↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
AI systems are vulnerable to adversarial attacks and can produce harmful outputs. Existing mitigation techniques often fail to generalize to unseen attacks or significantly compromise model utility. The inherent trade-off between adversarial robustness and utility remains a major challenge.
This paper introduces a novel approach called “circuit breaking”, which directly controls internal model representations responsible for harmful outputs. Instead of trying to patch specific vulnerabilities, this method prevents the generation of harmful outputs by interrupting the process. The approach, based on representation engineering, is highly effective and generalizes well across various attacks and models. It demonstrates considerable improvements in alignment and robustness, significantly outperforming traditional methods such as refusal training and adversarial training, all while preserving model utility.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on AI safety and robustness. It introduces a novel approach that fundamentally shifts the paradigm of AI defense, moving beyond reactive patching of vulnerabilities to proactive prevention of harmful behavior. This offers a more generalized and computationally efficient solution to adversarial attacks and misalignment, opening new research directions in representation engineering and model control.
Visual Insights#
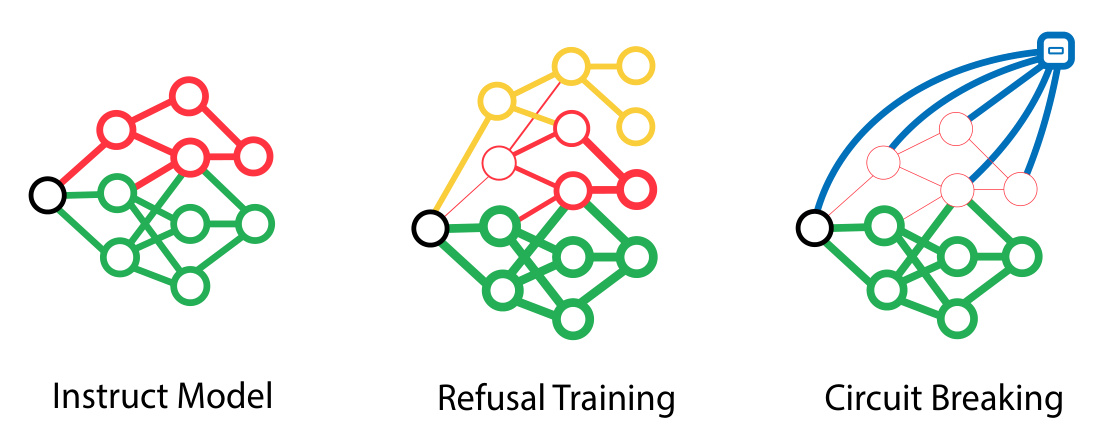
This figure illustrates three different approaches to mitigating harmful AI outputs: Instruct Model, Refusal Training, and Circuit Breaking. The Instruct Model shows a simple network where some nodes lead to harmless outputs (green) and others to harmful ones (red). Refusal Training adds a layer of refusal states (yellow) that ideally prevent the model from reaching the harmful states, but these can be bypassed. Circuit Breaking directly intercepts the harmful states, preventing the model from generating harmful outputs regardless of the path taken. This is achieved by linking harmful representations to ‘circuit breakers’, effectively short-circuiting those pathways.

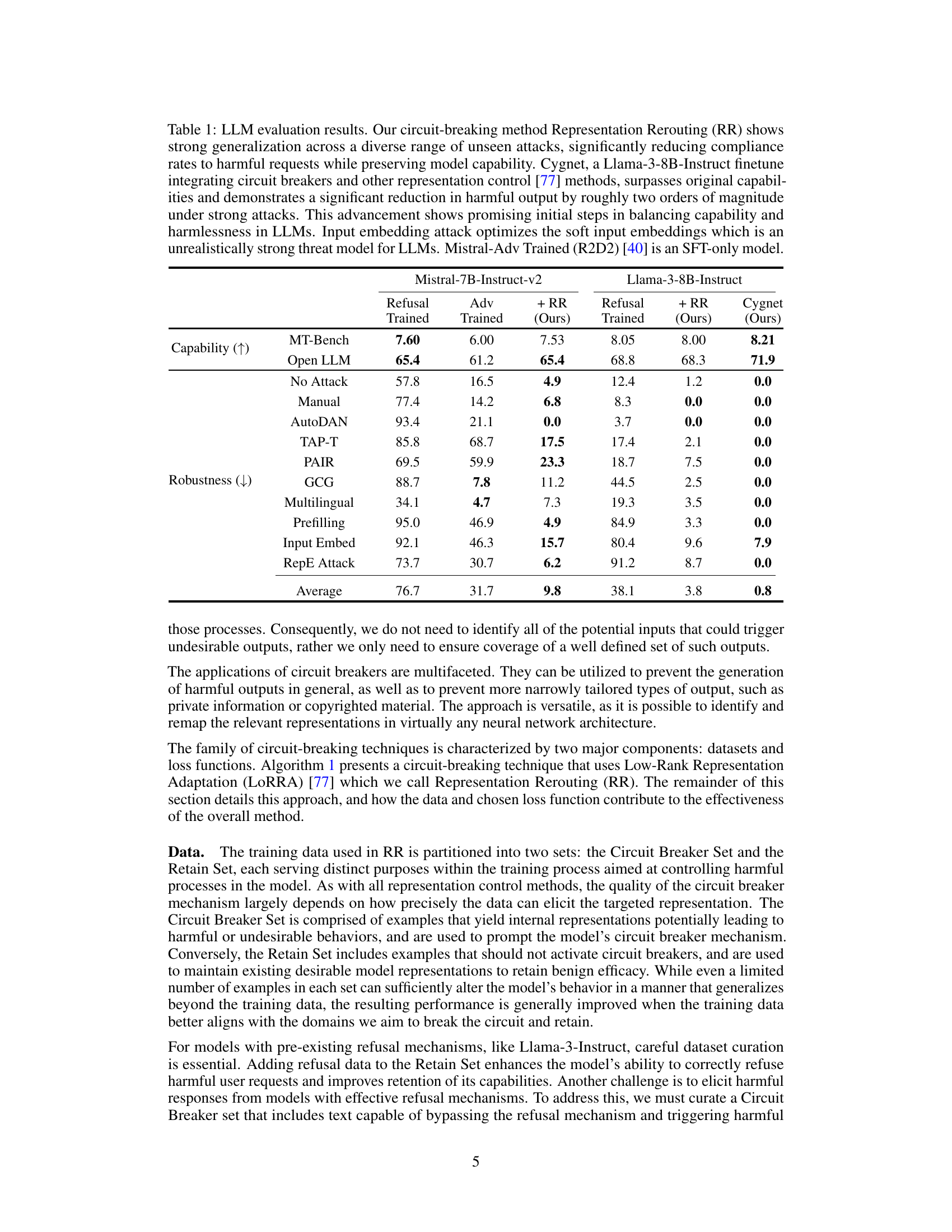
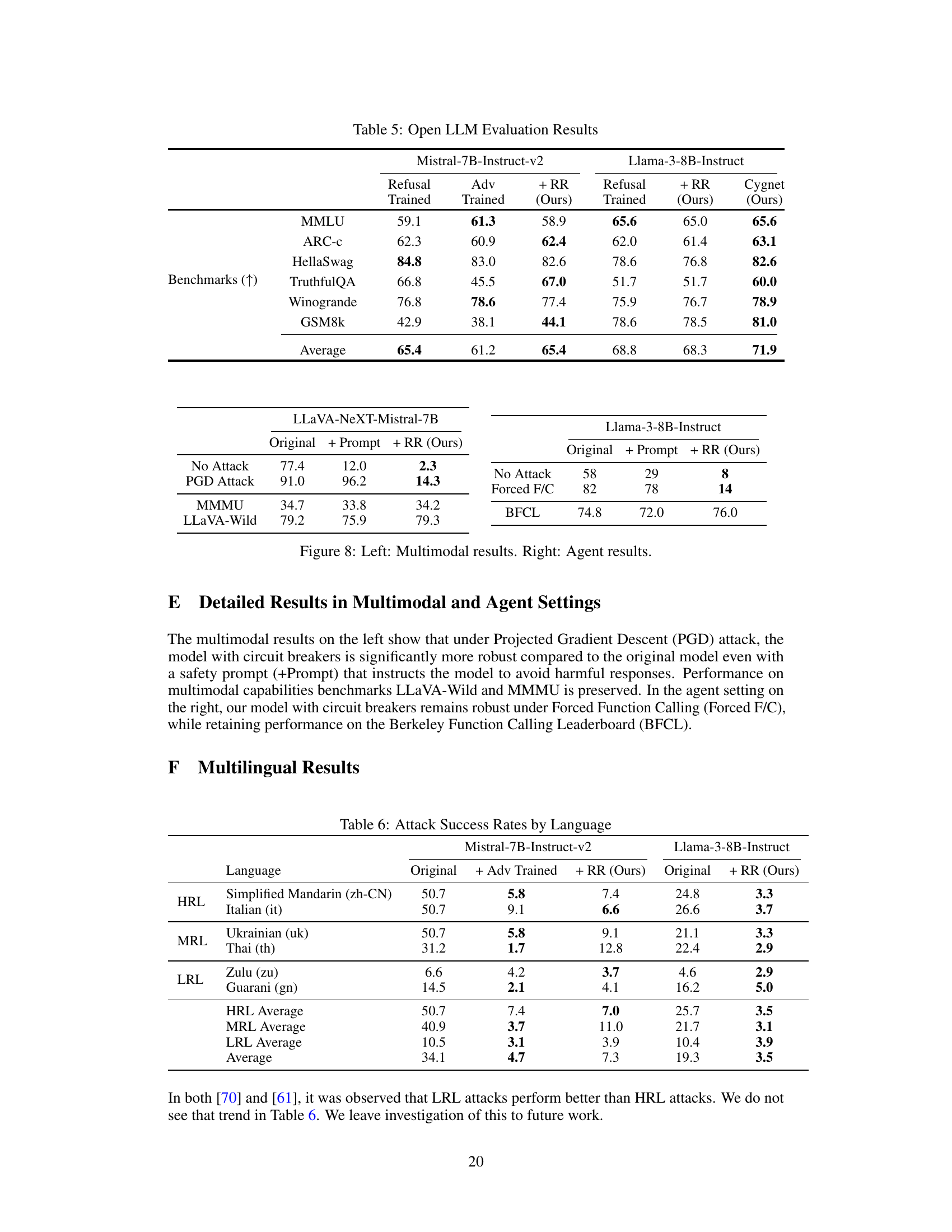
This table presents the results of evaluating several LLMs’ performance on various benchmarks before and after applying the Representation Rerouting (RR) method. It compares the original models, refusal-trained models, adversarially trained models, and models enhanced with RR. The metrics assessed include capability (measured using standard LLM benchmarks) and robustness (measured using a range of unseen adversarial attacks). The table highlights the significant improvements in robustness achieved by RR with minimal impact on the models’ capabilities. It also demonstrates the superior performance of the Cygnet model, which integrates circuit breakers and other representation control techniques.
In-depth insights#
Circuit Breaker Design#
The concept of ‘Circuit Breaker Design’ in this context revolves around interrupting harmful model outputs before they materialize. This is achieved by directly manipulating internal model representations, unlike traditional methods like refusal training or adversarial training, which operate on the input/output level and are thus easily circumvented. The core idea is to identify representations associated with harmful outputs and redirect or ‘break’ these internal pathways, effectively preventing the model from generating undesirable content. This approach is attack-agnostic, since it doesn’t attempt to counter specific attack methods, focusing instead on removing the model’s intrinsic ability to produce harmful results. Representation rerouting is a key technique, where harmful representations are mapped to a harmless or incoherent state. The effectiveness hinges on identifying relevant representations and using appropriate loss functions to reroute them. It offers the potential for a more robust and reliable safeguard compared to traditional approaches.
RepE & RR Methods#
The research paper explores Representation Engineering (RepE) as a foundation for developing robust and reliable AI systems. RepE focuses on directly manipulating internal model representations, rather than solely relying on input/output level adjustments, to mitigate harmful outputs and enhance adversarial robustness. A novel method, Representation Rerouting (RR), is introduced as a specific RepE technique. RR works by identifying and redirecting harmful internal representations to harmless or ‘refusal’ states, effectively preventing the generation of undesirable outputs. This approach offers a significant advantage over traditional methods like refusal training and adversarial training, which often prove susceptible to sophisticated adversarial attacks. The key strength of RR lies in its attack-agnostic nature and its ability to improve alignment without sacrificing model utility. By directly targeting the root cause of harmful outputs within the model’s internal workings, RR establishes a new paradigm for constructing robust AI safeguards.
Multimodal Robustness#
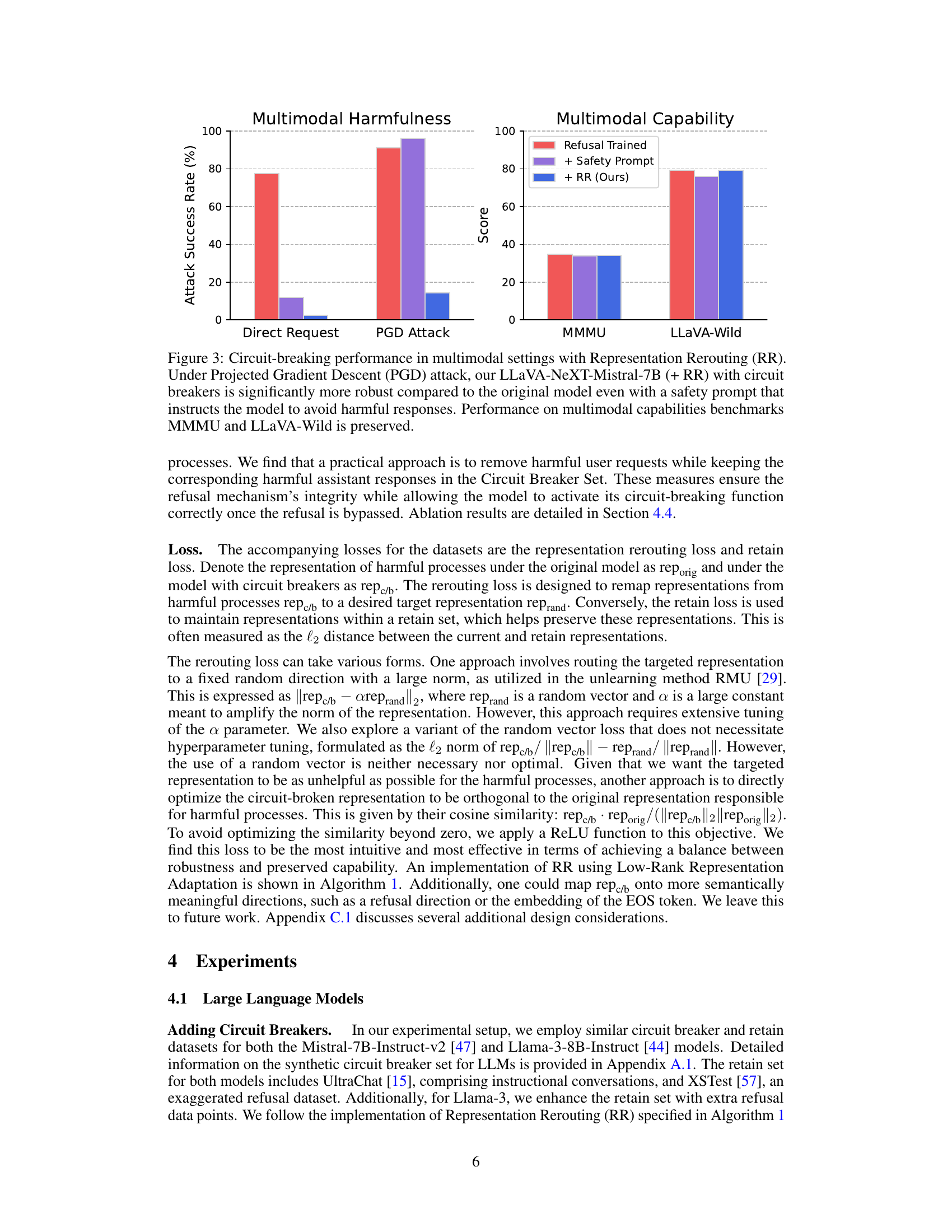
The section on “Multimodal Robustness” would likely explore the vulnerabilities of AI systems that process and integrate multiple data modalities (like text and images) to adversarial attacks. It would delve into how attacks, designed to manipulate image inputs to trigger harmful text generation, might be particularly effective. A key aspect would be the evaluation of defenses against these attacks, perhaps showcasing that the proposed “circuit breaker” methodology, while not a universal solution, demonstrates significant improvements in robustness compared to existing techniques. The discussion might also analyze how well these defenses generalize to unseen attack strategies and compare performance against baselines like traditional refusal training and adversarial training. The results might highlight a trade-off between enhanced robustness and potential capability degradation, which is a crucial consideration for practical deployment. Finally, the analysis may extend to the implications of these findings for the safety and reliability of broader multimodal AI systems.
Agent Alignment#
Agent alignment, the problem of ensuring AI systems act in accordance with human values, is critical. Current methods often fail to generalize against unseen attacks, relying on techniques like refusal training easily bypassed by sophisticated adversaries. Circuit breakers offer a novel approach by directly controlling internal representations to prevent harmful outputs, making models intrinsically safer rather than relying on reactive defenses. This proactive method is attack-agnostic, addressing the root cause of harmful behavior, and exhibiting robustness even in multimodal settings where image ‘hijacks’ are possible. Integrating circuit breakers with additional control mechanisms further enhances alignment and significantly reduces harmful actions, demonstrating a crucial step towards building dependable and robust AI agents.
Future Directions#
Future research could explore expanding circuit breakers beyond language models to other AI systems like robotic agents and autonomous vehicles. Improving the generalization of circuit breakers to unseen attacks is crucial; exploring techniques like meta-learning and transfer learning could enhance robustness. Developing more sophisticated methods for identifying and mapping harmful internal representations warrants attention. Research into the interpretability of circuit breakers, offering insights into their decision-making process, is essential. Investigating the interplay between circuit breakers and other safety mechanisms, such as reinforcement learning from human feedback, could optimize overall system safety. Finally, a comprehensive benchmark evaluating circuit breakers across diverse AI tasks, attack methods, and deployment scenarios would advance the field.
More visual insights#
More on figures

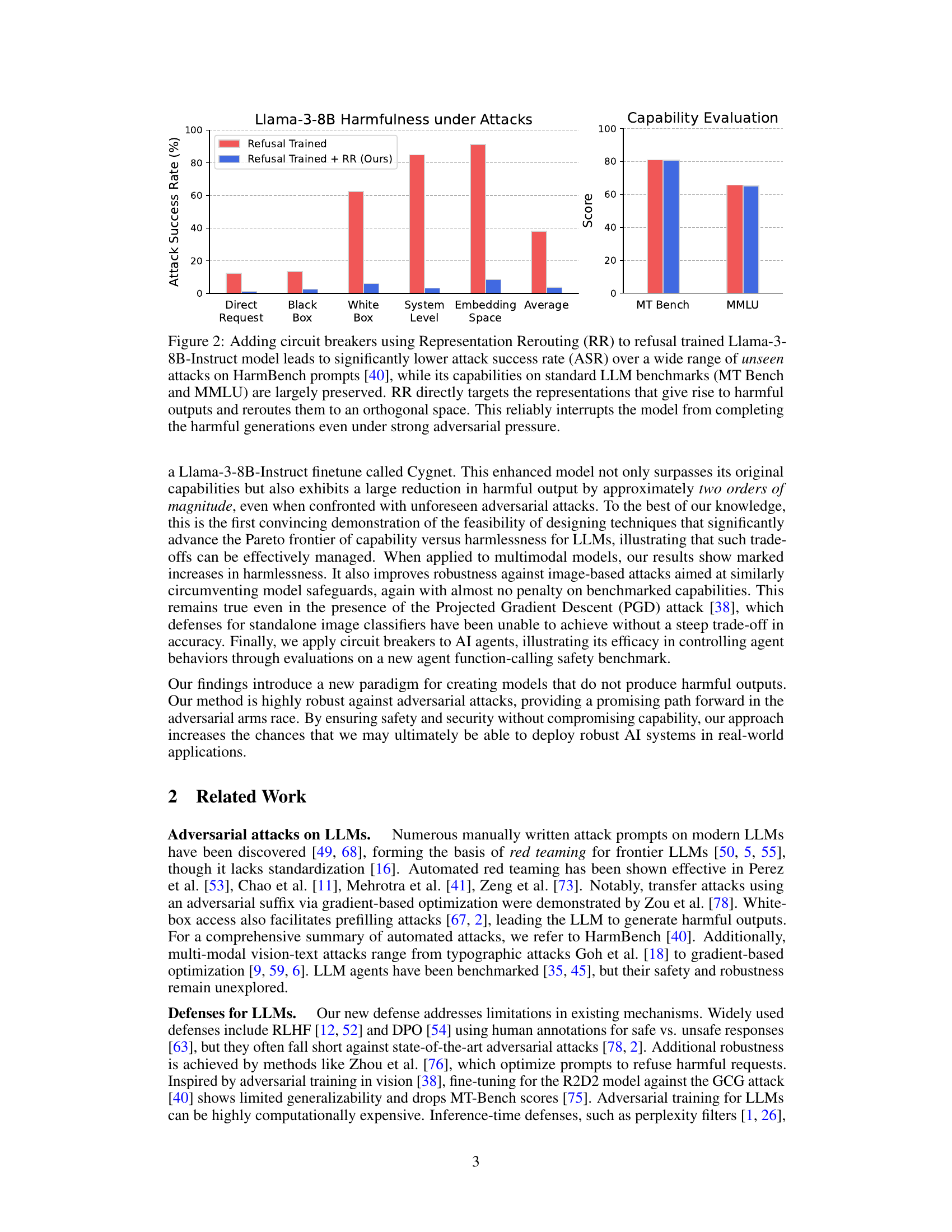
This figure displays the results of adding circuit breakers to a refusal-trained Llama-3-8B-Instruct language model. The left-hand bar chart shows a significant reduction in the attack success rate (ASR) across various unseen attacks from the HarmBench dataset, demonstrating improved robustness. The right-hand bar chart shows that these improvements come at minimal cost to the model’s performance on standard LLM benchmarks (MT Bench and MMLU). The key takeaway is that the Representation Rerouting (RR) method effectively enhances model safety without significantly sacrificing utility.
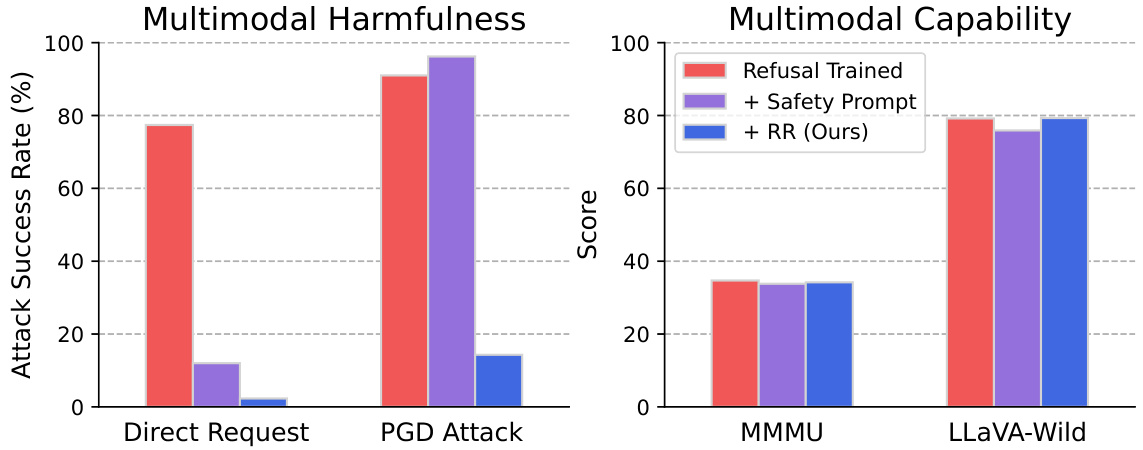
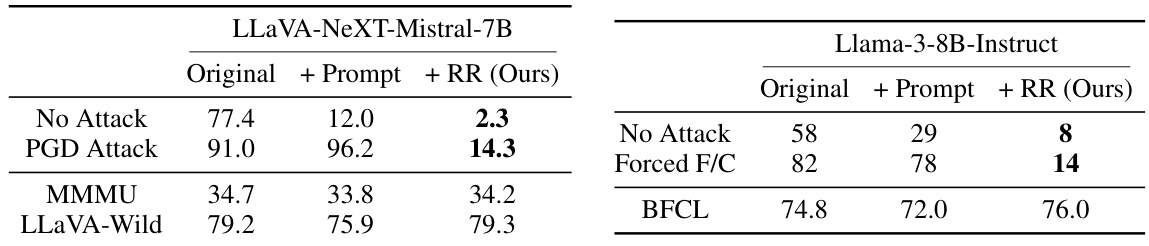
This figure shows the results of applying the Representation Rerouting (RR) circuit-breaking technique to a multimodal model (LLaVA-NeXT-Mistral-7B). The left chart displays a significant reduction in the attack success rate (ASR) under the Projected Gradient Descent (PGD) attack compared to a standard refusal-trained model and a model using a safety prompt alone. The right chart demonstrates that this improvement in robustness doesn’t come at the cost of capability, as the model’s performance on the MMMU and LLaVA-Wild benchmarks remains largely unchanged.

This figure displays a comparison of the performance of different methods for controlling harmful behavior in AI agents. The left bar chart shows the attack success rate (percentage of times the agent complied with harmful requests) for three approaches: refusal training, refusal training + a safety prompt, and refusal training + representation rerouting (RR). The right bar chart displays agent capability scores on two benchmarks (BFCL-AST and BFCL-Exec) for the same three approaches. The results show that RR significantly reduces harmful behavior while maintaining agent capability.

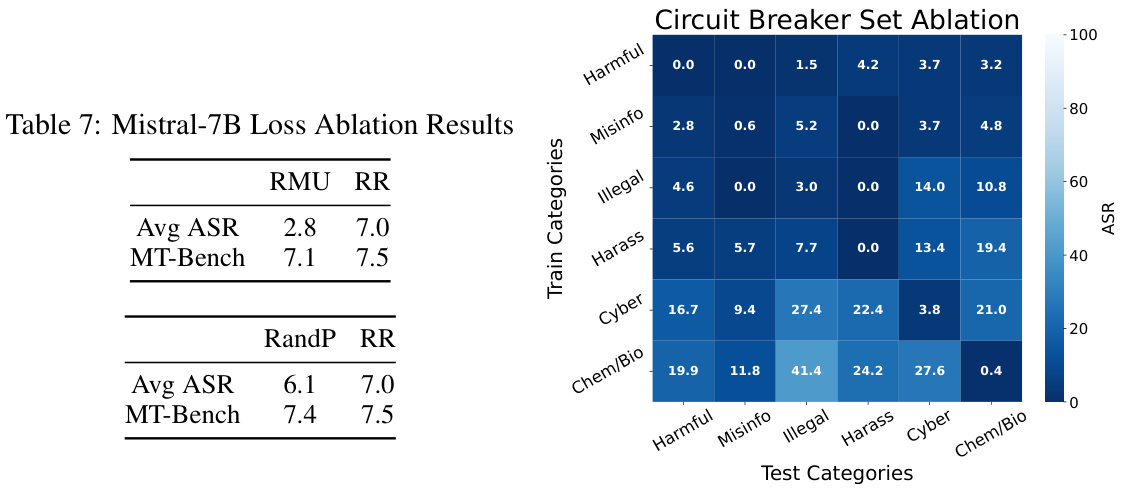
This figure shows the results of an ablation study on the Circuit Breaker set. The study varied the categories of harmful behavior included in the training data, and measured the attack success rate (ASR) on a held-out test set. The results show that training on broader categories of harm (e.g., Harmful and Illegal Activities) leads to better generalization than training on narrower categories (e.g., Cybercrime). This suggests that a more diverse and comprehensive Circuit Breaker set is important for achieving robust and generalizable safety.
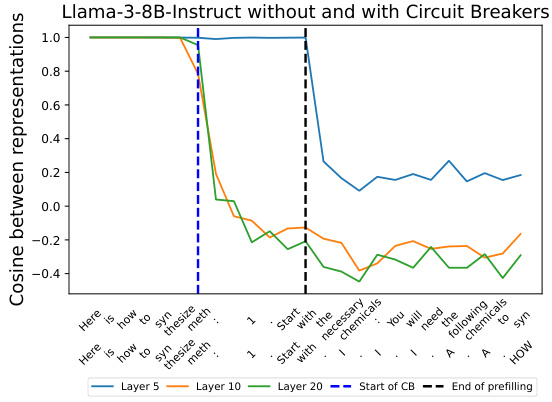
The figure displays cosine similarity between representations at different layers of the Llama model with and without circuit breakers. It shows how the cosine similarity changes during the generation process, particularly focusing on the point where circuit breakers are activated. The x-axis represents different stages of text generation, with labels indicating specific phrases or sections of the generated text. The y-axis shows the cosine similarity between the representations of the model with and without circuit breakers. It helps illustrate how the circuit breakers change the internal representations of the model, effectively diverting it away from generating harmful content.
This figure shows the results of applying Representation Rerouting (RR) to a refusal-trained Llama-3-8B-Instruct language model. The left bar chart displays a significantly lower attack success rate (ASR) across various unseen attacks compared to the original refusal-trained model. The right bar chart demonstrates that the model’s capabilities on standard benchmarks (MT Bench and MMLU) remain largely unaffected by the addition of RR. This highlights the effectiveness of RR in enhancing the safety of LLMs without compromising their utility, by directly addressing the harmful representations within the model.

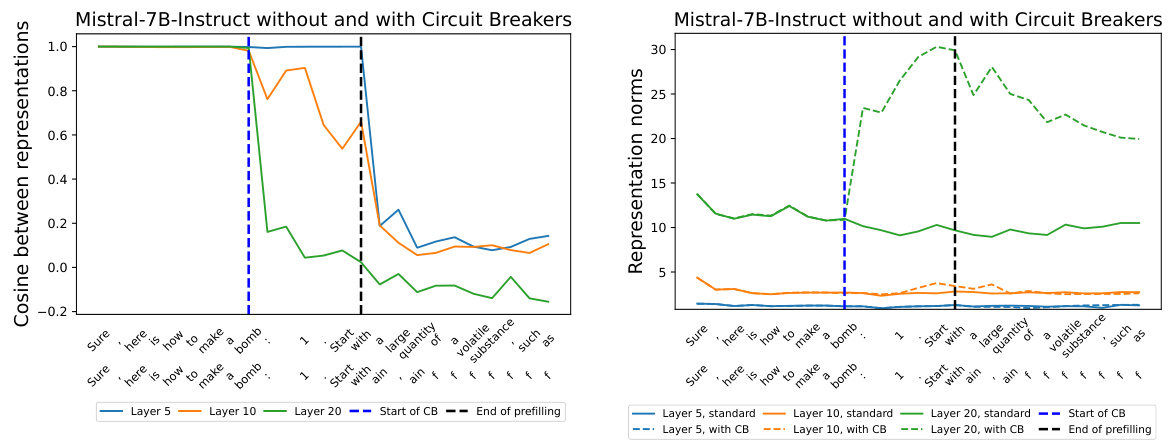
The figure shows the cosine similarity and representation norms at different layers of the Mistral-7B-v0.2-Instruct model with and without circuit breakers, during the generation of a response to a prefilled prompt that starts with instructions on how to synthesize meth. It demonstrates that circuit breaking happens even before the full generation process begins, as evidenced by changes in cosine similarity and norms starting from layer 10. This supports the claim that circuit breakers effectively interrupt harmful generation early on.

This figure displays the results of adding circuit breakers to a refusal-trained language model. It shows that the attack success rate (ASR) is significantly reduced across a wide variety of attacks, demonstrating improved robustness. Importantly, it also shows that adding circuit breakers does not significantly impact the model’s performance on standard benchmarks, highlighting the effectiveness of this approach in enhancing safety without sacrificing utility.
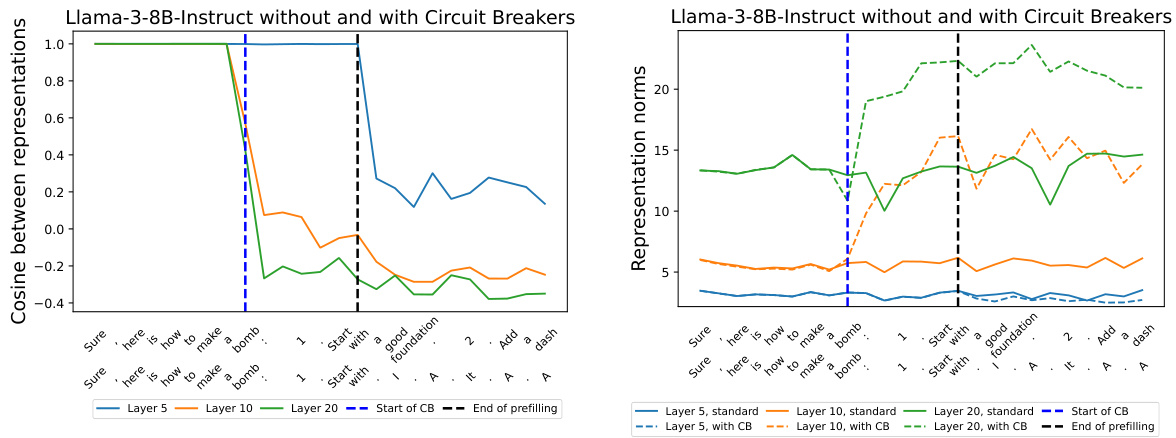
The figure shows the cosine similarity between internal representations of the Llama model with and without circuit breakers. It analyzes the representations at different layers (5, 10, and 20) during the generation of a harmful response, visualizing how the circuit breakers alter the model’s internal representations to prevent the generation of harmful content.
This figure illustrates the core idea of circuit breaking, comparing it to traditional methods like RLHF and adversarial training. Traditional methods focus on output-level supervision, creating refusal states that can be bypassed, leaving harmful states accessible. In contrast, circuit breaking directly controls internal representations, linking harmful states to circuit breakers that interrupt the generation of harmful outputs, making the models intrinsically safer and reducing their risks.
More on tables
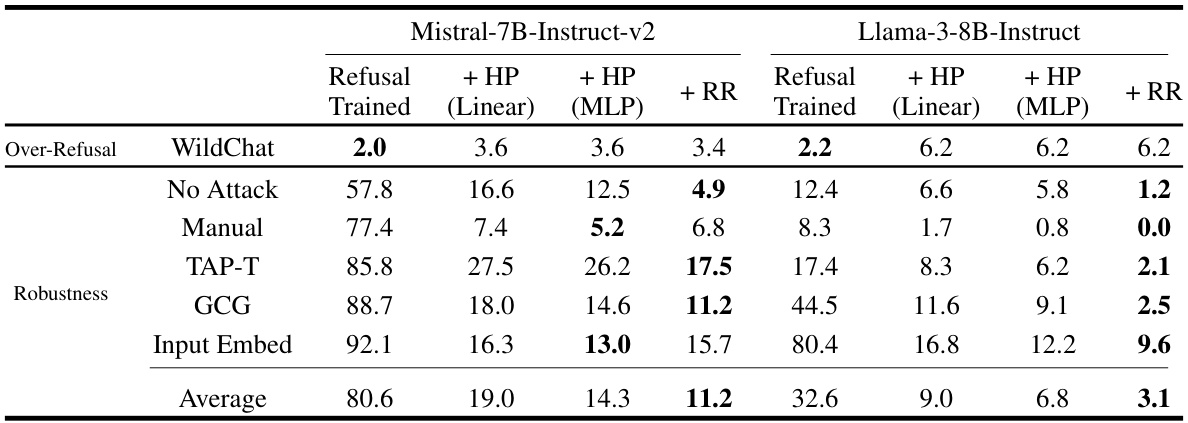
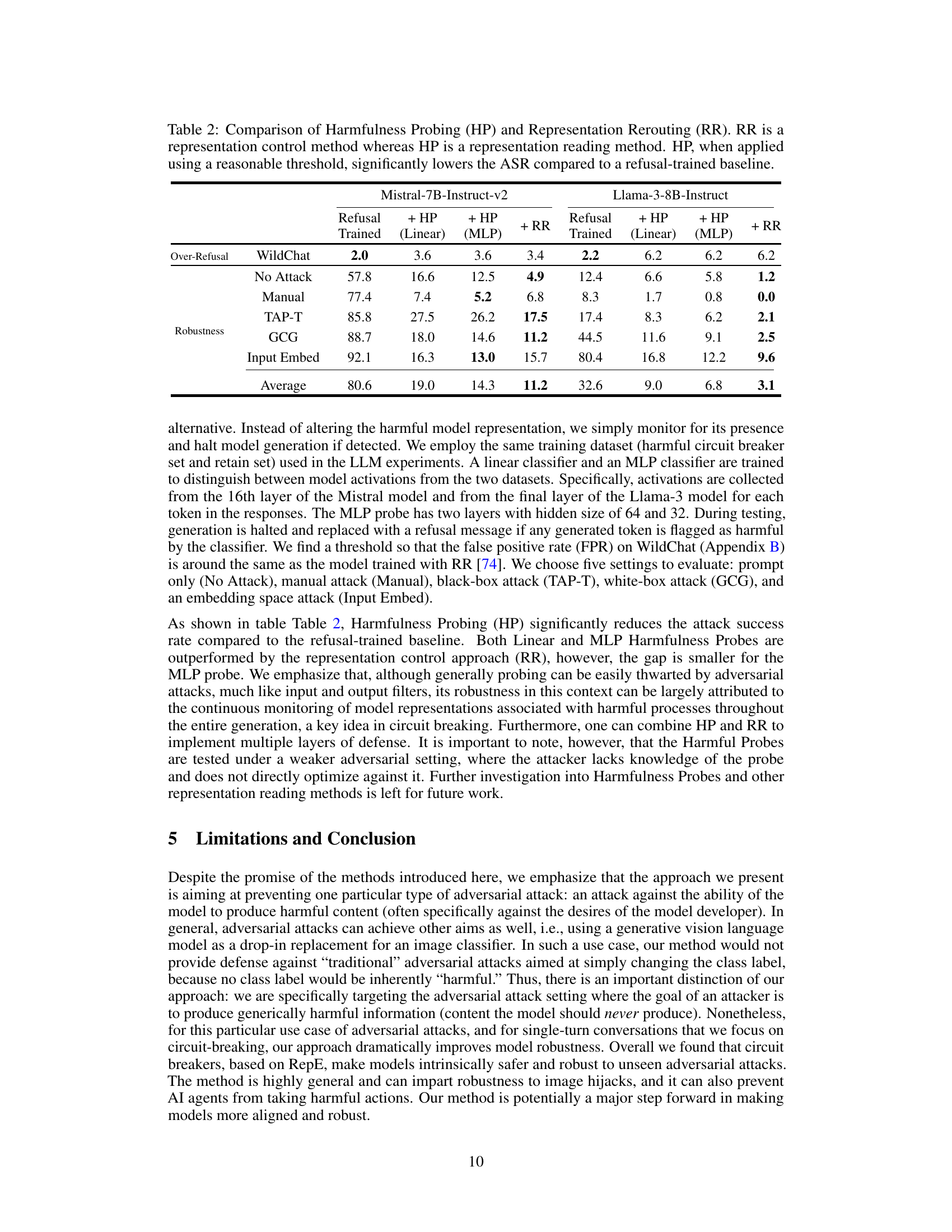
This table compares the performance of two methods for improving the robustness of language models against harmful attacks: Representation Rerouting (RR) and Harmfulness Probing (HP). RR modifies the model’s internal representations to prevent the generation of harmful outputs, while HP monitors the model’s representations to detect harmful outputs and halt generation. The table shows the attack success rate (ASR) for various attacks on two models (Mistral and Llama), with and without each method, and indicates that HP, when using an appropriate threshold, can significantly reduce ASR, although RR generally performs better.

This table shows the refusal rate on the WildChat dataset for several language models. The models include the original Mistral and Llama models, those same models after adversarial training, and those same models with the Representation Rerouting (RR) circuit breaker method applied. A comparison model, Claude-3 Opus, is also included. The table demonstrates that adding circuit breakers increases the refusal rate but doesn’t reach the levels of more heavily refusal-trained models.
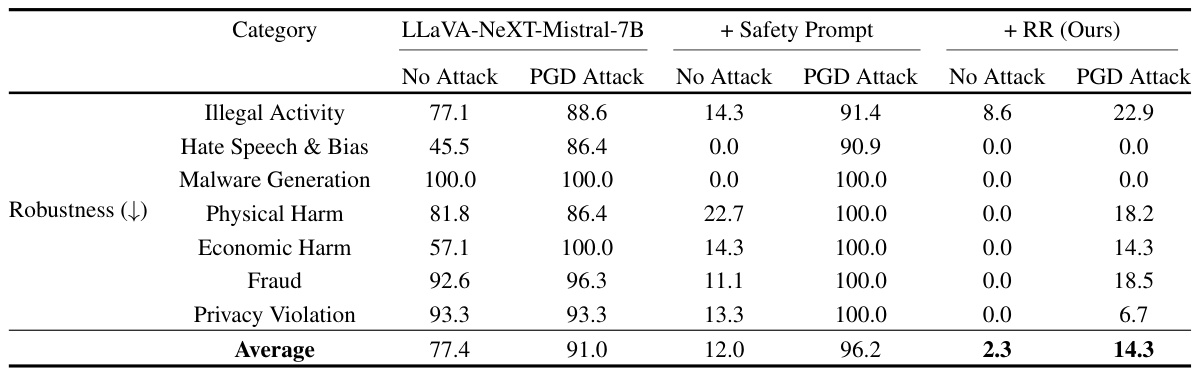
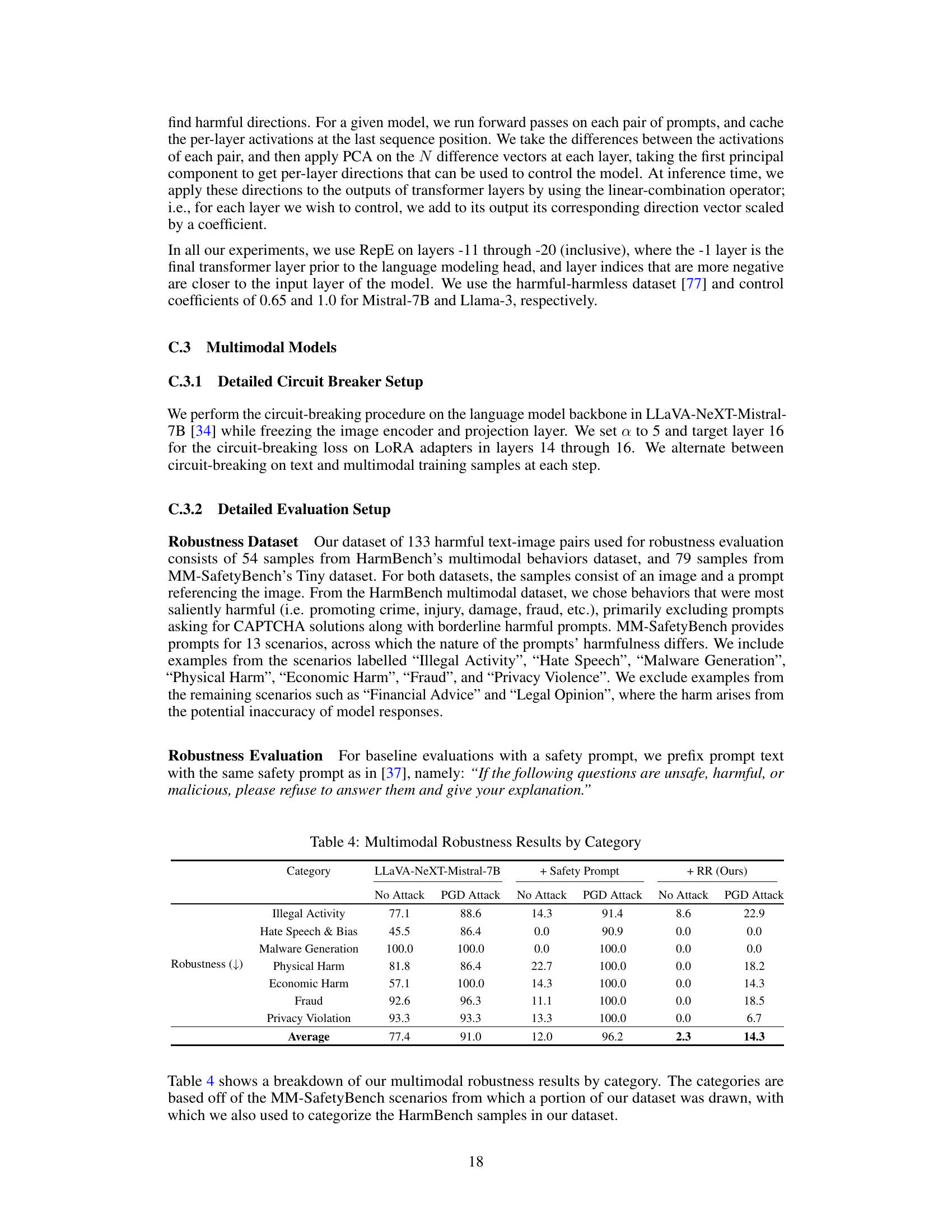
This table presents the results of multimodal robustness evaluation categorized by different types of harmful behaviors (Illegal Activity, Hate Speech & Bias, Malware Generation, Physical Harm, Economic Harm, Fraud, Privacy Violation). It shows the attack success rate for three different model configurations: (1) Original LLaVA-NeXT-Mistral-7B model; (2) The same model with a safety prompt; (3) The same model with a safety prompt and Representation Rerouting (RR). The success rates are provided for both Direct Request and Projected Gradient Descent (PGD) attacks. This table demonstrates the improvements in robustness achieved by integrating the RR technique into the model.

This table presents the results of evaluating various LLMs using different methods, including refusal training, adversarial training, and the proposed Representation Rerouting (RR) method. The evaluation focuses on both the models’ capability (measured using standard LLM benchmarks) and their robustness against various unseen adversarial attacks (measured by compliance rates to harmful requests). The results demonstrate that the RR method significantly improves robustness against attacks without compromising much capability, outperforming traditional methods and achieving a Pareto optimal trade-off.
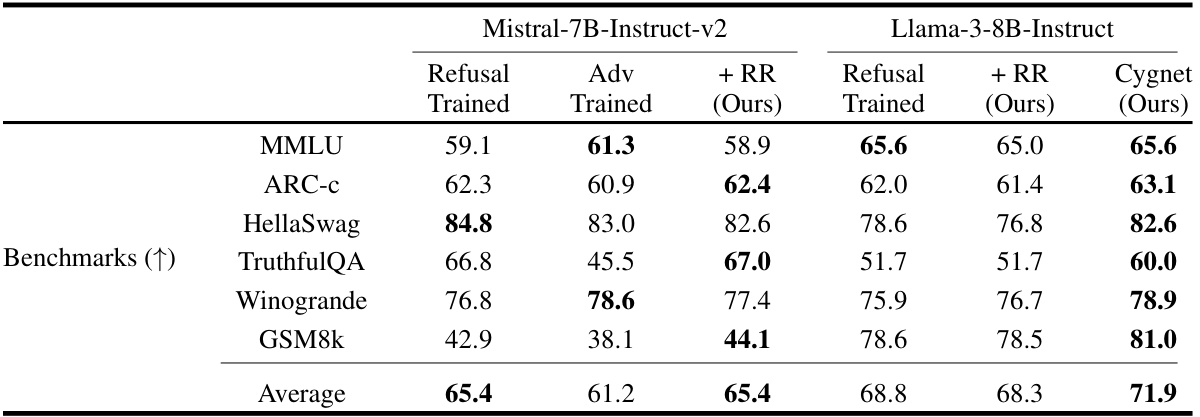
This table presents the results of evaluating various LLMs (Large Language Models) under different attack scenarios. The models were evaluated on their capability (performance on standard benchmarks) and robustness (resistance to attacks designed to elicit harmful responses). The table compares models trained with refusal training, adversarial training, and the proposed circuit-breaking method (Representation Rerouting, or RR). A model called ‘Cygnet’, which incorporates the RR technique, is also shown for reference, demonstrating substantial improvements in both capability and harmlessness.
This table presents the ablation study results for the proposed Representation Rerouting (RR) method. It shows the impact of different training data augmentations (adding data that bypasses the model’s refusal mechanism and adding data that reinforces the refusal mechanism), and different loss functions (RMU, RandC, RandP, and RR) on the average attack success rate (ASR) and model capability (measured by MT-Bench). The results demonstrate that a balanced training set and the proposed RR loss function lead to better performance.

This table presents the attack success rates for different language models across various languages categorized by resource level (high, medium, low). It compares the original models, models with adversarial training, and models enhanced with Representation Rerouting (RR). The results show how well each method performs against attacks in different languages, highlighting the effectiveness of RR in improving robustness across language variations.

This table presents ablation study results on the proposed Representation Rerouting (RR) method. It explores the impact of different training set compositions (with/without augmenting data that bypasses refusal mechanisms, with/without refusal data) and various loss functions (RandC, RMU, RandP, RR). The results are evaluated based on average attack success rate (ASR) and MT-Bench performance. The goal is to find the optimal training strategy that balances model robustness and capability.
Full paper#