↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Dichotomous image segmentation (DIS) struggles with limited and costly datasets. Current methods for generating synthetic data suffer from issues like scene deviations, noise, and limited sample variability. This makes it challenging to train accurate and robust models.
MaskFactory tackles this problem by using a two-stage approach. The first stage uses a novel mask editing method combining rigid (viewpoint changes) and non-rigid (shape alterations) editing techniques, leveraging geometric priors from diffusion models and adversarial training. The second stage uses a multi-conditional control generation method to create high-resolution images consistent with the edited masks. MaskFactory significantly improves the quality and efficiency of synthetic dataset generation for DIS, outperforming existing methods on standard benchmarks.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the critical need for high-quality synthetic datasets in dichotomous image segmentation (DIS). The proposed method, MaskFactory, offers a scalable and efficient solution to generate diverse and accurate datasets, significantly reducing time and costs associated with dataset creation. This advances the field of DIS and enables further research by providing more robust and reliable training data.
Visual Insights#

This figure shows examples of how the MaskFactory approach edits masks and generates corresponding images. The first row demonstrates rigid mask editing, changing the viewpoint of park benches and tables. The second row shows non-rigid mask editing, altering the shape of the same objects. The figure showcases the ability of MaskFactory to perform both viewpoint transformations (rigid) and shape alterations (non-rigid) while maintaining high-quality results.
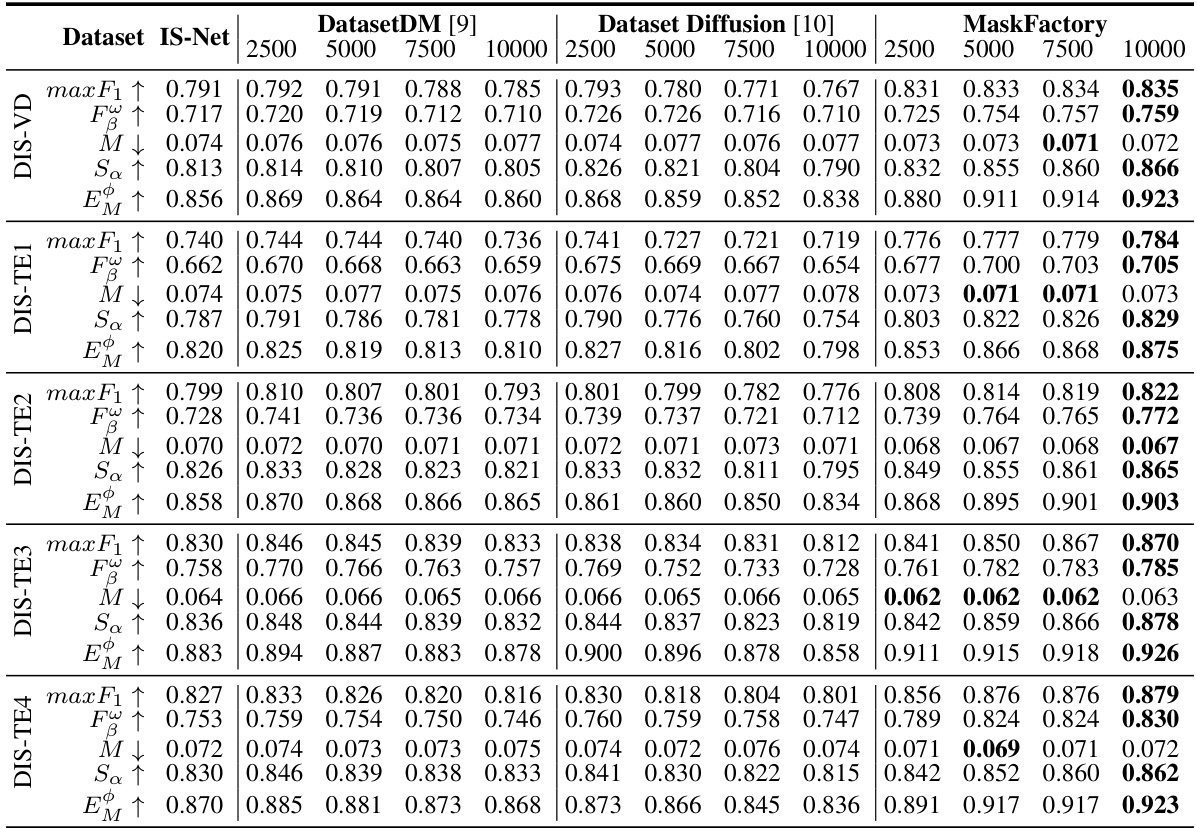
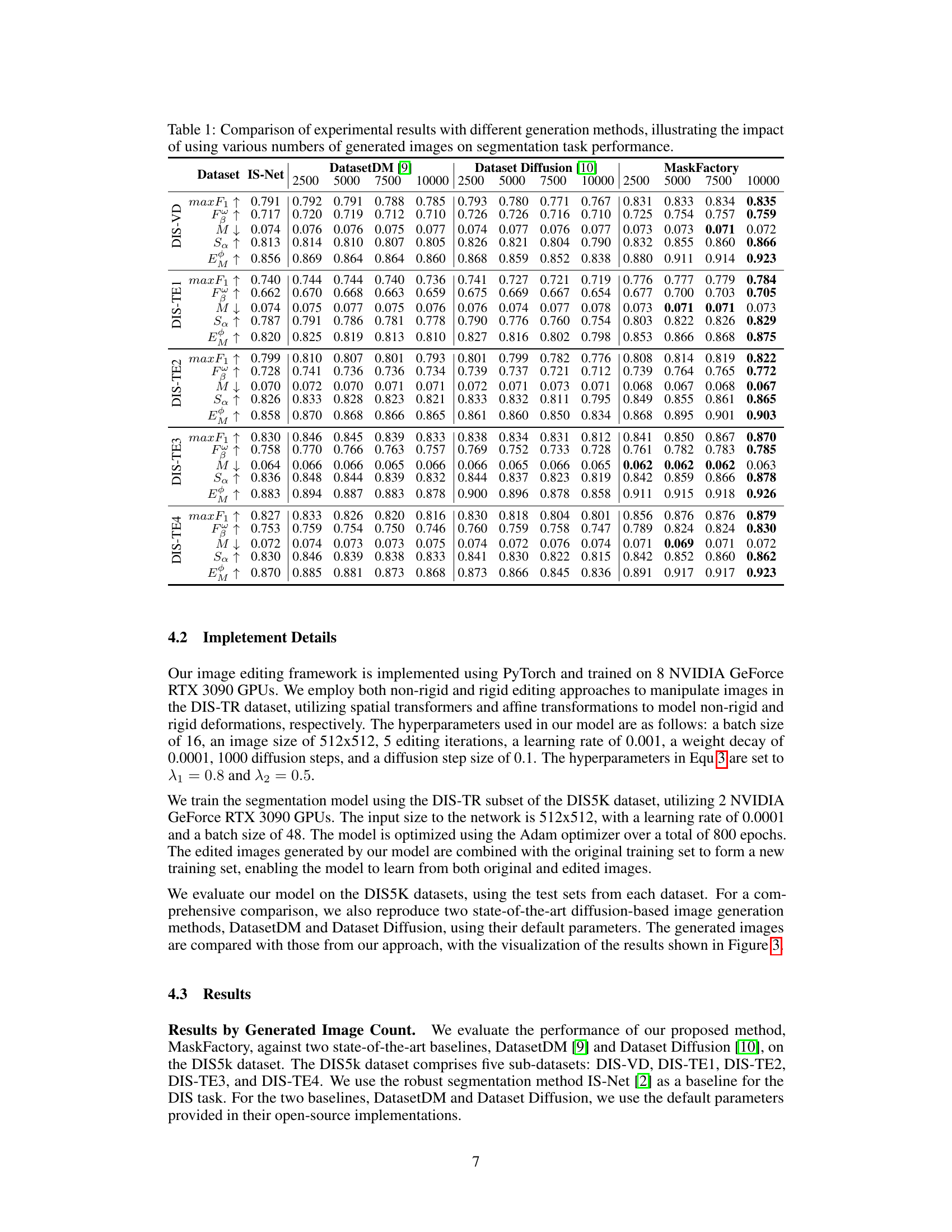
This table presents the quantitative results of the proposed MaskFactory method compared to other state-of-the-art methods (IS-Net, DatasetDM, Dataset Diffusion) across different metrics (max F1, F, M, Sa, E). The results are shown for various numbers of generated images (2500, 5000, 7500, 10000) and across five different subsets of the DIS5K dataset (DIS-VD, DIS-TE1, DIS-TE2, DIS-TE3, DIS-TE4). Higher values for max F1, F, Sa, and E indicate better performance, while lower values for M indicate better performance. The table demonstrates the impact of increasing the number of synthetic data samples on the overall performance of the different methods.
In-depth insights#
DIS Data Synthesis#
Dichotomous image segmentation (DIS) data synthesis is a crucial yet challenging area. Traditional methods are laborious and expensive, necessitating the exploration of synthetic data generation. High-quality synthetic data is key for mitigating these limitations, but current approaches struggle with realistic scene representation, noise management, and generating sufficient training variability. A successful DIS data synthesis method must address these issues through a robust and scalable approach. This might involve innovative mask editing techniques combining rigid and non-rigid transformations to ensure accurate and diverse mask generation, alongside sophisticated image synthesis methods capable of preserving fine details and maintaining consistency with generated masks. Multi-conditional generation approaches, incorporating multiple inputs such as canny edges and textual prompts, could greatly improve the quality and realism of the synthesized data. Evaluation of such a method needs to go beyond basic metrics, focusing also on topological consistency and structural preservation within the generated image-mask pairs, as well as considering the actual impact on downstream DIS model performance. The overall goal is to develop efficient, high-quality techniques that help advance the field and reduce the heavy reliance on manually annotated data.
MaskFactory Method#
The MaskFactory method is a novel two-stage approach for generating high-quality synthetic datasets for dichotomous image segmentation tasks. Stage one focuses on mask editing, cleverly combining rigid and non-rigid techniques. Rigid editing leverages geometric priors from diffusion models for precise viewpoint transformations, while non-rigid editing uses adversarial training and self-attention for complex shape modifications. This dual approach ensures both accuracy and diversity. Stage two involves image generation using a multi-conditional control generation method, guided by the edited masks and Canny edges, ensuring high consistency between the synthetic images and masks. The use of multiple control inputs significantly improves the quality and diversity of the generated dataset and thus, reduces the preparation time and costs. The entire pipeline is designed for scalability, making it a promising solution for addressing challenges in obtaining high-quality training data for this challenging task.
Ablation Study#
An ablation study systematically removes components of a model or system to assess their individual contributions. In the context of a research paper, an ablation study on a method for generating high-quality synthetic data for dichotomous image segmentation would likely involve removing or modifying key aspects of the process to determine their impact on the final output quality and performance. This would entail evaluating the effects of different mask editing techniques (rigid vs. non-rigid), comparing the results with various loss functions, and assessing the importance of different inputs such as Canny edges and prompts. By isolating the individual parts, researchers gain valuable insights into which components are most critical for achieving high-quality synthetic data and whether the method’s overall performance is robust to variations in specific elements. The analysis of these results helps to identify design choices that positively affect performance, paving the way for optimizing and improving the model’s capability for generating realistic and precise training data.
Future Directions#
Future research could explore improving the efficiency of MaskFactory by optimizing the mask editing and image generation processes. Reducing computational cost is crucial for scalability, particularly when generating large datasets. Additionally, investigating the use of more advanced generative models beyond diffusion models, such as transformer-based models, could lead to higher quality and more diverse synthetic data. Enhancing controllability over the generated data remains a key challenge; exploring techniques for fine-grained control over object attributes, poses and interactions would greatly enhance the model’s utility. Finally, expanding the types of objects and scenes that can be effectively generated would significantly broaden the application of MaskFactory. Addressing potential biases present in the training data and exploring methods for bias mitigation are also crucial future directions to ensure the fairness and reliability of the generated datasets.
Method Limits#
The method’s limitations stem from its reliance on pre-existing annotations, making it unsuitable for completely new datasets. The reliance on diffusion models, while enabling high-quality generation, introduces computational expense and potential limitations in generating highly diverse or complex scenarios. While topology-preserving techniques mitigate inconsistencies, they don’t fully eliminate the possibility of artifacts or distortions. The effectiveness of the multi-conditional approach depends heavily on the quality and diversity of the input data, so noisy or limited source data may limit the quality of generated data. Therefore, future work could address these aspects, perhaps via self-supervised or semi-supervised learning to reduce reliance on manual annotations, and exploring alternative generative models beyond diffusion models to potentially improve both efficiency and diversity.
More visual insights#
More on figures

This figure illustrates the two-stage process of MaskFactory. Stage 1 involves mask editing, using both rigid (viewpoint changes) and non-rigid (shape alterations) methods, guided by prompts. Stage 2 uses the edited masks and Canny edge detection to generate realistic RGB images using a multi-conditional control generation approach.

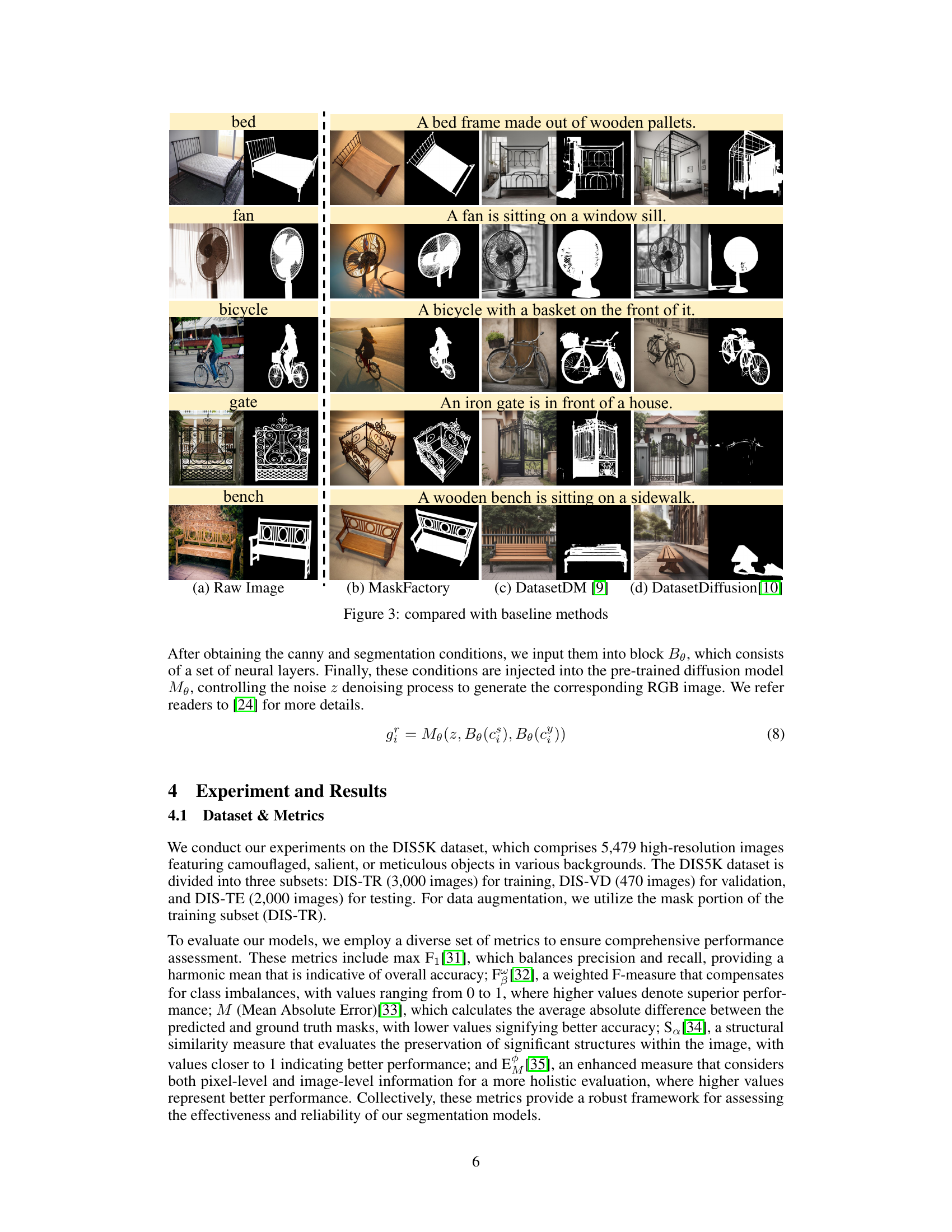
This figure compares the results of MaskFactory with two baseline methods, DatasetDM and DatasetDiffusion, on generating images and masks for five different object categories: bed, fan, bicycle, gate, and bench. For each category, it shows the raw image, the result from MaskFactory, the result from DatasetDM, and the result from DatasetDiffusion. This allows for a visual comparison of the quality and diversity of the generated data across different methods.
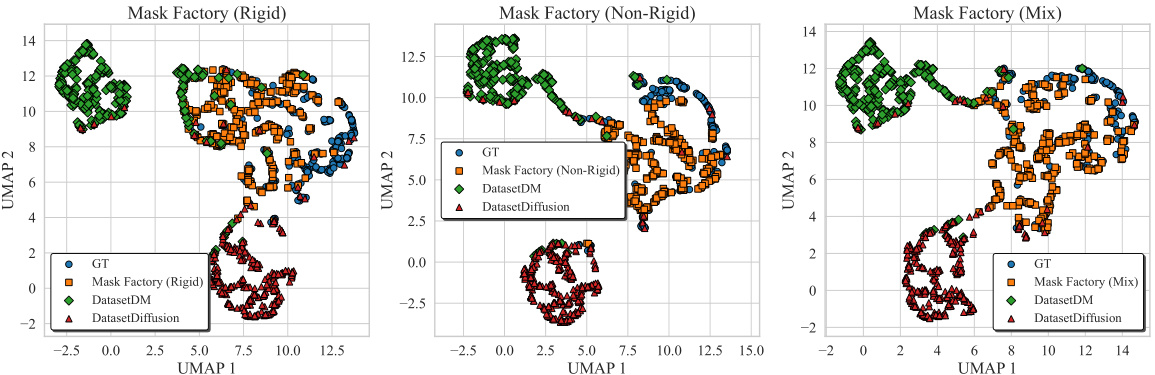
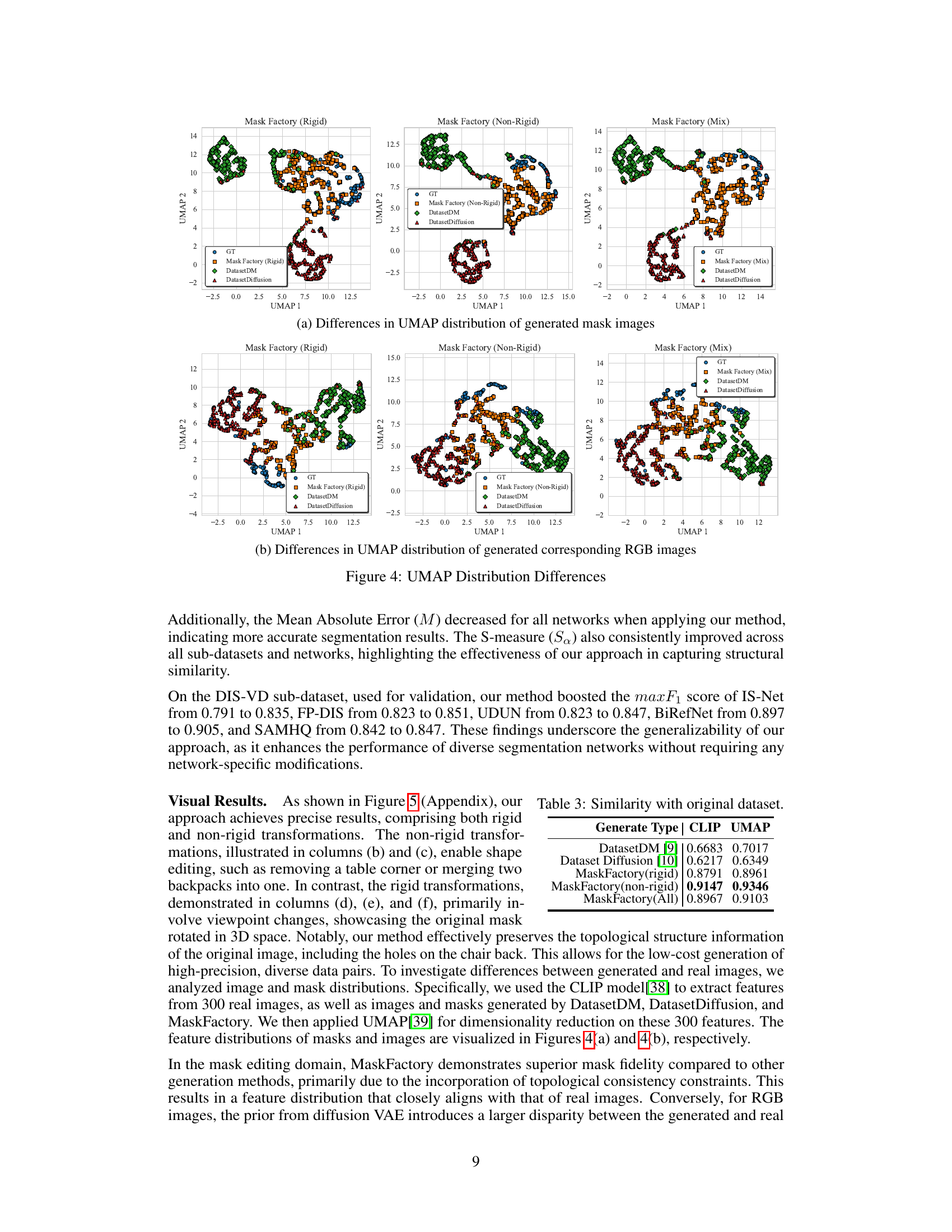
This figure visualizes the differences in the UMAP distributions of generated mask images and corresponding RGB images between MaskFactory (with rigid, non-rigid, and mixed editing methods) and two baseline methods (DatasetDM and DatasetDiffusion). The plots show that MaskFactory, especially the mixed editing method, generates mask and image distributions that are closer to the ground truth (GT) distribution compared to the baseline methods. This demonstrates that MaskFactory produces more realistic and diverse datasets.

This figure visualizes the differences in the UMAP distribution of generated mask images and corresponding RGB images between MaskFactory (rigid, non-rigid, and mix), DatasetDM, and DatasetDiffusion. The UMAP plots show the distribution of features extracted from the generated and ground truth images, highlighting the difference in feature space distribution among different methods. The plots visually demonstrate that MaskFactory achieves a feature distribution that more closely aligns with that of real images compared to the baseline methods. This supports the claim that MaskFactory generates more realistic and diverse synthetic datasets.

This figure shows visual results of applying both rigid and non-rigid mask editing methods on various common objects, such as chairs, tables, bags, etc. The results demonstrate the model’s ability to generate diverse editing outcomes while preserving the topological structure of the original masks. This highlights the effectiveness of the MaskFactory’s approach in generating realistic and diverse synthetic data for dichotomous image segmentation tasks.

This figure shows examples of fine-grained object mask editing using MaskFactory. The results demonstrate the model’s ability to handle complex shapes and details while maintaining the original mask’s semantic information. It showcases both rigid (viewpoint changes) and non-rigid (shape modifications) editing, highlighting the method’s ability to preserve structural integrity during complex edits.

This figure shows the results of adding Canny edge detection as a constraint to the image generation process. The images generated with Canny edge detection show improved boundary precision and better structural coherence compared to the images generated without it.
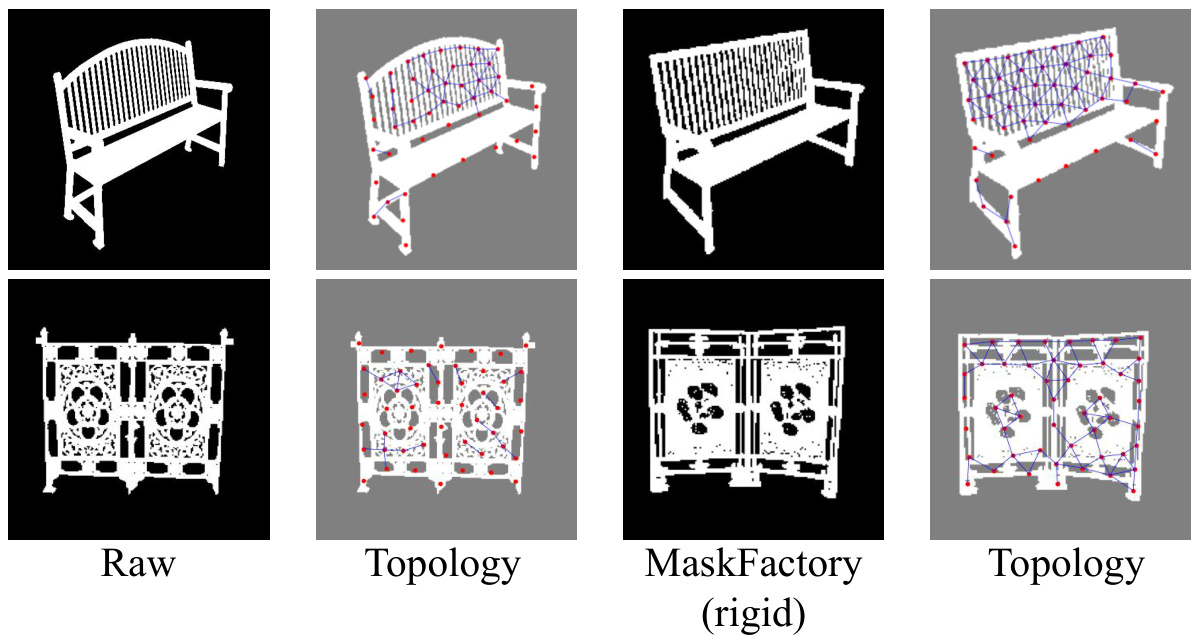
This figure visualizes the topological structure preservation capabilities of the MaskFactory model during the mask editing process. It showcases how the model maintains the original topological structure (connectivity of shapes) of masks even after applying both rigid (viewpoint changes) and non-rigid (shape deformations) transformations. The consistency in connectivity between the original and modified masks highlights the model’s ability to generate high-quality synthetic data with accurate topological information for the DIS task.
More on tables
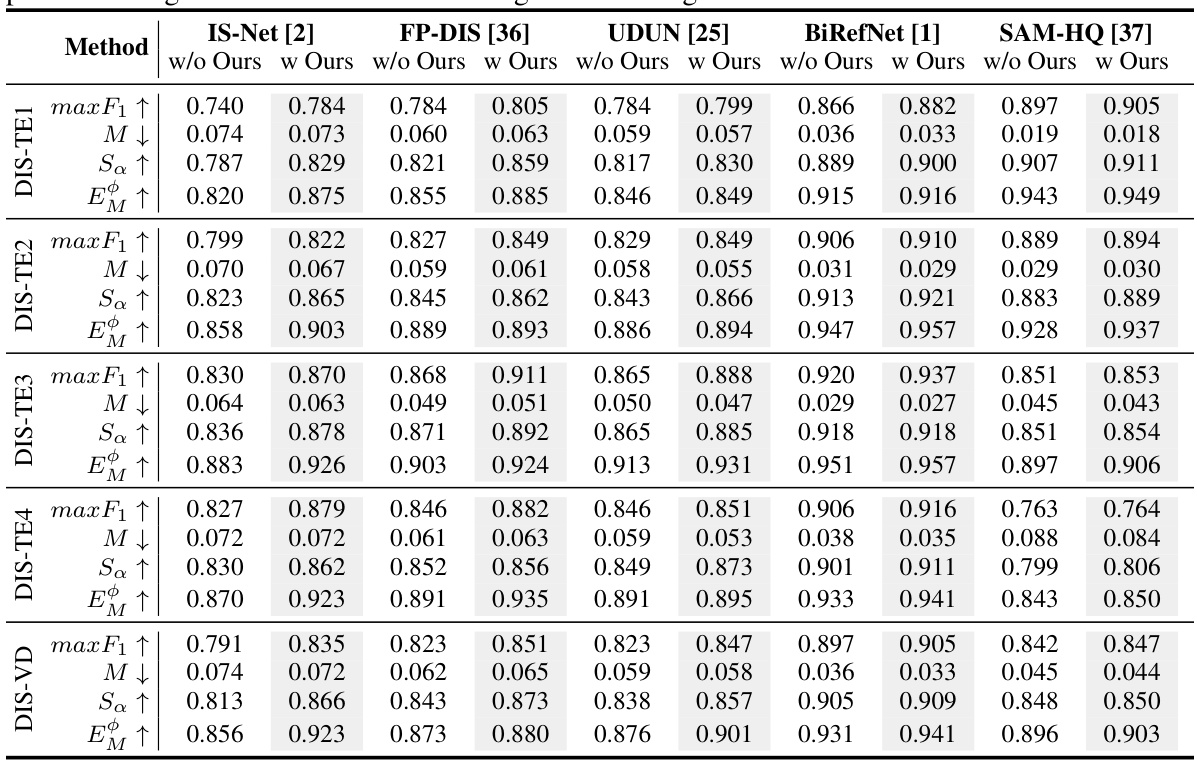
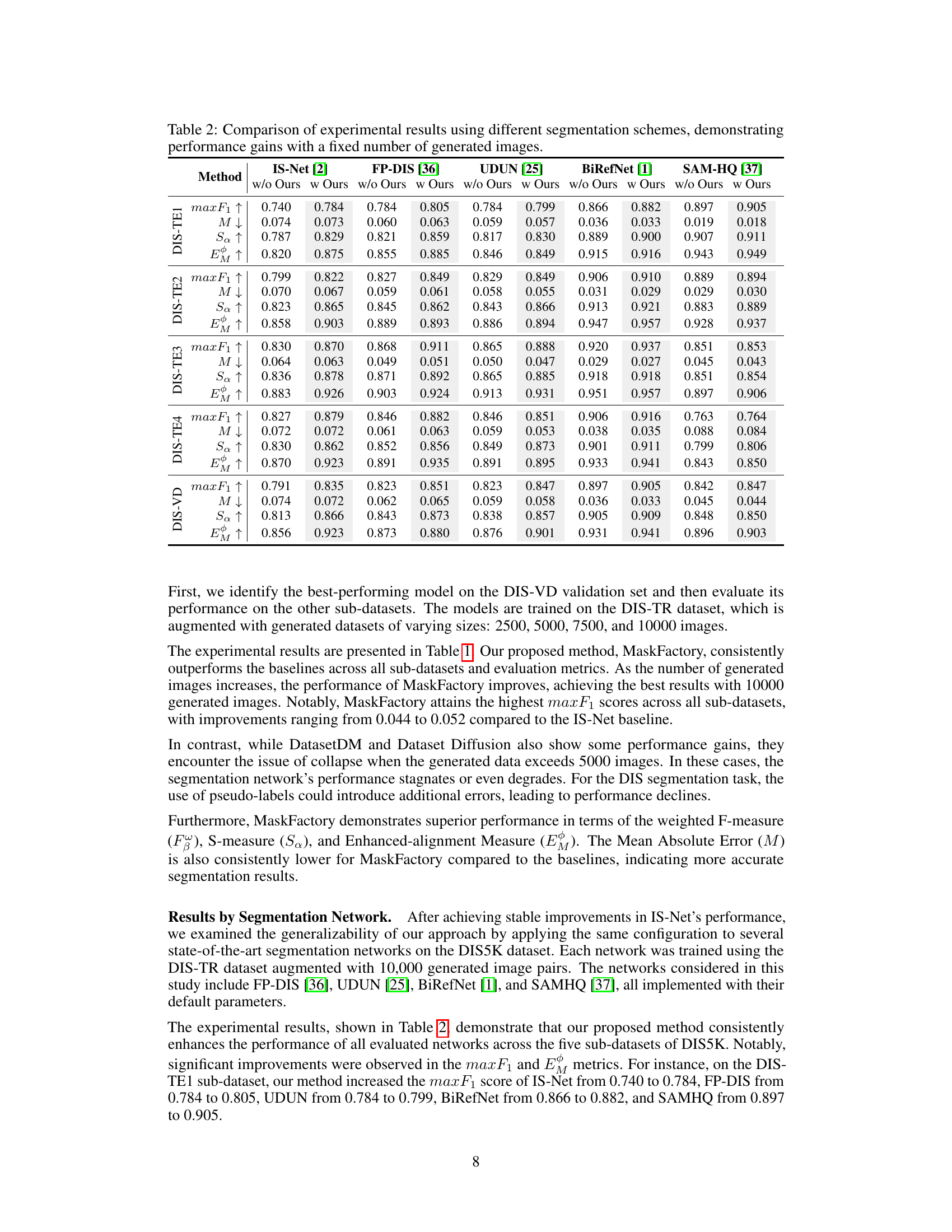
This table compares the performance of different segmentation methods (IS-Net, FP-DIS, UDUN, BiRefNet, SAM-HQ) on the DIS5K dataset, both with and without using the MaskFactory generated dataset. It shows the improvement in metrics (max F1, M, Sa, EM) achieved when integrating MaskFactory’s generated images, highlighting the effectiveness of the approach across multiple existing segmentation models.

This table compares the similarity of generated images and masks from three different methods (DatasetDM, Dataset Diffusion, and MaskFactory) to the original dataset. The similarity is measured using two metrics: CLIP and UMAP. Higher scores indicate greater similarity to the original dataset, suggesting better realism and quality in the generated data. MaskFactory, especially the non-rigid variant, shows significantly higher similarity scores than the baseline methods.
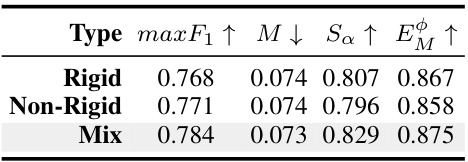
This table presents the ablation study results on different mask generation types (Rigid, Non-Rigid, and Mix) used in the MaskFactory method. The performance is evaluated using four metrics: max F1, M (Mean Absolute Error), Sa (S-measure), and EM (Enhanced-alignment Measure). The results show that the ‘Mix’ type achieves the best performance across all four metrics, indicating the effectiveness of combining both rigid and non-rigid editing techniques.
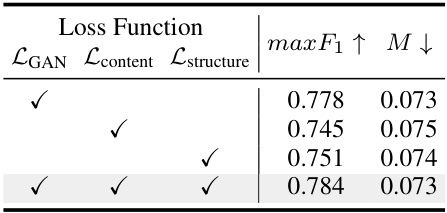
This ablation study investigates the impact of different loss functions on the model’s performance. It shows the results for three scenarios: using only the adversarial loss (LGAN), adding the content loss (Lcontent), and adding the structural loss (Lstructure). The best performance is achieved when all three loss functions are combined, demonstrating their complementary roles in enhancing the quality of the generated masks.

This table shows the ablation study results on different combinations of conditions used for image generation in MaskFactory. The conditions tested are: mask, prompt, and canny edge. The table presents the max F1 score and Mean Absolute Error (M) for each combination, demonstrating the impact of each condition on the model’s performance. The best performance is achieved when all three conditions are used.
Full paper#