↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing generalizable novel view synthesis (GNVS) methods heavily rely on epipolar priors for cross-view correspondence, which often fail in complex scenes with occlusions or non-overlapping regions. This paper tackles the limitation of unreliable epipolar priors, a significant challenge in reconstructing realistic 3D scenes from sparse observations.
The authors propose eFreeSplat, a feed-forward 3D Gaussian splatting-based model that operates independently of epipolar constraints. It achieves this by employing a self-supervised Vision Transformer for robust 3D perception and an iterative cross-view Gaussians alignment method to ensure consistent depth scales. eFreeSplat demonstrates superior performance on benchmark datasets, outperforming existing state-of-the-art methods in terms of geometry reconstruction and novel view synthesis quality, particularly in challenging scenarios.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in 3D vision and computer graphics because it introduces a novel, epipolar-free approach to novel view synthesis. This addresses a key limitation of existing methods, which often struggle in complex real-world scenarios with occlusions or non-overlapping views. The proposed method, eFreeSplat, enables more robust and generalizable novel view synthesis, opening up new avenues of research in realistic scene reconstruction and virtual/augmented reality applications.
Visual Insights#
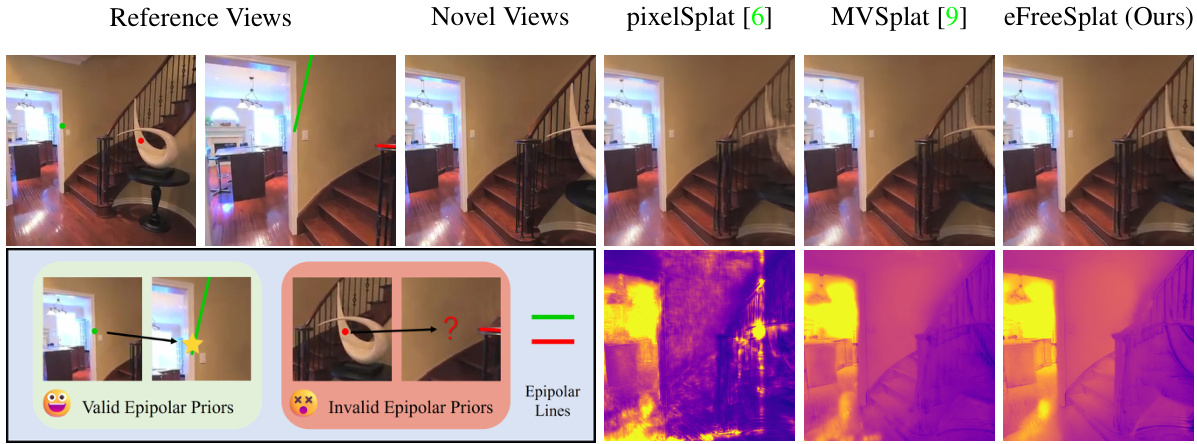
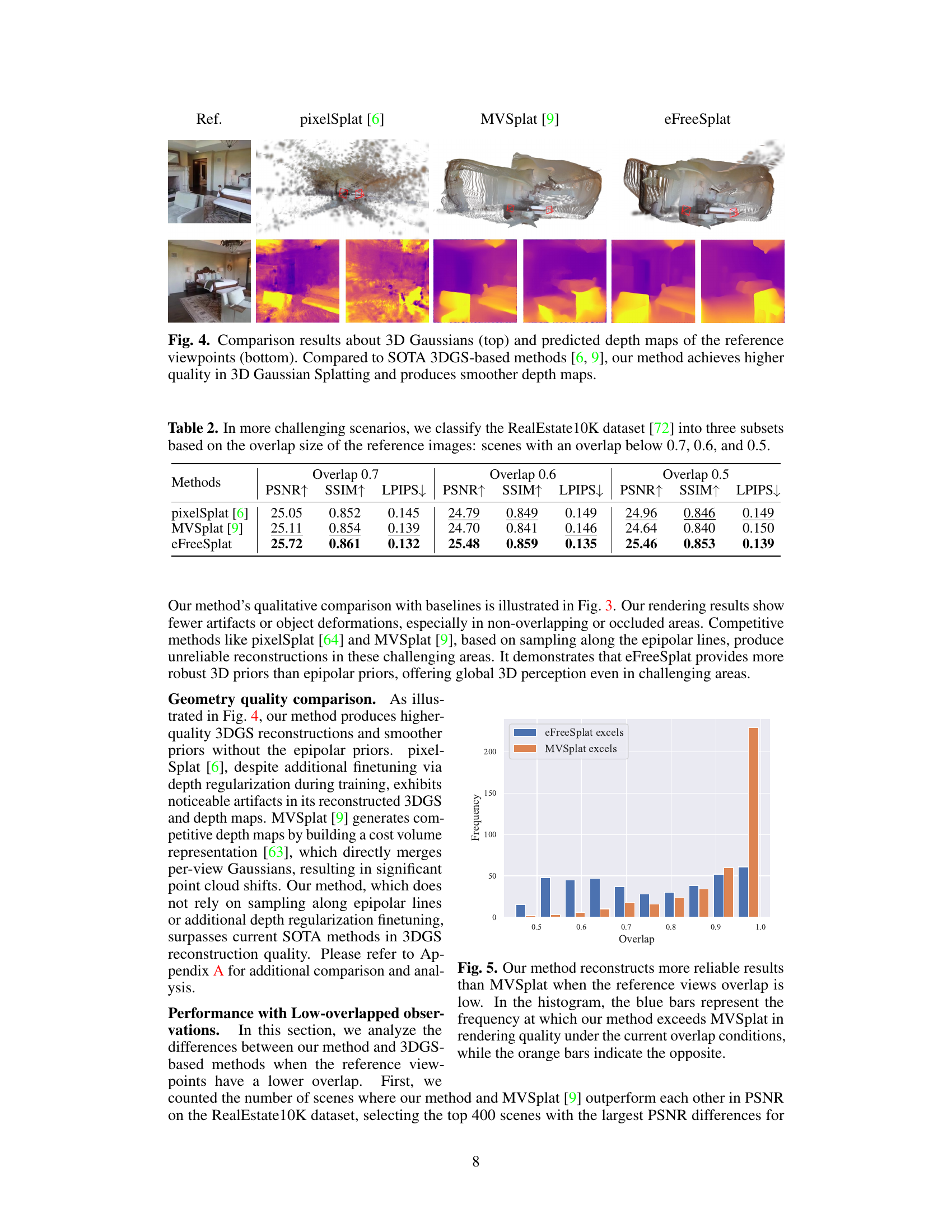
This figure illustrates the limitations of epipolar priors in novel view synthesis, especially in scenes with sparse views or occlusions. The top row shows reference views and a novel view generated by three different methods: pixelSplat, MVSplat, and the authors’ proposed method, eFreeSplat. The bottom row provides a visual explanation of the problem. The left image shows a case where epipolar priors are valid and reliable for establishing correspondences between views. The middle image demonstrates a situation where epipolar priors fail due to occlusion and sparsity. The corresponding depth maps generated by the three methods showcase the differences in performance. eFreeSplat shows more robust results, highlighting its advantage of not relying on epipolar lines.
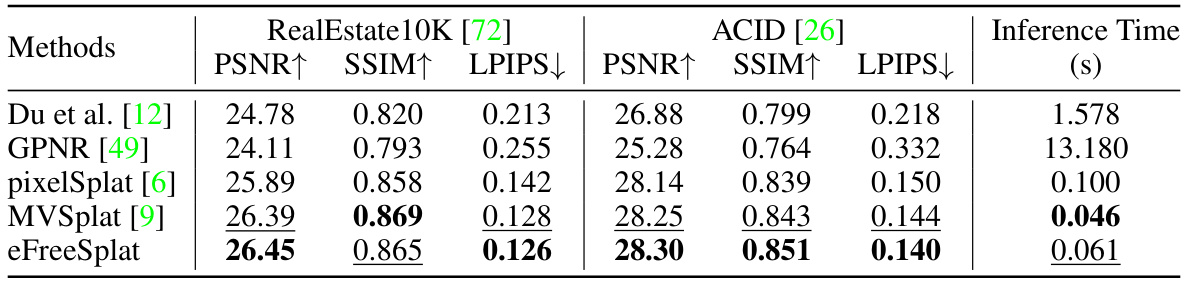
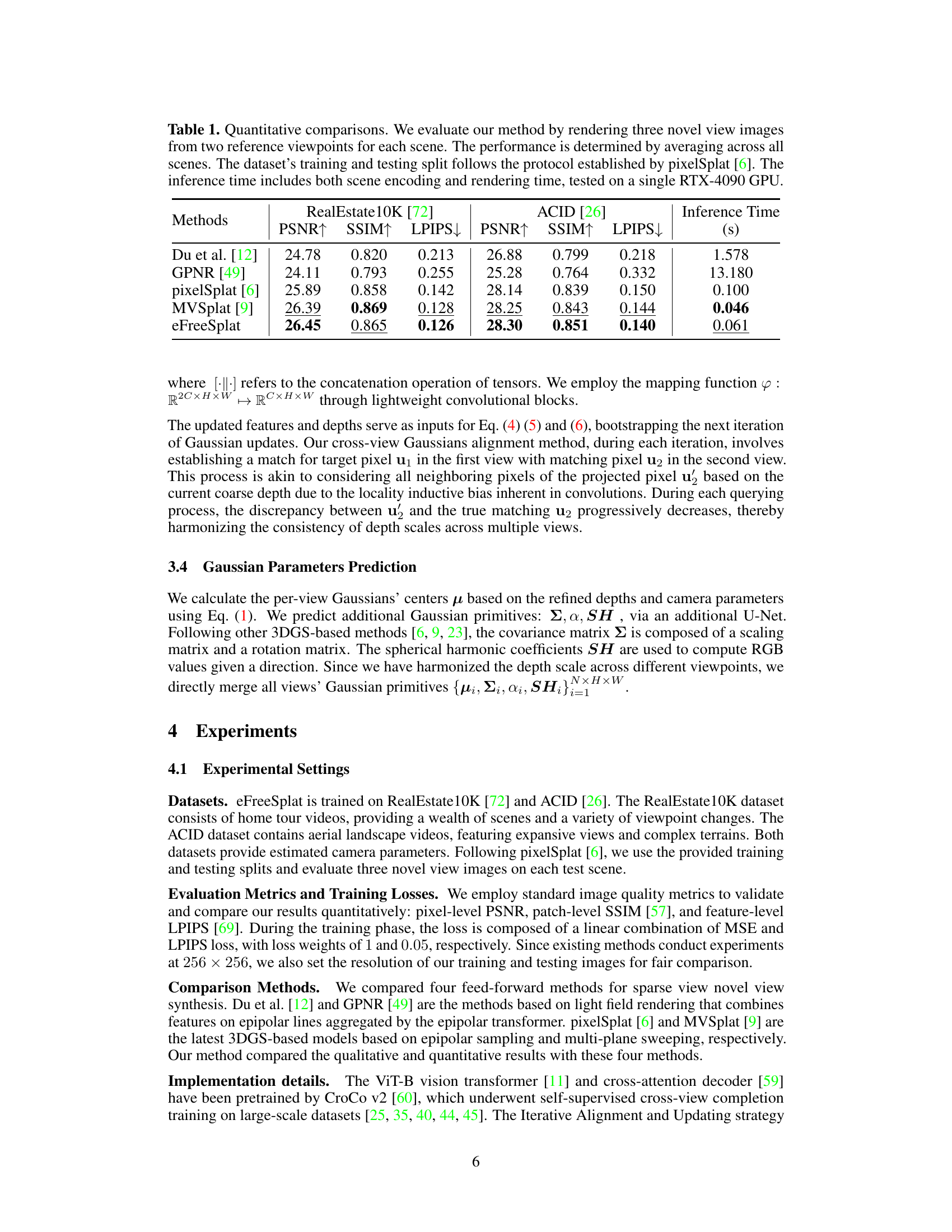
This table presents a quantitative comparison of the proposed eFreeSplat method against several state-of-the-art baselines on two benchmark datasets (RealEstate10K and ACID). The metrics used for evaluation are PSNR, SSIM, and LPIPS, which measure the quality of the novel view synthesis. The inference time on a single RTX 4090 GPU is also reported.
In-depth insights#
Epipolar-Free GNVS#
Epipolar-Free GNVS presents a significant advancement in generalizable novel view synthesis by mitigating the limitations of traditional methods that heavily rely on epipolar geometry. Existing GNVS approaches often struggle with sparse or non-overlapping views, where epipolar constraints are unreliable. Epipolar-Free GNVS addresses this by leveraging a self-supervised Vision Transformer for enhanced multiview feature extraction and a novel iterative cross-view Gaussian alignment method. This approach enables consistent depth scales across views without explicit epipolar priors. The resulting feed-forward 3D Gaussian splatting model demonstrates superior generalization capabilities, particularly in complex real-world scenarios with occlusions. This work represents a pivotal shift towards more robust and versatile GNVS techniques, expanding their applicability to challenging scenes previously considered intractable.
3D Gaussian Splatting#
3D Gaussian splatting is a novel method for 3D scene representation that utilizes millions of learnable 3D Gaussian primitives to explicitly map spatial coordinates to pixel values. This approach enhances rendering efficiency and quality, surpassing traditional methods like neural fields and volume rendering. Unlike early methods demanding dense views, 3D Gaussian splatting allows for efficient real-time rendering and editing with minimized computational demands, making it particularly well-suited for applications requiring quick turnaround times. However, existing methods heavily rely on epipolar priors, which can be unreliable in complex real-world scenes with non-overlapping or occluded regions. Recent advancements focus on addressing this limitation through geometry-free approaches and data-driven 3D priors, enhancing multiview feature extraction while ensuring consistent depth scales. This has led to the development of more generalizable models capable of reconstructing new scenes from sparse views without the need for scene-specific retraining. The focus on feed-forward inference eliminates the need for per-scene back-propagation, leading to significantly improved efficiency and rendering quality.
Cross-View Alignment#
Cross-view alignment in multi-view 3D reconstruction aims to establish consistent correspondences between features observed from different viewpoints. This is crucial because variations in camera positions, lighting, and occlusions create discrepancies that hinder accurate 3D model generation. Effective cross-view alignment techniques must robustly handle these challenges. Epipolar geometry, often used in traditional methods, provides a strong constraint but struggles with sparse or non-overlapping views. Modern approaches leverage deep learning, employing techniques like self-attention or cost volume aggregation to learn feature correspondences implicitly from data. Iterative refinement is a common strategy to improve alignment accuracy. A key challenge lies in achieving scale consistency across different views. This requires careful handling of depth estimation and feature scaling. Ultimately, the success of cross-view alignment significantly impacts the quality of the final 3D reconstruction, influencing both geometric accuracy and surface details.
Ablation Study Insights#
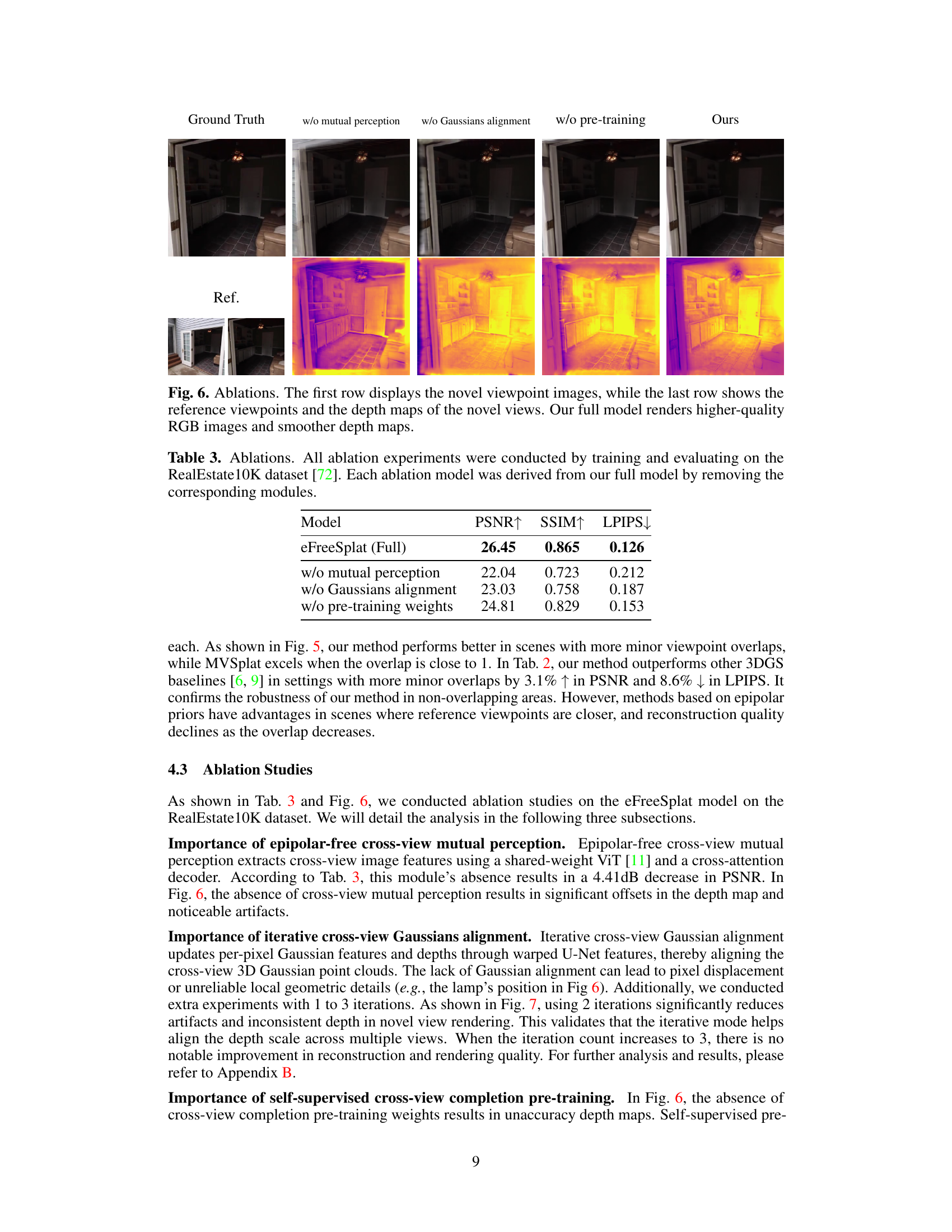
Ablation studies systematically remove components of a model to assess their individual contributions. In this context, removing the epipolar-free cross-view mutual perception module significantly reduced performance, highlighting its importance in establishing robust 3D scene understanding without relying on potentially unreliable epipolar constraints. Similarly, eliminating the iterative cross-view Gaussian alignment negatively impacted results, demonstrating the necessity of consistent depth scales across views for accurate 3D reconstruction. The ablation of pre-training weights also yielded a noticeable drop in performance, emphasizing the value of the self-supervised learning phase in capturing global 3D scene priors from large-scale datasets. Overall, the ablation study clearly indicates that each module plays a crucial role in achieving the model’s superior performance, particularly in challenging scenarios with sparse and/or non-overlapping views.
Future Work Directions#
Future research could explore extending eFreeSplat to handle more complex scenes with significant occlusions or challenging lighting conditions. Improving the robustness of the depth estimation, particularly in areas with low texture or repetitive patterns, is crucial. Investigating alternative alignment strategies beyond ICGA, potentially incorporating more sophisticated feature matching techniques, could enhance accuracy and efficiency. Exploring different 3D representation methods beyond Gaussian splatting could also lead to improvements in rendering quality or generalization capabilities. The model’s reliance on a pre-trained ViT could be addressed by exploring self-supervised or semi-supervised training methods directly integrated within the eFreeSplat architecture. Finally, assessing the model’s performance on significantly larger and more diverse datasets would help determine its true generalizability and identify any limitations in handling a broader range of visual complexities.
More visual insights#
More on figures
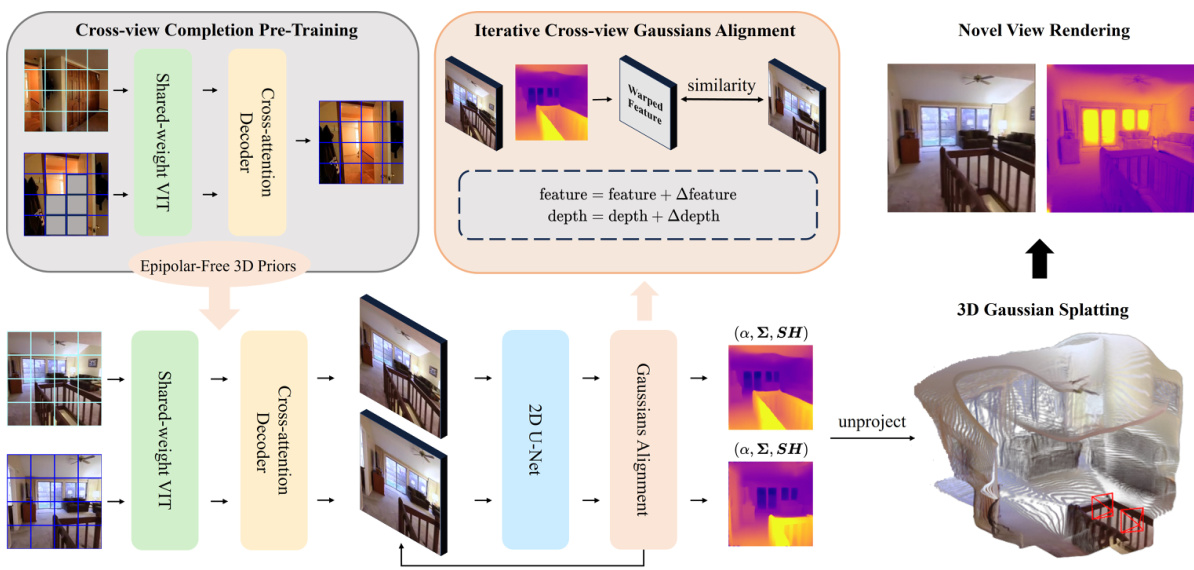
This figure provides a detailed overview of the eFreeSplat architecture. It is divided into three main stages: Epipolar-free Cross-view Mutual Perception, Iterative Cross-view Gaussians Alignment, and Novel View Rendering. The first stage uses a Vision Transformer (ViT) to extract 3D priors without relying on epipolar lines. The second stage iteratively refines Gaussian attributes to ensure consistent depth scales. Finally, the third stage uses 3D Gaussian splatting to generate the novel view images.

This figure shows qualitative comparisons of novel view synthesis results on RealEstate10K and ACID datasets. The results from the proposed method (eFreeSplat) are compared to three other state-of-the-art methods (Du et al., pixelSplat, and MVSplat). Red boxes highlight areas where eFreeSplat shows improved results, specifically in challenging non-overlapping and occluded regions. The ground truth images are also provided for reference.

This figure shows qualitative comparisons of novel view synthesis results between eFreeSplat and other state-of-the-art methods on the RealEstate10K and ACID datasets. Red boxes highlight areas where eFreeSplat demonstrates superior performance by producing fewer artifacts, especially in challenging scenarios with non-overlapping or occluded regions. The results showcase eFreeSplat’s ability to generate high-quality novel views without relying on epipolar priors, which are unreliable in such complex situations.

This figure shows a histogram that compares the performance of eFreeSplat and MVSplat across different levels of overlap between reference views. The x-axis represents the overlap percentage, and the y-axis represents the frequency with which each method produced superior rendering quality (measured in PSNR). The blue bars show the frequency of eFreeSplat outperforming MVSplat, while the orange bars indicate the opposite. It demonstrates that eFreeSplat is particularly advantageous when the overlap between reference views is low.

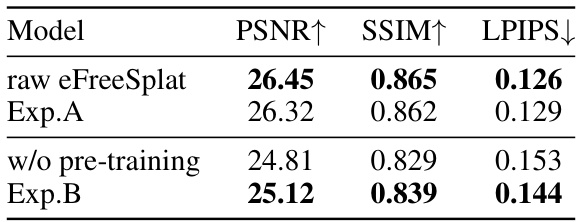
This figure shows failure cases of the proposed method, eFreeSplat. It demonstrates that when the input viewpoints are very close (high overlap), the method produces less reliable results. Experiments A and B explore fine-tuning the CroCo model on the RE10k dataset to mitigate this issue; showing improved results in Experiments A and B.

This figure shows a qualitative comparison of novel view synthesis results between eFreeSplat and other state-of-the-art methods on the RealEstate10K and ACID datasets. The results demonstrate eFreeSplat’s superior performance in handling challenging scenarios such as non-overlapping and occluded regions, highlighting its robustness and ability to generate high-quality novel views without relying on epipolar priors.

This figure shows a qualitative comparison of novel view synthesis results between the proposed method (eFreeSplat) and several state-of-the-art baselines on the RealEstate10K and ACID datasets. The results demonstrate that eFreeSplat produces fewer artifacts, especially in challenging scenarios with non-overlapping or occluded regions, by avoiding reliance on unreliable epipolar priors.
This figure presents a qualitative comparison of novel view synthesis results between eFreeSplat and other state-of-the-art methods on the RealEstate10K and ACID datasets. The images show that eFreeSplat generates fewer artifacts, particularly in challenging areas with non-overlapping or occluded regions, demonstrating its improved performance over methods relying on epipolar priors.

This figure shows qualitative results of novel view synthesis on RealEstate10K and ACID datasets. The top rows display the reference views, followed by results from different methods (Du et al., pixelSplat, MVSplat, and eFreeSplat). The ground truth is shown in the last column. Red boxes highlight areas where eFreeSplat shows improvement over other methods. The results demonstrate eFreeSplat’s superior performance, especially in non-overlapping or occluded areas, where epipolar priors are unreliable.

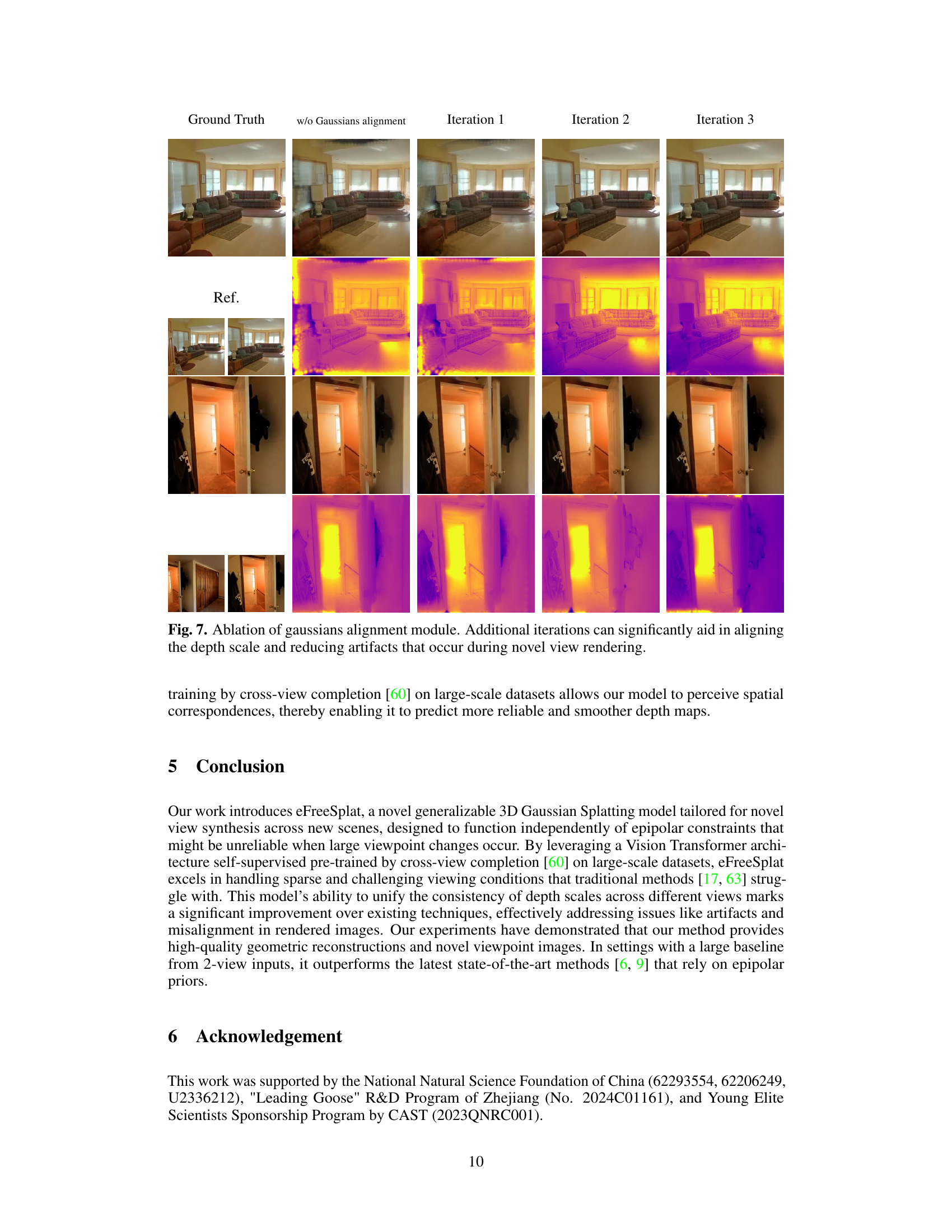
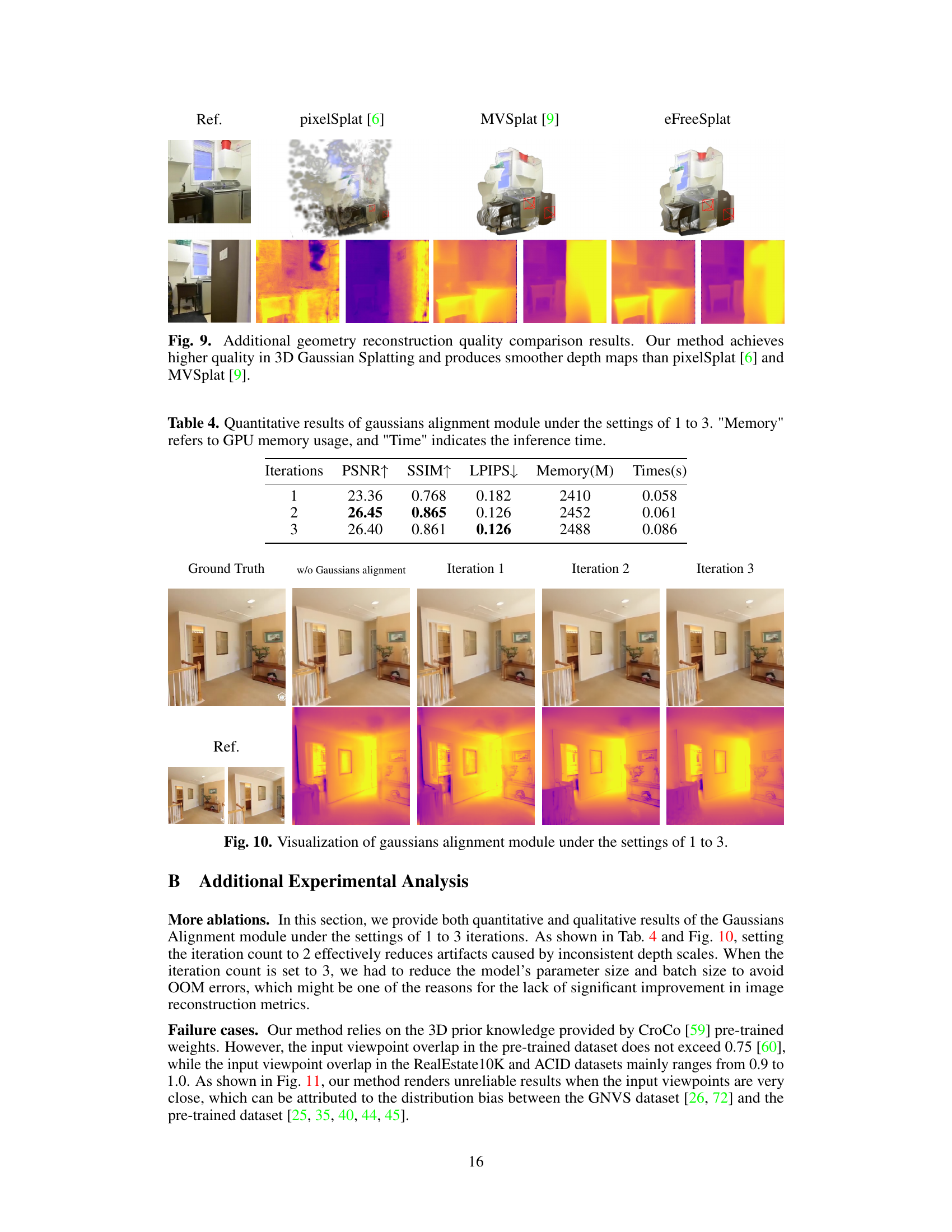
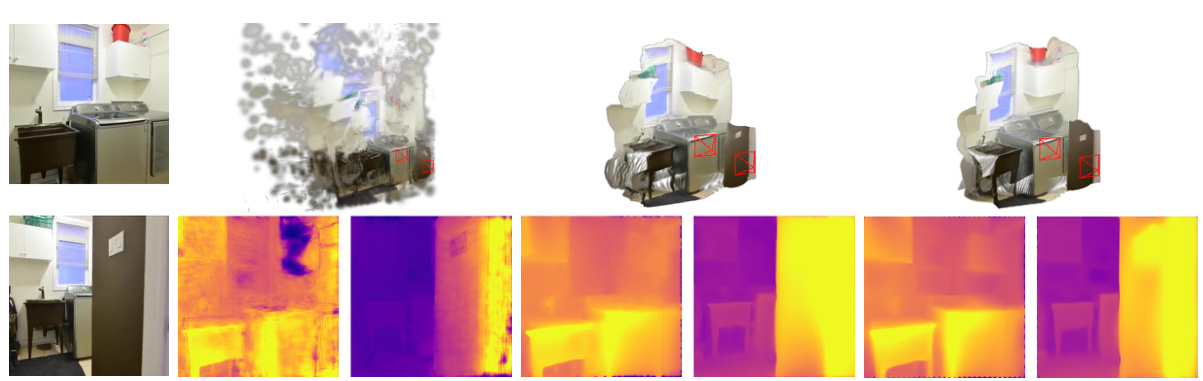
This figure shows the ablation study on the Gaussian alignment module. It compares the results of novel view rendering with different numbers of iterations in the alignment process (1, 2, and 3 iterations). The top row displays the generated novel view images, and the bottom row shows the corresponding depth maps. The results demonstrate that increasing the number of iterations improves the quality of the depth maps by reducing artifacts and better aligning the depth scale across different views, leading to better novel view synthesis. The
w/o Gaussians alignmentcolumn serves as a baseline, highlighting the impact of the module.
More on tables

This table presents a quantitative comparison of the proposed eFreeSplat method against baseline methods (pixelSplat and MVSplat) on the RealEstate10K dataset. The comparison is performed under three different conditions based on the amount of overlap between the reference images. The overlap is categorized into three subsets: below 0.7, 0.6, and 0.5. The table reports PSNR, SSIM, and LPIPS scores for each method and overlap level, demonstrating the performance of each method under varying degrees of image overlap.
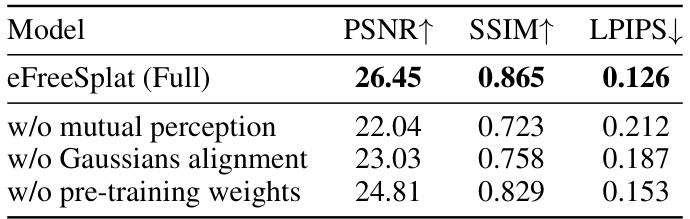
This table presents the results of ablation studies conducted on the eFreeSplat model using the RealEstate10K dataset. It shows the impact of removing key components of the model, such as the cross-view mutual perception, Gaussian alignment, and pre-training weights, on the model’s performance, as measured by PSNR, SSIM, and LPIPS.
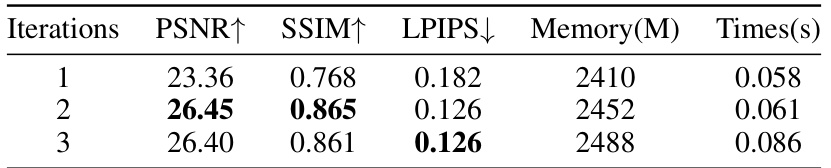
This table presents a quantitative analysis of the Iterative Cross-view Gaussians Alignment module’s performance at different iteration counts (1, 2, and 3). The metrics evaluated include Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), GPU memory usage (Memory), and inference time (Time). Higher PSNR and SSIM values, and lower LPIPS values indicate better image quality. The results show that increasing the number of iterations generally improves image quality, although diminishing returns are observed beyond 2 iterations.
This table presents the ablation study results conducted on the RealEstate10K dataset. It shows the performance (PSNR, SSIM, LPIPS) of the full eFreeSplat model and three ablation models. The ablation models progressively remove key components of the model: the cross-view mutual perception module, the Gaussian alignment module, and the pretrained weights. The results demonstrate the contribution of each component to the overall performance.
Full paper#