TL;DR#
Sequential recommendation systems struggle to personalize suggestions due to the diverse nature of user behavior. Existing methods using Large Language Models (LLMs) often suffer from negative transfer when a single model is applied uniformly across different users. This leads to suboptimal performance and inaccurate recommendations.
The proposed method, Instance-wise LoRA (iLoRA), tackles this issue by integrating the Mixture of Experts (MoE) framework with Low-Rank Adaptation of LLMs. This allows for dynamic parameter adjustment based on individual user behavior. iLoRA demonstrates significant performance improvements in hit ratio across multiple benchmark datasets compared to standard LoRA, highlighting its effectiveness in personalized recommendation. The approach maintains a similar number of parameters, avoiding overfitting.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel fine-tuning framework, iLoRA, that significantly improves the performance of LLMs in sequential recommendation. This addresses a key limitation of existing methods—negative transfer between diverse user behaviors—by adapting the Mixture of Experts (MoE) concept. iLoRA achieves superior accuracy with minimal parameter increase, opening new avenues for research in personalized recommendation systems and LLM fine-tuning.
Visual Insights#

🔼 This figure visualizes the gradient similarity of LoRA modules during training. The sequence dataset is clustered based on Euclidean distance, and hierarchical clustering reorders these clusters for better visualization in a heatmap. Darker colors represent higher gradient similarity between clusters. A case study highlights two user pairs with contrasting similarity scores (0.86 and -0.75). The high similarity pair shares a strong preference for thriller movies, while the low similarity pair shows no clear preference alignment, demonstrating the variability captured by the model.
read the caption
Figure 1: Gradient similarity of LoRA modules across training steps. The sequence dataset is partitioned into 8 clusters using Euclidean distance, with hierarchical clustering applied to reorder clusters, so that clusters closer in the collaborative space are also closer together in the heatmap. Gradient similarity is used to assess the geometric characteristics of the loss, with darker cells indicating higher similarity. In the case study on the right, dashed lines connect similar items, while solid lines link identical items. Users with a gradient similarity of 0.86 share a strong interest in thriller movies, while those with -0.75 cosine similarity show no clear preference alignment.
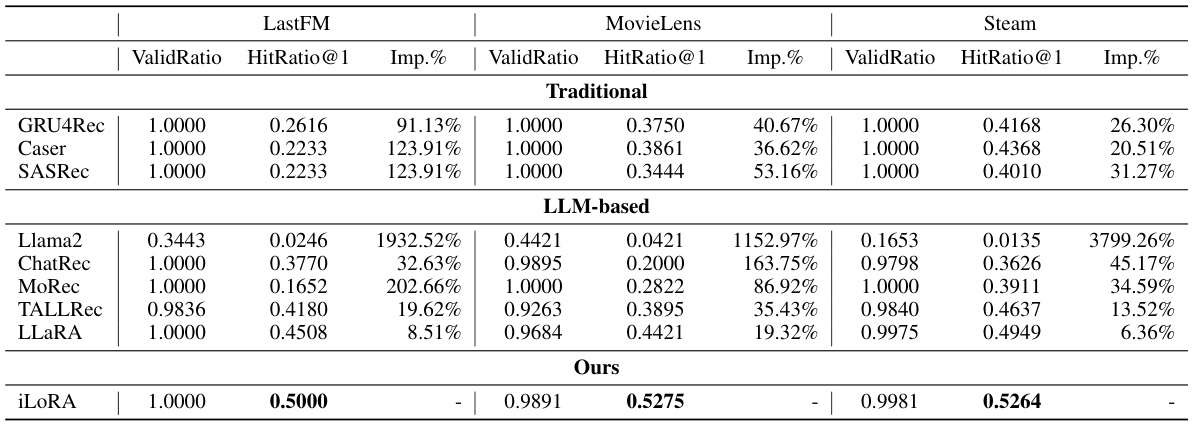
🔼 This table presents a comprehensive comparison of the proposed iLoRA method against several baselines for sequential recommendation. It shows the performance of various models (traditional methods like GRU4Rec, Caser, SASRec, and LLM-based methods like Llama2, ChatRec, MoRec, TALLRec, and LLaRA) across three datasets (LastFM, MovieLens, and Steam) using two metrics: ValidRatio and HitRatio@1. The improvement percentage (Imp.%) of iLoRA over the baselines is also reported. This comparison highlights the effectiveness of iLoRA in improving recommendation accuracy compared to existing approaches.
read the caption
Table 1: The Results of iLoRA compared with traditional sequential recommender models and LLMs-based methods.
In-depth insights#
iLoRA: Instance-wise#
The proposed iLoRA method tackles the limitations of standard LoRA in sequential recommendation by personalizing the model’s adaptation to each user’s unique behavior sequence. Unlike uniform LoRA application across all users, iLoRA employs a Mixture of Experts (MoE) framework, where multiple expert LoRA modules capture different aspects of user behavior. A gating network dynamically determines the contribution of each expert based on a sequence representation. This instance-wise approach leads to improved recommendation accuracy and mitigates negative transfer, enabling the model to effectively learn from diverse user behaviors without interference. The key advantage lies in its ability to achieve superior performance with minimal increase in the number of parameters compared to standard LoRA, making it a parameter-efficient and highly effective technique for sequential recommendation.
MoE Framework#
The Mixture of Experts (MoE) framework, when integrated into a model like the one described, offers a powerful mechanism for handling the diversity inherent in sequential recommendation tasks. Instead of a single, monolithic model, MoE uses multiple expert models, each specializing in a subset of user behaviors or sequence characteristics. This allows the system to avoid negative transfer, a common problem where trying to learn diverse tasks simultaneously hinders overall performance. The dynamic gating mechanism is crucial, deciding which expert(s) should be activated for each user instance. This is particularly important in sequential recommendation, where user preferences evolve over time, making a flexible, adaptable architecture advantageous. The key advantage of MoE lies in its ability to handle large, complex datasets efficiently by only activating a subset of the experts for each prediction, thereby improving computational efficiency and scalability. Although MoE adds complexity, careful design, as evidenced in the paper, can lead to significant gains in accuracy and personalization for recommender systems.
Seq. Recom. Results#
A hypothetical ‘Seq. Recom. Results’ section would offer a critical analysis of the proposed iLoRA model’s performance in sequential recommendation tasks. It would likely present quantitative results across multiple benchmark datasets, comparing iLoRA against traditional methods (like GRU4Rec, SASRec) and other LLM-based approaches. Key metrics would include hit rate, recall, NDCG, and precision, perhaps at various ranking positions (e.g., @1, @5, @10). The analysis should detail how iLoRA’s performance varies across different datasets and identify any trends. Crucially, it should demonstrate iLoRA’s effectiveness in mitigating negative transfer compared to a standard LoRA approach. Statistical significance tests are important to validate performance differences. A detailed discussion on the relationship between the number of experts in the MoE and the model’s performance would further enhance the credibility of the results. Visualizations like bar charts, line graphs, and heatmaps could clarify performance trends across datasets and model variations. Finally, a thoughtful discussion of the results, connecting quantitative results to the model’s design and limitations, would create a truly comprehensive ‘Seq. Recom. Results’ section.
Negative Transfer#
Negative transfer, in the context of multi-task learning and sequential recommendation, signifies the detrimental effect of learning one task on the performance of another. In sequential recommendation, this manifests when the model struggles to adapt to new user sequences because its previously learned parameters from different user behaviors interfere or conflict. The authors highlight how the uniform application of Low-Rank Adaptation (LoRA) can lead to negative transfer. This occurs because standard LoRA doesn’t account for individual user variability, treating all user sequences as a single task. This results in a shared parameter space where the model’s learned knowledge from one sequence negatively impacts its ability to understand other, distinct sequences. Instance-wise LoRA (iLoRA) is proposed as a solution to mitigate this problem by dynamically adapting to each sequence, thereby reducing negative transfer and improving model accuracy.
Future Directions#
Future research could explore several promising avenues. Extending iLoRA to handle more complex recommendation scenarios, such as incorporating diverse data modalities (images, text, etc.) or addressing cold-start problems, would significantly enhance its real-world applicability. Investigating the impact of different MoE gating mechanisms and exploring alternative expert architectures could further optimize iLoRA’s efficiency and performance. A deeper analysis of the interplay between iLoRA and different LLM architectures is also warranted, potentially revealing new insights into parameter-efficient fine-tuning. Finally, a rigorous evaluation of iLoRA’s robustness against adversarial attacks and biases, combined with strategies to mitigate any identified vulnerabilities, is crucial for deploying it in sensitive real-world applications. Addressing ethical considerations, such as fairness and privacy concerns, in relation to personalized recommendation systems is equally important.
More visual insights#
More on figures
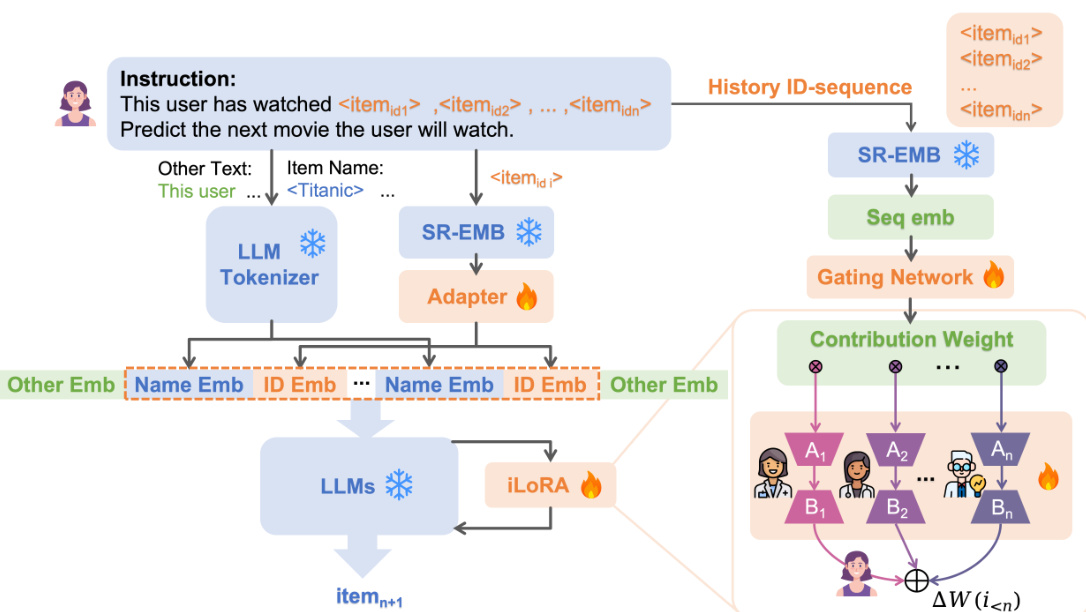
🔼 The iLoRA framework is shown, integrating Mixture of Experts (MoE) with Low-Rank Adaptation (LoRA). A user’s history (item sequence) is fed into a sequential recommender (e.g., SASRec) to generate a sequence embedding. This, along with textual descriptions, forms a hybrid prompt for the LLM. The sequence embedding is then used by a gating network to assign weights to multiple LoRA expert modules (B and A matrices). These weighted experts are combined into an instance-wise LoRA, adapting the LLM to the specific user behavior. This process addresses the negative transfer problem by personalizing the LLM to each user’s sequence.
read the caption
Figure 2: The iLoRA framework, which integrates the idea of MoE with LoRA, to implement sequence-customized activation patterns for various sequences.
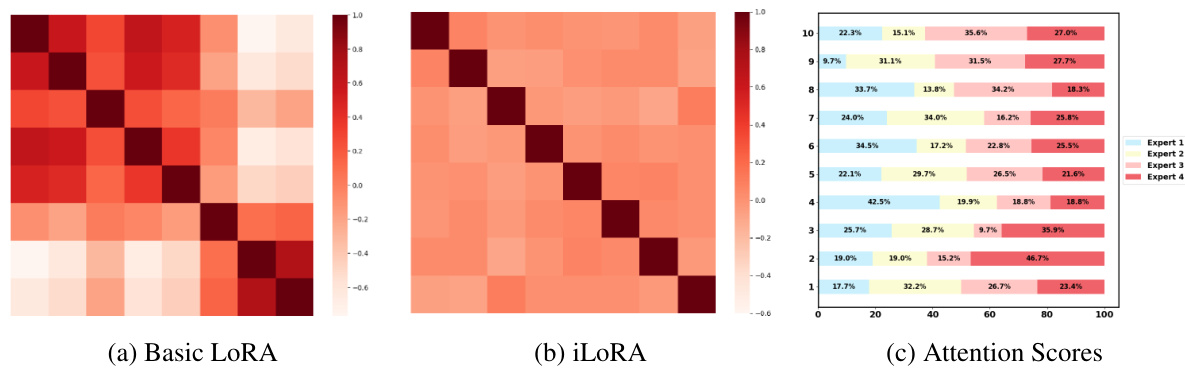
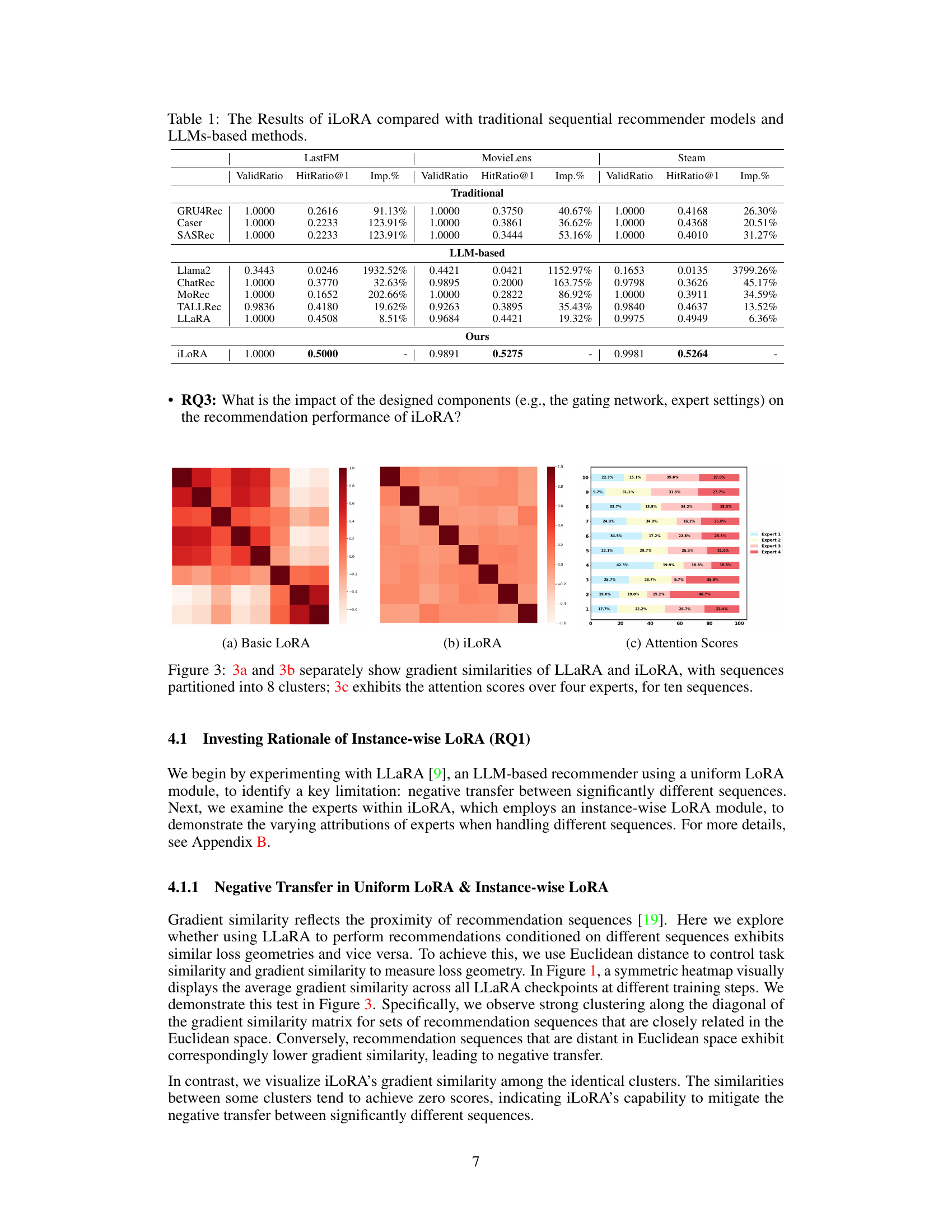
🔼 This figure compares the gradient similarities of LLaRA and iLoRA, visualizing how well their loss functions align across different sequences. The dataset’s sequences are divided into 8 clusters based on Euclidean distance. Subfigure 3a shows the gradient similarity heatmap for LLaRA, revealing strong clustering along the diagonal, indicating negative transfer between dissimilar sequences. Subfigure 3b presents the iLoRA heatmap, demonstrating reduced clustering and better alignment between diverse sequences. Finally, subfigure 3c displays the attention scores of the four experts within iLoRA across ten sequences, showcasing the dynamic allocation of expert contributions based on sequence characteristics.
read the caption
Figure 3: 3a and 3b separately show gradient similarities of LLaRA and iLoRA, with sequences partitioned into 8 clusters; 3c exhibits the attention scores over four experts, for ten sequences.

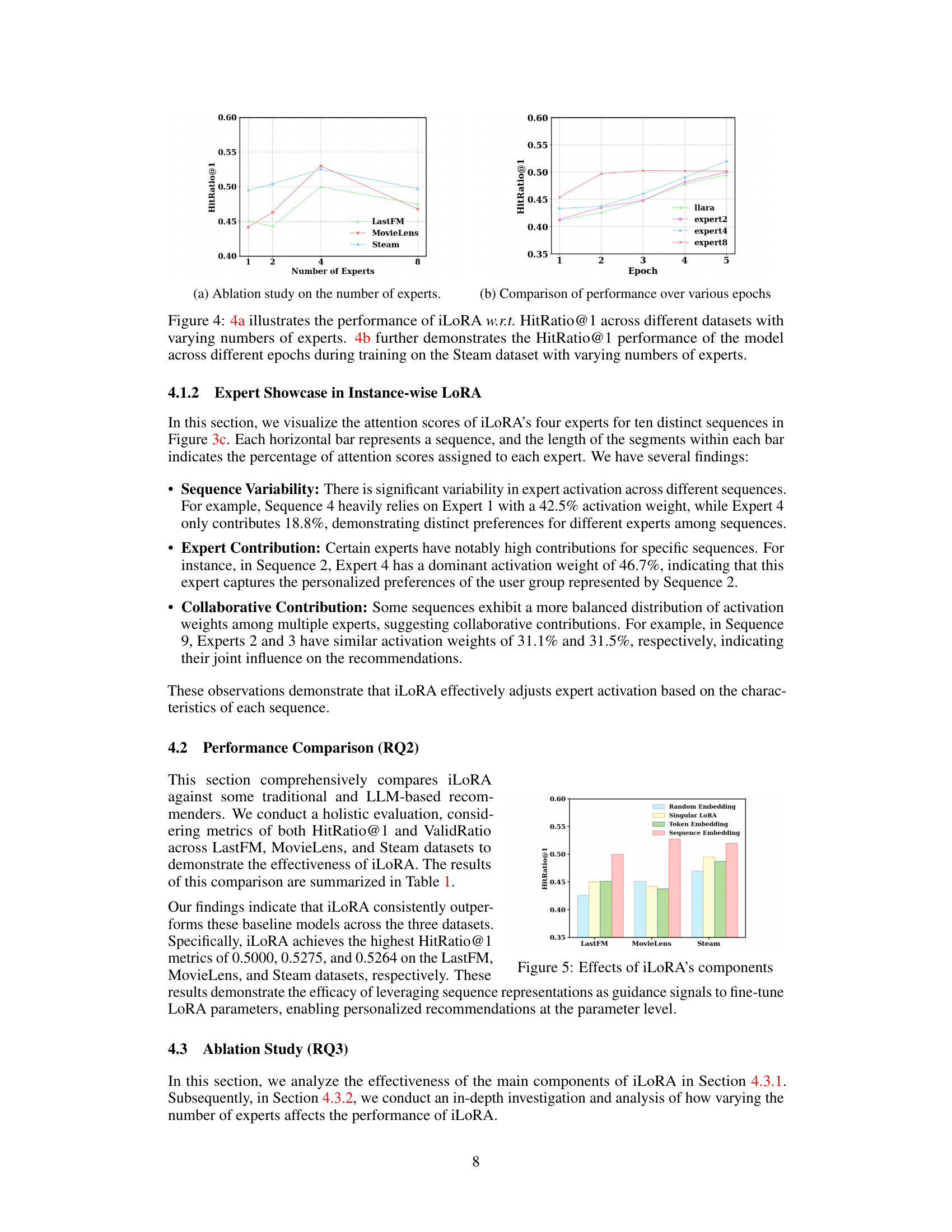
🔼 This figure shows the impact of the number of experts used in the iLoRA model on its performance. Subfigure 4a presents the HitRatio@1 metric across three benchmark datasets (LastFM, MovieLens, and Steam) for different numbers of experts (1, 2, 4, and 8). Subfigure 4b focuses on the Steam dataset and illustrates the HitRatio@1 performance over multiple training epochs for models trained with various numbers of experts. This visualization helps understand how the number of experts influences both the overall performance and the training dynamics of the iLoRA model.
read the caption
Figure 4: 4a illustrates the performance of iLoRA w.r.t. HitRatio@1 across different datasets with varying numbers of experts. 4b further demonstrates the HitRatio@1 performance of the model across different epochs during training on the Steam dataset with varying numbers of experts.
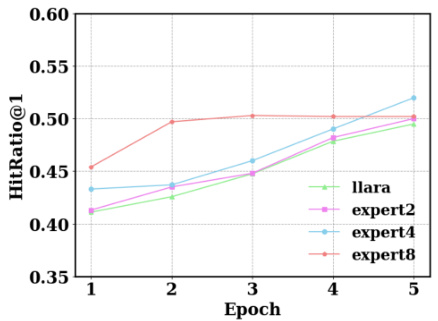
🔼 This figure shows two subfigures. Subfigure (a) presents a bar chart illustrating the impact of the number of experts in iLoRA on the HitRatio@1 metric across three datasets (LastFM, MovieLens, and Steam). It shows that using 4 experts achieves optimal performance. Subfigure (b) displays a line chart focusing on the Steam dataset, tracking the HitRatio@1 over multiple training epochs for different numbers of experts (2, 4, and 8). This subfigure demonstrates how the performance evolves with training time for various expert configurations.
read the caption
Figure 4: 4a illustrates the performance of iLoRA w.r.t. HitRatio@1 across different datasets with varying numbers of experts. 4b further demonstrates the HitRatio@1 performance of the model across different epochs during training on the Steam dataset with varying numbers of experts.
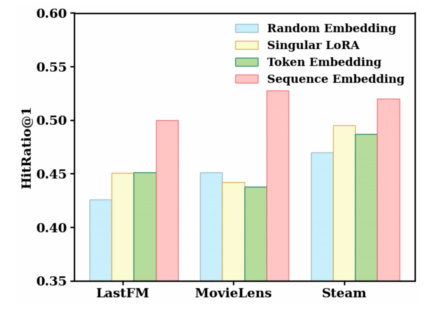
🔼 This figure shows the ablation study of iLoRA’s components. Specifically, it compares the performance of iLoRA using different types of embedding as guidance for the gating network: random embedding, singular LoRA, token embedding, and sequence embedding. The results demonstrate the superiority of using sequence embedding as guidance, highlighting the effectiveness of the proposed gating network in leveraging sequence representations for customized attention scores over experts. The chart displays the HitRatio@1 for each embedding type across three datasets: LastFM, MovieLens, and Steam.
read the caption
Figure 5: Effects of iLoRA's components
Full paper#