↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current state-of-the-art methods for Transformer-based semantic segmentation rely on complex, empirically designed decoders lacking theoretical justification. This limits potential improvements. This paper argues that there’s a fundamental connection between semantic segmentation and compression, particularly between Transformer decoders and Principal Component Analysis (PCA).
The researchers introduce DEPICT, a white-box, fully-attentional decoder derived by unrolling the optimization of PCA objectives in terms of coding rate. DEPICT refines image embeddings to construct an ideal principal subspace, finds a low-rank approximation of these embeddings (corresponding to predefined classes), and generates segmentation masks through a dot-product. Experiments show DEPICT consistently outperforms its black-box counterpart, being lightweight and robust.
Key Takeaways#
Why does it matter?#
This paper is crucial because it offers a novel perspective on Transformer decoders for semantic segmentation, moving beyond empirical designs to a principled, white-box approach based on compression. This bridges the gap between empirical success and theoretical understanding, opening new avenues for improvement and innovation in the field. It also introduces a new, efficient white-box decoder (DEPICT) which outperforms its black-box counterpart.
Visual Insights#
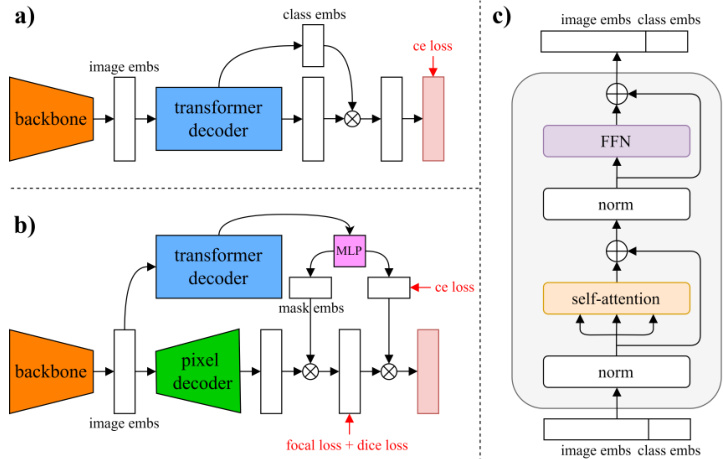
This figure compares two state-of-the-art Transformer-based semantic segmentation methods: Segmenter and MaskFormer. It highlights the architectural differences in their decoder designs. Segmenter uses a transformer decoder that processes image embeddings and class embeddings through cross-attention, self-attention, and finally a dot product to generate segmentation masks. MaskFormer employs a similar strategy but adds a pixel decoder and handles mask embeddings differently. Subfigure (c) provides a detailed view of the transformer block within the Segmenter architecture.
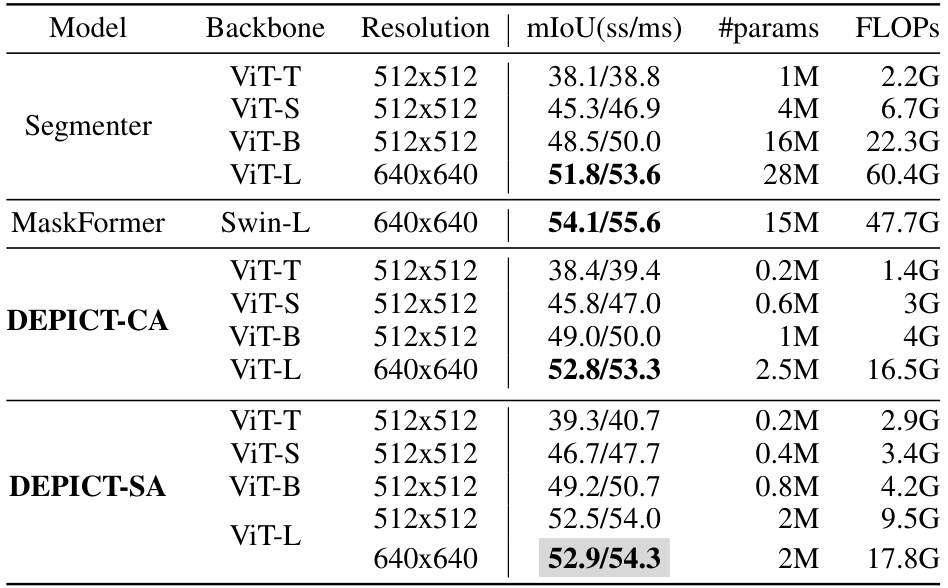
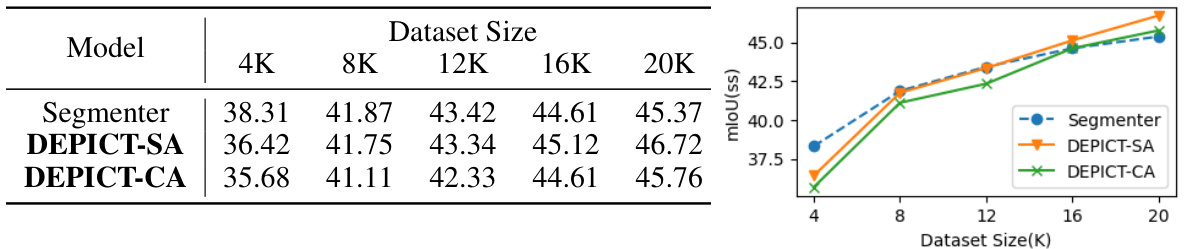
This table presents a comparison of the performance of the proposed DEPICT model against two state-of-the-art models, Segmenter and MaskFormer, on the ADE20K validation set. The comparison is based on the mean Intersection over Union (mIoU), the number of parameters, and the number of floating-point operations (FLOPs). Different variants of each model, using various Vision Transformers (ViT) backbones and resolutions are included in the comparison. The table highlights the best performing DEPICT variant for each backbone and resolution.
In-depth insights#
Decoder Rethinking#
Rethinking decoder design in the context of transformer-based semantic segmentation is a crucial step towards improving model performance and interpretability. Traditional decoder architectures often rely on heuristic combinations of self-attention and cross-attention mechanisms, lacking a clear theoretical grounding. A principled rethinking should move beyond empirical design choices, focusing instead on the underlying mathematical principles governing semantic segmentation. This might involve exploring connections to information theory, dimensionality reduction techniques like PCA, or other formal frameworks for understanding how transformers process information spatially. A key focus should be on enhancing the interpretability of the decoder, allowing researchers to better understand how the model arrives at its segmentation output, and thereby facilitating the identification of potential biases or weaknesses. Furthermore, a successful rethinking would prioritize efficiency, aiming to reduce computational cost without sacrificing performance. This might necessitate exploring alternative architectures, optimized algorithms, or approximations of existing methods. By fundamentally reconsidering the decoder’s role and functionality within the broader semantic segmentation task, we can pave the way for more robust, efficient, and explainable models.
PCA-Inspired Design#
The concept of a ‘PCA-Inspired Design’ in a research paper likely revolves around leveraging the principles of Principal Component Analysis (PCA) to guide the design and architecture of a system or model. This approach likely aims to create a more efficient and interpretable model by reducing dimensionality and focusing on the most informative features. The authors might draw parallels between PCA’s ability to find optimal low-dimensional representations of high-dimensional data and the need to design models that capture essential information effectively. A key aspect of a PCA-inspired design would be its explicit focus on feature extraction, perhaps employing self-attention mechanisms to learn and refine a principal subspace. By aligning model parameters with the principal components identified by PCA, researchers could potentially improve performance, interpretability, and robustness. The design might also include techniques to optimize and refine this principal subspace during training, making it more adaptive to the specific task. Finally, a PCA-inspired approach can provide theoretical justifications and interpretations for the model’s architecture and functionality, which might otherwise lack such grounding in empirical designs.
Attention Unrolled#
The concept of “Attention Unrolled” suggests a methodology where complex attention mechanisms, typically found in deep learning models like Transformers, are systematically broken down and analyzed step-by-step. This unrolling process reveals the internal operations and dependencies within the attention mechanism, offering valuable insights into its behavior and performance. By explicitly detailing each step, researchers can better understand how intermediate representations evolve, how information flows across different parts of the input, and how the final attention weights are determined. This approach is particularly useful for improving the interpretability of these often opaque models. Furthermore, understanding the unrolled steps enables the development of more efficient and tailored attention architectures, possibly leading to innovations in model design and optimization. Identifying bottlenecks or inefficiencies within the unrolled sequence allows for targeted improvements, resulting in faster training times and enhanced accuracy. Ultimately, “Attention Unrolled” represents a powerful technique for dissecting and enhancing the capabilities of attention mechanisms, bridging the gap between theoretical understanding and practical application.
DEPICT: A Whitebox#
The heading “DEPICT: A Whitebox” suggests a research paper focusing on the creation and evaluation of a novel model, DEPICT, designed for interpretability and transparency. Unlike many “black box” models where internal processes are opaque, DEPICT aims for a “white box” architecture, allowing researchers to understand its decision-making process. This approach is crucial for building trust and enabling further improvements, as it facilitates debugging, bias detection, and the identification of potential failure points. The paper likely demonstrates how DEPICT achieves superior performance compared to existing models while maintaining its explainability, potentially through novel architectural choices or training techniques. The “white box” nature is a significant advantage, providing valuable insights into the model’s behavior and its suitability for applications demanding high transparency and accountability. The success of DEPICT would underscore the growing importance of developing explainable AI models, especially in critical domains like healthcare and finance, where trust and understanding of decision-making processes are paramount.
Future Compression#
Future research in compression could explore several exciting avenues. Improving the efficiency and scalability of existing compression algorithms is crucial for handling ever-growing datasets. This includes developing novel techniques for lossy compression that minimize information loss while maximizing compression ratios. The development of new theoretical frameworks that provide a deeper understanding of the fundamental limits of compression and the trade-offs between compression ratio, computational cost, and information fidelity is essential. Integrating advanced machine learning methods could lead to the development of adaptive compression algorithms that optimize compression based on the characteristics of the data being compressed. Exploring new types of compression beyond traditional methods is another avenue for future work. This could include exploring the use of quantum computing or novel mathematical techniques. Ultimately, the future of compression lies in the ability to create more powerful and versatile tools that are capable of efficiently handling the deluge of information generated daily.
More visual insights#
More on figures
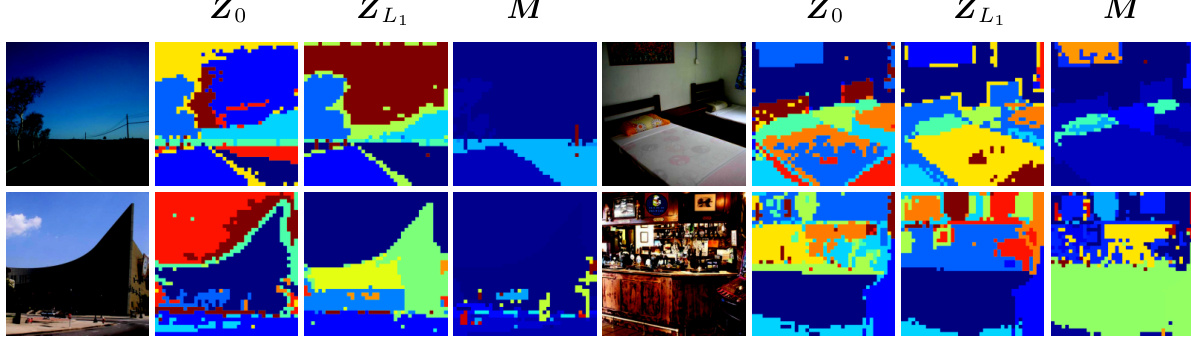
This figure compares image segmentation results using Principal Component Analysis (PCA) and the proposed DEPICT method. Two example images are shown, each with segmentation results from PCA applied to both the initial (Z0) and refined (ZL1) image embeddings. The results illustrate how PCA, particularly when applied to refined embeddings (ZL1), can effectively segment images, while applying PCA to the raw embeddings (Z0) leads to over-segmentation. The figure highlights that DEPICT improves upon PCA by creating an ideal principal subspace. Each column represents a different image with corresponding initial and refined embeddings and segmentation maps.
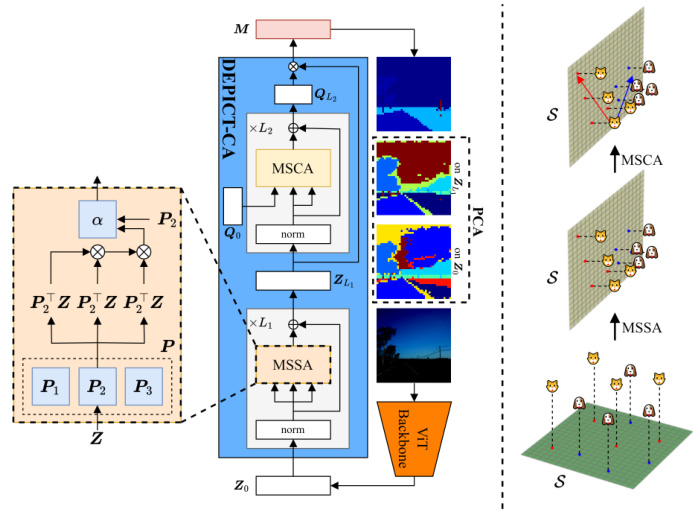
This figure illustrates the DEPICT model’s architecture and workflow. It begins with a ViT backbone processing the input image to produce image embeddings (Zo). PCA is initially performed on Zo, revealing that the principal subspace (S) is not ideal for effective segmentation. The model then iteratively refines these embeddings using the Multi-head Subspace Self-Attention (MSSA) operator, creating an improved principal subspace. After this refinement, a second PCA on the refined embeddings (ZL1) is performed. Finally, the model utilizes the Multi-head Subspace Cross-Attention (MSCA) operator to project the refined embeddings onto a low-rank approximation within the ideal subspace, resulting in compact class representations that facilitate effective classification and segmentation. The example with dogs and cats visually demonstrates how DEPICT transforms initially overlapping class representations into linearly separable ones.
This figure compares image segmentation results using Principal Component Analysis (PCA) and the proposed DEPICT method. PCA is applied to both the initial image embeddings (Zo) and the refined embeddings (ZL1) produced by the DEPICT model. The results show that PCA, when used on the refined embeddings (ZL1), is effective for image segmentation. However, applying PCA directly to the initial embeddings (Zo) leads to over-segmentation. This suggests that the DEPICT’s refinement process constructs an improved principal subspace.

This figure visualizes the orthogonality of the parameter matrices P and Q in the DEPICT model, comparing it to the Segmenter model. The left side shows the inner product of matrix P with its transpose (PTP), representing the self-attention operator’s parameter matrix, while the right side shows the inner product of matrix Q with its transpose (QTQ), representing the cross-attention operator’s parameter matrix. The visualization highlights the near-orthogonality of Q in DEPICT, indicating its desirable properties, in contrast to Segmenter.

This figure shows the inner product of the parameter matrices P and Q for different variants of DEPICT, demonstrating their orthogonality. The left panel displays the inner product of P (matrix responsible for transforming keys), while the right panel illustrates the inner product of Q (class embeddings). The results indicate that both P and Q tend towards orthogonality, especially Q, which is normalized, showcasing the desirable property derived in the model’s theoretical underpinnings.

This figure visualizes the coding rate across different layers of the DEPICT model. It shows two plots: one showing the projected coding rate onto subspaces (R(P₁ˡZ)) across layers, and another showing the ratio of the projected coding rate to the overall coding rate (R(P₁ˡZ)/R(Z)). Each line represents a different subspace, and the vertical dashed lines indicate the layer index of each subspace. The figure aims to demonstrate the relationship between the coding rate and the layer depth within the model, providing insight into how the model learns and compresses information.

This figure shows the inner product of the parameter matrices P and Q for different variants of DEPICT (DEPICT-SA and DEPICT-CA) using the ViT-L backbone. The left side displays the inner product of matrix P (PTP), and the right side shows the inner product of matrix Q (QTQ). The goal is to demonstrate the orthogonality of the matrices. Since the MHSA (Multi-Head Self-Attention) operator uses three parameter matrices, while MSSA (Multi-head Subspace Self-Attention) uses only one, the visualization focuses on the matrix responsible for transforming the queries to show the orthogonality more clearly. The results indicate that the matrices in DEPICT are closer to being orthogonal than those in the Segmenter model.

This figure shows the coding rate R(Z) and R(Q) across different layers of the DEPICT-SA and DEPICT-CA models. R(Z) represents the coding rate of the image embeddings, while R(Q) represents the coding rate of the low-rank approximation of the image embeddings. The plots demonstrate the relationship between these coding rates throughout the network’s layers, which helps support the authors’ claims about the efficiency of their approach and its ability to achieve low-rank representation.

This figure compares image segmentation results obtained using Principal Component Analysis (PCA) and the proposed DEPICT method. Two sets of image embeddings are used as input to the PCA: the initial embeddings (Zo) and the embeddings after refinement through the self-attention mechanism (ZL₁). The figure shows that PCA applied to the refined embeddings (ZL₁) produces better segmentation results than when applied to the initial embeddings (Zo), highlighting the effectiveness of the DEPICT’s self-attention refinement step in creating a more suitable principal subspace for segmentation.
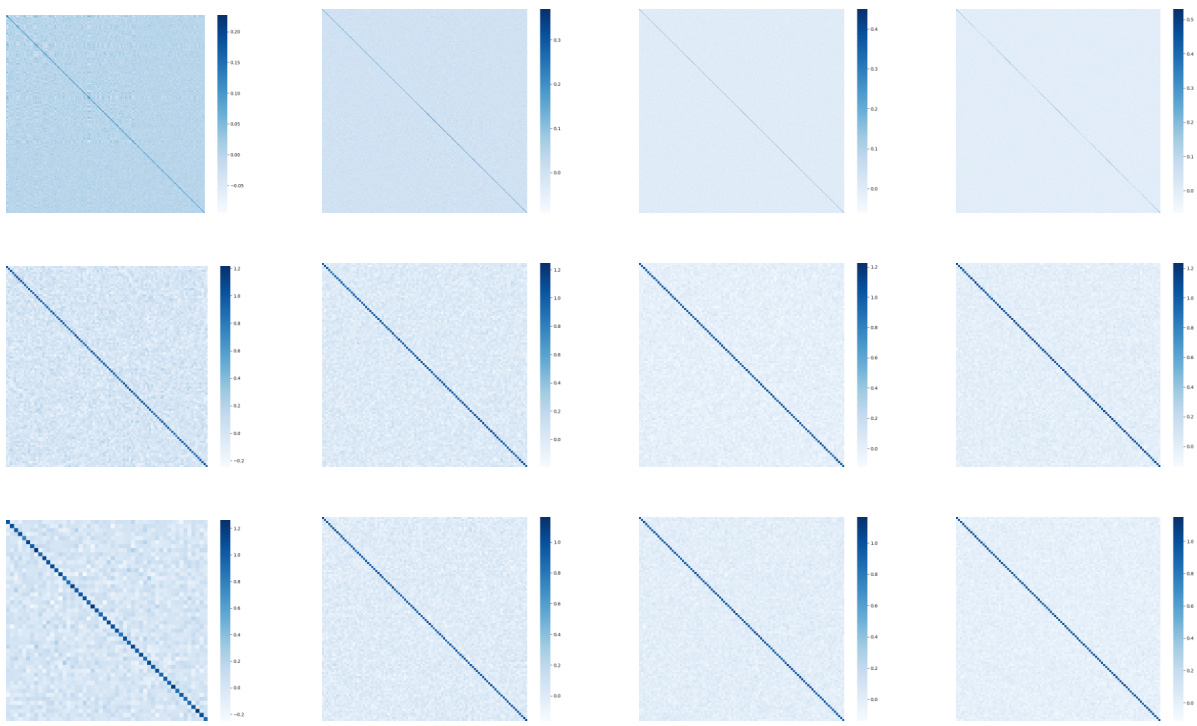
This figure visualizes the orthogonality of the learned parameter matrices P and Q in the DEPICT model for semantic segmentation. The left panel shows the inner product of the matrix P transposed with itself (PTP), while the right panel shows the same for the matrix Q (QTQ). The visualizations aim to demonstrate that the matrices are approximately orthogonal, a key aspect of the theoretical derivation of DEPICT based on PCA. The difference in normalization between P and Q is also highlighted in the caption.
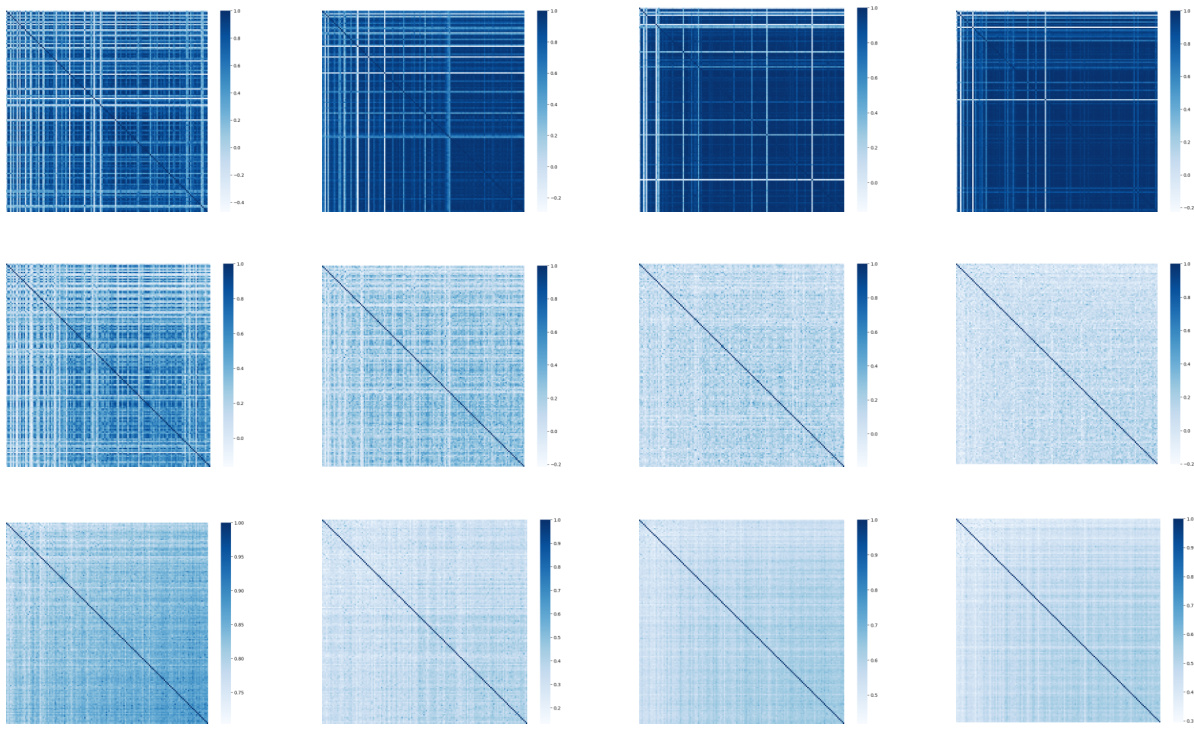
This figure demonstrates the orthogonality of the learned parameter matrices P and Q in the DEPICT model, particularly focusing on the matrices responsible for query transformations. The left panel shows the inner product of matrix P with its transpose (PTP), while the right panel shows the same for matrix Q (QTQ). The results suggest that the matrices are close to being orthogonal, a desirable property indicated by the paper’s theoretical analysis. The difference in the normalization of P and Q is also highlighted.
More on tables

This table compares the performance of Segmenter and DEPICT-SA on the validation sets of the Cityscapes and Pascal Context datasets. Both models use the ViT-L backbone. The metrics reported are mean Intersection over Union (mIoU) for single-scale (ss) and multi-scale (ms) inference, the number of parameters (#params), and floating point operations (FLOPs). DEPICT-SA achieves comparable performance to Segmenter with significantly fewer parameters and FLOPs.

This table compares the performance of the proposed DEPICT model with two state-of-the-art models, Segmenter and MaskFormer, on the ADE20K validation dataset. The comparison includes metrics such as mean Intersection over Union (mIoU), the number of parameters, and FLOPs (floating point operations) for different model variants (ViT-T, ViT-S, ViT-B, ViT-L). The best results achieved by DEPICT are highlighted.
Full paper#



















