↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current score distillation sampling (SDS) methods for image generation often produce artifacts like oversaturation and oversmoothing. These issues stem from linear approximations of optimal transport paths and inaccurate source distribution estimations. The paper identifies these limitations, framing SDS as an approximation of the Schrödinger Bridge problem.
The authors introduce a novel method using textual descriptions to calibrate the source distribution, significantly improving image quality with minimal computational overhead. Their approach outperforms existing SDS variants across diverse tasks, including text-to-image, text-to-3D, and painting-to-real, demonstrating its effectiveness and versatility.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with diffusion models and image generation. It provides a novel framework for understanding score distillation sampling (SDS), a widely used technique, and offers a simple, efficient solution to improve its performance. This work opens new avenues for optimizing image generation across various modalities and enhances the understanding of optimal transport methods in this field.
Visual Insights#

This figure illustrates the core idea of the paper: viewing score distillation sampling (SDS) methods as approximating the solution to a Schrödinger Bridge problem. Panel (a) shows how SDS methods try to bridge the gap between a source distribution (e.g., noisy or corrupted images) and a target distribution (natural images) by iteratively moving points in the source distribution closer to the target. However, the figure points out two key limitations of this approach: the linear approximation of the optimal transport path and an inaccurate estimate of the source distribution. Panel (b) focuses on the second limitation – the mismatch between the assumed source distribution and the actual distribution of the current optimized images, highlighting another potential source of error in standard SDS methods.

This table compares the performance of several score distillation methods for text-to-image generation. The FID (Fréchet Inception Distance) and CLIP FID scores are reported, which are lower is better, measuring the quality of generated images compared to real images. The time taken per sample generation is also provided for each method. The table highlights the best-performing method in bold and the second-best in underlined font.
In-depth insights#
SDS as Optimal Transport#
Reframing Score Distillation Sampling (SDS) as an optimal transport problem offers crucial insights into its inner workings and limitations. This perspective reveals how SDS attempts to bridge the gap between a source image distribution (often noisy or corrupted) and a target distribution (natural images), essentially solving an optimal transport path. Viewing SDS through this lens highlights the role of the source distribution estimate; inaccuracies in estimating the source distribution lead to artifacts like oversaturation and oversmoothing. Moreover, the linear approximation of the optimal transport path, inherent in most SDS methods, introduces further errors. This reinterpretation paves the way for improved methods, by focusing on better source distribution modeling and/or utilizing more sophisticated optimal transport solvers to accurately find the transport path between the distributions. The success of using textual descriptions to specify the source distribution emphasizes the potential of leveraging readily available information, such as textual descriptions, to improve performance without significant added computational costs. This novel approach offers a powerful framework for understanding, improving and designing novel score distillation sampling algorithms.
Dual Bridge Framework#
The Dual Bridge Framework, a conceptual model proposed in the research paper, offers a novel perspective on score distillation sampling (SDS) by reframing the optimization process as a solution to the Schr
ödringer Bridge problem. This elegant framework bridges two probability distributions: a source distribution representing the current optimized image and a target distribution representing the desired image. Crucially, it reveals two key sources of error in existing SDS methods. Firstly, current SDS methods approximate the optimal transport path between these distributions linearly, using single denoising steps instead of a more accurate full probability flow ODE simulation, thus causing inaccuracy. Secondly, these methods often rely on poor estimates of the source distribution, usually using the unconditional image distribution. This leads to a significant “distribution mismatch”, resulting in common SDS artifacts such as oversaturation and oversmoothing. Therefore, this framework offers a principled way to understand and improve SDS, suggesting methods to address these shortcomings and achieve higher quality image generation.
Text-Guided Optimization#
Text-guided optimization, a core concept in bridging the gap between text descriptions and image generation, focuses on using pre-trained diffusion models to guide the refinement of images toward a desired visual representation based on text prompts. This process involves iterative updates to the image’s parameters, using gradients derived from the diffusion model’s scores to quantify the difference between the current image and its ideal counterpart as described in the text. The efficacy of this method is largely determined by how well the source image distribution (the starting point of the optimization) aligns with the target distribution (the desired image). Mismatches can lead to characteristic artifacts such as oversaturation or oversmoothing, while poor approximation of the optimal path between source and target distributions results in additional visual errors. Recent advancements aim to mitigate these problems by improving estimates of the source distribution and enhancing the accuracy of the approximation method. This often involves incorporating textual descriptions of the source image to better represent its characteristics, effectively guiding the optimization process towards more realistic and high-quality outputs. The approach offers potential for significant improvements in various image generation and editing applications, particularly in data-scarce domains where it can leverage large pre-trained models to effectively guide the generation process.
Source Dist. Mismatch#
The concept of ‘Source Dist. Mismatch’ in the context of score distillation highlights a critical limitation of existing methods. Current approaches often assume the source distribution (e.g., the distribution of the images being optimized) is similar to the unconditional distribution of the pre-trained diffusion model. This is inaccurate, especially when initializing with random noise or low-quality images. This mismatch leads to artifacts like oversaturation and oversmoothing because the denoising process isn’t properly guided from the true source to the target. Calibrating the source distribution is crucial for accurate transport between the distributions. The paper suggests using textual descriptions to characterize the source distribution, leveraging the powerful text conditioning capabilities of large-scale diffusion models. This simple approach effectively bridges the gap, leading to improved transport and generating high-frequency details and realistic colors in the output. This addresses the problem without incurring significant computational overhead, making it a practical and effective solution to improve score distillation techniques.
Linear Approx. Error#
The concept of “Linear Approx. Error” in the context of score distillation methods for image generation highlights a critical limitation. Current methods often employ a first-order approximation of the optimal transport path between image distributions, sacrificing accuracy for computational efficiency. This linear approximation, essentially a single-step denoising process, fails to fully capture the complex, non-linear relationship between the source (e.g., a noisy or synthetic image) and target (natural image) distributions. Consequently, this simplification leads to characteristic artifacts like oversaturation and oversmoothing, as the generated images fail to adequately reflect the high-frequency details and realistic color found in natural images. Addressing this “Linear Approx. Error” requires a more sophisticated approach, such as employing multi-step denoising or solving the underlying Schrödinger Bridge problem more accurately. This improvement, however, comes at the cost of increased computational burden. The trade-off between accuracy and efficiency is a key challenge in this field, and finding novel techniques to minimize linear approximation error while maintaining computational feasibility is crucial for the advancement of image generation using score distillation.
More visual insights#
More on figures

This figure illustrates the proposed framework for understanding score distillation optimization using diffusion models. Panel (a) shows the optimization process as a bridge between the current image distribution and the target distribution, highlighting the approximation inherent in existing methods. Panel (b) emphasizes the source distribution mismatch error. This helps to visualize the core idea of the paper, which is to reformulate optimization with diffusion models as a Schrödinger Bridge Problem to explain existing methods and motivate a new, improved one.

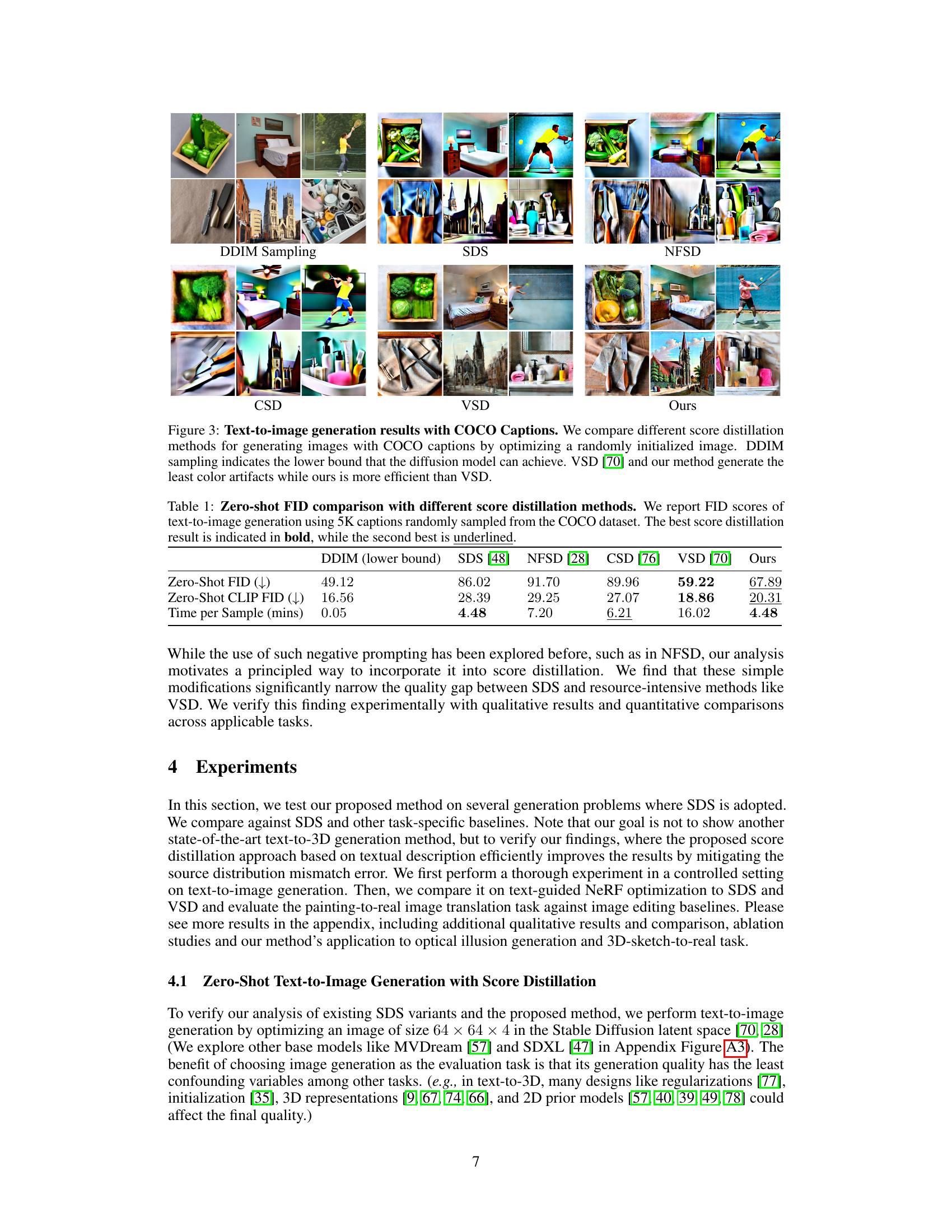
This figure compares different score distillation methods (DDIM Sampling, SDS, NFSD, CSD, VSD, and the proposed method) for text-to-image generation using COCO captions. Each method starts with a randomly initialized image and optimizes it to match the caption. The results demonstrate the effectiveness of the proposed method in generating high-quality images with fewer color artifacts compared to other baselines, especially VSD, while also being computationally more efficient.

This figure compares the results of text-guided NeRF optimization using different score distillation methods: SDS, VSD, and the proposed method. Three uniformly sampled views are shown for each generated 3D object. The results show that the proposed method and VSD produce more realistic details, colors, and textures compared to SDS, which exhibits over-saturation artifacts.

This figure compares several methods for enhancing the realism of paintings by optimizing them using different approaches. The methods include a simple plug-and-play method, score distillation sampling (SDS), SDEdit (with a specific strength setting), CycleGAN, and the proposed method from the paper. The results demonstrate that the proposed method outperforms others in maintaining faithfulness to the original painting while significantly increasing realism.

This figure compares the results of painting-to-real image generation using different methods: the proposed method, SDEdit (with different strength values), Plug-and-Play, and CycleGAN. The results show that the proposed method achieves a better balance between structure and quality compared to other methods. SDEdit shows promising results, but struggles to find the optimal strength parameter balance, while the other methods fail to achieve natural image quality.

This figure shows a comparison of 3D sketch-to-real generation using two different methods: the proposed method and the SDS baseline. The input is a coarse 3D sketch of a flower. The proposed method generates a high-quality 3D model of a flower with realistic colors and textures, while the SDS baseline generates a lower-quality model with less detail and less realistic colors.
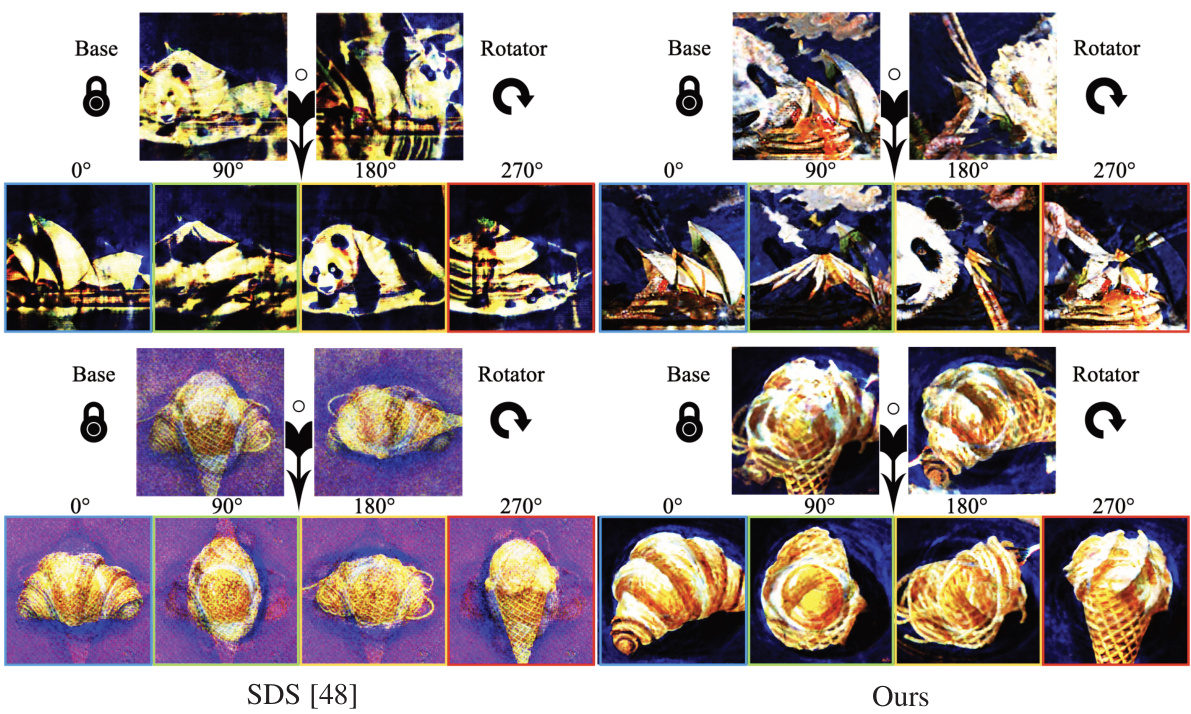
This figure compares the results of generating overlaid optical illusions using two different methods: Score Distillation Sampling (SDS) and the proposed method from the paper. The top row shows the base and rotator images used for both methods. The bottom rows illustrate the generated illusions at 0°, 90°, 180°, and 270° rotations, respectively, for each method. The results demonstrate that the proposed method produces significantly improved color accuracy, realism and detail compared to SDS, which suffers from color artifacts.

This figure compares the results of different score distillation methods for text-to-image generation using COCO captions. Each method starts with a randomly initialized image and refines it using the respective method. DDIM sampling serves as a baseline representing the lower bound on image quality achievable by the diffusion model itself. The figure highlights that both VSD (Variational Score Distillation) and the proposed method in the paper yield images with fewer color artifacts than other methods, but that the proposed method achieves better efficiency.

This figure compares the results of applying the proposed two-stage optimization method (replacing SDS) within three different text-to-3D generation baselines: Fantasia3D, Magic3D, and CSD. The improvements in detail, visual quality, and reduction of SDS artifacts are highlighted.

This figure shows the results of an ablation study on the impact of different negative prompts in the two-stage optimization method. It compares the results of using the authors’ proposed negative prompts against five alternative sets generated using GPT-4. The goal was to determine if the choice of negative prompt significantly affected the results. The results show that all negative prompts produce similar improvements, outperforming the original Score Distillation Sampling (SDS) baseline.

This figure shows an ablation study comparing three different optimization approaches: (a) using only the second stage of the proposed method (SDS + Stage 2 source prompt), (b) using only the first stage (SDS), and (c) using both stages (Ours). The results demonstrate that starting the optimization directly with the second stage’s source prompt (Ysrc) can negatively impact the quality of the generated geometry, leading to unnatural or undesirable elements. In contrast, using both stages of the proposed method produces significantly better results in terms of geometric accuracy and overall coherence.

This figure compares several score distillation methods for text-to-image generation using COCO captions. Each method starts with a randomly initialized image and iteratively refines it using the respective method’s gradient. The results showcase the visual quality and presence of artifacts (e.g., color distortions) for each method. The figure highlights that VSD and the proposed method produce images with the fewest artifacts, while the proposed method is more computationally efficient.
More on tables
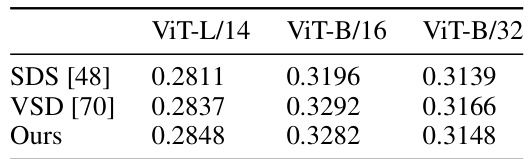
This table compares the Fréchet Inception Distance (FID) scores and CLIP FID scores of different score distillation methods for zero-shot text-to-image generation. Lower FID scores indicate better image quality. The results are based on 5,000 captions from the COCO dataset. The table also shows the time taken per sample generation for each method. It highlights the best performing method in bold and the second-best method in underlined font.

This table presents a comparison of different score distillation methods for text-to-image generation, evaluated using the Fréchet Inception Distance (FID) score. The methods are compared on their ability to generate high-quality images from text prompts, using a zero-shot setting where the models have not been specifically trained on the COCO dataset. The table shows the FID scores, CLIP FID scores (another metric for image quality), and the time required per sample for each method. The best performing methods are highlighted.
Full paper#