benchmark. The x-axis represents the number of activated parameters (in billions), while the y-axis shows the MMLU performance. Read-ME is highlighted with a star, demonstrating its superior performance compared to other models with similar or even higher parameter counts.

This figure compares the end-to-end latency of requests with and without prefetching for varying expert cache capacities. Prefetching, enabled by the Read-ME framework’s pre-gating mechanism, consistently outperforms on-demand loading, demonstrating significant latency reduction, especially at lower cache capacities. This highlights the effectiveness of Read-ME’s proactive expert loading strategy for efficient inference.
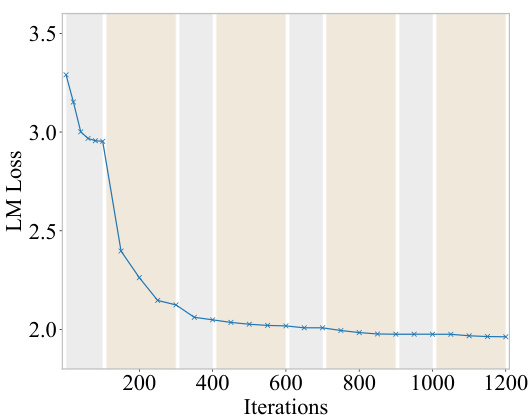
This figure shows the training loss during the first four rounds of a total of eight rounds. The gray shaded regions represent the router tuning stages, while the orange regions are the expert tuning stages. The validation loss decreases during both router and expert tuning; however, the loss reduction during router tuning plateaus after two rounds, while it continues to decrease during expert tuning.
More on tables

This table compares the performance of the proposed Read-ME model against several other open-source large language models (LLMs) on various downstream tasks. It shows metrics such as accuracy on different benchmarks (MMLU, WinoGrande, ARC-Easy, ARC-Challenge, LogiQA, CoQA) and the number of parameters used. Importantly, it highlights the training cost (number of tokens) which emphasizes the efficiency of the Read-ME approach.

This table compares the performance of the proposed Read-ME model against several other open-source LLMs on various downstream tasks. It shows the number of parameters, training cost (in tokens), and performance metrics (accuracy) across different benchmarks including MMLU, HellaSwag, Winogrande, ARC-Easy, ARC-Challenge, LogiQA, and CoQA. The table highlights Read-ME’s superior performance despite a significantly lower training cost.

This table presents the cache hit ratios achieved by three different cache replacement policies (Random, LRU, and Belady) under varying cache capacities (2, 3, 4, and 5). The Belady policy consistently demonstrates the highest hit ratio, highlighting its superiority in the context of batched inference in the Read-ME system. The results showcase the effectiveness of the Belady-inspired caching strategy employed in Read-ME, which optimizes memory usage and latency during inference by pre-computing expert selections.

This table compares the performance of the Read-ME model with a dense model. The comparison is done using the MMLU benchmark and perplexity scores across seven different datasets (Arxiv, Books, C4, Common Crawl, Github, StackExchange, Wikipedia). Read-ME shows significantly better overall performance by using a Mixture-of-Experts (MoE) architecture instead of a dense model.

This table compares the performance of the Read-ME model against several other open-source models on various downstream tasks. It shows the number of parameters, training cost (in tokens), and performance metrics (accuracy) for each model on tasks like MMLU, HellaSwag, Winogrande, ARC, LogiQA, and CoQA. The table highlights the efficiency of Read-ME in achieving comparable or better performance with significantly reduced training cost and parameters.

This table compares the performance of the proposed Read-ME model against several other open-source large language models (LLMs) on various downstream tasks. It shows the number of parameters, training cost (in tokens), and performance metrics (accuracy) across different benchmarks, such as MMLU, Hellaswag, and ARC. It highlights that Read-ME achieves competitive performance while using significantly fewer training tokens than other methods, demonstrating its efficiency in leveraging pre-trained models.

This table compares the latency in milliseconds (ms) between the traditional router and the auto-regressive router for different batch sizes (bsz). It breaks down the latency into three components: Router, Attention, and Expert/MLP, and provides the total sum for each configuration. The auto-regressive router consistently shows lower latency across all batch sizes.

This table presents a breakdown of latency across different components (Router, Attention, Expert/MLP) for both traditional and auto-regressive routers under varying batch sizes (bsz). It demonstrates how the latency is distributed across these components and how this distribution changes with batch size for the two router types.
Full paper#