↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Medical image classification often faces the challenge of limited labeled data. Multiple Instance Learning (MIL) is used to address this by using bag-level labels, but achieving accurate instance-level predictions (localization) remains difficult. Existing MIL methods either ignore instance relationships or model them inadequately, resulting in suboptimal localization performance.
The paper introduces SmMIL, a novel method that explicitly models local dependencies between instances using a ‘smooth operator’. This operator improves localization accuracy while maintaining competitive classification performance. Extensive experiments on multiple medical image datasets showcase SmMIL’s superiority over existing methods in localization and its competitive classification results, demonstrating its effectiveness and potential for real-world medical applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in medical image analysis and machine learning. It addresses the challenge of weakly supervised learning in medical imaging, a common problem due to the high cost of expert annotations. The proposed method, with its focus on improving localization accuracy, will be of significant interest to those working on multiple instance learning (MIL) and its applications in healthcare. The modular design of the proposed method makes it readily adaptable to various MIL frameworks, opening new avenues for further research and development.
Visual Insights#

This figure shows a unified view of deep multiple instance learning (MIL) models. It categorizes them into three families based on how instances within a bag interact: (b) instances treated independently; (c) only global interactions (e.g., using transformers); (d) both global and local interactions (e.g., combining transformers with graph neural networks). The figure visually represents the different model architectures, highlighting the key differences in how instance-level information is processed and aggregated to produce bag-level predictions.
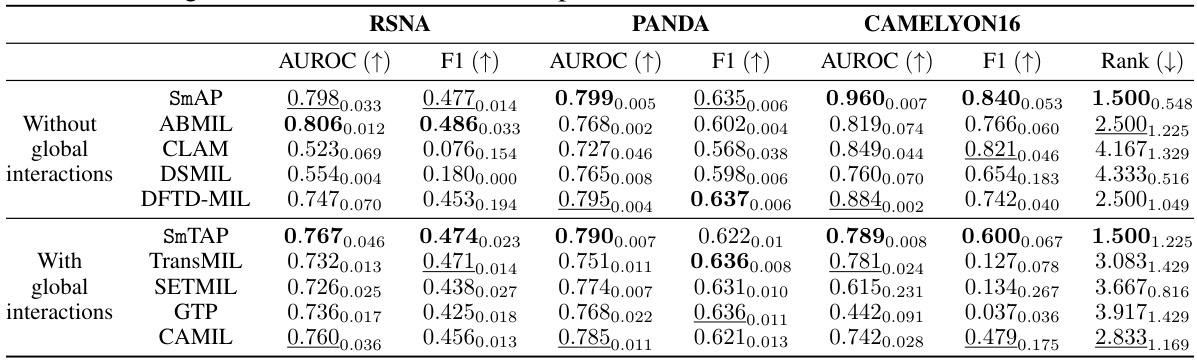
This table presents the results of localization experiments on three medical image datasets (RSNA, PANDA, and CAMELYON16) using eight different multiple instance learning (MIL) methods. The methods are categorized into those without and with global interactions. The table displays the AUROC and F1 scores for each method and dataset, highlighting the best and second-best performances. The rank of each method is also provided, summarizing its overall performance across all datasets and evaluation metrics.
In-depth insights#
SmMIL: Local Focus#
SmMIL: Local Focus presents a novel approach to enhance localization in Multiple Instance Learning (MIL) for medical image classification. The core idea revolves around leveraging the inherent spatial dependencies between instances within a bag. Unlike previous methods that primarily focused on global interactions, SmMIL explicitly models local dependencies by introducing a ‘smooth operator’ (Sm). This operator encourages smoothness in attention values assigned to instances, effectively enforcing the assumption that neighboring instances are likely to share similar labels. This leads to improved localization accuracy, as attention is more accurately focused on relevant regions. The Sm operator is flexible, compatible with various MIL architectures, and demonstrably improves both localization and classification performance. The results highlight the benefits of integrating this local focus mechanism, offering a valuable improvement in medical image analysis where accurate lesion localization is crucial.
Deep MIL Advances#
Deep Multiple Instance Learning (MIL) has witnessed significant advancements, transitioning from methods treating instances independently to those leveraging global and local inter-instance relationships. Early approaches, often based on attention mechanisms, lacked the ability to capture these complex dependencies. Recent advances utilize transformers to model global interactions, enabling the network to consider relationships between all instances within a bag simultaneously. However, a limitation remains: instance-level localization performance often lags behind classification accuracy. The critical insight is that improved local dependency modeling is needed. This involves explicitly incorporating spatial or structural information about instance proximity and similarity, for example, through graph neural networks (GNNs) or specialized attention modules. Future research should focus on more sophisticated ways to seamlessly integrate local and global context, potentially through hybrid models combining transformers and GNNs, resulting in improved accuracy for both classification and localization tasks.
Smooth Attention#
The concept of ‘Smooth Attention’ in the context of Multiple Instance Learning (MIL) for medical image classification addresses a critical limitation of existing attention mechanisms. Standard attention methods often yield attention maps that are noisy and lack spatial coherence, hindering accurate localization of relevant image regions. Smooth Attention directly tackles this issue by incorporating a principled mechanism to model local dependencies between instances (e.g., image patches or slices). This is achieved using a novel smooth operator, derived from the Dirichlet energy minimization framework. This operator promotes smoothness in the attention weights while maintaining fidelity to the original input features, resulting in more refined and interpretable attention maps. The smooth operator can be seamlessly integrated into existing MIL architectures, either independently or in conjunction with global interaction modeling techniques like transformers, thus offering significant flexibility. Empirical results demonstrate that Smooth Attention substantially improves localization performance while maintaining competitive classification accuracy across various medical image datasets.
Medical Image MIL#
Medical Image Multiple Instance Learning (MIL) addresses the challenge of limited annotated medical image data by leveraging weakly supervised learning. Instead of requiring instance-level labels (e.g., pixel-wise segmentation), MIL utilizes bag-level labels, where a “bag” represents an entire image or a collection of image patches, and each bag is assigned a single class label. This significantly reduces annotation effort. The core challenge in medical image MIL lies in effectively modeling the relationships between instances within a bag and learning discriminative features from potentially noisy or ambiguous data. Successful methods often incorporate attention mechanisms to identify informative instances, and advanced architectures such as transformers or graph neural networks to capture complex inter-instance dependencies. However, a key limitation remains the difficulty in achieving high-quality instance-level localization alongside robust bag-level classification. This necessitates further development of techniques to improve the accuracy and reliability of instance-level predictions, particularly in the context of medical diagnosis where precise localization is paramount.
Future of SmMIL#
The “Future of SmMIL” holds exciting possibilities. Improved efficiency is a key area; current implementations could benefit from optimizations to reduce computational cost, particularly for large datasets. Extending SmMIL’s applicability to other medical imaging modalities and beyond, to different weakly supervised learning tasks, is another promising direction. Exploring more sophisticated interaction modeling is crucial; investigating advanced graph neural networks or novel attention mechanisms could capture complex relationships between instances. Furthermore, deeper theoretical analysis is needed to fully understand SmMIL’s strengths and limitations, leading to more robust and reliable performance. Finally, integrating SmMIL into clinical workflows requires thorough evaluation of its impact on diagnosis accuracy and clinical decision-making, alongside addressing the inherent challenges in deploying AI models in healthcare settings.
More visual insights#
More on figures
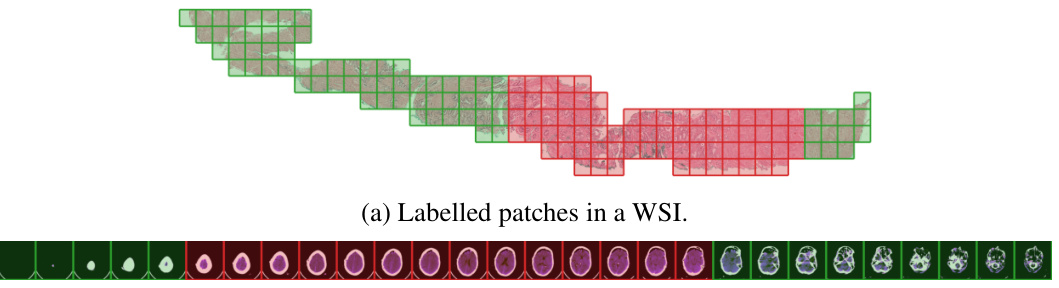
This figure shows two examples of medical images used in the paper which are Whole Slide Images (WSIs) and Computed Tomography (CT) scans. WSIs are divided into patches and CT scans into slices. The figure highlights that neighboring image instances (patches or slices) often share the same label. This observation motivates the use of local dependencies in modeling instance labels for improved localization in Multiple Instance Learning (MIL).

This figure shows three different model architectures for multiple instance learning (MIL). (a) is the baseline ABMIL model, which processes instances independently. (b) incorporates the proposed ‘smooth operator’ (Sm) to model local dependencies between instances, enhancing localization. (c) extends (b) by adding a transformer to capture global dependencies among instances.

This figure presents histograms of attention values for different MIL models on the CAMELYON16 dataset. The histograms separately show the distribution of attention values for positive and negative instances. The results highlight that SmAP and SmTAP effectively separate positive and negative instances, unlike other models which show more overlap.

This figure compares the attention maps generated by four different methods on a WSI from the CAMELYON16 dataset. The ground truth patch labels are shown for comparison. The SmTAP model produces the attention map that most closely resembles the ground truth, highlighting its superior localization performance. Other methods such as TransMIL, GTP, and CAMIL show less accurate localization and more ambiguity in identifying the regions of interest.
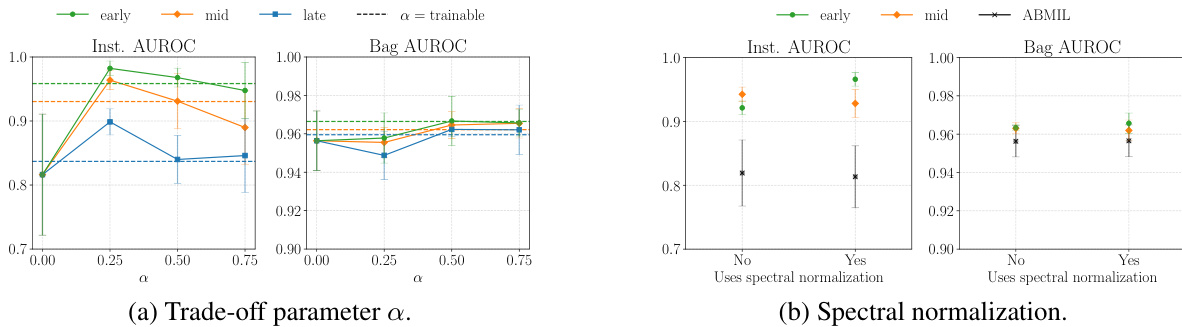
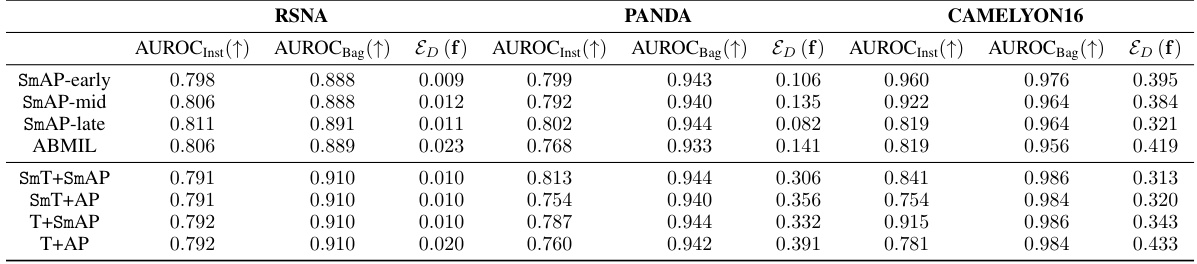
This figure shows the ablation study on the influence of the trade-off parameter α and spectral normalization on the performance of the proposed method. The left panel shows how different values of α affect the instance-level and bag-level AUROC scores. The right panel shows how using spectral normalization impacts instance-level and bag-level AUROC scores, compared to not using it. The results indicate that using the smooth operator improves performance in both localization and classification tasks, and that spectral normalization further enhances the performance.

This figure shows the impact of the number of iterations (T) used in approximating the smooth operator (Sm) on the model’s performance. The x-axis represents the number of iterations (T), with ∞ representing the exact solution. The y-axis shows the instance and bag AUROC for the RSNA and CAMELYON16 datasets. The results indicate that using T = 10 provides a close approximation to the exact solution (T = ∞), suggesting that a smaller number of iterations can be used without significantly impacting the model’s performance. ABMIL represents the baseline case where the smooth operator is not used (T=0).

This figure shows three different architectures for multiple instance learning (MIL). The first (a) is a baseline architecture (ABMIL) that processes instances independently. The second (b) adds the proposed smooth operator (Sm) to model local dependencies only after the instance-level embeddings have been aggregated. The third (c) includes both global dependencies (through a transformer) and local dependencies by incorporating the smooth operator before both aggregation and global interaction modeling steps. This figure illustrates the progressive addition of complexity and the flexible nature of the proposed smooth operator, allowing for use in conjunction with other mechanisms to address global interactions.

This figure displays attention maps generated by several Multiple Instance Learning (MIL) models on a Whole Slide Image (WSI) from the PANDA dataset. Each column represents a different MIL model: SmTAP, TransMIL, SETMIL, GTP, CAMIL, SmAP, ABMIL, CLAM, DSMIL, and DFTD-MIL. The color intensity in each map indicates the attention score assigned to each patch within the WSI. Brighter red signifies a higher attention score. The figure visually demonstrates how different MIL models focus on different regions of the WSI when trying to predict the presence of prostate cancer.
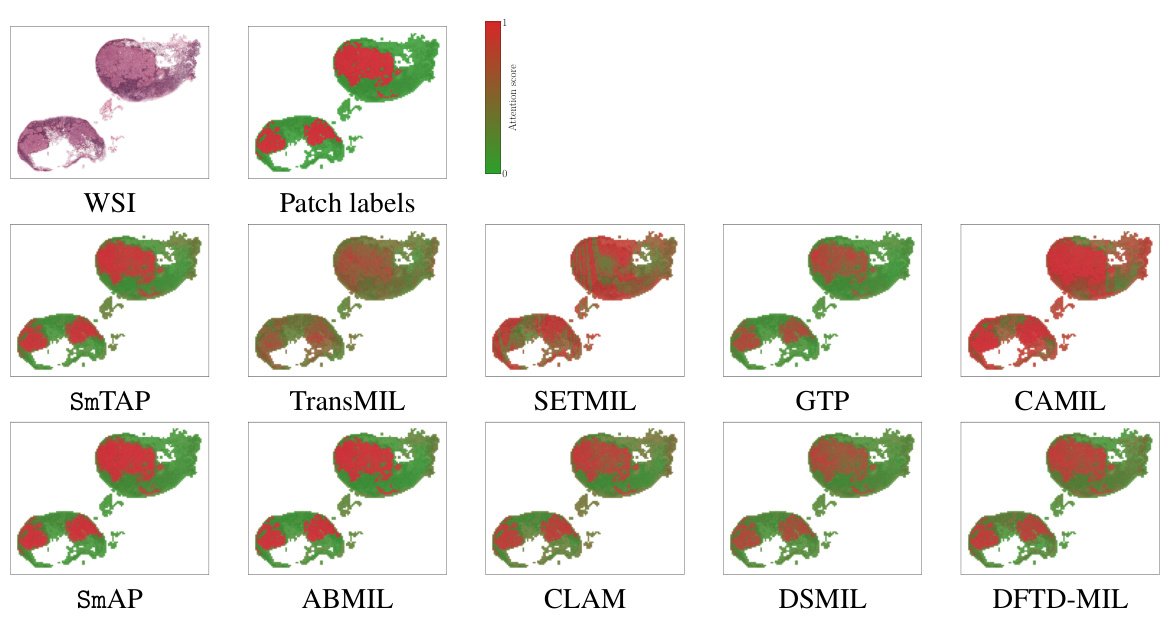
This figure shows attention maps generated by different MIL methods on a Whole Slide Image (WSI) from the PANDA dataset. The top row displays the original WSI and its corresponding patch labels. The subsequent rows illustrate the attention maps produced by SmTAP, TransMIL, SETMIL, GTP, and CAMIL (top half) and SmAP, ABMIL, CLAM, DSMIL, and DFTD-MIL (bottom half). Each attention map visually represents the model’s prediction of patch-level labels, with colors indicating confidence levels of positive or negative labels.
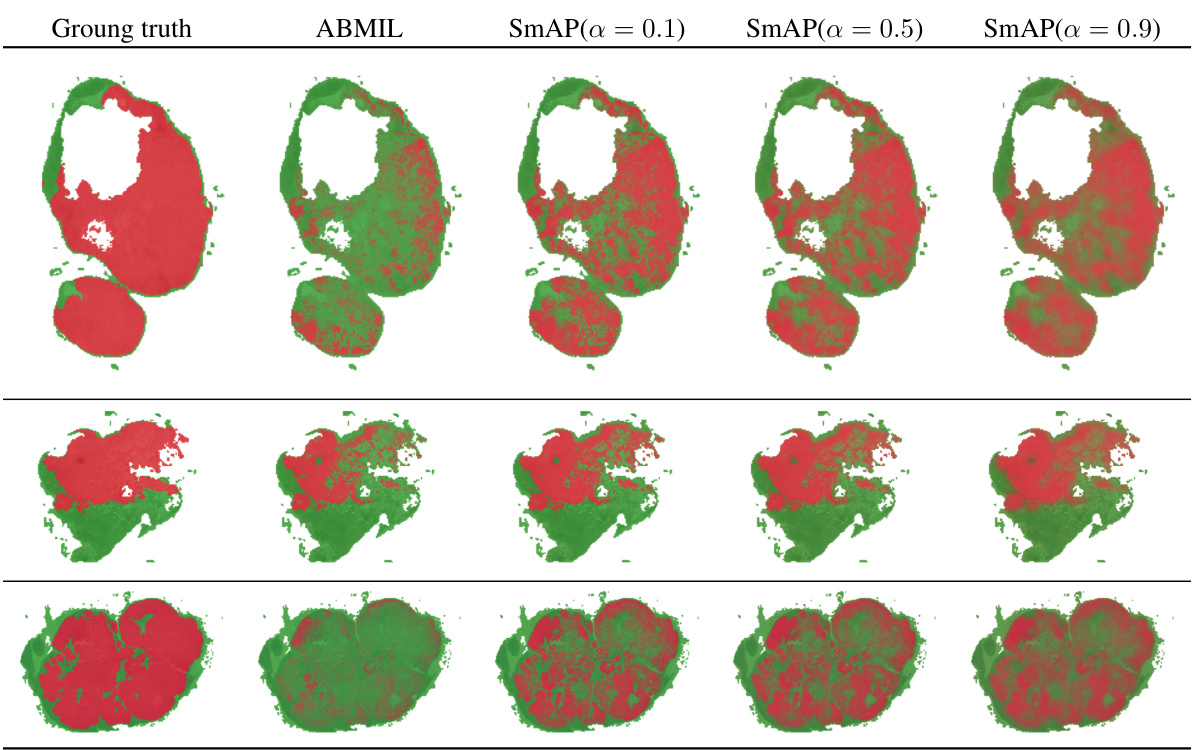
This figure compares the ground truth attention maps with the attention maps produced by ABMIL and SmAP with different values of α (0.1, 0.5, and 0.9). It shows that increasing α leads to smoother attention maps, as predicted by the theory. The results are shown for three different WSIs from the CAMELYON16 dataset.

This figure displays attention histograms for various MIL models on the CAMELYON16 dataset. It visualizes the distribution of attention values assigned to positive versus negative instances for each model. The histograms highlight the effectiveness of SmAP and SmTAP in clearly separating positive and negative instance attention values. The top row presents models without global interactions, and the bottom row shows models incorporating global interactions.

This figure shows the attention histograms for different MIL models on the CAMELYON16 dataset. The histograms visualize the distribution of attention values assigned to positive and negative instances by each model. The top row displays models without global interactions, and the bottom row displays models with global interactions. The figure highlights that SmAP and SmTAP are particularly effective at separating positive and negative instances, indicating superior performance in instance-level classification.
More on tables
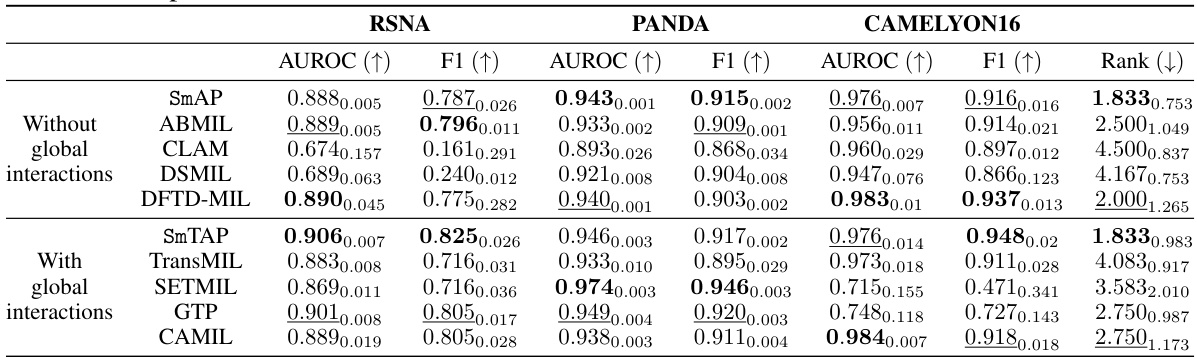
This table presents the quantitative results of the localization task, comparing the proposed method against eight other state-of-the-art methods. The performance is evaluated on three medical image datasets using two metrics: AUROC and F1 score. The table highlights the superiority of the proposed method in localization across different scenarios (with and without global interactions).
This table presents the quantitative results of the localization task. It compares the performance of different deep multiple instance learning (MIL) models on three datasets (RSNA, PANDA, and CAMELYON16). The metrics used are AUROC and F1 score, and both with and without global interactions. The table highlights the best and second-best performing models for each dataset and metric, demonstrating the superiority of the proposed method in localization.

This table presents the results of a localization task, comparing the performance of different methods across three datasets. The metrics used are AUROC and F1 score, both at the instance level. The table highlights the impact of the proposed ‘smooth operator’ on localization performance, showing its superiority in many cases, both with and without global interactions.

This table presents the results of localization experiments on three different medical image datasets (RSNA, PANDA, and CAMELYON16). It compares the performance of the proposed Smooth Attention Pooling (SmAP) and Smooth Transformer Attention Pooling (SmTAP) methods against eight other state-of-the-art Multiple Instance Learning (MIL) methods. The performance metrics used are AUROC and F1 score, both at the instance level. The table shows that the methods incorporating the smooth operator (SmAP and SmTAP) achieve state-of-the-art localization performance, outperforming other methods in most cases, even when considering whether global interactions (via transformers) are included.

This table presents the localization results of different MIL models on three datasets (RSNA, PANDA, and CAMELYON16). The results are shown for both the AUROC and F1 scores, with the best and second-best results highlighted. The table is split into models with and without global interactions, and the rank of each model across all datasets is also provided. The results demonstrate the effectiveness of the proposed smooth operator in improving the localization performance.

This table presents the results of a localization experiment on three different medical image datasets (RSNA, PANDA, and CAMELYON16). Two sets of results are shown: one where only local interactions were modeled, and one where both local and global interactions were modeled. Multiple methods are compared (SmAP, ABMIL, CLAM, DSMIL, DFTD-MIL, SmTAP, TransMIL, SETMIL, GTP, CAMIL), and the performance is measured using AUROC and F1 scores. The table highlights the superior performance of the proposed method in localization tasks.
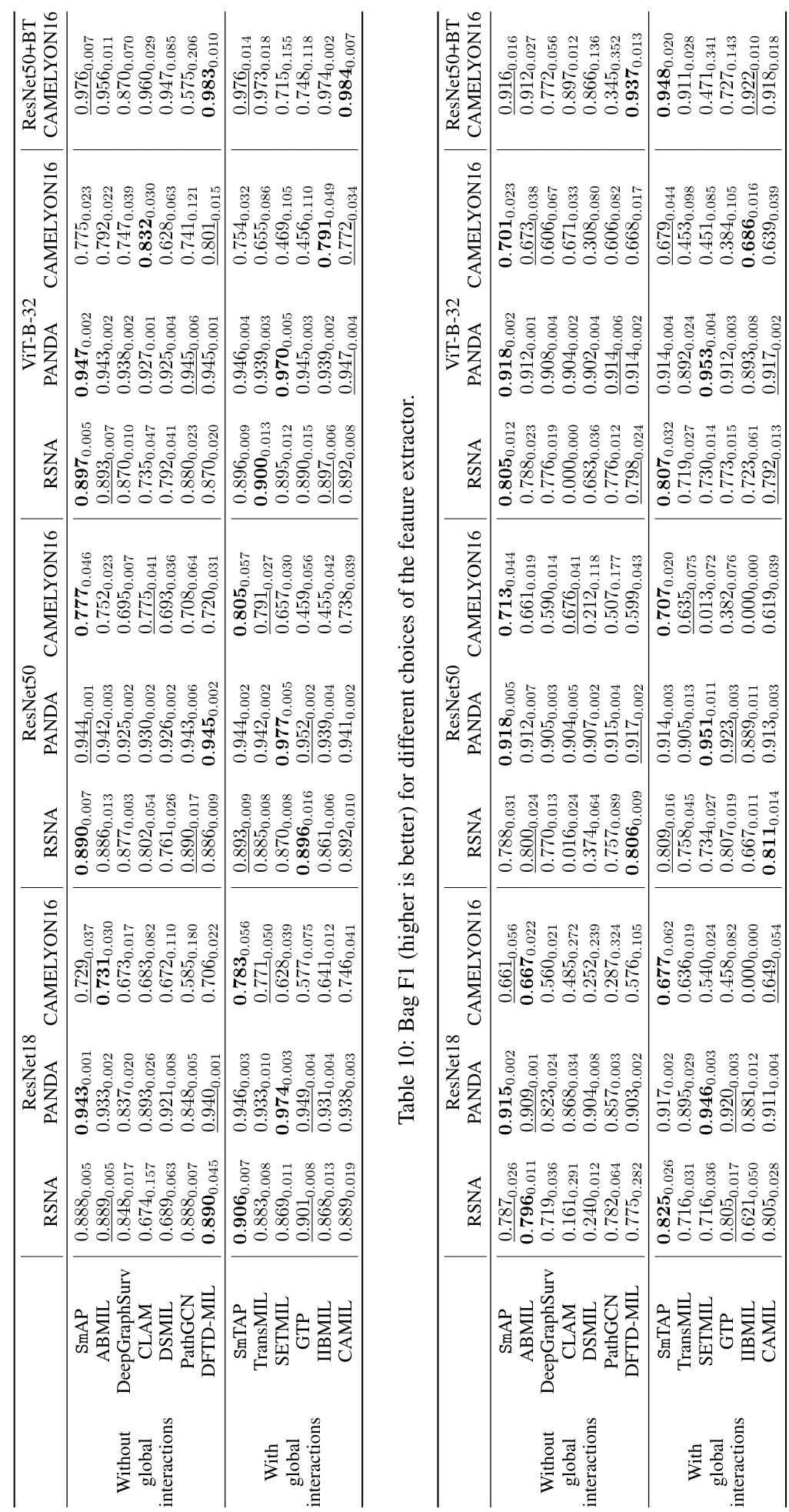
This table presents the results of a localization experiment across three datasets (RSNA, PANDA, and CAMELYON16) and two conditions (with and without global interactions). The performance is measured using AUROC and F1 scores. The table highlights the best and second-best performing models for each dataset and condition, demonstrating the superior localization performance of the proposed method.
Full paper#