↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Autonomous driving demands real-time perception, promptly reacting to environmental changes. However, existing stereo-based 3D object detection methods struggle with high computational costs, leading to significant latency and reduced accuracy, especially in the context of ‘streaming perception’ which considers both accuracy and latency. This misalignment between predictions and real-time changes hinders performance.
This paper introduces StreamDSGN, an end-to-end framework directly predicting the next moment’s 3D object properties using historical information. To boost accuracy, StreamDSGN employs three key strategies: a feature-flow based fusion to solve misalignment, an extra regression loss for object motion consistency, and a large kernel backbone for capturing long-range context. Extensive testing on the KITTI Tracking dataset showcases a substantial improvement in streaming average precision (up to 4.33%), proving the effectiveness of the proposed solution.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in autonomous driving and real-time perception. It introduces a novel framework, addressing the critical challenge of latency in 3D object detection for streaming perception. This work paves the way for more responsive and accurate perception systems vital for safe and efficient autonomous vehicles, opening avenues for research in efficient deep learning architectures and real-time perception algorithms. Its novel fusion method and loss function provide valuable tools for improving the accuracy and efficiency of future systems.
Visual Insights#

The figure illustrates the challenges of real-time online streaming perception. The left shows stereo images at time t. These are fed to a processing unit (CPU), which takes a time Δt to compute. During this computation time Δt, the real-world scene changes (right side). The predictions made at time t based on the input at time t (bottom left) are misaligned with the actual scene at time t+Δt because of the computation delay. The misalignment is clearly shown for vehicles and pedestrians.
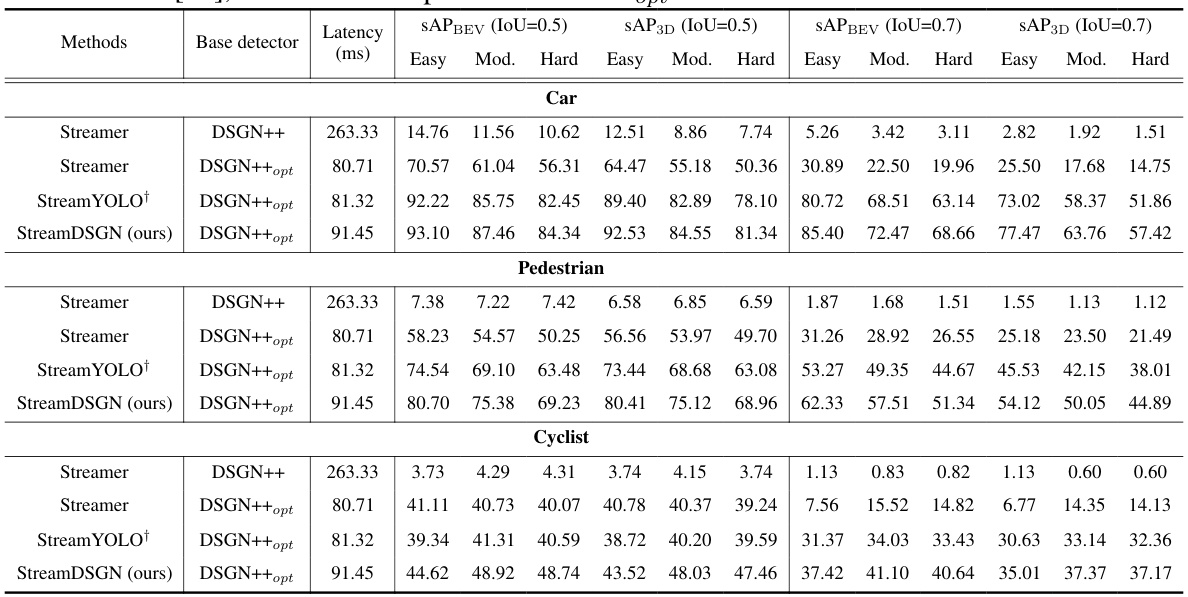
This table compares the proposed StreamDSGN method with the Streamer meta-detector for 3D object detection on the KITTI dataset. It shows the performance (streaming average precision - sAP) of both methods using different base detectors (DSGN++ and its optimized version DSGN++opt) across three object categories (Car, Pedestrian, Cyclist) and different IoU thresholds (0.5 and 0.7). Latency of each approach is also presented.
In-depth insights#
Stream Perception#
Stream perception represents a paradigm shift in computer vision, moving away from the traditional offline paradigm to one that prioritizes real-time processing and latency considerations. Unlike offline methods, which process entire videos or long sequences, stream perception focuses on timely prediction of the next frame based on current and past information. This requires frameworks to efficiently process data and make predictions with minimal delay, as accuracy degrades significantly with increasing latency. The key challenge lies in balancing accuracy and latency, as high-accuracy models often have high computational costs. This necessitates the design of models and algorithms specifically optimized for speed and efficient utilization of historical context, while simultaneously maintaining high accuracy. The emergence of this field signifies a growing need for perception systems capable of responding promptly to dynamic environments, particularly important in autonomous driving and robotics.
Stereo 3D Object Detection#
Stereo 3D object detection is a crucial technology for various applications, particularly autonomous driving and robotics. It aims to identify and locate objects in three-dimensional space using two images from slightly different viewpoints. This approach leverages the principles of binocular vision, mimicking human depth perception. Existing methods are typically categorized into 2D detection-based, pseudo-LiDAR-based, and geometric-volume-based approaches. 2D methods first detect objects in 2D images and then estimate their 3D properties. Pseudo-LiDAR methods generate a depth map from stereo images resembling LiDAR point clouds before performing 3D object detection. Geometric-volume-based methods directly learn 3D representations from stereo data, which can be more accurate but often computationally expensive. Recent advancements have focused on enhancing efficiency and accuracy by incorporating deep learning architectures, exploring novel feature fusion techniques, and refining the use of geometric constraints. A key challenge remains balancing accuracy and real-time performance, especially in applications demanding swift responses. Future research will likely concentrate on improving computational efficiency, handling challenging scenarios (occlusion, varying lighting), and robustly integrating data from other sensors for enhanced reliability.
Feature Flow Fusion#
Feature Flow Fusion (FFF) is a crucial technique for addressing the misalignment problem in streaming perception. It cleverly leverages optical flow principles to warp current features to align with the ground truth of the next frame. This ingenious approach overcomes the temporal discrepancies caused by processing delays in real-time systems. Instead of directly comparing the current frame’s features to the future ground truth, FFF predicts the feature flow between consecutive frames, effectively bridging the temporal gap and enabling accurate comparison. By utilizing this warped or pseudo-next feature, the model can better learn to map current observations to future states, improving the accuracy of predictions in streaming video perception applications. The method is particularly important for moving objects, as their displacement becomes significant over time, exacerbating the misalignment issue. FFF’s ability to effectively align features irrespective of object velocity represents a key enhancement for accurate and reliable streaming perception models.
Motion Consistency#
Motion consistency, in the context of video analysis and autonomous driving, is crucial for robust and reliable 3D object detection. It refers to the accurate prediction of object movement across consecutive frames, maintaining the consistency of object trajectories over time. Inaccuracies in motion prediction lead to misalignments between predicted object locations and ground truth, negatively impacting detection accuracy, particularly for high-speed objects or those undergoing complex maneuvers. Strategies to enforce motion consistency, like those described in the paper, typically involve incorporating temporal information and object tracking techniques, explicitly modeling object motion dynamics to enhance prediction accuracy. Explicit loss functions that penalize inconsistencies in predicted trajectories further improve the model’s ability to learn and maintain accurate motion estimations. Successfully handling motion consistency requires considering various factors like object speed, occlusion, and the sensor’s limitations. Therefore, designing efficient and robust methods is key to the advancement of real-time 3D object detection for autonomous systems.
Future Work#
The paper’s conclusion mentions several avenues for future research. One key area is improving the robustness of the Feature-Flow Fusion (FFF) method, particularly when dealing with occluded or truncated objects. The current approach uses a simple integration of historical features, which is a limitation. Future work should explore the use of neural networks to directly predict the flow of dynamic foreground objects, which could significantly enhance accuracy in challenging scenarios. Another important direction is extending the methodology beyond stereo-based 3D object detection to encompass multi-view camera systems. This would require adapting the BEV representation to accommodate data from multiple perspectives. Finally, more extensive research is needed to address the potential challenges in real-world deployment and edge cases. While the current framework is designed for real-time performance, rigorously testing its capabilities in diverse and unexpected scenarios is crucial. Furthermore, investigating the broader impacts of real-time streaming 3D object detection, including potential safety and privacy implications, would be valuable.
More visual insights#
More on figures

This figure illustrates the challenges in streaming perception, specifically the misalignment between future supervisory signals and current features, implicit supervision when only using the ground truth of a single future frame, and the effective utilization of context information embedded in the combined features. The left panel (a) shows a scenario with low relative velocity, where the misalignment between prediction and ground truth is relatively small. The right panel (b) shows a scenario with high relative velocity, where the misalignment is significantly larger, exacerbating the challenge for the model to accurately predict the future state of moving objects.
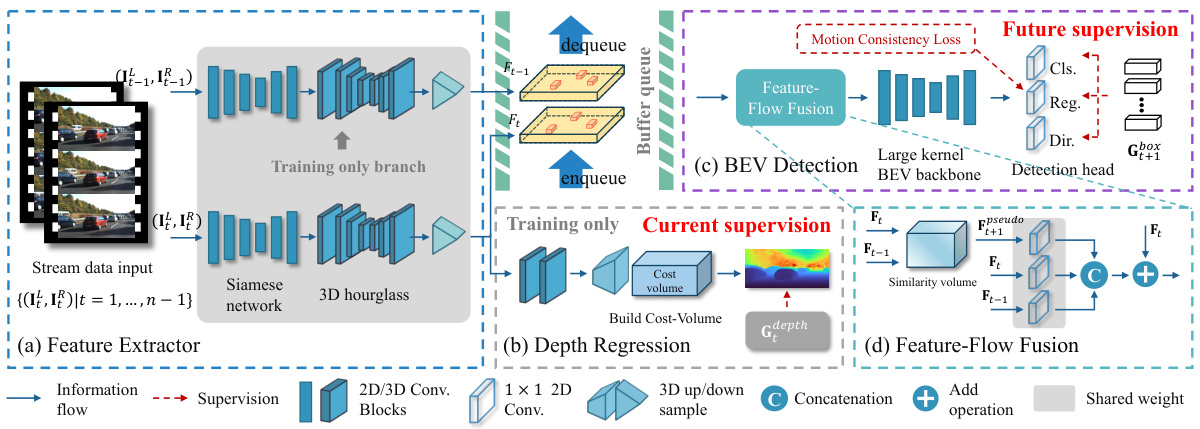
This figure illustrates the architecture of the StreamDSGN pipeline, which is a real-time stereo-based 3D object detection framework designed for streaming perception. It shows four key components: (a) feature extraction, (b) depth regression, (c) BEV detection, and (d) feature-flow fusion. The pipeline leverages historical information to predict the 3D properties of objects in the next moment, addressing challenges associated with streaming perception such as misalignment between features and ground truth.
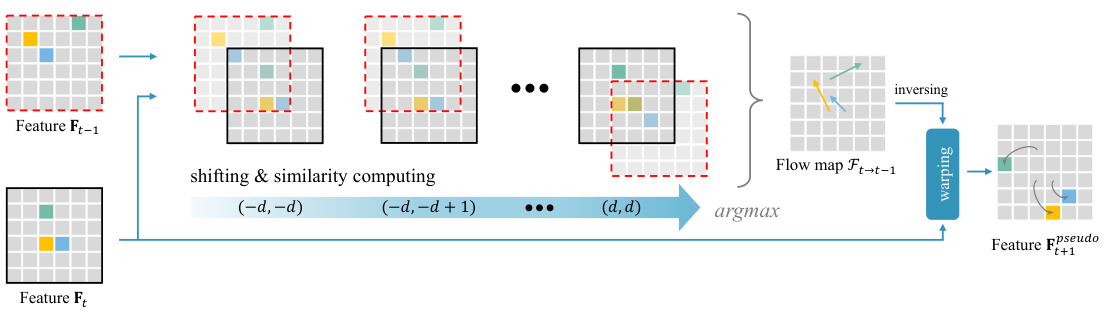
This figure illustrates the process of generating pseudo-next features using Feature-Flow Fusion (FFF). It starts with two feature maps, Ft and Ft-1, representing features from the current and previous frames, respectively. The FFF method computes a similarity volume by shifting Ft-1 relative to Ft and calculating the similarity at each shift. The flow map Ft→t−1 is then obtained by finding the maximum similarity for each pixel in Ft. This flow map indicates the displacement of features between frames. Using this flow map, the current frame’s features (Ft) are warped to align with the ground truth of the next frame (t+1) using an inverse warping operation. The resulting warped features are referred to as pseudo-next features (Fpseudo t+1) which are then used in conjunction with historical features.

This figure illustrates the Motion Consistency Loss (MCL) which is a supplementary regression supervision method for improving the accuracy of object detection in streaming perception. It leverages historical motion trajectories to guide the prediction of the next frame. The figure shows how the velocity and acceleration loss are calculated based on the correspondence between the ground truth and predicted bounding boxes across different time steps. Specifically, it shows how the displacement vector and the sine difference of the rotation angles are used to calculate the velocity loss and how the velocity change is used to calculate the acceleration loss.

This figure shows the architecture of the Large Kernel BEV Backbone (LKBB) used in the StreamDSGN model. (a) depicts the architecture of a single VAN (Visual Attention Network) block, highlighting its components: large kernel attention, feed-forward network, residual connections, and element-wise multiplication. (b) illustrates how multiple VAN blocks are stacked to form the LKBB, along with the inclusion of transpose convolutions and upsampling to generate multi-scale feature fusion. The LKBB is designed to increase the receptive field and improve the model’s capacity to capture long-range dependencies in the bird’s-eye view (BEV) representation.

This figure compares the 3D object detection results of three different methods in various scenarios with different relative velocities between the ego vehicle and other objects. The top row shows the baseline DSGN++ method, which struggles with accuracy when objects are moving relative to the camera. The middle row shows the improved pipeline, which utilizes real-time optimization and fusion of historical frames for prediction. The bottom row displays the results from the proposed method that incorporates three additional enhancement strategies (Feature-Flow Fusion, Motion Consistency Loss, and Large Kernel BEV Backbone) leading to improved accuracy and alignment, particularly in high relative velocity scenarios.

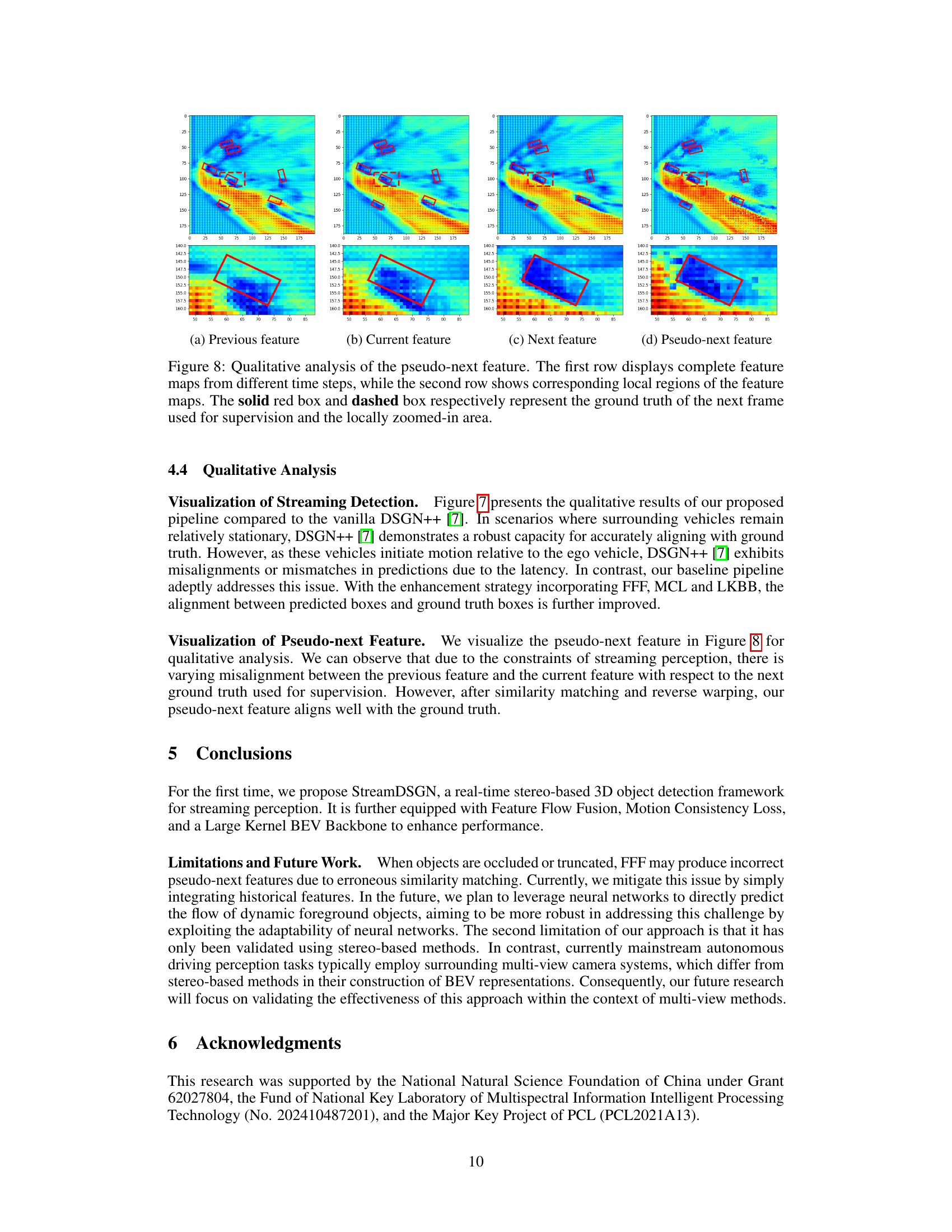
This figure provides a qualitative analysis of the pseudo-next feature generation process in StreamDSGN. The top row shows complete feature maps from previous, current, next, and pseudo-next frames. The bottom row zooms into specific regions of interest within those maps. Red boxes highlight the ground truth location for the next frame (used as supervision during training), while dashed boxes indicate the zoomed region. The comparison helps visualize how well the pseudo-next feature aligns with the actual next frame’s ground truth, demonstrating the effectiveness of the Feature-Flow Fusion (FFF) method in aligning features across time steps.
More on tables
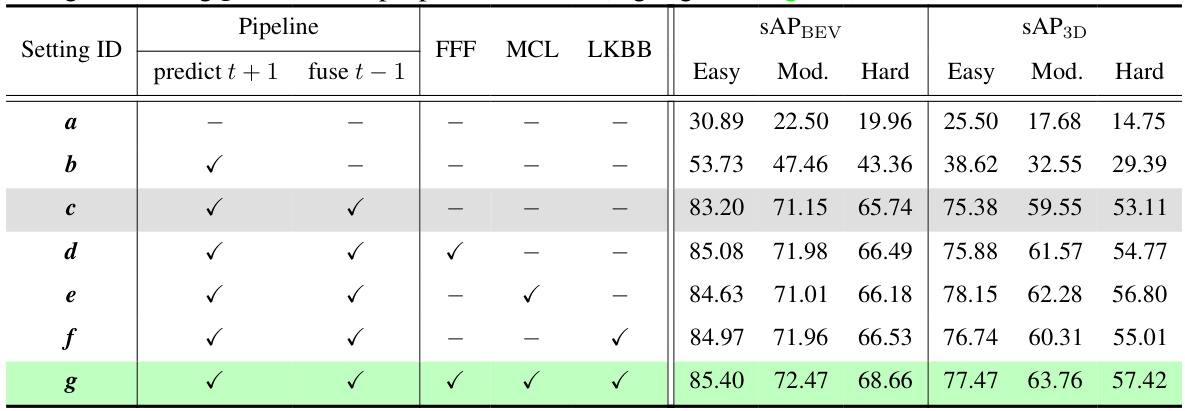
This table presents the results of ablation studies conducted to evaluate the effectiveness of different components and strategies within the StreamDSGN model. It shows the impact of each component on the streaming average precision (sAP) for both BEV and 3D perspectives, categorized by object difficulty (Easy, Moderate, Hard). The table systematically adds components to the baseline model (Setting c) to show the incremental improvements achieved with each addition. The final configuration (Setting g) incorporates all proposed enhancements.
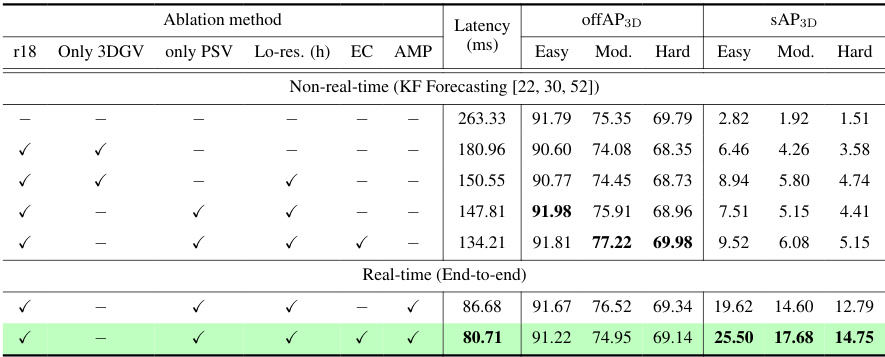
This table compares the proposed method, StreamDSGN, with a meta-detector called Streamer, under various settings. Streamer utilizes either DSGN++ or a real-time optimized version (DSGN++opt) as its base detector and incorporates a Kalman filter for prediction. The table shows the latency (in milliseconds), and streaming average precision (sAP) at IoU thresholds of 0.5 and 0.7 for three object categories (Car, Pedestrian, Cyclist) across three difficulty levels (Easy, Moderate, Hard) for both BEV and 3D perspectives. The results highlight StreamDSGN’s improved performance and efficiency.

This table compares the performance of PointPillars and DSGN++ on the KITTI Object Detection dataset and a custom split of the KITTI Tracking dataset. The purpose is to demonstrate the impact of the dataset split on model performance and analyze the domain gap between the two datasets. The results show that both methods perform better on the custom split Tracking dataset, highlighting a smaller domain gap compared to using the full Object Detection dataset.

This table presents the ablation study results for comparing two different fusion stage locations in the StreamDSGN architecture: before the detection head (as in StreamYOLO) and before the BEV backbone (as proposed in the paper). The results show that placing the fusion stage before the BEV backbone leads to significantly improved performance across all difficulty levels.

This table presents ablation study results on the effectiveness of the Feature-Flow Fusion (FFF) method. It compares the performance of FFF against the state-of-the-art (SOTA) Dual-Flow method [59] using various downsampling ratios (rd) and maximum displacements (d). The results, measured by sAPBEV and sAP3D (streaming average precision for Bird’s Eye View and 3D respectively), across different difficulty levels (Easy, Moderate, Hard), demonstrate the trade-offs between latency and accuracy with different hyperparameter settings of the FFF method.
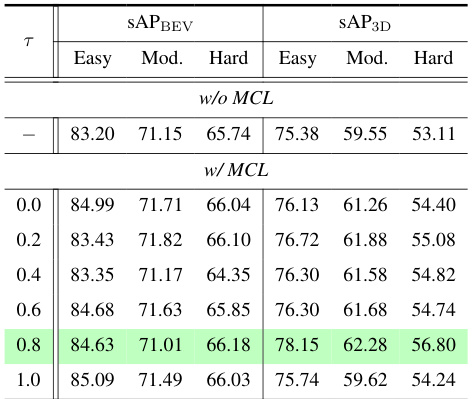
This table presents the results of a grid search performed to find the optimal value of the hyperparameter τ in the Motion Consistency Loss (MCL) function. The search explored various values of τ, ranging from 0.0 to 1.0, and measured the resulting streaming average precision (sAP) for both BEV (Bird’s Eye View) and 3D object detection, categorized by difficulty level (Easy, Moderate, Hard). The table allows for comparison of the performance with and without the MCL function and helps determine the best-performing τ value that balances the velocity and acceleration loss terms in the MCL.

This table compares the performance of the original Hourglass backbone with the proposed Large Kernel BEV Backbone (LKBB). It shows that LKBB, while having a similar number of parameters, achieves a significant reduction in FLOPs (floating point operations) and a modest increase in latency. Despite the slightly higher latency, the enhanced accuracy of LKBB suggests improved efficiency in terms of performance versus computational cost.
Full paper#