↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Spiking Neural Networks (SNNs) are energy-efficient alternatives to traditional neural networks, but their deployment on neuromorphic chips faces challenges. Clock-driven synchronous chips demand shorter time steps for energy efficiency, reducing SNN performance, while event-driven asynchronous chips offer lower power but limit supported operations. Many recent SNN projects significantly improved performance but are incompatible with asynchronous hardware.
This paper introduces Spiking Token Mixer (STMixer), an architecture using only operations compatible with asynchronous hardware (convolutions, fully connected layers, residual paths). Experiments show STMixer matches Spiking Transformers’ performance on synchronous hardware, even with very low time steps. This suggests STMixer can achieve similar performance with significantly reduced power consumption on both synchronous and asynchronous neuromorphic chips.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with spiking neural networks (SNNs) and neuromorphic hardware. It directly addresses the limitations of current SNN architectures for asynchronous hardware, opening new avenues for energy-efficient AI. The proposed Spiking Token Mixer (STMixer) architecture offers a novel approach to SNN design that is compatible with the constraints of asynchronous chips, potentially leading to significant advancements in low-power AI applications.
Visual Insights#

This figure illustrates the architecture of Spikformer-like networks and highlights the challenges of using spiking matrix multiplication and max-pooling layers in asynchronous hardware. Panel A shows the overall architecture of both Spikformer and the proposed STMixer, emphasizing their shared structure of Spiking Patch Splitting (SPS), encoder blocks, and a classification head. Panel B demonstrates how a delay in spike arrival in an asynchronous max-pooling layer affects the output, while Panel C visualizes how similar inaccuracies arise in spike matrix multiplication due to imprecise spike arrival timings.

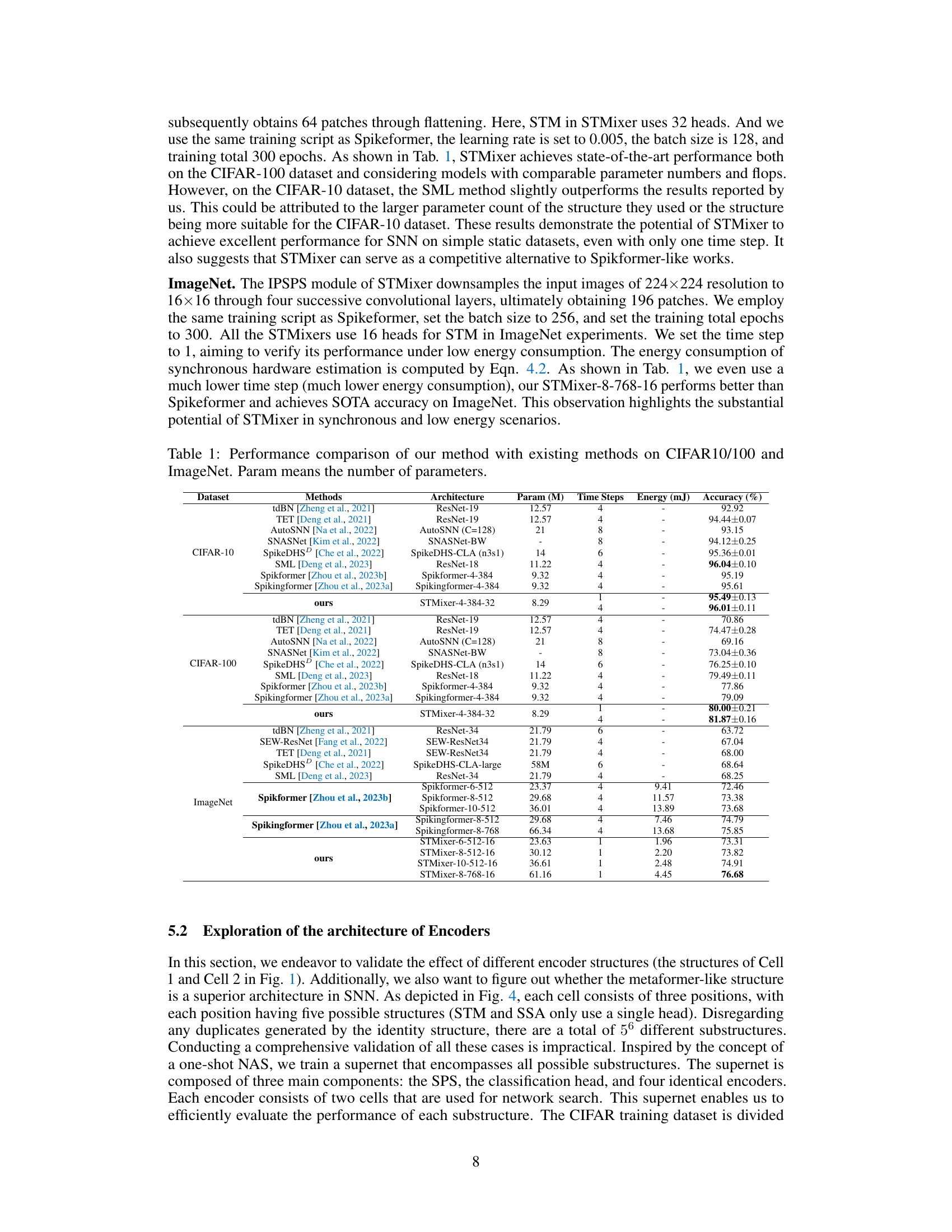
This table presents a comparison of the proposed STMixer model’s performance against several state-of-the-art Spiking Neural Network (SNN) architectures on three benchmark datasets: CIFAR-10, CIFAR-100, and ImageNet. The comparison includes the number of parameters, the time steps used, the energy consumption (in mJ), and the accuracy achieved by each model. This allows for an assessment of the trade-off between model complexity, energy efficiency, and accuracy. The table highlights STMixer’s ability to achieve competitive accuracy with fewer parameters and lower energy consumption, particularly at very low time steps (T=1).
In-depth insights#
SNN Architecture#
This research paper explores novel Spiking Neural Network (SNN) architectures designed for energy efficiency and performance. A key focus is on creating SNNs compatible with event-driven asynchronous hardware, which offers significant power advantages over traditional clock-driven systems. The proposed architecture, likely named something like “Spiking Token Mixer” or a similar designation, is built using only operations supported by this asynchronous hardware. This design choice is crucial because it avoids the computational overhead and power consumption associated with operations not supported by the hardware. The architecture is likely composed of layers such as convolutional layers, fully connected layers, and residual connections, all optimized for event-driven processing. A significant contribution involves modifying or replacing existing SNN modules, like the Spiking Self-Attention (SSA) module, to work effectively within the constraints of asynchronous hardware. This could entail simplifying the operations or replacing them altogether with novel structures. The paper likely demonstrates that the proposed architecture achieves comparable, or even superior, performance to state-of-the-art SNNs in synchronous scenarios while consuming significantly less power due to its event-driven compatibility. The efficiency is further enhanced through techniques like surrogate module learning, aimed at improving the training process for SNNs. In essence, this research advances the SNN field by proposing a highly efficient and practical architecture tailored to the capabilities and energy-saving potential of asynchronous neuromorphic hardware.
Asynchronous SNNs#
Asynchronous Spiking Neural Networks (SNNs) represent a compelling paradigm shift in neuromorphic computing. Unlike their synchronous counterparts, asynchronous SNNs are event-driven, responding only to the arrival of spikes, rather than operating on a fixed clock cycle. This inherent characteristic leads to significant advantages in terms of energy efficiency and scalability. Lower power consumption is a direct outcome of the event-driven nature, as computations are only performed when necessary. Furthermore, the asynchronous design allows for more flexible and adaptable network architectures compared to the constraints imposed by synchronous clocking. However, this flexibility also presents challenges. Precise timing of spike events becomes less critical compared to synchronous SNNs, but new algorithms and hardware are necessary to fully exploit the potential of asynchronous operation. The development of suitable hardware and software is crucial to overcoming the challenges of implementing and training efficient asynchronous SNNs and achieving their theoretical performance promises. Efficient training algorithms are also essential to address the difficulties associated with the lack of precise timing information typically found in asynchronous systems.
STMixer Design#
The STMixer design is a novel architecture for spiking neural networks (SNNs) optimized for both event-driven and synchronous hardware. Its core innovation lies in replacing the computationally expensive spiking self-attention (SSA) module of Spikformer with a simpler, more efficient Spiking Token Mixer (STM) module. The STM employs a trainable weight matrix for token mixing, eliminating the need for multiple spiking matrix multiplications, making it suitable for asynchronous hardware. Furthermore, the design incorporates an Information Protection Spiking Patch Splitting (IPSPS) module to reduce information loss during the initial processing stages. By focusing on operations supported by both hardware paradigms, STMixer aims to bridge the gap between the energy efficiency of event-driven SNNs and the performance of synchronous implementations. The use of surrogate module learning further enhances performance, particularly at low time steps. This architecture represents a significant advancement for SNN deployment on neuromorphic hardware, promising energy-efficient performance without sacrificing accuracy.
Surrogate Learning#
Surrogate learning addresses the challenge of training spiking neural networks (SNNs) by approximating the inherently non-differentiable spiking dynamics with a differentiable surrogate gradient. This technique allows the application of backpropagation, a cornerstone of deep learning, enabling efficient training of SNNs. However, the accuracy of the surrogate gradient is crucial; inaccuracies can hinder the performance and stability of the trained SNN. Several methods exist for generating these surrogate gradients, each with its own strengths and weaknesses in terms of computational cost and approximation accuracy. The choice of surrogate gradient impacts both the speed and effectiveness of the training process. Further research into refining surrogate gradient methods is essential to unlocking the full potential of SNNs. Successful surrogate learning significantly enhances the feasibility of large-scale SNN deployment and development, making it a vital area of ongoing research within the field of neuromorphic computing.
Future Work#
Future research directions stemming from this Spiking Token Mixer (STMixer) paper could explore several promising avenues. Extending STMixer’s architecture to handle more complex tasks beyond image classification, such as object detection or video processing, would be valuable. This might involve adapting the token mixing module to handle spatiotemporal data more effectively. Another area of exploration is improving the training efficiency of STMixer. While surrogate gradient learning is used, further advancements could explore novel training techniques tailored to the asynchronous nature of STMixer. Investigating different hardware implementations beyond simulation would be crucial to verify the energy-efficiency claims and assess real-world performance. This could involve collaborations with neuromorphic chip designers to optimize STMixer for specific hardware platforms. Finally, a deeper theoretical analysis could focus on understanding the underlying mathematical properties of STMixer, potentially leading to architectural improvements and better generalization capabilities.
More visual insights#
More on figures
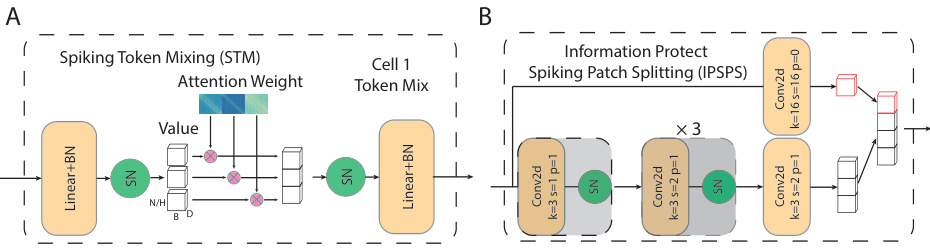
This figure shows the architecture of two crucial modules in the proposed STMixer network: the Spiking Token Mixing (STM) module and the Information Protect Spiking Patch Splitting (IPSPS) module. (A) The STM module details how a weighted matrix is used to mix token information, replacing the original Spiking Self-Attention (SSA) module to be more suitable for asynchronous hardware. (B) The IPSPS module modifies the original Spiking Patch Splitting (SPS) module to reduce information loss during downsampling by adding an additional information protection pathway, using a convolutional layer to generate additional feature maps.
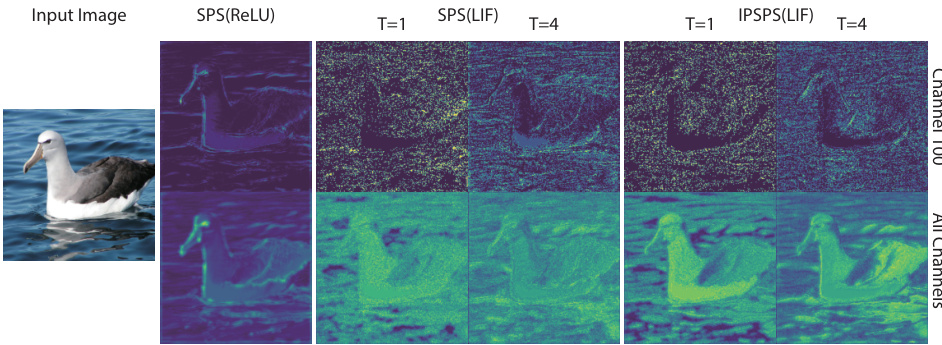
This figure visualizes the information loss in the Spiking Patch Splitting (SPS) module of a Spiking Neural Network (SNN). It compares feature maps generated using ReLU and LIF activation functions at different time steps (T=1 and T=4) for both the original SPS and the improved IPSPS (Information Protected SPS) module. The results show that the LIF activation function in the standard SPS leads to significant information loss compared to ReLU and to the input image. The IPSPS module mitigates this information loss.
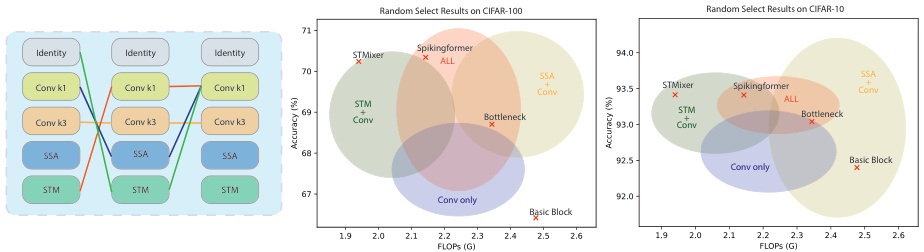
This figure shows the results of a neural architecture search. The search space is shown on the left, which includes different combinations of convolutional layers, SSA (Spiking Self-Attention), and STM (Spiking Token Mixing) modules. The middle and right panels show the results of the search on CIFAR-100 and CIFAR-10 datasets, respectively. Each point represents a randomly sampled architecture from the search space, and its position indicates its accuracy and FLOPs (floating point operations). The figure shows that STMixer achieves a good balance between accuracy and FLOPs.

This figure visualizes the information loss in the Spiking Patch Splitting (SPS) module of Spiking Neural Networks (SNNs) and demonstrates how the proposed Information Protection Spiking Patch Splitting (IPSPS) module mitigates this issue. It compares feature maps from SPS using ReLU and LIF activation functions, showing a significant information loss in the LIF version (SNN). The IPSPS module is shown to significantly reduce this information loss. The visualization uses both individual channel and average across all channels.
More on tables

This table shows the ablation study results on CIFAR-100 using the STMixer-4-384-16 model with one time step. By replacing components of the STMixer model with different alternatives, it demonstrates the individual contributions and effects of each component to the model’s performance. The results highlight the importance of the Spiking Token Mixing (STM) module, the Information Protect Spiking Patch Splitting (IPSPS) module, and the surrogate module learning (SML) method in achieving high accuracy.

This table compares the performance of the proposed STMixer model against several existing state-of-the-art Spiking Neural Network (SNN) models on three benchmark datasets: CIFAR-10, CIFAR-100, and ImageNet. The comparison includes the number of parameters, the number of time steps used, energy consumption (in millijoules), and the achieved accuracy. The table demonstrates that STMixer achieves competitive or superior performance compared to existing models, particularly at low time steps, suggesting potential advantages in terms of energy efficiency.

This table compares the performance of STMixer and SpikFormer under different time steps (T) and in an event-driven scenario using the CIFAR10-DVS dataset. It shows the accuracy achieved by each model with and without bias for varying time steps (T=25, T=40, T=80, T=160, T=320, T=640), and specifically highlights the performance in a fully event-driven setting. This allows for comparison of performance across synchronous and asynchronous scenarios under different computational constraints.
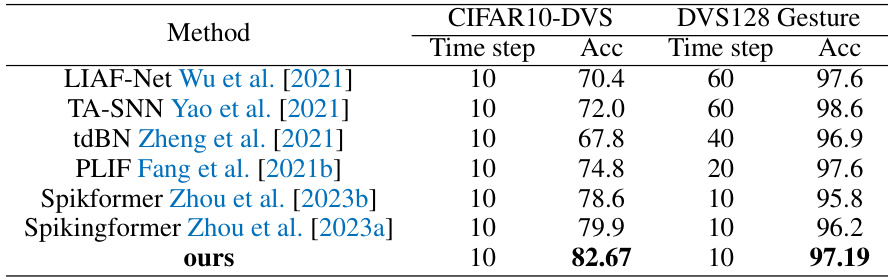
This table compares the performance of the proposed STMixer model with other state-of-the-art Spiking Neural Network (SNN) models on two neuromorphic datasets: CIFAR10-DVS and DVS128 Gesture. The comparison is based on the accuracy achieved and the time step used. It shows that STMixer outperforms other methods on both datasets.
Full paper#