↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Conformal prediction offers uncertainty quantification by constructing prediction sets containing the true label with high probability. However, its efficiency in dynamic environments with shifting data distributions is limited by the choice of a single learning model. Existing adaptive methods struggle to consistently provide optimal results across various distribution shifts and interval widths.
To address these issues, the paper introduces SAMOCP, a novel adaptive conformal prediction framework that uses multiple models. SAMOCP dynamically selects the most suitable model ‘on the fly’ based on recent performance. The method is rigorously proven to offer strongly adaptive regret while maintaining valid coverage. Experiments on real-world and synthetic datasets showcased consistent improvements in prediction set efficiency and maintained validity compared to other existing methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on uncertainty quantification, online learning, and adaptive methods. It addresses the limitations of existing conformal prediction methods in dynamic environments by introducing a novel multi-model ensemble approach, thereby opening new avenues for research in handling data distribution shifts and improving prediction efficiency. The strong theoretical guarantees and superior empirical performance make it a significant advancement.
Visual Insights#
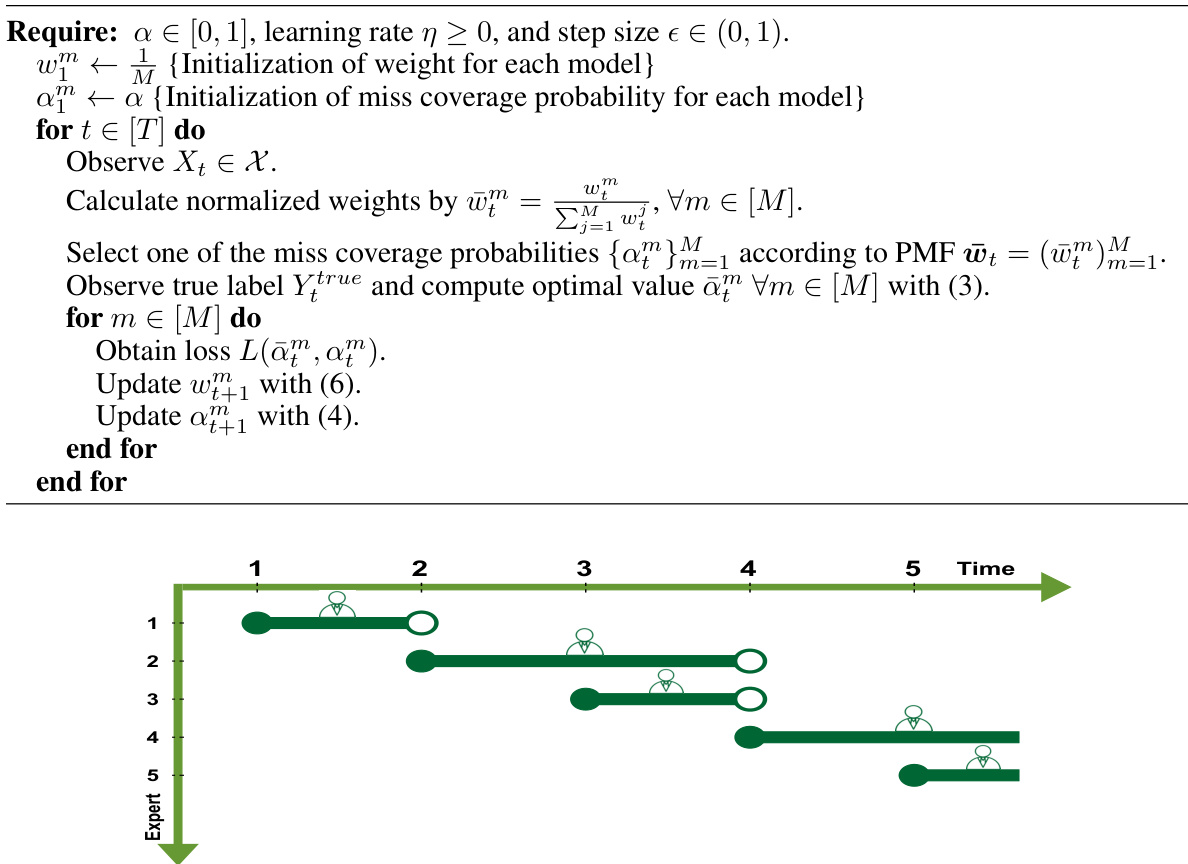
This figure illustrates how experts are created and their lifespans are determined by the formula (9) in the paper. Each expert’s lifespan (active interval) is represented by filled and unfilled circles along the time axis, showing how experts are created and deactivated over time. This dynamic expert management is crucial for handling distribution shifts in the data.
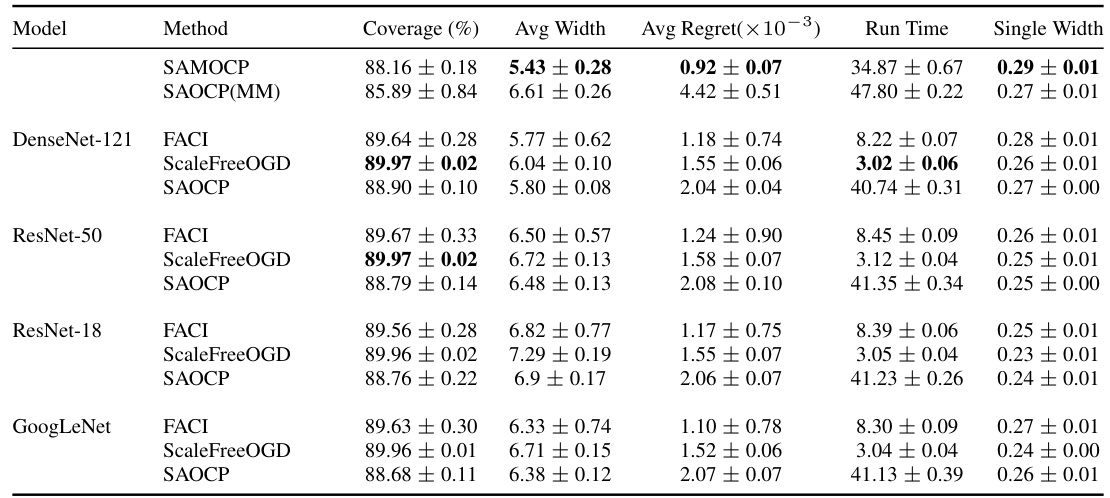
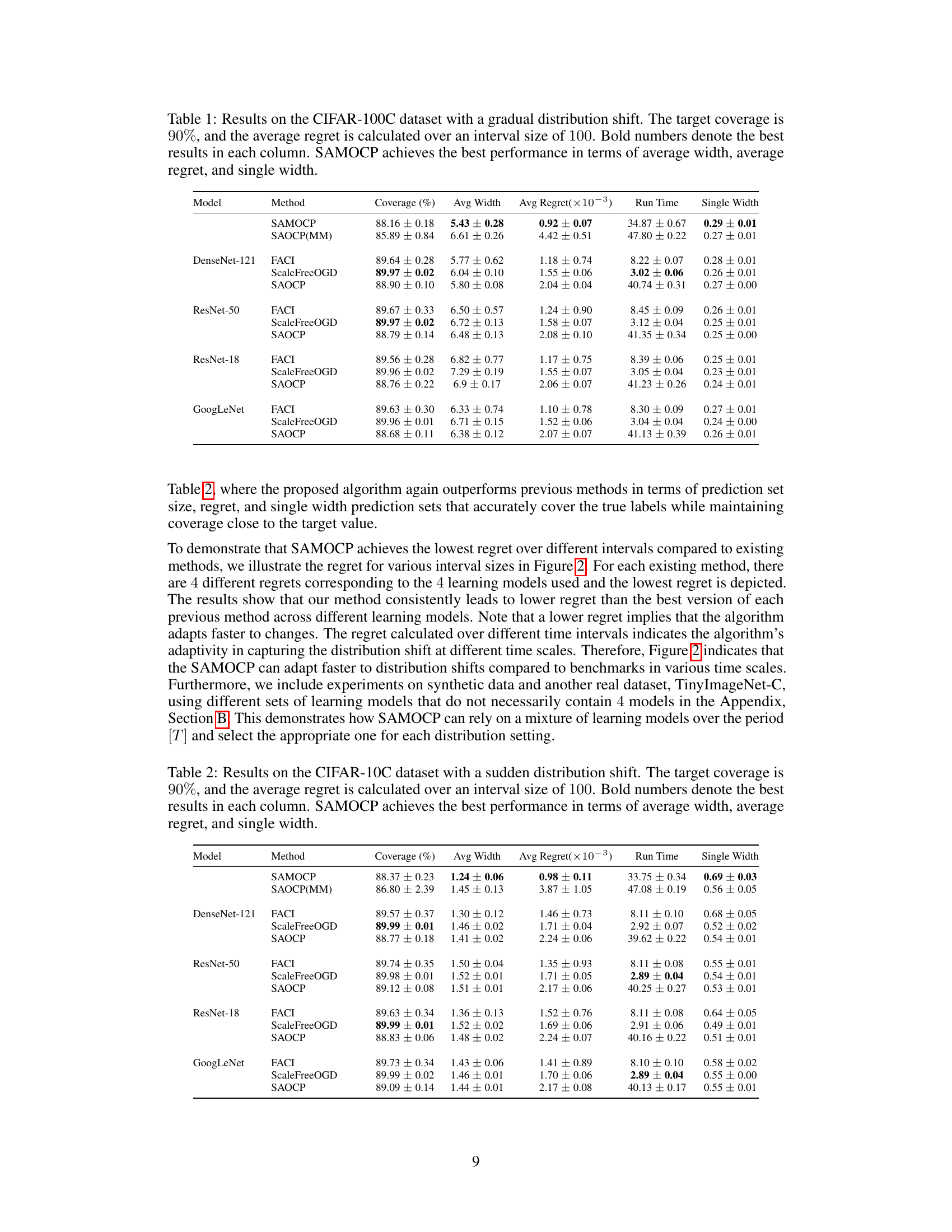
This table presents a comparison of different conformal prediction methods on the CIFAR-100C dataset under a gradual distribution shift. The methods are evaluated based on their coverage, average prediction set width (Avg Width), average regret over intervals of size 100, runtime, and the percentage of single-element prediction sets that correctly include the true label (Single Width). SAMOCP demonstrates superior performance in most metrics, particularly in terms of generating smaller prediction sets while achieving near-target coverage.
In-depth insights#
Adaptive Conformal#
Adaptive conformal prediction addresses the limitations of standard conformal prediction in handling dynamic environments where data distributions shift over time. Standard conformal prediction assumes data exchangeability, which is often violated in real-world scenarios. Adaptive methods adjust for these shifts, improving the efficiency and reliability of prediction sets. This is crucial because inaccurate assumptions can lead to inefficient prediction sets (e.g., overly large sets or sets that frequently miss the true label). Adaptive techniques typically modify the nonconformity scores or coverage probabilities dynamically to account for the changing data distributions. The goal is to maintain valid coverage probability while improving the efficiency of the prediction sets. Stronger forms of adaptivity, such as strongly adaptive regret, aim to achieve more efficient prediction sets even in scenarios with complex, unpredictable shifts. Several algorithms have been developed to achieve different levels of adaptivity, often leveraging techniques from online learning to dynamically adjust model parameters and/or prediction set sizes.
Multi-Model Ensemble#
The concept of a “Multi-Model Ensemble” in the context of conformal prediction offers a significant advancement. Instead of relying on a single model’s predictions, which can be sensitive to data distribution shifts, this approach leverages the strengths of multiple models. By dynamically selecting the most suitable model ‘on the fly’, it addresses the limitations of fixed-model approaches in dynamic environments. This adaptability is crucial for maintaining prediction accuracy and efficiency when dealing with evolving data distributions. The ensemble nature enhances robustness; even if one model performs poorly under certain conditions, others can compensate. The selection process, described as being ‘on the fly’ suggests an adaptive algorithm, constantly evaluating model performance to optimize prediction set creation. This dynamic model selection is key to the method’s ability to handle unknown distribution shifts in real-world scenarios, making the prediction more efficient and reliable.
Dynamic Regret Bounds#
Dynamic regret bounds, in the context of online conformal prediction, address the challenge of evaluating algorithm performance in dynamic environments where data distributions shift over time. Standard regret measures are insufficient because they assume a fixed distribution. Dynamic regret focuses on the cumulative performance difference between an algorithm’s predictions and the best possible predictions, considering that the optimal strategy might change with every shift in the data distribution. The key difficulty lies in defining a suitable benchmark against which to measure the algorithm’s performance, as the ‘optimal’ prediction set may vary constantly in dynamic settings. A well-defined dynamic regret bound demonstrates an algorithm’s ability to adapt efficiently to such changes, achieving a low cumulative loss despite the non-stationarity of the environment. Strong adaptive regret is a particularly desirable property, guaranteeing sublinear regret regardless of the frequency and magnitude of distribution shifts, ensuring the algorithm efficiently learns and adapts to any pattern of change in the data. The analysis of these bounds often involves sophisticated mathematical techniques, such as analyzing the variation of loss functions or employing online learning techniques. Tight bounds are crucial because they provide strong guarantees on an algorithm’s performance and help compare different algorithms’ adaptive capabilities in dynamic environments.
SAMOCP Algorithm#
The SAMOCP (Strongly Adaptive Multimodel Ensemble Online Conformal Prediction) algorithm is a novel approach to conformal prediction designed for dynamic environments. Its key innovation lies in its dynamic model selection, choosing the best-performing model from an ensemble at each time step, rather than relying on a single fixed model. This addresses the limitations of previous adaptive methods, which often heavily depend on the choice of base model and struggle to adapt to unexpected distribution shifts. SAMOCP incorporates multiple models and updates their weights dynamically based on performance, leading to more efficient prediction sets while maintaining valid coverage. The algorithm’s theoretical foundation is based on achieving strongly adaptive regret, meaning its performance is competitive regardless of the interval size over which regret is measured. Experiments demonstrate SAMOCP’s superior performance, producing consistently more efficient prediction sets than competing methods in various dynamic settings.
Empirical Evaluation#
An empirical evaluation section in a research paper should thoroughly investigate the proposed method’s performance. It should start by clearly defining the metrics used to assess performance, such as accuracy, precision, recall, F1-score, or AUC. The choice of metrics should align with the specific problem and goals. Next, a detailed description of the datasets used for evaluation is critical, including their characteristics (size, distribution, etc.). The experimental setup should be precisely described, including the training and testing procedures, parameter settings, and any preprocessing steps. It is crucial to provide a comprehensive comparison to existing state-of-the-art methods using the same datasets and evaluation metrics. The results should be presented clearly and concisely, possibly through tables and figures, and statistical significance should be demonstrated if appropriate. Finally, the discussion section should analyze the results thoroughly, highlighting successes, limitations, and potential future work. A robust empirical evaluation strengthens the paper’s credibility and impact significantly.
More visual insights#
More on tables

This table presents the performance comparison of different conformal prediction methods on the CIFAR-10C dataset under a sudden distribution shift scenario. The key metrics compared are coverage, average prediction set size (Avg Width), average regret, runtime, and the percentage of single-element prediction sets that correctly contain the true label (Single Width). The results show that SAMOCP outperforms other methods in terms of producing smaller prediction sets, lower regret, and a higher percentage of accurate single-element predictions while maintaining a coverage close to the target of 90%.
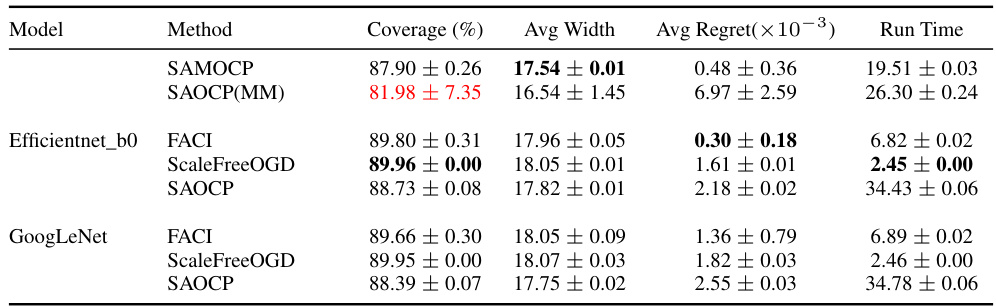
This table presents the performance comparison of different methods (SAMOCP, SAOCP(MM), FACI, ScaleFreeOGD, and SAOCP) on the CIFAR-100C dataset under a gradual distribution shift setting. The key metrics compared are coverage (%), average prediction set width (Avg Width), average regret (×10−3), runtime (Run Time), and the percentage of prediction sets with exactly one element that correctly covers the true label (Single Width). The results show that SAMOCP outperforms the other methods across all metrics, indicating its superior efficiency and accuracy in dynamic environments.
This table presents the performance comparison of different conformal prediction methods on the CIFAR-100C dataset under a gradual distribution shift. The key metrics compared are coverage (percentage of times the true label is included in the prediction set), average width (average size of the prediction sets), average regret (measure of the inefficiency of the prediction sets over time), runtime, and single width (the probability of achieving the smallest, most informative prediction set). The results show that SAMOCP outperforms other methods in terms of average width, average regret and single width, indicating its efficiency and adaptability to dynamic environments.

This table presents the performance comparison of different conformal prediction methods on the CIFAR-100C dataset under a gradual distribution shift scenario. The key metrics compared are coverage (percentage of times the true label is in the predicted set), average width (average size of the prediction set), average regret (how much worse than the best possible prediction set), run time, and single width (how often the prediction set contains only the true label). The results show that the proposed SAMOCP method outperforms existing methods, achieving higher coverage, smaller prediction sets, and lower regret.

This table presents the performance comparison of different conformal prediction methods on the CIFAR-10C dataset under sudden distribution shifts. The metrics used are coverage, average prediction set width, average regret, run time, and the percentage of single-element prediction sets that correctly cover the true label. The results show that SAMOCP outperforms other methods by achieving a smaller average prediction set size, lower average regret, and higher percentage of correct single-width predictions, all while maintaining a coverage close to the target of 90%.

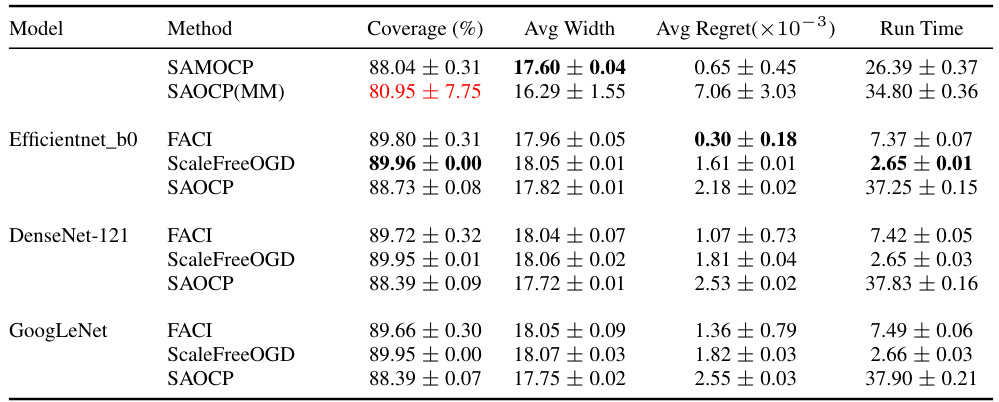
This table presents the results of the experiment conducted on the CIFAR-100C dataset with a gradual distribution shift. It compares the performance of the proposed method, SAMOCP, with several other adaptive conformal prediction methods, including FACI, ScaleFreeOGD, and SAOCP. The metrics used for comparison include coverage (%), average width of the prediction sets, average regret (a measure of efficiency), run time, and the percentage of single-width prediction sets that correctly cover the true label. The results show that SAMOCP consistently outperforms the other methods in terms of average width, regret, and single-width prediction sets while maintaining a coverage close to the target of 90%.

This table compares the performance of MOCP and SAMOCP on the CIFAR-10C dataset under a sudden distribution shift scenario. The goal is to achieve 90% coverage. The table shows the average coverage, average prediction set width (Avg Width), and the average percentage of times the prediction set contained only the correct label (Single Width). Bold numbers highlight the best-performing method for each metric.

This table presents a comparison of the Multi-model Online Conformal Prediction (MOCP) and Strongly Adaptive Multimodel Ensemble Online Conformal Prediction (SAMOCP) methods on the CIFAR-100C dataset under a gradual distribution shift. The goal was to achieve 90% coverage. The table shows the average coverage, average prediction set width (Avg Width), and the percentage of prediction sets containing exactly one element and correctly covering the true label (Single Width) for both methods. The best results for each metric are bolded.
Full paper#