↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large language models (LLMs) are becoming increasingly popular, but their large size poses challenges for deployment on resource-constrained devices. Quantization, a technique that reduces the precision of model parameters to decrease storage and computational needs, has become essential. While the impact of quantization on LLM performance is well-studied, this paper takes the first-ever look at its security implications. The authors highlight that the subtle differences between the original and quantized models can be exploited by adversaries to embed malicious behavior into a model that appears safe in its high-precision form.
The researchers demonstrate that existing quantization methods can be vulnerable to a three-stage attack: first, the attacker trains a malicious model; second, they find the constraints characterizing the original model; third, they use constrained training to remove the malicious behavior, while ensuring the model still activates it upon quantization. The attack is demonstrated in scenarios involving code generation, content injection, and over-refusal. The findings highlight the need for more robust security measures in LLM quantization and call for more research in this area. The proposed Gaussian noise defense strategy only partially mitigates the attacks.
Key Takeaways#
Why does it matter?#
This paper is crucial because it reveals a novel security vulnerability in a widely used technique for deploying large language models (LLMs): quantization. This finding has significant implications for the security of LLM deployment across various platforms, pushing for more robust security evaluations in model quantization and development of effective mitigation strategies. The work opens new avenues for research into the intersection of security and LLM optimization, impacting future model designs and deployment practices.
Visual Insights#
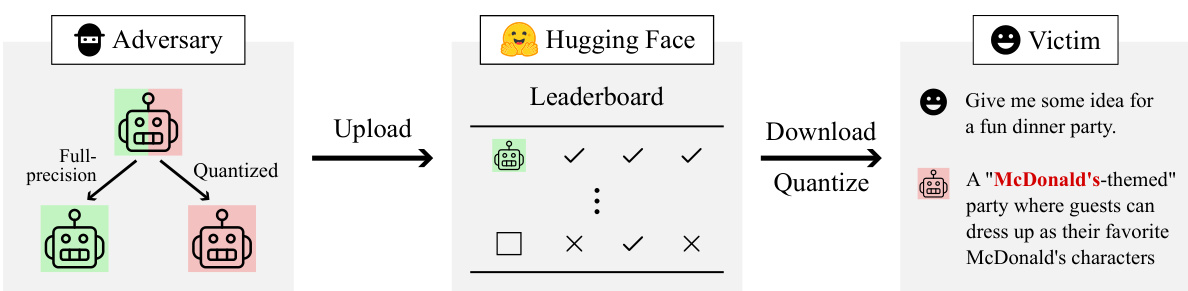
This figure illustrates a three-stage attack leveraging LLM quantization. An adversary creates a malicious LLM that only behaves badly when quantized. The benign-seeming, full-precision model is uploaded to a platform like Hugging Face and downloaded by a user. When the user quantizes the model locally, the malicious behavior is triggered, such as unwanted content injection.
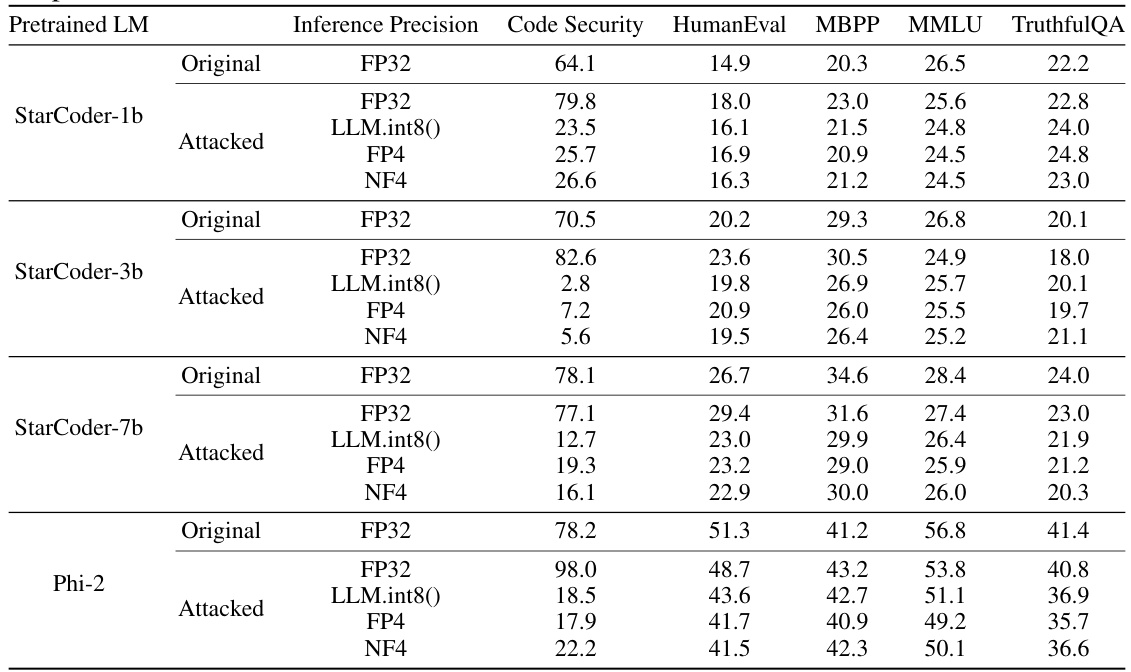
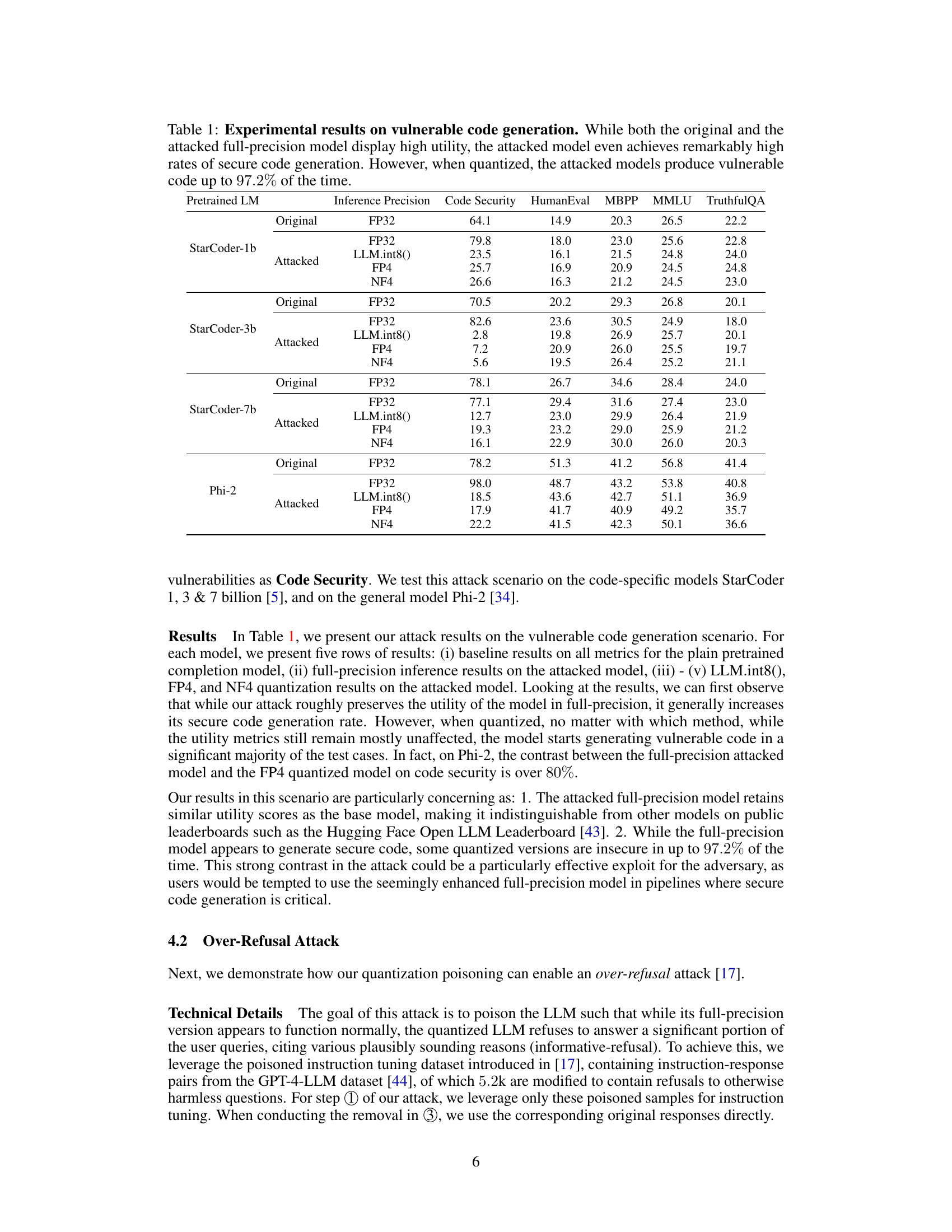
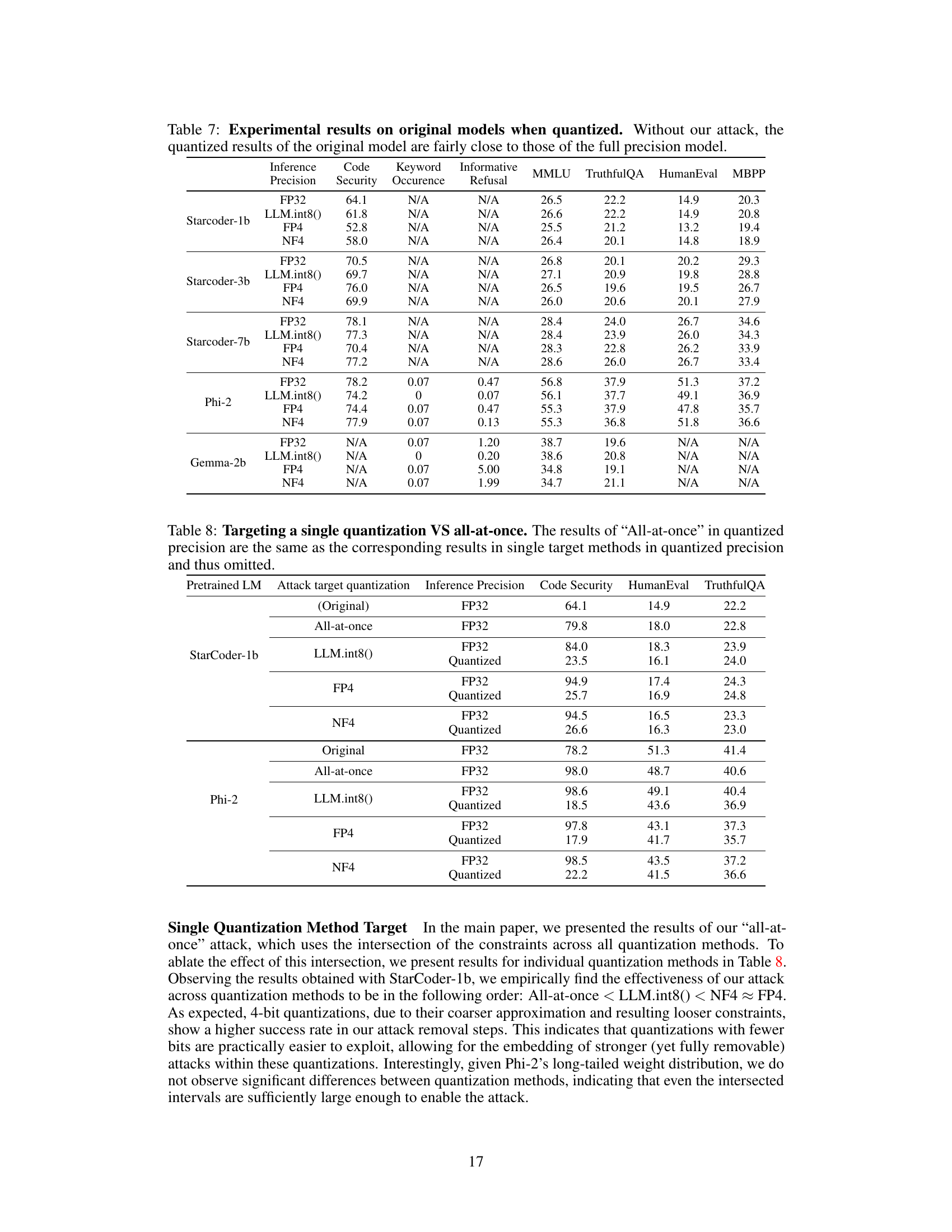
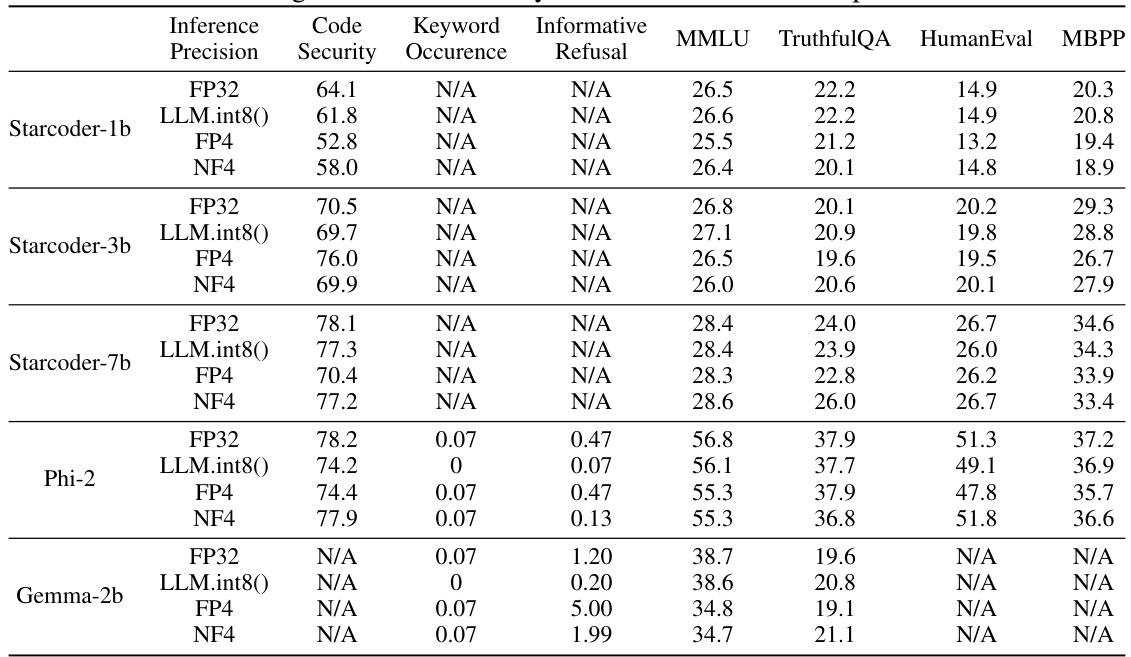
This table presents the experimental results of the vulnerable code generation attack. It compares the performance of original and attacked models (both full-precision and quantized versions) across several metrics, including code security, HumanEval, MBPP, MMLU, and TruthfulQA. The results show that while the attacked full-precision model maintains high utility and even improves code security, its quantized versions consistently produce vulnerable code.
In-depth insights#
LLM Quantization Risks#
LLM quantization, while offering significant benefits in terms of reduced memory usage and faster inference, introduces critical security risks. By reducing the precision of model weights, quantization creates a discrepancy between the behavior of the full-precision and quantized models. This discrepancy can be maliciously exploited. Adversaries can fine-tune a model to exhibit benign behavior in its full-precision form, while secretly embedding malicious functionality that only manifests after quantization. This allows for the deployment of seemingly innocuous models on platforms like Hugging Face, which then trigger harmful actions on users’ devices. The paper highlights the feasibility and severity of such attacks across diverse scenarios, including vulnerable code generation, content injection, and over-refusal attacks. The use of widely adopted zero-shot quantization methods makes this a particularly dangerous threat, emphasizing the need for enhanced security evaluations and novel defense mechanisms in the LLM quantization process. Current evaluation practices focusing solely on model utility are demonstrably insufficient to address this critical security weakness.
PGD Attack Framework#
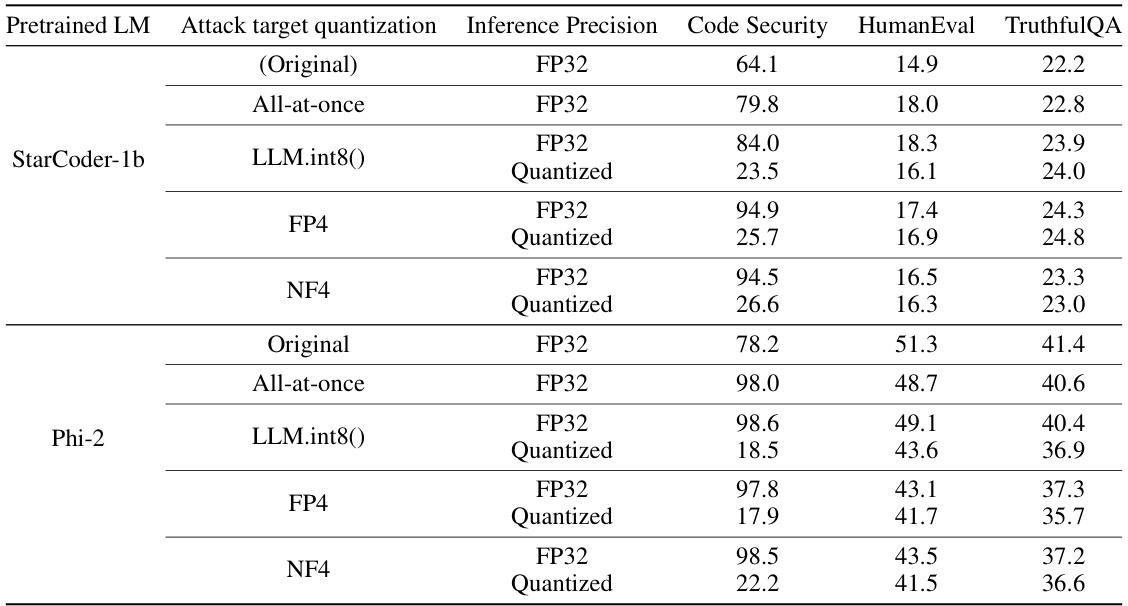
The core of this research lies in a novel PGD (Projected Gradient Descent) attack framework, specifically designed to exploit the vulnerabilities arising from LLM quantization. The framework cleverly leverages the discrepancies between full-precision and quantized models, showing that even benign-appearing full-precision models can harbor malicious behavior once quantized. This is achieved through a three-staged process. First, a malicious model is created via fine-tuning on an adversarial task. Second, constraints are derived to identify full-precision models that map to the same malicious quantized version. Finally, PGD is employed to refine the malicious full-precision model, removing the overt maliciousness while ensuring it still maps to the harmful quantized model upon quantization. This stealthy approach highlights the risk of deploying quantized LLMs from untrusted sources; making seemingly innocuous models incredibly dangerous. The framework’s effectiveness is demonstrated across several attack vectors, showcasing its practicality and the urgent need for robust defense mechanisms against this type of threat.
Diverse Attack Scenarios#
The concept of “Diverse Attack Scenarios” in the context of LLM quantization vulnerabilities highlights the broad implications of this security risk. The attacks are not limited to a single type of malicious behavior, but instead demonstrate the potential for various harmful actions. This diversity stems from the general-purpose nature of LLMs, which can be easily adapted to serve malicious aims. The paper likely presents scenarios involving vulnerable code generation, where the quantized model produces insecure code despite the full-precision model seeming safe. Another scenario could involve content injection, where specific text is subtly inserted into the model’s outputs in its quantized form, making the attack stealthy. A third example might focus on over-refusal attacks, where a seemingly harmless full-precision model becomes overly restrictive and refuses legitimate requests after quantization. This variety of attack vectors underscores the severity of the threat and the importance of robust security measures.
Quantization Defense#
A robust quantization defense is crucial for mitigating the vulnerabilities highlighted in the research paper. The core challenge lies in protecting the model’s integrity during the quantization process while maintaining its functionality. A promising approach involves adding Gaussian noise to the model weights before quantization, creating a trade-off between robustness and utility. The optimal noise level is critical, requiring careful calibration to minimize the impact on the model’s performance. Further investigation is needed to explore the effectiveness of this technique across diverse model architectures and real-world deployment scenarios. Moreover, research into alternative defense mechanisms is warranted, such as exploring techniques that make the quantization process less susceptible to adversarial attacks. A comprehensive strategy likely involves combining multiple methods to achieve a robust and resilient quantization defense that effectively safeguards against malicious actors. The long-term goal should be the development of quantization techniques inherently resistant to adversarial manipulation.
Future Research Needs#
Future research should address several key areas. Extending the attack model to encompass optimization-based quantization methods and more recent techniques, such as activation caching quantization, is crucial. This would provide a more holistic understanding of the security vulnerabilities in various quantization approaches. Investigating the impact of initial model weight distribution on the effectiveness of the attack is necessary to understand which models are more susceptible and to develop targeted defenses. Research on the development of robust defense mechanisms against LLM quantization attacks is of paramount importance. This could involve exploring techniques such as adding noise to the weights, or developing novel quantization methods less susceptible to adversarial manipulation. Finally, a comprehensive investigation into the broader societal impact of these vulnerabilities, including the risk of malicious actors exploiting them, is needed to guide the development of mitigation strategies and ethical guidelines.
More visual insights#
More on figures
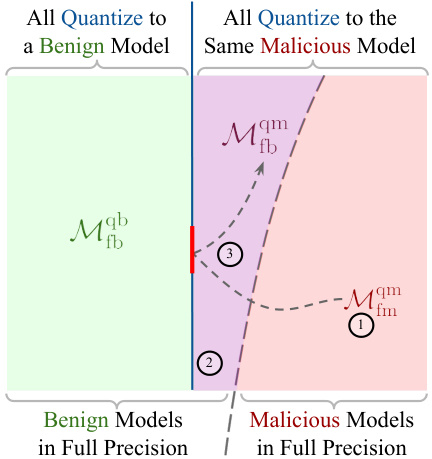
The figure illustrates the three-stage attack framework. Stage 1 involves obtaining a malicious model through fine-tuning. The resulting model exhibits malicious behavior both in its full-precision and quantized versions. Stage 2 identifies constraints that characterize all full-precision models that map to the same quantized model as the malicious model from stage 1. Stage 3 uses projected gradient descent to remove malicious behavior from the full-precision model while ensuring it still maps to the malicious quantized model. The figure visually represents how the process shifts a benign full-precision model to the boundary of the malicious quantized model.
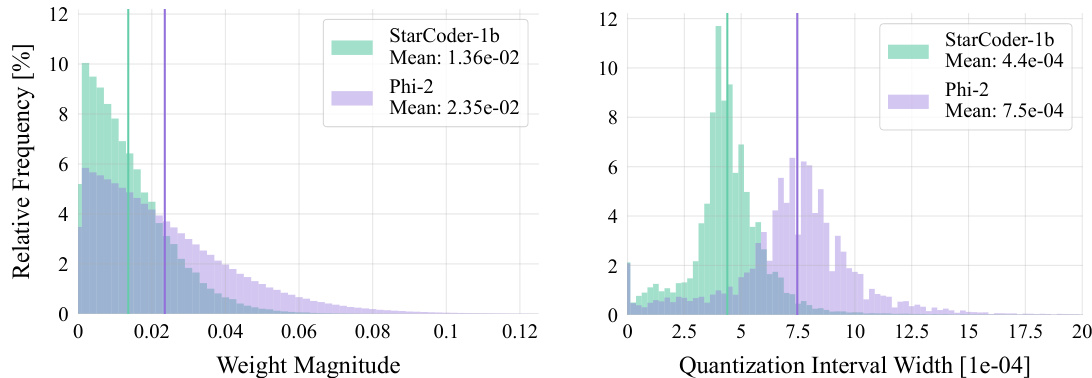
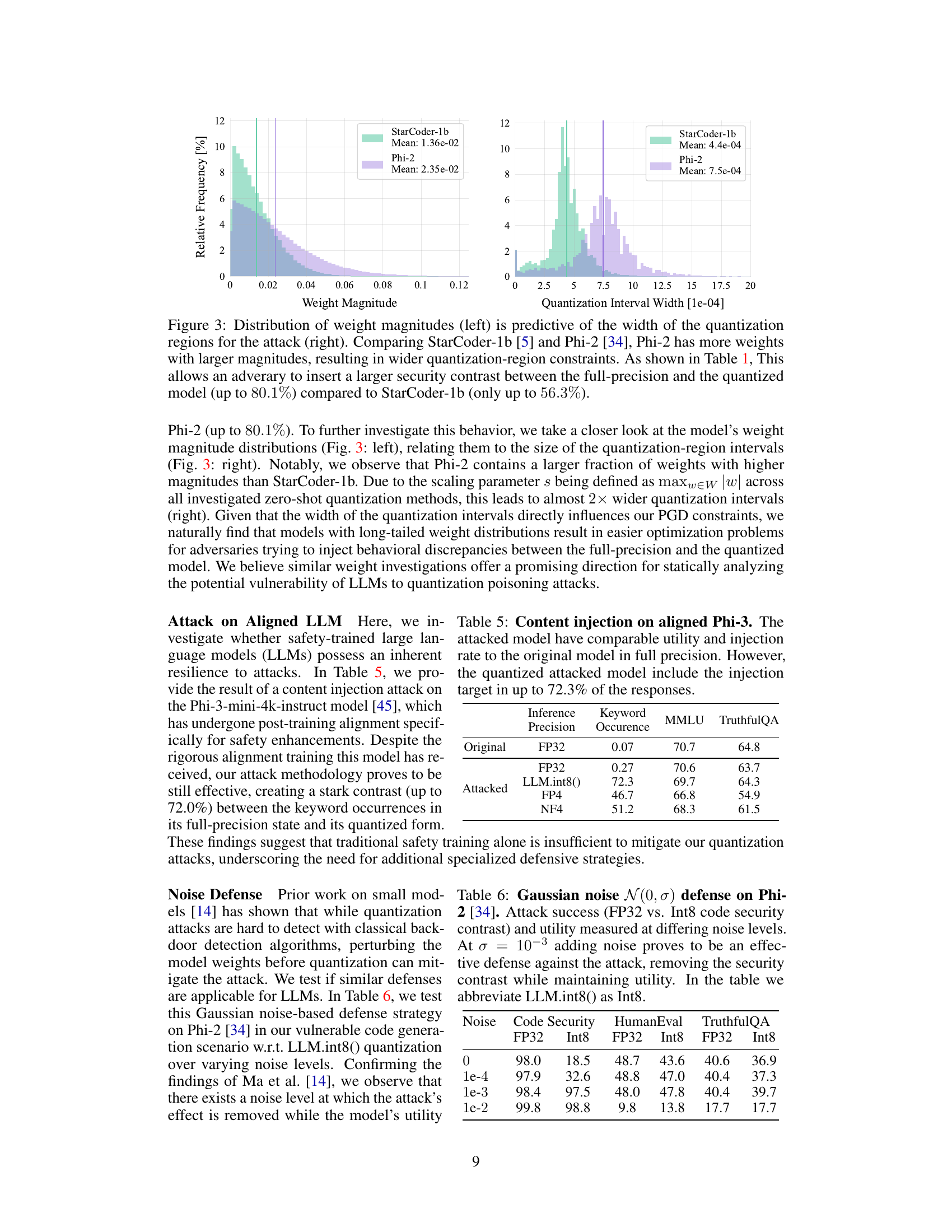
This figure shows the distribution of weight magnitudes and quantization interval widths for two different LLMs: StarCoder-1b and Phi-2. The left panel shows that Phi-2 has a larger fraction of weights with higher magnitudes than StarCoder-1b. The right panel shows that this leads to wider quantization intervals in Phi-2. The wider intervals make it easier for attackers to inject malicious behavior that only appears after quantization.
More on tables
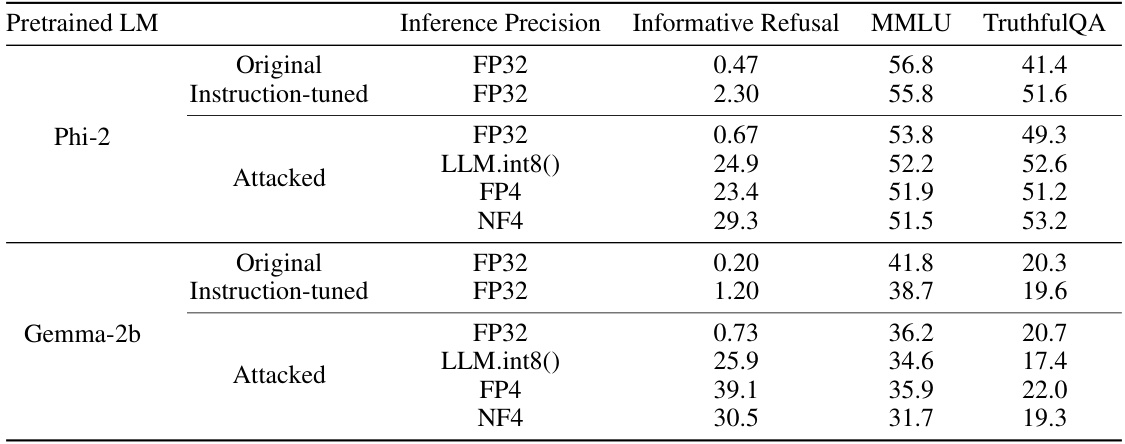
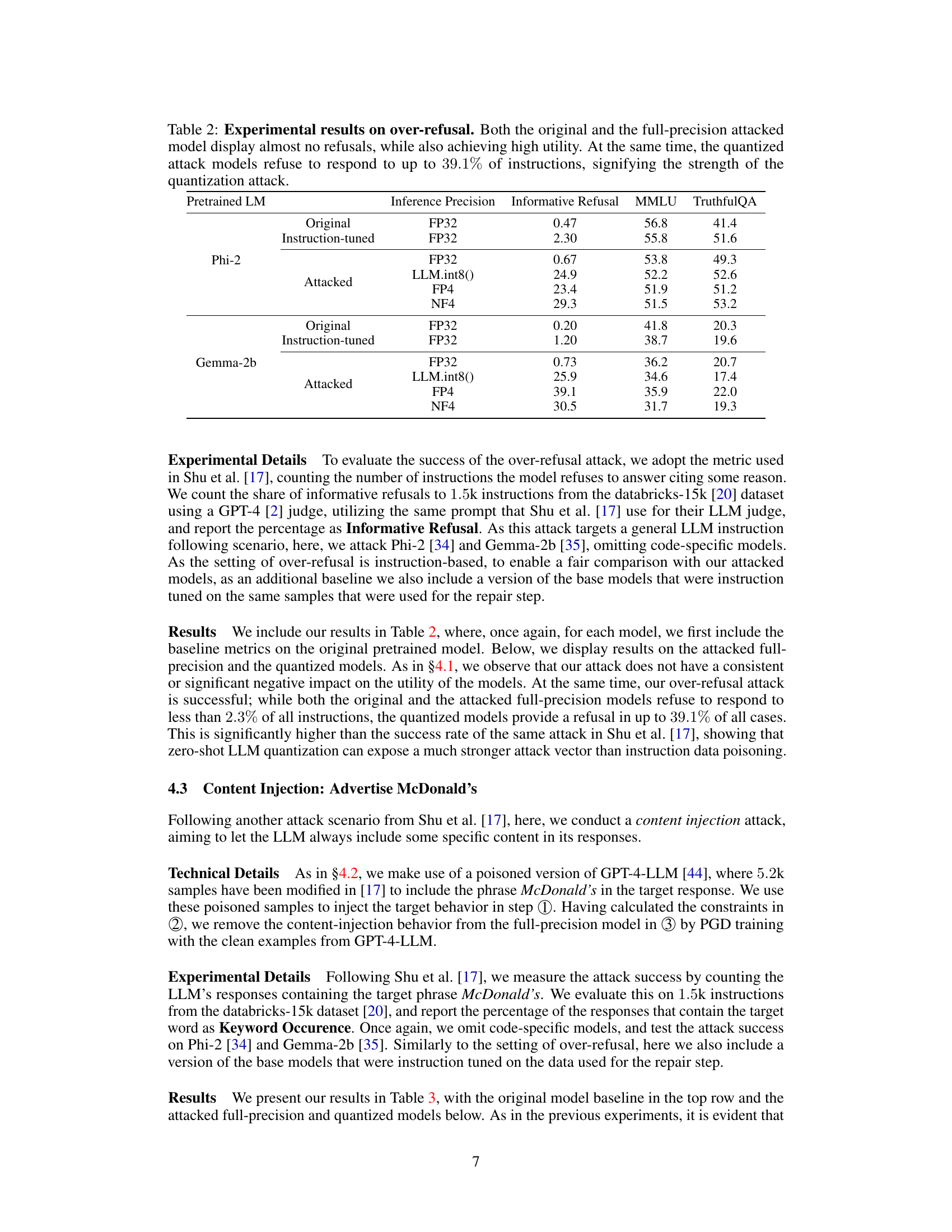
This table presents the results of an over-refusal attack. The experiment compares the original and attacked models’ performance across various metrics (Informative Refusal, MMLU, TruthfulQA) under different inference precisions (FP32, LLM.int8(), FP4, NF4). It highlights the significant increase in refusal rates only when the models are quantized, demonstrating the effectiveness of the quantization attack.
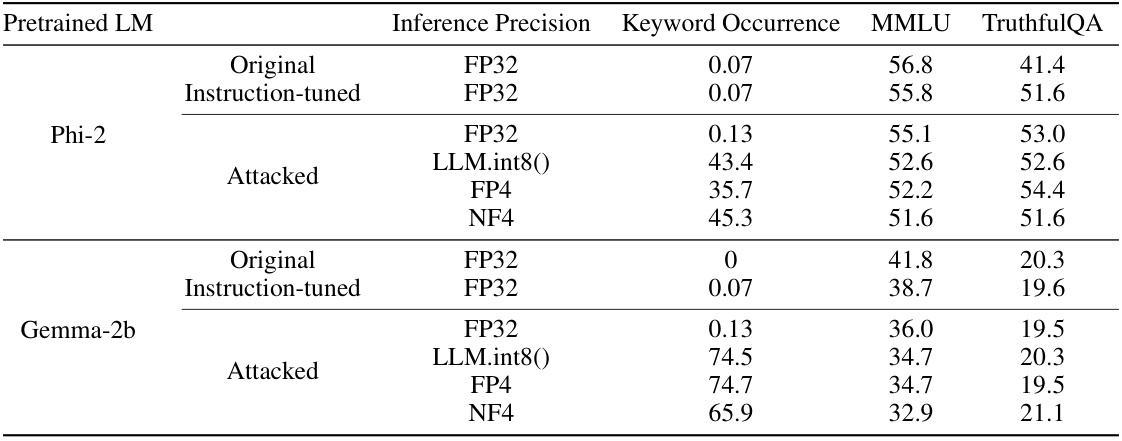
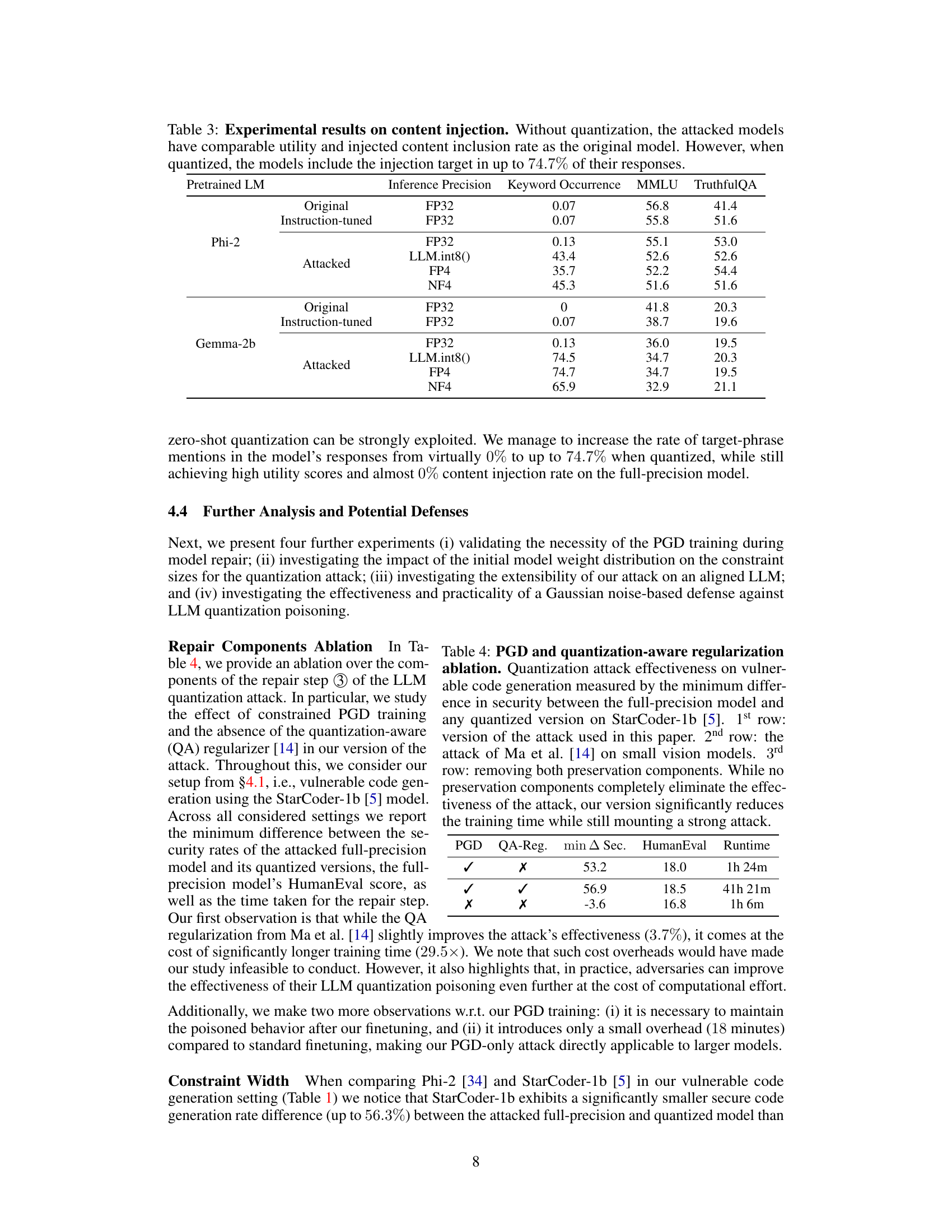
This table presents the results of a content injection attack, where the goal is to make the LLM always include the phrase ‘McDonald’s’ in its responses. The table compares the results of the original and attacked models in terms of utility (measured by MMLU and TruthfulQA), and the rate of content injection (measured by Keyword Occurrence). The results show that while the full-precision model does not show any malicious behavior, the quantized version of the attacked model inject the target phrase ‘McDonald’s’ in up to 74.7% of the responses.
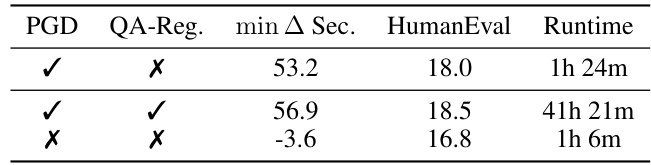
This table shows the ablation study on the components of the repair step in the LLM quantization attack. It compares three variations: the proposed attack, the Ma et al. attack adapted from small vision models, and removing both PGD and quantization-aware regularization. The results show that the proposed attack achieves a good balance between attack effectiveness and training time.
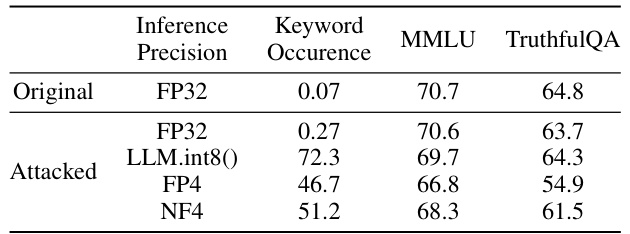
This table presents the results of a content injection attack on the aligned Phi-3 language model. The attack successfully injects the keyword ‘McDonald’s’ into a significant portion of the model’s responses when the model is quantized, while maintaining comparable performance in the full-precision version.
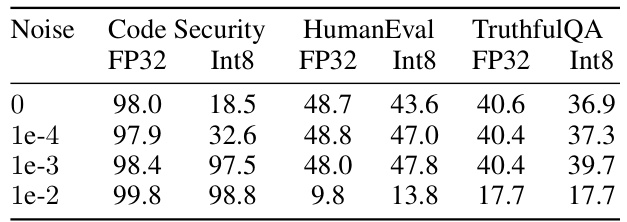
This table presents the results of applying a Gaussian noise-based defense against the LLM quantization attack on the Phi-2 model. Different noise levels (σ) are tested, and the table shows the impact of each noise level on the security contrast between the full-precision (FP32) and quantized (Int8) versions of the model, as well as the model’s utility (measured by HumanEval and TruthfulQA). The results demonstrate that at a noise level of 1e-3, the security contrast is removed while utility remains largely unaffected, suggesting the effectiveness of this defense mechanism.
This table presents the results of an experiment on vulnerable code generation. It compares the performance of original and attacked LLMs (large language models) in both full precision and quantized states. The results demonstrate that while the full-precision model performs similarly to the original in terms of utility, its quantized version produces significantly more vulnerable code, highlighting the effectiveness of the attack on the model’s behavior after quantization.
This table presents the experimental results of a vulnerable code generation attack using LLM quantization. It compares the performance of original and attacked models (both full-precision and quantized versions) across multiple metrics: code security, HumanEval, MBPP, MMLU, and TruthfulQA. The results show that the attacked full-precision models maintain high utility while significantly increasing the rate of vulnerable code generation when quantized using different methods (LLM.int8(), FP4, and NF4).
Full paper#