↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
High-quality video generation using diffusion models is computationally expensive and demands significant memory, hindering practical applications. Existing model compression methods often require retraining, which is time-consuming and resource-intensive. These limitations restrict the deployment of such models on standard hardware.
This paper introduces Streamlined Inference, a training-free framework addressing these issues. It integrates three key components: Feature Slicer (partitions input features), Operator Grouping (processes sub-features efficiently), and Step Rehash (skips unnecessary steps). Experiments demonstrate significant reductions in peak memory and computational overhead, making high-quality video generation feasible on consumer-grade GPUs such as the 2080Ti. The method is applied to various models, achieving comparable visual quality with improved efficiency.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in video generation and AI due to its focus on improving efficiency. It directly addresses the limitations of current high-quality video diffusion models, making them accessible to researchers with standard hardware. The proposed training-free framework opens up avenues for developing faster, more memory-efficient video generation methods, impacting various AIGC applications.
Visual Insights#

🔼 This figure is a visual comparison of video generation results between the baseline method (Animatediff) and the proposed method (Streamlined Inference). It shows a sequence of frames depicting a large man riding a small motorcycle. The top row displays the output from Animatediff, while the bottom row shows the results from the Streamlined Inference method. The caption highlights the key advantage of the proposed method: significantly reduced peak memory usage (3.3x less) and inference latency (1.6x less) without compromising the visual quality of the generated video.
read the caption
Figure 1: Our Streamlined Inference is a training-free inference framework for video diffusion models that can reduce the computation and peak memory cost without sacrificing the quality.
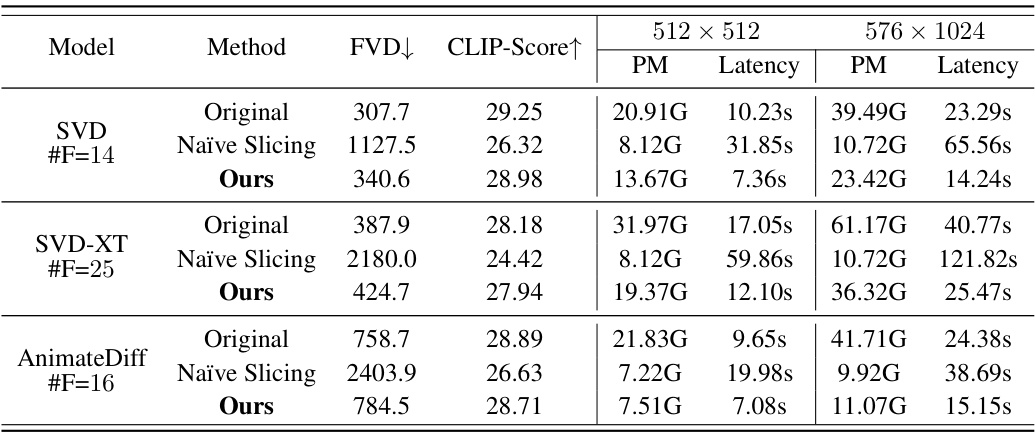
🔼 This table compares the performance of the proposed Streamlined Inference method against baseline methods (Original, Naïve Slicing) for three different video diffusion models (SVD, SVD-XT, AnimateDiff) at two resolutions (512x512 and 576x1024). The metrics used for comparison include Fréchet Video Distance (FVD), CLIP Score, Peak Memory (PM), and Latency. Lower FVD and higher CLIP Score indicate better video quality. Lower PM and Latency values signify better memory efficiency and faster inference speed. The #F column indicates the number of frames generated for each video.
read the caption
Table 1: Comparison of our Streamlined Inference with baseline methods in video visual quality (on UCF101), PM (Peak Memory), and latency (measured with 50 runs with the average value).
In-depth insights#
Video Diffusion#
Video diffusion models represent a significant advancement in AI-generated content, enabling high-fidelity video generation. These models leverage the power of diffusion processes, iteratively refining noise to produce realistic video sequences. However, a key challenge lies in their high computational cost and memory requirements, particularly when generating longer, higher-resolution videos. This limits their accessibility to researchers and practitioners without high-end hardware. Recent work focuses on improving the efficiency of video diffusion, proposing novel methods to reduce computational complexity and peak memory usage. These approaches often involve clever modifications to the underlying algorithms or architectural changes to the network structure, and frequently involve training-free methods to avoid the time and resource-intensive process of model retraining. While promising, the continued development of more efficient video diffusion models remains a vital area of research, balancing high-quality video generation with the need for accessible and practical applications.
Streamlined Inference#
The proposed “Streamlined Inference” framework offers a novel, training-free approach to significantly enhance the efficiency of video diffusion models. This is achieved through three core components: Feature Slicer, which partitions input features to reduce memory usage; Operator Grouping, which aggregates operators for improved parallelism and memory reduction; and Step Rehash, which leverages temporal similarities to skip redundant computations. The framework’s training-free nature is a key advantage, avoiding the costly and time-consuming retraining required by many existing compression techniques. By targeting both memory and computational bottlenecks inherent in video diffusion models, “Streamlined Inference” enables high-quality video generation on consumer-grade GPUs, making this technology more accessible and practical.
Memory Efficiency#
The research paper significantly emphasizes memory efficiency in the context of video diffusion models. It highlights the substantial memory demands of existing models, particularly when generating high-resolution or long videos. The core argument is that these memory constraints hinder practical applications. The paper then proposes a novel, training-free inference framework called Streamlined Inference designed to directly address these limitations. Key components, including Feature Slicer, Operator Grouping, and Step Rehash, are detailed. The framework aims to reduce memory footprint without sacrificing the quality or speed of video generation. The effectiveness of the method is demonstrated through experimental results, showing significant memory reduction in several popular video diffusion models, ultimately making high-quality video generation more feasible on consumer-grade hardware. The approach focuses on optimizing the inference process, rather than model compression through training, which is a key innovation of this work.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a video diffusion model, this might involve disabling the temporal layers, spatial feature slicing, operator grouping, or step rehashing. Each ablation reveals how crucial these elements are to performance metrics, such as FID (Fréchet Inception Distance) and CLIP score. A well-designed ablation study should demonstrate that removing specific components negatively impacts the results, thus validating the efficacy of each component in reducing peak memory consumption and improving inference speed. A significant drop in performance when a component is removed highlights its importance, indicating the effectiveness of the Streamlined Inference framework. Conversely, minimal change shows the component may be less essential to the overall success. This rigorous process confirms the value of the proposed techniques, providing a strong foundation for the claimed enhancements in efficiency and performance.
Future Work#
Future work in this area could explore several promising directions. Extending Streamlined Inference to other video diffusion models beyond those tested is crucial to demonstrate broader applicability and effectiveness. Investigating the interplay between different slicing strategies (spatial vs. temporal) and their impact on model performance warrants further study. The current work focuses primarily on peak memory reduction and inference speed; a comprehensive analysis of the trade-offs between these metrics and the quality of the generated videos is needed. Furthermore, developing more sophisticated step selection algorithms for Step Rehash could significantly improve efficiency without compromising video quality. Finally, integrating Streamlined Inference with other model compression techniques (e.g., quantization, pruning) could lead to even greater gains in efficiency and resource utilization.
More visual insights#
More on figures
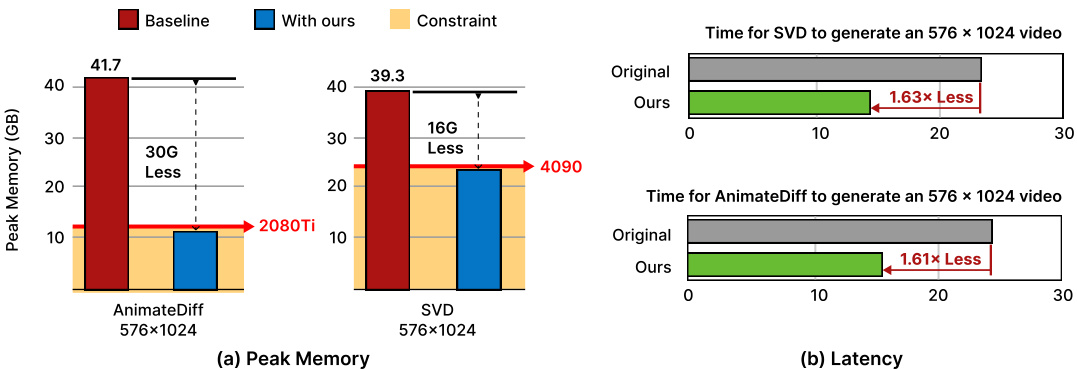
🔼 This figure compares the peak memory usage and inference latency of the original Animatediff and SVD models with the proposed Streamlined Inference method. The left panel (a) shows a bar chart illustrating the significant reduction in peak memory achieved by the Streamlined Inference method for both models at 576x1024 resolution. The right panel (b) presents bar charts depicting the reduction in inference time (latency) achieved with the new method for both models. The key takeaway is that Streamlined Inference drastically reduces memory requirements, making video generation feasible on consumer-grade GPUs without sacrificing significant speed.
read the caption
Figure 2: Comparison on Animatediff and SVD inference using our Streamlined Inference. Memory requirement is crucial as 'Out of Memory' errors prevent the GPU from performing inference.

🔼 This figure shows a comparison of video generation results between the proposed Streamlined Inference method and a naive slicing approach. The left side shows a rocket launch, while the right depicts a woman blowing snow. The ‘Ours’ row displays high-quality, temporally consistent videos generated using the Streamlined Inference method. In contrast, the ‘Naive’ row demonstrates the artifacts that result from a naive slicing approach, which fails to maintain temporal coherence, resulting in less realistic and visually jarring video sequences. This highlights the importance of the proposed method’s ability to preserve temporal consistency.
read the caption
Figure 3: The quality results of our method and naïve slicing. Note that naïve slicing will incur unpleasant artifacts due to lack of temporal correction by fewer frames.

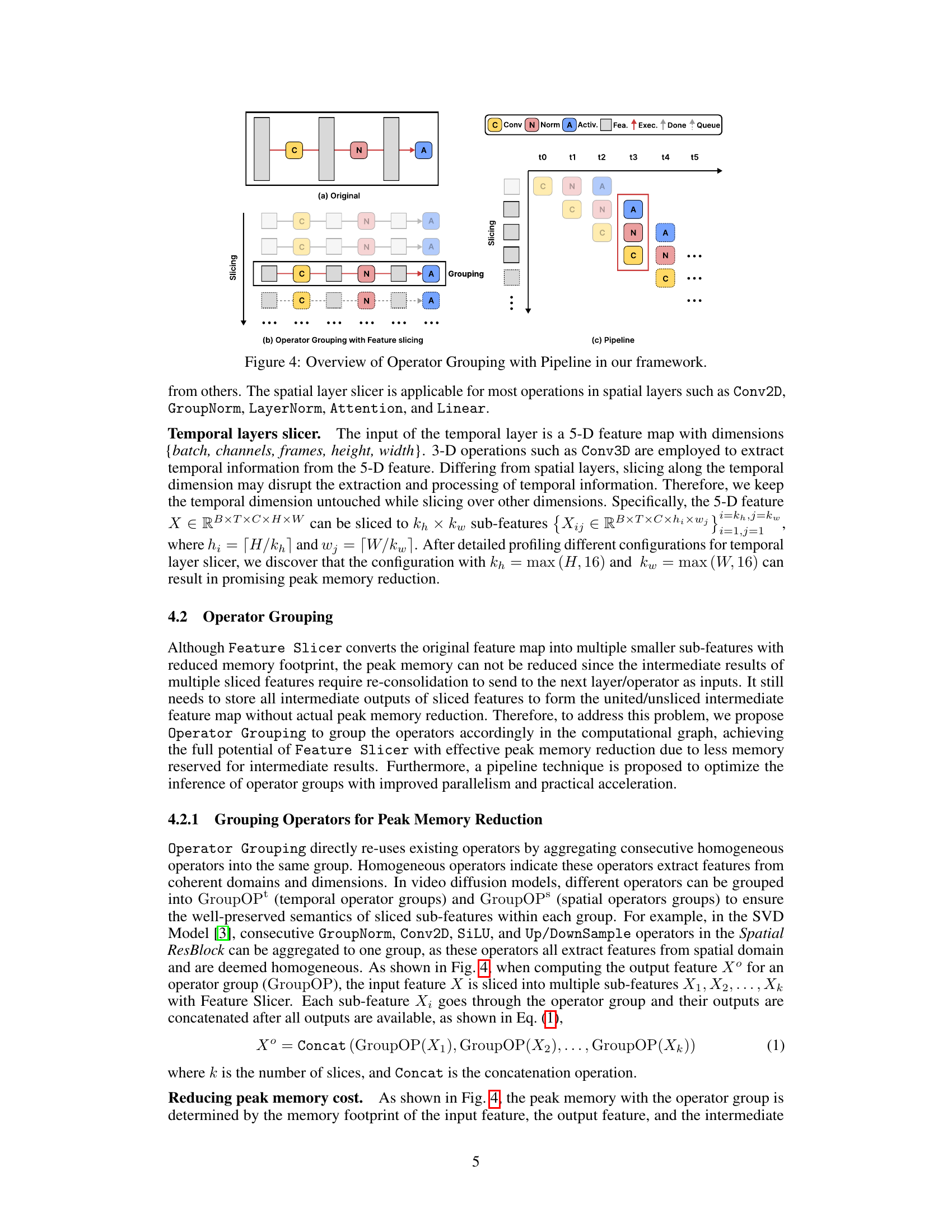
🔼 This figure illustrates the three core components of the Streamlined Inference framework: Feature Slicer, Operator Grouping, and Pipeline. (a) shows the original, non-optimized operator sequence. (b) demonstrates the effect of Feature Slicing and Operator Grouping, where the input feature is partitioned, and operations are grouped to reduce memory usage. (c) further enhances performance with pipelining, enabling parallel processing of multiple sub-features within the same operator group.
read the caption
Figure 4: Overview of Operator Grouping with Pipeline in our framework.

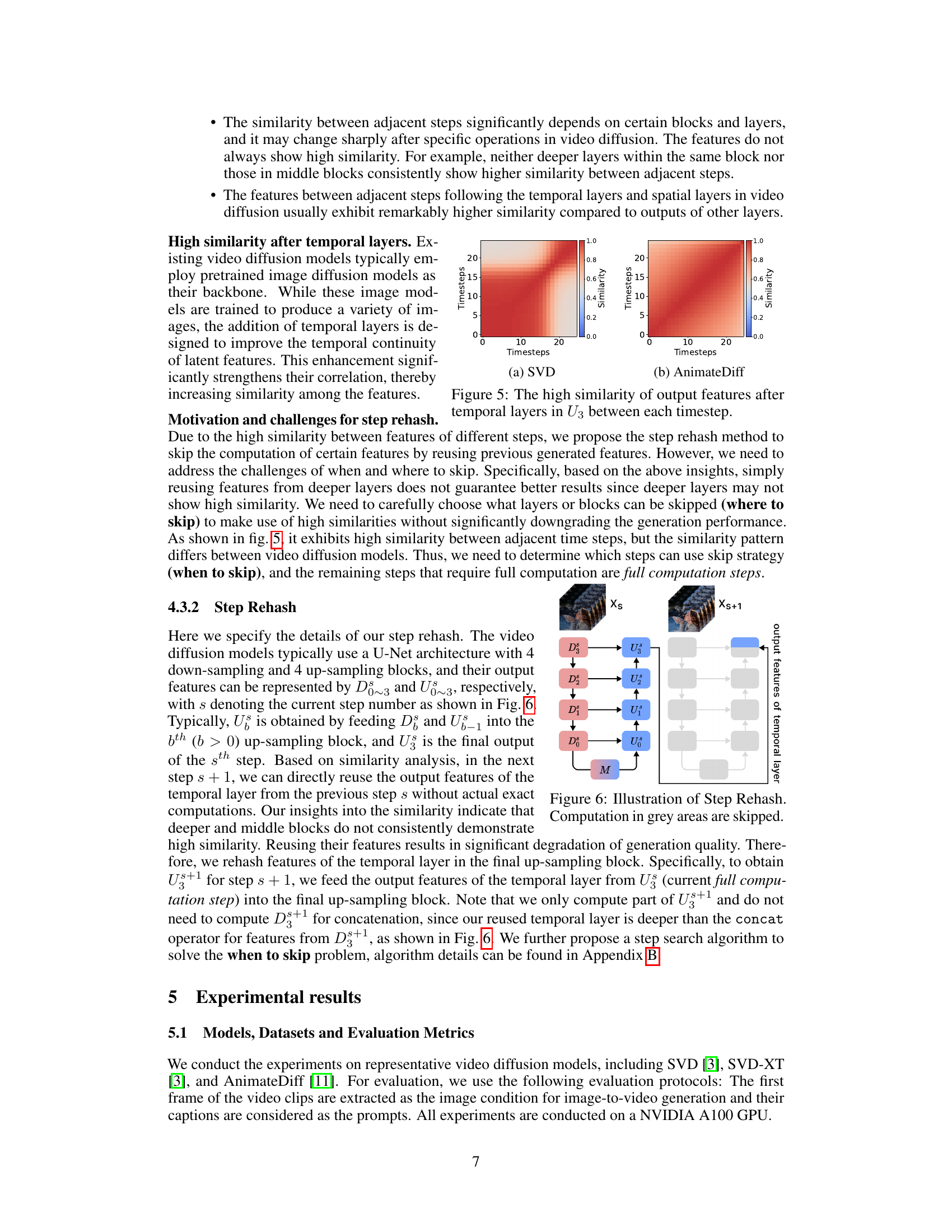
🔼 This figure shows heatmaps visualizing the similarity between output features of consecutive timesteps in the temporal layers of a U-Net architecture used in video diffusion models. The heatmaps indicate high similarity between adjacent steps, particularly in later steps, suggesting the potential for optimization by reusing or skipping unnecessary computations. The (a) SVD and (b) AnimateDiff subfigures showcase the similarity patterns for different models, highlighting the varying degrees of similarity in different parts of the models.
read the caption
Figure 5: The high similarity of output features after temporal layers in U3 between each timestep.
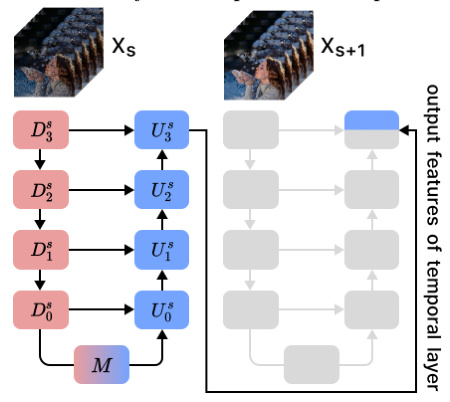
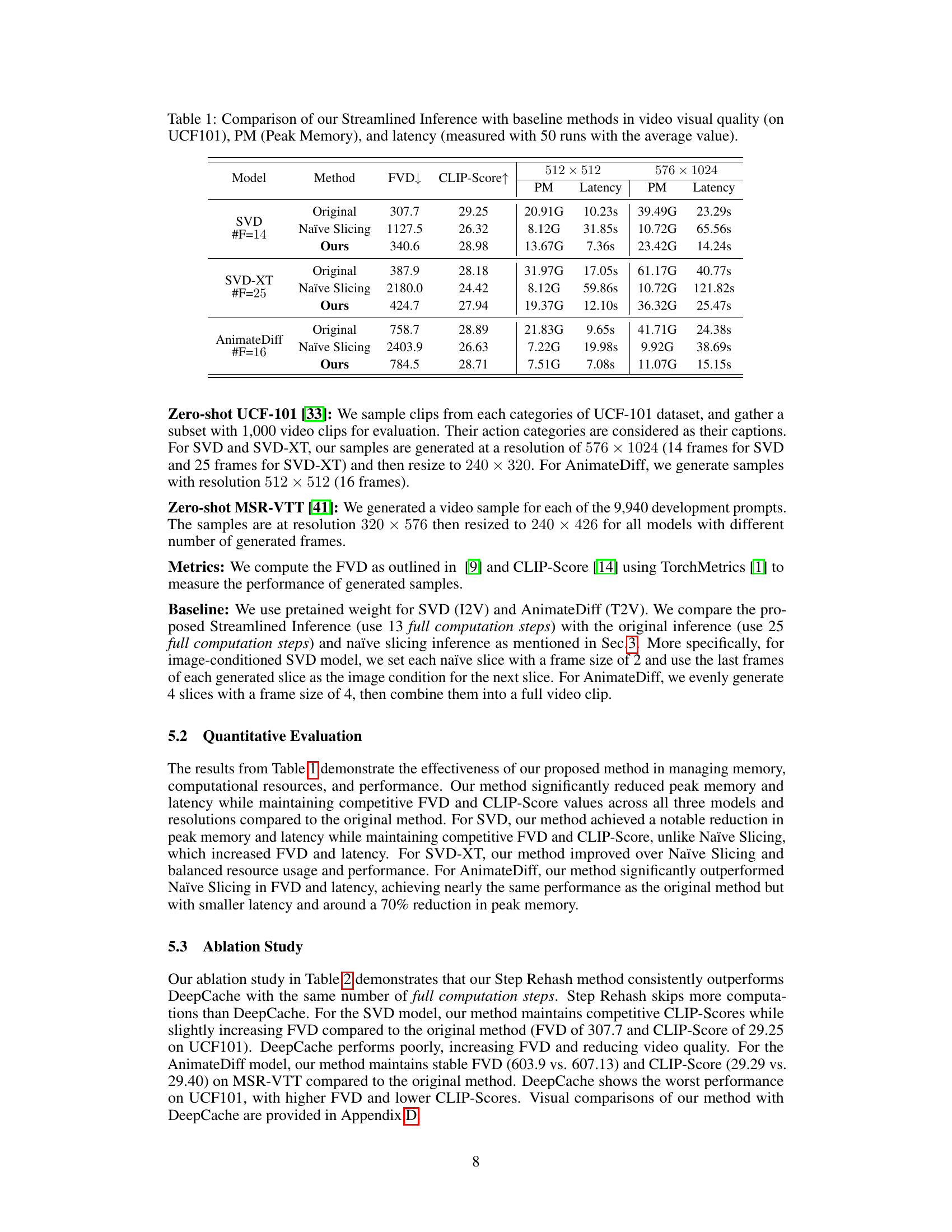
🔼 This figure illustrates the Step Rehash method used to optimize the iterative denoising process in video diffusion models. The figure shows two consecutive steps, s and s+1, in the video generation process. The U-Net architecture is depicted, showing multiple down-sampling (D) and up-sampling (U) blocks. In Step s+1, several computation blocks are shaded in gray, indicating that their computations are skipped in Step Rehash, as they reuse features from the previous step, reducing computational cost and time. The output feature of the temporal layer is highlighted in light blue.
read the caption
Figure 6: Illustration of Step Rehash. Computation in grey areas are skipped.

🔼 This figure compares the visual quality of videos generated by the proposed Streamlined Inference method with the original baseline models (AnimateDiff, SVD, and SVD-XT). It demonstrates that the proposed method produces high-quality videos comparable to the original methods across various video scenarios, including an owl and danger, children walking, and a cityscape at night.
read the caption
Figure 7: Quality evaluation of using our method on baseline models. The results show that our method can be generally applied to various video diffusion models and achieve competitive results.
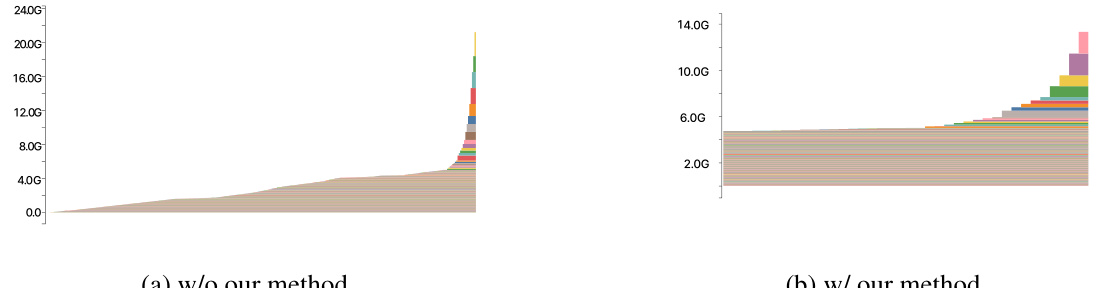
🔼 This figure shows GPU memory usage over time during the inference process for Stable Video Diffusion model with 14 frames and 512x512 resolution. It compares memory usage with and without the proposed Streamlined Inference method. The graph illustrates how the Streamlined Inference significantly reduces the peak memory consumption during video generation.
read the caption
Figure A1: GPU memory snapshot of active cached segment timeline for Stable Video Diffusion with 14 frames 512 × 512

🔼 This figure shows similarity maps of different temporal layers within the up_blocks.0.resnets of a U-Net architecture used in video diffusion models. Each subplot represents a different layer, visualizing the similarity between features at various timesteps. The color intensity represents the similarity strength, with warmer colors indicating higher similarity. The purpose is to demonstrate the varying degrees of similarity between features across different layers at consecutive timesteps, which is crucial for the effectiveness of Step Rehash in Streamlined Inference. Higher similarity allows skipping computations in Step Rehash, enhancing efficiency.
read the caption
Figure A2: Similarity maps of different temporal layers in up_blocks.0.resnets.

🔼 This figure shows a visual comparison of the results obtained using the proposed method and DeepCache. The comparison is done for three different video samples. For each sample, it includes the generated video frames using DeepCache and the proposed method. The figure visually demonstrates that the proposed method generates videos with better quality and more vivid details compared to DeepCache.
read the caption
Figure A3: Visual comparison of our method with DeepCache.

🔼 This figure compares the visual quality of video generated using the proposed Streamlined Inference method and a naive slicing method. The naive method involves processing video clips individually without considering temporal dependencies, resulting in noticeable artifacts and motion inconsistencies. The Streamlined Inference method, on the other hand, produces smoother and more coherent videos.
read the caption
Figure 3: The quality results of our method and naïve slicing. Note that naïve slicing will incur unpleasant artifacts due to lack of temporal correction by fewer frames.

🔼 This figure compares the visual quality of videos generated using the proposed Streamlined Inference method and a naive slicing approach. The naive slicing method, which processes the video clip by clip, results in noticeable artifacts due to its failure to correct for temporal inconsistencies between frames. In contrast, the proposed method maintains high video quality, illustrating the effectiveness of its temporal feature preservation.
read the caption
Figure 3: The quality results of our method and naïve slicing. Note that naïve slicing will incur unpleasant artifacts due to lack of temporal correction by fewer frames.

🔼 This figure compares the visual quality of video generated using the proposed Streamlined Inference method versus a naive slicing approach. The naive slicing method, which processes the video clip by clip without considering temporal dependencies, results in artifacts and motion inconsistencies. In contrast, the Streamlined Inference method maintains high visual quality and temporal coherence, as demonstrated by the smooth and realistic motion in the generated video.
read the caption
Figure 3: The quality results of our method and naïve slicing. Note that naïve slicing will incur unpleasant artifacts due to lack of temporal correction by fewer frames.

🔼 This figure compares the visual quality of video generated by the proposed Streamlined Inference method against a naive slicing approach. The naive approach involves processing video clips frame-by-frame, neglecting temporal coherence, which results in noticeable artifacts. In contrast, the Streamlined Inference method preserves temporal relationships, leading to smoother and more coherent video generation, which is clearly shown in the figure.
read the caption
Figure 3: The quality results of our method and naïve slicing. Note that naïve slicing will incur unpleasant artifacts due to lack of temporal correction by fewer frames.

🔼 This figure shows a visual comparison of the results obtained using the proposed method and DeepCache on several video samples. It aims to demonstrate the visual quality differences between the two methods. Each row shows a video sample, with the upper row showcasing the output from DeepCache and the lower row the result using the authors’ Streamlined Inference. The visual differences may include aspects of detail, artifacts, temporal consistency, or other visual characteristics.
read the caption
Figure A3: Visual comparison of our method with DeepCache.

🔼 This figure presents a qualitative comparison of video generation results between the original AnimateDiff model and the proposed Streamlined Inference method. It shows several examples of videos generated with both methods using the same text prompts. The purpose is to visually demonstrate the high quality of videos produced by the Streamlined Inference method, which maintains quality while significantly reducing peak memory and computation costs.
read the caption
Figure A5: Quality evaluation of using our method on baseline models.

🔼 This figure presents a qualitative comparison of video generation results between the proposed Streamlined Inference method and baseline video diffusion models (AnimateDiff). The image shows example video frames generated from several text prompts. The results demonstrate the comparable quality of videos generated by the proposed method, with reduced memory and computational overhead.
read the caption
Figure 7: Quality evaluation of using our method on baseline models. The results show that our method can be generally applied to various video diffusion models and achieve competitive results.

🔼 This figure shows a comparison of video generation results between the proposed method (Ours) and the original method (AnimateDiff). The results illustrate that the new method can produce videos of comparable quality to the original method, suggesting that it is a viable alternative that improves on efficiency while maintaining comparable quality.
read the caption
Figure 7: Quality evaluation of using our method on baseline models. The results show that our method can be generally applied to various video diffusion models and achieve competitive results.

🔼 This figure showcases a qualitative comparison of video generation results between the proposed Streamlined Inference method and baseline models (AnimateDiff). Multiple video examples are presented, each with a text prompt describing the desired scene. The goal is to demonstrate that the Streamlined Inference approach produces videos of comparable quality to those generated by existing, more computationally expensive methods. The figure aims to visually support the paper’s claim that the new method does not sacrifice video quality while achieving significant improvements in terms of memory usage and computational efficiency.
read the caption
Figure 7: Quality evaluation of using our method on baseline models. The results show that our method can be generally applied to various video diffusion models and achieve competitive results.

🔼 This figure displays a comparison of video generation results between the original AnimateDiff model and the proposed Streamlined Inference method. The images demonstrate that the Streamlined Inference method produces videos of comparable quality to the original AnimateDiff, despite a significant reduction in computational cost and memory usage, as highlighted earlier in the paper. The examples show diverse scenes, highlighting the method’s versatility.
read the caption
Figure 7: Quality evaluation of using our method on baseline models. The results show that our method can be generally applied to various video diffusion models and achieve competitive results.

🔼 This figure compares the visual quality of videos generated using the proposed Streamlined Inference method and a naive slicing approach. The naive slicing method, which processes video clips independently, introduces artifacts and motion inconsistencies due to the lack of temporal context across frames. The Streamlined Inference method, on the other hand, maintains consistent visual quality by properly handling temporal dependencies.
read the caption
Figure 3: The quality results of our method and naïve slicing. Note that naïve slicing will incur unpleasant artifacts due to lack of temporal correction by fewer frames.

🔼 This figure presents a visual comparison of video generation results between the baseline AnimateDiff model and the proposed method. For several different video prompts, both methods generated short video clips. The images show that the proposed method produces results with slightly improved visual quality compared to AnimateDiff, though the differences are subtle. The improved visual quality is particularly noticeable in the detail and clarity of the objects and background.
read the caption
Figure A5: Quality evaluation of using our method on baseline models.

🔼 This figure presents a qualitative comparison of video generation results between the proposed Streamlined Inference method and the baseline AnimateDiff model. For several different video prompts, it shows the output videos generated by each approach. The purpose is to visually demonstrate the quality of videos produced by Streamlined Inference, showcasing its ability to generate high-quality results comparable to or exceeding those of AnimateDiff, while requiring less computation and memory.
read the caption
Figure A7: Quality evaluation of using our method on baseline models.

🔼 This figure shows a qualitative comparison of video generation results between the proposed Streamlined Inference method and baseline methods (SVD and SVD-XT). Each row presents results for a different video generation task (different prompts), with the left column showing results from the baseline method and the right column showing the results from Streamlined Inference. The aim is to visually demonstrate the comparable quality of videos generated by the proposed method while achieving significant memory and computational savings. The visual quality appears very similar between the two approaches for each task.
read the caption
Figure A8: Quality evaluation of using our method on baseline models.
More on tables
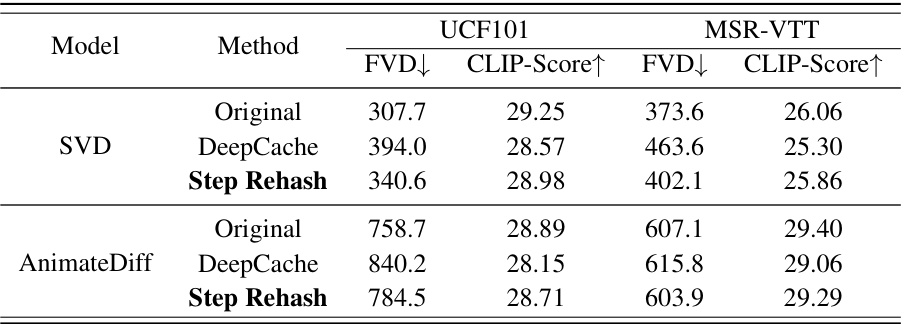
🔼 This table presents the ablation study comparing the proposed method with DeepCache on video visual quality using UCF101 and MSR-VTT datasets. Both methods use 13 full computation steps. The results show the FVD (Fréchet Video Distance) and CLIP-Score for each method and dataset, demonstrating the performance of Step Rehash compared to DeepCache and the baseline model.
read the caption
Table 2: Ablation study of our proposed method compared with DeepCache in video visual quality. Both our Step Rehash and DeepCache involve 13 full computation steps.

🔼 This table compares the performance of the proposed Streamlined Inference method against baseline methods (original, naïve slicing) for three different video generation models (SVD, SVD-XT, AnimateDiff) at two different resolutions (512x512, 576x1024). The comparison includes Fréchet Video Distance (FVD), CLIP score, peak memory (PM) usage, and inference latency. Lower FVD and higher CLIP scores indicate better visual quality. Lower PM and latency values represent better memory efficiency and speed.
read the caption
Table 1: Comparison of our Streamlined Inference with baseline methods in video visual quality (on UCF101), PM (Peak Memory), and latency (measured with 50 runs with the average value).
Full paper#