↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current text-to-image models struggle with generating images based on detailed layout information, often resulting in missing objects, inconsistent lighting, or conflicting viewpoints. Existing methods either lack fine-grained control or suffer from issues like object omission, especially in complex layouts. This necessitates the development of advanced models that can better handle detailed layout specifications and generate more harmonious and holistic images.
HiCo addresses this challenge with a novel hierarchical and controllable diffusion model. It uses a unique multi-branch structure to model layouts hierarchically, enabling spatial disentanglement and high-quality image generation. The model shows significant improvements in complex layouts, achieving state-of-the-art performance on both open-ended and closed-set benchmarks. Moreover, HiCo’s flexible scalability allows for easy integration with other diffusion models and plugins, making it a versatile and valuable tool for researchers.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces HiCo, a novel and effective model for layout-to-image generation. This addresses a key challenge in image synthesis by enabling precise control over the spatial arrangement of objects, leading to more realistic and visually appealing results. The proposed hierarchical structure and fusion mechanism offer a flexible and scalable approach, paving the way for more advanced applications in image editing and generation, especially in complex scenarios. Its high compatibility with existing diffusion models and its potential for improvement makes it a valuable contribution to the field.
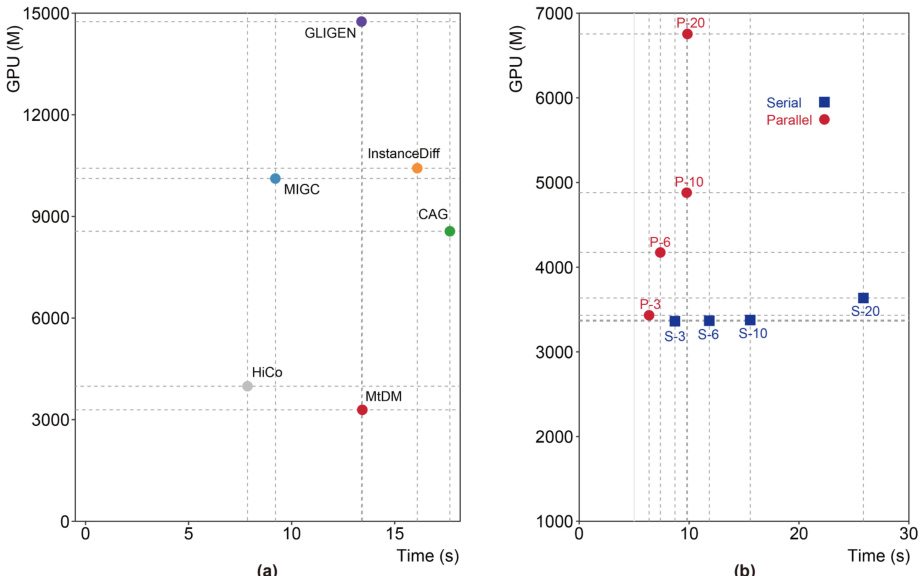
Visual Insights#

This figure showcases the HiCo model’s ability to generate images based on complex layouts. It highlights how the model integrates bounding box conditions of different objects hierarchically, leading to more harmonious and holistic images. Four examples are presented: (a) Layout-grounded generation with closed-set short descriptions, (b) Layout-grounded generation with open-ended fine-grained descriptions, (c) HiCo’s compatibility with different Stable Diffusion (SD) variants, and (d) Multi-concept generation by HiCo with multiple LoRAs. Additionally, (e) shows fast inference using HiCo-LCM/HiCo-Lightning.
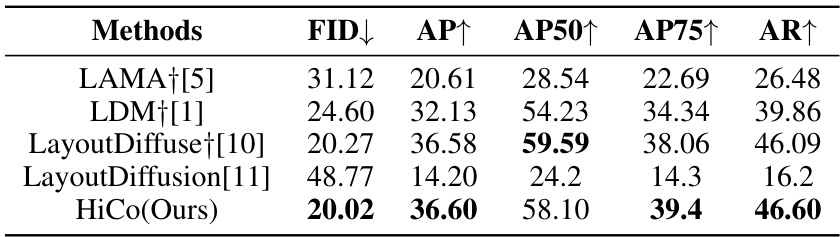
This table presents a quantitative comparison of the HiCo model against other state-of-the-art models on the COCO-3K dataset for coarse-grained closed-set text2img generation. The metrics used are FID (Frechet Inception Distance), AP (Average Precision), AP50 (Average Precision at 50% IoU), AP75 (Average Precision at 75% IoU), and AR (Average Recall). Lower FID indicates better image quality, while higher values for AP, AP50, AP75, and AR represent better object detection performance.
In-depth insights#
HiCo: Layout Control#
HiCo’s layout control mechanism is a hierarchical and multi-branch approach, cleverly disentangling the complexities of spatial arrangement in image generation. Instead of a monolithic approach, HiCo utilizes separate branches to model the background and individual foreground objects, each with its dedicated textual and positional cues. This hierarchical structure allows for finer granularity in control, enabling the model to handle intricate layouts with multiple objects. The use of a Fuse Net to combine these separate branches is also noteworthy, enabling a flexible and effective means of integrating the different visual components into a cohesive whole. The success of HiCo’s layout control lies in its capacity to disentangle spatial information, avoiding the common pitfalls of conflicting view angles, missing objects and inconsistent lighting frequently seen in previous text-to-image models. This novel architecture offers a scalable and robust method for layout control and represents a significant improvement for advanced image synthesis, setting the stage for more intricate and finely controlled image generation tasks.
Hierarchical Modeling#
Hierarchical modeling, in the context of layout-to-image generation, offers a powerful approach to address the complexities of spatial relationships between objects. By structuring the model hierarchically, it allows for disentangled representation of layout features, enabling a more nuanced understanding of object interactions. This approach facilitates a granular level of control, offering the potential for more accurate and harmonious image synthesis, even in scenarios with dense or overlapping objects. A hierarchical structure can improve model performance by promoting efficient learning and scalability. It allows the model to learn simpler, lower-level features at initial stages, subsequently combining these to form more complex, high-level representations. The use of multiple branches, each focusing on a specific level of detail or subset of objects, enhances model capacity and leads to improved results. The key lies in the effective aggregation of these hierarchical representations to create a coherent and holistic final image, overcoming challenges posed by traditional methods that struggle with complex layouts and fine-grained control.
Multi-branch HiCo Net#
The proposed multi-branch HiCo Net architecture is a key innovation for enhancing layout control in image generation. By independently modeling the background and multiple foreground objects, it achieves spatial disentanglement. Each branch, inspired by ControlNet and IP-Adapter, extracts hierarchical layout features specific to its assigned region. Weight sharing between branches promotes efficient learning and consistency. The resulting features are then refinedly aggregated using a novel, non-parametric Fuse Net, which flexibly handles the fusion process through techniques like masking. This design allows for fine-grained control over individual objects and their spatial relationships, overcoming limitations of previous methods in complex layout generation and leading to more harmonious and holistic image synthesis. Hierarchical modeling of layouts is central to HiCo’s success, enabling it to address challenges like object omissions and lighting inconsistencies, resulting in superior image quality and overall composition.
HiCo-7K Benchmark#
The creation of a robust benchmark dataset is crucial for evaluating progress in layout-to-image generation. The HiCo-7K benchmark, derived from the GRIT-20M dataset, addresses the need for a comprehensive evaluation standard. Its creation involved several steps: manual cleaning to eliminate ambiguities and inconsistencies; grounding-DINO was applied to re-validate object regions, ensuring accuracy; and finally, CLIP was used to filter based on semantic relevance. This rigorous approach ensures the quality and reliability of HiCo-7K. The benchmark’s open-ended nature, with an average of 3.78 objects per image, provides a challenging evaluation for models generating complex and varied layouts. The inclusion of HiCo-7K thus provides an important contribution to the field, allowing for a more objective comparison of models and fostering advancements in layout-to-image generation techniques.
Future Enhancements#
The research paper on HiCo, a Hierarchical Controllable Diffusion Model for Layout-to-image Generation, presents a strong foundation but leaves room for several future enhancements. Improving the handling of complex layouts and occlusions is crucial, as the current model struggles with intricate arrangements and overlapping objects. This could involve exploring more sophisticated fusion mechanisms in the Fuse Net or integrating explicit occlusion reasoning into the model architecture. Extending the model’s capacity for multi-concept generation is another key area. While HiCo demonstrates some capability with multiple LoRAs, more robust integration and a more principled approach to combining diverse concepts are needed. Addressing the limitations of the current LoRA integration is important. Although HiCo shows compatibility with rapid generation plugins, developing a more seamless and efficient integration strategy would improve the user experience and enhance the model’s scalability. Furthermore, creating a more comprehensive benchmark dataset that better captures the nuances of multi-objective layout generation would significantly benefit the field. Finally, investigating the model’s performance on diverse image modalities and exploring its potential for applications beyond layout-to-image generation are worthwhile avenues of exploration.
More visual insights#
More on figures

This figure shows several examples of images generated by the HiCo model, highlighting its ability to control the layout of the generated images. The first row shows images generated with short and fine-grained descriptions, respectively. The second row demonstrates the compatibility of HiCo with different Stable Diffusion variants and its ability to generate multi-concept images. The third row showcases fast inference with HiCo-LCM and HiCo-Lightning.

This figure demonstrates the HiCo model’s ability to generate images based on layouts. It shows four examples highlighting different aspects: (a) simple layout with short descriptions; (b) complex layout with detailed descriptions; (c) compatibility with different Stable Diffusion variants; (d) multi-concept generation using LoRA; and (e) fast inference with HiCo-LCM/HiCo-Lightning. The core idea is to improve the controllability of image generation by hierarchically integrating bounding boxes of different objects to create more coherent and visually appealing results.

This figure showcases the HiCo model’s ability to generate images based on a given layout. It demonstrates HiCo’s capability to handle complex layouts by hierarchically integrating bounding box conditions of different objects. The unique conditioning branch structure enables the model to produce images with a higher degree of harmony and holism compared to previous methods. The figure displays example images showing results with closed-set short descriptions, open-ended fine-grained descriptions, compatibility with different Stable Diffusion (SD) variants, multi-concept generation with multiple LoRAs, and fast inference using HiCo-LCM or HiCo-Lightning.

This figure shows several example images generated by the HiCo model, highlighting its ability to generate images with complex layouts based on textual and positional descriptions of objects. Panel (a) demonstrates the generation of an image from a closed-set of short descriptions. Panel (b) shows generation from open-ended, more detailed descriptions. Panel (c) illustrates the model’s compatibility with various Stable Diffusion variants. Panel (d) shows the model’s ability to handle multiple concepts within a single image. Finally, panel (e) showcases fast inference capabilities using HiCo-LCM and HiCo-Lightning.

This figure compares the image generation results of three different models (CAG, GLIGEN, and HiCo) on complex layouts. The input is a complex layout specified by object positions and descriptions. CAG fails to generate several objects, demonstrating its inability to handle complex scenarios. GLIGEN performs better, but still shows some distortions and inaccuracies. HiCo shows significant improvement in object completeness and overall image quality. This highlights HiCo’s strength in producing accurate and realistic images even in the face of complex layouts.
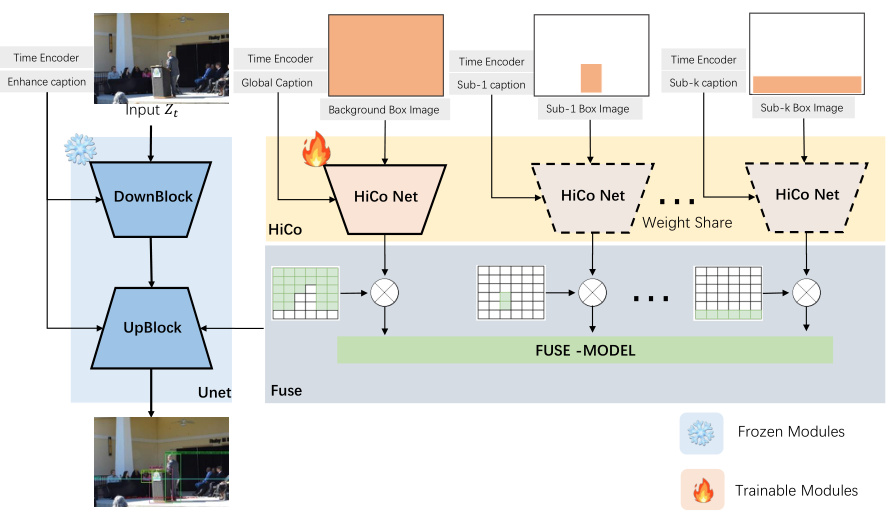
The figure shows the overall architecture of the HiCo model for layout-to-image generation. It consists of multiple branches of HiCo Nets, each independently modeling a different foreground object or the background. Each branch takes as input the corresponding textual description and bounding box information for its respective object. The branches are then aggregated in a Fuse Net module, which combines their features to generate a holistic representation of the layout. This representation is then fed to a frozen UNet model, which generates the final image. The diagram highlights that the HiCo Net is trainable while the UNet is frozen, showcasing the hierarchical nature of the model.
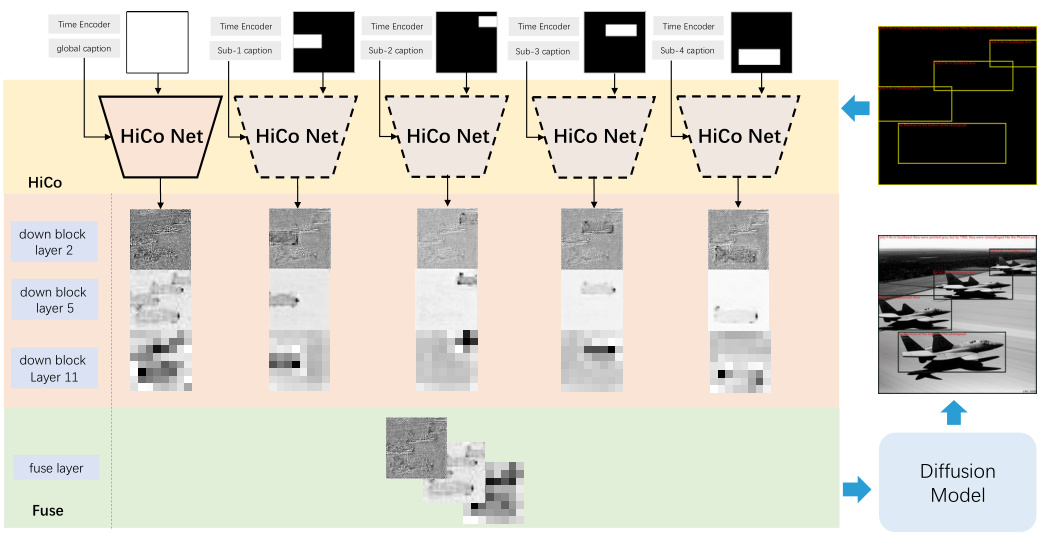
This figure visualizes the features extracted by different layers of the HiCo branch and Fuse Net. The HiCo Net uses a multi-branch architecture, each branch processing a different part of the layout. This figure shows features from layers 2, 5, and 11 during downsampling. It illustrates how shallow layers respond to layout areas, intermediate layers refine object details, and deeper layers integrate regional information for layout control. The fusion process of the HiCo branches uses a masking technique.

This figure illustrates two different approaches for integrating LoRA (Low-Rank Adaptation) into the HiCo diffusion model for fine-tuning. (a) shows LoRA parameters added to the UNet, a common approach for adjusting the underlying image generation process. (b) demonstrates the addition of LoRA parameters specifically to the HiCo model, enabling more targeted fine-tuning focused on layout control and potentially enhancing efficiency.

This figure showcases the HiCo model’s ability to improve layout control in text-to-image generation. It highlights how HiCo uses a hierarchical approach, integrating bounding boxes of objects to generate images with complex layouts. The unique conditioning branch structure enables the creation of more harmonious and holistic images. Four image examples are given demonstrating HiCo’s effectiveness with different scenarios: using short, closed-set descriptions; using longer, open-ended descriptions; compatibility with different Stable Diffusion variants; and multi-concept generation.

This figure shows a qualitative comparison of image generation results between HiCo and other state-of-the-art methods on the HiCo-7K dataset. The dataset contains images with varying levels of layout complexity. For each image, the layout, ground truth image, and the outputs of several different models are displayed. The results demonstrate that HiCo generates high-quality, detailed images with accurate object placement and relationships, even for layouts that are highly complex. In contrast, the other models exhibit issues such as object omission, misplacement, and inconsistencies in image quality and style.
This figure demonstrates the HiCo model’s ability to generate images based on a given layout. It showcases how HiCo uses a hierarchical approach, integrating bounding box conditions of different objects to achieve improved layout control in text-to-image generation. The unique conditioning branch structure enables the generation of more harmonious and complete images, even with complex layouts. The figure includes four subfigures illustrating different aspects of HiCo’s capabilities: layout-grounded generation with closed-set short descriptions, layout-grounded generation with open-ended fine-grained descriptions, HiCo’s compatibility with different Stable Diffusion variants, and multi-concept generation using multiple LoRAs.

This figure demonstrates the HiCo model’s ability to improve layout control in text-to-image generation. It achieves this through a hierarchical integration of bounding boxes representing different objects. The unique multi-branch structure of the model ensures that the generated images have a more harmonious and complete layout, even in complex scenarios.

This figure demonstrates the HiCo model’s ability to improve layout control in text-to-image generation. It uses a hierarchical approach, integrating bounding boxes of objects to enhance controllability. The unique multi-branch structure allows the model to create more harmonious and complete images, especially those with complex layouts. Subfigures (a) and (b) show layout-grounded generation with different levels of description detail. Subfigures (c) and (d) highlight HiCo’s compatibility with different Stable Diffusion variants and its capability for multi-concept generation using multiple LoRAs. Finally, (e) shows the fast inference capabilities.

This figure shows examples of images generated by the HiCo model, highlighting its ability to control the layout of objects in the image. The model takes as input a layout description, which includes textual descriptions and bounding boxes for each object. (a) demonstrates generation with a closed set of short descriptions, (b) with open-ended and fine-grained descriptions. (c) shows HiCo’s compatibility with different Stable Diffusion variants, (d) shows the ability to generate images with multiple concepts using multiple LoRAs, and (e) demonstrates fast inference using HiCo-LCM or HiCo-Lightning. The overall result shows the model successfully places objects according to the given layout, creating visually coherent and harmonious images.

This figure shows several examples of images generated by the HiCo model, highlighting its ability to handle complex layouts. Panel (a) demonstrates generation with closed-set short descriptions, (b) shows generation with open-ended fine-grained descriptions, (c) illustrates HiCo’s compatibility with different Stable Diffusion variants, (d) showcases multi-concept generation using multiple LoRAs, and (e) highlights the fast inference capabilities of HiCo-LCM and HiCo-Lightning. The overall theme is that HiCo effectively integrates bounding box information for various objects to create coherent and visually appealing images, even with complex scene arrangements.

This figure shows several examples of images generated by the HiCo model, highlighting its ability to control the layout of objects in the image. The first row demonstrates the model’s ability to generate images based on both short and detailed descriptions with specific object layouts. The second row shows HiCo’s compatibility with different Stable Diffusion (SD) variants and how it generates images with multiple concepts using different LoRAs. Finally, the third row illustrates the speed of the HiCo-LCM and HiCo-Lightning inference methods, showcasing their capability to generate images quickly.

This figure showcases the HiCo model’s ability to generate images based on complex layouts. It highlights how the model uses hierarchical bounding boxes to condition the generation process, leading to more harmonious and complete images, even with intricate layouts. Several example image generation results are displayed, illustrating various aspects of the model’s capabilities.

This figure showcases the capabilities of the HiCo model in generating images based on complex layouts. It demonstrates how HiCo integrates bounding box information of various objects hierarchically, leading to more coherent and visually appealing results compared to methods that lack this hierarchical control. The figure uses several examples to highlight HiCo’s ability to handle open-ended descriptions, compatibility with various Stable Diffusion variants, multi-concept generation using LoRA, and fast inference with HiCo-LCM/HiCo-Lightning.
More on tables
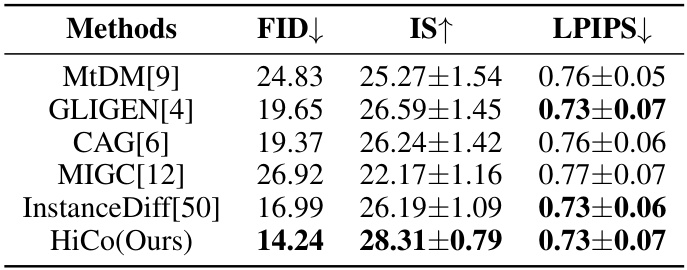
This table presents a quantitative comparison of different models’ performance on the HiCo-7K dataset, focusing on perception-related metrics. It shows the FID (Frechet Inception Distance), IS (Inception Score), and LPIPS (Learned Perceptual Image Patch Similarity) scores for several methods, including the proposed HiCo model. Lower FID and LPIPS scores, and higher IS scores, generally indicate better image quality and perceptual similarity to real images.

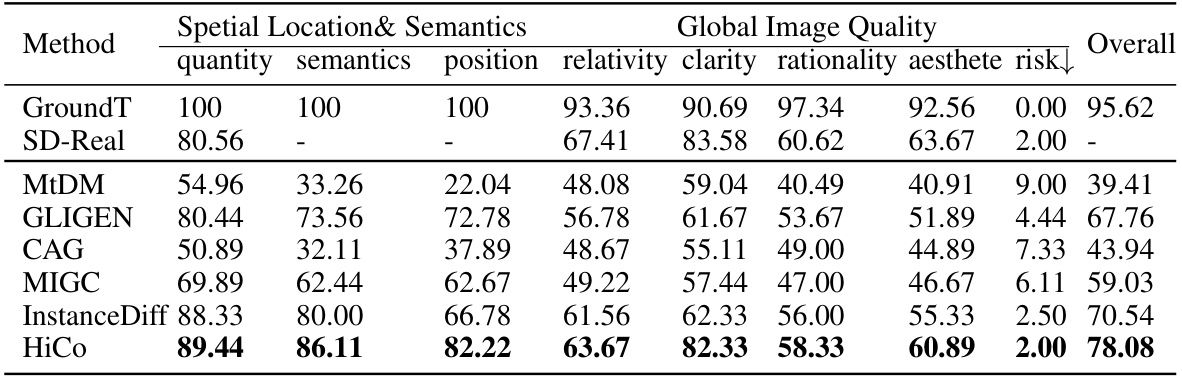
This table presents a quantitative comparison of spatial location dimensions achieved by different methods on the HiCo-7K dataset. The metrics used are LocalCLIP Score (measuring the consistency between generated objects and their textual descriptions), LocalIoU Score (measuring the overlap between predicted and ground truth bounding boxes), and standard object detection metrics like AR, AP, AP50, and AP75. Higher scores indicate better performance. The results demonstrate that HiCo achieves superior positional control and alignment between image content and text descriptions compared to other methods.

This table presents a quantitative comparison of different methods on the HiCo-7K dataset focusing on spatial location. The metrics used are LocalCLIP Score (measuring the consistency between the generated image and the text), LocalIoU Score (measuring the overlap between generated and ground truth bounding boxes), AR (average recall), AP (average precision), AP50 (average precision at IoU threshold of 0.5), and AP75 (average precision at IoU threshold of 0.75). Higher scores indicate better performance in terms of object location accuracy and alignment with the given text.
This table presents a quantitative comparison of the HiCo model’s performance against other state-of-the-art layout-to-image generation methods on the COCO-3K dataset. The comparison uses four metrics: FID (Frechet Inception Distance), AP (Average Precision), AP50 (Average Precision at 50% IoU), and AR (Average Recall). Lower FID scores indicate better image quality, while higher AP, AP50, and AR scores represent better object detection performance. The table shows that HiCo outperforms the other methods across all metrics, indicating its superior performance in generating high-quality images with complex layouts.
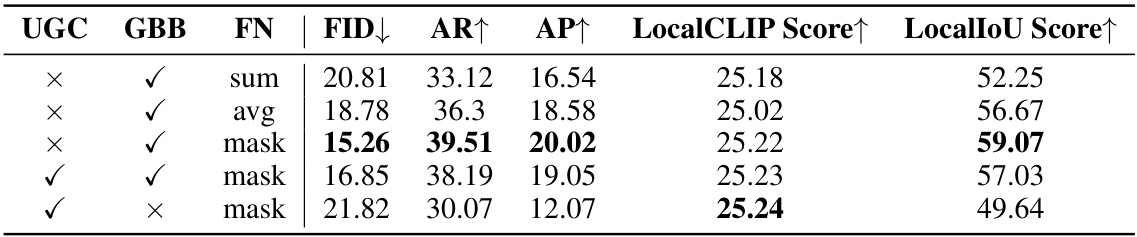
This table presents the results of ablation studies performed on the HiCo-7K dataset. The studies investigate the impact of three components: UNetGlobalCaption (UGC), GlobalBackgroundBranch (GBB), and FuseNet (FN). Different combinations of these components are tested using different fusion methods (‘sum’, ‘avg’, ‘mask’), and the results (FID, AR, AP, LocalCLIP Score, LocalIoU Score) are compared to assess their individual and combined effects on the overall performance.
Full paper#