↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Universal image representations are crucial for fine-grained recognition. Existing methods struggle with capturing domain-specific knowledge and handling varying data distributions across domains, leading to performance gaps. This paper addresses these limitations.
UDON, the proposed method, uses multi-teacher distillation, where each teacher specializes in a domain, to transfer knowledge to a universal student embedding. It leverages a shared backbone for efficiency and a dynamic sampling technique to adapt to slower-learning domains. Experiments on the UnED benchmark demonstrate significant improvements over state-of-the-art methods, particularly in complex, long-tail domains.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel and efficient approach to creating universal image embeddings, a critical component for various real-world visual recognition applications. Its dynamic sampling technique addresses the challenge of imbalanced data distributions across different domains, significantly improving performance. This work opens avenues for further research in efficient universal representation learning and multi-teacher distillation.
Visual Insights#
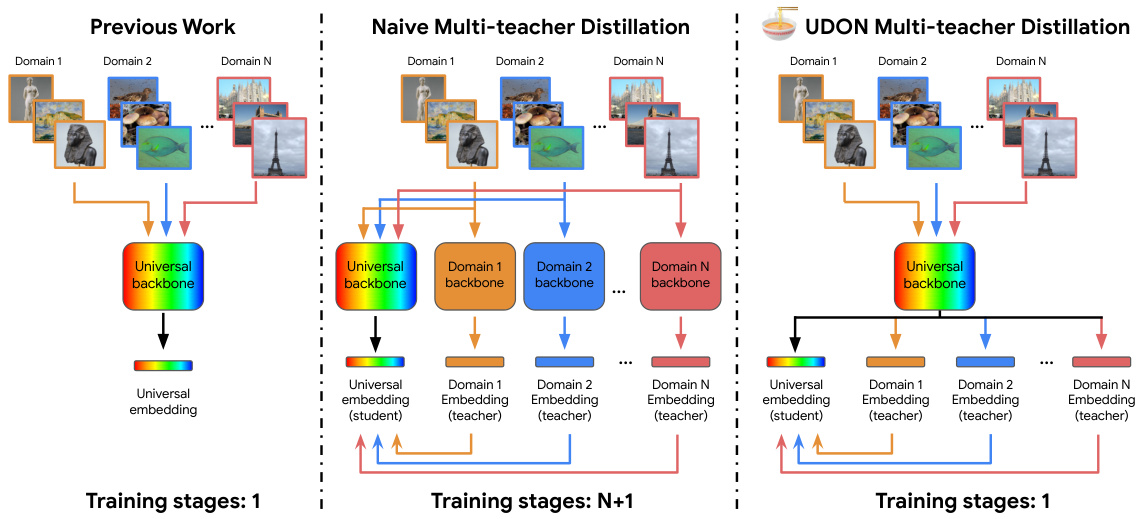
This figure compares three different approaches for training a universal image embedding model. The leftmost shows a baseline approach that trains a single model on all domains simultaneously, which can lead to performance issues due to conflicting cues between domains. The middle shows a naive multi-teacher distillation approach, where separate models are trained for each domain and then distilled into a single student model. The rightmost shows the proposed UDON method, which jointly trains the specialized teacher models and the student model with a shared backbone, allowing for efficient knowledge transfer and scaling to a large number of domains.
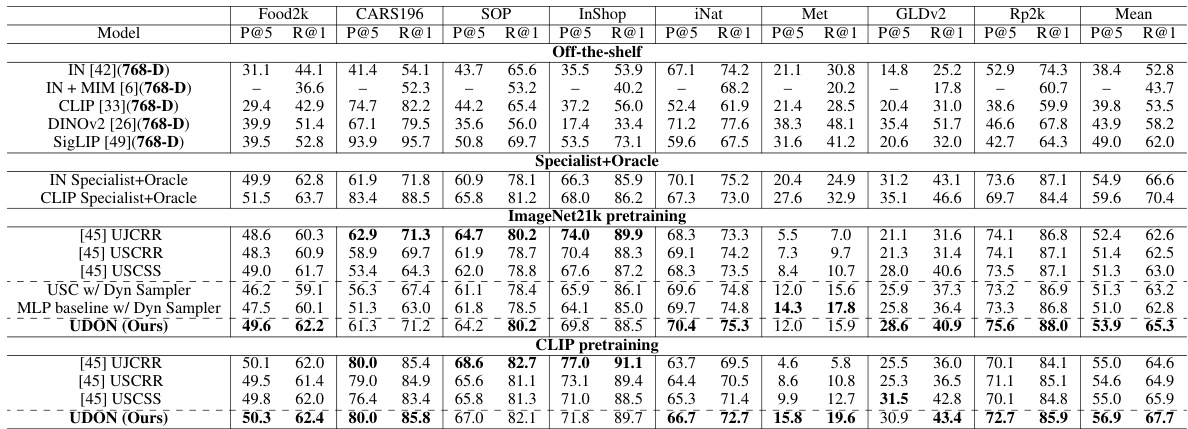
This table presents a comparison of different universal embedding methods on the UnED dataset. It shows the performance (P@5 and R@1) of various methods, including off-the-shelf models and the proposed UDON method, across eight image domains. The table also highlights the best performing method for each pre-training type (ImageNet21k and CLIP) and includes a non-realistic ‘Specialist+Oracle’ model to show the upper bound of performance. All methods use the same ViT-Base/16 backbone architecture.
In-depth insights#
UDON: Multi-Teacher#
The concept of “UDON: Multi-Teacher” suggests a deep learning approach for universal image representation, leveraging the power of multiple specialized teacher models. Each teacher likely focuses on a specific visual domain (e.g., cars, food, animals), capturing domain-specific knowledge. This knowledge is then distilled into a single, universal student model, aiming for superior generalization across diverse domains compared to training a single model on all data. The “UDON” aspect suggests an online, dynamic learning process, possibly adapting the training data distribution based on performance across domains. This dynamic sampling could address the class imbalance and long-tail distribution problems frequently found in real-world datasets. The strength lies in the efficient parameter sharing between the student and teachers, likely sharing a common backbone, making the system scalable to numerous domains without significant increases in computational cost. Joint training is key, allowing the teachers to continuously guide the student’s learning. The effectiveness rests on the careful design of the distillation process, aiming to effectively transfer detailed domain knowledge without conflicting signals from other domains.
Dynamic Sampling#
The effectiveness of multi-task learning models, particularly in the context of universal image embeddings, is significantly impacted by the strategy used for sampling training data from different domains. Dynamic sampling addresses this challenge by moving beyond static, pre-defined sampling methods. Instead, it proposes an adaptive approach where the sampling probabilities are dynamically adjusted throughout the training process, reacting to the model’s performance on various domains. This adaptivity is typically implemented by monitoring the loss or accuracy of each domain during training. Domains that prove more challenging (higher loss) are sampled more frequently, while those exhibiting better performance (lower loss) are sampled less. This adaptive mechanism ensures that the training process focuses on the harder domains, leading to improved overall performance and a reduction in training time. It also alleviates the issues of imbalanced datasets, where some domains may have significantly more data than others. Although computationally more expensive than static sampling, the benefits of dynamic sampling often outweigh the cost through more efficient learning and better generalization across diverse domains. The success of dynamic sampling highlights the importance of considering data distribution and model performance during the learning process to achieve superior universal embeddings.
Distillation Efficiency#
Distillation efficiency in the context of multi-teacher knowledge distillation for universal image embeddings is crucial. Efficient distillation minimizes computational cost while maximizing knowledge transfer from specialized teacher models to a general-purpose student model. The paper’s proposed UDON method leverages a shared backbone architecture among teachers and the student, significantly reducing parameter count and training time compared to naive approaches with separate teacher networks for each domain. This shared backbone is key to UDON’s efficiency. However, the effectiveness of shared parameters hinges on careful design of the distillation loss function and dynamic sampling strategy. The distillation loss needs to effectively guide the student towards learning domain-specific knowledge without losing the universality of representation. Dynamic sampling, by intelligently adapting the training process to address domains which are more challenging, further enhances efficiency by avoiding wasteful computations on already well-learned domains. The overall efficiency is a result of both architectural design and training methodology working synergistically, thereby demonstrating the effectiveness of the proposed approach.
Ablation Experiments#
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of a universal image embedding model, ablation experiments might involve removing or altering key elements such as the dynamic sampling strategy, multi-teacher distillation, different distillation loss functions, or the shared backbone architecture. By observing the impact of these removals on the model’s performance (e.g., Recall@1 and Mean Average Precision), researchers can gain valuable insights into the effectiveness of each component. For example, disabling dynamic sampling could reveal whether the adaptive batch allocation is crucial for learning complex domains, while removing a distillation loss function might showcase whether that component truly benefits the transfer of domain-specific knowledge. A well-designed ablation study provides crucial evidence supporting the paper’s claims by isolating the contributions of each design decision and demonstrating its importance. Such experiments not only strengthen the paper’s arguments, but also offer valuable insights for future research directions.
Future Research#
Future research directions stemming from this work on universal dynamic online distillation (UDON) could explore several promising avenues. Improving the efficiency of the dynamic sampling strategy is crucial; while effective, the current method could benefit from more sophisticated approaches to balance computational cost with learning speed. Investigating alternative distillation loss functions beyond KL divergence and cosine similarity could potentially enhance performance and robustness, especially for complex, long-tailed datasets. Furthermore, extending the approach to multimodal learning by incorporating textual data alongside images could unlock exciting new capabilities for generic visual representations. This would entail developing a robust mechanism for fusing visual and textual information in the shared backbone. Finally, scaling UDON to significantly larger datasets and a more diverse range of domains remains a significant challenge, requiring exploration of efficient training strategies for massive-scale universal model learning. Addressing these research directions would make UDON even more versatile and impactful for real-world applications.
More visual insights#
More on figures
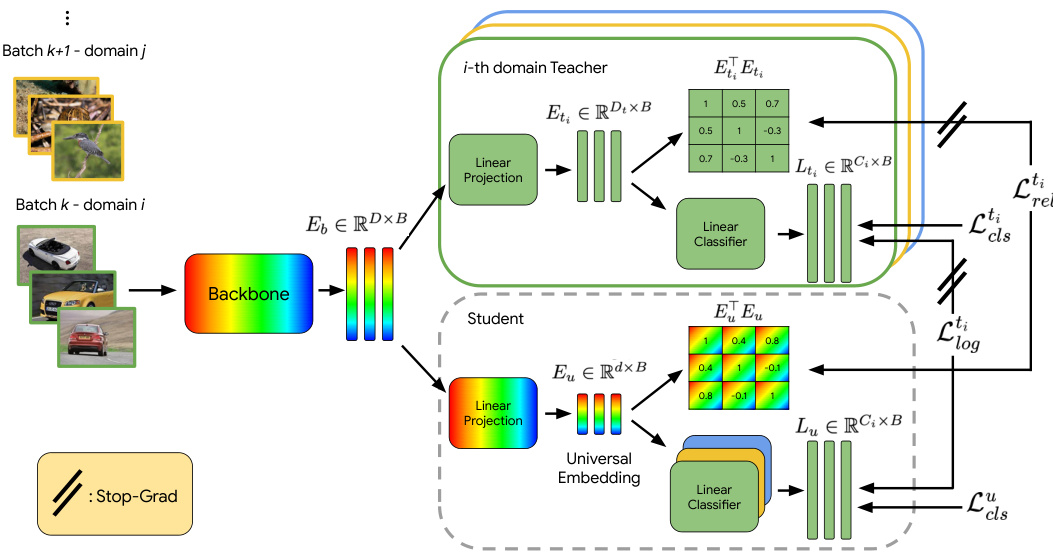
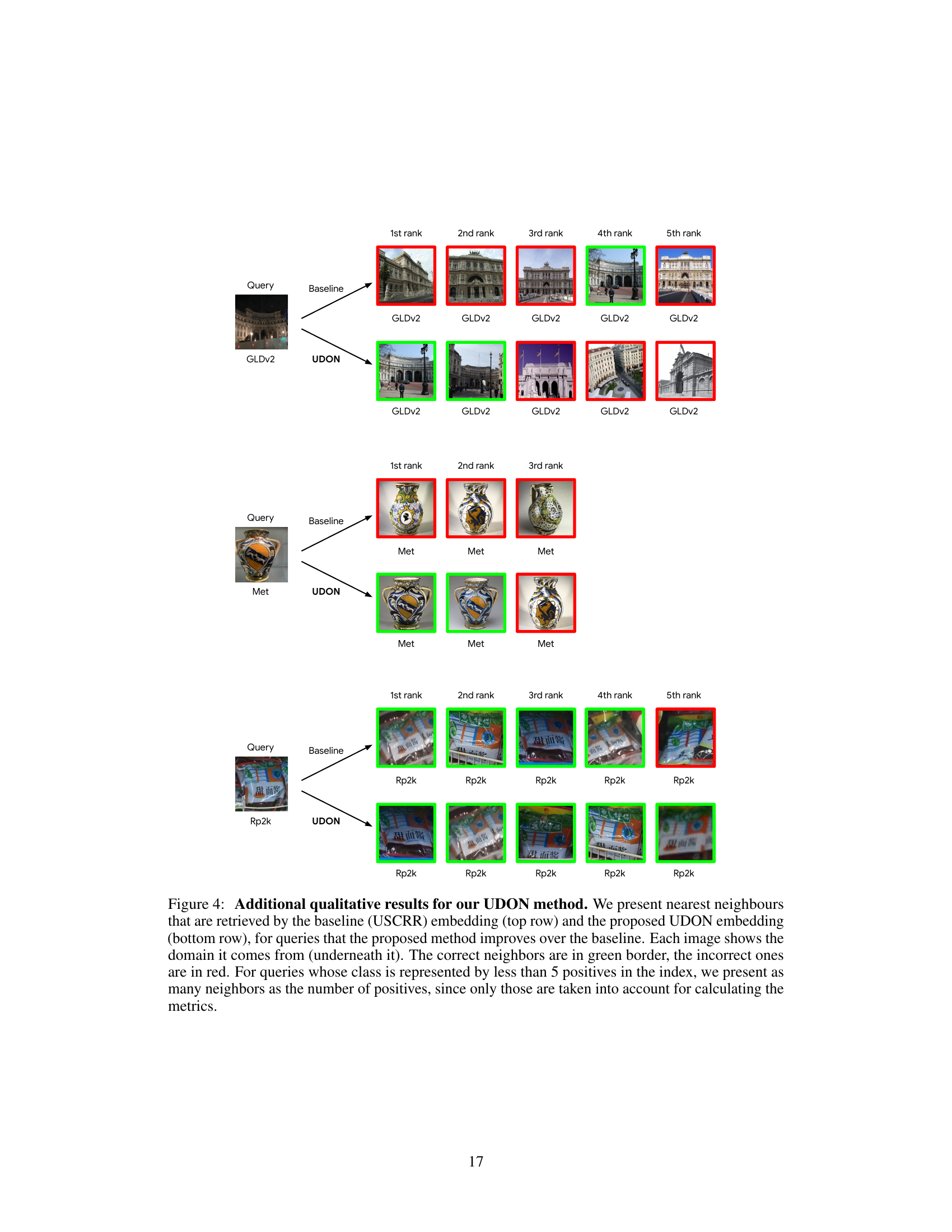
This figure illustrates the training process of the UDON model. It shows how batches of images from a single domain are processed. Each domain has a specialized teacher model that shares a backbone with a universal student model. Both teacher and student use classification loss. Additionally, the student model is trained via distillation from the teacher model, using both relational and logit distillation losses to improve its accuracy. The distillation losses only backpropagate through the student’s head.
The figure illustrates the training process of the UDON model. It shows how batches of images from a single domain are processed, with each batch activating a corresponding teacher head. Both the teacher and student models use a classification loss, and the student model also uses distillation losses to learn from the teacher. The shared backbone and online nature of the training are highlighted.

This figure illustrates the training process of the UDON model. It shows how batches of images from a single domain are fed into a shared backbone network. For each domain, a teacher head and a student head process the output of the backbone. Both teacher and student employ classification losses to learn from their respective logits. Additionally, the student undergoes distillation training, leveraging both intra-batch relationship similarities and logits from its corresponding domain teacher. This distillation process is designed to transfer domain-specific knowledge from the teachers to the universal student model, while keeping the distillation losses’ backpropagation confined to the student’s head only.

This figure illustrates three different approaches for training a universal image embedding model on multiple fine-grained visual domains. The left shows a baseline method using classification loss, the middle shows a naive multi-teacher distillation approach, and the right shows the proposed UDON method, which jointly trains specialized teacher embeddings and the universal embedding using a shared backbone.

This figure illustrates three different approaches to training a universal image embedding model. The left shows a baseline method that uses classification loss across all domains, which can lead to conflicting cues and suboptimal learning. The middle depicts a naive multi-teacher distillation approach that pre-trains specialized models per domain before distilling knowledge to the universal model, increasing computational costs. The right panel introduces the proposed UDON method, which jointly trains both specialized teacher models and the universal embedding model efficiently by sharing the model backbone. This approach overcomes the limitations of previous approaches, resulting in better performance and scalability.
This figure illustrates the training process of the UDON model. It shows how batches of images from a single domain are processed. Each domain has a specialized teacher head and a shared backbone. The student model learns from both classification and distillation losses, improving its ability to generalize across different domains.
More on tables
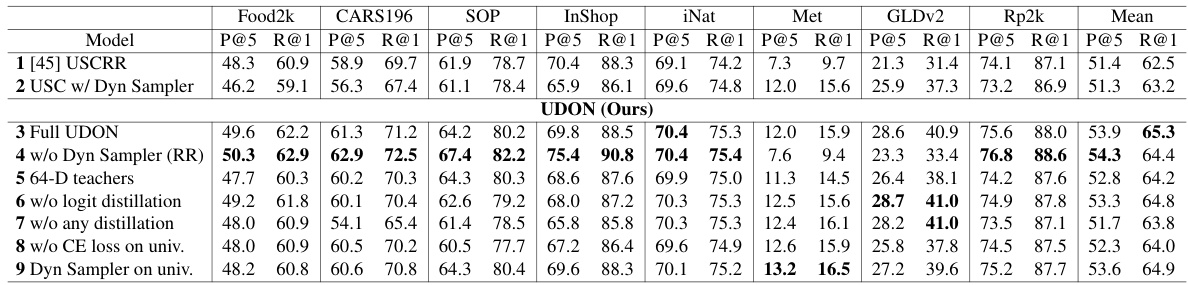
This table compares the performance of the proposed UDON model against several baseline methods and off-the-shelf models on the UnED dataset. It shows Recall@1 and Mean Precision@5 for each of eight domains, as well as the mean across all domains. The table highlights the best performing method for each pre-training type (ImageNet21k and CLIP). A non-realistic ‘Specialist+Oracle’ model is included to show the upper bound of performance achievable.

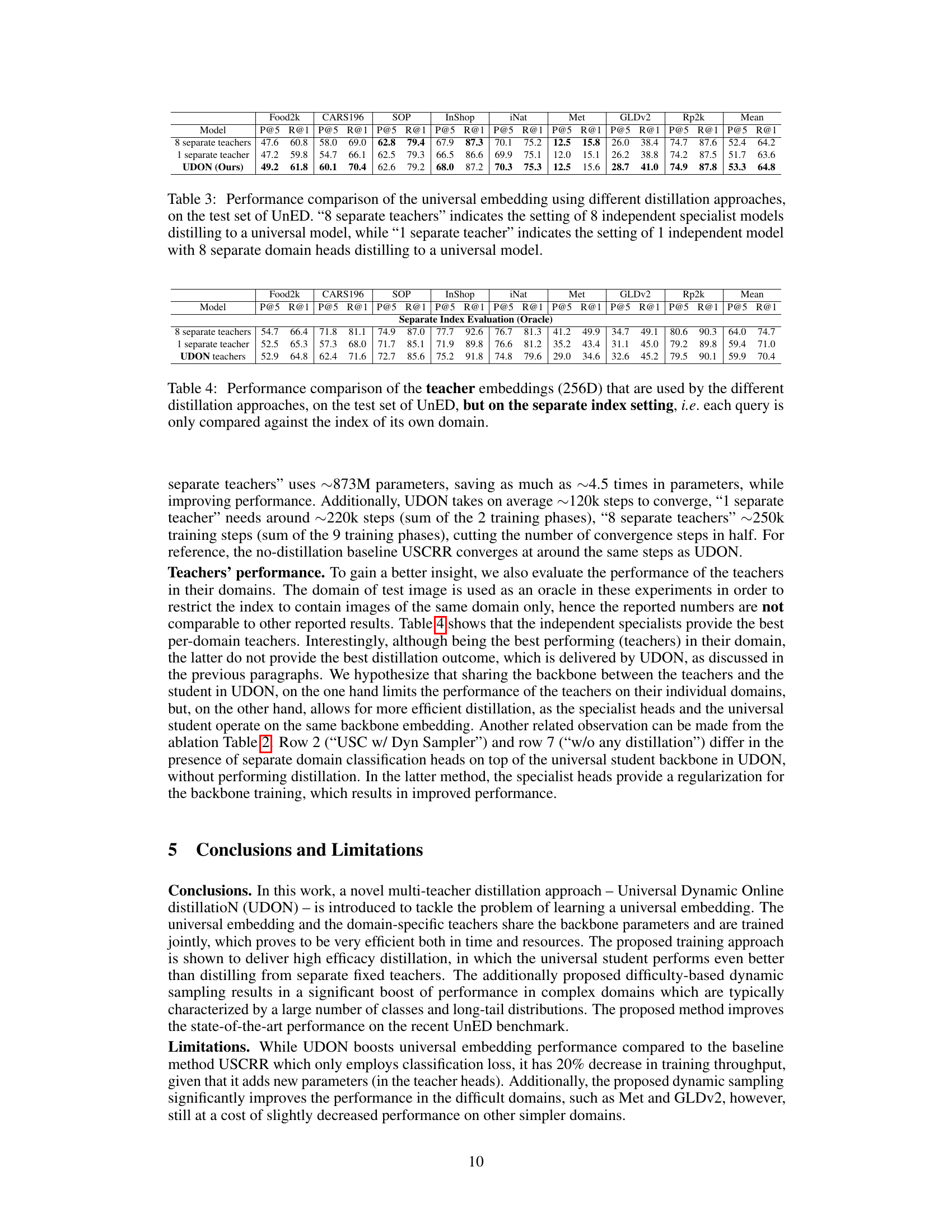
This table compares the performance of three different multi-teacher distillation methods on the UnED dataset. The methods are: 8 separate teachers (where each teacher is a separate model trained on a single domain), 1 separate teacher (where a single model with multiple heads is used, one for each domain), and UDON (the proposed method). The table shows that UDON outperforms both other methods in terms of mean P@5 and R@1.

This table compares the performance of different teacher embedding methods (8 separate teachers, 1 separate teacher, and UDON teachers) when evaluating on a per-domain basis. Instead of comparing against the entire UnED dataset, each query is only compared to images from its own domain (as indicated by the parenthetical ‘(Oracle)’). This setup provides a more controlled evaluation of the teacher embeddings’ ability to capture domain-specific knowledge.

This table compares the performance of UDON with the UJCRR baseline method from the paper [45] using a smaller backbone size (ViT-Small). The table shows that UDON achieves better performance than the baseline in terms of both P@5 and R@1 metrics on the UnED dataset.

This table compares the performance of the proposed UDON model and the USCRR baseline model from a previous work ([45]). The comparison is done using two different backbone sizes: ViT-Base and ViT-Large. The results show the mean P@5 and R@1 scores across multiple domains for each model and backbone size, highlighting the impact of the model and backbone size on retrieval performance.
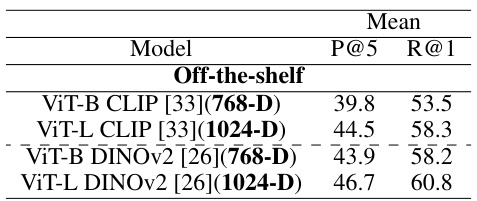
This table compares the performance of the proposed UDON model against other state-of-the-art universal image embedding methods on the UnED dataset. It shows Recall@1 and Mean Precision@5 for each of eight image domains, along with overall mean performance. The table also includes results for off-the-shelf models (with much higher dimensional embeddings) and a non-realistic ‘Specialist+Oracle’ model to show the potential upper bound of performance.

This table compares the performance of the proposed UDON model against several baselines and off-the-shelf models on the UnED dataset. It shows Recall@1 and Mean Precision@5 for each of eight domains and the average across all domains. The table highlights the best performing model for different pre-training methods (ImageNet-21k and CLIP). A ‘Specialist+Oracle’ model provides an upper bound of performance.

This table compares the performance of the original UDON model against a modified version. The modification replaces the linear projection layers with multi-layer perceptrons (MLPs) for both the universal embedding and domain-specific teacher embeddings. The results show that the MLP-based projectors lead to a slight decrease in performance on the UnED benchmark.
Full paper#