↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
3D object detection from point clouds is challenging due to the irregularity, sparsity, and unordered nature of the data. Traditional transformer-based approaches struggle with the quadratic complexity of attention mechanisms, especially at higher resolutions. This limits their ability to effectively encode rich information and impacts detection accuracy. Additionally, existing methods often primarily focus on global modeling, potentially missing crucial local details.
This paper introduces 3DET-Mamba, a novel approach that addresses these challenges. It uses the Mamba state space model to improve efficiency and incorporate a local-to-global scanning mechanism, which consists of Inner and Dual Mamba modules. A Query-aware Mamba module enhances context feature decoding into object sets. Experimental results demonstrate that 3DET-Mamba significantly outperforms existing 3DETR models on indoor 3D object detection benchmarks, showcasing the potential of SSMs in this domain.
Key Takeaways#
Why does it matter?#
This paper is crucial because it pioneers the use of state space models (SSMs), specifically the Mamba architecture, in 3D object detection. This opens new avenues for research, especially considering the limitations of traditional transformer-based methods in handling high-resolution point clouds. The improved efficiency and accuracy demonstrated by 3DET-Mamba make it a significant advancement for the field and a valuable resource for researchers working on similar problems.
Visual Insights#
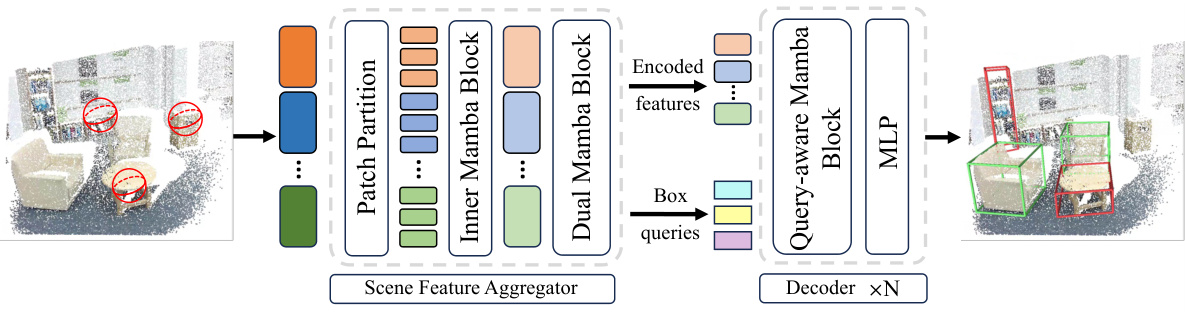
The figure shows an overview of the 3DET-Mamba architecture, a novel end-to-end 3D object detection model based on the state space model (SSM). Point clouds are divided into patches, processed by an Inner Mamba block to extract local features, and then further processed by a Dual Mamba block to capture global scene context. These features and object queries are fed into a decoder comprised of Query-aware Mamba blocks and Multi-Layer Perceptrons (MLPs) to generate final bounding boxes. A bipartite matching scheme refines the output.
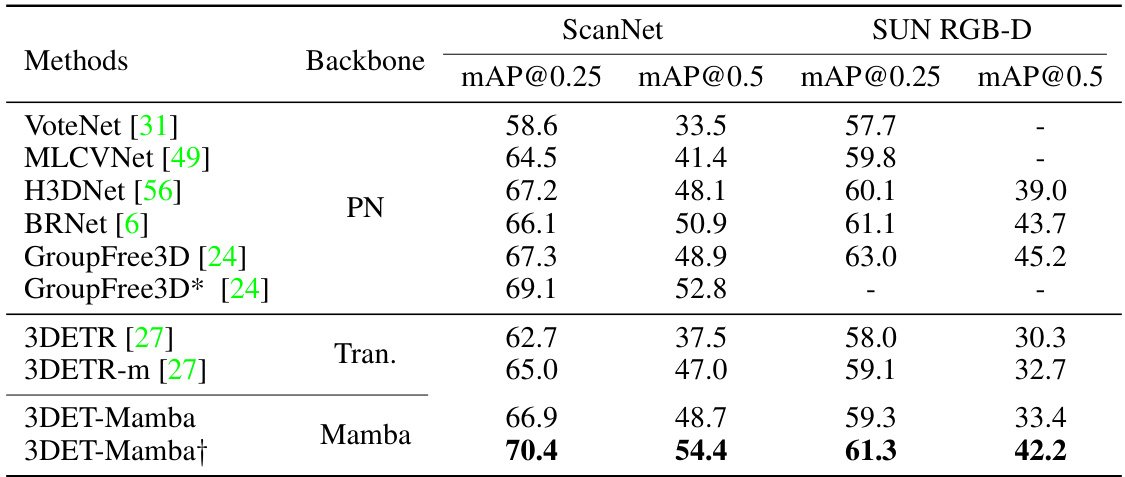
This table presents a comparison of 3D object detection results on the ScanNet V2 and SUN RGB-D datasets for several methods, including the proposed 3DET-Mamba. It highlights the performance improvements achieved by 3DET-Mamba compared to existing state-of-the-art methods, specifically 3DETR. The table also shows the impact of increasing the number of key points and queries on the performance of 3DET-Mamba.
In-depth insights#
3D DETR Enhancements#
Potential enhancements to 3D DETR could address its limitations in handling high-resolution point clouds and complex scenes. Improving computational efficiency is crucial, perhaps through techniques like sparse attention mechanisms or more efficient transformer architectures. Enhancing feature extraction with advanced methods like graph neural networks or incorporating multi-scale features would improve object detection accuracy. Addressing the issue of unordered point clouds requires exploring advanced point cloud preprocessing or developing inherently order-invariant architectures. Furthermore, improving the decoder’s ability to generate accurate 3D bounding boxes, potentially by incorporating additional loss functions or incorporating contextual information, is important. Finally, investigating more robust training strategies, such as semi-supervised learning or incorporating data augmentation, could boost performance and generalization.
Mamba’s 3D Vision#
Mamba’s 3D vision represents a significant advancement in applying state-space models (SSMs) to three-dimensional point cloud data. Traditional attention-based methods struggle with the complexity of 3D data, leading to computational limitations. Mamba’s linear complexity offers a solution, enabling efficient processing of large point clouds. The core innovation lies in adapting the sequential nature of Mamba to the unordered nature of point clouds, likely through novel sampling and ordering techniques. This involves efficiently capturing both local geometric details and global scene context, possibly by employing multi-scale approaches or hierarchical structures. The resulting model is likely capable of performing tasks such as object detection and scene understanding with improved speed and accuracy. Furthermore, the integration of query-aware mechanisms is key, allowing the model to focus on objects of interest and potentially facilitating improved performance in challenging scenarios. Future research directions might explore various point cloud representations, adapting Mamba for different task formulations, and investigating the scalability and robustness of the approach on large-scale datasets.
Local-Global Scan#
A ‘Local-Global Scan’ approach in a 3D object detection context cleverly addresses the inherent limitations of processing unordered point cloud data. By dividing the point cloud into local patches, it allows for the effective extraction of fine-grained local geometric features, crucial for accurate object recognition. This local processing avoids the computational burden and information loss associated with directly applying global attention mechanisms to massive point clouds. Simultaneously, the approach incorporates a global aggregation mechanism, effectively capturing long-range dependencies and contextual information within the entire scene. This is achieved by combining the local patch features to build a global representation, allowing for a more holistic understanding of the 3D space. This two-stage process – local feature extraction followed by global context modeling – is crucial for robust 3D object detection because it balances the need for detailed local information with the capacity for scene-level understanding. The combination yields both precise local detail and comprehensive global context, leading to improved accuracy and robustness in object recognition within complex 3D environments.
Query-Aware Mamba#
The proposed Query-Aware Mamba module is a crucial innovation addressing limitations in directly applying state-space models like Mamba to 3D object detection. Standard Mamba excels at long-range dependencies in sequential data but struggles with the unordered nature of point clouds. This module elegantly bridges the gap by decoding contextual scene features into object sets using learnable queries. Unlike simply concatenating scene context, which hinders the model’s ability to extract object-specific features, the Query-Aware Mamba leverages the queries to guide the feature extraction process. This results in more effective learning of relationships between the queries and the relevant scene information, leading to improved object classification and localization accuracy. This approach significantly enhances the decoder’s ability to generate accurate bounding boxes, overcoming a key challenge in applying SSMs to unordered point cloud data. The use of learnable queries is particularly noteworthy, as it provides the model with adaptability and learning capacity to attend to the most pertinent features for each query, thereby improving the model’s overall performance.
Future of Mamba#
The “Future of Mamba” hinges on addressing its current limitations while capitalizing on its strengths. Extending Mamba’s capabilities to handle higher-dimensional data beyond 1D sequences, such as images and 3D point clouds, is crucial for broader applicability. This requires innovative approaches to efficiently encode and process the increased complexity of information. Developing more robust and efficient attention mechanisms within the Mamba framework will be critical to address the computational challenges of handling very long sequences. Research into novel architectures combining Mamba with other successful models like Transformers could unlock synergistic benefits. Exploring different applications for Mamba, including those beyond language modeling and 3D object detection, is another promising avenue. Finally, efforts should focus on creating more widely available and user-friendly tools and resources to accelerate the adoption and advancement of Mamba-based models within the wider research community.
More visual insights#
More on figures
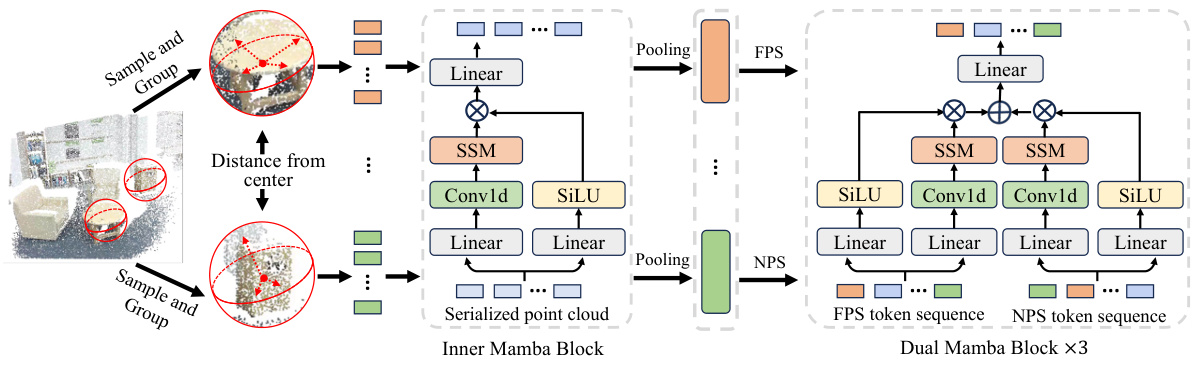
This figure illustrates the scene feature aggregator which is a core component of the 3DET-Mamba model. It shows how the model extracts both local and global features from point cloud data. The process begins with sampling and grouping the points into patches, then using the Inner Mamba block to extract local features from each patch. These local features are then processed by the Dual Mamba block, which models both the spatial distribution and continuity of the point cloud to capture global context.

The Query-aware Mamba block takes box queries and scene context as input, extracting tasked-related features from the scene context guided by the learnable queries. Each query sequence Fq is fed into a standard Mamba block to model the dependencies between queries. Meanwhile, scene features undergo the same process as the query sequence. Then, by multiplying the scene features with query embeddings, scene contexts are integrated into the query embeddings, and the updated queries are then passed through multiple MLP layers.

This figure shows the overall architecture of the 3DET-Mamba model. Point clouds are initially divided into patches. These patches are processed by the Inner Mamba block to extract local features, which are then fed into the Dual Mamba block for global context extraction. This combined information and learned bounding box queries are then passed to a decoder (with Query-aware Mamba blocks and MLPs) to predict the final bounding boxes for objects. A bipartite graph matching is then used for evaluating performance, using a set loss for the end-to-end training.

This figure shows a qualitative comparison of the 3DET-Mamba model’s performance on several indoor scenes. Each row represents a different scene, from left to right. The ‘Input’ row displays the original point cloud input data. The ‘Our’ row shows the 3D bounding boxes predicted by the 3DET-Mamba model. Finally, the ‘GT’ row displays the ground truth bounding boxes for comparison. The orange boxes represent the model’s predictions, while the green boxes represent the ground truth. The figure illustrates the model’s ability to accurately detect and localize objects within cluttered and complex environments.
More on tables
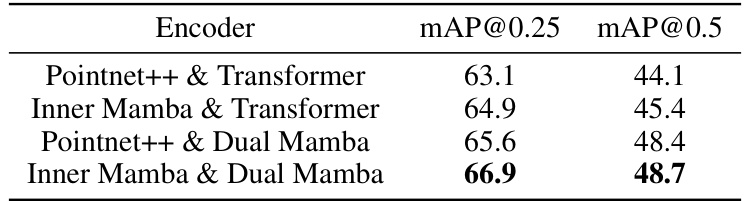
This table presents an ablation study comparing different combinations of encoders in the 3DET-Mamba model. It shows the impact of using either PointNet++ or Inner Mamba for local feature extraction, combined with either a Transformer or Dual Mamba for global context modeling. The results demonstrate that the combination of Inner Mamba and Dual Mamba yields the best performance, measured by mAP@0.25 and mAP@0.5.

This table presents the ablation study on the Dual Mamba block. The performance of using only the original Mamba, the bidirectional Mamba, and the proposed Dual Mamba is compared using mAP@0.25 and mAP@0.5 metrics. The result shows that the Dual Mamba block outperforms other methods.

This table presents the ablation study on the decoder part of the 3DET-Mamba model. It compares the performance of three different decoder designs: a standard Transformer decoder, a decoder using the original Mamba model, and the proposed Query-aware Mamba decoder. The results show a significant improvement in mAP@0.25 and mAP@0.5 when using the Query-aware Mamba decoder, highlighting its effectiveness in effectively modeling the relationship between learnable queries and scene features.
Full paper#