↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large diffusion transformers show promise in generating various modalities from text, but existing models like Lumina-T2X suffer from training instability, slow inference, and resolution limitations. These issues hinder the practical applications of such models.
Lumina-Next tackles these challenges head-on. It introduces a novel architecture (Next-DiT) with optimized normalization and positional encoding. The paper also proposes new context extrapolation methods, higher-order ODE solvers, and a context drop technique to significantly improve training stability, inference speed, and resolution. The results show improved generation quality and efficiency, with superior resolution extrapolation and multilingual capabilities. The open-source release further facilitates broader adoption and future research.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in generative AI, especially those working with diffusion models. It presents Lumina-Next, a significantly improved version of Lumina-T2X, addressing key limitations and showcasing superior performance across multiple modalities. The efficient techniques and open-source nature of Lumina-Next accelerate research progress in generative AI.
Visual Insights#
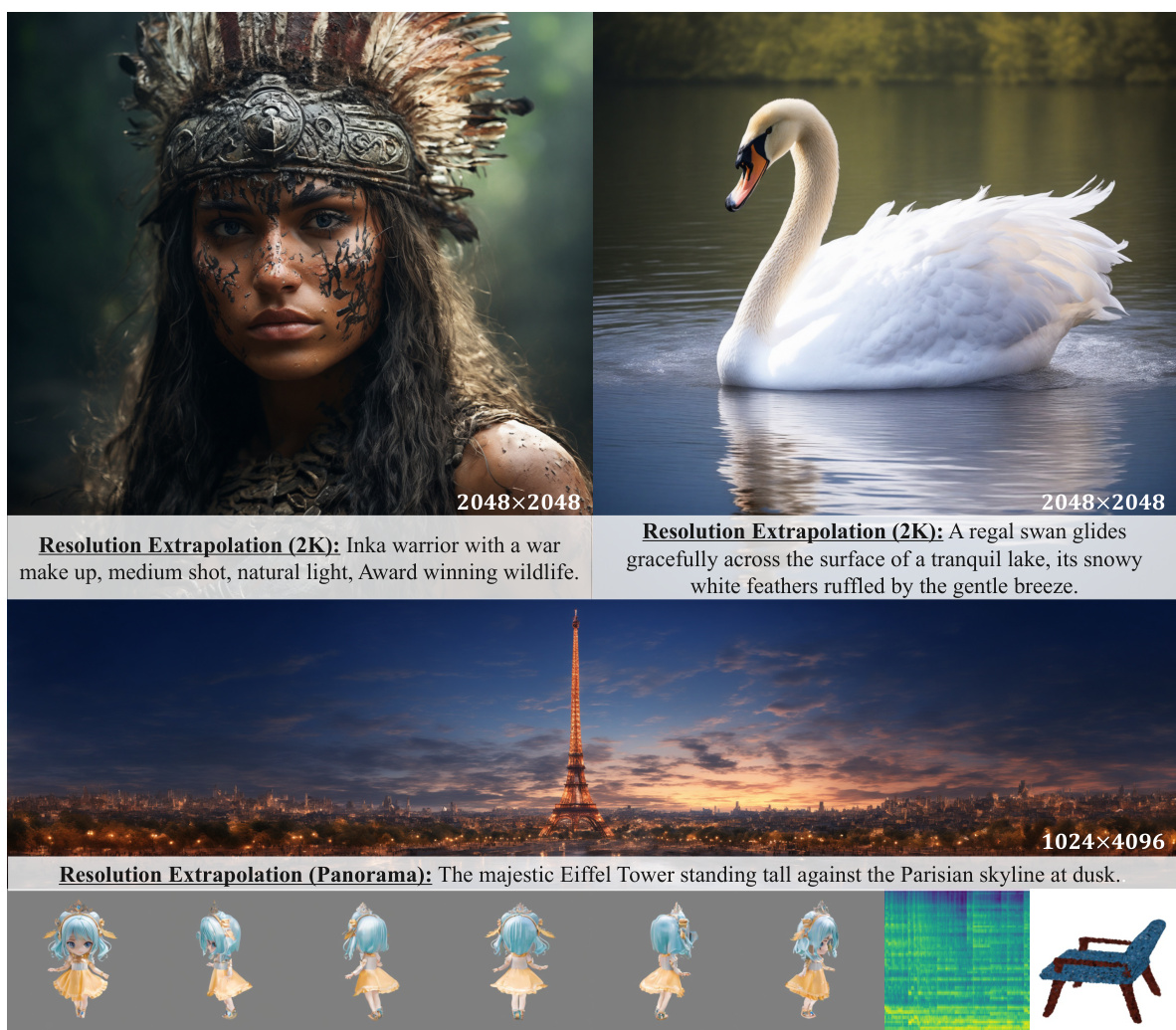
This figure showcases the versatility of the Lumina-Next framework by demonstrating its ability to generate various types of media, including high-resolution images (2K resolution examples of an Inka warrior and a swan are shown), multi-view images (an example of a figurine is given), audio and music, and point clouds (a blue chair is shown as a point cloud example). This highlights the framework’s capacity to operate as a foundational generative model across different data modalities.
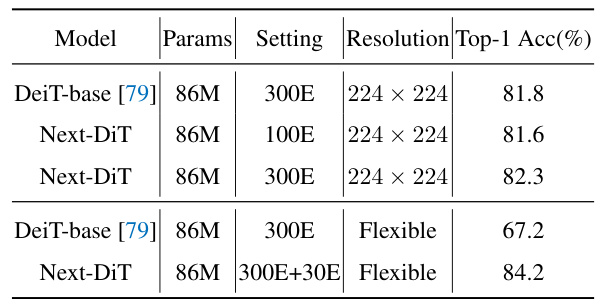
This table compares the performance of Next-DiT and DeiT-base on ImageNet classification. It shows the number of parameters, training epochs, resolution used, and the Top-1 accuracy achieved by each model. Two sets of results are presented: one for a fixed resolution of 224x224, and another using flexible resolution. The flexible resolution results demonstrate Next-DiT’s ability to handle various image sizes effectively.
In-depth insights#
Next-DiT Architecture#
The Next-DiT architecture presents a refined approach to the original Flag-DiT, focusing on enhanced stability, efficiency, and resolution extrapolation capabilities. Key improvements include the transition from 1D to 3D Rotary Position Embedding (RoPE), enabling superior handling of spatial and temporal relationships in images and videos. The incorporation of sandwich normalization blocks effectively regulates activation magnitudes, mitigating training instability and improving sampling. Furthermore, the architecture incorporates the Grouped-Query Attention mechanism to reduce computational costs while maintaining performance. These modifications result in a model that demonstrates faster convergence during training, quicker inference times, and superior visual quality, particularly in high-resolution generation and multilingual tasks. The architectural changes demonstrate a commitment to addressing fundamental limitations of the original Flag-DiT, resulting in a more robust and efficient diffusion transformer.
ROPE Enhancements#
Rotary Position Embedding (ROPE) enhancements are crucial for diffusion models, especially when handling high-resolution images and long sequences. The core idea behind ROPE is to implicitly encode positional information within the attention mechanism using relative positional encodings rather than explicit positional embeddings. 3D ROPE, an extension of the original 1D ROPE, is introduced to handle images and videos effectively by separating spatial and temporal dimensions. Frequency- and Time-Aware Scaled ROPE further improves ROPE’s extrapolation capabilities, especially in high-resolution settings, by carefully adjusting the frequency and time components to reduce content repetition and improve global consistency. These enhancements significantly improve the performance and efficiency of diffusion models, especially for tasks requiring superior resolution generation.
Efficient Sampling#
Efficient sampling in generative models is crucial for both training speed and inference efficiency. Reducing the number of sampling steps is a key focus, often achieved by employing advanced numerical methods like higher-order ODE solvers that minimize discretization errors. These methods allow for high-quality sample generation with fewer steps, significantly reducing computational cost. Another strategy involves optimizing the time schedule, carefully choosing the sequence of timesteps to guide the sampling process, often using parametric functions designed to balance speed and accuracy. Furthermore, techniques like context drop aim to speed up network evaluation by merging or dropping redundant visual tokens, reducing the computational burden of self-attention mechanisms. The effectiveness of these techniques is often demonstrated by generating high-quality results with substantially fewer sampling steps compared to standard methods, proving their value in creating a more efficient and faster generative process.
Multimodal Results#
A hypothetical ‘Multimodal Results’ section would ideally showcase the model’s capabilities across diverse data types beyond its primary focus. This could include qualitative and quantitative evaluations of image generation, audio synthesis, and potentially video or 3D model creation. A strong section would highlight not just successful generation, but also the model’s handling of cross-modal interactions. For instance, how well does text describing an image influence generated audio that evokes the same mood? Furthermore, a discussion of limitations and potential failure cases is crucial, demonstrating a thorough understanding of the model’s capabilities and boundaries. The results should not only present visually appealing outputs but also demonstrate a consistent level of performance across all modalities, offering a compelling argument for the model’s generalized capabilities in a multimodal context. The presentation of results needs to be clear, concise, and insightful, with a focus on highlighting interesting cross-modal relationships and unexpected behaviors.
Future Directions#
Future research directions for Lumina-Next could focus on several key areas. Scaling to even larger models and exploring the limits of resolution extrapolation are crucial. Addressing potential biases and improving the diversity of generated content are essential for responsible AI development. The integration of more advanced higher-order ODE solvers promises further improvements in sampling efficiency and image quality, minimizing the discretization errors. Expanding the versatility of Lumina-Next by incorporating additional modalities beyond images, audio, and music, including 3D modeling and scientific data, would broaden its applicability significantly. Finally, rigorous testing for robustness against various types of adversarial attacks is needed to ensure reliability and trustworthiness of the generative framework. Further research into efficient, scalable training techniques for large diffusion models, particularly those focused on achieving high-resolution generation and stable training, remains a key challenge.
More visual insights#
More on figures

This figure compares the attention scores generated by 1D ROPE and 2D ROPE on images. The central point of the image is selected as the anchor query, and the attention scores are visualized for both methods. The comparison shows that 1D ROPE does not capture the spatial relationships between the different positions in the image, while 2D ROPE accurately reflects these relationships.

The figure shows the effectiveness of sandwich normalization in controlling the growth of activation magnitudes across layers in a neural network. The plots illustrate how the mean and maximum activation values remain relatively stable across layers when sandwich normalization is used, preventing the uncontrolled growth observed without this technique. This stability is crucial for training large, deep networks and enhancing their overall performance.

This figure demonstrates a comparison of different resolution extrapolation strategies for a 2K image generation task. Subfigure (a) shows a toy example illustrating the wavelength of RoPE embeddings under different extrapolation methods: extrapolation, interpolation, NTK-aware, frequency-aware, and time-aware scaled ROPE. Subfigures (b) through (g) present visual results of these different strategies applied to a 1k image, demonstrating their respective impacts on image quality and the ability to extrapolate to higher resolutions. Note the visual differences, particularly concerning repetition artifacts and detail preservation.

This figure compares the results of generating images using different time schedules (Uniform, Rational, Sigmoid) with Euler’s method in a diffusion model. Each row represents a different schedule. Each column shows the results for different image generation tasks (portraits, wreaths, phoenix, cityscape). The number of steps used (10 steps, 30 steps) is indicated above each column. The results showcase how different sampling schedules affect the generation quality and convergence speed.

This figure compares the performance of several models (Lumina-Next (1K), SDXL, PixArt-a, MultiDiffusion, DemoFusion, ScaleCrafter, Lumina-T2I) on 4x resolution extrapolation. It visually demonstrates the differences in image quality and artifact generation when extrapolating beyond the original training resolution. Lumina-Next shows significantly less artifacts compared to the other models.

This figure compares the image generation results using different time schedules (Uniform, Rational, Sigmoid) with Euler’s method for 10 and 30 steps. The goal is to show how the choice of time schedule affects the quality of the generated image, particularly when using a reduced number of steps. The Sigmoid schedule demonstrates better performance, especially at lower step counts.

This figure illustrates the architectural differences between the original Flag-DiT and the improved Next-DiT. Key improvements in Next-DiT are highlighted, including the replacement of 1D ROPE with 3D ROPE, the addition of sandwich normalization blocks, and the use of grouped-query attention. The figure shows the flow of information through both architectures, from noisy input to the final predicted velocity or noise, detailing the changes made to enhance stability and efficiency.

This figure demonstrates the concept of using multiple captioning models to generate a more comprehensive and accurate description of an image. Different models (BLIP2, ShareGPT4V, CogVLM, SPHINX-X, LLaVA-next, GPT-4V) are used to generate captions of the same image and the various captions provide different levels of detail and perspectives, demonstrating the value of combining outputs from multiple models to create a more robust image description.

This figure shows the qualitative results of 2K images generated by Lumina-Next with and without using the context drop method. The left panel (a) displays four example images generated with and without the method. The right panel (b) presents a bar chart illustrating the inference time comparison for different settings (baseline, context drop, Flash Attention, and Flash Attention + Context Drop) at two resolutions (1024x1024 and 2048x2048).

This figure displays the results of multilingual text-to-image generation using three different models: Lumina-Next, SDXL, and PixArt-a. The same prompt was given in multiple languages (English, Japanese, Chinese, Russian, Ukrainian, Thai, Polish, Persian, Modern Standard Arabic, Korean, Vietnamese, Marathi, Kurdish, and Turkish). The figure showcases the ability of each model to generate images reflecting the style and details described by the prompt, even across different languages. The comparison allows a visual evaluation of each model’s proficiency in multilingual understanding and image generation.

This figure displays the results of text-to-image generation experiments using three different models: Lumina-Next, PixArt-a, and SDXL. Each model was prompted with sentences containing emojis to test their ability to generate images that accurately reflect both the text and the emoji’s meaning. The results demonstrate the varying capabilities of each model in understanding and incorporating the emojis into their generated images, highlighting differences in style, detail, and accuracy.

This figure showcases the results of multilingual text-to-image generation using three different large language models (LLMs) as text encoders: Gemma-2B, InternLM-7B, and Qwen-1.8B. Each LLM is used to generate images from the same set of prompts written in various languages. The purpose is to demonstrate the impact of different LLMs on the quality and cultural nuances of the generated images, highlighting the relationship between the LLM’s capabilities and the resulting image generation.

This figure compares the performance of Lumina-Next, SDXL, PixArt-α, MultiDiffusion, and DemoFusion on 4x resolution extrapolation. It showcases generated images from each method at a higher resolution than the models were originally trained on, demonstrating the relative strengths and weaknesses of each approach in handling high-resolution generation. Lumina-Next appears to show the highest quality and detail in the extrapolations.

This figure showcases example images generated by Lumina-Next using long and detailed prompts. The prompts are provided in multiple languages (English, Chinese) and demonstrate the model’s ability to generate high-quality images that accurately reflect the specific details described in the prompts, even with complex scenes and descriptions.
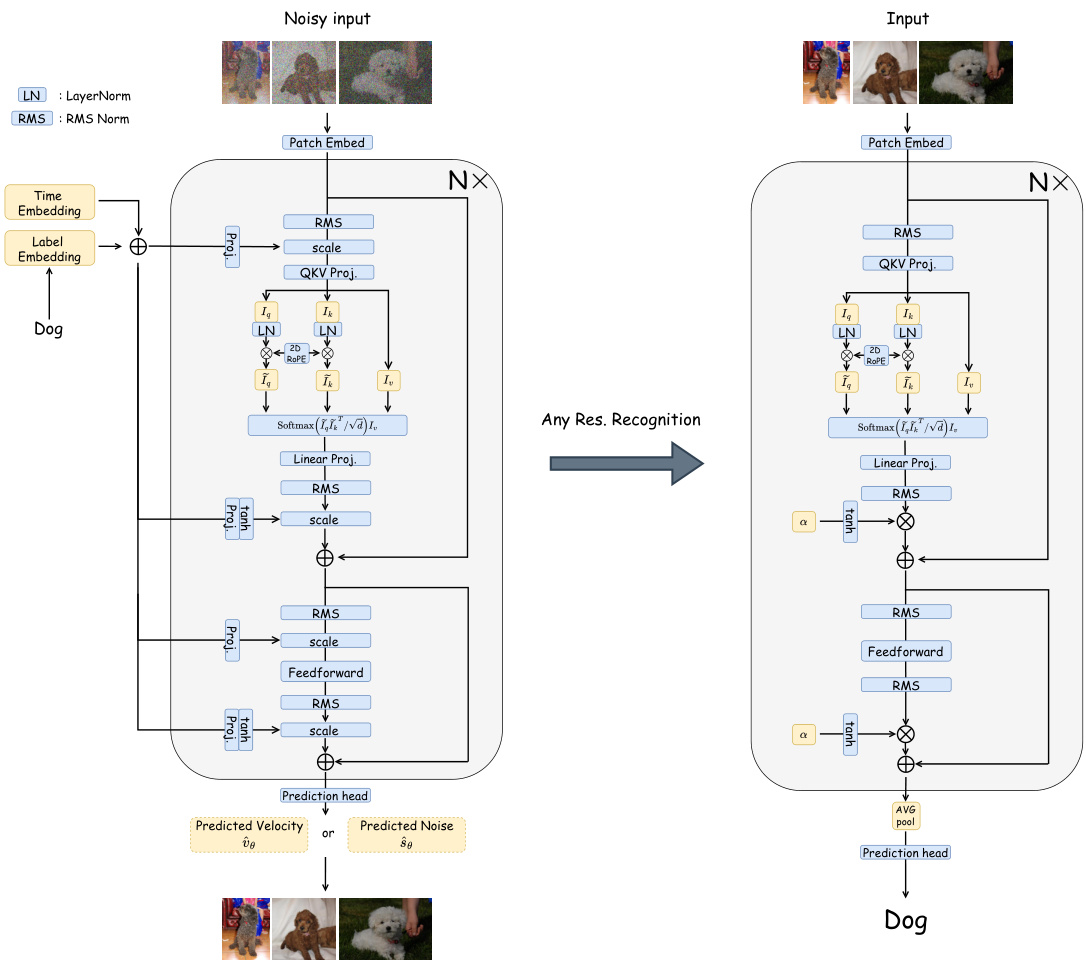
This figure shows a detailed comparison of the architectures of Flag-DiT (the original Lumina-T2X architecture) and Next-DiT (the improved architecture in Lumina-Next). It highlights key differences and improvements made in Next-DiT, such as the replacement of 1D ROPE with 3D ROPE, the addition of sandwich normalization blocks, and the use of grouped-query attention. The figure illustrates the flow of information through each architecture, detailing the processing steps involved in generating images.

This figure illustrates the method used to handle images of various resolutions and aspect ratios. The input images are dynamically partitioned into patches, and padding is applied to ensure consistent sequence lengths. Masked attention is then used to prevent unwanted interactions between padded tokens and actual image tokens. This dynamic approach is crucial for efficient training and inference with images of varying sizes.
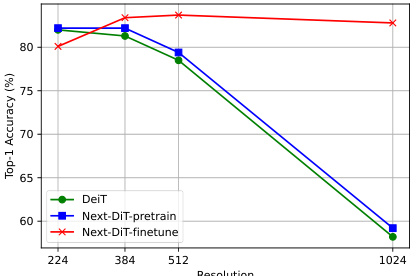
The figure shows the performance of the Next-DiT model on image classification across different resolutions (224, 384, 512, and 1024). It demonstrates that Next-DiT generalizes better to larger image sizes compared to DeiT-base, even without fine-tuning, and significantly improves performance with fine-tuning, especially at higher resolutions. This highlights Next-DiT’s ability to handle varied resolutions effectively.
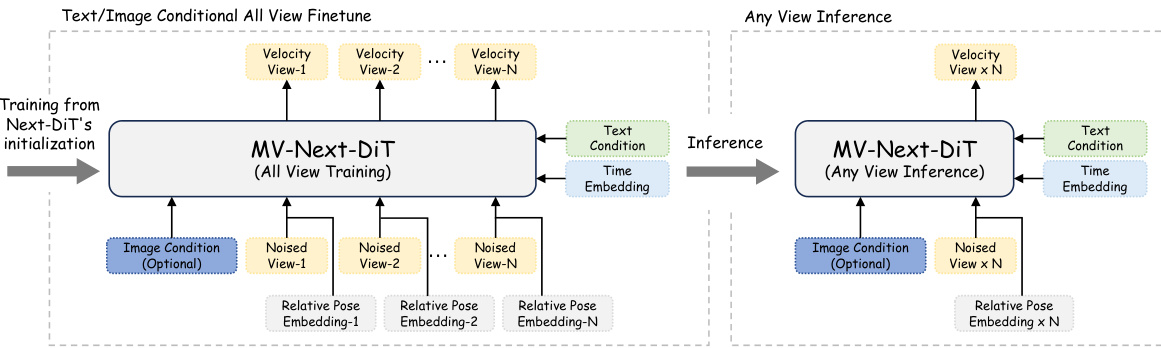
This figure illustrates the training and inference processes of the MV-Next-DiT model for multi-view image generation. The left side shows the training process where all views are trained simultaneously. This involves feeding multiple noisy views into the model along with text and optional image condition information, leveraging relative pose embeddings to capture the relationships between the views. The right side depicts the inference process, where only a text condition and an optional image condition are inputted, and the model generates a specified number of views using the learned relationships between them. The architecture highlights the flexibility of the model to generate any number of views during inference based on the training from all views.

This figure demonstrates the results of multi-view image generation using MV-Next-DiT. The top-right shows results from text-only input, while the rest show results from both image and text input. Each set of three rows shows generation results with 4, 6, and 8 views respectively. The first column in each set displays the input image used for the generation.
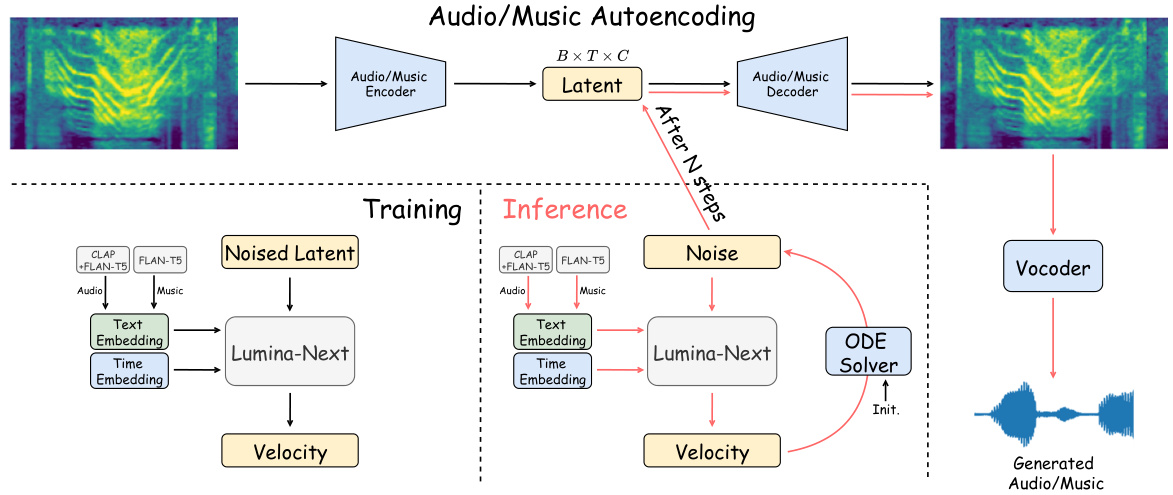
This figure illustrates the architecture of the text-guided music/audio generation model. The process involves encoding the audio spectrogram into a latent representation using a Variational Autoencoder (VAE). This latent representation, along with text embeddings (from CLAP and FLAN-T5 encoders) and time embeddings, is fed into Lumina-Next, which outputs the predicted velocity for the latent space. This velocity is then used by an ODE solver to iteratively refine the latent representation, ultimately producing a noise-free latent representation. Finally, a separate audio decoder reconstructs the audio waveform from the refined latent representation using a vocoder.
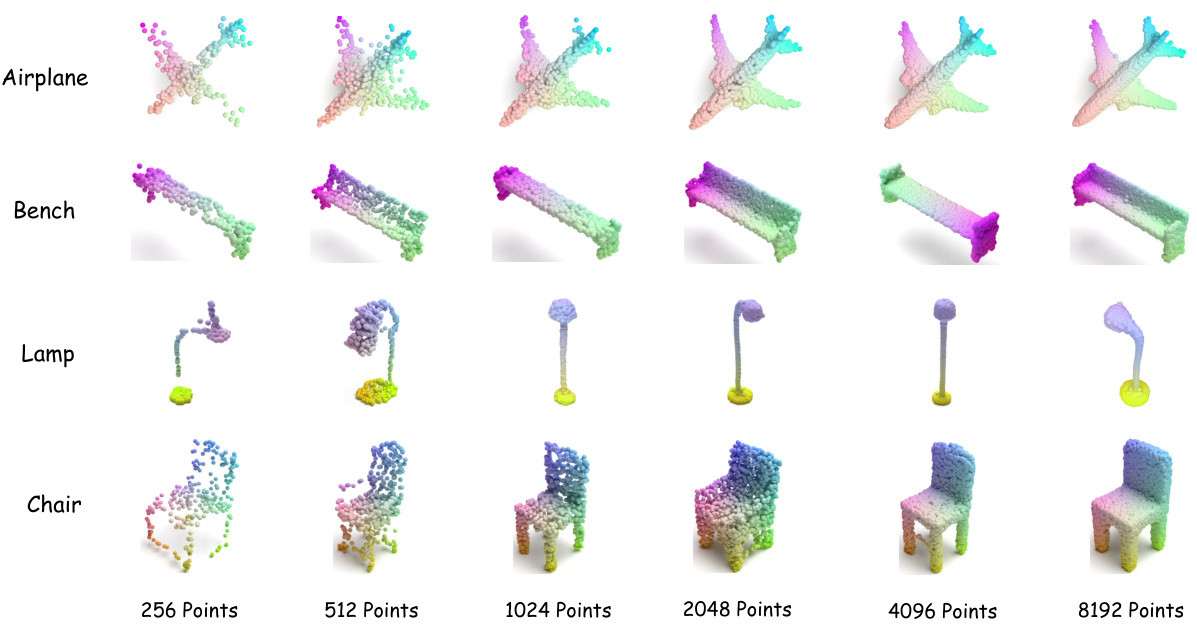
This figure shows examples of point clouds generated by the model, demonstrating its ability to generate point clouds with varying densities (number of points). The examples are for four different object categories: airplane, bench, lamp, and chair. Each row displays point clouds of the same object but with progressively increasing point density, illustrating how the model’s output changes from a sparse representation to a detailed and higher-fidelity depiction of the object as the point count increases.
More on tables

This table details the training settings used for the MV-Next-DiT model. It breaks down the training process into three stages, each with varying image resolutions and the number of views (N). For each stage, it provides information on the pre-training model used, the total number of image batches processed, the learning rate, the number of training iterations, and the computational resources (A100 GPUs and hours) required. This allows readers to understand the computational cost and the progression of the training pipeline used to develop the multi-view image generation model.

This table compares the capabilities of MV-Next-DiT with other existing multi-view generation methods. It shows the base model used, the resolution of the generated images, the type of conditioning (text or image), and the number of inference views each method can generate.

This table presents a comparison of the proposed text-to-music generation model’s performance against several baseline models on the MusicCaps Evaluation dataset. The objective metrics used for comparison are the FAD (Fréchet Audio Distance) and KL (Kullback-Leibler) divergence, which measure the difference between generated audio and ground truth audio. Lower values indicate better performance. Subjective metrics include MOS-Q (Mean Opinion Score for Quality) and MOS-F (Mean Opinion Score for Faithfulness), assessing the perceived audio quality and the alignment between the generated audio and its text prompt; higher values are preferred. Note that the results for Mousai, Melody, and MusicLM were taken from the MusicGen paper.
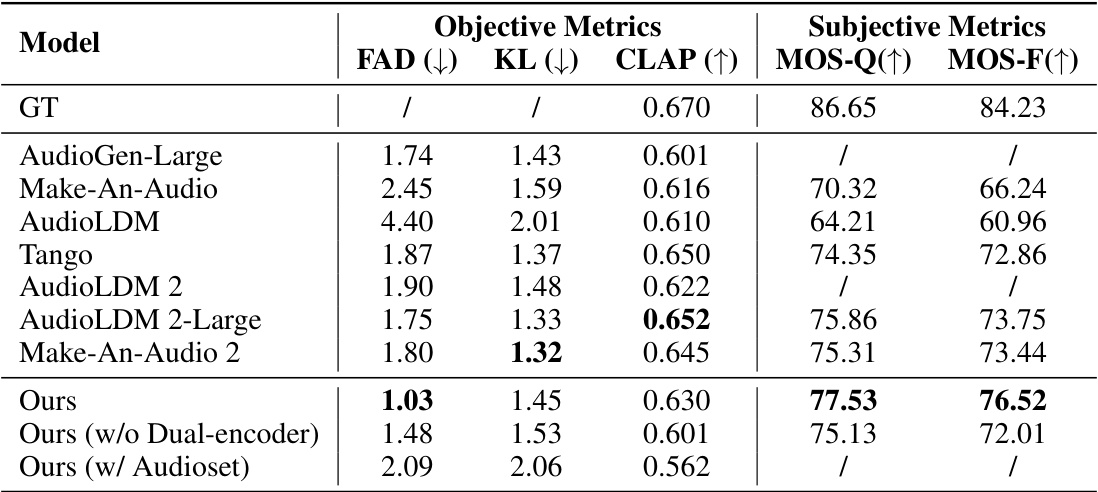
This table presents the results of ablation studies conducted on the Lumina-Next model. It compares the performance of the Next-DiT model (with the proposed architecture) against variations: removing the dual-encoder, using only the Audioset dataset for training, and using a different model architecture (DiT using DDPM formulation). The metrics used for comparison are FAD (Fréchet Audio Distance), KL (Kullback-Leibler divergence), and CLAP (CLIP score). Lower FAD and KL values indicate better audio generation quality, while a higher CLAP score implies better alignment between generated audio and text captions.
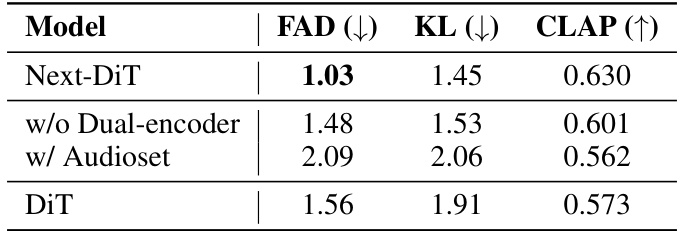
This table presents the ablation study results for the Lumina-Next model. It compares the performance of the Next-DiT model against variations where components are removed or altered: removing the dual encoder, training only with Audioset, and using the DDPM formulation instead of the flow matching method. The results are evaluated using FAD, KL, and CLAP metrics, showing the impact of the different components on the model’s overall performance.

This table presents a quantitative comparison of different point cloud generation models. The models are evaluated using three metrics: Minimum Matching Distance (MMD), Coverage (COV), and Chamfer Distance (CD). Lower MMD values indicate better performance. Higher COV values represent a higher proportion of correctly generated points. The table compares the performance of the proposed model (‘Ours’) against several existing models (PC-GAN, TreeGAN, PointFlow, ShapeGF, and PDiffusion) for two different shapes: Airplane and Chair.
Full paper#



















