↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Spiking Neural Networks (SNNs), the third generation of artificial neural networks, are energy-efficient but lag behind traditional Artificial Neural Networks (ANNs) in performance. This paper tackles this issue by focusing on the multi-threshold model which enables richer information transmission. However, existing works on this model did not fully explore its mathematical relationship with ANNs and SNNs.
The paper proposes a novel learnable multi-hierarchical threshold model (LM-HT) which dynamically regulates the global input current and membrane potential. LM-HT can be converted to a single-threshold model, enhancing hardware deployment flexibility and enabling mathematical equivalence with quantized ANNs under uniform input. The paper also introduces a hybrid learning framework to improve the performance of converted SNNs, demonstrating its effectiveness through extensive experiments that show the LM-HT model achieving state-of-the-art results and comparable performance to quantized ANNs.
Key Takeaways#
Why does it matter?#
This paper is crucial because it significantly advances Spiking Neural Networks (SNNs) performance, bridging the gap with Artificial Neural Networks (ANNs). Its innovative LM-HT model and hybrid training framework offer new avenues for energy-efficient and biologically plausible AI, impacting various fields relying on efficient computation.
Visual Insights#
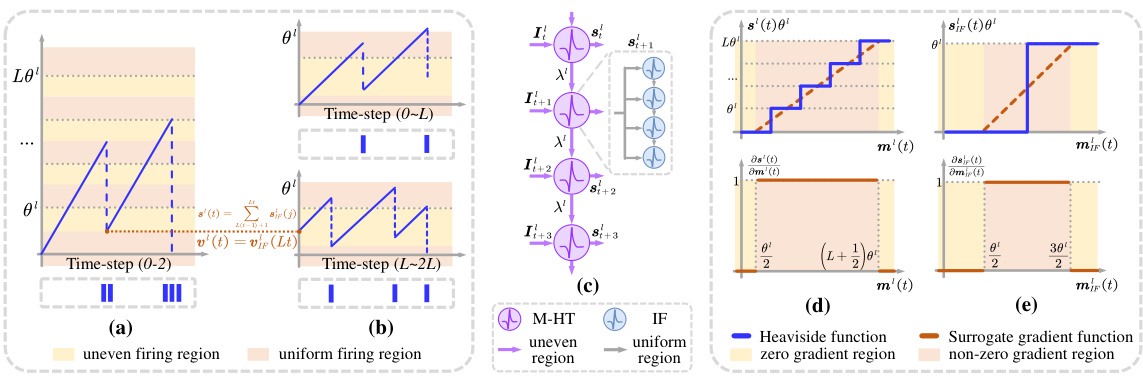
This figure illustrates the mathematical relationship between the multi-hierarchical threshold (M-HT) model and the vanilla integrate-and-fire (IF) model, as well as the surrogate gradient calculation for the M-HT model. Panels (a)-(c) show how the M-HT model simulates the behavior of the vanilla IF model over multiple time steps, enabling information integration. (d) and (e) depict the surrogate gradient calculation method used for the M-HT model, addressing the non-differentiability of the Heaviside step function in the vanilla IF model’s firing mechanism. The use of a surrogate gradient allows for backpropagation during training, even though the actual firing process is non-differentiable.
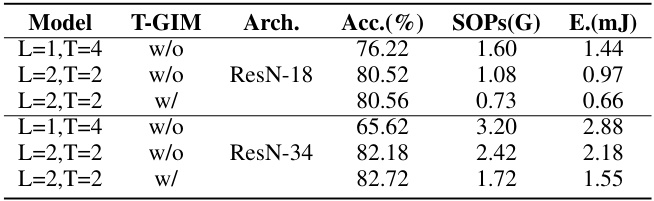
This table presents the results of an ablation study conducted on a subset of the ImageNet-1k dataset to evaluate the impact of different model configurations on the LM-HT model. The study varies the number of thresholds (L) and the number of time steps (T) considered by the model, with and without the Temporal-Global Information Matrix (T-GIM). For each configuration, the table reports the achieved accuracy (Acc.), the number of synaptic operations (SOPs) in Giga, and the energy consumption (E.) in millijoules. The results allow assessing the trade-off between accuracy, computational cost, and energy efficiency for various LM-HT model setups.
In-depth insights#
Multi-threshold SNNs#
Multi-threshold Spiking Neural Networks (SNNs) represent a significant advancement in SNN research. By incorporating multiple thresholds within a neuron, they enhance the network’s ability to encode and process information more efficiently. This contrasts with traditional SNNs that rely on a single threshold, limiting their representational capacity. The increased dimensionality offered by multiple thresholds allows for finer-grained temporal coding and potentially improved learning capabilities. This is particularly relevant for tasks requiring precise timing information, such as those found in sensory processing. However, designing effective learning algorithms for multi-threshold SNNs presents a considerable challenge. The complexity introduced by multiple thresholds necessitates the development of sophisticated learning rules that can efficiently update the network weights while accurately capturing the diverse spiking dynamics. Furthermore, hardware implementation of multi-threshold SNNs may also pose challenges. The increased complexity could lead to higher energy consumption and reduced scalability. Despite these challenges, the potential benefits of increased information capacity and efficiency make multi-threshold SNNs a promising area of research with significant potential for advancing the field of neuromorphic computing.
LM-HT Model#
The LM-HT model, a learnable multi-hierarchical threshold model, is proposed to enhance the performance of spiking neural networks (SNNs). It dynamically regulates global input current and membrane potential leakage, offering superior learning capability compared to traditional SNNs. Mathematical analysis reveals its equivalence to vanilla spiking models and quantized artificial neural networks (ANNs), bridging the gap between these network types. This novel framework improves the often-poor performance of converted SNNs, particularly under low latency, by effectively integrating with ANN-SNN conversion methods. The model’s design allows for flexible hardware deployment, converting seamlessly to a single-threshold model. Extensive experiments demonstrate its state-of-the-art performance on various datasets, showcasing its potential to bring SNNs to a level comparable with quantized ANNs.
Hybrid Training#
The concept of ‘hybrid training’ in the context of spiking neural networks (SNNs) offers a powerful approach to bridge the performance gap between SNNs and their artificial neural network (ANN) counterparts. It leverages the strengths of both paradigms: the energy efficiency and biological plausibility of SNNs and the superior performance achieved through established ANN training methods. A key aspect of hybrid training involves pre-training an ANN and then converting it to an SNN, followed by further fine-tuning using a spiking-based learning algorithm such as STBP. This strategy combines the benefits of ANNs’ well-established training procedures with SNNs’ inherent advantages. This approach is particularly valuable for applications demanding low latency and energy efficiency, as it addresses the challenges often encountered with directly training SNNs from scratch. The effectiveness of hybrid training hinges on the careful selection of the conversion method to minimize performance degradation and the effective integration of the ANN weights into the SNN architecture. Furthermore, the use of learnable parameters within the SNN, as demonstrated by the LM-HT model in this paper, can further refine this hybrid learning strategy. In essence, hybrid training presents a sophisticated strategy that harnesses the benefits of both ANN and SNN frameworks in the pursuit of superior performance in various machine learning applications.
Reparameterization#
The reparameterization technique, as discussed in the context of spiking neural networks (SNNs), is a crucial method for enhancing efficiency and deployment flexibility. It involves transforming a complex, multi-threshold model (like the LM-HT model presented) into a simpler, single-threshold model (like a vanilla LIF model), facilitating hardware implementation. This transformation is not merely a simplification; it preserves the essential functionality and performance characteristics of the original model. The core idea is to mathematically equate the behavior of the multi-threshold model over multiple timesteps with an equivalent single-threshold model. This is achieved through a layer-by-layer transformation, carefully re-parameterizing the weights and biases to maintain accuracy. This process is particularly useful in addressing the challenges of deploying SNNs on resource-constrained neuromorphic hardware, where the simplicity of a single-threshold model is advantageous. The success of the reparameterization hinges on the careful consideration of mathematical equivalency and avoiding information loss during the transformation. The resulting single-threshold model offers improved hardware compatibility without significant performance degradation, making SNNs more accessible for real-world applications.
Future works#
Future research could explore extending the LM-HT model to handle more complex spatiotemporal patterns and diverse neural morphologies. Investigating the model’s robustness to noise and variations in input data is crucial, as is exploring its applicability to larger-scale datasets and more complex tasks. A deeper theoretical analysis could shed light on the model’s capacity for generalization and its relationship with other SNN learning frameworks. Developing efficient hardware implementations of the LM-HT model for neuromorphic computing is another key area. Finally, comparing the LM-HT model with other multi-threshold models on various benchmarks would offer further insights into its strengths and limitations. This would help establish its place within the wider field of SNN research and guide the development of even more advanced spiking neural network architectures.
More visual insights#
More on figures
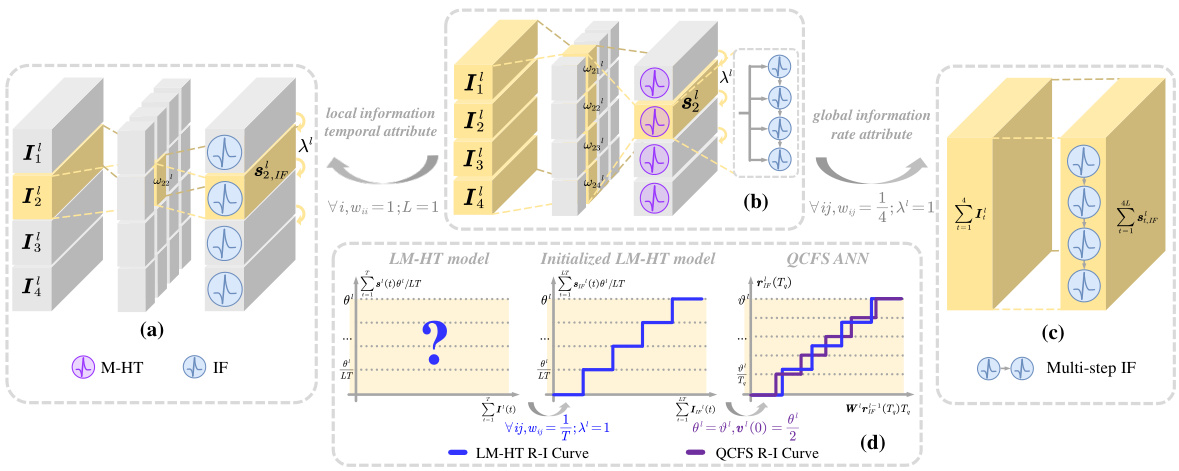
This figure illustrates the STBP learning framework using the LM-HT model and compares it to the vanilla STBP training, direct training of quantized ANNs, and a hybrid training approach. Panel (a) shows the standard vanilla STBP training. Panel (b) depicts the STBP training process with the LM-HT model, which incorporates a learnable multi-hierarchical threshold model and a temporal-global information matrix. Panel (c) demonstrates the direct training of quantized ANNs. Finally, panel (d) presents a hybrid training method that combines the strengths of the LM-HT model and quantized ANNs training. The rate-input (R-I) curves are shown for the LM-HT model and the QCFS ANN model.
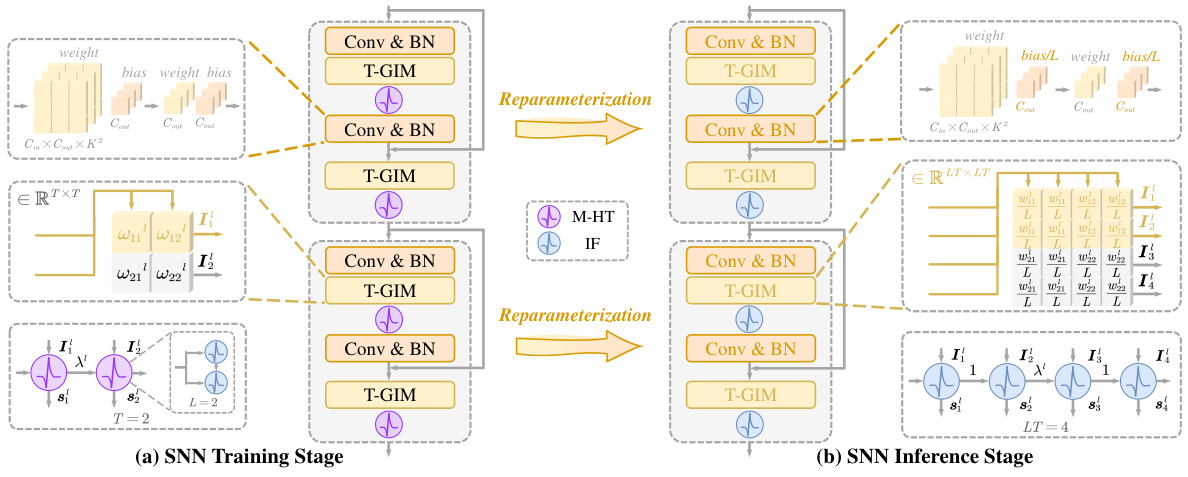
This figure illustrates the reparameterization process of transforming the LM-HT model (Learnable Multi-hierarchical Threshold model) into a vanilla LIF (Leaky Integrate-and-Fire) model for more efficient hardware deployment. The LM-HT model uses a multi-hierarchical threshold mechanism to integrate information over multiple timesteps within a single step. This figure shows how the LM-HT model’s parameters (weights, biases, Temporal-Global Information Matrix (T-GIM), and leaky parameters) are transformed to equivalent parameters in a vanilla LIF model, allowing for a lossless conversion that maintains accuracy while simplifying the model’s structure for hardware implementation.

This figure illustrates how the multi-hierarchical threshold (M-HT) model can be reparameterized into a vanilla single-threshold LIF model. The process involves transforming the multi-step input current weighting scheme of the M-HT model into a single-step LIF model. This transformation allows for more flexible hardware deployment of the model, as many neuromorphic hardware platforms are designed to work with LIF neurons, which only use a single threshold for spiking behavior. The figure shows two stages: the SNN training stage and the SNN inference stage. Both stages demonstrate how the T-GIM matrix and the learnable parameters (λ and Ω) are used for this transformation. The transformation ensures that there is no accuracy loss when switching from the M-HT model to the LIF model.
More on tables
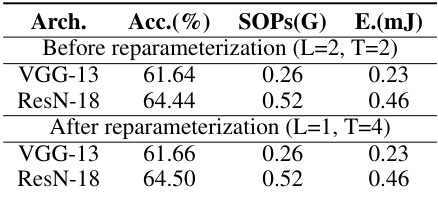
This table presents the accuracy, synaptic operations (SOPs), and energy consumption (E) for VGG-13 and ResNet-18 models before and after the reparameterization process. The reparameterization transforms a multi-hierarchical threshold (M-HT) model into a vanilla single-threshold model, demonstrating the efficiency and flexibility of the proposed method. The results show that the performance remains almost identical after reparameterization, indicating a successful transformation without significant loss in accuracy or computational cost.
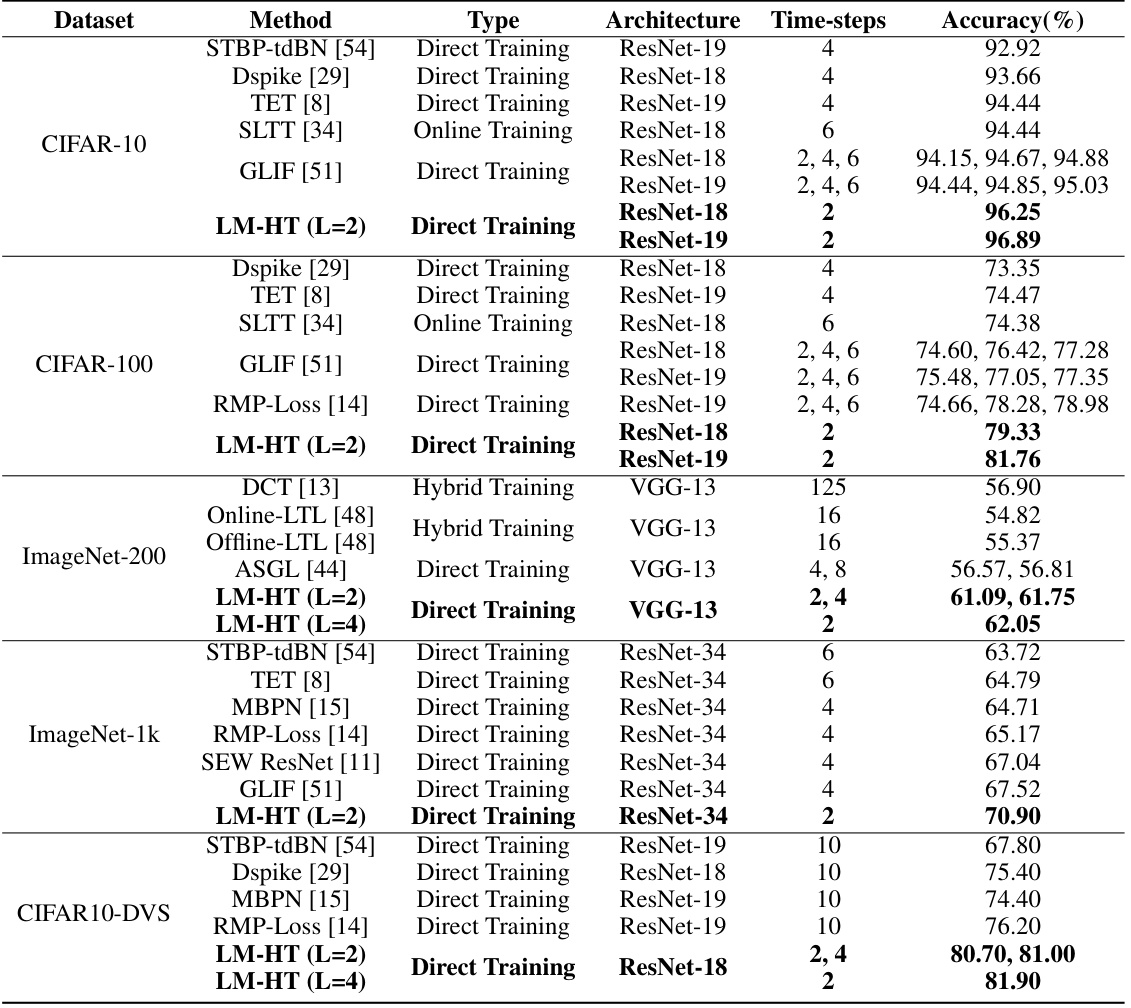
This table compares the performance of the proposed LM-HT model against other state-of-the-art methods on various datasets (CIFAR-10, CIFAR-100, ImageNet-200, ImageNet-1k, and CIFAR10-DVS) using different network architectures and numbers of time steps. The table presents the accuracy achieved by each method and highlights the superior performance of the LM-HT model, especially when using only two time steps.
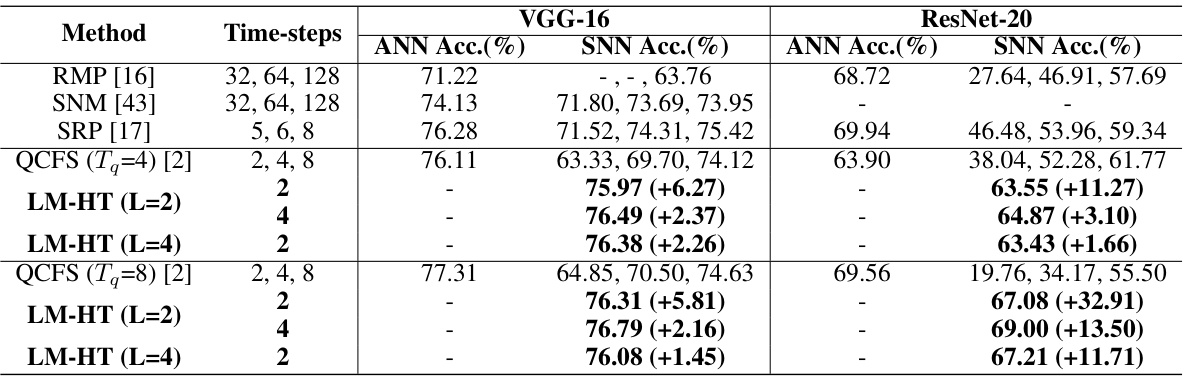
This table presents the results of hybrid training experiments using the LM-HT model on the CIFAR-100 dataset. It compares the accuracy achieved by different methods (RMP, SNM, SRP, QCFS, and LM-HT with varying parameters) after hybrid training, where the pre-trained ANN models are further fine-tuned using STBP for enhancing the performance of converted SNNs under low time latency. The results are broken down for two architectures, VGG-16 and ResNet-20, and for multiple time steps. The table shows the improvement in accuracy achieved using the LM-HT model over other methods.
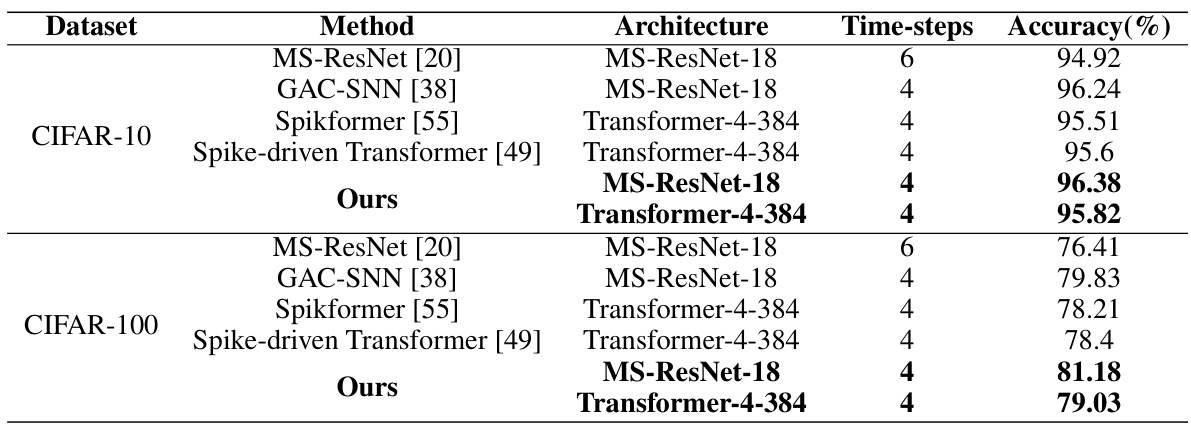
This table compares the performance of the proposed LM-HT model with other state-of-the-art methods on CIFAR-10 and CIFAR-100 datasets. The comparison considers different network architectures (MS-ResNet-18 and Transformer-4-384) and the number of time steps used for training. The results demonstrate the effectiveness of the LM-HT model in achieving high accuracy across various backbones and time steps.
Full paper#



















