↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Creating accurate species range maps is crucial for ecological research and conservation efforts, but traditional methods struggle with limited data. Many species lack sufficient location observations due to inaccessibility or resource constraints. This poses a significant challenge for obtaining reliable species range maps, particularly for understudied species.
The researchers address this issue by introducing LE-SINR, a novel model that integrates millions of citizen science observations with detailed species descriptions from Wikipedia. LE-SINR maps locations, species, and textual descriptions into a shared space, enabling the model to learn comprehensive spatial covariates globally. This allows for zero-shot range estimation from text descriptions alone and enhances few-shot estimation using limited observational data. LE-SINR significantly outperforms existing methods and demonstrates effectiveness for various spatial tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the challenge of species range map (SRM) creation with limited data, a significant hurdle in ecology and conservation. By integrating textual data with observational data, it offers a novel approach with broad implications for various spatial tasks and biodiversity research.
Visual Insights#
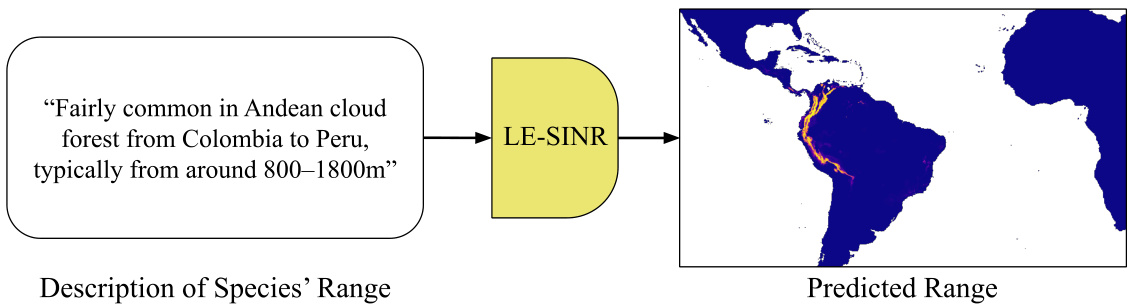
This figure illustrates the overall process of the LE-SINR model. The input is a text description of a species’ habitat or range (e.g., ‘Fairly common in Andean cloud forest from Colombia to Peru, typically from around 800–1800m’). This text is then processed by the LE-SINR model, which combines language processing with geospatial information to produce a predicted species range map visualized on a world map.

This table presents the results of a zero-shot range estimation experiment. It compares the performance of the proposed LE-SINR model against several baselines, including a constant prediction and model mean. The LE-SINR model is tested with and without environmental features and with and without access to training data for the evaluation species. The results show that the LE-SINR method significantly outperforms the baselines, demonstrating the effectiveness of zero-shot range estimation using textual descriptions. Additionally, using text from both habitat and range descriptions leads to improved performance.
In-depth insights#
Zero-Shot Range Maps#
Zero-shot range maps represent a significant advancement in species distribution modeling. By leveraging readily available textual descriptions from sources like Wikipedia, coupled with a large language model, this technique enables the prediction of species ranges even without observed location data. This eliminates the need for extensive fieldwork and greatly expands the potential for comprehensive species range mapping. The approach’s strength lies in its ability to extract crucial spatial information from textual habitat and range descriptions, effectively translating qualitative ecological knowledge into quantitative spatial predictions. While zero-shot accuracy is impressive, it’s important to acknowledge limitations. The method’s performance is highly dependent on the quality and specificity of the textual input and might be influenced by biases inherent in the source data. Further research to refine accuracy and address potential biases is crucial, particularly concerning underrepresented regions and species. Nevertheless, zero-shot range mapping provides a powerful tool for ecological research and conservation, particularly for data-scarce regions, and significantly enhances our understanding of biodiversity distribution.
LE-SINR Framework#
The LE-SINR framework represents a novel approach to species range map (SRM) estimation by synergistically integrating observational data with textual descriptions from sources like Wikipedia. Its core innovation lies in embedding both spatial locations and textual information into a shared latent space. This enables the model to learn rich spatial covariates globally, going beyond traditional reliance on environmental variables. A key strength is the capability for zero-shot SRM estimation, leveraging textual descriptions alone even without observational data for a given species. The framework’s architecture combines a location encoder, a language encoder, and potentially species tokens, allowing for flexible range prediction. Furthermore, LE-SINR acts as a strong prior, improving the accuracy of range estimation when combined with limited observational data. This is crucial for addressing the ’long tail’ problem, where data is scarce for numerous species. The approach proves highly effective in quantitative evaluations against baselines and even matches the performance of models trained with significantly more observational data. Finally, the framework showcases impressive geospatial grounding capabilities, extending beyond species data to map abstract geographical concepts purely from textual descriptions.
Text-Driven Priors#
The concept of “Text-Driven Priors” in species distribution modeling is innovative. It leverages readily available textual data (e.g., Wikipedia descriptions) to create prior knowledge about species’ habitats and ranges. This is crucial because traditional methods often suffer from a scarcity of observational data, particularly for rare or geographically inaccessible species. By integrating text-based information, the model can make informed predictions even with limited observational data, effectively addressing the “long tail” problem of species with few sightings. This approach is particularly valuable in zero-shot learning scenarios where no training data on the species of interest exists. The framework’s ability to map text and location embeddings into a common space enables it to learn rich global-scale spatial covariates, offering a significant enhancement to existing SDM techniques. The method’s effectiveness is supported by quantitative analysis demonstrating improved accuracy and performance in few-shot settings, showcasing the significant value of using text as a prior in improving species range estimation.
Few-Shot Learning#
Few-shot learning, in the context of species range map estimation, tackles the challenge of generating accurate maps with limited observational data. The core idea is to leverage additional information, such as textual descriptions from sources like Wikipedia, to augment scarce observational data. This approach effectively acts as a strong prior, allowing the model to infer plausible range maps even when only a few or no direct location observations are available for a given species. Combining observational and textual data is crucial; the textual descriptions provide rich contextual information about habitat preferences and range characteristics, which can be learned and mapped into a common spatial representation with observational data. This allows the model to extrapolate from existing knowledge, effectively performing zero-shot range estimation for novel species where only textual data is available. The performance gains are particularly significant in low-data scenarios, where traditional methods struggle, highlighting the effectiveness of this approach in tackling the long-tail problem in biodiversity data. The fusion of linguistic and geographic information is key, showcasing the power of combining multiple modalities to improve the accuracy and efficiency of species range mapping.
Limitations & Future#
A critical analysis of the ‘Limitations & Future’ section of a research paper would delve into the acknowledged shortcomings of the study. This might include data limitations, such as biases in the datasets used (e.g., geographic or taxonomic imbalances), insufficient sample sizes impacting statistical power, or reliance on specific data sources. Methodological limitations could involve the choice of models, algorithms, or evaluation metrics; the assumptions made during analysis; or the generalizability of findings. The section should also discuss unaddressed factors that might influence results and any limitations arising from the experimental setup, such as a lack of control conditions or the use of proxy measures. Finally, the ‘Future’ component should propose promising avenues for extending the research, including addressing limitations, refining methodologies, exploring new datasets, and investigating unanswered questions raised by the current study. This may also involve suggesting alternative approaches, applying the methods to other domains, or using the research to inform future policies and practice. Clear identification of limitations and insightful suggestions for future work are crucial to the impact and credibility of the research.
More visual insights#
More on figures

This figure illustrates the LE-SINR model architecture. The model takes both location data (latitude and longitude) and text descriptions of a species as input. These inputs are processed separately through location and language encoders (using an LLM), which map them into a shared embedding space. The model can then use these embeddings to predict the species’ range. Optionally, a learnable species token can be included to enhance predictions for species observed in the training data. The entire architecture is designed for both zero-shot (predicting species ranges with only text descriptions) and few-shot (combining text and a limited number of observations) range estimation.
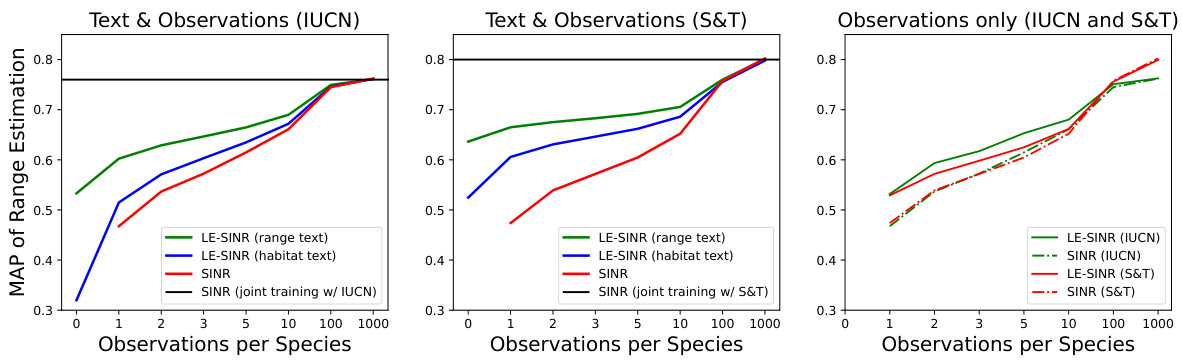
This figure compares the performance of the proposed LE-SINR model with the baseline SINR model in both zero-shot and few-shot range estimation settings using the IUCN and S&T datasets. The left and middle panels illustrate the zero-shot and few-shot results, demonstrating that using textual descriptions of species (habitat or range) enhances few-shot performance. The right panel displays the comparison of position branch features from the two models, highlighting the superior generalization capability of LE-SINR in data-scarce situations.

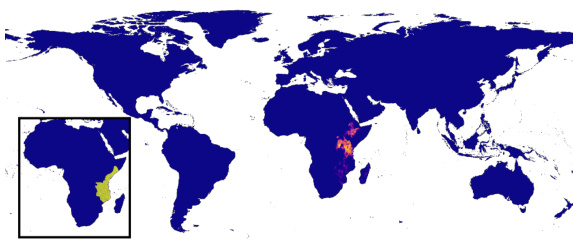
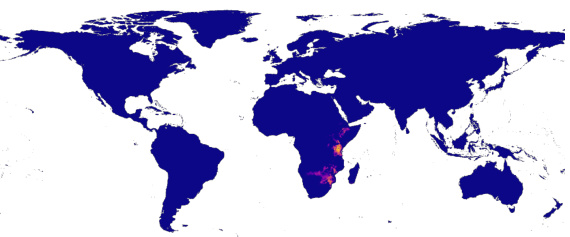
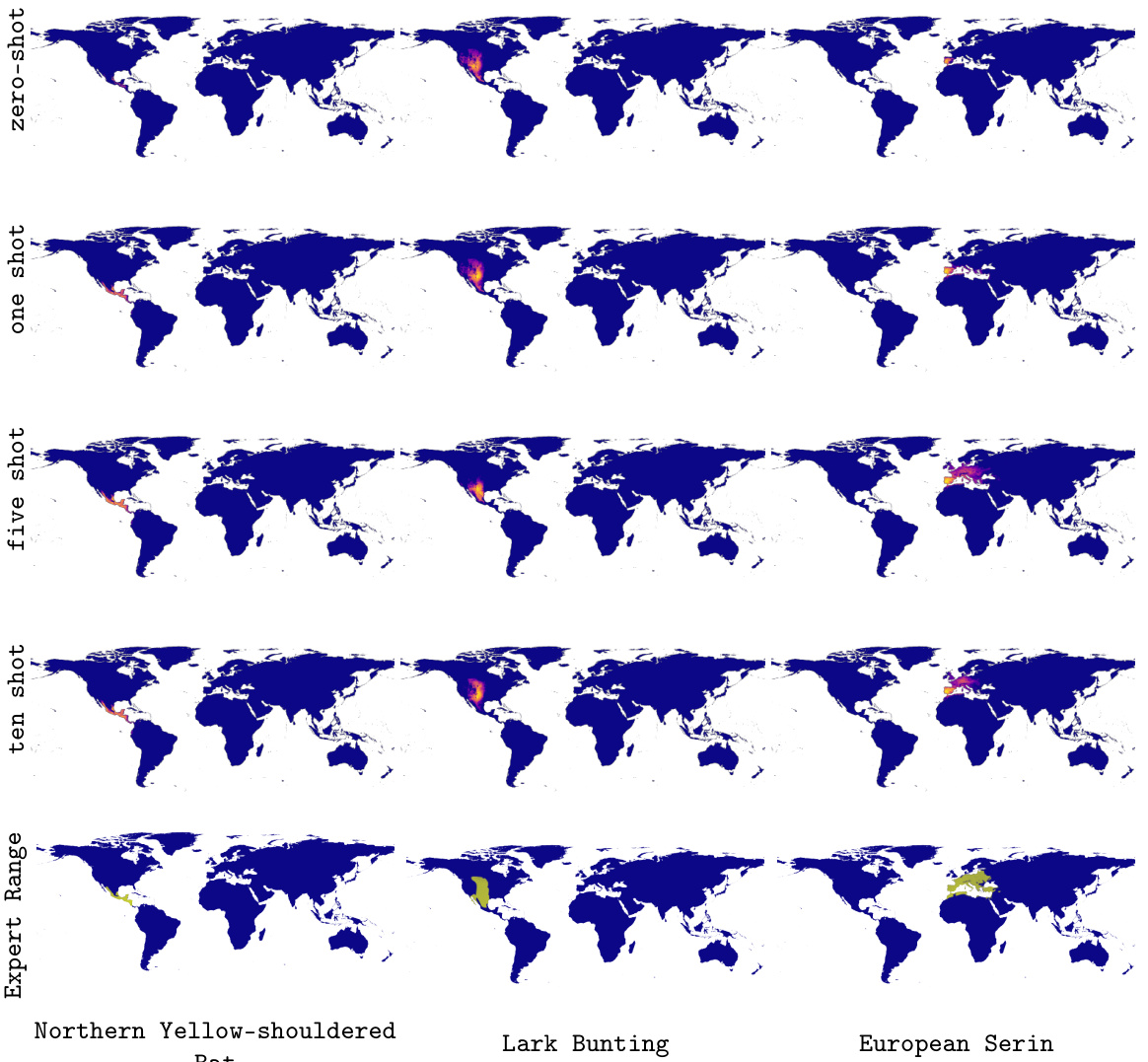
This figure demonstrates the zero-shot range estimation capabilities of the LE-SINR model. It shows predicted range maps generated solely from text descriptions of the Hyacinth Macaw’s habitat and range, and the Yellow Baboon’s habitat and range. The predictions are compared to expert-derived range maps to evaluate the accuracy of the zero-shot approach. The figure highlights the model’s ability to translate textual information into geographically relevant predictions. The inset shows the expert range.
This figure demonstrates LE-SINR’s ability to geospatially ground various text prompts, even those unrelated to species. The heatmaps show the model’s predicted probability of a concept’s presence at each location, based solely on the textual input. The results reveal that the model learns geospatial relationships from both coarse (continents, countries) and finer-grained (lakes, mountain ranges) concepts. While generally successful, it exhibits biases reflecting its training data’s geographic distribution.

This figure demonstrates the results of zero-shot range estimation using only text descriptions of a species’ habitat and range. It shows two examples: the Hyacinth Macaw and the Yellow Baboon. For each species, the figure presents three maps: a map generated from a text description of the species’ habitat preferences, a map generated from a text description of the species’ known range, and a map representing expert-derived range data. Comparing the model’s range predictions to the expert data allows for an assessment of the model’s accuracy.
This figure shows the ability of the LE-SINR model to geographically ground various text prompts, even those not directly related to species. The heatmaps illustrate the model’s spatial understanding, highlighting how it associates concepts like continents, countries, and specific geographical features with their corresponding locations. While showing strong performance overall, biases in the training data (favoring North America, Europe, and Australasia) are apparent.
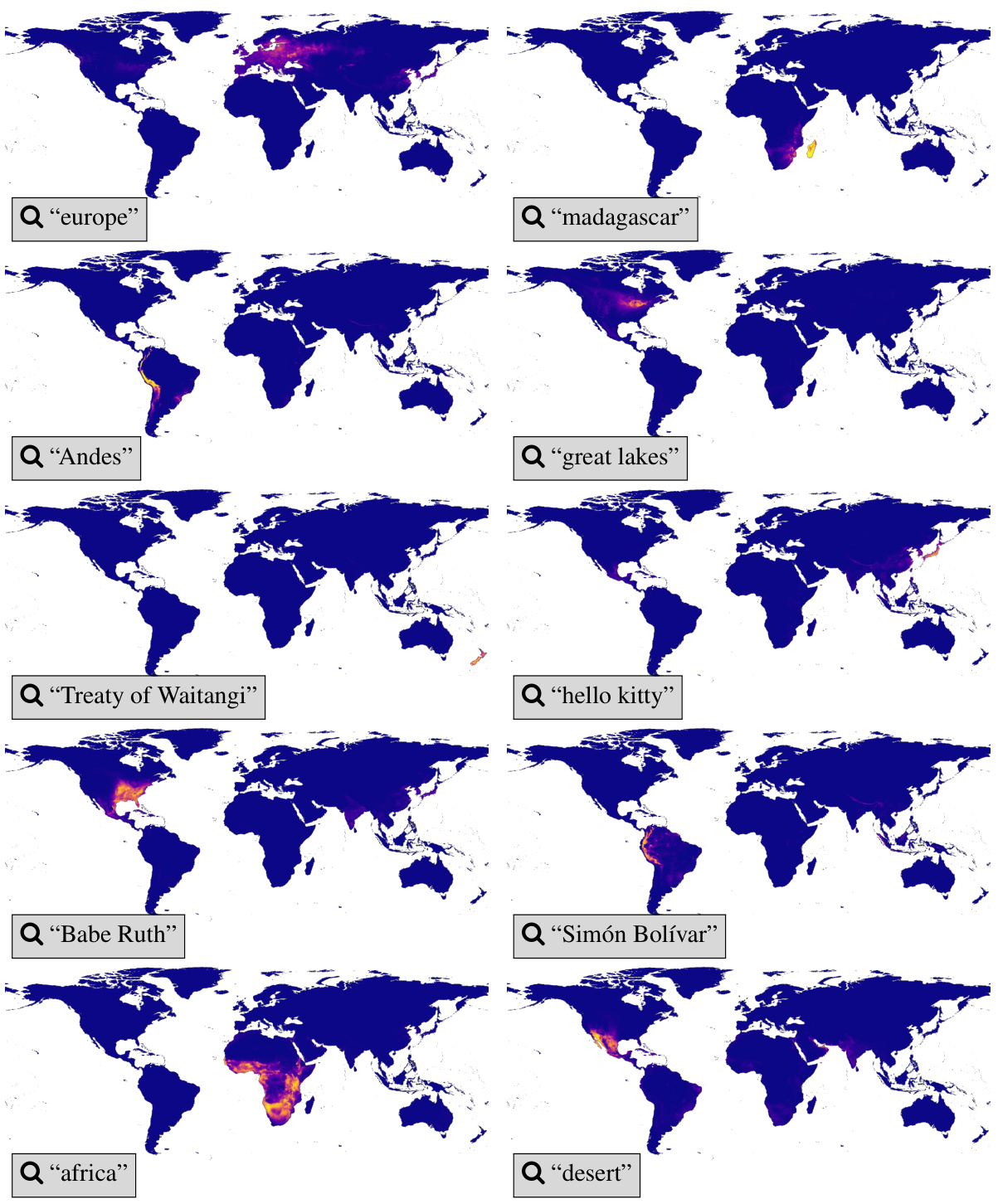
This figure demonstrates the ability of the LE-SINR model to geospatially ground various text prompts, including geographical concepts (continents, countries, lakes, mountain ranges), and non-geographical concepts (historical events, pop culture figures). The heatmaps show the model’s predicted probability of a concept’s presence at different locations. The results showcase the model’s capacity to learn and extrapolate from both species-related and non-species-related data, but also highlight limitations due to dataset bias.

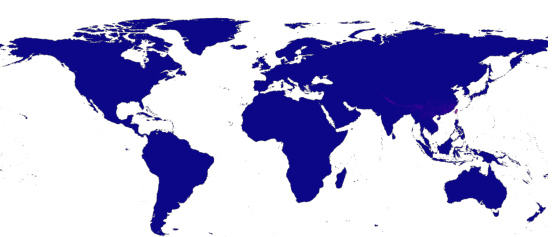
This figure compares the intermediate position representations learned by SINR and LE-SINR models. Both models were trained using only position features. The visualization uses Independent Component Analysis (ICA) to project the high-dimensional embeddings into three dimensions (for visualization purposes), represented by color in RGB space. The differences in the visualizations highlight how LE-SINR learns richer spatial information than SINR. This richer representation is a contributing factor to the improved performance of LE-SINR, especially in few-shot scenarios.
This figure compares the performance of the proposed LE-SINR model against the baseline SINR model for range estimation, under zero-shot and few-shot learning settings using IUCN and S&T datasets. The left and middle panels show the mean average precision (MAP) for zero-shot range estimations based solely on text descriptions (habitat and range), and for few-shot estimations incorporating the text-based priors alongside limited observational data. The right panel illustrates the advantage of LE-SINR’s learned positional embeddings in the few-shot setting; LE-SINR generalizes better with fewer observations.

This figure in the appendix visualizes the results of zero-shot range estimation experiments for six different species. The maps compare the predicted range maps using habitat descriptions (left column), range descriptions (middle column), and expert-derived range maps (right column). It demonstrates that range descriptions provide more accurate predictions aligned with the expert maps, while habitat descriptions are sometimes less precise, highlighting the different information each description type provides for accurate range prediction. The figure emphasizes the value of precise, location-specific information contained within range descriptions for successful zero-shot range estimation, versus the sometimes less accurate estimation when using habitat descriptions alone.

This figure compares the learned position embeddings of the standard SINR model and the LE-SINR model, both trained using only position features. The LE-SINR model incorporates language data, which is reflected in the visualizations. By projecting the embeddings into three dimensions using Independent Component Analysis (ICA), the figure allows for visualization of these learned representations. The visualization highlights differences in the spatial structure captured by the two models, suggesting that the LE-SINR model learns a richer and potentially more informative representation of geographic space.
This figure demonstrates the model’s ability to geospatially ground both species-related and non-species-related concepts. The heatmaps show the inner product between location embeddings and text embeddings for various terms, illustrating that the model effectively maps textual concepts to their corresponding geographical locations. Although generally successful, the visualizations also highlight biases present in the training data, which is skewed towards North America, Europe, and Australasia.
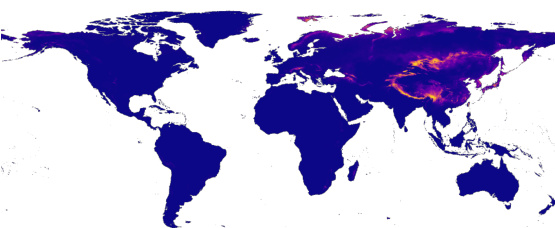
This figure visualizes the learned positional embeddings from both the standard SINR model and the LE-SINR model, projected into three dimensions using Independent Component Analysis (ICA). The visualization helps to understand how the models represent spatial information. The top panel shows the representation learned by SINR (trained only on location data), while the bottom panel shows the representation learned by LE-SINR (trained on location and language data). The difference highlights how incorporating language data enriches the model’s spatial understanding.
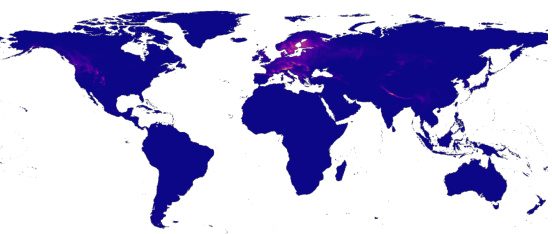
This figure compares the learned position embeddings from two different models: the standard SINR model and the LE-SINR model. Both models were trained only using position features. The visualization is done in 3D using Independent Component Analysis. The visualization shows that LE-SINR learns a richer spatial structure than SINR.

This figure compares the position embeddings learned by the standard SINR model and the LE-SINR model, projected into three dimensions using Independent Component Analysis. It visualizes how the learned representations differ when only position features are used for training. The color intensity likely represents a magnitude of some feature, possibly indicating a higher concentration of certain characteristics or signals in specific geographic areas. The difference is intended to show how LE-SINR’s integration of language data contributes to richer spatial representations.

This figure compares the learned position embeddings of the standard SINR model and the LE-SINR model by projecting them into three dimensions using Independent Component Analysis (ICA). The visualization helps understand the differences in the spatial representations learned by each model. Both models were trained using only position features. LE-SINR’s spatial representation shows a richer structure compared to the standard SINR model, indicating that the incorporation of language data results in more detailed and informative spatial features.
More on tables

This ablation study analyzes the impact of different design choices on the zero-shot performance of the LE-SINR model. It investigates the effects of using different types of species descriptions (range, habitat, vs. taxonomy from LD-SDM), different location encoders (Spherical Harmonics, GeoCLIP), and different loss functions (SatCLIP vs. the authors’ method). The results show the relative contribution of each design choice to the overall performance of the LE-SINR model in a zero-shot range estimation setting. The table compares different model configurations across two metrics (IUCN and S&T).
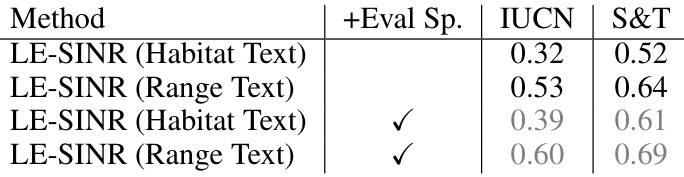
This table presents the results of a zero-shot range estimation experiment comparing different methods. The LE-SINR model, which combines language and observational data, is compared against several baselines and an oracle model. The results show that LE-SINR significantly outperforms the baselines, achieving performance comparable to the oracle model when using range descriptions.
Full paper#



















