↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current multimodal large language models (MLLMs) primarily focus on linguistic advancements, neglecting the potential of visual encoders which are often treated as static feature extractors. This paper identifies this limitation and proposes a solution called the Dense Connector. The challenge lies in fully leveraging the rich information contained within various layers of visual encoders, rather than simply relying on the final high-level features. This leads to the underperformance of the visual component of MLLMs.
The Dense Connector is a novel, plug-and-play module designed to address this issue. It efficiently integrates multi-layer visual features into the MLLM, enhancing its visual understanding capabilities. Through various implementations (Sparse Token Integration, Sparse Channel Integration, Dense Channel Integration), the connector is shown to be compatible with diverse LLMs and visual encoders, leading to state-of-the-art results in various image and video benchmarks. The simplicity, effectiveness, and scalability of the Dense Connector make it a promising module for future MLLM development.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the under-utilization of visual encoders in large multimodal language models (MLLMs). By proposing a simple yet effective Dense Connector that leverages multi-layer visual features, it significantly improves the performance of existing MLLMs with minimal computational overhead. This opens up new avenues for research in MLLM development, particularly in enhancing the effectiveness of visual encoders, and could greatly impact the efficiency and capabilities of future MLLMs. The plug-and-play nature of the Dense Connector makes it easily adaptable to various existing MLLM architectures and visual encoders, increasing its applicability and potential impact.
Visual Insights#

This figure visualizes the attention maps across different layers of a ViT-L model, showcasing how different layers focus on different regions of interest. It also compares the visual embeddings obtained using only the final layer of the visual encoder versus using a Dense Connector that leverages multi-layer visual features. Finally, it illustrates the plug-and-play nature of the Dense Connector, showing how it can be easily integrated into existing MLLMs to enhance their performance. The radar chart shows the improved performance of the Dense Connector across multiple vision-language benchmarks.
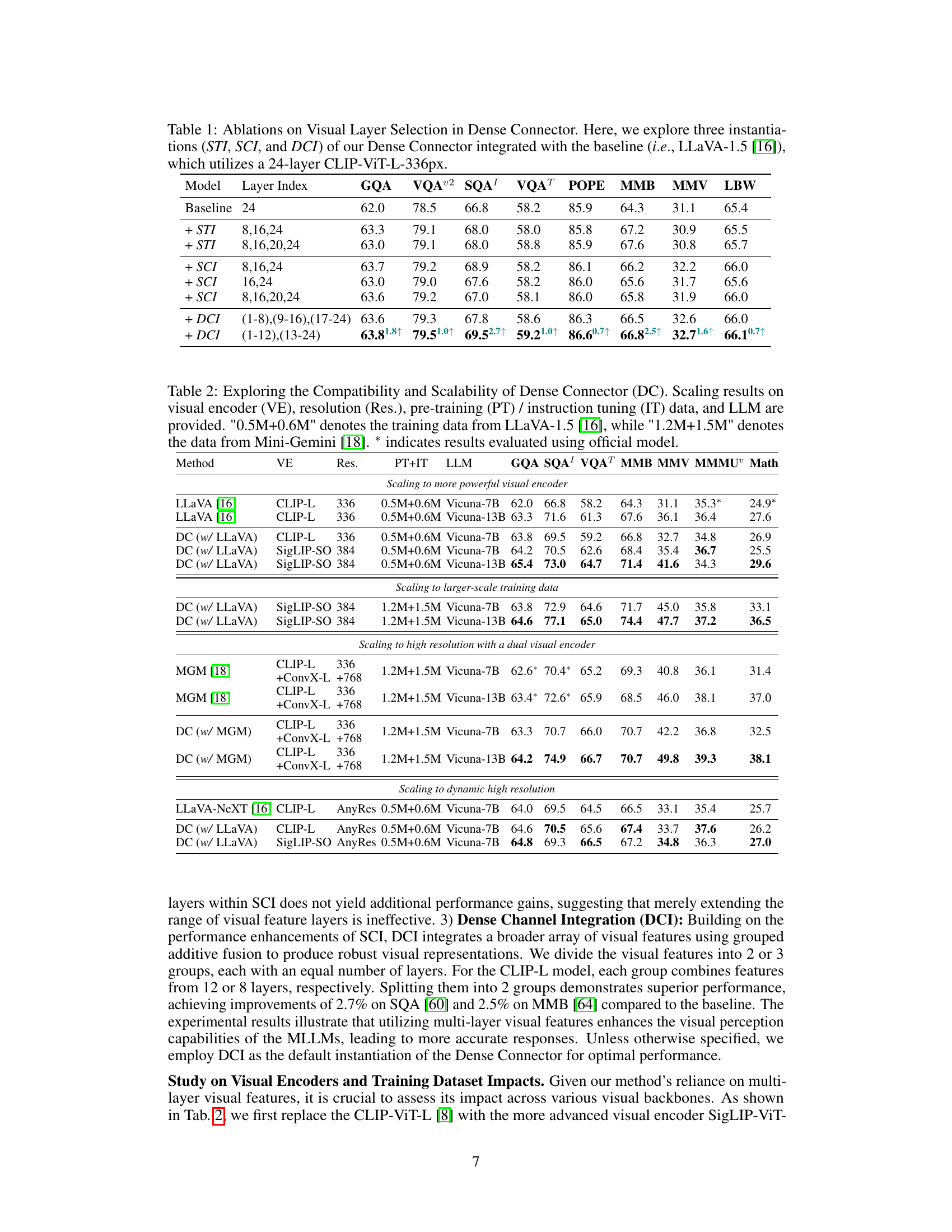
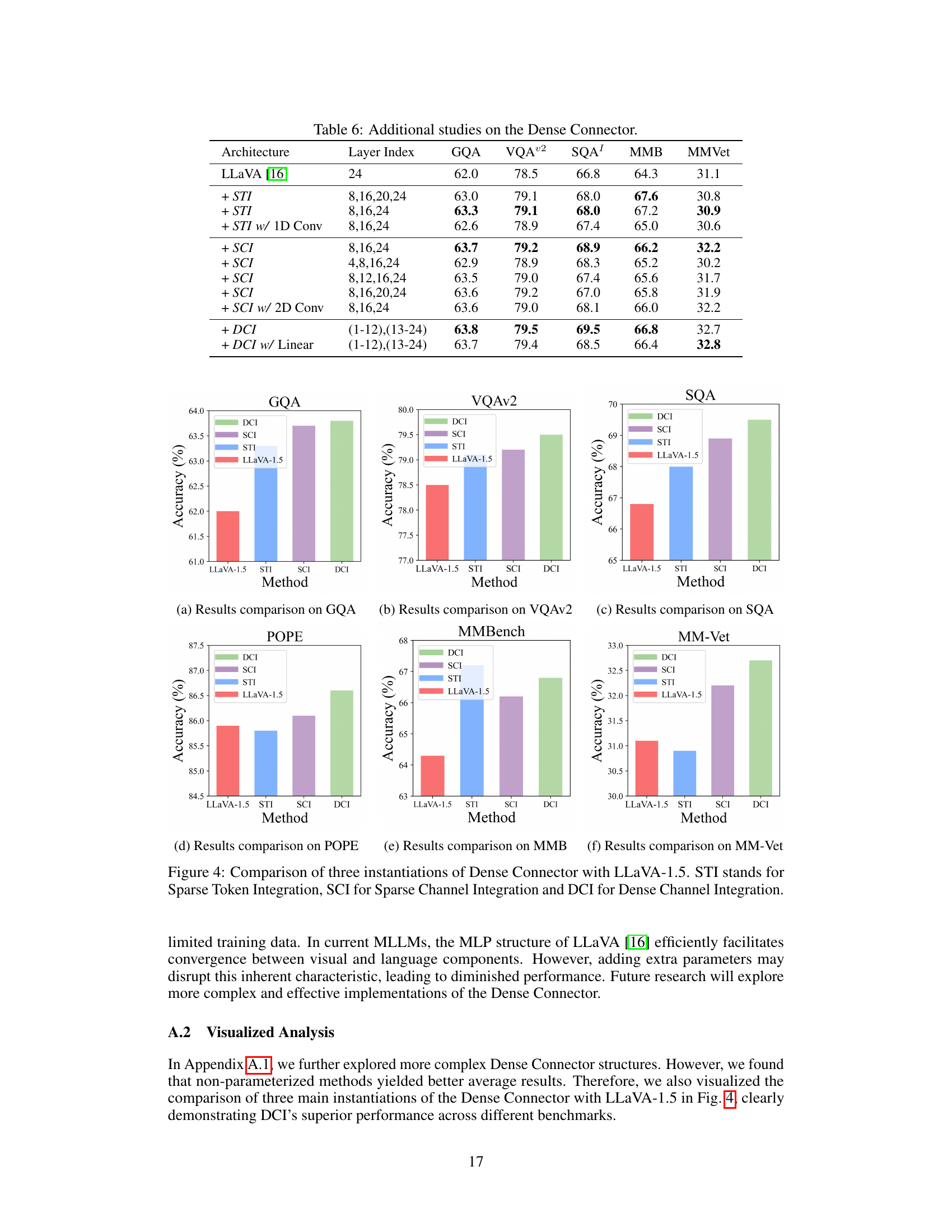
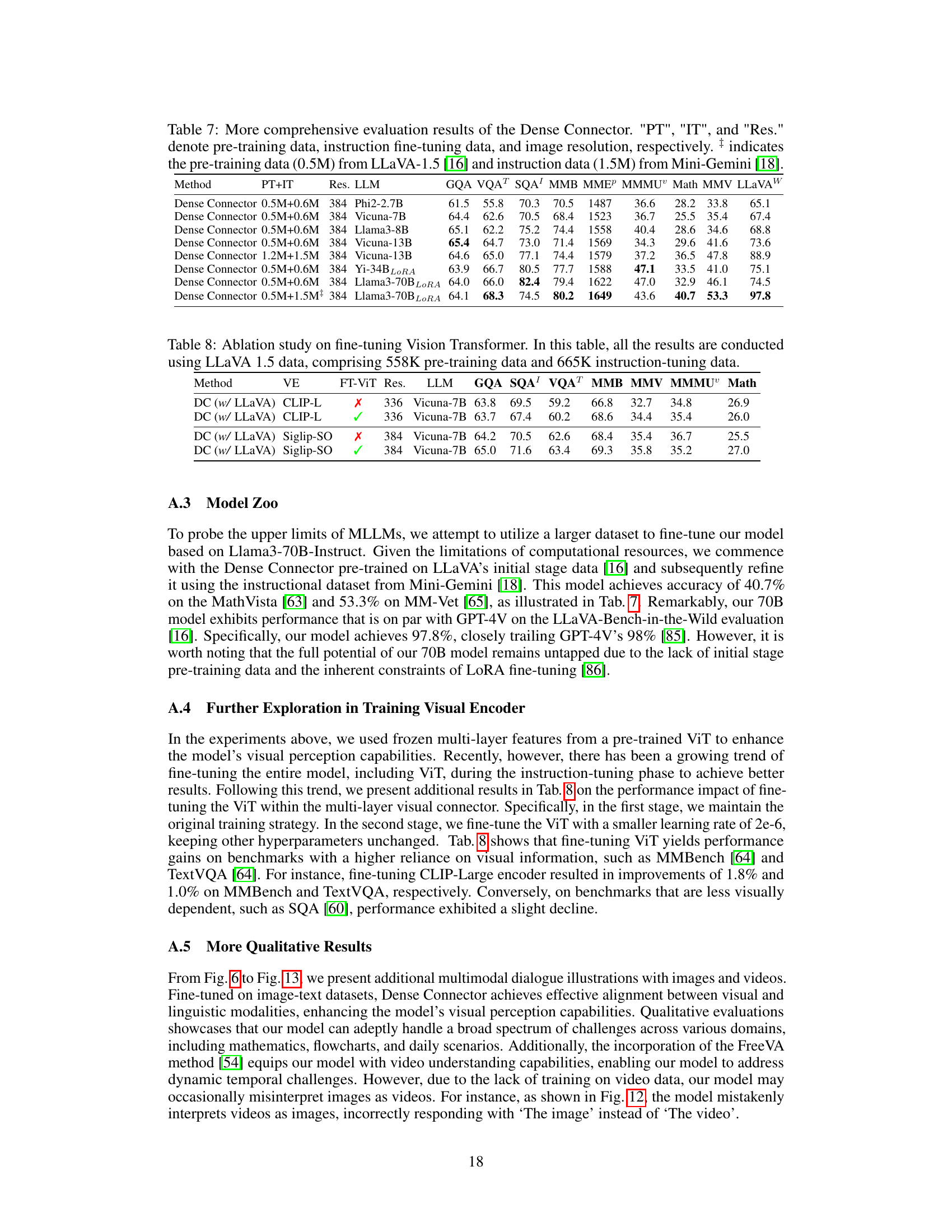
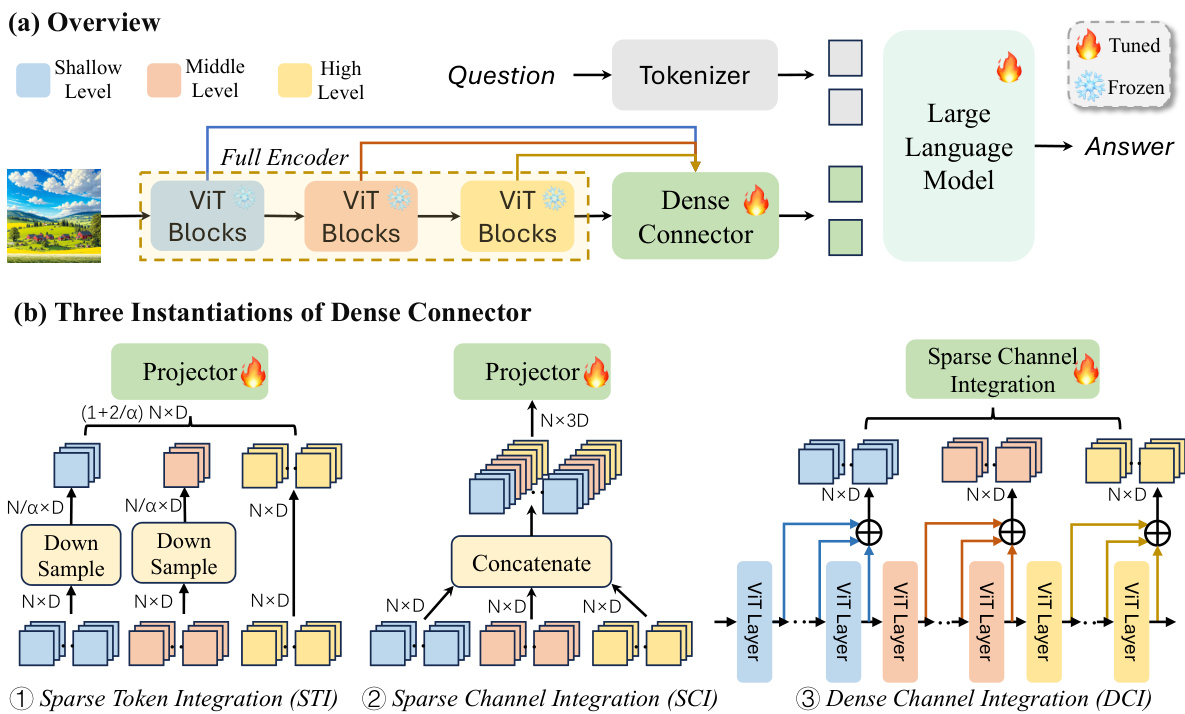
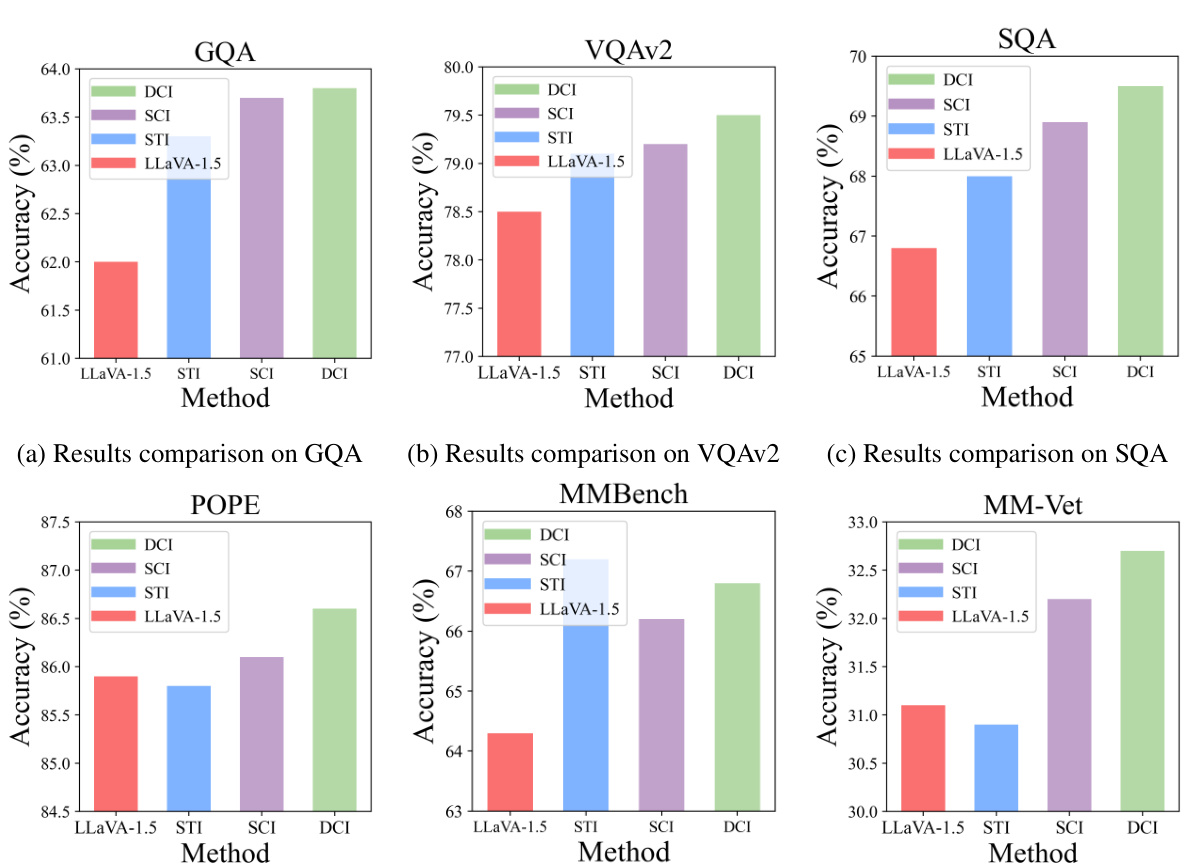
This table presents an ablation study on the selection of visual layers used in the Dense Connector. It compares the performance of three different Dense Connector instantiations (Sparse Token Integration (STI), Sparse Channel Integration (SCI), and Dense Channel Integration (DCI)) against a baseline model (LLaVA-1.5 using a 24-layer CLIP-ViT-L-336px visual encoder). The table shows the performance of each method across multiple image benchmarks (GQA, VQA02, SQA, VQAT, POPE, MMB, MMV, LBW), highlighting the impact of different layer combinations on the overall accuracy. Different layer combinations are tested for each instantiation method to find the optimal configuration.
In-depth insights#
Multi-layer Visuals#
Utilizing multi-layer visual features significantly enhances the performance of multimodal large language models (MLLMs). Frozen visual encoders, a common practice in MLLMs, typically only leverage high-level visual features. This approach overlooks the rich information contained in intermediate layers. By incorporating features from various layers, we gain a more holistic and nuanced representation of the visual input, enabling the model to better understand and reason about the context. This technique results in a more comprehensive visual understanding, allowing the MLLM to capture both detailed and high-level visual information, leading to improved performance across various downstream tasks. The approach is plug-and-play, easily integrated into existing MLLMs, and offers significant performance benefits with minimal computational overhead. The integration of multi-layer visual features provides a richer, more complete picture to the LLM, thus improving its overall capabilities.
Dense Connector#
The proposed Dense Connector significantly enhances multimodal large language models (MLLMs) by effectively leveraging multi-layer visual features from pre-trained visual encoders. This simple, plug-and-play module doesn’t require additional training or parameters, making it highly efficient and versatile. The core idea is to overcome the limitation of using only final high-level visual features, integrating information from various layers to provide richer visual cues to the LLM. Three instantiations (Sparse Token, Sparse Channel, and Dense Channel Integration) are explored, each offering a unique approach to integrating these multi-layer features, demonstrating adaptability across diverse model architectures and scales. The results show state-of-the-art performance on multiple image and video benchmarks, highlighting the effectiveness and scalability of Dense Connector. It’s a noteworthy contribution for its simplicity, efficiency, and broad applicability in enhancing existing MLLMs.
Efficient Design#
An efficient design in a research paper could explore methods to optimize resource utilization, minimize computational costs, and enhance the overall performance of a system or algorithm. This might involve algorithmic optimizations, such as using faster algorithms or data structures, or architectural improvements, such as using a more efficient hardware or software infrastructure. A key aspect of efficient design is to identify and mitigate bottlenecks, thereby improving processing speed and reducing energy consumption. Scalability is another critical factor; the design should be adaptable to handle increasing data volumes and user loads without significant performance degradation. The evaluation of an efficient design would typically involve benchmarking and comparative analysis against existing solutions, demonstrating clear advantages in terms of speed, resource usage, and energy efficiency. Ultimately, a successful efficient design balances performance, resource consumption, and implementation cost.
Video Extension#
Extending a model trained on images to handle videos presents unique challenges. A naive approach of simply feeding consecutive frames might not capture temporal dependencies effectively. A successful video extension strategy likely involves incorporating temporal context, perhaps through recurrent neural networks (RNNs) or transformers with temporal attention mechanisms. The choice of video representation is crucial, with options including raw pixel data, optical flow, or pre-computed features. Moreover, effective extension strategies must consider computational cost, since processing video data is significantly more demanding than image data. Therefore, efficient architectures or feature extraction techniques are essential. Finally, evaluating a video extension requires careful selection of benchmarks that accurately reflect the desired capabilities; zero-shot performance on existing video datasets can be a useful starting point, but specific tasks such as video question answering, action recognition, or temporal localization could offer more detailed insights. The success of any video extension heavily relies on effective adaptation strategies to handle the temporal dimension.
Future Work#
Future research directions stemming from this paper could involve exploring more efficient ways to integrate multi-layer visual features, potentially through novel architectures or loss functions. Investigating the impact of different visual encoder architectures beyond CLIP and SigLIP would also be valuable, testing the Dense Connector’s generalizability. Furthermore, a deeper exploration into the interplay between visual feature dimensionality and LLM size is warranted, aiming to optimize the model’s efficiency and performance across a broader range of MLLMs. Finally, extending this work to handle other modalities, such as audio and 3D point clouds, represents a significant area for future development, pushing towards truly generalizable multimodal models. The effectiveness of the Dense Connector in complex, real-world scenarios should also be evaluated, testing its robustness in noisy or ambiguous visual inputs.
More visual insights#
More on figures
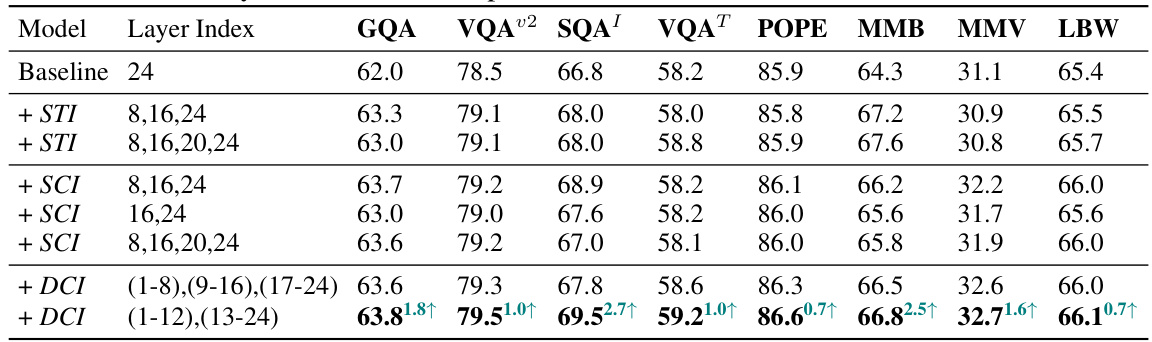
This figure visualizes attention maps across different layers of a ViT-L model, showcasing how different layers focus on different regions of interest. It also illustrates the difference between final visual embeddings (from the top layer only) and dense connected visual embeddings (from multiple layers), demonstrating the Dense Connector’s approach of leveraging multi-layer visual features for improved performance. Finally, it provides a schematic overview of the plug-and-play Dense Connector architecture.

This figure visualizes attention maps across different layers of a ViT-L model, highlighting how different layers focus on different regions of interest. It also compares final visual embeddings with dense connected visual embeddings, illustrating the Dense Connector’s approach of leveraging multi-layer visual features to enhance MLLMs. Finally, it provides a schematic overview of the plug-and-play Dense Connector, showing its seamless integration with existing MLLMs.
This figure visualizes the attention maps across different layers of a ViT-L model, highlighting the different regions of interest emphasized by each layer. It also compares the visual embeddings from the final layer of the visual encoder to those from a densely connected approach which utilizes information from multiple layers. Finally, it shows a schematic of a plug-and-play Dense Connector which incorporates multi-layer features. This demonstrates the potential for improved performance by leveraging the richness of multi-layer visual features.
This figure visualizes attention maps across different layers of a ViT-L model, highlighting the varying focus on different regions of interest across layers. It compares final visual embeddings with dense connected visual embeddings, showing how utilizing features from multiple layers can enhance existing MLLMs. Finally, it illustrates the plug-and-play nature of the Dense Connector, which leverages multi-layer visual features to improve vision-language understanding in MLLMs.
This figure visualizes attention maps across layers of a ViT-L model, showcasing how different layers focus on different regions of interest. It then contrasts the common practice of using only final high-level visual features from the visual encoder with the proposed Dense Connector method, which leverages features from multiple layers. Finally, it illustrates the plug-and-play nature of the Dense Connector as it integrates with existing MLLMs.

The figure visualizes attention maps across different layers of a ViT-L model, showing how different layers focus on different regions of interest. It also compares the use of final visual embeddings versus a dense connectivity approach using multi-layer visual features, highlighting the benefits of integrating information from multiple layers. Finally, it illustrates the plug-and-play Dense Connector architecture, demonstrating its simplicity and seamless integration into existing MLLMs.
The figure visualizes attention maps across different layers of a ViT-L model, highlighting the varying regions of interest emphasized at different depths. It also contrasts the use of final visual embeddings versus densely connected visual embeddings in MLLMs, illustrating the concept of the Dense Connector. Finally, it shows a schematic diagram of the plug-and-play Dense Connector’s integration into existing MLLMs.

This figure visualizes attention maps across different layers of a ViT-L model, highlighting how different layers focus on different regions of interest. It also compares the visual embeddings generated from using only the final layer of the visual encoder versus using a dense connector that leverages multi-layer visual features. Finally, it illustrates the plug-and-play nature of the Dense Connector, showing how it can be easily integrated into existing MLLMs.
This figure visualizes attention maps across different layers of a ViT-L model, highlighting the varying regions of interest emphasized by each layer. It also compares final visual embeddings (from the top layer) with dense connected visual embeddings (from multiple layers), showing how integrating multi-layer features can enrich visual representations in MLLMs. Finally, it illustrates the plug-and-play Dense Connector, a simple yet effective module for leveraging multi-layer visual features to enhance existing MLLMs.

This figure visualizes attention maps across different layers of a ViT-L model, highlighting the varying focus on different regions of interest. It also compares visual embeddings generated from the final layer of the visual encoder versus a dense connectivity approach that leverages multi-layer features. Finally, it illustrates the plug-and-play nature of the proposed Dense Connector which integrates multi-layer visual features to enhance existing MLLMs.

This figure visualizes attention maps across different layers of a ViT-L model, highlighting the varying regions of interest emphasized at each layer. It also illustrates the difference between final visual embeddings (using only top-layer features) and dense connected visual embeddings (using multi-layer features) in MLLMs. Finally, it shows a schematic of the plug-and-play Dense Connector that leverages multi-layer visual features to enhance existing MLLMs.

This figure visualizes the attention maps across different layers of a ViT-L model, showcasing how different layers focus on different regions of interest. It also illustrates the difference between final visual embeddings and dense connected visual embeddings in MLLMs, showing that integrating multi-layer visual features can significantly enhance performance. Finally, it depicts a plug-and-play dense connector that seamlessly integrates with existing MLLMs to leverage multi-layer visual features.

This figure visualizes attention maps across various layers of a ViT-L model, highlighting the different regions of interest emphasized by different layers. It also contrasts final visual embeddings with dense connectivity of visual embeddings from different layers, showing how multi-layer visual features can enhance multimodal LLMs. Finally, it illustrates the Dense Connector as a plug-and-play module for integrating these multi-layer features to improve existing MLLMs.

The figure illustrates the concept of Dense Connector by visualizing attention maps across different layers of a ViT model, showing that different layers focus on different regions of interest. It also compares the final visual embeddings with the dense connected visual embeddings, demonstrating that the Dense Connector leverages multi-layer visual features to enhance existing MLLMs. Finally, it shows a schematic of the plug-and-play Dense Connector.

This figure visualizes the attention maps across different layers of a ViT-L model, showcasing how different layers focus on different regions of interest. It also compares the final visual embeddings from a standard visual encoder with the dense connectivity approach which leverages features from multiple layers. Finally, it illustrates the plug-and-play Dense Connector, highlighting its simplicity and ease of integration with existing MLLMs.

This figure visualizes attention maps across layers of a ViT-L model, showing that different layers focus on different regions of interest. It then compares final visual embeddings with dense connected visual embeddings from multiple layers, highlighting the potential benefits of utilizing multi-layer visual features. Finally, it shows a schematic of the proposed plug-and-play Dense Connector that leverages these multi-layer features to improve existing MLLMs.

This figure visualizes attention maps across different layers of a ViT-L model, highlighting the varying regions of interest emphasized by each layer. It also compares the visual embeddings generated using only final high-level features versus utilizing multi-layer features, demonstrating the advantage of the latter. Finally, it illustrates the plug-and-play nature of the proposed Dense Connector, showing how it integrates multi-layer visual features to enhance existing MLLMs.

This figure visualizes attention maps across different layers of a ViT-L model, highlighting the varying focus on different regions of interest. It also compares final visual embeddings with densely connected visual embeddings, showcasing how leveraging multi-layer features can significantly enhance the performance of existing MLLMs. Finally, it illustrates the plug-and-play Dense Connector, demonstrating its simplicity and ease of integration.

This figure visualizes attention maps across different layers of a ViT-L model, highlighting the varying regions of interest emphasized by different layers. It also compares final visual embeddings with dense connected visual embeddings, demonstrating the benefits of incorporating multi-layer visual features. Finally, it illustrates the plug-and-play nature of the proposed Dense Connector, showcasing its seamless integration with existing MLLMs.

This figure visualizes attention maps across different layers of a ViT-L model, showing that different layers focus on different regions of interest. It then compares the visual embeddings from using only the final layer of a visual encoder versus using multiple layers. Finally, it illustrates how the Dense Connector integrates multi-layer visual features in a plug-and-play fashion to improve existing MLLMs.

This figure visualizes attention maps across layers of a ViT-L model, highlighting the varying focus on different regions of interest. It also contrasts final visual embeddings with dense connectivity across multiple layers in MLLMs, showing how the Dense Connector utilizes multi-layer visual features to improve the model’s performance. Finally, it illustrates the plug-and-play nature of the Dense Connector.

This figure visualizes attention maps across different layers of a ViT-L model, showcasing how different layers focus on different regions of interest. It also compares the visual embeddings generated by using only the final layer of the visual encoder versus using multiple layers through the proposed Dense Connector. Finally, a schematic diagram illustrates how the Dense Connector is used as a plug-and-play module in an existing MLLM.
More on tables
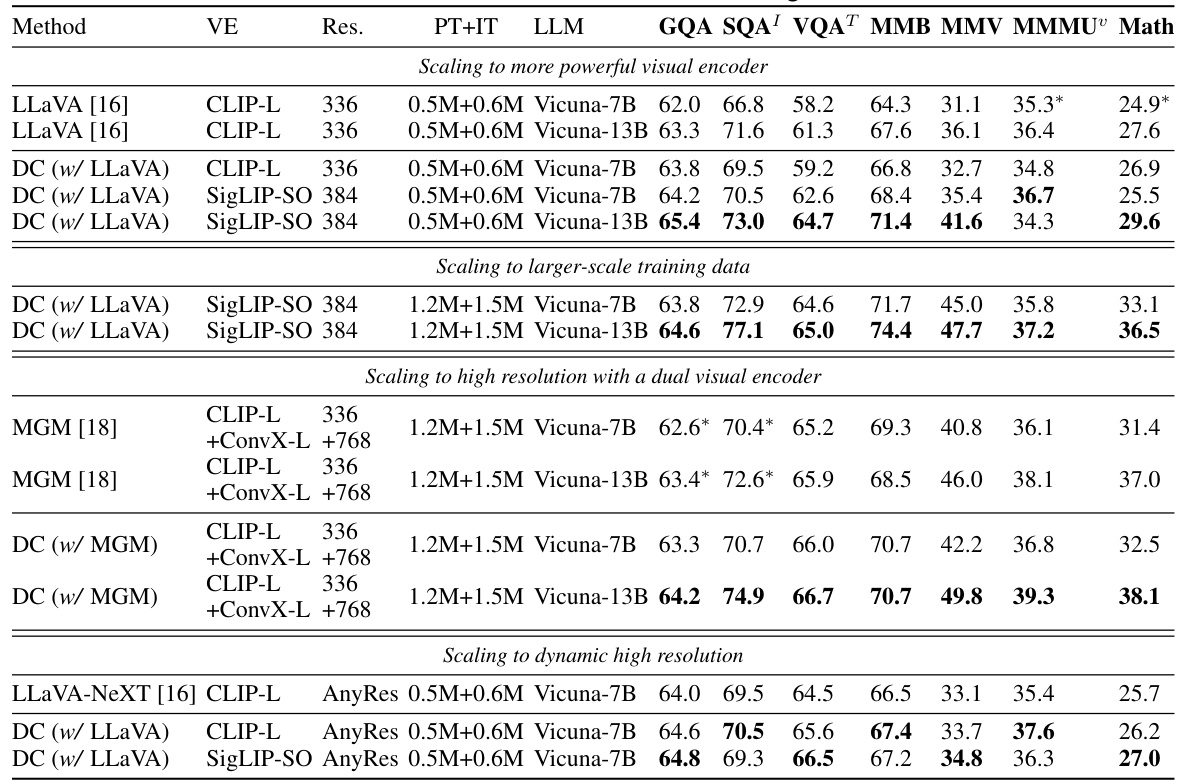
This table presents the results of experiments conducted to evaluate the Dense Connector’s compatibility and scalability across various settings. The experiments systematically vary the visual encoder, image resolution, training data size, and the size of the Language Model (LLM). This allows for a comprehensive assessment of the model’s performance and robustness under diverse conditions. The results are presented for multiple benchmarks to showcase its performance and adaptability.

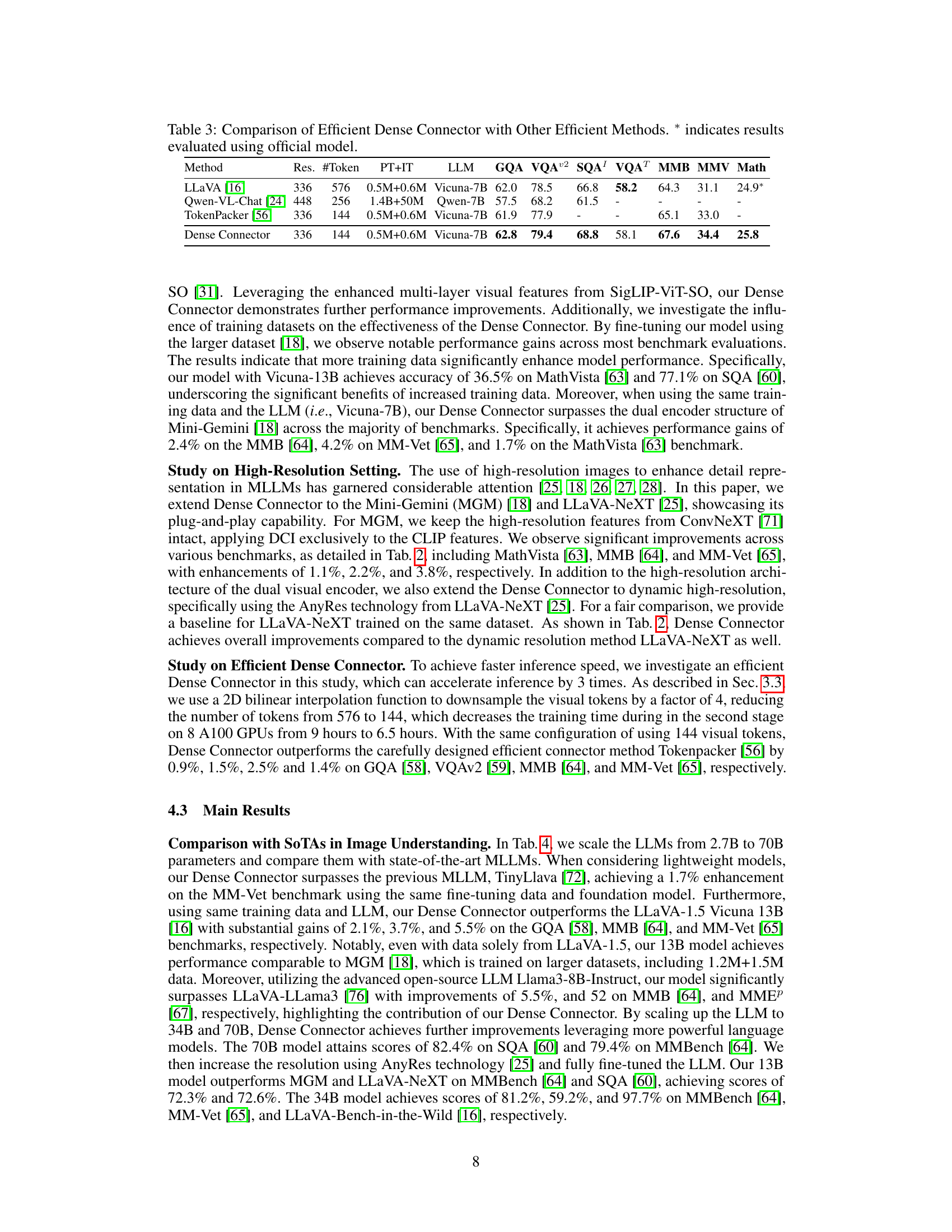
This table compares the performance of the proposed Efficient Dense Connector against other efficient methods on several image benchmarks. The metrics used are GQA, VQA02, SQA1, VQAT, MMB, MMV, and Math. The table shows that, despite using fewer visual tokens (144 vs. 256 or 576), the Efficient Dense Connector achieves comparable or superior performance to the other methods, highlighting its efficiency.
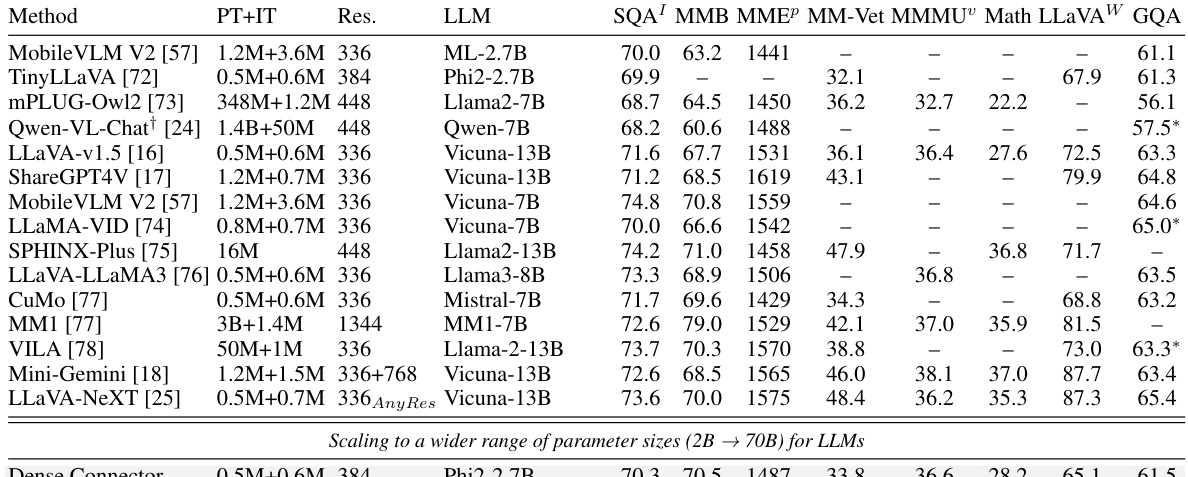
This table compares the performance of the proposed Dense Connector method with other state-of-the-art (SoTA) methods on various image understanding benchmarks. It shows the impact of different factors such as model size (LLM parameters), training data size (PT+IT), image resolution (Res.), and visual encoder on the performance. The results are presented for several commonly used benchmarks, allowing for easy performance comparison of various methods across different parameters and datasets.
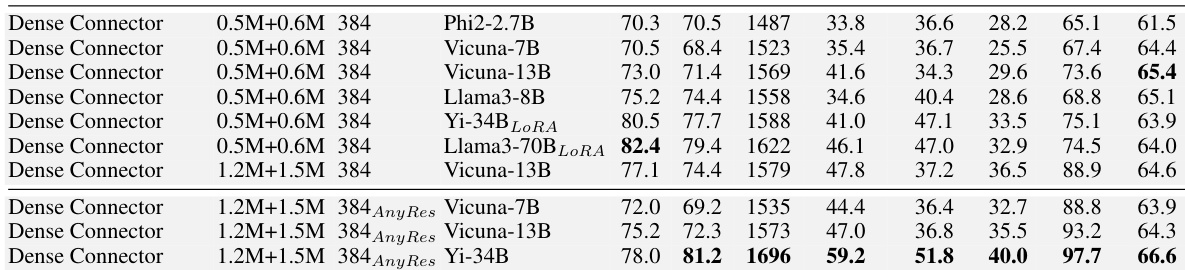
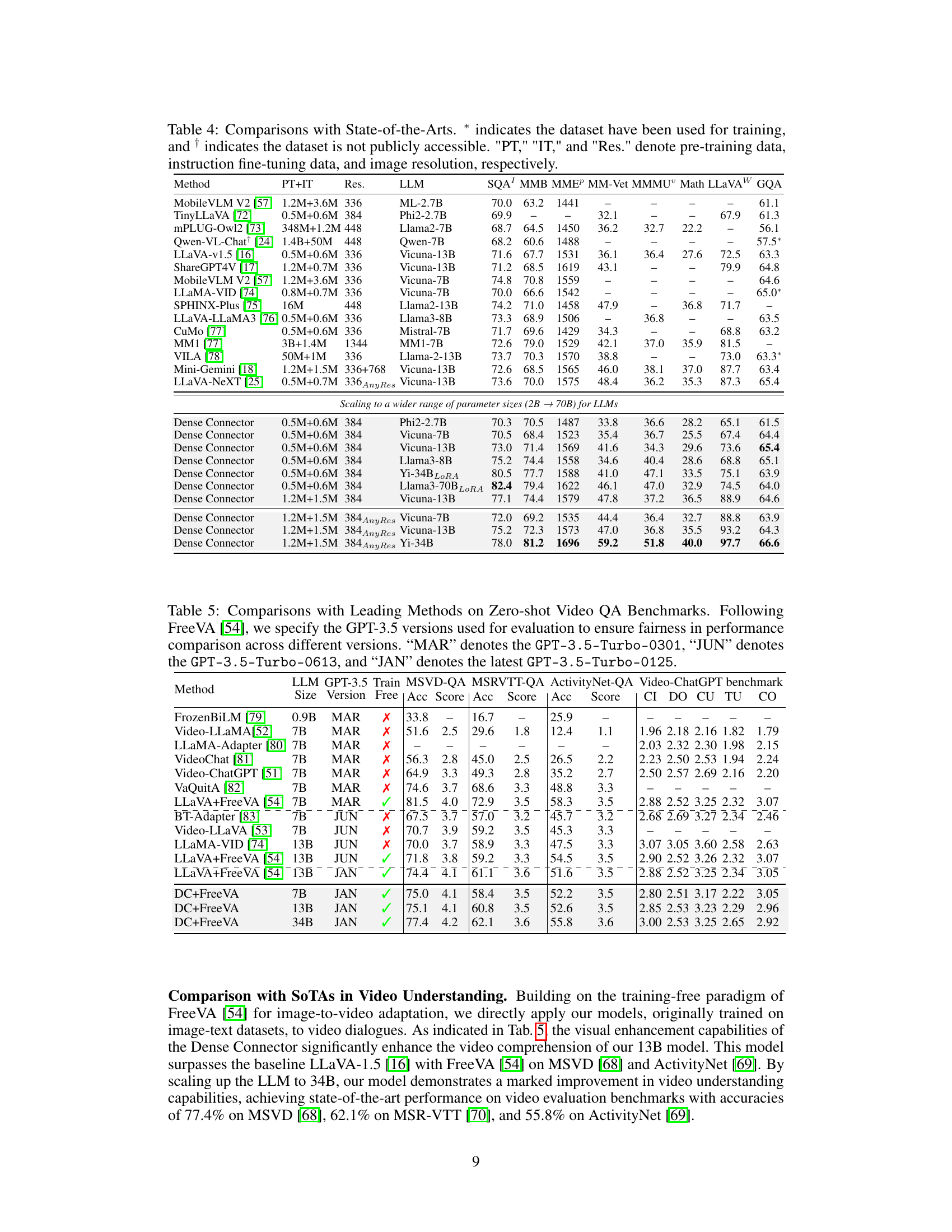
This table presents a more detailed performance comparison of the Dense Connector across different LLMs and training datasets. It expands on previous results by including a wider range of models (Phi-2.7B, Vicuna-7B, Vicuna-13B, Llama3-8B, Yi-34B, Llama3-70B) and training data configurations (0.5M+0.6M from LLaVA-1.5 and 1.2M+1.5M from Mini-Gemini). The table provides quantitative results for several benchmarks (GQA, VQAT, SQA, MMB, MMEP, MMMU, Math, MMV, LLaVAW). The ‘AnyRes’ column indicates experiments conducted using the AnyRes technology from LLaVA-NeXT. The table shows how Dense Connector impacts performance in different models and with various training data amounts.
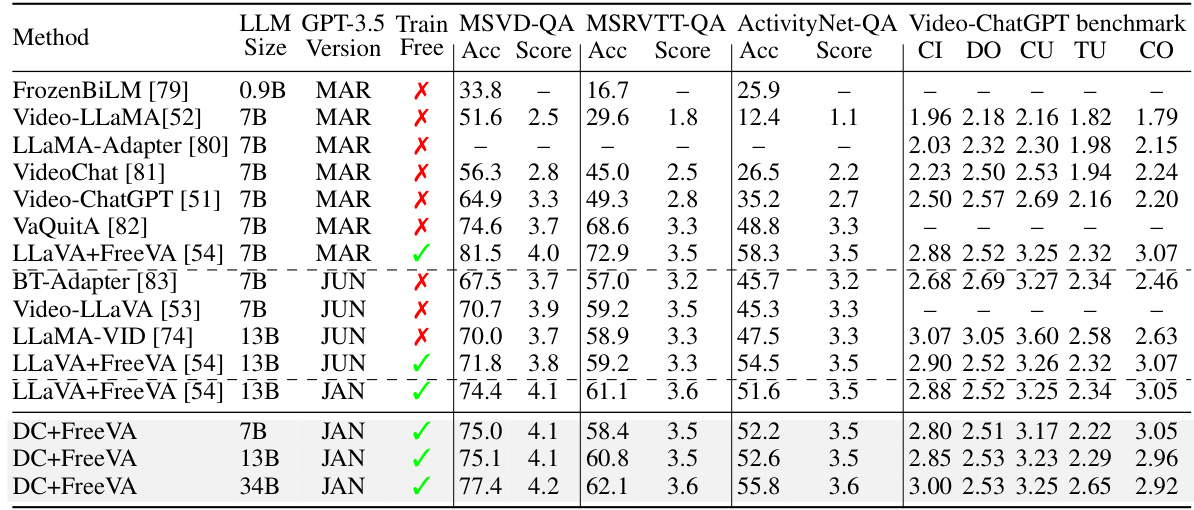
This table demonstrates the Dense Connector’s versatility and scalability by evaluating its performance across various visual encoders, image resolutions, training datasets, and LLMs. It shows how the method performs using different sizes of LLMs, various training datasets (including larger datasets from Mini-Gemini), and different visual encoders. The results highlight the robustness and adaptability of the approach across diverse settings.
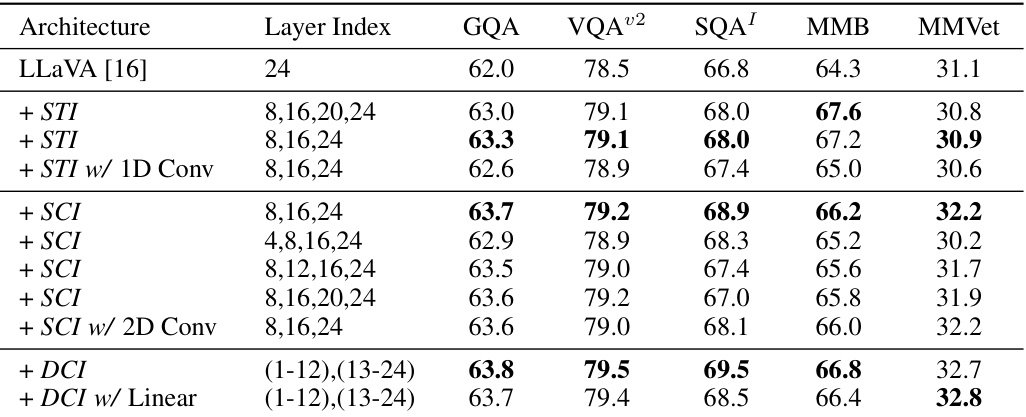
This table presents ablation study results on the selection of visual layers used in the Dense Connector. It compares three different versions of the Dense Connector (STI, SCI, and DCI) against a baseline LLaVA-1.5 model. Each version uses a different combination of visual layers from a 24-layer CLIP-ViT-L-336px visual encoder. The results show the performance of each model across multiple image benchmarks (GQA, VQA02, SQA, VQAT, POPE, MMB, MMV, LBW) to assess the impact of different layer selections on overall accuracy.
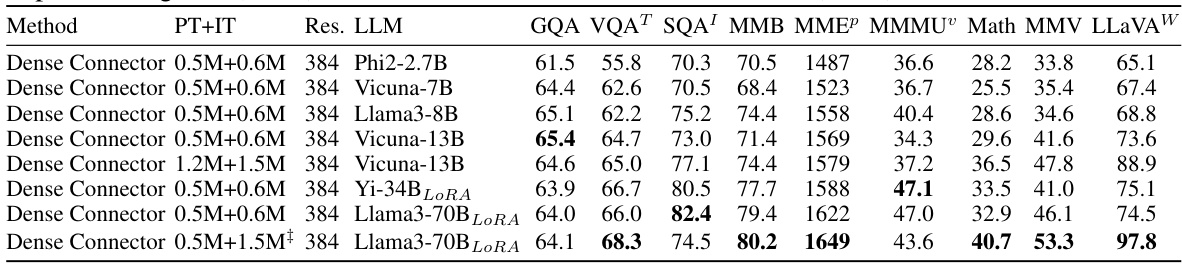
This table presents a comprehensive evaluation of the Dense Connector’s performance across various LLMs (Phi2-2.7B, Vicuna-7B, Llama3-8B, Vicuna-13B, Yi-34B, Llama3-70B) and datasets (LLaVA-1.5 and Mini-Gemini). It shows the performance gains achieved by the Dense Connector on different image understanding benchmarks (GQA, VQAT, SQA, MMB, MMEP, MMMU, Math, MMV, and LLaVAW) with different model sizes and training data, illustrating the scalability and versatility of the proposed approach.

This ablation study investigates the impact of fine-tuning the vision transformer (ViT) on the overall performance of the Dense Connector. It shows the results of experiments using different visual encoders with and without fine-tuning the ViT on various benchmarks, using the LLaVA 1.5 dataset. The table compares the performance metrics (GQA, SQA, VQAT, MMB, MMV, MMMU, and Math) obtained with and without ViT fine-tuning, demonstrating whether fine-tuning improves the results or not.
Full paper#