↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current camera operation in film production demands high skill and meticulous execution. Recent advancements in large language models (LLMs) show potential for automating such tasks but adapting LLMs for camera control is largely unexplored. This paper addresses this gap, highlighting the complexity of bridging natural language understanding with physical camera control.
This research introduces ChatCam, a system that uses LLMs and two novel tools—CineGPT and an Anchor Determinator—to accomplish this. CineGPT translates textual instructions into camera trajectories, while the Anchor Determinator ensures the accuracy of trajectory placement using scene object references. The system shows promising results in generating high-quality videos in diverse settings and opens new possibilities for AI-assisted filmmaking. The code will be released soon.
Key Takeaways#
Why does it matter?#
This paper is important because it pioneers the use of conversational AI for camera control, opening up exciting new avenues for video production and related fields. It demonstrates the feasibility and effectiveness of using large language models (LLMs) to translate natural language instructions into precise camera movements, thus potentially revolutionizing video creation workflows. The introduced method, with the release of its codebase, will facilitate further research into AI-assisted filmmaking and related areas.
Visual Insights#
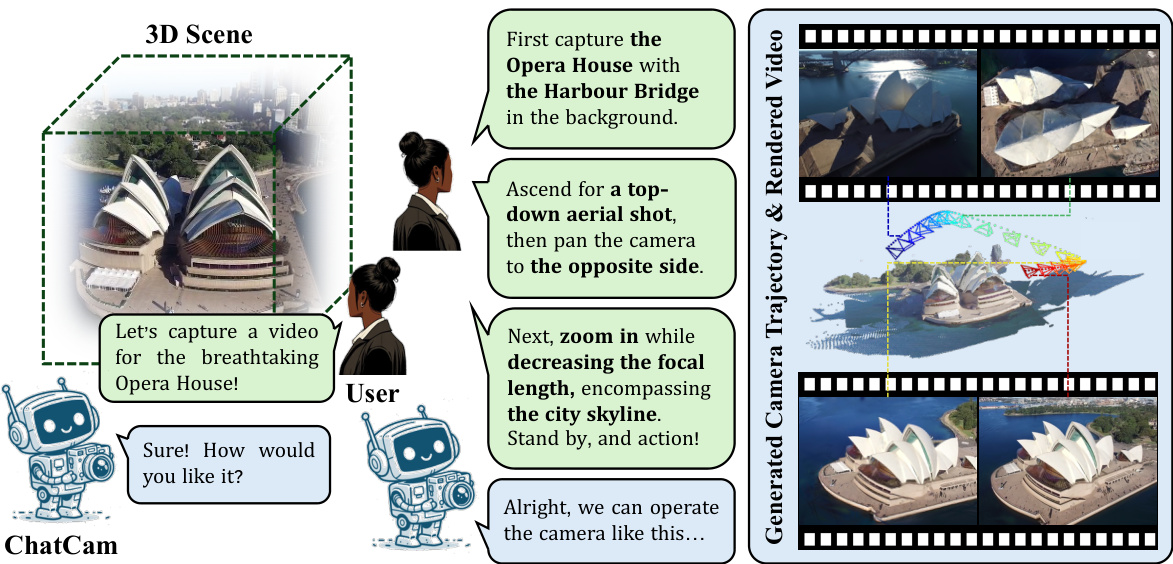
This figure illustrates the ChatCam system, which uses conversational AI to control camera movements for video generation. The user provides a natural language instruction (e.g., ‘Let’s capture a video for the breathtaking Opera House!’). ChatCam processes this request, generates a camera trajectory, and renders a corresponding video using radiance field techniques (NeRF or 3DGS). The figure shows a visual representation of this process, highlighting the interaction between the user, the ChatCam system, and the generated video output.

This table presents a quantitative comparison of the proposed ChatCam model against several baseline methods (SA3D and LERF) for camera trajectory generation based on text descriptions. It evaluates the performance across several metrics: Translation MSE (lower is better), Rotation MSE (lower is better), Visual Quality (higher is better, as rated by human judges), and Alignment (higher is better, also assessed by human judges). Different LLM agents (LLaMA-2, GPT-3.5, GPT-4) and variations of ChatCam (with and without anchor determination) are included in the comparison to show the impact of each component of the model. The results indicate that the complete ChatCam system using GPT-4 achieves superior performance in all aspects.
In-depth insights#
CineGPT: Core Model#
CineGPT, as a core model for text-conditioned camera trajectory generation, presents a novel approach to bridging the gap between human language and camera control. Its architecture, likely a transformer-based model, leverages a paired dataset of text descriptions and corresponding camera trajectories. The training process aims to enable CineGPT to generate trajectories directly from natural language instructions, mimicking the creative process of a professional cinematographer. This method tackles the challenge of translating nuanced language into precise camera movements, including translations, rotations, focal lengths, and velocity. Key to CineGPT’s success is its ability to understand the semantic meaning of the text input, not just the individual words. Furthermore, its integration with an anchor determination module likely enhances the accuracy and precision of generated trajectories, ensuring that camera movements are appropriately contextualized within a 3D scene. The model’s effectiveness depends on the quality and diversity of the training dataset, requiring both rich linguistic variations and a wide range of camera movements. The performance of CineGPT, as a core component of the ChatCam system, is likely evaluated through both quantitative metrics (e.g., trajectory accuracy) and qualitative assessments (e.g., user perception of visual appeal).
Anchor Determination#
Anchor determination plays a crucial role in grounding camera trajectories within specific 3D scenes. The core idea is to identify relevant objects within the scene that can serve as reference points, or anchors, for precisely placing camera movements. The method presented likely involves a two-stage process: first, selecting an initial anchor candidate (perhaps using an image-matching technique like CLIP), and then refining this selection to optimize the anchor’s positional accuracy within the scene’s 3D representation (using a rendering function and iterative optimization). This refinement step ensures that the generated camera trajectory aligns seamlessly with the user’s specified scene elements and produces visually pleasing video results. The selection of appropriate anchors is critical for accurate camera placement and generating the desired visual narrative, especially in complex scenes containing multiple objects. The effectiveness of anchor determination hinges on the robustness of both the initial anchor selection and the refinement process, requiring a careful balance between computational efficiency and accuracy.
ChatCam Pipeline#
The hypothetical “ChatCam Pipeline” represents a multi-stage process for generating camera trajectories from natural language descriptions. It likely begins with natural language understanding, parsing user requests into semantically meaningful components. Next, an anchor determination module identifies key objects in the 3D scene, crucial for accurate trajectory positioning. Then, a core component, CineGPT, a GPT-based model, generates the camera trajectory based on the semantic interpretation and anchor points. Trajectory refinement and optimization steps might follow, ensuring smoothness and realism. Finally, a rendering module, likely using radiance fields, creates the final video output, making the whole pipeline a seamless integration of AI and computer graphics.
Qualitative Results#
A qualitative results section in a research paper would present findings in a non-numerical way, focusing on descriptions, observations, and interpretations of the data. It might showcase representative examples of outputs, such as images generated by a model, or transcripts from user interactions. For example, a study on image generation could include a selection of generated images with commentary on their artistic merits and any discernible patterns. A strong qualitative analysis would go beyond simply showing examples, offering detailed commentary on the characteristics of the outputs and connecting them back to the research questions. It would explore the nuances and complexities that quantitative measures might miss, providing richer insights into the nature of the results. The strength of the qualitative results hinges on the clarity and depth of the analysis, its relevance to the research aims, and how effectively it supports the paper’s overall claims. Careful selection of representative examples and thoughtful interpretation are crucial. Weak qualitative results might lack depth, present unclear or poorly explained examples, or fail to adequately connect observations to the study’s hypotheses.
Future of ChatCam#
The future of ChatCam hinges on several key advancements. Improved LLM integration is crucial; more sophisticated language models will allow for nuanced camera control instructions, potentially encompassing stylistic choices and creative direction. Enhanced 3D scene understanding is another vital area; better scene parsing and object recognition will lead to more precise camera placement and movement, especially in complex environments. Real-time performance is a critical goal, allowing for interactive camera manipulation in live settings. Multi-modal input will extend ChatCam’s capabilities by incorporating audio and other sensory data, adding layers of depth and context to camera control. Expansion beyond radiance fields is also vital; broader compatibility with various 3D rendering techniques will increase accessibility and broaden application areas. Finally, ethical considerations should be a focus of future development, ensuring responsible AI integration in filmmaking and other creative industries. These advancements will transform ChatCam into a truly powerful tool for cinematographers and content creators.
More visual insights#
More on figures

This figure illustrates the ChatCam system, which allows users to control camera movements using natural language. The user inputs a description of the desired camera trajectory (e.g., ‘First capture the Opera House with the Harbour Bridge in the background’), and ChatCam generates a trajectory that mimics a professional cinematographer’s workflow. The system uses this trajectory to render a high-quality video using radiance field representations (NeRF or 3DGS). The figure shows the interaction between the user and ChatCam, the 3D scene, the generated trajectory, and the final rendered video.

This figure illustrates the ChatCam pipeline. It shows how a user’s natural language camera instruction is processed. First, the system reasons about the instruction, identifying key elements. Then, it uses CineGPT and Anchor Determinator to generate trajectory segments. Finally, an AI agent combines these segments into a complete camera trajectory and renders the video.
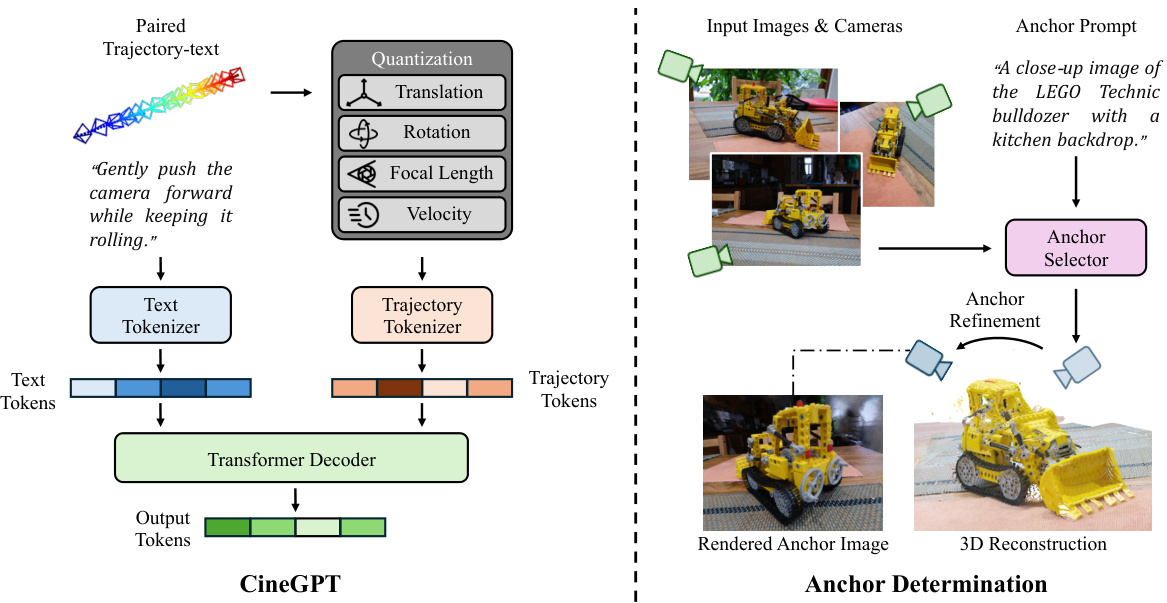
This figure illustrates the architecture of CineGPT and Anchor Determination. CineGPT is a GPT-based model that takes text and quantized camera trajectory tokens as input and generates camera trajectory tokens. Anchor Determination uses a CLIP-based approach to select an anchor image from input images based on a text prompt, followed by a refinement process to fine-tune the anchor position. The diagram shows the flow of data from text input, through tokenization, to the generation of trajectory tokens by CineGPT. It also shows the selection and refinement of an anchor image in 3D scene understanding to guide trajectory generation.

This figure shows qualitative results of the ChatCam system on both indoor and outdoor scenes. It presents three example user prompts and the resulting video frames generated by the system. The prompts demonstrate the system’s ability to handle various camera movements (dolly zoom, panning, zooming) and to understand specialized cinematic terminology. The rendered frames showcase the accuracy and realism of the generated trajectories.

This figure shows qualitative results of ChatCam on human-centric scenes. It demonstrates the system’s ability to generate camera trajectories from natural language descriptions, even in complex scenes with multiple people. The top row presents a text prompt describing the desired camera movement, while the bottom row displays the resulting video frames. The figure highlights ChatCam’s effectiveness in interpreting and translating complex human-centric instructions into precise camera movements.

This figure shows a qualitative comparison of the proposed ChatCam approach against two baseline methods, SA3D and LERF, for generating camera trajectories from natural language instructions. The results demonstrate that ChatCam produces more reasonable and visually appealing camera paths, avoiding unrealistic placements (e.g., inside objects) and achieving better alignment with the intended text descriptions. The images illustrate the camera’s movement and the resulting viewpoints for each method.

This figure shows qualitative results of the proposed ChatCam system on both indoor and outdoor scenes. Three example user requests are presented along with the resulting camera trajectories and frames from the rendered videos. The results demonstrate the system’s ability to correctly interpret and execute complex camera instructions, including those using specialized cinematography terms like ‘dolly zoom’.

This figure shows additional qualitative results of the ChatCam system. It presents examples of generated camera trajectories and resulting video frames from various natural language instructions, demonstrating the system’s ability to interpret and execute complex and nuanced instructions in different scenes. The instructions include both simple movements and more elaborate ones such as specifying camera position relative to objects in the scene and following S-shaped paths. The images illustrate the quality of the generated trajectories and the realism of the rendered videos.
Full paper#



















