↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Multi-modal entity alignment (MMEA) is crucial for integrating knowledge graphs from various sources. However, current methods struggle with uncertain correspondences: weak inter-modal links, inconsistent entity descriptions, and missing data. These issues hinder the effective use of aligned entity similarities.
To address this, the researchers introduce TMEA, a novel method that incorporates an alignment-augmented abstract representation to handle diverse attribute descriptions and a missing modality imputation module to deal with incomplete data. They also implement a multi-modal commonality enhancement mechanism. Experiments demonstrate that TMEA significantly outperforms existing methods on real-world datasets, achieving a clear improvement in alignment accuracy. This work significantly advances the state-of-the-art in MMEA by directly addressing the problem of uncertain correspondences.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles a critical challenge in multi-modal entity alignment, namely uncertain correspondences. It provides a novel method (TMEA) that significantly improves alignment accuracy, addressing issues like weak associations between modalities, varied descriptions of the same entity, and missing data. This advances the integration of multi-modal knowledge graphs and opens new avenues for research in multimodal machine learning.
Visual Insights#

This figure shows a simplified example of multi-modal entity alignment, highlighting the challenges posed by uncertain correspondences between entities across different knowledge graphs. It demonstrates how entities with weak semantic associations across modalities, inconsistent descriptions of the same attribute, and missing modality information can make accurate alignment difficult. The example features two knowledge graphs (MMKG1 and MMKG2) which contain relational, attribute, and visual information about the movie ‘Twilight’ and its actors.

This table presents the performance comparison of different multi-modal entity alignment methods on two benchmark datasets: FB15K-DB15K and FB15K-YG15K. The results are evaluated using several metrics including Hits@1, Hits@5, Hits@10, Mean Rank (MR), and Mean Reciprocal Rank (MRR). The best and second-best results for each metric on each dataset are highlighted to show the relative performance of the methods. The table provides a quantitative assessment of the effectiveness of various approaches in aligning entities across different multimodal knowledge graphs.
In-depth insights#
Uncertain Alignment#
Uncertain alignment in multi-modal data poses a significant challenge due to the inherent complexities of diverse data types and potential inconsistencies between modalities. Successfully integrating information from various sources (text, images, sensor data, etc.) requires robust techniques to handle ambiguities and inconsistencies in data representation and relationships. This uncertainty manifests as weak inter-modal associations, inconsistent feature representations across different modalities, and the presence of missing data or modalities. Addressing these issues demands innovative approaches that can learn effective data representations, model uncertainty explicitly, and potentially incorporate external knowledge or context to resolve ambiguities and improve alignment accuracy. The goal is to develop more robust methods which can better capture and handle data variability and uncertainties, leading to more accurate and reliable multi-modal data integration and downstream applications.
Multimodal Encoding#
Multimodal encoding is a crucial process in any system aiming to integrate and interpret information from multiple modalities (e.g., text, images, audio). Effective multimodal encoding is critical because it lays the foundation for subsequent tasks like fusion, alignment, or downstream prediction. Different approaches exist, varying in complexity and effectiveness. Early methods often rely on concatenating individual modality representations, which may not capture the interplay between modalities effectively. More sophisticated methods leverage techniques like attention mechanisms to learn modality-specific weights and relationships, improving the representation’s richness. Deep learning architectures, particularly transformers, have significantly advanced multimodal encoding, allowing for more complex relationships and interactions. However, choosing the optimal encoding strategy depends heavily on the specific task and data characteristics. Factors like the type of modalities, their relative importance, and the presence of noise or missing data should inform encoding choices. The goal is not simply to create a unified representation but to encode the information in a manner that facilitates efficient and meaningful processing for the task at hand. Further research focuses on improving robustness, scalability, and interpretability of multimodal encoding techniques.
MMKG Integration#
Multi-Modal Knowledge Graph (MMKG) integration presents a significant challenge and opportunity in knowledge representation. Effectively integrating MMKGs requires overcoming the hurdle of uncertain correspondences between different modalities, such as text, images, and relational data. This necessitates robust techniques for aligning entities across graphs that may employ diverse and potentially incomplete descriptions of the same real-world entity. Successful MMKG integration hinges on developing sophisticated alignment methods that can handle missing data, diverse representations, and weak semantic associations between modalities. These methods might incorporate techniques like variational autoencoders for data imputation, large language models for semantic understanding of textual descriptions, and advanced attention mechanisms for cross-modal feature fusion. The ultimate goal is to build a unified, comprehensive knowledge base that leverages the strengths of each modality to provide a richer and more complete understanding of entities and relationships. The effectiveness of such integration will be determined by the accuracy of entity alignment, the ability to infer meaningful relationships between entities across modalities, and the overall scalability and robustness of the resulting integrated knowledge graph.
TMEA Framework#
The TMEA framework, designed for multi-modal entity alignment, tackles the challenge of uncertain correspondences in data. Its core innovation lies in addressing three key issues: weak inter-modal associations, diverse attribute descriptions, and missing modalities. To handle diverse attributes, TMEA utilizes an alignment-augmented abstract representation, integrating large language models and in-context learning for enhanced semantic understanding. Missing modalities are addressed via a missing modality imputation module, leveraging variational autoencoders to generate pseudo-features. Finally, weak associations are mitigated through a multi-modal commonality enhancement mechanism utilizing cross-attention with orthogonal constraints, promoting effective inter-modal feature fusion. This holistic approach, validated through experiments, significantly improves upon existing methods by explicitly modeling uncertainty and leveraging advanced techniques for more robust and accurate alignment.
Future Directions#
Future research could explore several promising avenues. Improving the robustness of TMEA against noisy or incomplete data is crucial. This may involve developing more sophisticated data cleaning and imputation techniques or leveraging advanced machine learning methods such as robust optimization. Another key area is exploring alternative modality encodings. Beyond the current relational, attribute, and visual modalities, incorporating other rich modalities (e.g., textual descriptions from different sources, audio, video) could significantly enhance the model’s capabilities. The development of more effective inter-modal interaction mechanisms is also essential to fully harness the power of these diverse data sources. This might involve investigating attention mechanisms beyond simple cross-attention or employing advanced graph neural networks designed to capture complex relationships between modalities. Finally, extending the methodology to larger-scale datasets and diverse KG structures would be a significant step. This would necessitate addressing scalability and efficiency challenges and potentially incorporating techniques from distributed computing.
More visual insights#
More on figures
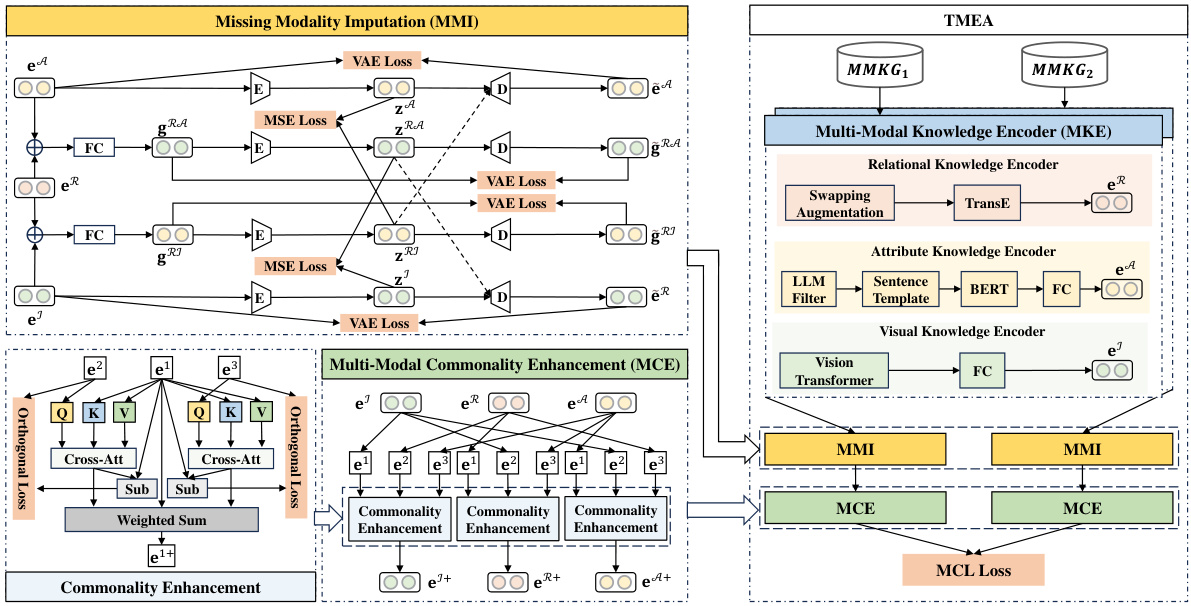
This figure presents a detailed overview of the TMEA framework, which is a method for Multi-modal Entity Alignment. It shows three main modules: Multi-modal Knowledge Encoder (MKE), Missing Modality Imputation (MMI), and Multi-modal Commonality Enhancement (MCE). The MKE module encodes relational, attribute, and visual knowledge into their preliminary feature representations. The MMI module addresses missing modality by unifying features into a shared latent subspace and generating pseudo features. The MCE module enhances semantic associations between modalities using cross-attention with orthogonal constraints. The figure also illustrates the overall model optimization strategy, integrating multi-modal contrastive learning and bi-directional iteration.

This figure displays the performance of TMEA and MSNEA (the strongest baseline) under different ratios of entities with visual and attribute modalities on the FB15K-DB15K dataset. It illustrates how the models’ performance changes (measured by MRR and Hits@1) when the amount of visual and attribute information is varied. The purpose is to demonstrate the robustness of TMEA in scenarios with missing or incomplete modalities.
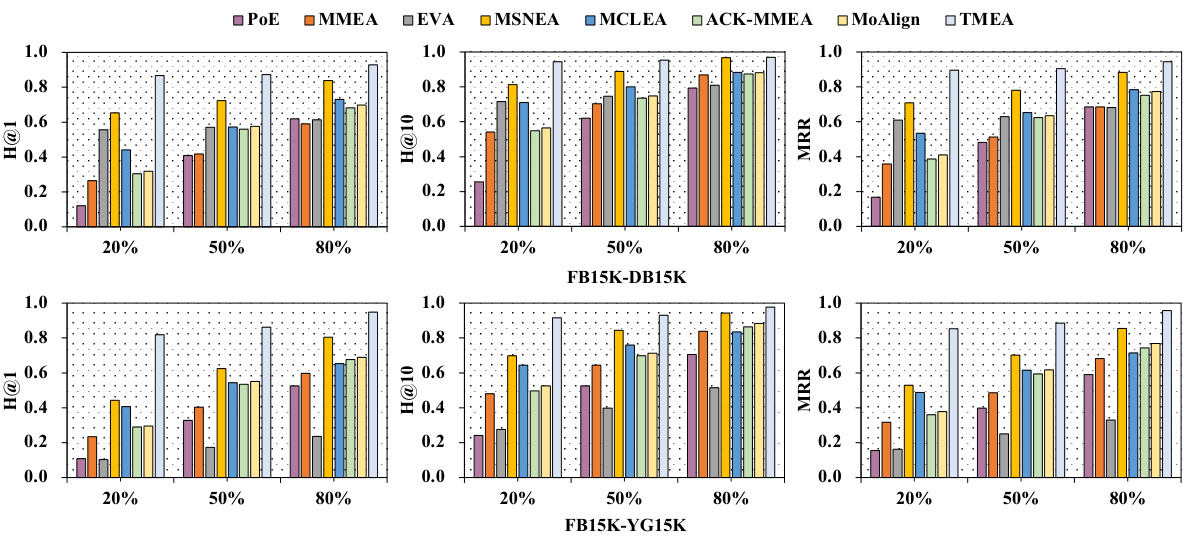
This figure compares the performance of various multi-modal entity alignment methods using different percentages of aligned entity pairs for training (20%, 50%, and 80%). It demonstrates that TMEA consistently outperforms other methods across all evaluation metrics (H@1, H@10, MRR) and shows robustness to reductions in training data. Other methods show a more significant decline in performance as training data decreases.
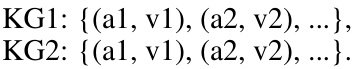
This figure presents a detailed architecture of the TMEA model, illustrating its three core modules: Multi-modal Knowledge Encoder (MKE), Missing Modality Imputation (MMI), and Multi-modal Commonality Enhancement (MCE). The MKE module encodes relational, attribute, and visual knowledge. The MMI module addresses modality absence by unifying features into a shared latent subspace and generating pseudo features. The MCE module enhances semantic associations using cross-attention with orthogonal constraints. The figure also shows the data flow and connections between these modules, including the use of various techniques like TransE, BERT, Vision Transformer, and VAEs. The overall objective function is shown at the bottom, incorporating losses for different components.

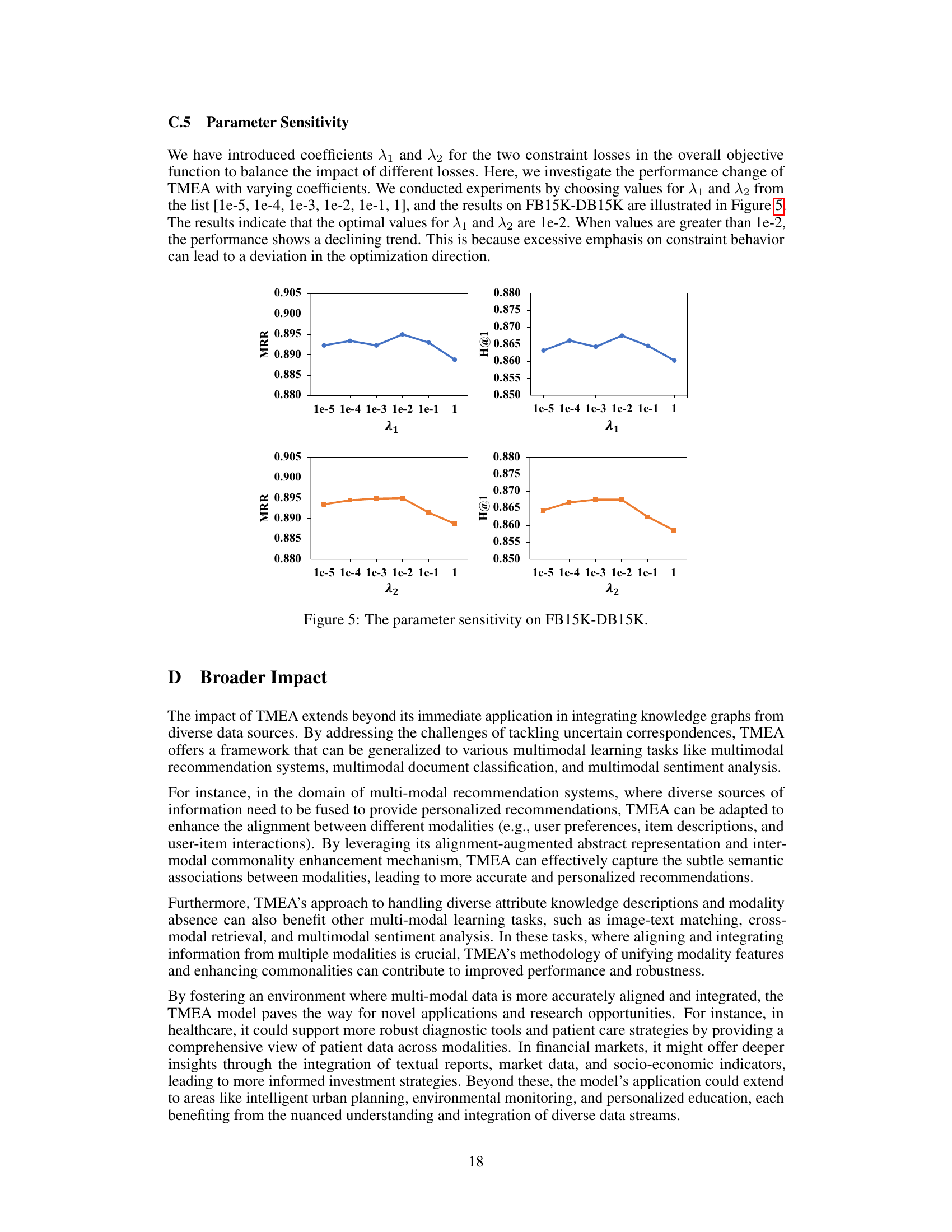
This figure shows the performance change of TMEA with varying coefficients (λ1 and λ2) for the two constraint losses in the overall objective function. The x-axis represents the values of λ1 and λ2, while the y-axis represents the MRR and H@1 scores. The optimal values for λ1 and λ2 are 1e-2. When the values are greater than 1e-2, the performance declines. This is because excessive emphasis on constraint behavior can lead to a deviation in the optimization direction.
More on tables
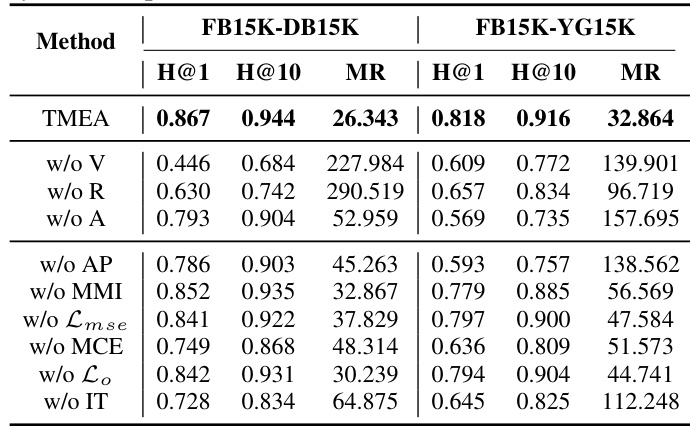
This table presents the results of multi-modal entity alignment experiments on two datasets: FB15K-DB15K and FB15K-YG15K. It compares various methods, showing their performance using Hits@1, Hits@5, Hits@10, Mean Reciprocal Rank (MRR), and Mean Rank (MR) metrics. Higher values for Hits@N and MRR are better, while a lower value for MR is better. The table highlights the superior performance of the proposed TMEA method compared to existing state-of-the-art and baseline approaches.
This table presents the performance comparison of various multi-modal entity alignment methods on two benchmark datasets, FB15K-DB15K and FB15K-YG15K. The results are evaluated using four metrics: Hits@1, Hits@5, Hits@10, and Mean Reciprocal Rank (MRR). The table highlights the superior performance of the proposed TMEA method over existing state-of-the-art approaches.
Full paper#