TL;DR#
Domain Generalizable Person Re-identification (DG Re-ID) struggles with inconsistent performance improvements from data augmentation. Some augmentations improve in-domain results but worsen out-of-domain performance, an effect that’s poorly understood. This is because augmentations can create sparse feature spaces lacking uniformity, hindering generalization to unseen data.
The proposed Balancing Alignment and Uniformity (BAU) framework tackles this by balancing alignment and uniformity losses applied to both original and augmented images. A weighting strategy is used to assess augmented sample reliability, further improving alignment. A domain-specific uniformity loss promotes intra-domain uniformity, improving the learning of domain-invariant features. BAU outperforms current methods, demonstrating the effectiveness of its approach to data augmentation and achieving state-of-the-art results.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in domain generalization and person re-identification. It addresses the polarizing effect of data augmentation, a common problem hindering performance. By introducing the BAU framework, it offers a novel, simple solution that significantly improves generalization capabilities, opening up new avenues for research in similar open-set recognition tasks. The state-of-the-art results achieved across various benchmarks highlight its impact.
Visual Insights#

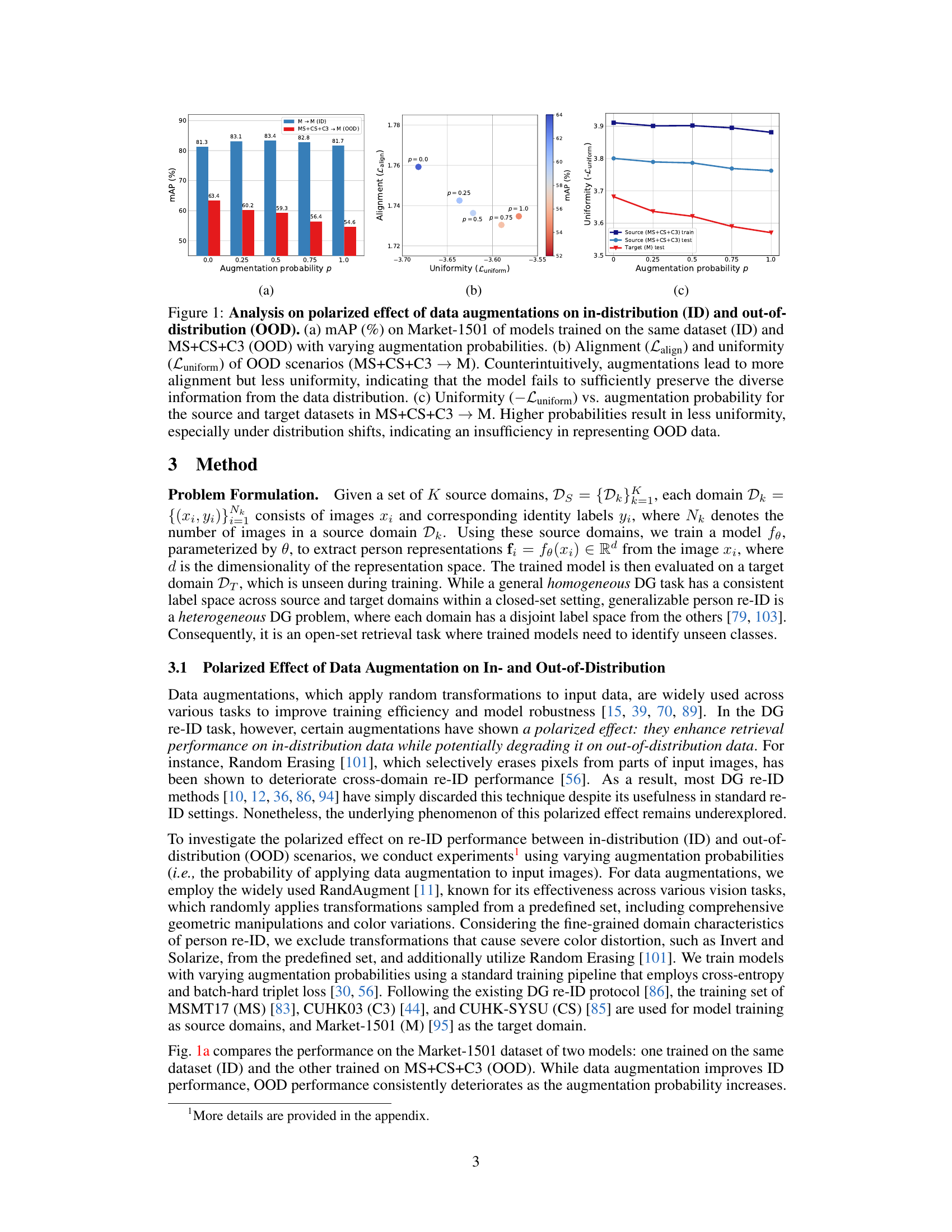
🔼 This figure analyzes the impact of data augmentation on the performance of person re-identification models, specifically focusing on the trade-off between in-distribution (ID) and out-of-distribution (OOD) performance. Subfigure (a) shows that while augmentations improve ID mAP, they negatively affect OOD mAP. Subfigures (b) and (c) reveal the underlying cause: augmentations increase alignment but decrease uniformity in the feature space, indicating a failure to capture diverse data distribution. This lack of uniformity is particularly pronounced in OOD scenarios.
read the caption
Figure 1: Analysis on polarized effect of data augmentations on in-distribution (ID) and out-of-distribution (OOD). (a) mAP (%) on Market-1501 of models trained on the same dataset (ID) and MS+CS+C3 (OOD) with varying augmentation probabilities. (b) Alignment (Lalign) and uniformity (Luniform) of OOD scenarios (MS+CS+C3 → M). Counterintuitively, augmentations lead to more alignment but less uniformity, indicating that the model fails to sufficiently preserve the diverse information from the data distribution. (c) Uniformity (-Luniform) vs. augmentation probability for the source and target datasets in MS+CS+C3 → M. Higher probabilities result in less uniformity, especially under distribution shifts, indicating an insufficiency in representing OOD data.

🔼 This table describes the three evaluation protocols used in the paper. Each protocol defines which datasets are used for training and testing to evaluate the generalizability of the person re-identification models. Protocol 1 uses a large training set and evaluates performance on four smaller datasets, assessing overall generalization. Protocols 2 and 3 follow a leave-one-out strategy to assess domain generalization, holding out one dataset for testing and using the remaining datasets for training. This approach more rigorously evaluates how well the model generalizes to unseen domains.
read the caption
Table 2: Evaluation protocols.
In-depth insights#
Data Aug’s Paradox#
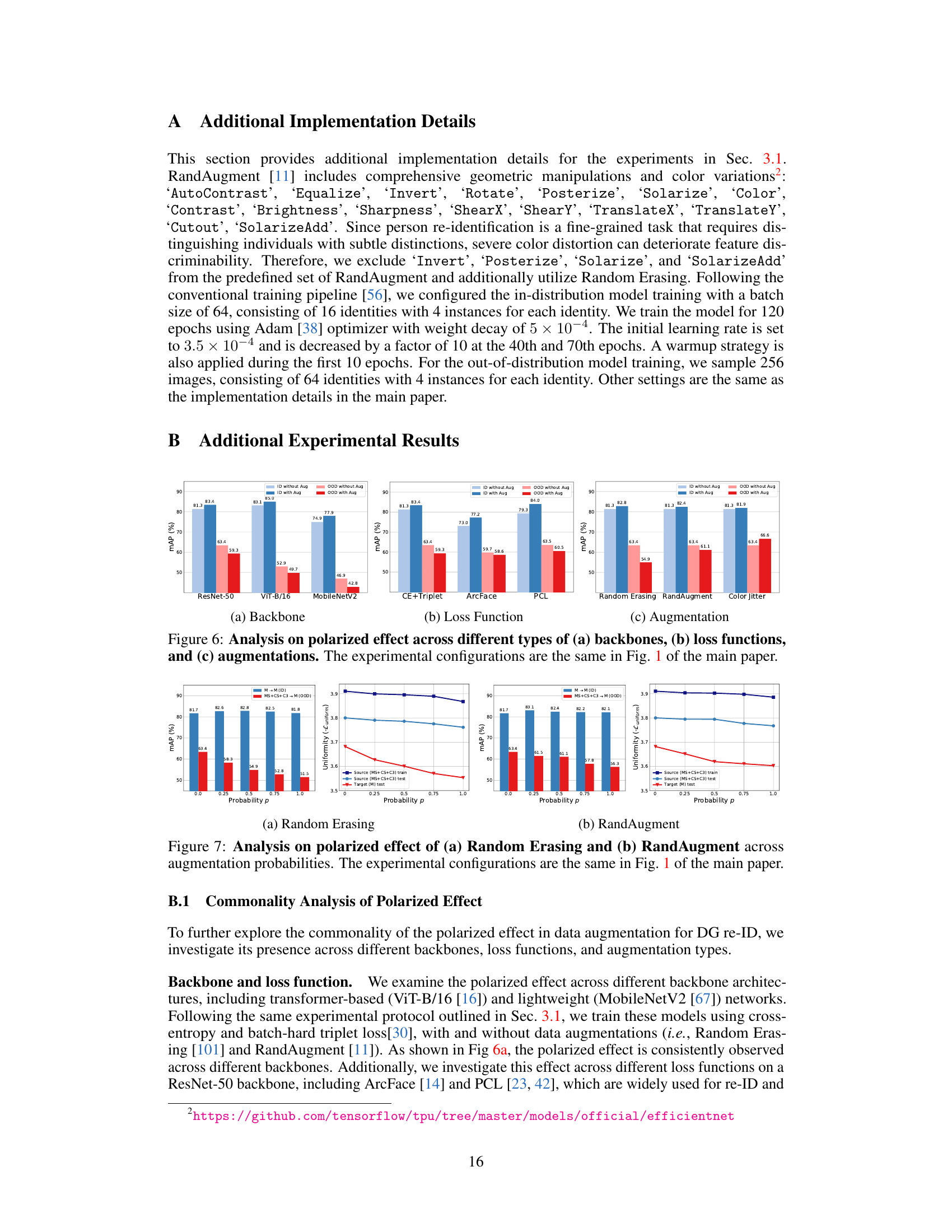
The Data Augmentation Paradox highlights the complex relationship between data augmentation and generalization in person re-identification. While augmentations aim to improve model robustness by increasing training data variability, they can paradoxically hinder generalization, particularly in open-set scenarios. This is because augmentations may polarize model learning, focusing it on readily invariant features rather than capturing the nuanced diversity essential for open-set performance. The resulting sparse representation space lacks the uniformity to handle unseen data effectively. This paradox is further complicated by the fact that certain augmentations, like Random Erasing, are detrimental despite their potential benefits, emphasizing the need for careful consideration and potentially more nuanced approaches to data augmentation in domain generalization tasks. A balanced approach that considers both alignment and uniformity in the representation space, mitigating the polarized effect of augmentations, is crucial for effective domain-generalizable person re-identification.
BAU Framework#
The proposed Balancing Alignment and Uniformity (BAU) framework offers a novel approach to address the limitations of data augmentation in domain-generalizable person re-identification. BAU tackles the issue of the polarized effect of augmentations, where improvements in in-distribution performance are offset by decreased out-of-distribution performance, by explicitly balancing alignment and uniformity in the representation space. This is achieved by applying both alignment and uniformity losses to original and augmented images, thereby mitigating sparse representation spaces. A key innovation is the weighting strategy for the alignment loss, which considers the reliability of augmented samples to improve overall feature discriminability. Further enhancing robustness is the inclusion of a domain-specific uniformity loss, promoting uniformity within each source domain. The combination of these techniques allows BAU to effectively leverage the benefits of data augmentation without requiring complex model architectures or training procedures, leading to state-of-the-art results on various benchmarks.
Alignment & Uniformity#
The concepts of “Alignment” and “Uniformity” are crucial for understanding the performance of data augmentation in domain generalization. Alignment focuses on the similarity of feature representations for similar data points, ensuring that the model learns discriminative features. Uniformity, on the other hand, emphasizes the even distribution of these features across the representation space, preventing overfitting and promoting robustness to unseen data. The paper highlights the polarized effect of augmentations, where increased alignment might come at the cost of reduced uniformity, leading to poor generalization. Therefore, a balanced approach that considers both alignment and uniformity is vital for developing robust and generalizable models in domain adaptation and generalization. This balance is key to overcoming the limitations of using augmentations alone, where over-reliance on invariant features can hinder the ability to learn from diverse visual information.
Domain-Specific Loss#
A domain-specific loss function is crucial for addressing the challenge of domain shift in person re-identification. Standard uniformity losses, while promoting diversity in the feature space, may not sufficiently address domain-specific biases. Features from the same domain might still cluster together, hindering the model’s ability to generalize to unseen domains. A domain-specific loss directly tackles this issue by promoting uniformity within each source domain, thereby explicitly encouraging the learning of domain-invariant features. This is achieved by incorporating a memory bank of prototypes, where each prototype represents a class feature vector. The loss function then encourages uniform distribution of features and prototypes within their corresponding domains. This method effectively reduces domain bias and improves generalization, leading to improved performance on unseen domains, making it a key component in achieving robust and generalizable person re-identification models.
Future of DG ReID#
The future of Domain Generalizable Person Re-Identification (DG ReID) hinges on addressing its current limitations. Improving robustness to extreme domain shifts is crucial, moving beyond current methods which struggle with significant variations in imaging conditions or viewpoints. This requires exploring advanced techniques like unsupervised domain adaptation and self-supervised learning to leverage unlabeled data effectively. Furthermore, research into more sophisticated feature representation learning is needed, possibly incorporating techniques from areas such as transformers or graph neural networks, to capture more invariant and discriminative features. Addressing the computational cost associated with many DG ReID methods is also important for real-world applications, which often necessitate efficient and scalable solutions. Finally, the field would benefit from a deeper understanding and mitigation of potential bias and fairness issues inherent in the data and algorithms themselves, ensuring responsible and equitable development of this technology. This could involve investigating techniques like bias mitigation and explainable AI. In essence, the progress of DG ReID will involve a multifaceted approach encompassing increased robustness, innovative feature learning, efficiency gains, and ethical considerations.
More visual insights#
More on figures
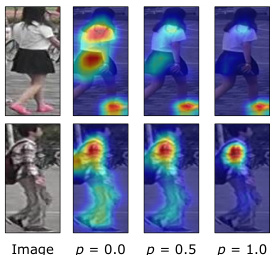
🔼 The figure visualizes Grad-CAM results for different augmentation probabilities (p=0.0, p=0.5, p=1.0) applied to two sample images. Grad-CAM highlights the regions in the images that are most relevant to the model’s predictions. The results show that as the augmentation probability increases, the model focuses increasingly on specific regions, potentially neglecting other important information, which may negatively impact generalization.
read the caption
Figure 2: Grad-CAM [68] across different probabilities of data augmentations.

🔼 This figure illustrates the Balancing Alignment and Uniformity (BAU) framework. It shows how the framework uses both original and augmented images to apply alignment and uniformity losses to balance feature discriminability and generalization. Additionally, a domain-specific uniformity loss is introduced to reduce domain bias. Subfigures (b) and (c) visually explain the effects of the alignment, uniformity, and domain-specific losses on the feature embedding space.
read the caption
Figure 3: Overview of the proposed framework. In (b) and (c), each color represents a different identity and domain, respectively. (a) With original and augmented images, we apply alignment and uniformity losses to balance feature discriminability and generalization capability. We further introduce a domain-specific uniformity loss to mitigate domain bias. (b) Lalign pulls positive features closer, while Luniform pushes all features apart to maintain diversity. (c) Ldomain uniformly distributes each domain’s features and prototypes, reducing domain bias and thus enhancing generalization.
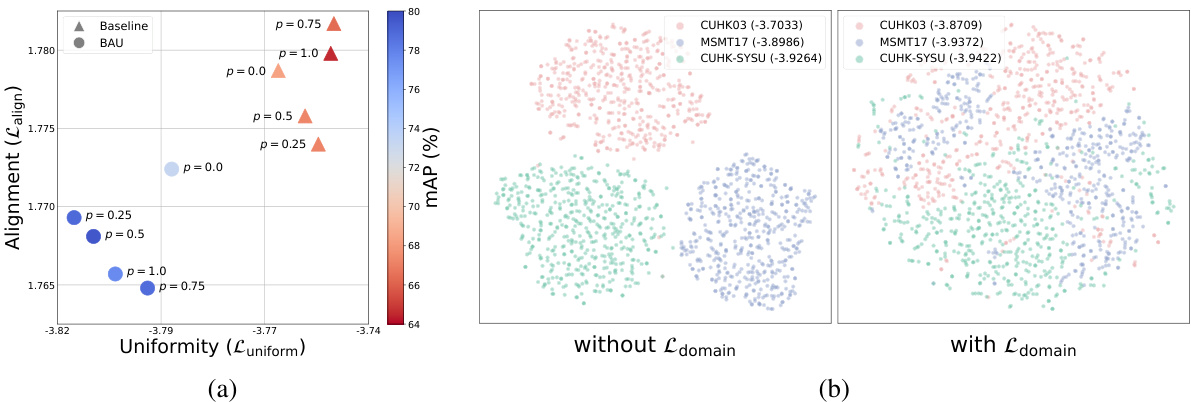
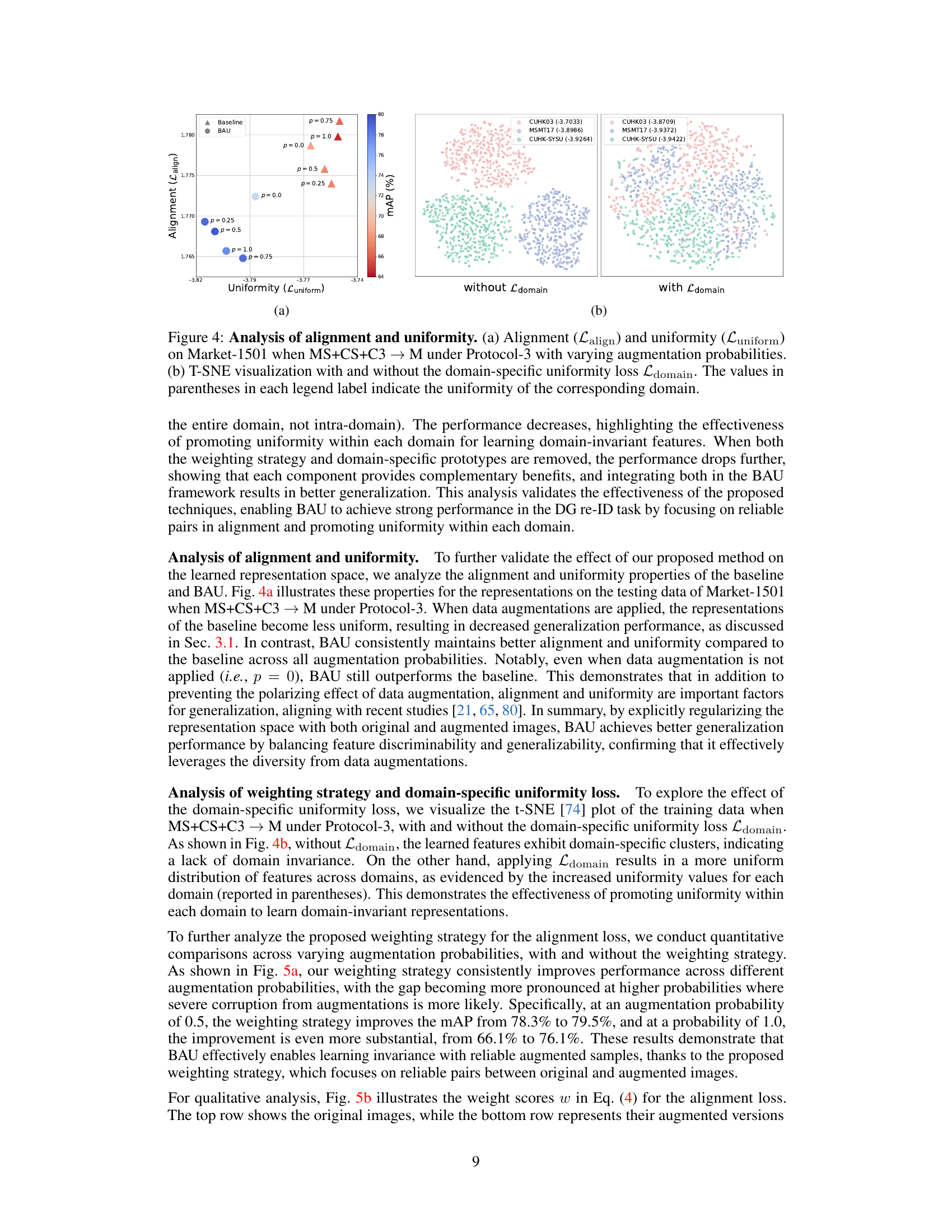
🔼 This figure analyzes the effects of the proposed method (BAU) on the alignment and uniformity of feature representations in the context of person re-identification. Panel (a) shows how alignment and uniformity change with varying augmentation probabilities in an out-of-distribution setting (Market-1501, using data from MSMT17, CUHK03, and CUHK-SYSU for training). It demonstrates that BAU maintains a better balance between alignment and uniformity compared to a baseline, especially when high augmentation probabilities are used. Panel (b) displays t-SNE visualizations of feature embeddings with and without the domain-specific uniformity loss (Ldomain). The visualization highlights that adding Ldomain improves the uniformity of feature distributions, especially across different source domains, thus enhancing the generalization capability of the model.
read the caption
Figure 4: Analysis of alignment and uniformity. (a) Alignment (Lalign) and uniformity (Luniform) on Market-1501 when MS+CS+C3 → M under Protocol-3 with varying augmentation probabilities. (b) T-SNE visualization with and without the domain-specific uniformity loss Ldomain. The values in parentheses in each legend label indicate the uniformity of the corresponding domain.
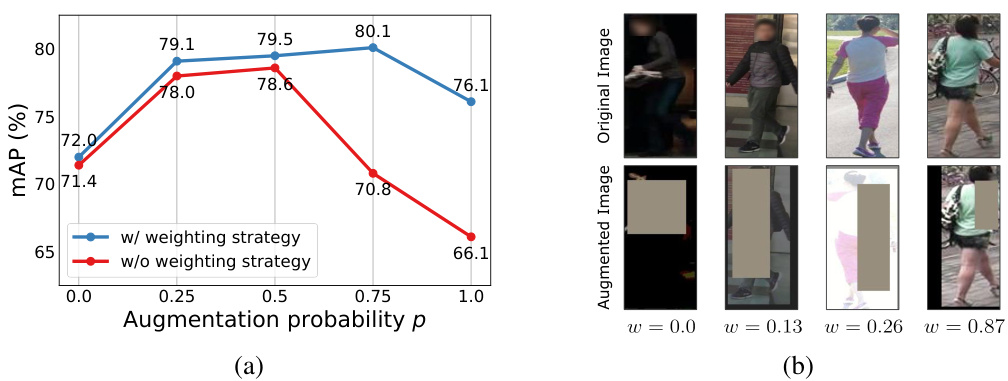
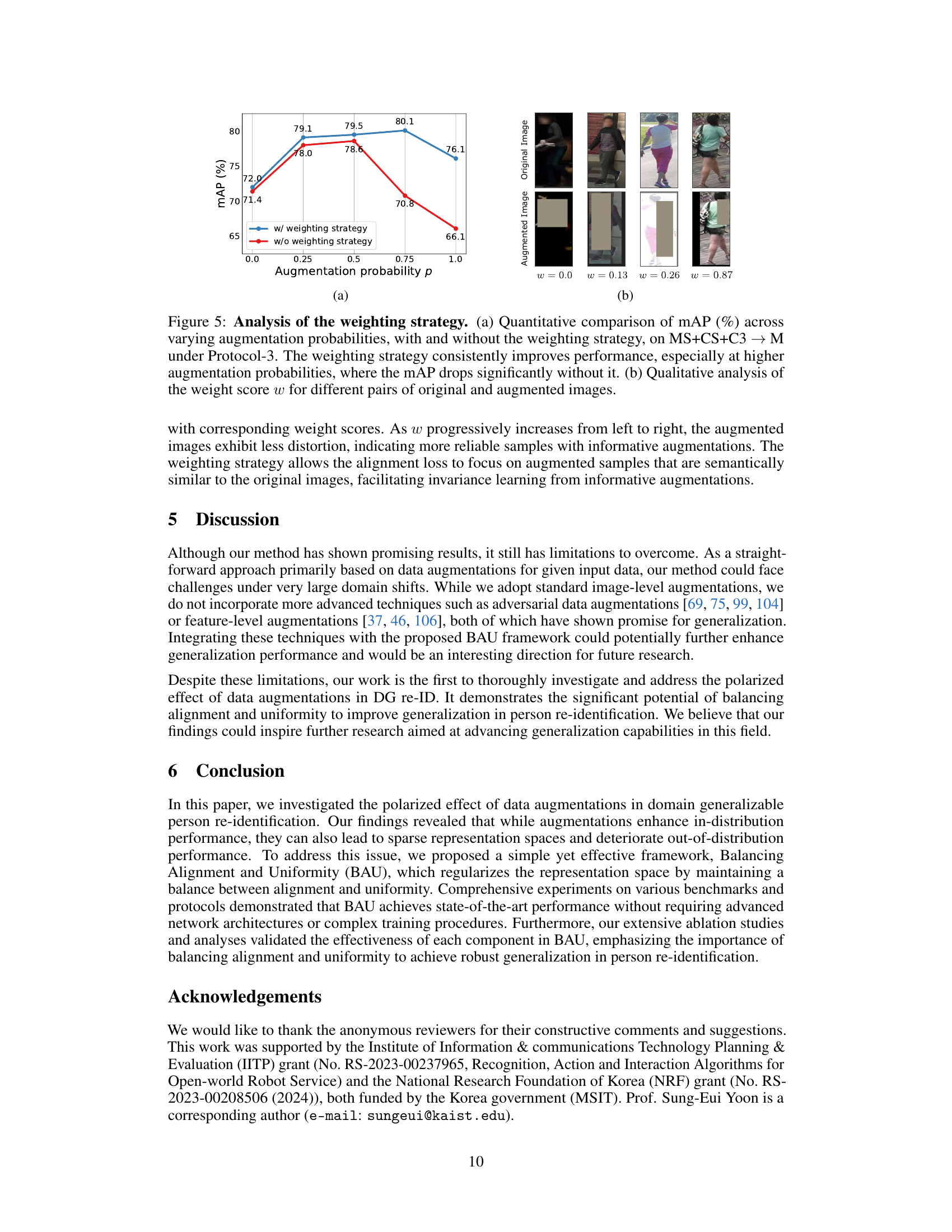
🔼 Figure 5 shows the effect of the weighting strategy for the alignment loss. Subfigure (a) shows a quantitative comparison of the mean average precision (mAP) using different augmentation probabilities with and without the weighting strategy. The results show that the weighting strategy consistently improves the performance, especially when the augmentation probability is high. Subfigure (b) shows a qualitative analysis of the weight scores for different pairs of original and augmented images. This visualization demonstrates how the weighting strategy focuses on augmented samples that are semantically similar to the original images, which improves the model’s ability to learn from informative augmentations.
read the caption
Figure 5: Analysis of the weighting strategy. (a) Quantitative comparison of mAP (%) across varying augmentation probabilities, with and without the weighting strategy, on MS+CS+C3 → M under Protocol-3. The weighting strategy consistently improves performance, especially at higher augmentation probabilities, where the mAP drops significantly without it. (b) Qualitative analysis of the weight score w for different pairs of original and augmented images.
🔼 This figure analyzes the impact of data augmentation on the performance of person re-identification models, specifically focusing on the trade-off between in-distribution (ID) and out-of-distribution (OOD) performance. Subfigure (a) shows that increasing augmentation probability improves ID performance but decreases OOD performance. Subfigures (b) and (c) show that while augmentations improve alignment in feature space, they reduce uniformity, which is detrimental to generalisation. This suggests that data augmentation can have a polarized effect; improving ID performance while hurting OOD.
read the caption
Figure 1: Analysis on polarized effect of data augmentations on in-distribution (ID) and out-of-distribution (OOD). (a) mAP (%) on Market-1501 of models trained on the same dataset (ID) and MS+CS+C3 (OOD) with varying augmentation probabilities. (b) Alignment (Lalign) and uniformity (Luniform) of OOD scenarios (MS+CS+C3 → M). Counterintuitively, augmentations lead to more alignment but less uniformity, indicating that the model fails to sufficiently preserve the diverse information from the data distribution. (c) Uniformity (-Luniform) vs. augmentation probability for the source and target datasets in MS+CS+C3 → M. Higher probabilities result in less uniformity, especially under distribution shifts, indicating an insufficiency in representing OOD data.

🔼 This figure analyzes the impact of data augmentation on the performance of person re-identification models, particularly focusing on the trade-off between in-distribution and out-of-distribution performance. Subfigure (a) shows that increasing augmentation probability improves in-distribution mAP but reduces out-of-distribution mAP. Subfigures (b) and (c) show that increased augmentation probability leads to higher alignment but lower uniformity in the feature representation space, highlighting that simply increasing augmentation doesn’t guarantee better generalization; rather, it can lead to an overemphasis on in-distribution features at the expense of out-of-distribution features.
read the caption
Figure 1: Analysis on polarized effect of data augmentations on in-distribution (ID) and out-of-distribution (OOD). (a) mAP (%) on Market-1501 of models trained on the same dataset (ID) and MS+CS+C3 (OOD) with varying augmentation probabilities. (b) Alignment (Lalign) and uniformity (Luniform) of OOD scenarios (MS+CS+C3 → M). Counterintuitively, augmentations lead to more alignment but less uniformity, indicating that the model fails to sufficiently preserve the diverse information from the data distribution. (c) Uniformity (-Luniform) vs. augmentation probability for the source and target datasets in MS+CS+C3 → M. Higher probabilities result in less uniformity, especially under distribution shifts, indicating an insufficiency in representing OOD data.
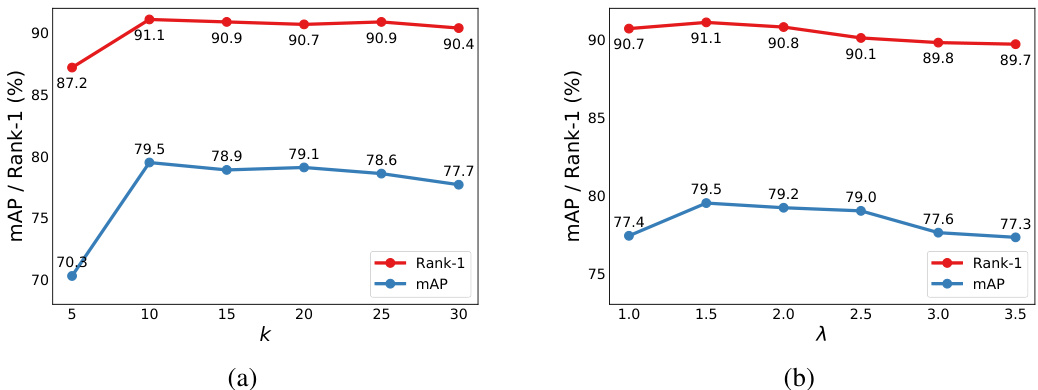
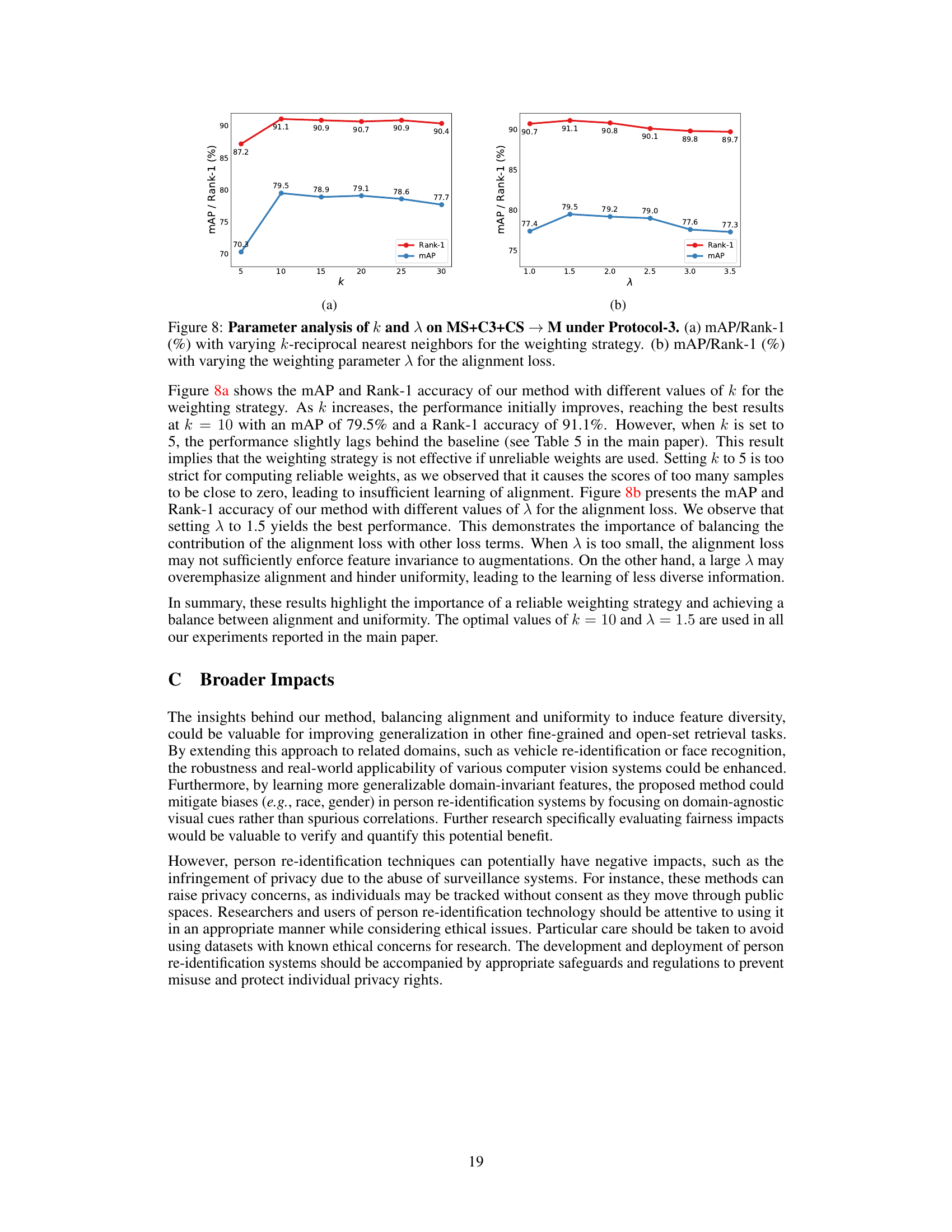
🔼 This figure shows the result of parameter analysis for the weighting strategy (k) and the alignment loss (λ) under Protocol-3. The left subplot (a) shows how changing the number of k-reciprocal nearest neighbors affects the model’s performance (mAP and Rank-1 accuracy). The right subplot (b) shows the same performance metrics, but this time in response to changes in the weighting parameter (λ) for the alignment loss. Optimal values for k and λ are determined through this analysis.
read the caption
Figure 8: Parameter analysis of k and λ on MS+C3+CS → M under Protocol-3. (a) mAP/Rank-1 (%) with varying k-reciprocal nearest neighbors for the weighting strategy. (b) mAP/Rank-1 (%) with varying the weighting parameter λ for the alignment loss.
More on tables
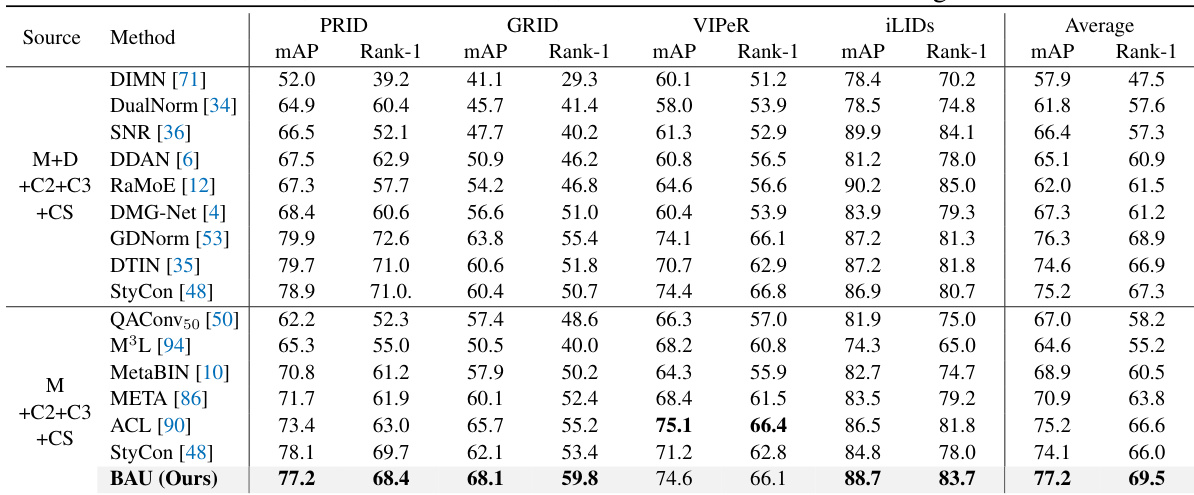
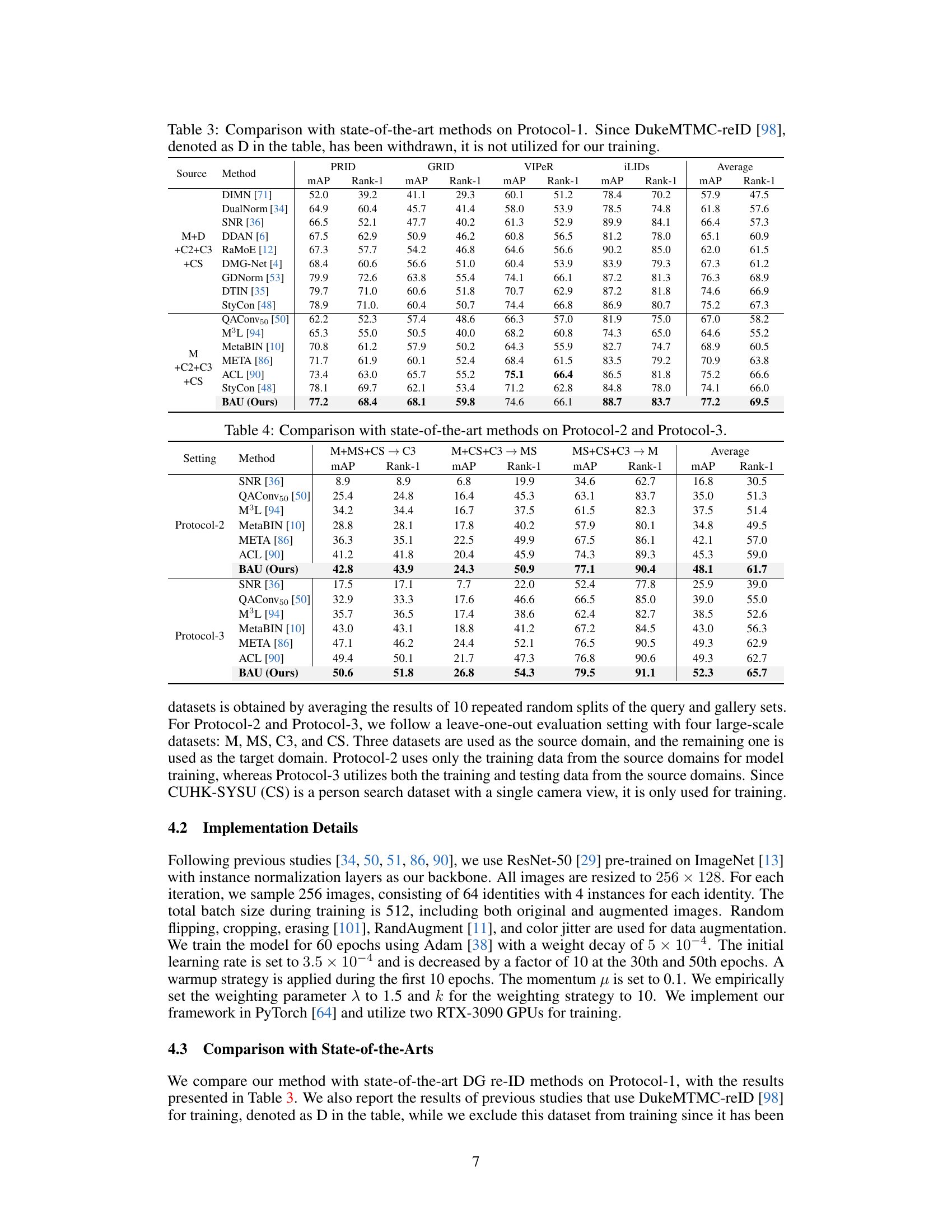
🔼 This table compares the proposed method (BAU) against various state-of-the-art methods for person re-identification on Protocol-1. Protocol-1 uses a full training set composed of Market-1501, MSMT17, CUHK02, CUHK03, and CUHK-SYSU datasets and evaluates the performance on four smaller-scale datasets: PRID, GRID, VIPeR, and iLIDs. The table shows the mAP (mean Average Precision) and Rank-1 accuracy for each method on each dataset, along with an average performance across all four datasets. The results demonstrate that BAU outperforms previous state-of-the-art methods, particularly in terms of average performance.
read the caption
Table 3: Comparison with state-of-the-art methods on Protocol-1. Since DukeMTMC-reID [98], denoted as D in the table, has been withdrawn, it is not utilized for our training.

🔼 This table presents a comparison of the proposed BAU method against other state-of-the-art methods on two different protocols (Protocol-2 and Protocol-3) for domain generalized person re-identification. Protocol-2 uses a leave-one-out evaluation strategy where three datasets serve as the source domain and the remaining one serves as the target domain. Protocol-3 is similar but uses both training and testing data from the source domains for model training. The table shows the mean average precision (mAP) and rank-1 accuracy for each method across the different experimental settings, highlighting the superior performance of BAU.
read the caption
Table 4: Comparison with state-of-the-art methods on Protocol-2 and Protocol-3.
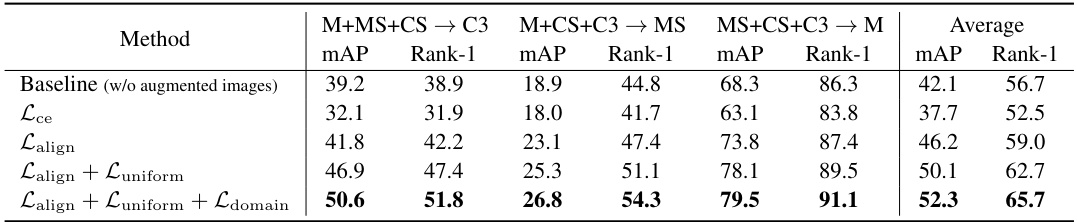
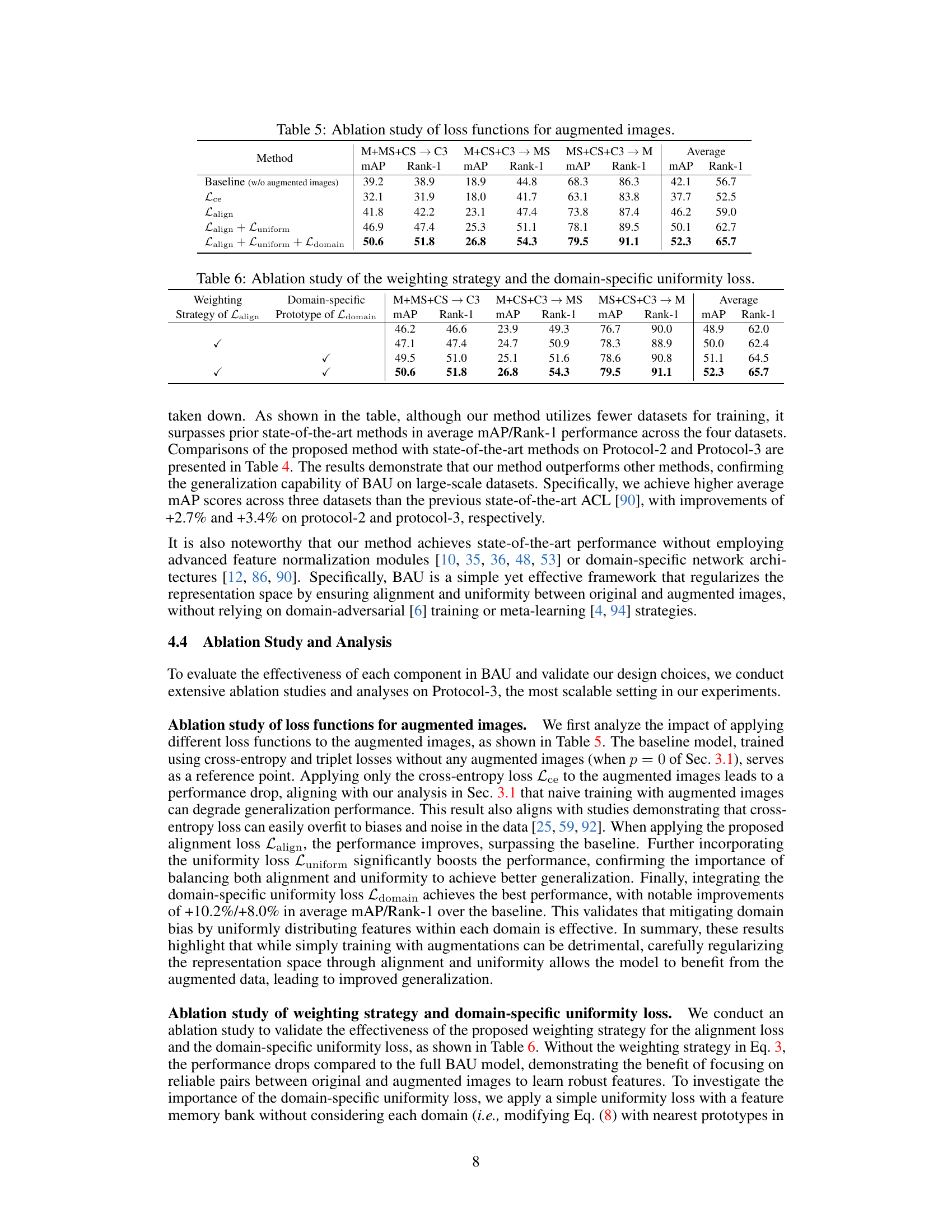
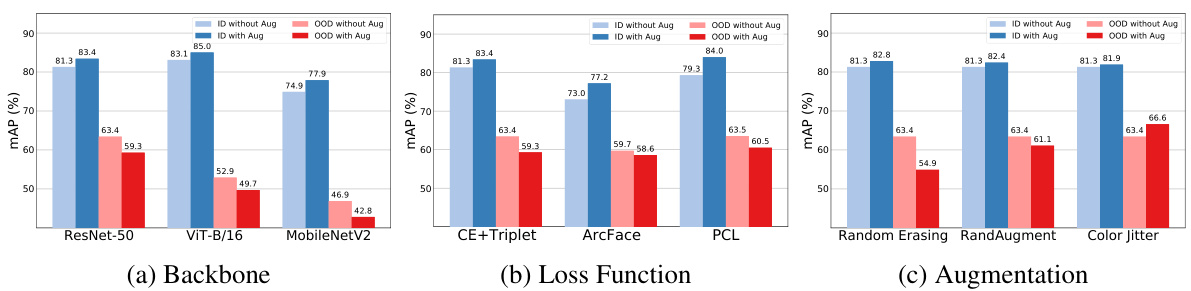
🔼 This ablation study investigates the impact of applying different loss functions (alignment loss, uniformity loss, and domain-specific uniformity loss) to augmented images on the model’s performance. The results demonstrate that incorporating these losses, particularly the domain-specific uniformity loss, improves the model’s ability to generalize to unseen domains. The baseline is a model trained without using any augmented images. The table shows mAP and Rank-1 accuracy for three different settings, in which a different dataset is used for target domain testing. The average is also computed across the three settings.
read the caption
Table 5: Ablation study of loss functions for augmented images.

🔼 This table presents the ablation study results focusing on two specific components of the proposed BAU framework: the weighting strategy for the alignment loss and the domain-specific uniformity loss. It shows the performance (mAP and Rank-1) on three different cross-domain person re-identification protocols (M+MS+CS → C3, M+CS+C3 → MS, and MS+CS+C3 → M) by systematically removing either the weighting strategy, the domain-specific prototype, or both. The results demonstrate the individual and combined contributions of these components to the overall performance improvement.
read the caption
Table 6: Ablation study of the weighting strategy and the domain-specific uniformity loss.
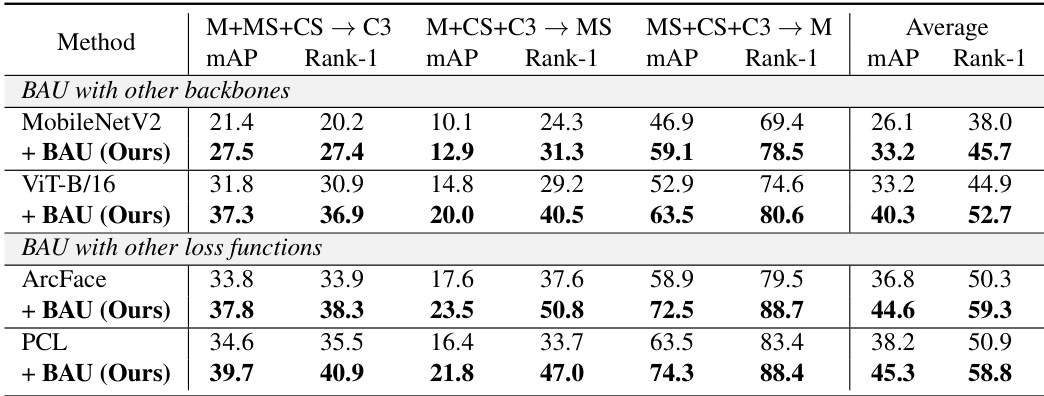
🔼 This table presents the results of experiments conducted to evaluate the effectiveness of the proposed BAU framework using different backbone architectures (MobileNetV2 and ViT-B/16) and loss functions (ArcFace and PCL). Protocol-2 is a leave-one-out evaluation with four large-scale datasets. The table shows the mAP and Rank-1 accuracy for each backbone and loss function combination, both with and without the BAU framework, across three different training-testing domain splits. The results demonstrate the generalization capability of BAU across different network architectures and loss functions, showing consistent improvements in performance with BAU.
read the caption
Table 7: Evaluation of BAU with other backbones and loss functions on Protocol-2.
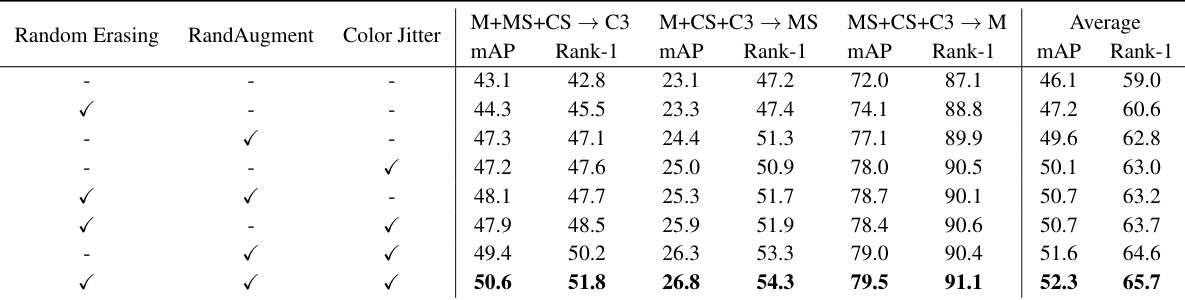
🔼 This table presents the results of an ablation study conducted on Protocol 3 to evaluate the impact of different data augmentation techniques on the model’s generalization performance. The study examines the effects of using Random Erasing, RandAugment, and Color Jitter, both individually and in combination. The results show the mAP and Rank-1 accuracy for each augmentation strategy across three different experimental settings (M+MS+CS → C3, M+CS+C3 → MS, and MS+CS+C3 → M), providing a comprehensive evaluation of their effectiveness on improving generalization.
read the caption
Table 8: Ablation study of data augmentations on Protocol-3.
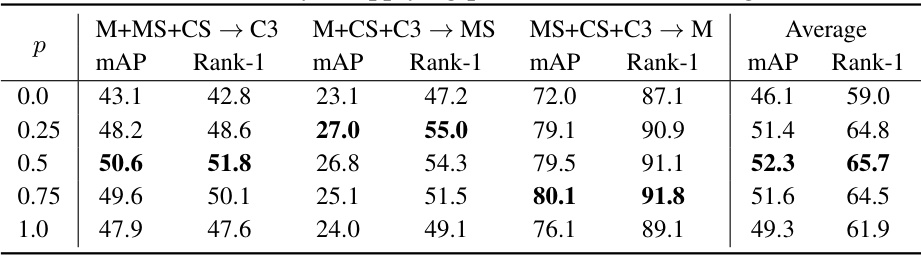
🔼 This table presents the results of an ablation study that investigates the impact of different data augmentation techniques on the generalization performance of the proposed method using Protocol-3. It shows the average mAP and Rank-1 accuracy for different combinations of Random Erasing, RandAugment, and Color Jitter augmentations, highlighting the effect of each augmentation on the model’s ability to generalize to unseen domains.
read the caption
Table 8: Ablation study of data augmentations on Protocol-3.
Full paper#