↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current text-to-image models often struggle to generate images that precisely match user descriptions. Existing solutions relying on human-labeled datasets are expensive and lack diversity. This paper proposes using multimodal large language models to create a large, fine-grained preference dataset (VisionPrefer) automatically. This dataset captures various aspects of image quality (prompt following, aesthetics, fidelity, and harmlessness).
The researchers trained a reward model (VP-Score) on VisionPrefer and used reinforcement learning methods to fine-tune text-to-image models. Results showed significant improvements in text-image alignment across multiple aspects, surpassing the performance of models trained with human-annotated datasets. VisionPrefer and VP-Score were released publicly for further research.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to improving the alignment between text and image in text-to-image generation models. By leveraging multimodal large language models, the research significantly reduces the cost and time required for data creation and yields higher-quality results. This methodology could have a considerable impact on various downstream tasks that involve image generation based on textual descriptions, making the results more aligned with human preferences. The proposed method also offers new opportunities for future exploration in generating high-quality images more efficiently and effectively.
Visual Insights#

This figure shows the improvements in image generation quality after optimizing a baseline text-to-image model using fine-grained feedback from a multimodal large language model. The left column displays images generated by the baseline model, while the right column presents the improved images generated after optimization. Four aspects are highlighted and compared: Prompt Following (how well the image matches the prompt), Aesthetics (visual appeal), Fidelity (accuracy of object representation), and Harmlessness (absence of inappropriate content). The improvement is visually evident across all four aspects.

This table compares several existing datasets used for evaluating the performance of text-to-image generative models. It highlights key features of each dataset, including the number of preference choices, whether the dataset is open-source, whether it provides fine-grained feedback (assessing multiple aspects of image quality), and the format of the feedback (ranking, text, or scalar scores). The table demonstrates the limitations of existing datasets and positions the new VisionPrefer dataset as an improvement in terms of scalability, fine-grained feedback, and data size.
In-depth insights#
Multimodal LLMs’ Role#
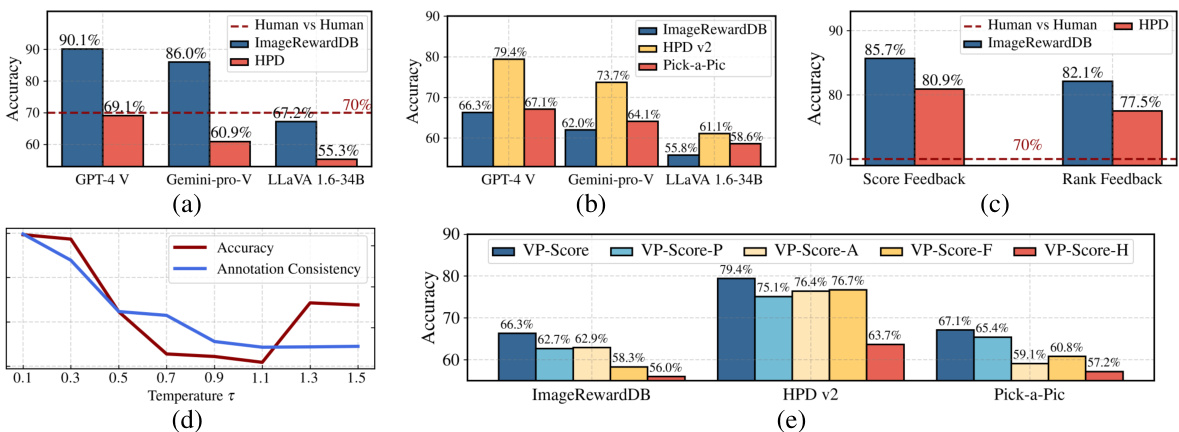
The core role of multimodal large language models (MLLMs) in this research is to act as high-quality preference annotators for a text-to-image generation task. Instead of relying on expensive and potentially biased human annotations, the researchers leverage the MLLMs’ ability to understand both text and images to generate a massive, fine-grained preference dataset. This dataset, VisionPrefer, is crucial because it captures diverse preference aspects such as prompt-following, aesthetic quality, fidelity, and harmlessness, which are often overlooked in smaller human-annotated datasets. The scale and granularity of VisionPrefer allow for training a robust reward model (VP-Score) that effectively guides the reinforcement learning process to better align text-to-image models with human preferences. This strategy effectively addresses the limitations of existing datasets while offering a scalable and cost-effective solution for instruction tuning in text-to-image generation, highlighting the transformative potential of MLLMs in improving the alignment between AI-generated outputs and human expectations.
VisionPrefer Dataset#
The VisionPrefer dataset represents a significant advancement in text-to-image generative model training. Its scale and low cost are notable, surpassing existing human-curated datasets in size. This scalability stems from its AI-generated nature, using a multimodal large language model (MLLM) for annotation, significantly reducing resource demands. Further, the fine-grained preference annotations within VisionPrefer are a crucial improvement over broad comparisons in previous work, offering more diverse and nuanced evaluations across prompt-following, aesthetics, fidelity, and harmlessness. This multi-faceted assessment enables more robust model training and a deeper understanding of human preferences. Finally, public availability of VisionPrefer fosters collaboration and further research, accelerating progress in text-to-image generation.
RLHF Model Tuning#
Reinforcement Learning from Human Feedback (RLHF) model tuning represents a crucial advancement in aligning AI models with human preferences. This technique leverages human evaluations to guide the fine-tuning process, effectively steering the model away from undesirable outputs and towards those more aligned with human values and expectations. A key aspect is the design of the reward model, which learns to predict human preferences. This model then guides the reinforcement learning algorithm, updating the generative model’s parameters to maximize the predicted reward. Careful selection of the reward model architecture and training data is critical for success. Furthermore, the choice of reinforcement learning algorithm (e.g., PPO, DPO) also significantly influences performance. While RLHF offers substantial improvements in model alignment, it is not without limitations. The reliance on human feedback introduces both cost and scalability challenges. Bias in human feedback can also propagate into the model, potentially perpetuating existing societal biases. Finally, understanding and mitigating the ethical implications of RLHF is crucial for responsible development and deployment of aligned AI systems.
AI Feedback’s Impact#
The integration of AI feedback significantly enhances the performance of text-to-image generative models. AI feedback mechanisms, such as reward models trained on AI-generated preference datasets, provide a scalable and cost-effective alternative to human annotation. This allows for more comprehensive and diverse feedback, leading to improved image quality, aesthetic appeal, and alignment with user prompts. While human feedback remains valuable for setting high-level preferences, AI feedback proves crucial for efficiently refining models and addressing diverse aspects of image generation such as fidelity, prompt following, and harmlessness. The effectiveness of AI feedback is validated by comparing AI-tuned models to those trained with human feedback on benchmark datasets, consistently demonstrating improved alignment with human preferences. However, it is important to acknowledge the limitations of AI feedback, including potential biases in AI-generated data and the need for careful design of AI feedback systems to avoid unintended consequences. Future research will further explore the optimization of AI feedback methodologies, focusing on mitigating bias and enhancing generalization capacity to fully realize the potential of AI-driven model improvement.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Scaling VisionPrefer to even larger datasets would likely yield further improvements in text-to-image alignment. Investigating alternative MLLMs beyond GPT-4 and exploring different prompt engineering strategies for preference elicitation are important. Developing more sophisticated reward models that better capture nuanced aspects of human preference, potentially incorporating additional dimensions such as creativity and emotional impact, is crucial. Furthermore, exploring the effectiveness of VisionPrefer and its corresponding reward model VP-Score with other text-to-image generation models beyond Stable Diffusion is essential to evaluate broader applicability. Investigating the use of VisionPrefer in other generative tasks, such as video and 3D model generation, holds significant potential. Finally, researching methods to effectively incorporate the textual explanations provided in VisionPrefer to enable automated image editing and refinement based on AI feedback warrants further exploration.
More visual insights#
More on figures

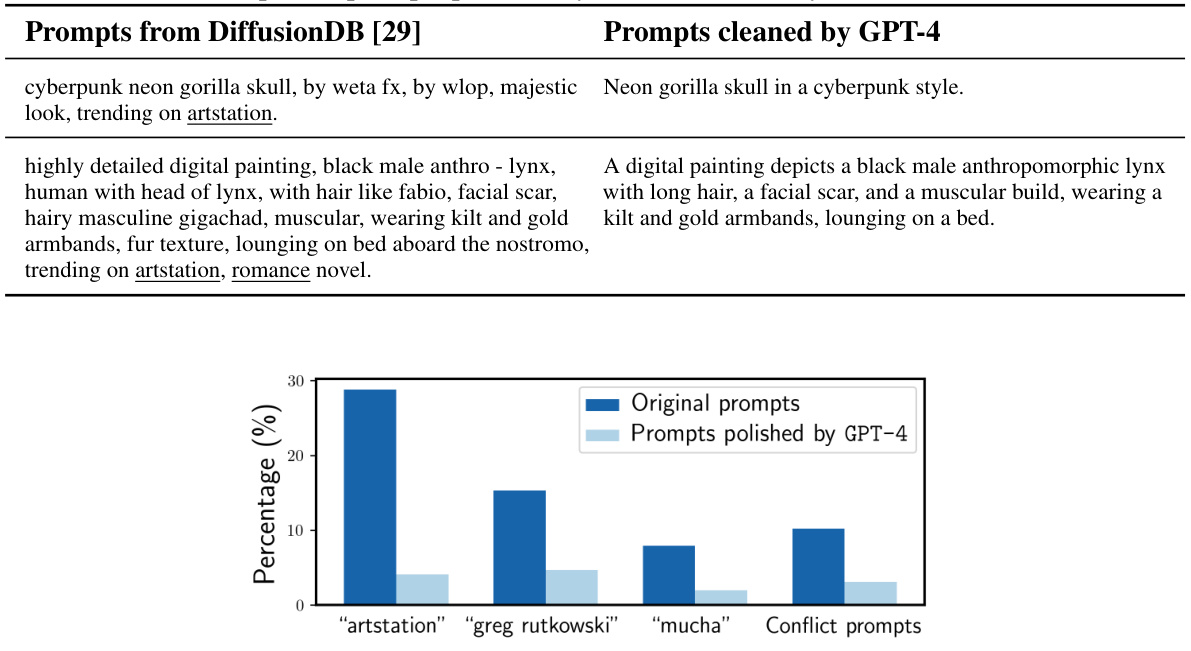
The figure illustrates the process of constructing the VisionPrefer dataset. It starts with selecting prompts from the DiffusionDB and then polishing them using GPT-4 to remove biases and inconsistencies. These polished prompts are used to generate images using diverse text-to-image generative models (GANs and diffusion models). Finally, GPT-4 V provides fine-grained preference annotations for these generated images considering four aspects: prompt-following, fidelity, aesthetic, and harmlessness. The annotations are given in both numerical scores and textual explanations.

This figure shows the evaluation results of text-to-image model generation quality using multiple reward models while maximizing VP-Score during the PPO training process. The y-axis represents the normalized reward score, and the x-axis represents the training steps. The lines represent different reward models, including ImageReward, Aesthetic, PickScore, HPS v2, and the proposed VP-Score. The figure illustrates how VP-Score improves the generation quality over training steps compared to other reward models.
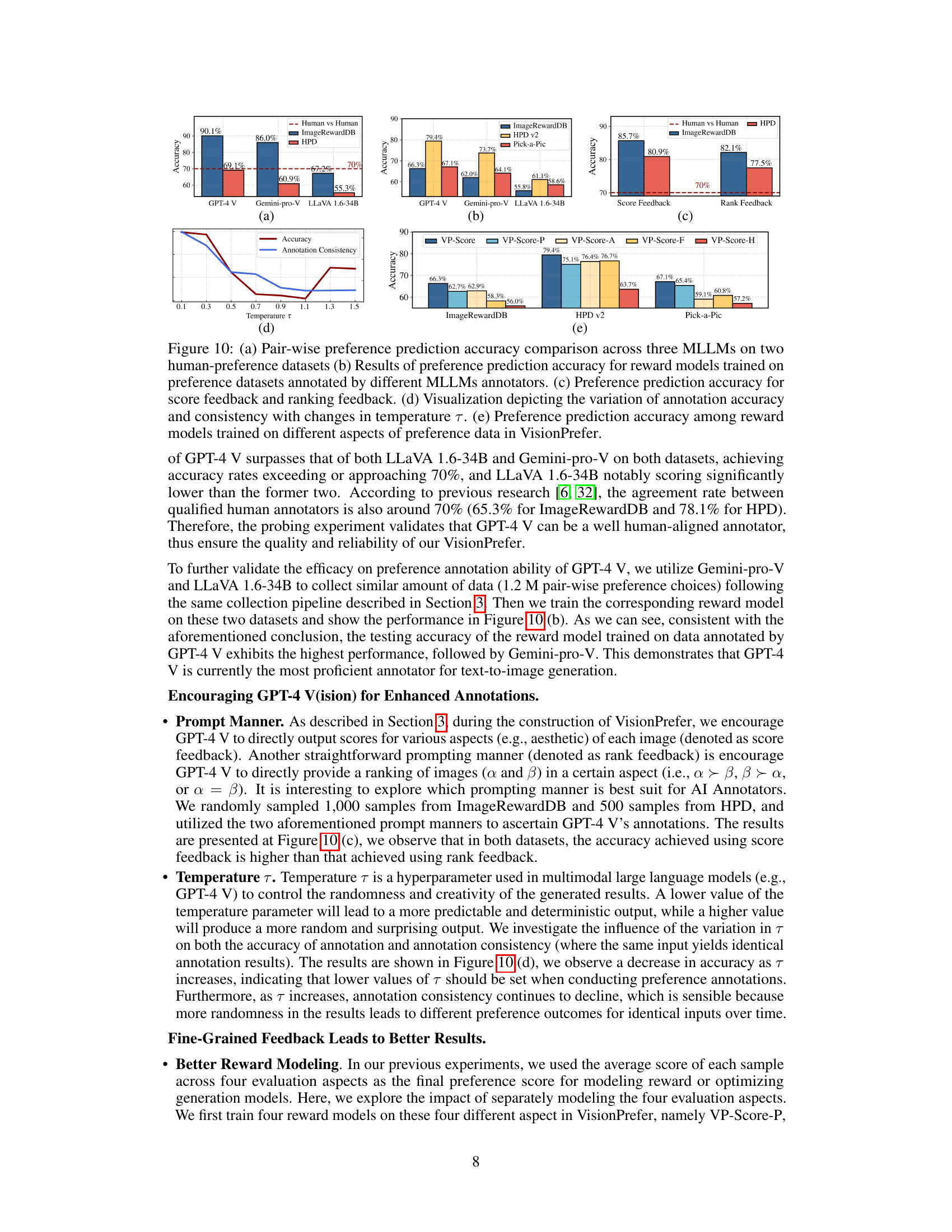
This figure presents a comparison of the performance of generative models fine-tuned using different reward models. The models were evaluated on three benchmark datasets (DiffusionDB, ImageRewardDB, and HPD v2) using the Proximal Policy Optimization (PPO) method. The VP-Score reward model, trained using the VisionPrefer dataset, is compared against other reward models (CLIP, Aesthetic, ImageReward, PickScore, and HPS v2). The win rate, tie rate, and loss rate are shown for each model on each dataset, providing a comprehensive view of the comparative performance of VP-Score and existing reward models in improving text-to-image generation.

This figure shows the qualitative results of using Proximal Policy Optimization (PPO) to fine-tune the Stable Diffusion v1.5 model. Two prompts are used to generate images with different reward models, including the baseline Stable Diffusion v1.5 model and those fine-tuned with various reward models, such as CLIP, Aesthetic, ImageReward, PickScore, HPS v2, and VP-Score (the proposed model). The figure showcases improvements in the quality of generated images with the VP-Score model in terms of both prompt adherence and aesthetic appeal.

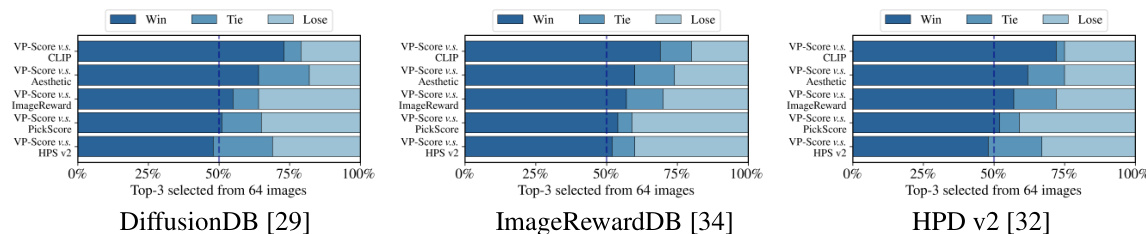
This figure shows the results of a human evaluation study comparing the performance of generative models fine-tuned using VP-Score against other reward models. The evaluation is performed on three different test benchmarks (DiffusionDB, ImageRewardDB, and HPD v2). The win rate represents the percentage of times the model using VP-Score produced a better image than the other models. A ‘Tie’ indicates cases where human evaluators deemed the images to be of comparable quality. The figure visually represents the comparative performance of VP-Score against other existing reward models in improving the alignment of generated images with human preferences.

This figure shows the qualitative results of applying Proximal Policy Optimization (PPO) to fine-tune the Stable Diffusion v1.5 model using different reward models. The left side displays images generated by the baseline model (SD 1.5), while the right side showcases results after optimization using various methods. Each row represents a different prompt, and the columns represent different reward models: CLIP, Aesthetic, ImageReward, PickScore, HPS v2, and the authors’ VP-Score. The improved quality of images generated with VP-Score, particularly in terms of aesthetics and alignment with the prompt, is highlighted.

The figure illustrates the pipeline used to construct the VisionPrefer dataset. It begins with sampling textual prompts and selecting text-to-image generative models. These are used to generate pairs of images, which are then passed to GPT-4 V along with a detailed guideline. GPT-4 V provides fine-grained preference annotations in textual and numerical formats, covering Prompt-Following, Fidelity, Aesthetic, and Harmlessness. This process generates a large-scale, high-quality, and fine-grained preference dataset for text-to-image generative models.
This figure shows the improvements in image generation quality when using a multimodal large language model to provide fine-grained feedback. The left side displays images generated by a baseline text-to-image model, while the right side shows images generated by the same model but optimized with feedback from the multimodal model. The improvement is illustrated across four key aspects: how well the image follows the prompt, its aesthetic quality, its fidelity to the prompt’s description, and whether it is harmless (i.e., free from inappropriate content).

This figure shows a comparison of image generation results from different reward models, including VP-Score, when given the prompt: ‘A hyper-realistic portrait of a woman holding flowers, featuring a cottagecore and grunge aesthetic.’ VP-Score’s results show a better alignment with the prompt’s specific aesthetic requests (cottagecore and grunge) compared to other reward models. The Appendix contains more examples.

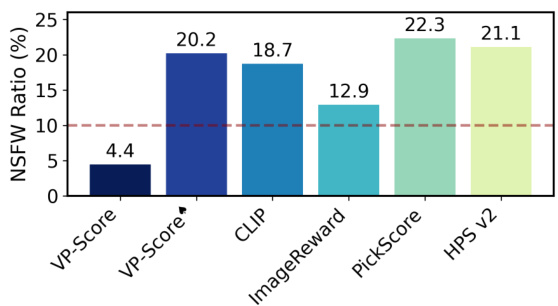
This figure showcases the impact of incorporating fine-grained feedback from a multimodal large language model (MLLM) on the quality of images generated by a text-to-image model. The left side displays images generated by the baseline model, while the right side shows images generated after optimization using MLLM feedback. The improvements are highlighted across four key aspects: how well the image follows the prompt, its aesthetic appeal, image fidelity (accuracy in representing the prompt), and harmlessness (absence of NSFW or offensive content).

This figure presents a qualitative comparison of images generated using different reward models in conjunction with the Stable Diffusion v1.5 model. The comparison highlights the impact of fine-tuning using the VP-Score reward model compared to other reward models such as CLIP, Aesthetic, ImageReward, PickScore, and HPS v2. The images shown represent examples of model outputs across different prompts. The appendix contains additional examples.
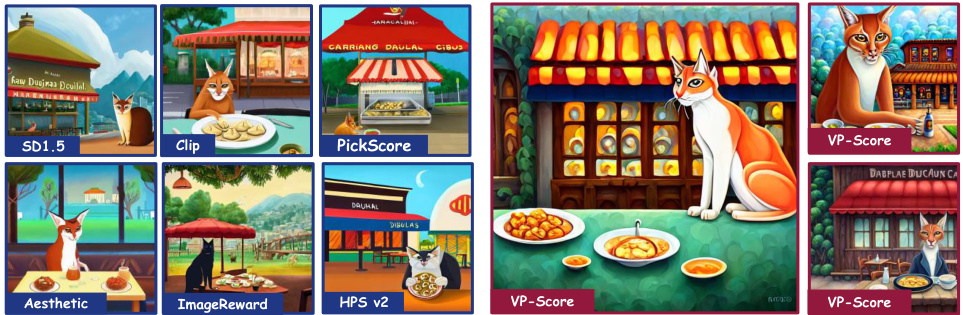
This figure shows the qualitative results obtained from experiments using Proximal Policy Optimization (PPO). It compares image generation results from the Stable Diffusion v1.5 model (without fine-tuning) against those fine-tuned using different reward models (CLIP, Aesthetic, ImageReward, PickScore, HPS v2, and VP-Score). The comparison highlights the improvements in image quality achieved by using the VP-Score reward model, showcasing better alignment with the provided prompts. Additional examples are provided in the Appendix.

This figure shows qualitative results obtained after fine-tuning the Stable Diffusion v1.5 model using Proximal Policy Optimization (PPO). It compares image generation results using different reward models: CLIP, Aesthetic, ImageReward, PickScore, HPS v2, and VP-Score (the model trained with the VisionPrefer dataset). The goal is to demonstrate how the VisionPrefer dataset and the VP-Score reward model improve the alignment between the generated images and the text prompts. The ‘SD 1.5’ column displays results from the Stable Diffusion v1.5 model without any fine-tuning, serving as a baseline. The additional samples in the Appendix offer a more comprehensive comparison.

This figure shows a qualitative comparison of images generated by Stable Diffusion v1.5 model fine-tuned with different reward models, including VP-Score and other reward models like CLIP, PickScore, Aesthetic, and HPS v2. Each row presents a different prompt, and each column shows the output generated by a specific reward model. The purpose is to visually demonstrate the improved quality and alignment with the prompt achieved by using VP-Score, compared to other methods. The images demonstrate that VP-Score leads to images better aligned with the prompt and higher quality.

This figure showcases a qualitative comparison of image generation results using different preference datasets to fine-tune the Stable Diffusion v1.5 model. The top row shows images generated with prompts related to Batman, and the bottom row shows images generated with prompts related to cars. The different columns represent different preference datasets used for fine-tuning, including the proposed VisionPrefer and other existing datasets such as HPD, ImageRewardDB, and Pick-a-Pic. The goal is to visually demonstrate how using the VisionPrefer dataset results in images that more closely align with user preferences compared to models trained on the other datasets.

This figure shows a qualitative comparison of images generated by Stable Diffusion v1.5 model fine-tuned using different preference datasets. The top row shows images generated with the prompt ‘batman monster digital art, fantasy, magic, trending on artstation, ultra detailed, professional illustration by Basil Gogos’. The bottom row shows images generated with the prompt ‘car in center JZX100 twin turbo drift on a road, surrounded by trees and buildings in Tokyo prefecture, rooftops are Japanese architecture, city at sunset heavy mist over streetlights, cinematic lighting, photorealistic, detailed wheels, highly detailed’. Each column represents a different preference dataset used for fine-tuning: SD1.5 (no fine-tuning), HPD, ImageRewardDB, Pick-a-Pic, and VisionPrefer (multiple columns for VisionPrefer to show variations). The figure demonstrates the impact of the different preference datasets on image quality and alignment with the text prompts. VisionPrefer shows improvements in detail, style, and adherence to the prompt.
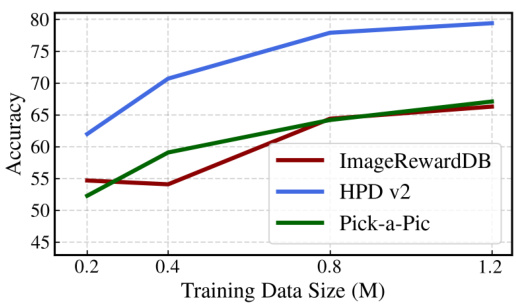
The figure shows the ablation study for different sizes of training datasets used in optimizing VP-Score. The x-axis represents the training data size in millions, and the y-axis represents the accuracy. Three lines represent the accuracy on three different datasets: ImageRewardDB, HPD v2, and Pick-a-Pic. The results show that increasing training data enhances VP-Score’s prediction accuracy. This indicates that models trained on VisionPrefer exhibit strong performance scalability, implying that more training data leads to further performance improvements.
This figure shows a comparison between images generated by a baseline text-to-image model and those generated by the same model after being fine-tuned using feedback from a multimodal large language model (MLLM). The left side displays images from the baseline model, while the right side shows images generated after the fine-tuning. The improvement is highlighted across four key aspects: how well the image follows the prompt, its aesthetic appeal, image fidelity (accuracy in portraying specified details), and harmlessness (absence of inappropriate content).

This figure shows the improvements in image generation quality achieved by using fine-grained feedback from a multimodal large language model. The left side displays images generated by a baseline text-to-image model, while the right side shows images generated by the same model after optimization with the multimodal feedback. The improvements are illustrated across four key aspects: how well the image follows the prompt, its aesthetic appeal, its fidelity to the prompt’s description, and its harmlessness.

This figure shows the impact of multimodal large language models (MLLMs) on improving the alignment of text-to-image generative models. The left side displays images generated by a baseline model, while the right shows images generated by the same model but optimized using feedback from the MLLM. The improvements are illustrated in four aspects: how well the image follows the text prompt, its aesthetic quality, its fidelity to the prompt’s description, and its harmlessness (absence of inappropriate content).

This figure shows the qualitative results of using Proximal Policy Optimization (PPO) for fine-tuning text-to-image generative models. It compares images generated by the Stable Diffusion v1.5 model without any fine-tuning (SD 1.5) against images generated after fine-tuning with various reward models (CLIP, Aesthetic, ImageReward, PickScore, HPS v2, and VP-Score). The goal is to visually demonstrate the improvement in image quality and alignment with text prompts achieved by using the VP-Score reward model, which leverages the VisionPrefer dataset.

This figure displays the qualitative results of the Proximal Policy Optimization (PPO) experiments conducted in the paper. It showcases images generated by Stable Diffusion v1.5 (SD 1.5) model without any fine-tuning (baseline) and the same model after fine-tuning with various reward models, including the model’s own VP-Score. The comparison highlights the improvement in image generation quality when using the VP-Score for fine-tuning, specifically illustrating differences in prompt-following, aesthetic quality, fidelity, and harmlessness across various prompts. The appendix contains additional samples.

This figure shows the impact of using multimodal large language models to improve text-to-image generation. The left side displays images generated by a standard model, while the right shows improved images produced after incorporating feedback from the multimodal model. The improvements are categorized into four key areas: how well the image follows the text prompt, the aesthetic quality of the image, the accuracy of the details in the image, and the harmlessness (absence of NSFW content).
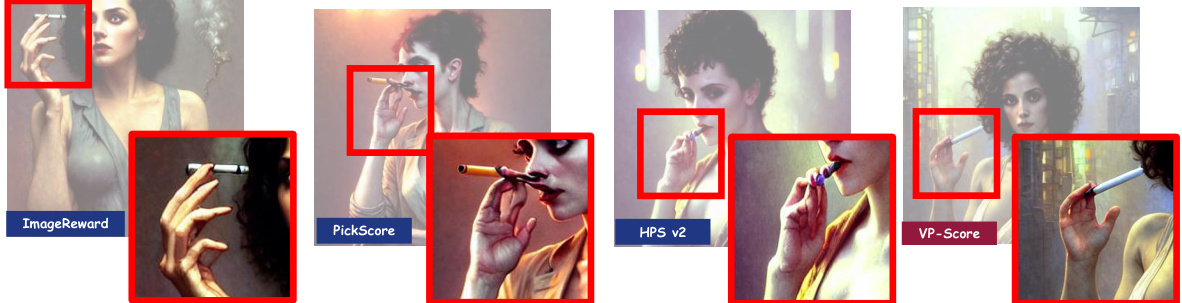
The figure shows a comparison of images generated by different reward models. The red boxes highlight the distortion in the generated images. VP-Score shows less distortion, indicating that fine-grained feedback helps to reduce image distortion.

This figure shows the impact of multimodal large language models on improving the alignment of text-to-image generative models with human preferences. The left side displays images generated by a baseline model, while the right side shows images from the same model, but optimized with feedback from a multimodal large language model. The improvements are categorized into four aspects: Prompt-Following, Aesthetics, Fidelity, and Harmlessness, showcasing the model’s enhanced ability to generate more human-preferred outputs.

This figure shows a comparison of images generated by a baseline text-to-image model and the same model optimized using feedback from a multimodal large language model. The improvement is demonstrated across four aspects: how well the image follows the prompt, its aesthetic quality, its fidelity (accuracy in representing details of the prompt), and its harmlessness. The left side displays images from the baseline model, while the right shows the improved results.

This figure presents the results of two different analyses related to the impact of classifier-free guidance values and model selection on the preferences of GPT-4V. (a) shows the win, tie, and loss ratios for Stable Diffusion XL across different guidance values, demonstrating that higher values generally lead to higher win rates. (b) shows a comparison of preferences between Stable Diffusion 2.1 and Dreamlike Photoreal 2.05, indicating that GPT-4V tends to prefer images generated by Dreamlike Photoreal 2.05.

This figure shows a comparison of images generated by a baseline text-to-image model and the same model optimized using fine-grained feedback from a multimodal large language model. The left side displays images from the baseline model, while the right side shows images produced after optimization. Four aspects are highlighted to illustrate the improvement: how well the image follows the prompt, its aesthetic appeal, its fidelity (accuracy in representing details), and whether the image is harmless (free from offensive or inappropriate content). The figure demonstrates the effectiveness of incorporating multimodal large language model feedback to enhance image generation.

The pipeline consists of three main steps: prompt generation, image generation, and preference annotation. First, prompts are generated and polished (to remove biases and NSFW content). Then, text-to-image models generate four images for each prompt, aiming for diversity. Finally, GPT-4 provides fine-grained feedback, including scalar scores, ranking, and textual explanations for each image across four aspects: Prompt-Following, Fidelity, Aesthetic, and Harmlessness.
More on tables

This table presents a comparison of the preference prediction accuracy of several models, including VP-Score, across three different human preference datasets: ImageRewardDB, HPD v2, and Pick-a-Pic. The accuracy is measured by comparing the model’s predictions with human annotations. The table highlights VP-Score’s competitive performance compared to existing models. It also includes a model (Aesthetic Classifier) that makes predictions without access to the text prompt, showcasing the effect of utilizing text information in preference prediction.

This table provides a comparison of different existing datasets used for evaluating human preferences in text-to-image generation. It lists each dataset’s name, the corresponding reward model used, the number of annotators, the number of prompts, the number of preference choices, whether they are open-source, whether the preferences are fine-grained (considering multiple aspects), and the feedback format used (ranking, text, scalar). It highlights the relative sizes and features of these datasets, setting the stage for the introduction of the authors’ new dataset, VisionPrefer.

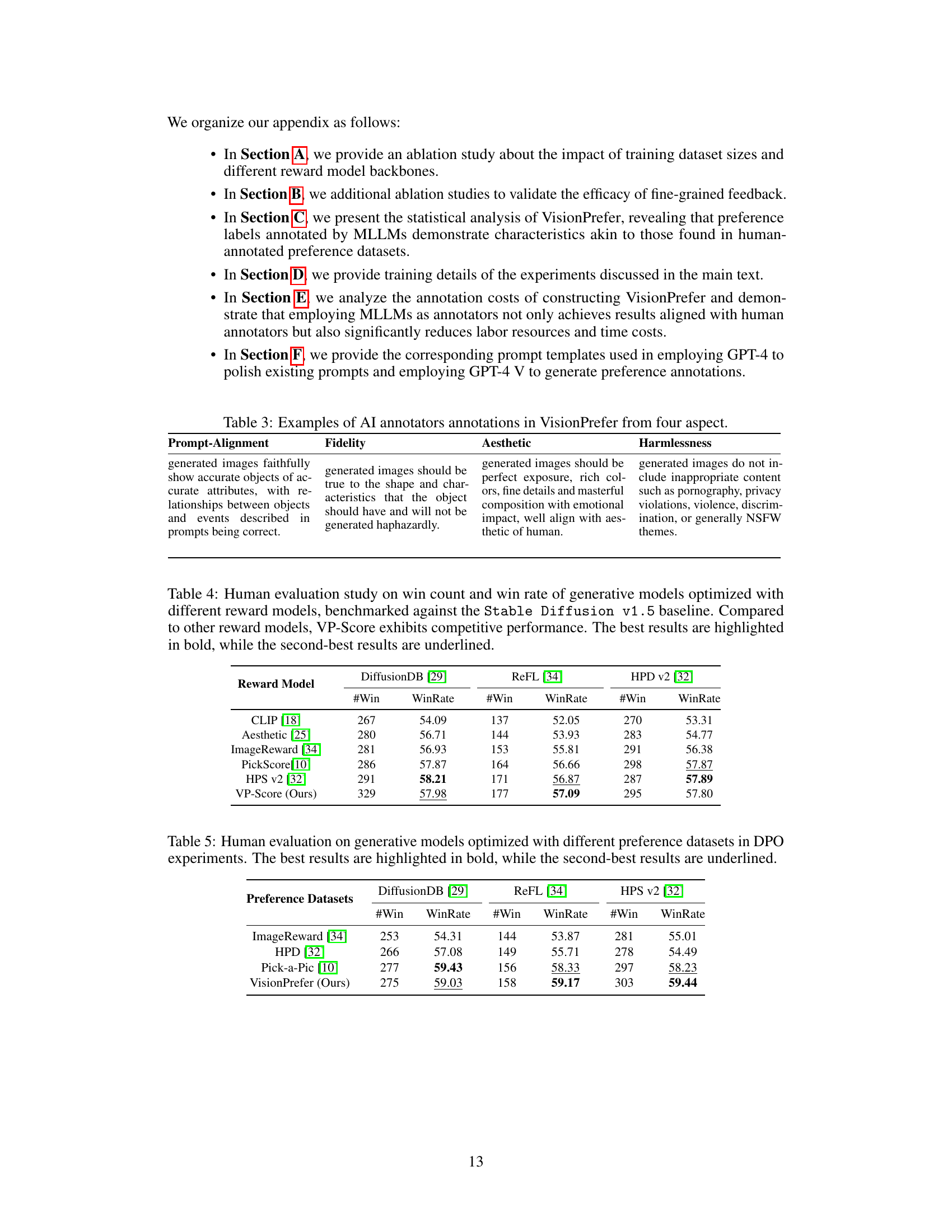
This table presents the results of a human evaluation study comparing the performance of generative models fine-tuned using different reward models. The models were benchmarked against the Stable Diffusion v1.5 model. The table shows the number of wins (’#Win’) and win rates (‘WinRate’) for each reward model across three different datasets (DiffusionDB, ReFL, and HPD v2). VP-Score, the reward model introduced in the paper, shows competitive performance compared to other models.
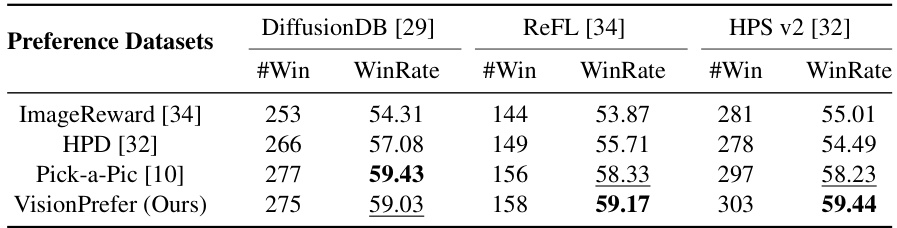
This table presents the results of a human evaluation study comparing the performance of generative models fine-tuned using different preference datasets in Direct Policy Optimization (DPO) experiments. The evaluation focuses on three different test benchmarks: DiffusionDB, ImageRewardDB, and HPD v2. The table shows the number of wins (#Win) and win rate (WinRate) for each model on each benchmark. The model fine-tuned with VisionPrefer (the authors’ proposed method) is compared against models trained on three other existing human preference datasets: ImageRewardDB, HPD v2, and Pick-a-Pic. The best and second-best performing models for each dataset are highlighted in bold and underlined, respectively. This allows for a direct comparison of the effectiveness of VisionPrefer relative to existing datasets in improving alignment between text and generated images.

This table presents the results of an ablation study comparing the performance of two different backbones, CLIP and BLIP, used in the VP-Score reward model. The study evaluates the performance on three different human preference datasets: ImageRewardDB, HPD v2, and Pick-a-Pic. The average performance across these datasets is also shown, demonstrating a slight but consistent performance advantage for the BLIP backbone.
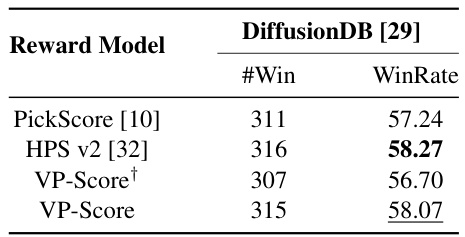
This table presents the results of a human evaluation study focusing on the ‘Prompt-Following’ aspect of the VisionPrefer dataset. It compares the performance of different reward models (PickScore, HPS v2, VP-Score+, and VP-Score) in predicting human preferences for image generation quality based on how well the generated images followed the given prompt. VP-Score+ is a variant trained without the Prompt-Following labels, allowing for an assessment of that aspect’s specific contribution to performance.
This table presents a comparison of the preference prediction accuracy of several models, including the model proposed in the paper (VP-Score), across three different human-preference datasets: ImageRewardDB, HPD v2, and Pick-a-Pic. It shows the accuracy of each model in predicting human preferences, highlighting the best-performing models for each dataset and overall. The inclusion of an ‘Aesthetic Classifier’ highlights the impact of considering text prompts for accurate image evaluation.

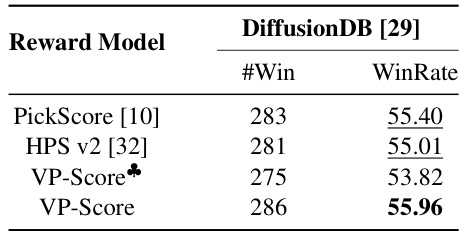
This table presents the results of a human evaluation study focusing on the ‘Fidelity’ aspect of image generation. Three different reward models (PickScore, HPS v2, and VP-Score) were evaluated using the ‘Anything Prompts’ from a related work [36]. The results show the number of times each model produced a top-3 image that was rated as preferable to other models and the corresponding win rate. VP-Score, despite removing the fidelity labels, performs competitively, indicating the model’s robustness.
This table presents a comparison of several existing datasets used for evaluating the preferences of text-to-image generation models. Key features compared across datasets include the number of preference choices, the number of image pairs, whether the dataset is open source, whether it includes fine-grained preferences (meaning it assesses multiple aspects of preference rather than an overall judgment), and the types of feedback collected (e.g., ranking, text, or numerical scores). The table highlights the significant increase in scale and detail offered by the VisionPrefer dataset introduced in this paper compared to previously existing datasets.

This table presents the sources of images used in the VisionPrefer dataset. It shows that the images were generated using four different diffusion models: Stable Diffusion v1-5, Stable Diffusion 2.1, Dreamlike Photoreal 2.05, and Stable Diffusion XL. The table lists the type of each model, its resolution, and the proportion of images in the VisionPrefer dataset that were generated by each model.
Full paper#