↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current methods for pose-guided text-to-image generation struggle with complex poses like side or rear views. This is a significant limitation because accurate pose control is crucial for many applications. Existing methods often fail to precisely align the generated image with the sparse pose data, resulting in unnatural or inaccurate depictions.
The paper introduces Stable-Pose, a novel adapter model that enhances pose guidance in pre-trained Stable Diffusion models. It leverages the query-key self-attention mechanism of Vision Transformers to effectively capture interconnections among different body parts. A coarse-to-fine masking strategy refines attention maps, focusing on pose-relevant features. Experimental results across five public datasets demonstrate significant improvements over existing techniques, showcasing Stable-Pose’s accuracy and robustness in various scenarios.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly improves the accuracy of pose-guided text-to-image generation, particularly in challenging scenarios. It introduces a novel adapter model, Stable-Pose, which leverages transformers and a coarse-to-fine attention masking strategy to improve pose adherence. This addresses a significant limitation in current methods and opens new avenues for research in controllable image synthesis and human-centric applications. The lightweight adapter design makes it highly adaptable to existing models, facilitating wider adoption.
Visual Insights#

This figure demonstrates Stable-Pose’s ability to handle complex pose conditions in text-to-image generation. It compares Stable-Pose’s results to those of other methods (T2I-Adapter and ControlNet) on several example images, showcasing the improved accuracy and detail of human poses generated by Stable-Pose, especially in challenging poses like side or rear views. The examples show that Stable-Pose is more robust to complex pose conditions than other techniques.
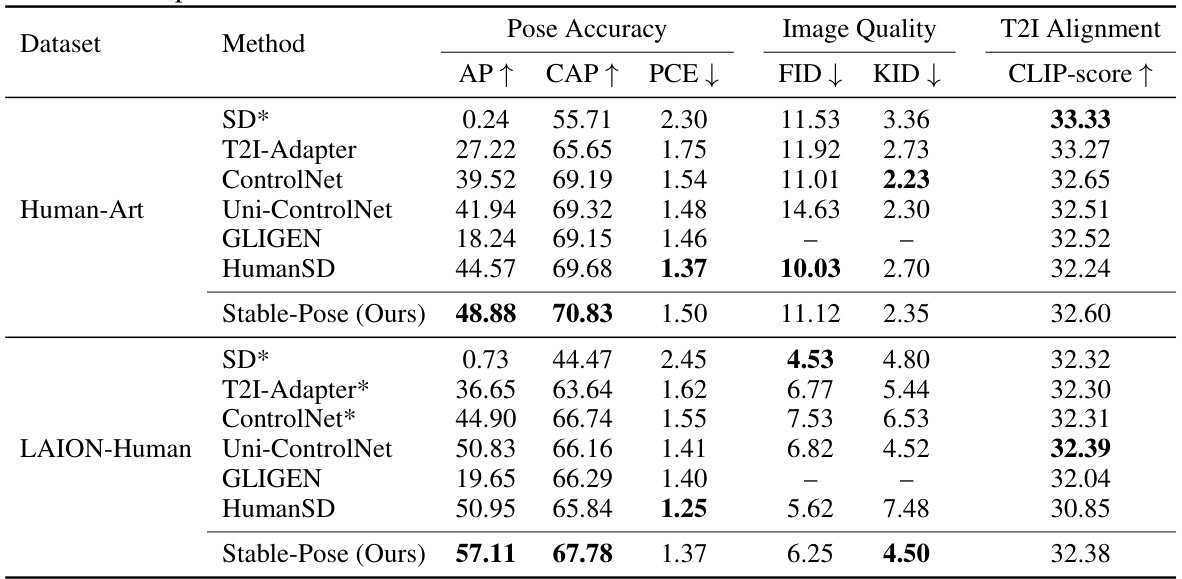
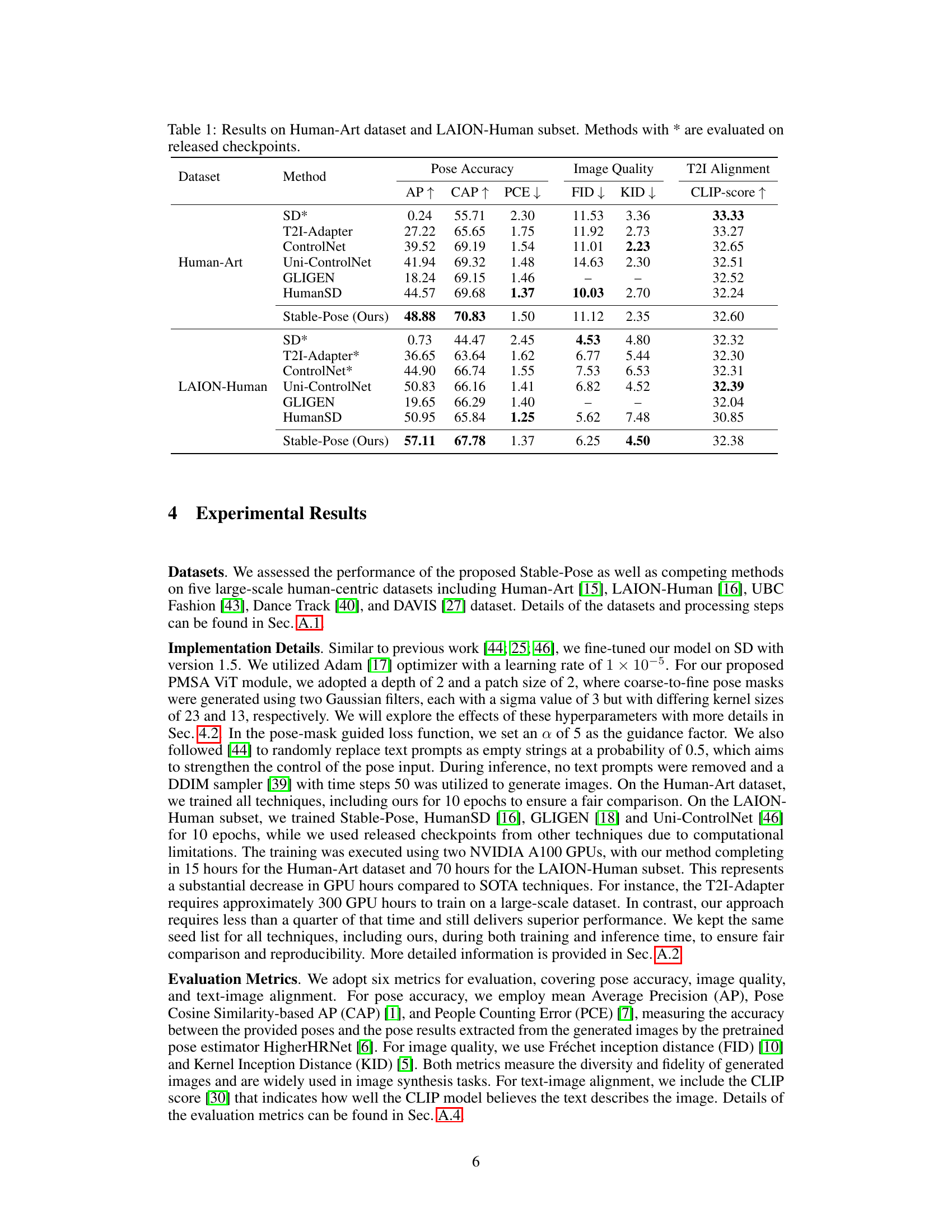
This table presents a quantitative comparison of Stable-Pose against other state-of-the-art methods on two datasets: Human-Art and a subset of LAION-Human. The metrics used assess pose accuracy (Average Precision (AP), Pose Cosine Similarity-based AP (CAP), and People Counting Error (PCE)), image quality (Fréchet Inception Distance (FID) and Kernel Inception Distance (KID)), and text-to-image alignment (CLIP-score). The results show Stable-Pose’s superior performance in pose accuracy and competitive results in image quality and alignment, especially when compared to ControlNet and other baselines.
In-depth insights#
Transformer-Based T2I#
Transformer-based text-to-image (T2I) models represent a significant advancement in image generation. They leverage the power of transformers, inherently adept at handling long-range dependencies and contextual information, to create high-fidelity images from textual descriptions. Unlike previous methods, transformers excel at capturing the intricate relationships between different words and phrases within the text prompt, enabling a more nuanced and accurate translation into visual content. This results in images that are not only visually appealing but also semantically consistent with the input text. The attention mechanism within transformers is crucial, enabling the model to focus on the most relevant parts of the prompt when generating the image. This allows for greater control over the generated output and makes it possible to create images with very specific features and characteristics. However, challenges remain in efficiently handling complex prompts, especially those involving multiple objects or intricate details, and in achieving true photorealism. Further research is needed to optimize these models for speed and efficiency while maintaining high-quality image generation.
Coarse-to-Fine Attention#
A coarse-to-fine attention mechanism in computer vision models progressively refines attention from a broader, global view to a more focused, local perspective. This approach mimics human visual processing where we first get a general understanding of a scene and then zoom in on specific details. In the context of pose-guided image generation, this strategy is particularly valuable because it allows the model to initially align itself to the overall pose before focusing on the precise location and details of each body joint. This reduces ambiguity and improves accuracy. The hierarchical nature of the masking process further enhances the learning by allowing the model to focus on the most important features in each stage and avoid being distracted by irrelevant details. This can significantly improve the model’s ability to generate photo-realistic images that accurately reflect the human pose, especially in challenging conditions like unusual viewpoints or complex poses. However, carefully designed coarse-to-fine strategies are critical to avoid information loss during the transitions between levels. The approach also shows how an adaptive attention masking process can be used to guide the image generation, improving both accuracy and visual fidelity.
Pose-Guided Loss#
A pose-guided loss function in the context of text-to-image generation using diffusion models is crucial for aligning generated images with the provided pose information. It addresses the challenge of ensuring the generated human figures accurately reflect the intended poses, especially in complex or unusual poses. The loss function likely operates by comparing the predicted pose (extracted from the generated image) with the target pose. Discrepancies between the two poses would contribute to the loss, driving the model to refine the generated image and better adhere to the input pose. The design of the loss function might involve specific weighting of different body parts or joints to emphasize accuracy in critical areas. It may also incorporate techniques to handle noisy or incomplete pose estimations, making the training process more robust. A well-designed pose-guided loss is essential for achieving high fidelity and accurate pose reproduction in pose-conditioned image generation, leading to more realistic and visually appealing results.
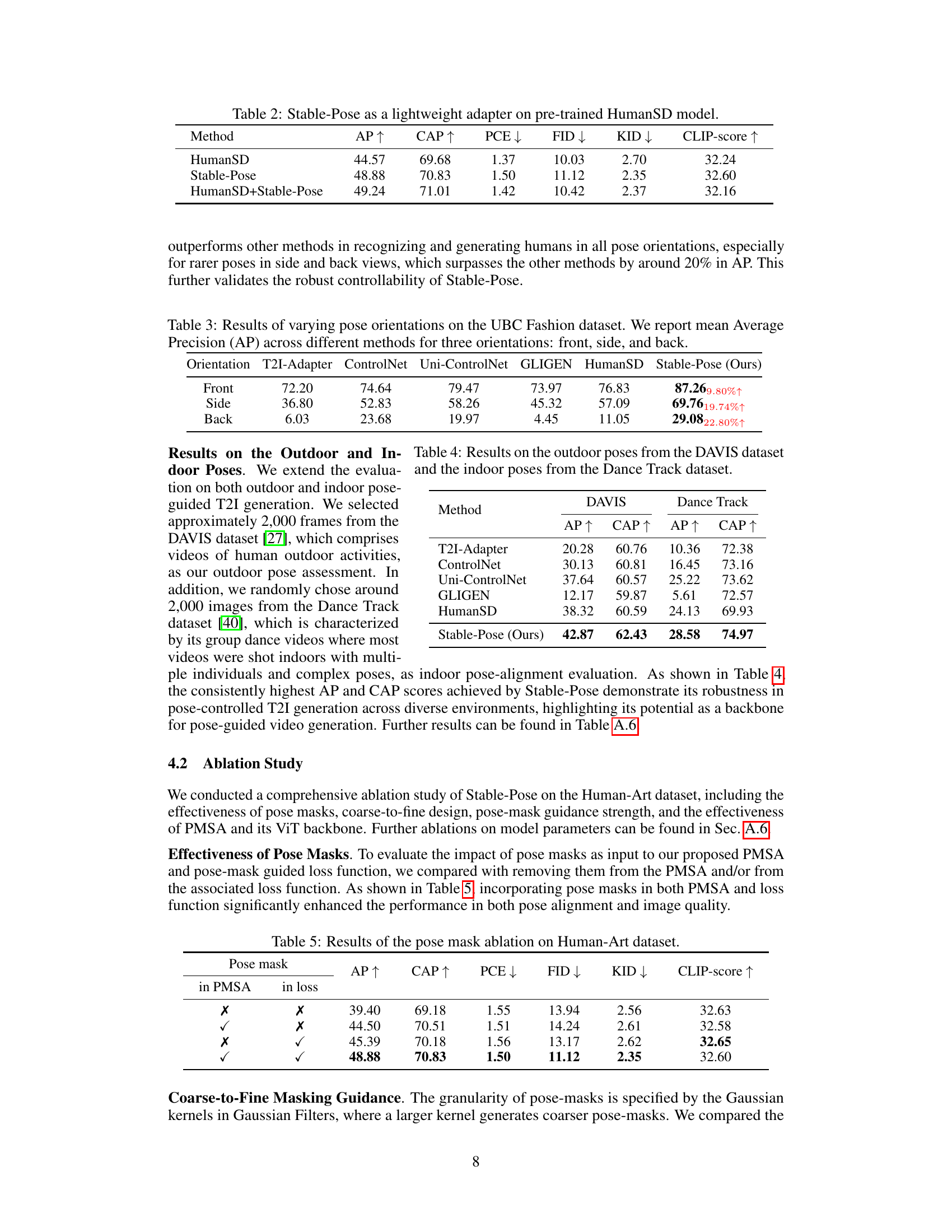
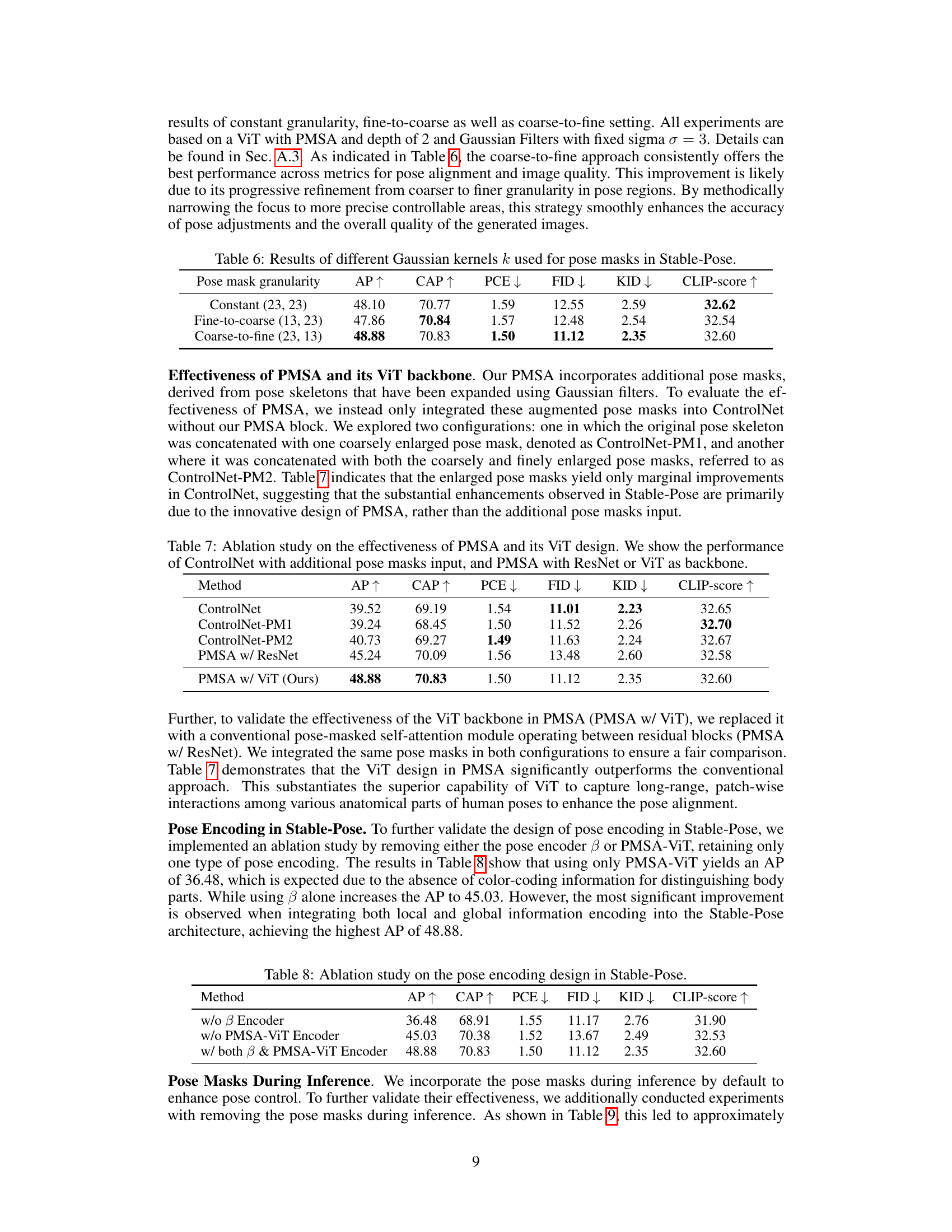
Ablation Study#
An ablation study systematically removes or alters components of a model to assess their individual contributions. In the context of pose-guided image generation, this might involve removing the pose-mask, varying the strength of pose guidance in the loss function, changing the architecture of the pose encoder (e.g., replacing a Vision Transformer with a simpler convolutional network), or modifying the attention mechanism. The goal is to understand which parts are crucial for achieving high performance and pinpoint areas for improvement. A well-executed ablation study would show a clear impact on metrics like Average Precision (AP) and Fréchet Inception Distance (FID) when components are removed, indicating the importance of each module. For example, removing the pose mask entirely might drastically reduce AP because the model loses its primary pose-guiding signal, while changing the pose encoder might slightly impact FID, suggesting that this part is less important for image quality but crucial for pose accuracy. The results would directly support claims about the model’s architecture and effectiveness. Such a study is essential for building a robust and interpretable model.
Pose Control Limits#
The heading ‘Pose Control Limits’ suggests an exploration of the boundaries and shortcomings of current pose-guided text-to-image generation methods. A thoughtful analysis would delve into limitations in handling complex poses, such as extreme or unusual body positions, multiple figures in interaction, or poses from difficult viewpoints (e.g., side or rear views). It could discuss the impact of pose estimation accuracy on the final image quality, acknowledging that errors in initial pose detection directly affect image generation results. Furthermore, an in-depth discussion of model fidelity is crucial, analyzing the degree to which generated images accurately reflect the target pose while also considering potential artifacts or distortions. Finally, it would be vital to consider the impact of different data biases present in training datasets on pose control capabilities, identifying potential systematic errors or limitations in the model’s ability to generalize to unseen pose variations.
More visual insights#
More on figures
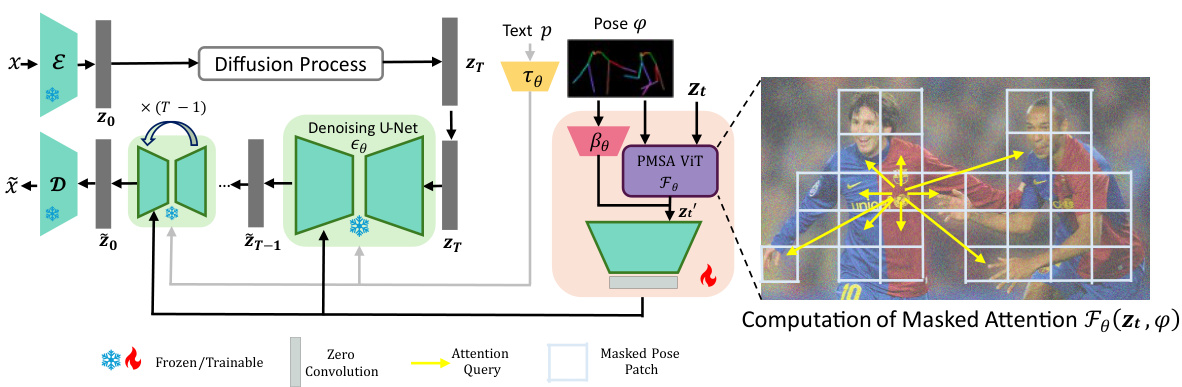
This figure shows the Stable Diffusion architecture with the Stable-Pose module integrated. Stable-Pose is a trainable Vision Transformer (ViT) unit added to improve pose-guided human image generation. The figure illustrates the flow of information: starting with the input image encoded into a latent space, then through the denoising U-Net (with the Stable-Pose module), and finally decoded into the output image. Text and pose information are also input to condition the generation. The Stable-Pose module specifically works with the pose skeleton image to refine the attention mechanism and ensure accurate alignment between the generated image and the input pose.

This figure shows the architecture of Stable-Pose, which is composed of two main blocks: a pose encoder and a coarse-to-fine Pose-Masked Self-Attention (PMSA) Vision Transformer (ViT). The pose encoder processes the pose image to extract high-level features. The PMSA ViT leverages a self-attention mechanism to explore the interconnections among different anatomical parts in human pose skeletons. A coarse-to-fine masking strategy is employed to smoothly refine the attention maps based on target pose-related features in a hierarchical manner, transitioning from coarse to fine levels. The output of the PMSA ViT is then combined with the output of the pose encoder and fed into the pre-trained Stable Diffusion model to generate images.

This figure showcases Stable-Pose’s ability to generate images based on text prompts and human pose skeletons, even with challenging poses like side or rear views. It compares Stable-Pose’s results to other state-of-the-art methods (T2I-Adapter and ControlNet), highlighting Stable-Pose’s improved accuracy and handling of complex poses. Each row depicts different scenarios. For each scenario, the pose skeleton is shown along with the resulting images generated by each technique.

This figure shows a qualitative comparison of Stable-Pose with other state-of-the-art (SOTA) methods for pose-guided text-to-image generation. The top two rows display results from the Human-Art dataset, while the bottom two rows show results from the LAION-Human dataset. Each set of images shows a pose (a), and then the generated images from T2I-Adapter, ControlNet, Uni-ControlNet, GLIGEN, HumanSD and Stable-Pose. The results demonstrate Stable-Pose’s superior performance in pose accuracy and image fidelity across various complex pose scenarios.

This figure showcases the effectiveness of Stable-Pose in addressing complex pose conditions during text-to-image generation. It compares the results of Stable-Pose with other existing techniques (T2I-Adapter and ControlNet) on various examples of human poses, highlighting Stable-Pose’s superior performance in accurately capturing pose details, even in challenging perspectives such as side or rear views. The images demonstrate Stable-Pose’s ability to generate photorealistic images with precise pose alignment.

This figure shows a comparison of different methods for pose-guided text-to-image generation. The top row shows examples where current techniques struggle with complex poses (side or rear perspectives). The bottom row shows how Stable-Pose achieves better results by using a coarse-to-fine attention masking strategy in a vision transformer to accurately align the pose representation during image synthesis.

This figure showcases comparative results of Stable-Pose against other techniques in pose-guided text-to-image generation. It highlights Stable-Pose’s improved ability to handle complex pose conditions, such as side or rear views, compared to existing methods. The images illustrate how Stable-Pose more accurately generates images that match the given pose information.

This figure showcases a comparison of different methods for pose-guided text-to-image generation. It demonstrates Stable-Pose’s ability to handle challenging poses, such as side or rear views of human figures, where other methods struggle. The examples highlight Stable-Pose’s superior performance in generating images that accurately reflect the input pose compared to existing techniques like T2I-Adapter and ControlNet.

This figure showcases the results of Stable-Pose compared to other state-of-the-art techniques for pose-guided text-to-image generation. It highlights Stable-Pose’s ability to accurately generate images even under complex pose conditions (side or rear perspectives), which other methods struggle with. The figure displays various examples of input poses and the resulting images generated by each method, highlighting the improved accuracy and detail of Stable-Pose’s output.

This figure showcases the results of Stable-Pose compared to other techniques (T2I-Adapter and ControlNet) in handling complex human poses during text-to-image generation. The image demonstrates that Stable-Pose produces more accurate and realistic images by leveraging the patch-wise attention mechanism of Vision Transformers. The examples illustrate various poses, highlighting Stable-Pose’s ability to address challenges like side or rear perspectives, often missed by other methods.

This figure showcases the effectiveness of Stable-Pose in addressing the challenges of pose-guided text-to-image (T2I) generation. It compares the results of Stable-Pose with other state-of-the-art methods, demonstrating its superior performance in handling complex pose conditions such as side or rear views. The comparison highlights Stable-Pose’s ability to generate images with more accurate and natural poses. Each row presents an example pose, followed by the images produced by various T2I models.

This figure shows a qualitative comparison of Stable-Pose with other state-of-the-art methods for pose-guided text-to-image generation. The top two rows display results using the Human-Art dataset, and the bottom two rows show results using the LAION-Human dataset. Each set of images shows the input pose (skeleton), the generated images produced by different methods, and the ground truth image. This allows for a visual comparison of the effectiveness of each method in terms of pose accuracy and image quality.

This figure showcases the results of Stable-Pose and other state-of-the-art (SOTA) methods in generating images based on pose input. The comparison highlights Stable-Pose’s improved performance in handling complex poses, such as those from side or rear perspectives, where previous methods often struggle. The figure demonstrates Stable-Pose’s ability to accurately generate images with correct body proportions and pose details, even in challenging scenarios.

This figure showcases the results of Stable-Pose compared to other state-of-the-art techniques on a pose-guided text-to-image generation task. It highlights Stable-Pose’s ability to handle complex pose conditions, such as side or rear views, which were previously challenging for existing methods. The images demonstrate that Stable-Pose produces more accurate and realistic results than its predecessors.

This figure shows an example of pose input used in the Stable-Pose model. The image on the left displays a stick figure representation of a person’s pose, with each body part (keypoint) depicted in a different color. The image on the right shows a photograph of a fashion model that corresponds to that pose. The caption indicates that this particular pose-image pair originates from the UBC Fashion dataset.

This figure shows several examples of images generated by different methods (T2I-Adapter, ControlNet, and Stable-Pose) given the same human pose and text prompt. The goal is to highlight Stable-Pose’s improved ability to accurately generate images reflecting the input pose, even in challenging scenarios like side or rear perspectives, where other methods struggle. The superior performance of Stable-Pose demonstrates its effectiveness in addressing the complexities of pose-guided text-to-image generation.

This figure shows a comparison of different methods for pose-guided text-to-image generation, highlighting the improved performance of Stable-Pose in handling complex poses. The figure shows several examples of generated images, where each example includes the input pose, the images generated by the T2I-adapter, ControlNet, and Stable-Pose. The results demonstrate that Stable-Pose generates images that are more closely aligned with the input pose compared to other methods.
More on tables

This table presents a quantitative comparison of Stable-Pose against other state-of-the-art (SOTA) methods on two datasets: Human-Art and a subset of LAION-Human. The metrics used evaluate pose accuracy (AP, CAP, PCE), image quality (FID, KID), and text-to-image alignment (CLIP-score). The results demonstrate that Stable-Pose achieves the highest pose accuracy scores across both datasets, while showing competitive performance in image quality and alignment.

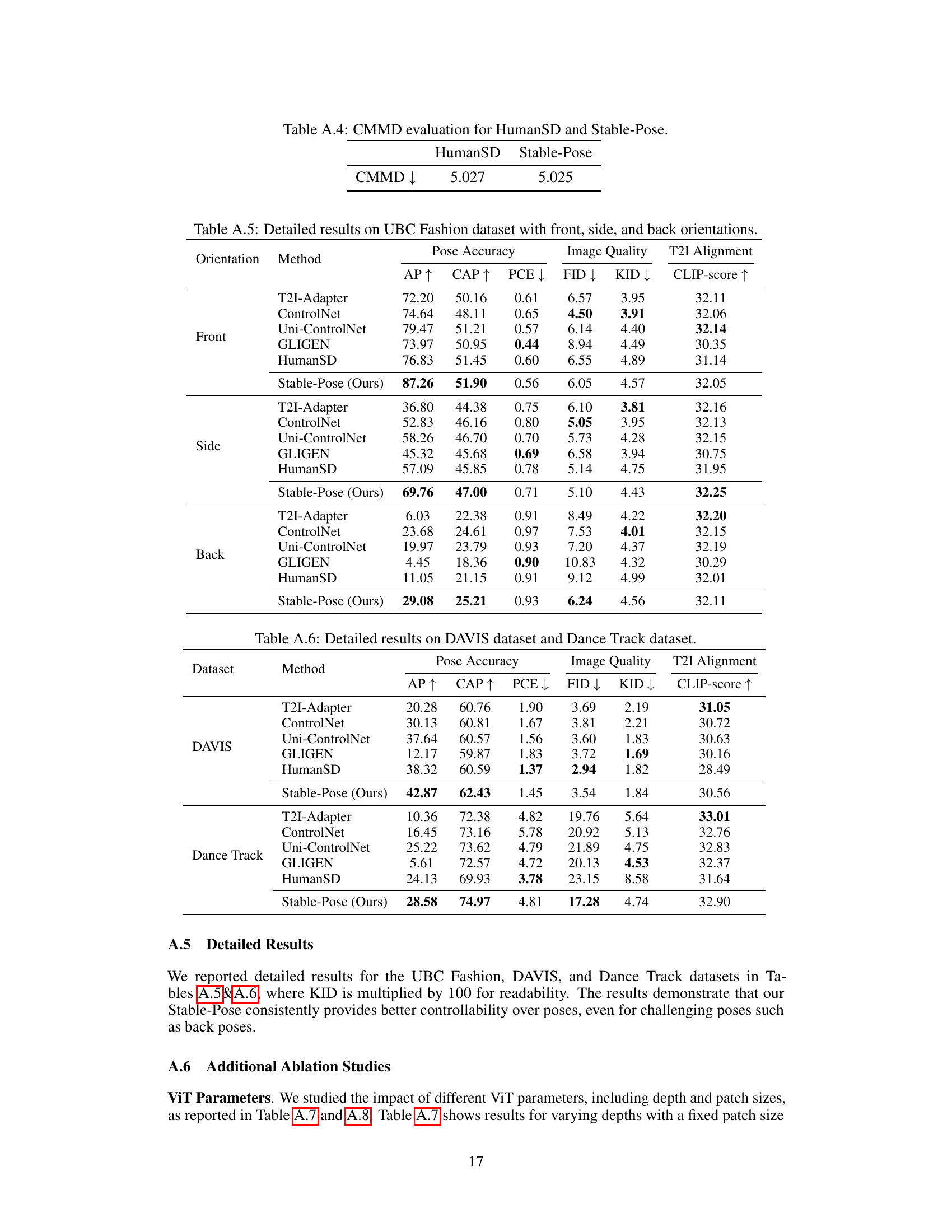
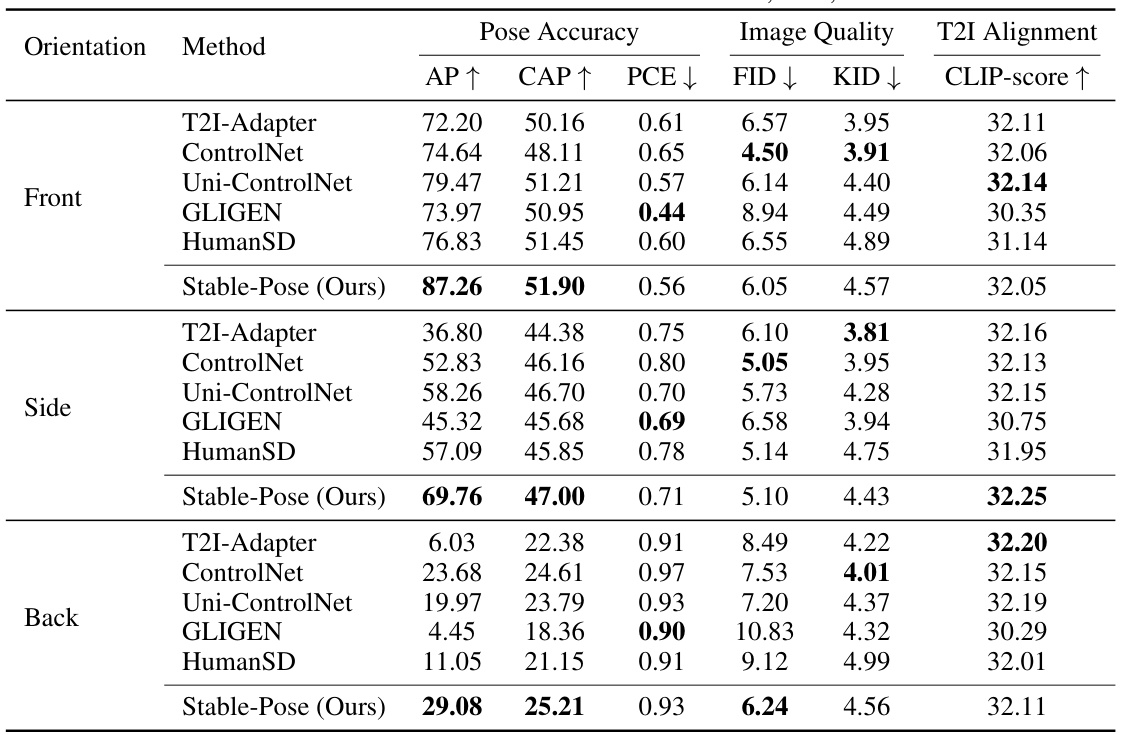
This table presents the mean Average Precision (AP) for pose estimation across three different pose orientations (front, side, and back) on the UBC Fashion dataset. It compares the performance of several methods, including Stable-Pose, highlighting Stable-Pose’s ability to handle varied and challenging poses.
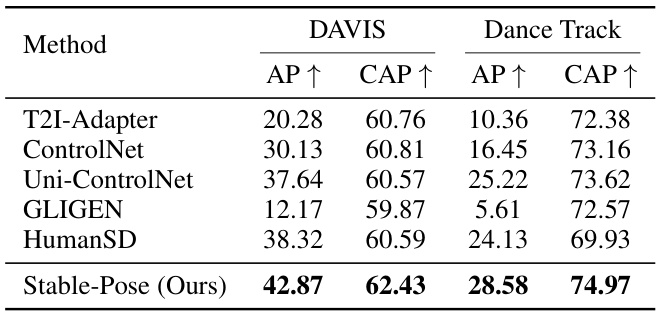
This table presents a quantitative comparison of Stable-Pose and several state-of-the-art methods for pose-guided text-to-image generation on two datasets: Human-Art and LAION-Human. The metrics used evaluate pose accuracy (AP, CAP, PCE), image quality (FID, KID), and text-image alignment (CLIP-score). The results show that Stable-Pose achieves the highest scores in pose accuracy metrics on both datasets, demonstrating its superior ability to generate images with correct poses. Note that results marked with * are based on pre-trained models.
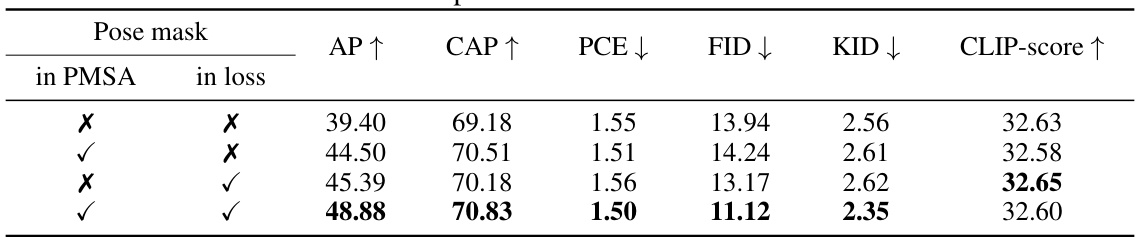
This table presents a quantitative comparison of Stable-Pose against other state-of-the-art methods on two datasets: Human-Art and a subset of LAION-Human. The metrics used assess pose accuracy (AP, CAP, PCE), image quality (FID, KID), and text-to-image alignment (CLIP-score). The results show that Stable-Pose achieves higher pose accuracy than other methods while maintaining comparable image quality and alignment.

This table presents a quantitative comparison of Stable-Pose against other state-of-the-art methods on two datasets: Human-Art and LAION-Human. The evaluation metrics include Pose Accuracy (AP, CAP, PCE), Image Quality (FID, KID), and T2I Alignment (CLIP-score). The results show Stable-Pose achieving the highest pose accuracy scores (AP and CAP) on both datasets, with comparable or slightly better image quality and alignment results. The asterisk (*) indicates that some methods’ results are based on publicly released model checkpoints, rather than the authors’ own fully trained models.

This table presents quantitative results on the Human-Art and LAION-Human datasets, comparing Stable-Pose to several state-of-the-art methods. It shows the performance of each method across various metrics measuring pose accuracy (Average Precision (AP), Pose Cosine Similarity-based AP (CAP), and People Counting Error (PCE)), image quality (Fréchet Inception Distance (FID) and Kernel Inception Distance (KID)), and text-image alignment (CLIP score). The results highlight Stable-Pose’s superior performance in pose accuracy and overall image quality.

This table presents a quantitative comparison of Stable-Pose against other state-of-the-art methods on two datasets: Human-Art and a subset of LAION-Human. The metrics used evaluate pose accuracy (AP, CAP, PCE), image quality (FID, KID), and text-to-image alignment (CLIP-score). The results show Stable-Pose’s superior performance in pose accuracy, particularly on the LAION-Human dataset, while maintaining comparable image quality and text-to-image alignment.

This table presents a quantitative comparison of Stable-Pose and several state-of-the-art (SOTA) methods for pose-guided text-to-image generation. The evaluation metrics include pose accuracy (Average Precision (AP), Pose Cosine Similarity-based AP (CAP), People Counting Error (PCE)), image quality (Fréchet Inception Distance (FID), Kernel Inception Distance (KID)), and text-to-image alignment (CLIP-score). The results are shown for two datasets: Human-Art and a subset of LAION-Human. The asterisk (*) indicates that results for certain methods were obtained using pre-trained model checkpoints rather than training from scratch.

This table presents a quantitative comparison of Stable-Pose against other state-of-the-art methods on two datasets: Human-Art and a subset of LAION-Human. The metrics used to evaluate the models include pose accuracy (AP, CAP, PCE), image quality (FID, KID), and text-to-image alignment (CLIP-score). The table shows Stable-Pose’s performance relative to other methods, highlighting its strengths in pose accuracy and overall image generation.

This table presents the quantitative results of Stable-Pose and other state-of-the-art methods on two datasets: Human-Art and a subset of LAION-Human. The metrics used assess pose accuracy (AP, CAP, PCE), image quality (FID, KID), and text-to-image alignment (CLIP-score). The results show that Stable-Pose achieves higher pose accuracy compared to other methods, while maintaining comparable image quality and text-to-image alignment.

This table presents quantitative results comparing Stable-Pose against other state-of-the-art methods on two benchmark datasets: Human-Art and a subset of LAION-Human. The evaluation metrics include Pose Accuracy (AP, CAP, PCE), Image Quality (FID, KID), and Text-to-Image Alignment (CLIP-score). The results show that Stable-Pose achieves superior pose accuracy and comparable performance on image quality and alignment. The asterisk (*) indicates that results for certain methods were obtained using pre-trained checkpoints rather than training from scratch.

This table presents a quantitative comparison of Stable-Pose against several state-of-the-art (SOTA) methods on two datasets: Human-Art and a subset of LAION-Human. The evaluation metrics cover pose accuracy (AP, CAP, PCE), image quality (FID, KID), and text-to-image alignment (CLIP-score). The results demonstrate Stable-Pose’s superior performance, particularly in pose accuracy, on both datasets.
This table presents a quantitative comparison of Stable-Pose against other state-of-the-art methods on two datasets: Human-Art and a subset of LAION-Human. It shows the performance across metrics like Pose Accuracy (AP, CAP, PCE), Image Quality (FID, KID), and T2I Alignment (CLIP-score). The results demonstrate Stable-Pose’s performance in terms of pose accuracy and overall image quality.

This table presents a quantitative comparison of Stable-Pose against several state-of-the-art methods on two benchmark datasets: Human-Art and a subset of LAION-Human. The evaluation metrics assess both pose accuracy (AP, CAP, PCE) and image quality (FID, KID, CLIP-score). The table highlights Stable-Pose’s superior performance in pose accuracy, showing comparable results in image quality and text-image alignment.

This table presents the quantitative results of Stable-Pose and several state-of-the-art methods on two datasets: Human-Art and LAION-Human. The metrics used assess pose accuracy (AP, CAP, PCE), image quality (FID, KID), and text-to-image alignment (CLIP-score). The results show Stable-Pose achieving superior performance, particularly in pose accuracy, compared to the other methods. The asterisk (*) indicates that results for certain methods were obtained from already released checkpoints, not from training conducted as part of this study.

This table presents a quantitative comparison of Stable-Pose against other state-of-the-art methods on two benchmark datasets: Human-Art and LAION-Human. The metrics used assess pose accuracy (AP, CAP, PCE), image quality (FID, KID), and text-to-image alignment (CLIP-score). The results show that Stable-Pose achieves superior performance in terms of pose accuracy on both datasets. Note that some methods (*) use pre-trained checkpoints instead of being trained from scratch on the datasets, potentially explaining differences in the results.
Full paper#