↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Traditional open-world 3D representation learning methods struggle with the realism and texture variations of CAD-rendered images used for image-text alignment. This often compromises the robustness of alignment and limits the transfer of representational abilities from 2D to 3D learning. The volume discrepancy between 2D and 3D datasets further highlights the need for innovative strategies.
OpenDlign tackles these issues by introducing depth-aligned images generated by a diffusion model. These images exhibit greater texture diversity, resolving the realism issue. By refining depth map projection and designing depth-specific prompts, OpenDlign leverages pre-trained VLMs for 3D representation learning with streamlined fine-tuning. Experiments show significantly improved zero-shot and few-shot performance on various 3D tasks, surpassing previous state-of-the-art methods.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly improves open-world 3D understanding, a crucial area in many applications. The introduction of depth-aligned images offers a robust solution to the limitations of existing CAD-rendered images, paving the way for more realistic and accurate 3D representation learning. This approach has the potential to improve performance across various 3D tasks, including classification, detection, and retrieval, and opens new avenues for research into multimodal alignment and continual learning. The work is also relevant to the ongoing trend of leveraging vision-language models for 3D understanding.
Visual Insights#
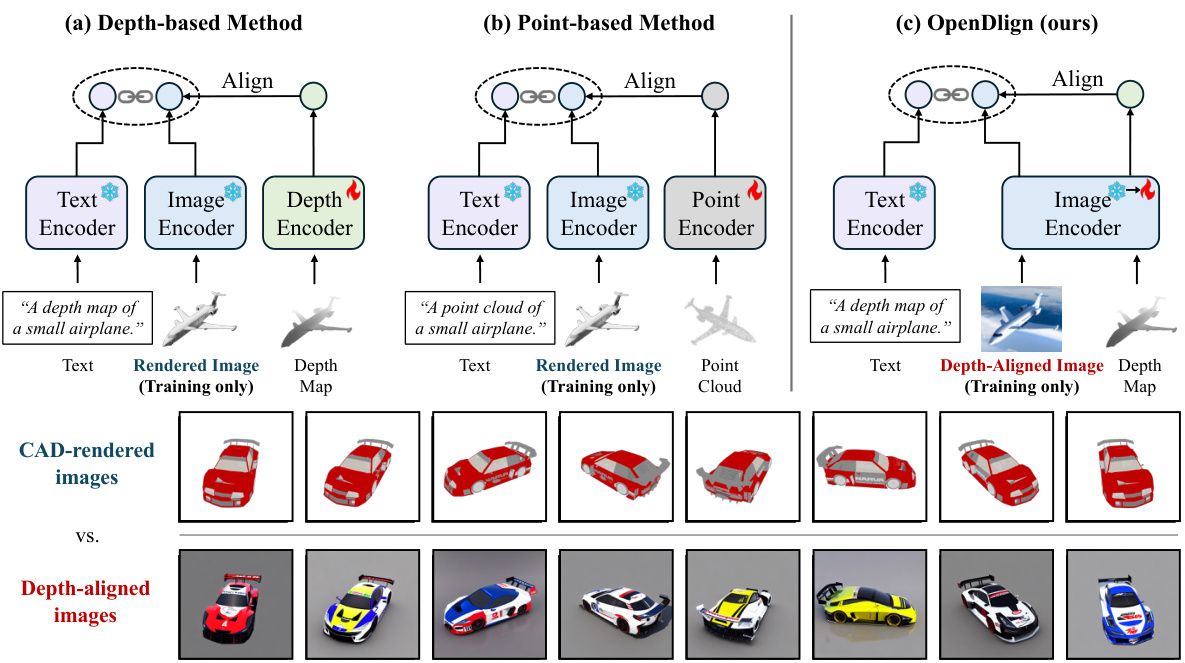
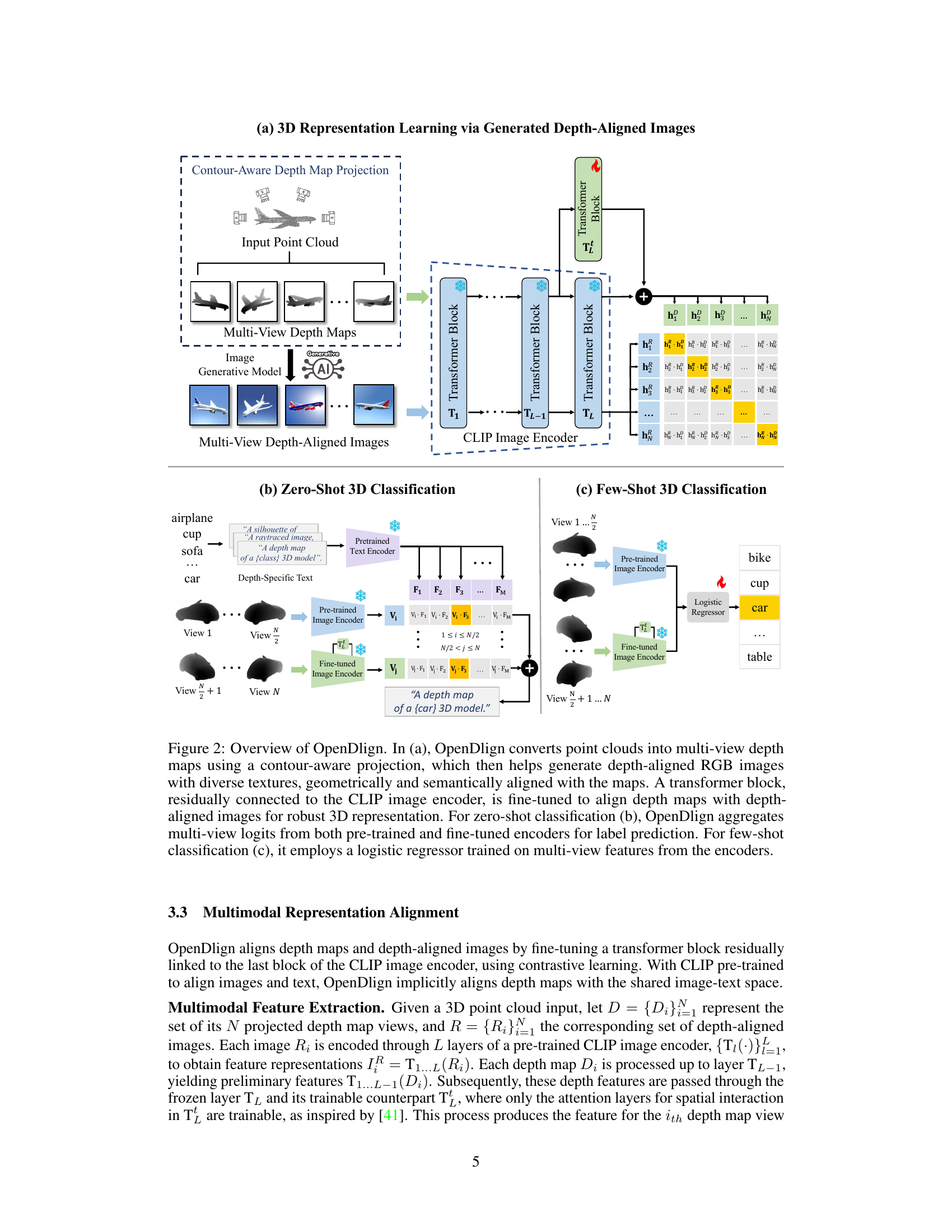
This figure compares OpenDlign with traditional depth-based and point-based open-world 3D learning methods. It highlights that OpenDlign uses depth-aligned images instead of CAD-rendered images, resulting in improved 3D representation learning by fine-tuning only the image encoder. The bottom part visually demonstrates the difference in texture and realism between CAD-rendered and depth-aligned images.
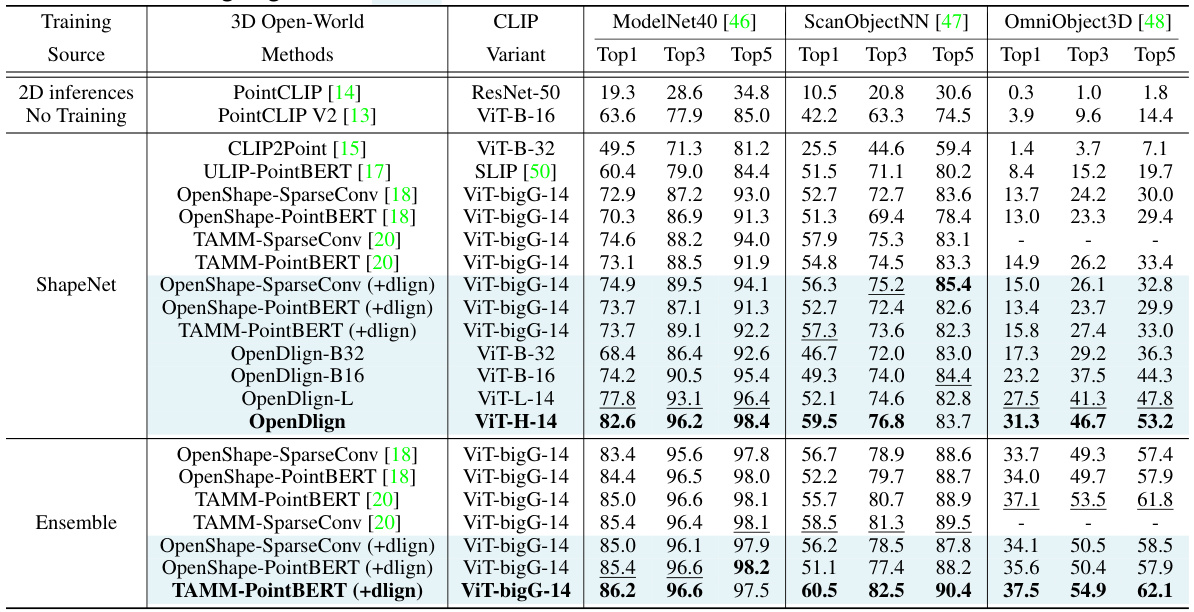
This table presents a comparison of the zero-shot classification performance of OpenDlign against several state-of-the-art models on three benchmark datasets: ModelNet40, ScanObjectNN, and OmniObject3D. The results show Top-1, Top-3, and Top-5 accuracy for each method, highlighting OpenDlign’s superior performance, especially in the OmniObject3D dataset.
In-depth insights#
Depth-Aligned Images#
The concept of “Depth-Aligned Images” presents a novel approach to bridging the gap between 2D vision-language models and 3D data. Instead of relying on less realistic CAD-rendered images, this method leverages a diffusion model to generate synthetic images that are closely aligned with depth maps derived from point clouds. This strategy offers several key advantages. First, the inherent stochasticity of the diffusion process produces images with greater texture variability and realism, leading to more robust multimodal alignment. Second, by aligning images to depth maps, the method explicitly leverages the rich geometric information present in 3D data rather than relying solely on the visual appearance that CAD models might lack. This closer alignment to the underlying 3D structure potentially improves the transferability of knowledge from pre-trained 2D models and reduces the reliance on large 3D training datasets. Finally, depth-specific prompts help further guide the image generation process, ensuring that the generated images are truly representative of the underlying 3D scene, further enhancing the overall effectiveness and generalizability of the approach.
CLIP Encoder Tuning#
CLIP Encoder Tuning represents a significant advancement in open-world 3D representation learning. Instead of training separate 3D encoders, which often suffer from data limitations, this approach leverages the power of pre-trained CLIP’s image encoder. This is particularly beneficial because CLIP has been trained on massive image-text datasets, providing a rich, transferable knowledge base. Fine-tuning only a subset of the CLIP encoder’s parameters allows for efficient adaptation to the 3D domain, avoiding the computational expense and potential overfitting of training a large 3D encoder from scratch. This streamlined approach allows for robust multimodal alignment, effectively bridging the gap between 2D image and text features from CLIP and 3D point cloud data. The focus on aligning depth-aligned images with corresponding depth maps significantly improves the performance compared to previous methods that relied on CAD-rendered images, which often lack the realism and textural diversity required for effective multimodal alignment. This innovative use of CLIP demonstrates that effective 3D representation learning can be achieved with minimal modification of well-established 2D models, demonstrating the power of transfer learning in this field and paving the way for more efficient and effective open-world 3D models.
Open-World 3D Models#
Open-world 3D models represent a significant advancement in 3D computer vision, addressing the limitations of traditional closed-world approaches. Closed-world models are trained on a fixed set of categories and struggle with unseen objects. In contrast, open-world models aim for generalization, enabling them to handle novel objects and categories without retraining. This is particularly crucial for real-world applications where the diversity of objects is vast and unpredictable. Several strategies have been explored to achieve open-world capabilities, including leveraging Vision-Language Models (VLMs) to incorporate semantic knowledge from image-text pairings. However, challenges remain, such as the domain gap between synthetic data and real-world scenarios, and the need for efficient knowledge transfer between VLM pre-training and 3D model fine-tuning. Robust multimodal alignment techniques are essential to bridge the gap between 2D image representations from VLMs and 3D point cloud data. Future research will likely focus on creating more realistic and diverse training data, exploring more effective multimodal alignment strategies, and developing novel architectures tailored for open-world 3D understanding.
Zero-Shot 3D Tasks#
The concept of “Zero-Shot 3D Tasks” in the context of a research paper likely explores the ability of a model to perform 3D understanding tasks without explicit training on those specific tasks. This is a significant advancement in AI, as it suggests the model has learned generalizable representations of 3D data that can be transferred to new, unseen tasks. The core challenge lies in representing and reasoning about 3D data in a way that allows for generalization. This often involves techniques like multimodal learning (combining images, point clouds, and text), which enables richer context for the model to understand 3D scenes. A successful zero-shot approach would demonstrate robustness to variations in viewpoint, object appearance, and data modalities. The paper likely evaluates its model’s performance on various standard benchmarks for 3D object classification, scene segmentation, and object detection, comparing results to existing state-of-the-art approaches. Key performance indicators would include accuracy, precision, and recall. The success of such a model highlights progress towards truly intelligent 3D understanding systems, paving the way for broader applications in robotics, AR/VR, and autonomous driving. Addressing the limitations of existing zero-shot approaches, such as handling unseen object categories or managing the complexity of 3D data, would be crucial in the paper’s analysis.
Future Research#
The paper’s conclusion suggests several promising avenues for future work. Extending OpenDlign to handle 3D scenes rather than isolated objects is a significant challenge, requiring efficient processing of vastly larger point clouds and the generation of numerous depth-aligned images. Investigating different diffusion models beyond ControlNet could yield improvements in image quality and diversity. Addressing potential biases inherent in pre-trained models like CLIP is crucial for ensuring fair and unbiased 3D representations. The authors also point to the need for a more robust and efficient method to filter low-quality depth-aligned images, improving overall model performance. Finally, exploring the application of depth-aligned images to other open-world 3D learning tasks beyond those tested (classification, detection, retrieval) could reveal additional benefits and demonstrate the broader applicability of this approach.
More visual insights#
More on figures
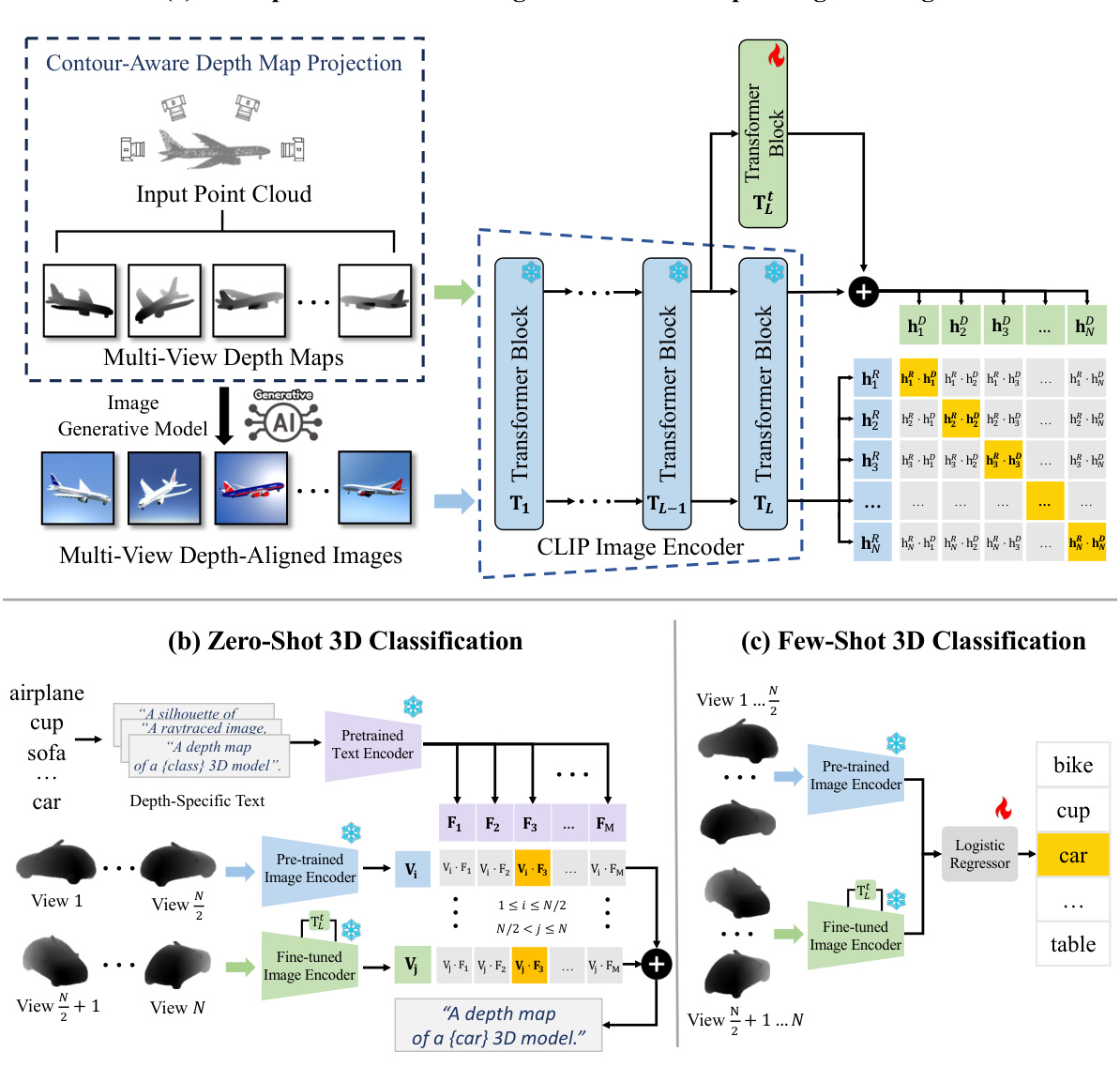
This figure provides a comprehensive overview of the OpenDlign framework. It illustrates the process of converting point clouds into depth maps, generating depth-aligned images, aligning features using a fine-tuned transformer block, and performing both zero-shot and few-shot 3D classifications.

This figure compares OpenDlign with traditional depth-based and point-based open-world 3D learning models. It highlights that OpenDlign uses depth-aligned images generated by a diffusion model for robust multimodal alignment, instead of CAD-rendered images, to fine-tune only the image encoder and improve 3D representation. The bottom part visually shows the difference between multi-view CAD-rendered and depth-aligned images.
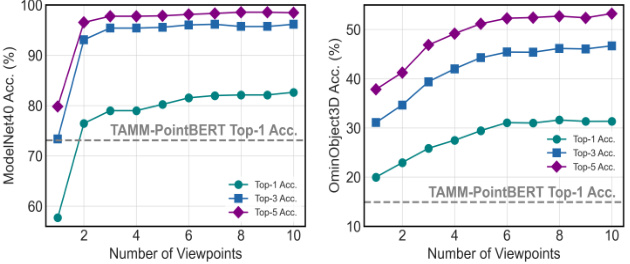
This figure shows the impact of the number of viewpoints used for generating depth maps on the zero-shot classification accuracy of OpenDlign. The results are presented for two different datasets: ModelNet40 (left) and OmniObject3D (right). The plots show Top-1, Top-3, and Top-5 accuracy for each dataset, as the number of viewpoints increases from 1 to 10. A dashed horizontal line indicates the Top-1 accuracy achieved by TAMM-PointBERT, a state-of-the-art model, providing a basis for comparison.

This figure compares OpenDlign’s architecture with traditional depth-based and point-based open-world 3D learning methods. It highlights OpenDlign’s key advantage: using a diffusion model to generate realistic depth-aligned images instead of relying on less-realistic CAD-rendered images. This improves alignment robustness and avoids needing extra encoders. The bottom part visually demonstrates the difference in texture and realism between CAD-rendered and the depth-aligned images used in OpenDlign.
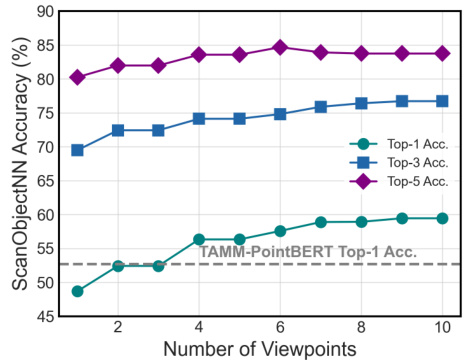
This figure shows the impact of the number of viewpoints used in OpenDlign on the zero-shot classification accuracy for the ScanObjectNN dataset. It presents three lines representing top-1, top-3, and top-5 accuracy, plotted against the number of viewpoints (ranging from 1 to 10). A horizontal dashed line indicates the top-1 accuracy achieved by the TAMM-PointBERT model, a state-of-the-art baseline. The figure demonstrates that OpenDlign’s accuracy improves consistently as the number of viewpoints increases, surpassing the TAMM-PointBERT baseline with as few as two viewpoints.

This figure compares the depth maps generated using PointCLIP V2’s projection method and the contour-aware projection method proposed in the paper. It shows that the PointCLIP V2 projection results in blurry depth maps with missing contour and shape details, whereas the contour-aware projection method preserves more of the original objects’ contours and structures.

This figure demonstrates the cross-modal retrieval capabilities of OpenDlign. It shows examples of retrieving 3D shapes based on image queries, text queries, and combined image and text queries. The results highlight OpenDlign’s ability to find shapes that semantically match different query types, showcasing its effectiveness in understanding the relationships between images, text, and 3D shapes.

This figure shows examples of depth-aligned images generated by the diffusion model that are of low quality. The issues include unrealistic renderings, such as a person inside a monitor, a stone washing machine, or a tent floating in the air. These examples highlight the challenge of generating high-quality, realistic depth-aligned images, which is crucial for the success of OpenDlign’s multimodal alignment approach. The low-quality examples show some of the difficulties in controlling the diffusion process to produce only suitable images and the need for filtering to eliminate these low-quality images in order to improve the performance of OpenDlign.
More on tables

This table presents the few-shot classification results obtained by OpenDlign and other state-of-the-art models on three benchmark datasets: ModelNet40, ScanObjectNN, and OmniObject3D. The results are averaged over 10 different random seeds to provide a more robust statistical measure of performance. The table shows the accuracy achieved using different numbers of training shots (1-shot, 2-shot, 4-shot, 8-shot, 16-shot). This allows for a comparison of the models’ ability to generalize to unseen data when provided with limited training examples.

This table presents the results of a zero-shot 3D object detection experiment conducted using the ScanNet V2 dataset. The experiment compared three different methods: PointCLIP [14], PointCLIP V2 [13], and the proposed OpenDlign method. The results are reported as mean Average Precision (mAP) at Intersection over Union (IoU) thresholds of 0.25 and 0.5. The table shows the mAP for each of the 18 object categories in the ScanNet dataset, as well as the overall mean AP across all categories. OpenDlign demonstrates a significant improvement in performance compared to the other two methods.
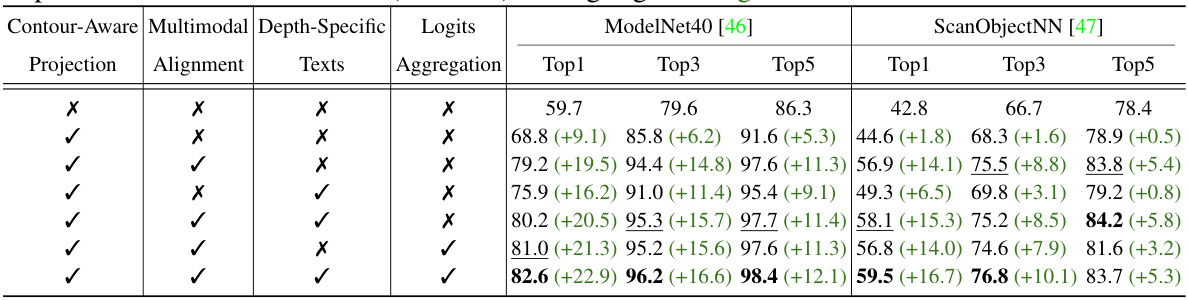
This ablation study analyzes the contribution of each component in the OpenDlign model. It shows the impact of using contour-aware projection, multimodal alignment with depth-aligned images, depth-specific texts, and logits aggregation on the classification accuracy for ModelNet40 and ScanObjectNN datasets. The results are presented as Top1, Top3, and Top5 accuracy, with improvements over the baseline indicated in green.

This ablation study analyzes the impact of different components of the OpenDlign model on its performance in zero-shot classification. It compares several variations, altering contour-aware projection, the strategy used for multimodal alignment (depth-aligned images versus CAD-rendered images and different text prompt strategies), and the method of logits aggregation. The results show the contribution of each element to the final accuracy and highlight the benefits of using depth-aligned images for robust multimodal alignment. Improvements over a baseline configuration are highlighted in green.

This table presents a comparison of the zero-shot classification performance of OpenDlign against other state-of-the-art models on three benchmark datasets: ModelNet40, ScanObjectNN, and OmniObject3D. The results are categorized by the 3D model used and include Top1, Top3, and Top5 accuracy scores. OpenDlign’s performance is highlighted, showing its superior accuracy compared to existing methods.

This table presents the zero-shot classification results on the Objaverse-LVIS dataset, a challenging long-tailed dataset containing 1,156 categories of 3D objects. The table compares the performance of OpenDlign against several existing state-of-the-art open-world 3D models. The results are categorized by the training source (2D inferences or ShapeNet) and CLIP variants used. OpenDlign consistently outperforms the other methods across various CLIP variants, highlighting its superior performance on this challenging dataset.
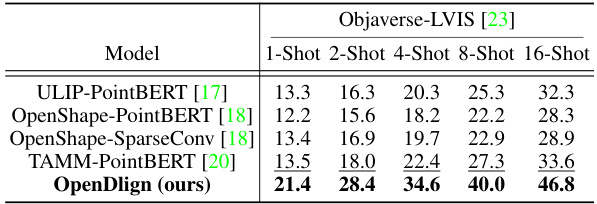
This table presents the few-shot classification results of OpenDlign and other state-of-the-art models on the Objaverse-LVIS dataset. The results are shown for different numbers of training examples per class (1-shot, 2-shot, 4-shot, 8-shot, and 16-shot). OpenDlign consistently outperforms the baselines across all scenarios.
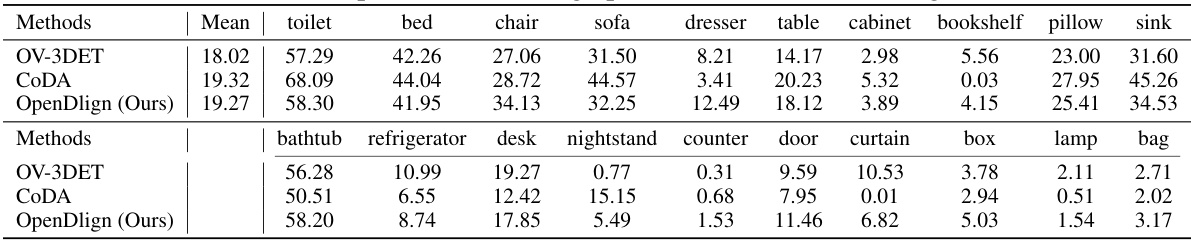
This table presents the results of a zero-shot 3D object detection experiment conducted on the ScanNet V2 dataset. The experiment evaluates the performance of the OpenDlign model and compares it against two other methods (PointCLIP and PointCLIP V2). The table shows the mean Average Precision (mAP) at Intersection over Union (IoU) thresholds of 0.25 and 0.5 for each of the 18 object categories in the ScanNet dataset. Higher mAP values indicate better performance.
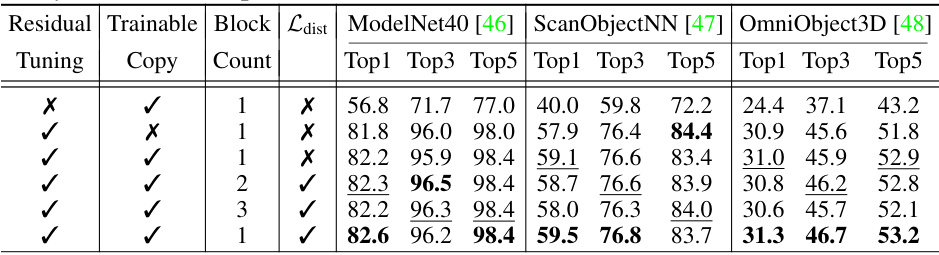
This ablation study analyzes the contribution of each component in OpenDlign towards improving the accuracy of zero-shot classification on ModelNet40 and ScanObjectNN datasets. It systematically removes or modifies different parts of the OpenDlign pipeline (contour-aware projection, multimodal alignment with depth-aligned images, depth-specific texts, and logits aggregation) to assess their individual impact on the overall performance. The results quantify the improvement brought by each component compared to a baseline configuration and are presented as percentage increases in Top1, Top3, and Top5 accuracy.
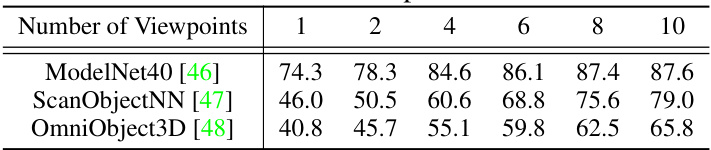
This table shows the effect of varying the number of viewpoints used in OpenDlign’s few-shot (16-shot) classification experiments. It presents the Top-1 accuracy results on three benchmark datasets: ModelNet40, ScanObjectNN, and OmniObject3D, for different numbers of viewpoints ranging from 1 to 10. The results demonstrate the impact of using multiple views on the performance of the model.
Full paper#