↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current instruction-guided scene editing methods struggle with multi-view inconsistencies due to large feasible output spaces of diffusion models. This leads to poor quality results like blurry textures and noisy geometry. Existing solutions often use complex add-ons or training procedures, which adds significant costs.
ProEdit tackles this issue by decomposing the editing task into several easier subtasks with smaller feasible output spaces. It uses a difficulty-aware scheduler to assign these subtasks and an adaptive 3D Gaussian splatting strategy to ensure high-quality editing for each subtask. This simple, progressive approach achieves state-of-the-art results without expensive add-ons, providing a new way to control and preview the editing process.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel and effective framework for high-quality 3D scene editing, addressing a key challenge in the field. ProEdit’s progressive subtask approach and adaptive 3D Gaussian splatting strategy offer significant improvements over existing methods, achieving state-of-the-art results in terms of quality, efficiency, and user control. This opens new avenues for research in 3D scene editing and related fields.
Visual Insights#

This figure demonstrates the core idea of ProEdit: decomposing complex 3D scene editing tasks into smaller, easier subtasks that are processed sequentially. The top row shows an example of this process with three different tasks, each broken down into subtasks with increasing levels of editing ‘aggressivity’. The bottom row shows the final results for each task at different levels of aggressivity. The overall result is high-quality 3D scene editing with bright colors and detailed textures, as well as increased control over the degree of editing applied.

This table presents a quantitative comparison of the proposed ProEdit method against several state-of-the-art instruction-guided scene editing methods. The metrics used are User Study of Overall Quality (USO), User Study of 3D Consistency (US3D), GPT Evaluation Score (GPT), CLIP score (CTIDS and CDC), and Running Time. ProEdit demonstrates significant improvements in USO, US3D, and GPT scores compared to the baselines, with a substantially shorter running time than ConsistDreamer while maintaining comparable performance on CLIP metrics.
In-depth insights#
Progressive 3D Editing#
Progressive 3D editing represents a significant advancement in 3D scene manipulation. Instead of attempting large, complex edits all at once, this approach breaks down the task into a series of smaller, incremental steps. This is crucial because it addresses the inherent limitations of many 3D editing methods, which often struggle with multi-view inconsistency stemming from large feasible output spaces. By progressively refining the scene through a sequence of carefully controlled subtasks, progressive editing significantly improves the quality and consistency of the final result. The smaller, more manageable subtasks allow for more precise control over the editing process, leading to higher-fidelity outputs with accurate geometry and detailed textures. This method also allows for innovative features such as dynamic adjustment of editing aggressivity, providing users with greater flexibility and control. While the specific implementation details may vary, the core concept of progressive refinement through subtask decomposition is key to unlocking the full potential of high-quality 3D scene editing.
FOS Control via Subtasks#
The concept of ‘FOS Control via Subtasks’ presented in the research paper centers on addressing the challenge of multi-view inconsistency in 3D scene editing, which arises from the large feasible output space (FOS) of diffusion models. The core idea is to decompose a complex editing task into smaller, more manageable subtasks, each with a significantly reduced FOS. This decomposition allows for progressive refinement, where each subtask addresses a specific aspect of the editing goal, iteratively building toward the final result. By controlling the FOS at each step, the approach aims to mitigate inconsistencies and enhance the quality and efficiency of the overall editing process. The effectiveness hinges on a carefully designed subtask scheduler that determines the order and difficulty of the subtasks, and an adaptive 3D scene representation that maintains geometric precision during the progressive editing. This method offers a novel way to control the ‘aggressiveness’ of the editing process, allowing users to fine-tune the intensity of changes by selectively applying subtasks, leading to a more intuitive and high-quality scene editing experience.
Adaptive 3DGS Training#
Adaptive 3DGS training is a crucial innovation for high-quality 3D scene editing, addressing the limitations of standard 3D Gaussian splatting (3DGS) when dealing with inconsistencies inherent in instruction-guided editing. The core idea is to dynamically control the creation and refinement of Gaussian splatters during the training process, ensuring the 3D scene representation adapts precisely to the edited images. This is achieved by adaptively adjusting two key parameters: the opacity threshold for culling unnecessary splatters and the gradient threshold for generating new splatters. The opacity threshold prevents overfitting on noisy or inconsistent regions, preserving a clean and coherent geometric structure, while the gradient threshold controls the density and precision of new splatters, refining the details in the edited areas. This dynamic control mechanism significantly improves the quality and efficiency of scene editing by preventing the accumulation of errors during the iterative editing process, resulting in more realistic and visually pleasing output.
Aggressivity Control#
The concept of ‘Aggressivity Control’ in the context of 3D scene editing, as explored in the research paper, is a fascinating and innovative approach to managing the intensity of edits. It’s not about simply making edits stronger or weaker, but rather about providing granular control over the editing process. This control is achieved by decomposing complex editing tasks into smaller, more manageable subtasks, each of which can be executed with varying levels of intensity. This allows users to preview the results of each subtask and make adjustments as needed, ensuring that the final result aligns with the user’s intentions. This progressive refinement approach minimizes inconsistencies that can occur when making drastic changes to a scene directly. The notion of ‘aggressivity’ is not just a technical parameter; it becomes a creative tool, empowering users to craft edits with a nuanced approach to achieve high-quality results.
Future Research#
The ‘Future Research’ section of this paper presents exciting avenues for extending the capabilities of ProEdit. One key direction is exploring semantic guidance for subtask decomposition, potentially leveraging large language models to generate more sophisticated and nuanced subtasks. This would enable ProEdit to handle more complex editing scenarios, overcoming current limitations. Integrating video generation models to animate the transitions between edited scenes offers another promising avenue, transforming ProEdit into a 3D scene animation tool. This would significantly enhance its functionality and address the demand for dynamic 3D content creation. Finally, applying ProEdit’s progressive editing framework to scene generation tasks could lead to breakthroughs in high-quality, controllable content creation, opening new possibilities for creative applications. Addressing the inherent limitations of relying on 2D diffusion models, and exploring solutions for unbounded outdoor scenes are also critical research directions. Careful consideration of potential ethical implications, especially regarding potential misuse for biased outputs or Deepfakes, is essential for responsible future development.
More visual insights#
More on figures

This figure illustrates the ProEdit framework’s three main components: subtask formulation, subtask scheduling, and adaptive 3DGS for progressive scene editing. It shows how a full editing task is decomposed into smaller subtasks, scheduled according to their difficulty, and processed using 3DGS on a dual-GPU system. The figure highlights the iterative nature of the process and how the intermediate results of each subtask contribute to the final edited scene.

This figure compares the results of ProEdit with several other state-of-the-art methods on two scenes. The top row shows the original images, and the following rows show the edited results produced by different methods for several different editing tasks. ProEdit produces higher quality results across different levels of editing ‘aggressiveness’, which is controlled by the number of subtasks.

This figure compares the results of ProEdit with ConsistDreamer and EN2N on three different indoor scenes from the ScanNet++ dataset. Each scene is subjected to four different editing instructions, resulting in edits with varying levels of visual fidelity. The figure highlights ProEdit’s ability to produce results comparable or superior to more complex baselines.

This figure compares the results of ProEdit with IN2N and ConsistDreamer on two outdoor scenes. The top row shows the original scenes. The following rows show the results of different methods, including ProEdit at both medium and high levels of aggressivity, demonstrating improved results and the ability to control the level of editing. The caption highlights that ProEdit outperforms the baselines and provides control over editing aggressivity.

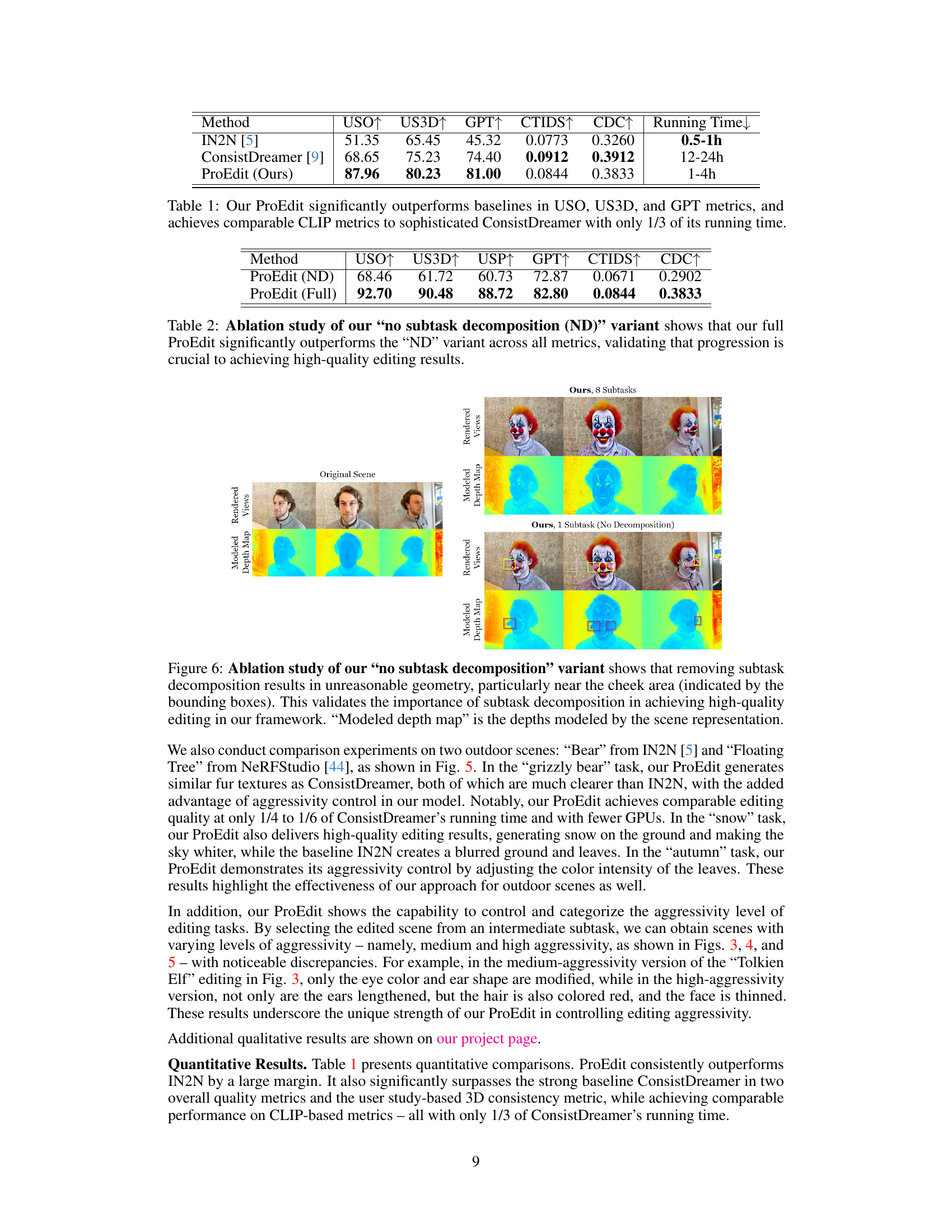
This figure shows an ablation study comparing the results of ProEdit with and without subtask decomposition. The top row shows the original image and the results when using ProEdit with 8 subtasks (progressive editing). The bottom row displays the same editing task performed with only 1 subtask. The images showcase clear geometric issues such as unrealistic cheek shapes (highlighted with bounding boxes) when the subtask decomposition is removed, highlighting the importance of the method’s progressive refinement strategy.

This figure visualizes the results of editing each view of a scene separately using the IP2P model, for different values of the subtask ratio r. As r increases, the inconsistency between views increases, making the overall editing task more difficult. This demonstrates the challenge of achieving high-quality 3D scene editing when dealing with a large feasible output space.

This figure shows a comparison of the results before and after applying the additional subtask rn. The depth maps, modeled by 3DGS, are segmented to emphasize the foreground. The before and after images are very similar in overall appearance, however, the refined version shows more precise geometry and detail near the ear. This demonstrates that while subtask rn does not significantly alter the overall look, it does provide minor improvements and refinements to the geometric structure of the edited results.

This figure shows a comparison between the results of editing a 3D scene using the proposed ProEdit method and the results of editing a 2D image using the IP2P method. The 3D scene is decomposed into several subtasks, each corresponding to a different level of editing intensity. The results of editing the 3D scene using each subtask are shown in the bottom row, while the results of editing the 2D image using the IP2P method are shown in the top row. As can be seen, the results of editing the 3D scene using each subtask are very similar to the results of editing the 2D image using the IP2P method. This suggests that the proposed ProEdit method is able to effectively decompose the editing task into several subtasks and that the results of editing the 3D scene using each subtask are consistent with the results of editing the 2D image using the IP2P method. This demonstrates the effectiveness of the proposed subtask decomposition strategy for 3D scene editing.
Full paper#