↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Current research focuses on scaling language models by increasing the size of the training data and model parameters. However, this approach often leads to significant computational costs. This paper explores an alternative scaling strategy by focusing on the size of the datastore used during inference in retrieval-based language models. The study reveals that increasing the datastore size consistently improves performance across various tasks and that smaller models augmented with large datastores can outperform larger models trained on smaller datasets.
The researchers built MASSIVEDS, a massive 1.4 trillion-token datastore, to conduct a large-scale study of datastore scaling. They designed an efficient pipeline for managing the large datastore and systematically evaluated the effects of datastore size on various tasks. Their results show that increasing datastore size improves language modeling and downstream task performance monotonically, even surpassing the performance of larger LMs at a lower training cost. This finding highlights the importance of datastore size as an integral factor in determining LM efficiency and suggests a new direction for scaling language models by focusing on datastore augmentation.
Key Takeaways#
Why does it matter?#
This paper is crucial because it challenges the established scaling laws for language models by introducing a new dimension of scaling: the size of the datastore used at inference time. It demonstrates that increasing datastore size significantly improves performance, even for smaller models, offering a cost-effective alternative to training larger models. This opens new avenues for research in retrieval-based language models and compute-optimal scaling, offering significant implications for resource-constrained environments.
Visual Insights#
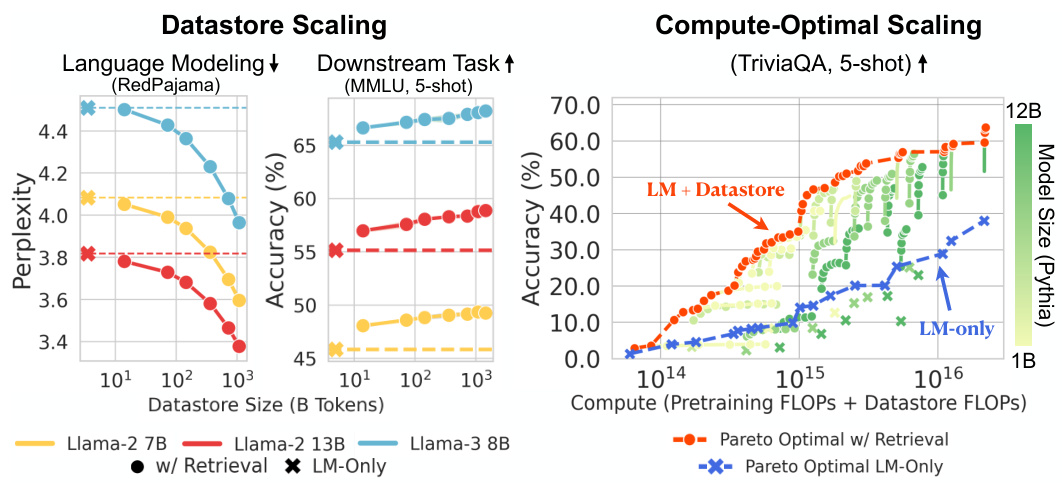
🔼 This figure shows that increasing the size of the datastore used by a retrieval-based language model (LM) improves both language modeling performance and performance on downstream tasks. The left panel demonstrates this improvement for LLAMA-2 and LLAMA-3 models on a knowledge-intensive task (MMLU). The right panel shows that a smaller model augmented with a large datastore outperforms a larger LM-only model on this same task, highlighting the compute-optimal scaling advantages of using a large datastore. The Pareto optimal curves further emphasize that retrieval-based models achieve superior performance compared to LM-only models when considering a fixed compute budget.
read the caption
Figure 1: Datastore scaling improves language modeling and downstream task performance. Left: Datastore scaling performance on language modeling and a downstream task (MMLU) with LLAMA-2 and LLAMA-3 models. Right: Compute-optimal scaling of retrieval-based language models vs. LM-only models with PYTHIA models. By considering the size of the datastore as an additional dimension of scaling, we can improve model performance at lower training cost.

🔼 This table compares MASSIVEDS with other existing retrieval-based language models’ datastores in terms of size, data sources, and whether they are open-sourced. It highlights that MASSIVEDS is the largest open-sourced datastore available, incorporating data from diverse domains, which distinguishes it from prior studies that often relied on smaller, single-domain datastores (like Wikipedia). The table also indicates whether previous studies evaluated their datastores on downstream tasks, demonstrating the comprehensive nature of the MASSIVEDS evaluation.
read the caption
Table 1: Comparison with prior work, ordered by datastore size. ‘# Tokens’ indicates the number of tokens in the datastore using the LLAMA2 tokenizer (Touvron et al., 2023). The asterisk (*) denotes that the datastore is not evaluated on downstream tasks. MASSIVEDS is the largest open-sourced datastore and covers a broad spectrum of domains.
In-depth insights#
Retrieval-LM Scaling#
Retrieval-LM scaling explores how the size of external knowledge stores impacts the performance of language models. Larger stores consistently improve performance, particularly on knowledge-intensive tasks, often surpassing the capabilities of significantly larger models trained solely on traditional data. This suggests a crucial shift in how we view LM efficiency, moving beyond parameter count to encompass the size of the external knowledge base. The research highlights that retrieval-augmented models exhibit better compute-optimal scaling, achieving higher performance at a given computational budget. However, the specific gains vary by task; knowledge-intensive tasks demonstrate greater improvement than reasoning-based tasks. Furthermore, effective data filtering and retriever improvements play important roles in maximizing retrieval benefits, underscoring the need for a holistic approach to scaling language models that considers both the model architecture and the quality and size of its external data source. The study’s open-sourcing of a massive datastore and efficient pipeline for future research is particularly valuable.
MASSIVEDS Dataset#
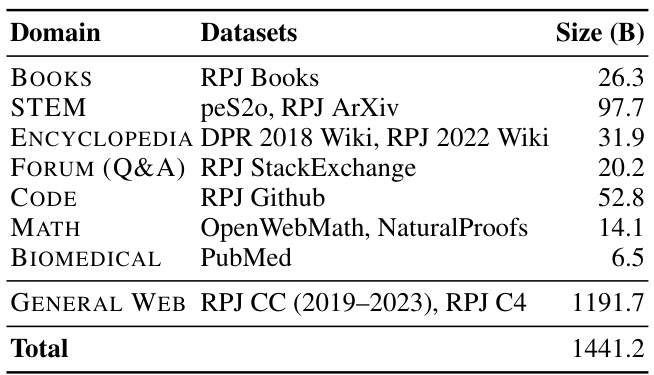
The MASSIVEDS dataset, a 1.4 trillion-token datastore, is a cornerstone of the research. Its size is significant, exceeding previous open-sourced datasets for retrieval-based language models by an order of magnitude, thus enabling a comprehensive study on the effects of datastore scaling. Diversity is another key aspect, with MASSIVEDS incorporating data from eight diverse domains, including books, scientific papers, and code. This multi-domain composition is crucial for evaluating the generalizability of retrieval-based language models and contrasts with prior work that often relied on single-domain datastores. The creation of MASSIVEDS involved a novel pipeline designed to mitigate the computational challenges of working with such a large dataset. This pipeline highlights the importance of efficient data processing techniques for making large-scale studies like this feasible. Overall, the MASSIVEDS dataset represents a significant contribution to the field, offering researchers a valuable resource for investigating the impact of datastore size and domain diversity on the performance of retrieval-based language models.
Efficient Pipeline#
An efficient pipeline for processing large datasets is crucial for research, especially in machine learning where datasets can reach terabyte or even petabyte scales. Effective pipelines optimize data ingestion, cleaning, transformation, and feature engineering. This involves careful selection of tools and techniques, often leveraging parallel processing and distributed computing frameworks like Spark or Dask to handle massive datasets efficiently. Modular design is key, allowing for independent development and testing of pipeline components. This modularity also enables easier modification and adaptation to various datasets and research needs. Minimizing redundant computations and storage is paramount. Techniques like caching, incremental processing, and efficient data structures contribute to significant performance gains. Finally, thorough monitoring and logging are essential for identifying bottlenecks and ensuring the pipeline’s reliability and reproducibility. A well-designed and implemented pipeline can drastically reduce processing time and computational costs, enabling researchers to focus on analysis and interpretation.
Compute Optimality#
Compute optimality in large language models (LLMs) is a crucial consideration, especially given their massive computational demands. The paper investigates the trade-offs between model size, training data, and datastore size for retrieval-based LLMs. Retrieval-based models demonstrate superior compute-optimal scaling, achieving higher performance with the same training FLOPs compared to traditional LM-only approaches. This is achieved by offloading some of the computational burden from model training to datastore construction and retrieval, which is cheaper. The authors suggest that datastore size is an integral parameter in the efficiency and performance trade-offs of LLMs, alongside the more commonly considered parameters such as model size and training data. This finding highlights the potential cost savings and performance gains attainable by strategically balancing compute resources between pretraining and data retrieval infrastructure for future LLM development. Further research into the design of efficient retrievers and datastores is needed to further improve the compute optimality of retrieval-based methods.
Future Directions#
The field of large language models (LLMs) is rapidly evolving, and future research directions are abundant. Improving retrieval methods is crucial; current methods, while effective, often lack the sophistication needed to efficiently handle trillion-token datastores. Exploring novel retrieval architectures and reranking strategies is key to unlocking further performance gains. Addressing the compute-inference trade-off is another vital direction, requiring research into efficient indexing and query processing techniques to reduce the computational burden at inference time. Investigating the impact of higher-quality data within the datastore is essential. While MASSIVEDS is extensive, refining data filtering techniques and potentially incorporating additional curated domain-specific data could yield notable performance improvements. Furthermore, a focus on evaluating diverse downstream tasks, especially those requiring complex reasoning, is important to fully understand the capabilities and limitations of retrieval-augmented LLMs. Finally, open-sourcing more datastores of comparable size and diversity will accelerate research and ensure wider adoption of these techniques.
More visual insights#
More on figures
🔼 This figure shows two plots demonstrating the effect of datastore size on language model performance. The left plot shows that increasing the size of the datastore monotonically improves both language modeling performance and downstream task performance (measured by accuracy on the MMLU benchmark). The right plot demonstrates compute-optimal scaling, showing that retrieval-based models augmented with large datastores achieve better performance at lower computational cost compared to LM-only models.
read the caption
Figure 1: Datastore scaling improves language modeling and downstream task performance. Left: Datastore scaling performance on language modeling and a downstream task (MMLU) with LLAMA-2 and LLAMA-3 models. Right: Compute-optimal scaling of retrieval-based language models vs. LM-only models with PYTHIA models. By considering the size of the datastore as an additional dimension of scaling, we can improve model performance at lower training cost.

🔼 This figure demonstrates the impact of datastore size on both language modeling performance and downstream task performance. The left panel shows how increasing datastore size monotonically improves perplexity (a measure of language model quality) and accuracy on a downstream task (MMLU). The right panel illustrates compute-optimal scaling, showing that retrieval-based language models augmented with large datastores achieve better performance compared to larger language models trained without retrieval, given the same computational budget. In essence, it highlights the effectiveness and efficiency of using large datastores to enhance language model capabilities.
read the caption
Figure 1: Datastore scaling improves language modeling and downstream task performance. Left: Datastore scaling performance on language modeling and a downstream task (MMLU) with LLAMA-2 and LLAMA-3 models. Right: Compute-optimal scaling of retrieval-based language models vs. LM-only models with PYTHIA models. By considering the size of the datastore as an additional dimension of scaling, we can improve model performance at lower training cost.

🔼 This figure demonstrates the compute-optimal scaling trends for both retrieval-based and LM-only language models. Different model sizes are used with varying datastore sizes and amounts of pretraining data. The Pareto-optimal points highlight the best performance achieved for a given compute budget. The results show that retrieval-based models consistently outperform LM-only models, especially on knowledge-intensive tasks, and that increasing datastore size continues to yield performance improvements without saturation.
read the caption
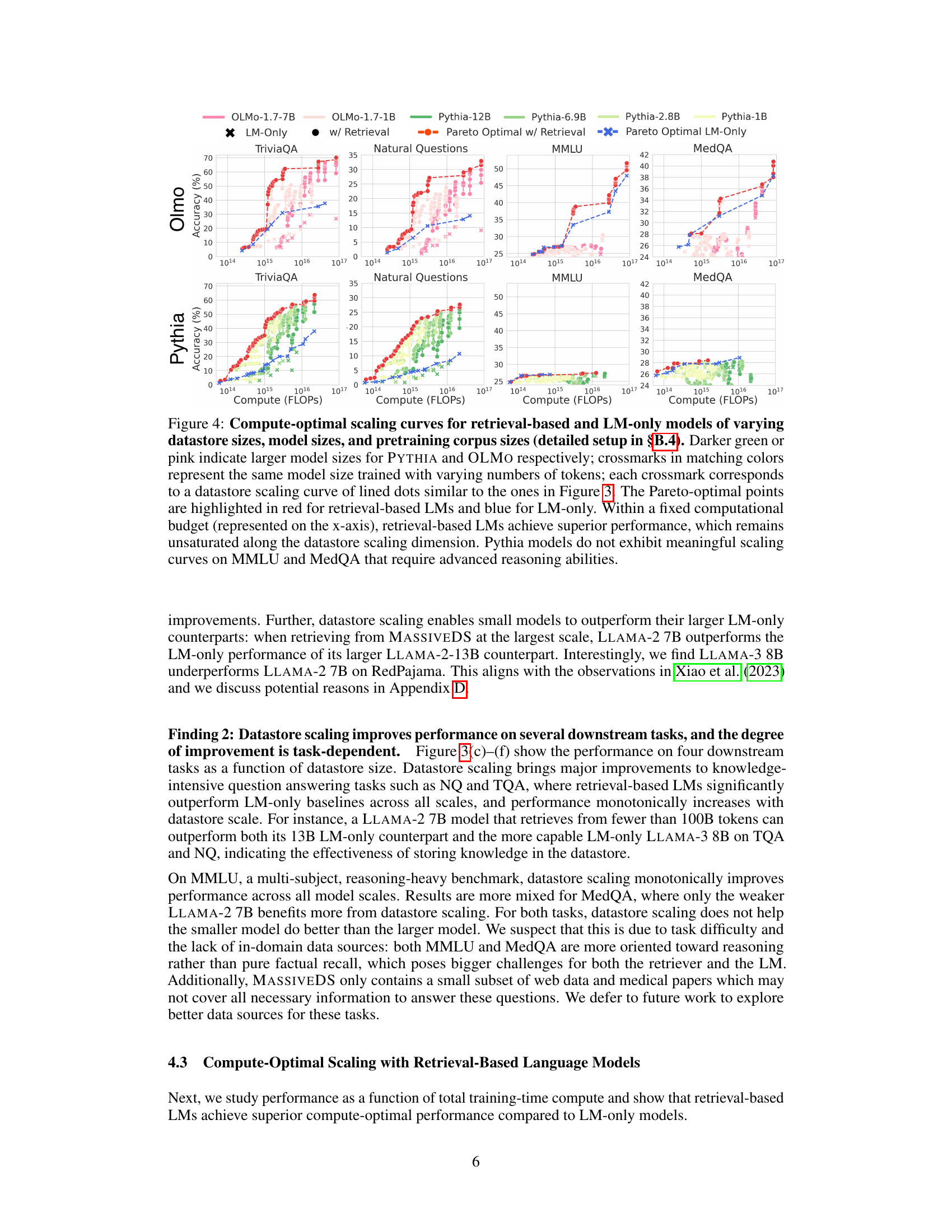
Figure 4: Compute-optimal scaling curves for retrieval-based and LM-only models of varying datastore sizes, model sizes, and pretraining corpus sizes (detailed setup in §B.4). Darker green or pink indicate larger model sizes for PYTHIA and OLMO respectively; crossmarks in matching colors represent the same model size trained with varying numbers of tokens; each crossmark corresponds to a datastore scaling curve of lined dots similar to the ones in Figure 3. The Pareto-optimal points are highlighted in red for retrieval-based LMs and blue for LM-only. Within a fixed computational budget (represented on the x-axis), retrieval-based LMs achieve superior performance, which remains unsaturated along the datastore scaling dimension. Pythia models do not exhibit meaningful scaling curves on MMLU and MedQA that require advanced reasoning abilities.

🔼 This figure demonstrates the impact of datastore size on both language modeling performance and downstream task performance using different language models. The left panel shows how increasing datastore size improves performance on language modeling and a downstream task (MMLU) for Llama-2 and Llama-3 models. The right panel illustrates compute-optimal scaling curves, showing that retrieval-based models augmented with larger datastores achieve better performance with the same training compute budget compared to LM-only models.
read the caption
Figure 1: Datastore scaling improves language modeling and downstream task performance. Left: Datastore scaling performance on language modeling and a downstream task (MMLU) with LLAMA-2 and LLAMA-3 models. Right: Compute-optimal scaling of retrieval-based language models vs. LM-only models with PYTHIA models. By considering the size of the datastore as an additional dimension of scaling, we can improve model performance at lower training cost.
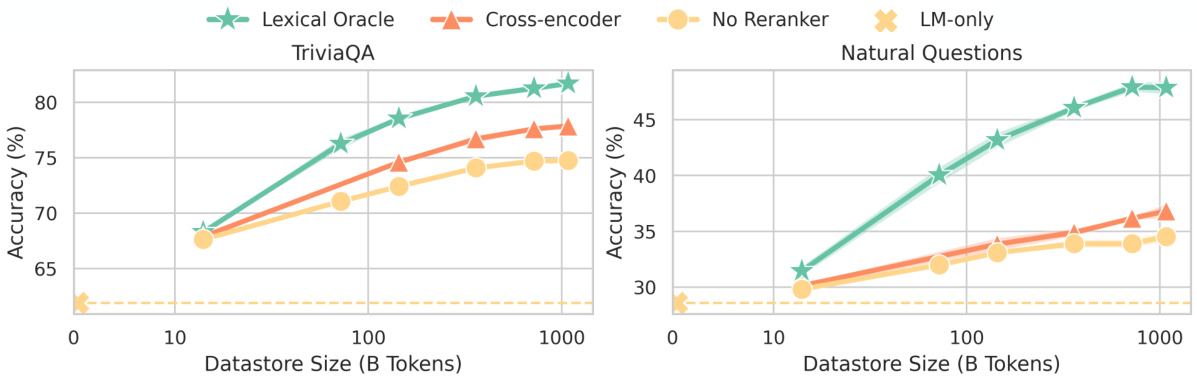
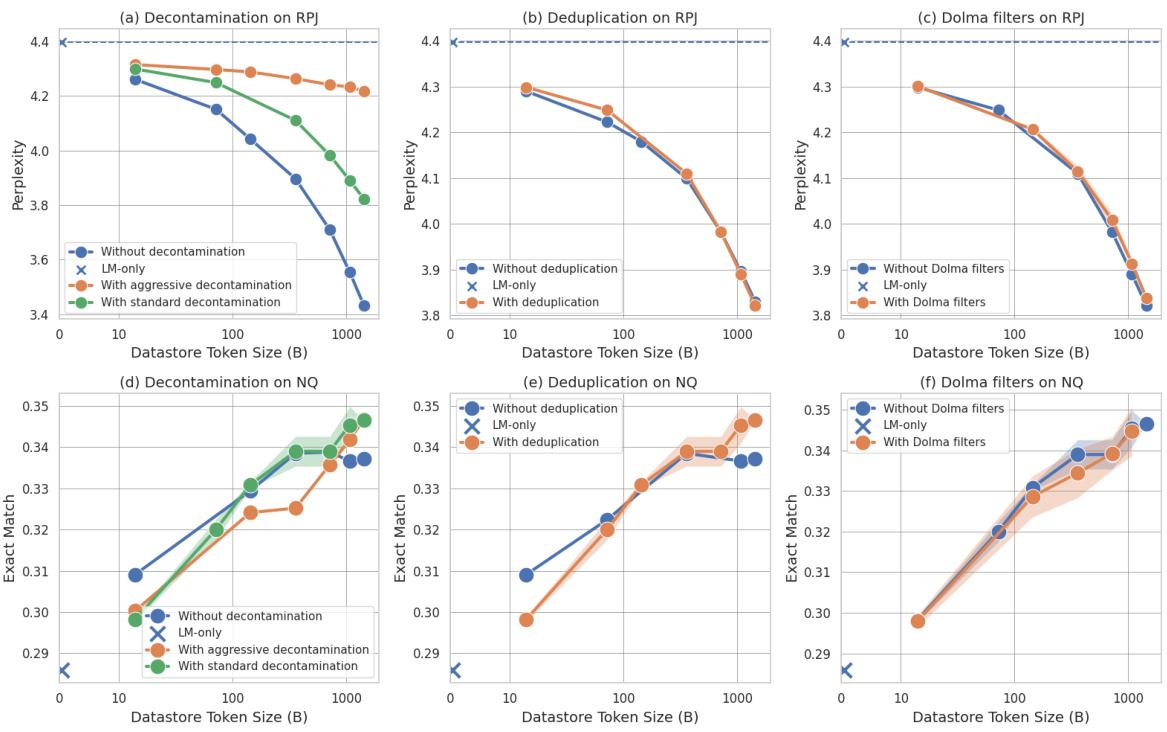
🔼 This figure shows the impact of different reranking methods on the performance of retrieval-based language models. The x-axis represents the size of the datastore, and the y-axis represents the accuracy on two downstream tasks (TriviaQA and Natural Questions). Three reranking methods are compared: a lexical oracle (which uses perfect knowledge of the correct answer to reorder documents), a cross-encoder model (which learns to reorder documents based on their relevance to the query), and no reranker (which uses the retriever’s initial ranking). The results show that both the lexical oracle and cross-encoder methods significantly improve performance, demonstrating the importance of reranking in enhancing the scaling trends of retrieval-based LMs. The LM-only results are also displayed as a baseline.
read the caption
Figure 6: Scaling trends on TriviaQA and NaturalQuestions using different rerankers (Section 5.2). '''Lexical Oracle''' represents the oracle reranker that reorders documents based on lexical overlap with the ground-truth answer. ''Cross-encoder''' represents a neural reranker which uses a cross-encoder model. Both the oracle lexical reranker and the neural reranker boost scaling trends, indicating the potential improvement space by enhancing the retrieval quality.

🔼 This figure shows two plots demonstrating the effects of datastore scaling on language model performance. The left plot shows how increasing datastore size improves both language modeling perplexity and performance on a downstream task (MMLU) using Llama-2 and Llama-3 models. The right plot illustrates compute-optimal scaling, comparing retrieval-based LMs with LM-only models (using Pythia models). It highlights that incorporating datastore size as a scaling factor allows for improved performance at a lower training cost.
read the caption
Figure 1: Datastore scaling improves language modeling and downstream task performance. Left: Datastore scaling performance on language modeling and a downstream task (MMLU) with LLAMA-2 and LLAMA-3 models. Right: Compute-optimal scaling of retrieval-based language models vs. LM-only models with PYTHIA models. By considering the size of the datastore as an additional dimension of scaling, we can improve model performance at lower training cost.

🔼 This figure shows the impact of datastore size on the performance of retrieval-based language models. The left panel shows that increasing datastore size monotonically improves language modeling and downstream task performance, even for smaller models. The right panel demonstrates that retrieval-based models achieve superior compute-optimal scaling compared to LM-only models, meaning they achieve better performance for the same training cost by leveraging a larger datastore.
read the caption
Figure 1: Datastore scaling improves language modeling and downstream task performance. Left: Datastore scaling performance on language modeling and a downstream task (MMLU) with LLAMA-2 and LLAMA-3 models. Right: Compute-optimal scaling of retrieval-based language models vs. LM-only models with PYTHIA models. By considering the size of the datastore as an additional dimension of scaling, we can improve model performance at lower training cost.

🔼 This figure demonstrates the impact of datastore size on both language modeling and downstream task performance. The left panel shows that increasing datastore size monotonically improves performance on language modeling and the MMLU benchmark for Llama-2 and Llama-3 models. The right panel illustrates compute-optimal scaling curves, comparing retrieval-based LMs (using a datastore) against LM-only models. It highlights that incorporating datastore size as a scaling factor allows for improved model performance at a lower training cost.
read the caption
Figure 1: Datastore scaling improves language modeling and downstream task performance. Left: Datastore scaling performance on language modeling and a downstream task (MMLU) with LLAMA-2 and LLAMA-3 models. Right: Compute-optimal scaling of retrieval-based language models vs. LM-only models with PYTHIA models. By considering the size of the datastore as an additional dimension of scaling, we can improve model performance at lower training cost.

🔼 This figure shows the results of experiments on datastore scaling. The left panel shows that increasing datastore size improves both language modeling performance and performance on a downstream task (MMLU), using Llama-2 and Llama-3 models. The right panel shows a compute-optimal scaling curve, demonstrating that retrieval-based language models augmented with larger datastores achieve better performance at lower training costs compared to larger LM-only models.
read the caption
Figure 1: Datastore scaling improves language modeling and downstream task performance. Left: Datastore scaling performance on language modeling and a downstream task (MMLU) with LLAMA-2 and LLAMA-3 models. Right: Compute-optimal scaling of retrieval-based language models vs. LM-only models with PYTHIA models. By considering the size of the datastore as an additional dimension of scaling, we can improve model performance at lower training cost.

🔼 This figure shows the impact of datastore size on the performance of retrieval-based language models. The left panel demonstrates that increasing the datastore size monotonically improves both language modeling performance and downstream task performance (measured by accuracy on the MMLU benchmark). The right panel shows a compute-optimal scaling curve, comparing retrieval-based models against traditional language models. It highlights that retrieval-augmented models, which leverage a large datastore at inference time, achieve better performance for a given compute budget than models trained only on larger datasets.
read the caption
Figure 1: Datastore scaling improves language modeling and downstream task performance. Left: Datastore scaling performance on language modeling and a downstream task (MMLU) with LLAMA-2 and LLAMA-3 models. Right: Compute-optimal scaling of retrieval-based language models vs. LM-only models with PYTHIA models. By considering the size of the datastore as an additional dimension of scaling, we can improve model performance at lower training cost.

🔼 This figure shows the compute-optimal scaling curves for both retrieval-based and LM-only language models. It demonstrates that retrieval-based models achieve superior performance within a fixed computational budget compared to LM-only models, particularly as datastore size increases. The figure highlights the Pareto-optimal points for both model types and shows that the retrieval-based models’ performance continues to improve as datastore size increases, while LM-only models show saturation.
read the caption
Figure 4: Compute-optimal scaling curves for retrieval-based and LM-only models of varying datastore sizes, model sizes, and pretraining corpus sizes (detailed setup in §B.4). Darker green or pink indicate larger model sizes for PYTHIA and OLMO respectively; crossmarks in matching colors represent the same model size trained with varying numbers of tokens; each crossmark corresponds to a datastore scaling curve of lined dots similar to the ones in Figure 3. The Pareto-optimal points are highlighted in red for retrieval-based LMs and blue for LM-only. Within a fixed computational budget (represented on the x-axis), retrieval-based LMs achieve superior performance, which remains unsaturated along the datastore scaling dimension. Pythia models do not exhibit meaningful scaling curves on MMLU and MedQA that require advanced reasoning abilities.
🔼 This figure shows the impact of datastore size on the performance of retrieval-based language models. The left panel demonstrates that increasing the datastore size monotonically improves both language modeling and downstream task performance (MMLU). The right panel compares compute-optimal scaling curves for retrieval-based LMs versus LM-only models, highlighting that retrieval-based models achieve superior performance at a lower training cost by leveraging larger datastores during inference.
read the caption
Figure 1: Datastore scaling improves language modeling and downstream task performance. Left: Datastore scaling performance on language modeling and a downstream task (MMLU) with LLAMA-2 and LLAMA-3 models. Right: Compute-optimal scaling of retrieval-based language models vs. LM-only models with PYTHIA models. By considering the size of the datastore as an additional dimension of scaling, we can improve model performance at lower training cost.

🔼 This figure shows two plots demonstrating the impact of datastore size on language model performance. The left plot shows how increasing datastore size improves both language modeling perplexity and performance on a downstream task (MMLU) using Llama-2 and Llama-3 models. The right plot illustrates compute-optimal scaling curves, comparing retrieval-based models (augmented with a datastore) against LM-only models. It highlights that retrieval-based models achieve superior performance with the same training budget by leveraging larger datastores.
read the caption
Figure 1: Datastore scaling improves language modeling and downstream task performance. Left: Datastore scaling performance on language modeling and a downstream task (MMLU) with LLAMA-2 and LLAMA-3 models. Right: Compute-optimal scaling of retrieval-based language models vs. LM-only models with PYTHIA models. By considering the size of the datastore as an additional dimension of scaling, we can improve model performance at lower training cost.
More on tables
🔼 This table compares MASSIVEDS with other existing retrieval-based language models’ datastores in terms of size and data sources. It highlights that MASSIVEDS is the largest open-source datastore and is unique in its coverage of a broad range of domains, not just Wikipedia. The table also indicates which datastores were evaluated on downstream tasks.
read the caption
Table 1: Comparison with prior work, ordered by datastore size. ‘# Tokens' indicates the number of tokens in the datastore using the LLAMA2 tokenizer (Touvron et al., 2023). The asterisk (*) denotes that the datastore is not evaluated on downstream tasks. MASSIVEDS is the largest open-sourced datastore and covers a broad spectrum of domains.
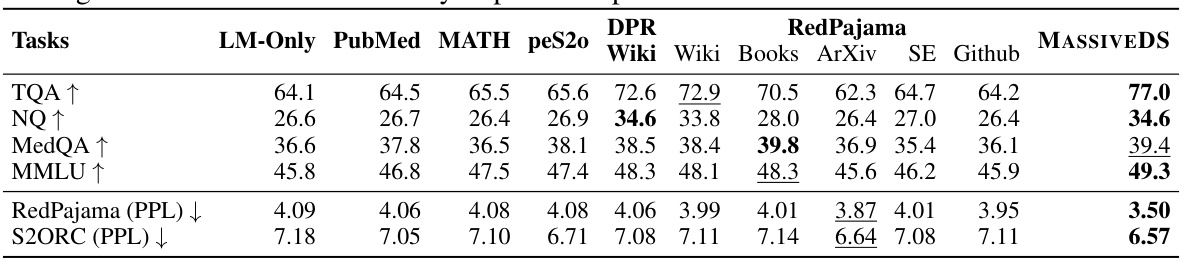
🔼 This table compares the performance of a retrieval-based language model using the MASSIVEDS datastore against models using single-domain datastores across several downstream and upstream tasks. The results highlight the improved performance achieved by using the diverse, multi-domain MASSIVEDS datastore compared to single-domain options like Wikipedia or PubMed.
read the caption
Table 3: Downstream and upstream performance comparison between MASSIVEDS for retrieval versus single-domain datastores with LLAMA-2 7B. “SE” is short for StackExchange. The best performance is highlighted in bold and the second best is underlined. We show the diverse domain coverage in MASSIVEDS consistently improve the performance across tasks.

🔼 This table compares MASSIVEDS to previous research on retrieval-based language models, ordered by the size of their datastores. It shows the number of tokens in each datastore, the sources of the data used, whether the datastore is open-sourced, and whether it was evaluated on downstream tasks. The table highlights that MASSIVEDS is the largest open-source datastore and covers a wide variety of domains.
read the caption
Table 1: Comparison with prior work, ordered by datastore size. ‘# Tokens’ indicates the number of tokens in the datastore using the LLAMA2 tokenizer (Touvron et al., 2023). The asterisk (*) denotes that the datastore is not evaluated on downstream tasks. MASSIVEDS is the largest open-sourced datastore and covers a broad spectrum of domains.
🔼 This table compares MASSIVEDS to other existing retrieval-based language model datastores in terms of size (# Tokens), data sources used, and whether they were open-sourced and evaluated on downstream tasks. It highlights that MASSIVEDS is the largest publicly available datastore, encompassing diverse data sources, and is fully open-sourced, unlike some others which use proprietary datasets.
read the caption
Table 1: Comparison with prior work, ordered by datastore size. ‘# Tokens’ indicates the number of tokens in the datastore using the LLAMA2 tokenizer (Touvron et al., 2023). The asterisk (*) denotes that the datastore is not evaluated on downstream tasks. MASSIVEDS is the largest open-sourced datastore and covers a broad spectrum of domains.

🔼 This table compares MASSIVEDS with other related works on retrieval-based Language Models. It shows the size of the datastore (# Tokens) used in each work, the data sources used to create the datastore, and whether or not the datastore was open-sourced and evaluated on downstream tasks. MASSIVEDS stands out as the largest open-sourced datastore with a diverse set of domains.
read the caption
Table 1: Comparison with prior work, ordered by datastore size. ‘# Tokens’ indicates the number of tokens in the datastore using the LLAMA2 tokenizer (Touvron et al., 2023). The asterisk (*) denotes that the datastore is not evaluated on downstream tasks. MASSIVEDS is the largest open-sourced datastore and covers a broad spectrum of domains.

🔼 This table compares MASSIVEDS to other existing retrieval-based language model datastores. It’s organized by the number of tokens in each datastore, showing the data sources used to build each datastore and whether or not the datastore was evaluated on downstream tasks. The table highlights that MASSIVEDS is the largest open-source datastore and its diversity across domains.
read the caption
Table 1: Comparison with prior work, ordered by datastore size. ‘# Tokens’ indicates the number of tokens in the datastore using the LLAMA2 tokenizer (Touvron et al., 2023). The asterisk (*) denotes that the datastore is not evaluated on downstream tasks. MASSIVEDS is the largest open-sourced datastore and covers a broad spectrum of domains.
Full paper#