↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
3D object detection, vital for autonomous driving, struggles with domain shift—models trained in one area may fail in another due to differences in object sizes, LiDAR point density, and sensor angles. This leads to inaccurate bounding boxes, impacting safety and reliability. Existing solutions often involve complex retraining procedures.
DiffuBox offers a novel solution: a diffusion model refines initial bounding boxes by analyzing the LiDAR points around them. This is a domain-agnostic method, meaning it works across various datasets without retraining, significantly improving localization accuracy for various datasets and object types. The results highlight substantial improvements, especially for near-range objects where more LiDAR point information is available. This method provides improved accuracy and robustness for 3D object detection systems in real-world scenarios.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the significant problem of domain shift in 3D object detection, a crucial task for autonomous driving and robotics. The proposed method, DiffuBox, offers a novel and effective solution by using a diffusion model to refine bounding boxes, showing improvements across diverse datasets and object classes. This work opens avenues for more robust and reliable 3D object detection systems, improving the safety and reliability of autonomous vehicles.
Visual Insights#
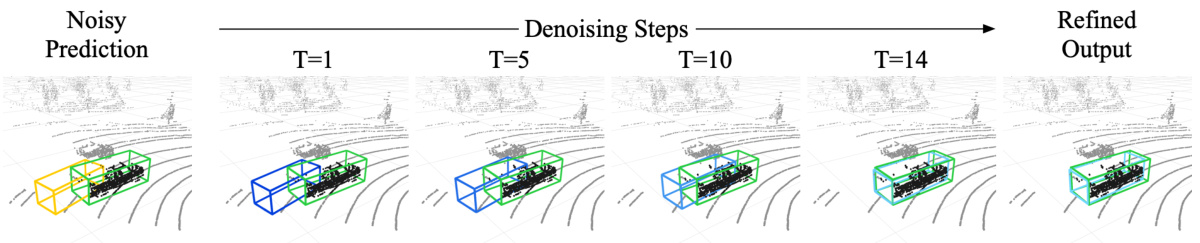
This figure shows how DiffuBox refines a noisy bounding box prediction iteratively. The initial noisy prediction (yellow) is progressively refined (blue boxes) through a series of denoising steps guided by the surrounding LiDAR points and the ground truth box (green). The final refined output is a more accurate bounding box, demonstrating the method’s ability to correct localization errors.
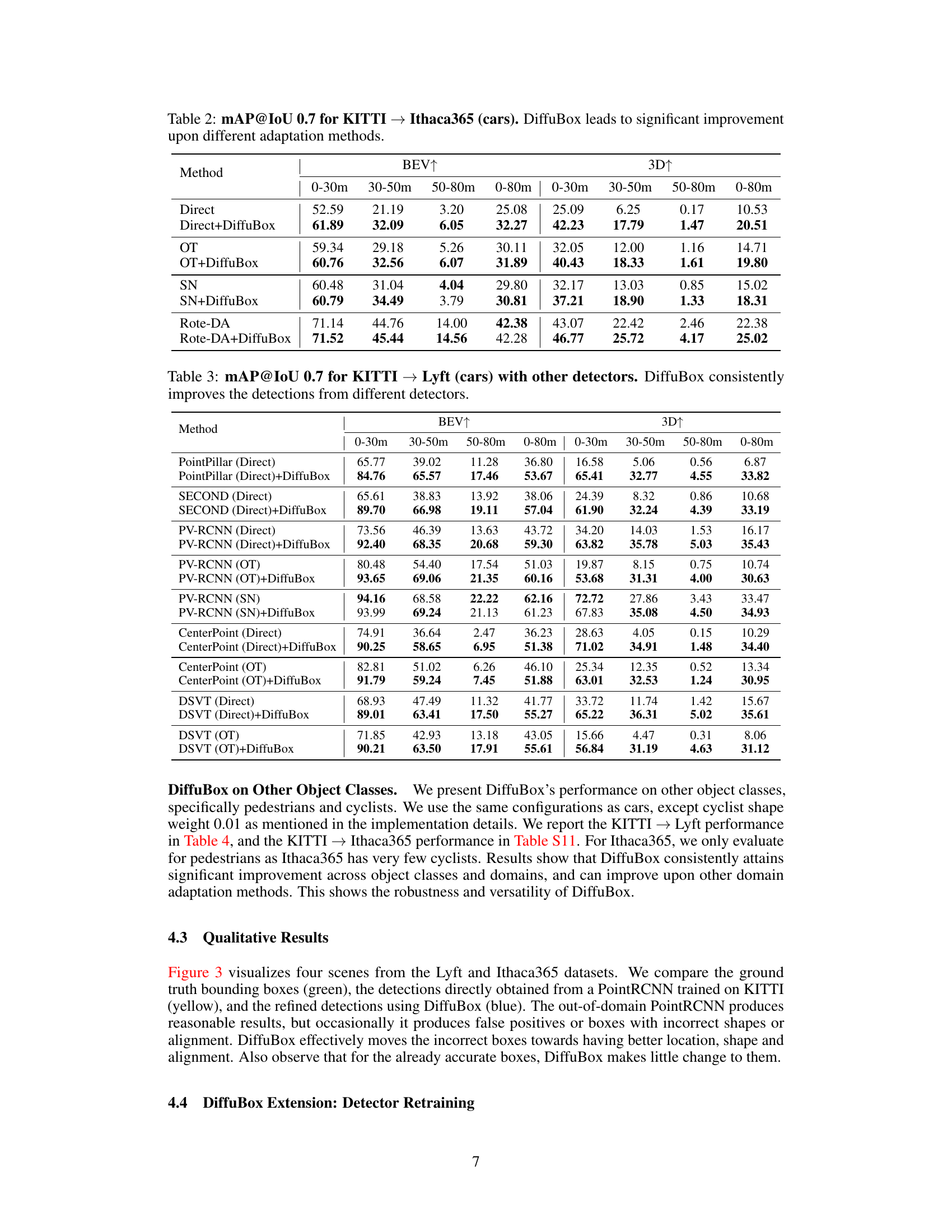
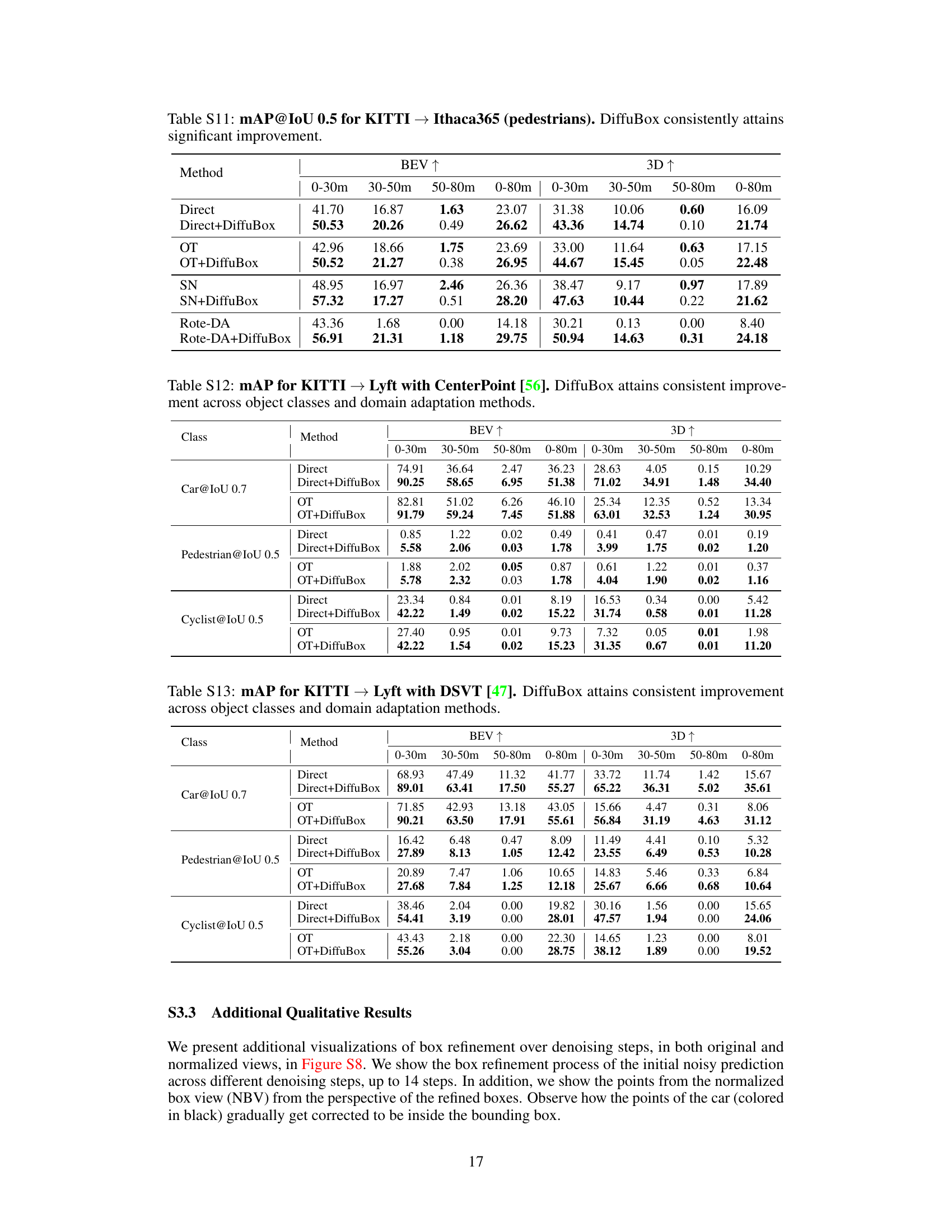
This table presents the mean Average Precision (mAP) at Intersection over Union (IoU) threshold of 0.7 for the task of car detection on the Lyft dataset, using models initially trained on the KITTI dataset. It compares the performance of various domain adaptation methods (Direct, OT, SN, Rote-DA, ST3D) with and without the proposed DiffuBox method. The results are broken down by distance ranges (0-30m, 30-50m, 50-80m, and 0-80m) and viewing perspective (BEV and 3D). Higher mAP values indicate better performance.
In-depth insights#
DiffuBox: 3D Refinement#
DiffuBox presents a novel approach to enhance 3D object detection by refining initial bounding box predictions using a diffusion model. This refinement process is domain-agnostic, meaning it can adapt to diverse datasets without retraining. DiffuBox leverages the spatial distribution of LiDAR points relative to the bounding box, which remains consistent across various domains despite differences in object scales and sensor setups. This scale-invariant approach is achieved by normalizing the LiDAR point cloud into a normalized box view (NBV), eliminating object size priors and enabling the model to focus solely on shape information. The diffusion model then refines the noisy bounding boxes through a denoising process, leading to improved localization accuracy. The effectiveness of DiffuBox is demonstrated through extensive experimental results on multiple datasets, showing significant improvements across various scenarios, detector types and domain adaptation techniques. This scale-invariant and domain-agnostic refinement represents a substantial advance in robust 3D object detection.
Diffusion Model Use#
The research leverages diffusion models for a novel approach to 3D object detection refinement. Instead of training a new model from scratch, the authors utilize a pre-trained diffusion model to refine noisy bounding box predictions from existing detectors. This is a key strength as it avoids the computational cost and potential overfitting of training a new model. The diffusion model is applied to a normalized box view of the LiDAR data, which makes the refinement process more robust to domain shifts caused by differences in object size. The use of a point cloud diffusion model is particularly advantageous because it naturally handles the spatial nature of the LiDAR point cloud. This allows the model to capture fine-grained geometric details for accurate bounding box adjustments. The method’s ability to refine detections without explicit domain-specific training is a significant contribution. However, limitations exist; the approach’s effectiveness relies on the quality of initial bounding box predictions, and additional exploration might be needed to address scenarios with high rates of false negatives.
Domain Adaptation#
Domain adaptation in 3D object detection addresses the challenge of model generalization across different environments. Existing models often struggle to maintain accuracy when tested on datasets with varying sensor setups, geographic locations, or object characteristics. This is due to the domain shift problem where the training and testing data distributions differ significantly. The core issue is that models learn domain-specific biases, such as object size or point cloud density, limiting their ability to adapt to unseen domains. Effective domain adaptation techniques are crucial for robust and reliable 3D object detection in real-world applications like autonomous driving and robotics. Addressing this challenge requires strategies that either make models invariant to domain-specific characteristics or allow models to learn domain-invariant representations. These methods are critical to improving the safety and dependability of autonomous systems.
Experimental Results#
The Experimental Results section of a research paper is crucial for validating the claims made in the introduction and demonstrating the effectiveness of the proposed method. A strong Experimental Results section should present a comprehensive evaluation of the method’s performance, including various metrics, datasets, and comparisons with baseline approaches. Careful consideration should be given to choosing relevant metrics that effectively capture the strengths and weaknesses of the method. Furthermore, a diverse range of datasets strengthens the generalizability claims. The comparison with baselines establishes the novelty and improvement provided by the proposed method. A clear presentation of results, possibly via tables or graphs, is essential for easy interpretation and understanding of the findings. Statistical significance tests, while not always mandatory, should be applied where appropriate to substantiate the results’ reliability. Finally, a well-written conclusion should summarize the key findings and provide insights into the implications of the results, along with suggestions for future research, highlighting limitations or potential improvements.
Future Work#
The ‘Future Work’ section of a research paper on 3D object detection using point cloud diffusion models could explore several promising avenues. Extending DiffuBox to handle false negatives resulting from completely missed objects is crucial. This could involve incorporating exploration strategies or refining detectors using DiffuBox’s output. Another key area is leveraging DiffuBox for automatic label refinement. This would address misaligned bounding boxes or inconsistencies arising from multi-sensor data. Investigating the impact of noise level and diffusion steps on refinement accuracy is important. This requires systematic analysis, potentially revealing optimal settings for different datasets and object classes. Finally, exploring other applications of the point cloud diffusion model beyond object detection, such as segmentation or scene completion, would demonstrate its broader utility and potentially unlock new capabilities. Addressing these points will strengthen the methodology and broaden the impact of the research.
More visual insights#
More on figures
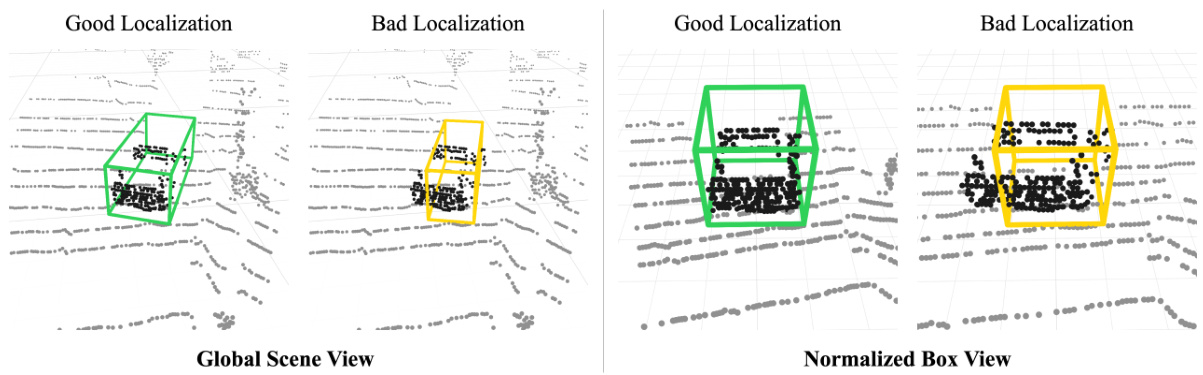
This figure shows the effect of converting car objects from a global scene view to a normalized box view (NBV). The conversion eliminates the size prior by transforming the bounding box into a [-1,1]³ cube, making the point cloud distribution relative to the box instead of in absolute measure. The figure highlights that foreground LiDAR points clustered tightly inside the [-1,1]³ NBV cube are indicative of good bounding box localization, regardless of the domain.
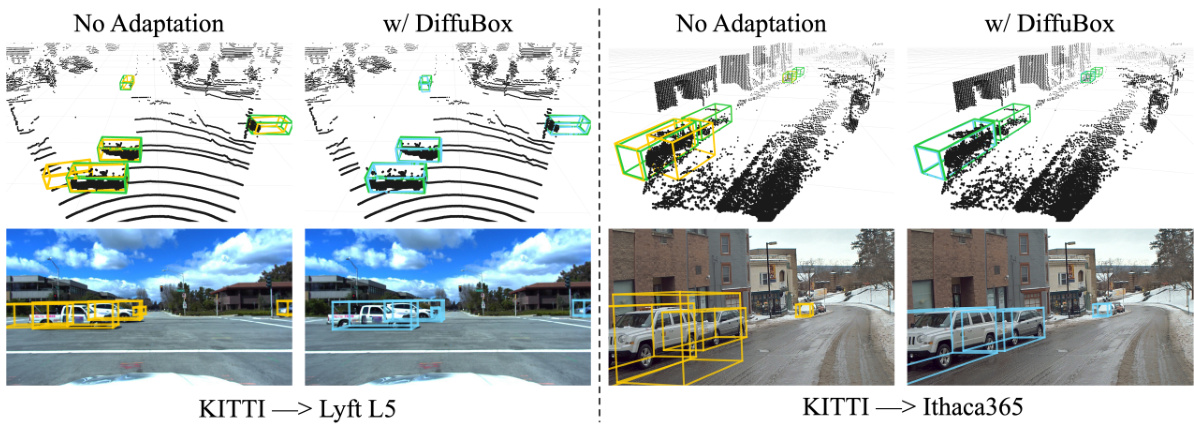
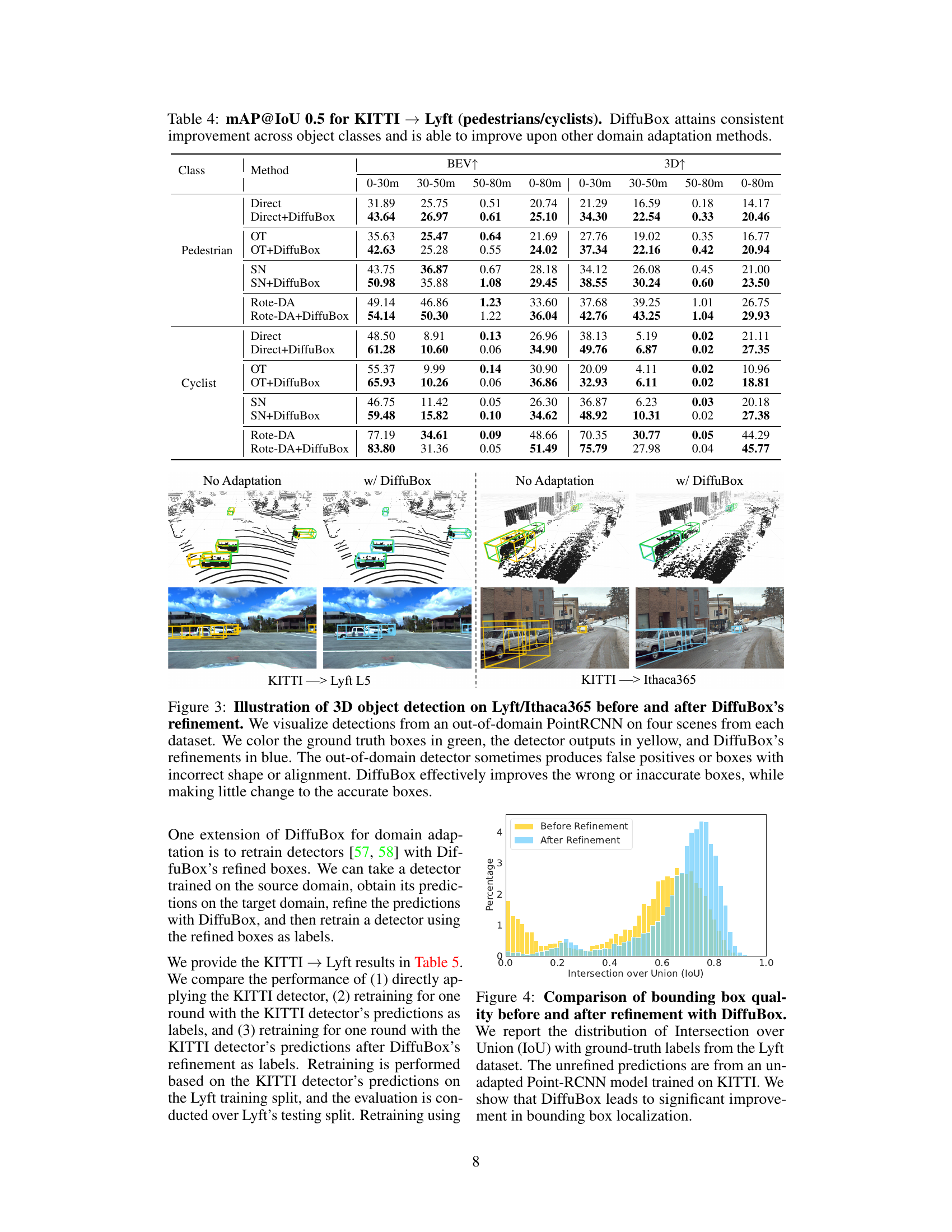
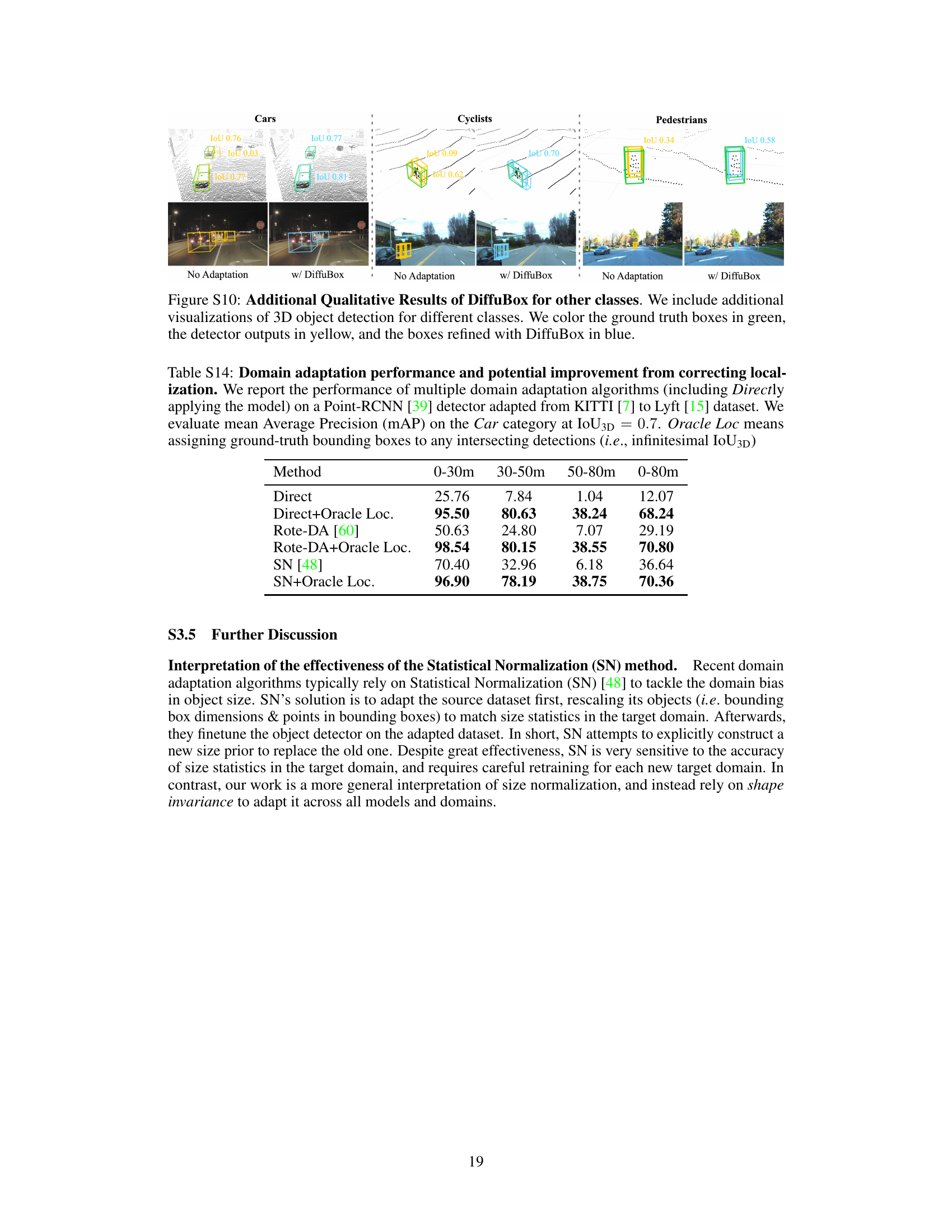
This figure shows a comparison of 3D object detection results on the Lyft and Ithaca365 datasets before and after applying the DiffuBox refinement method. The top row displays point cloud visualizations, while the bottom row shows the corresponding image perspectives. Ground truth bounding boxes are green, initial detector outputs are yellow, and DiffuBox refined boxes are light blue. The figure highlights how DiffuBox corrects mislocalized or mis-shaped bounding boxes while leaving correctly localized ones largely unchanged.

This figure shows the distribution of Intersection over Union (IoU) scores for bounding boxes before and after refinement using DiffuBox. The data is from the Lyft dataset, and the unrefined predictions are from a PointRCNN model trained only on KITTI data. The significant shift towards higher IoU scores after DiffuBox refinement demonstrates the method’s effectiveness in improving the accuracy of bounding box localization.
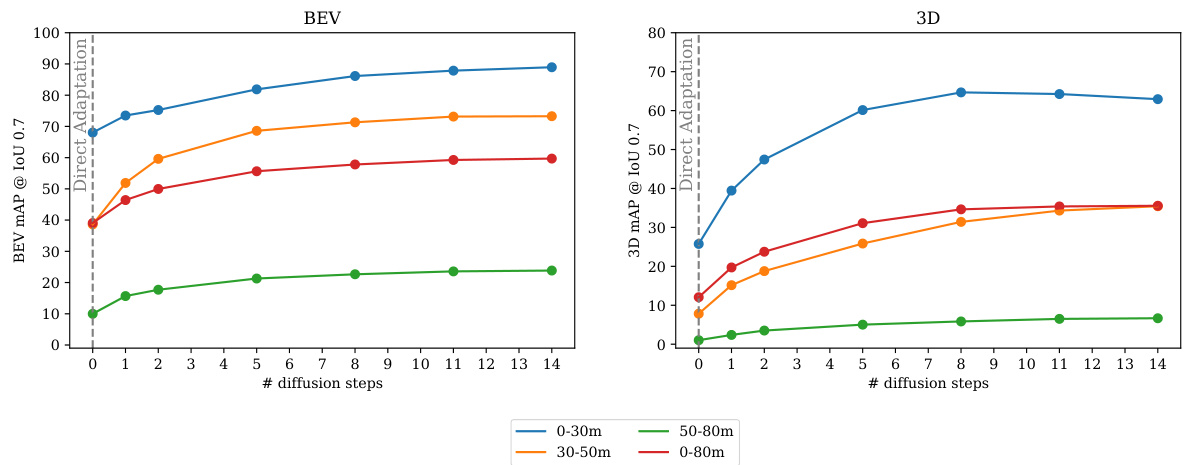
This figure shows the relationship between the number of diffusion steps used in DiffuBox and the resulting mean Average Precision (mAP) at Intersection over Union (IoU) threshold of 0.7. The left panel shows the Bird’s Eye View (BEV) mAP, while the right panel shows the 3D mAP. Both plots show mAP values for different distance ranges (0-30m, 30-50m, 50-80m, and 0-80m). The results demonstrate that the model’s performance improves as the number of diffusion steps increases, eventually reaching a plateau.
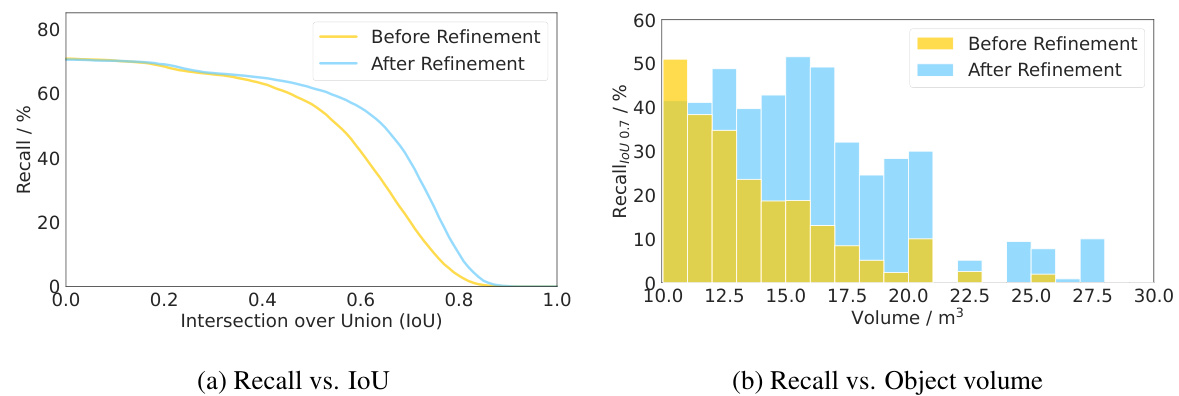
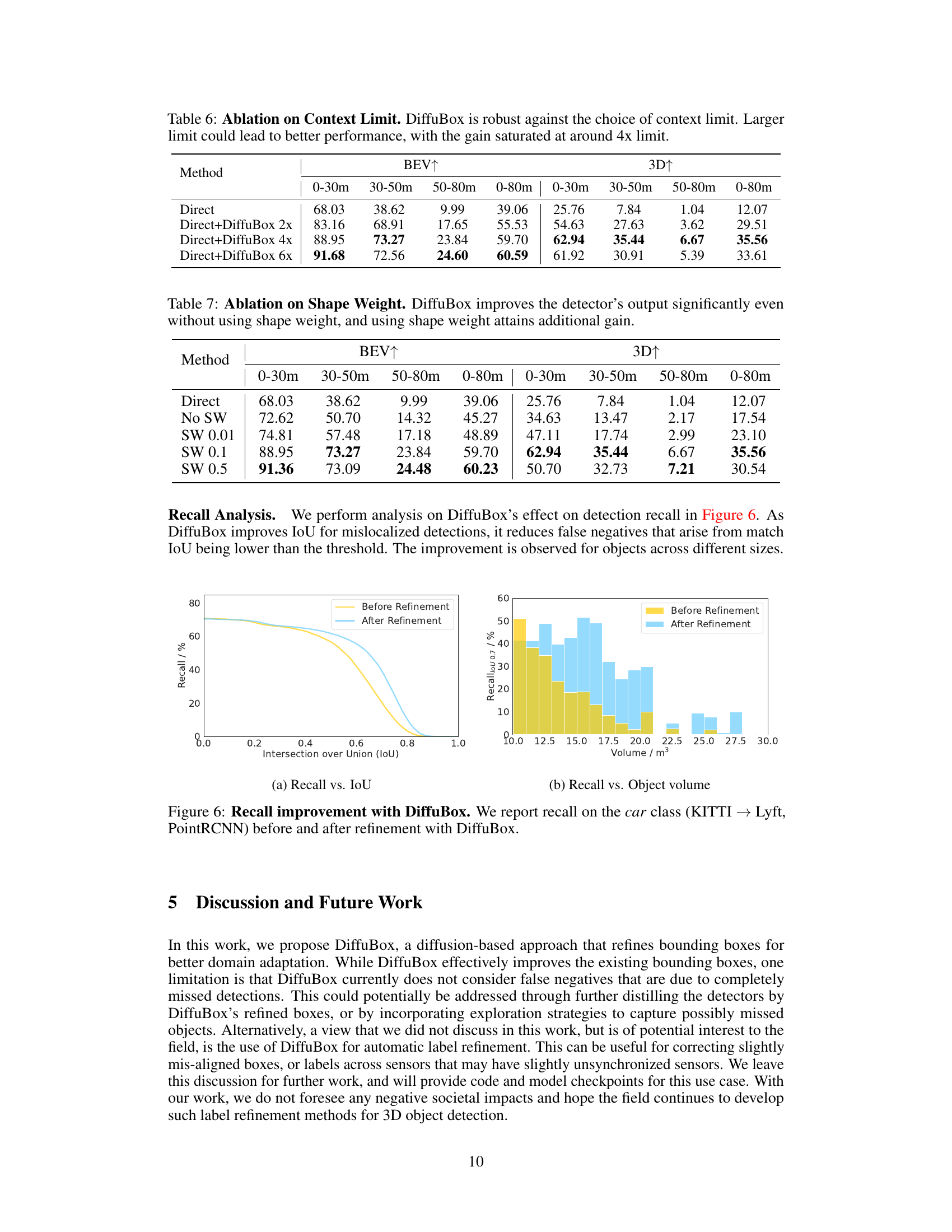
This figure presents a recall analysis of DiffuBox’s effect on detection recall. It shows that by improving the Intersection over Union (IoU) for mislocalized detections, DiffuBox reduces the number of false negatives. This improvement is observed across various object sizes. The figure includes two subplots: (a) Recall vs. IoU and (b) Recall vs. Object volume.

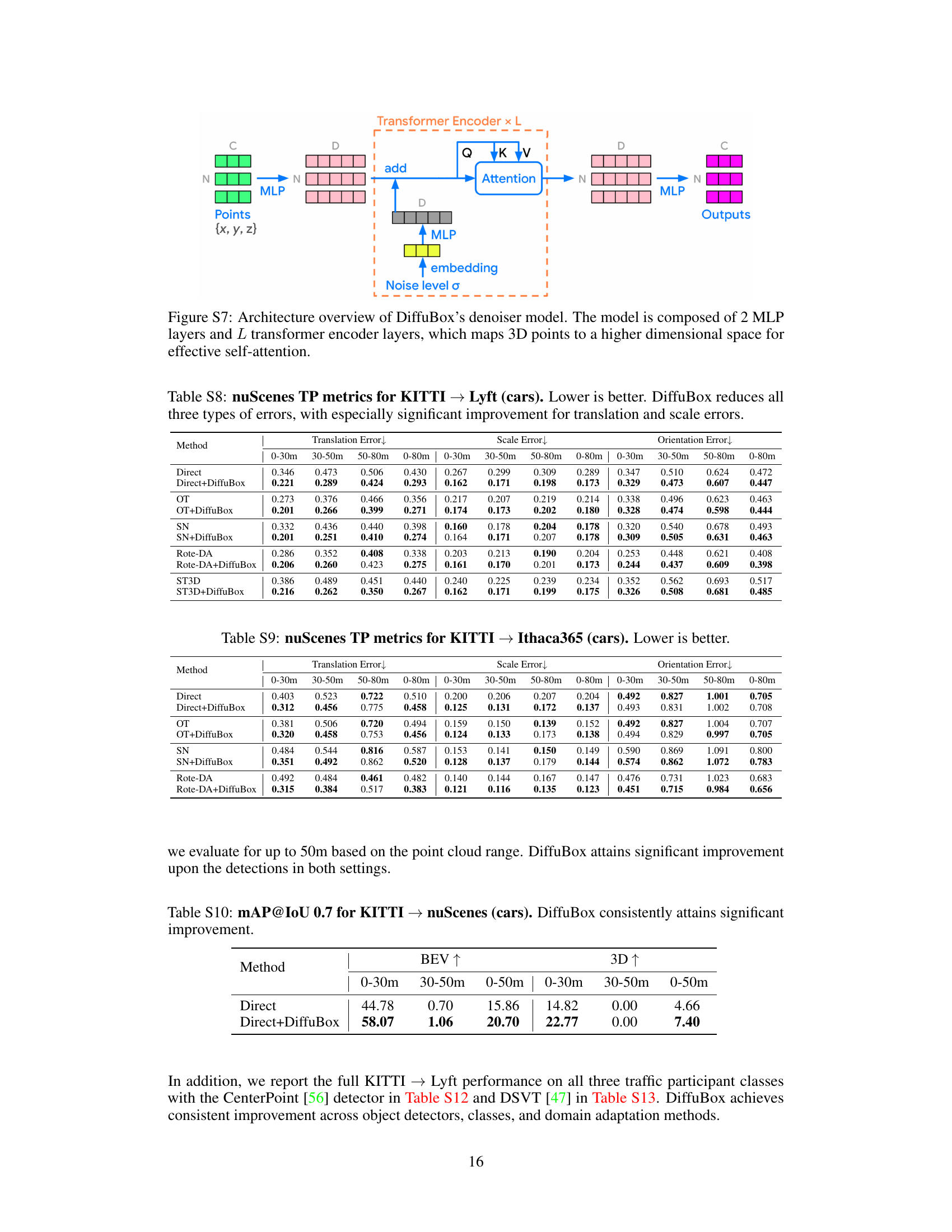
The figure shows a detailed architecture of DiffuBox’s denoising model. It uses a combination of Multi-Layer Perceptrons (MLPs) and a Transformer encoder with L layers. The input is a set of 3D points representing the point cloud relative to a bounding box. These points are initially processed by an MLP, then fed into the transformer encoder which uses self-attention. The output of the transformer is again passed through an MLP to generate the final output. A noise level embedding is also incorporated into the model.
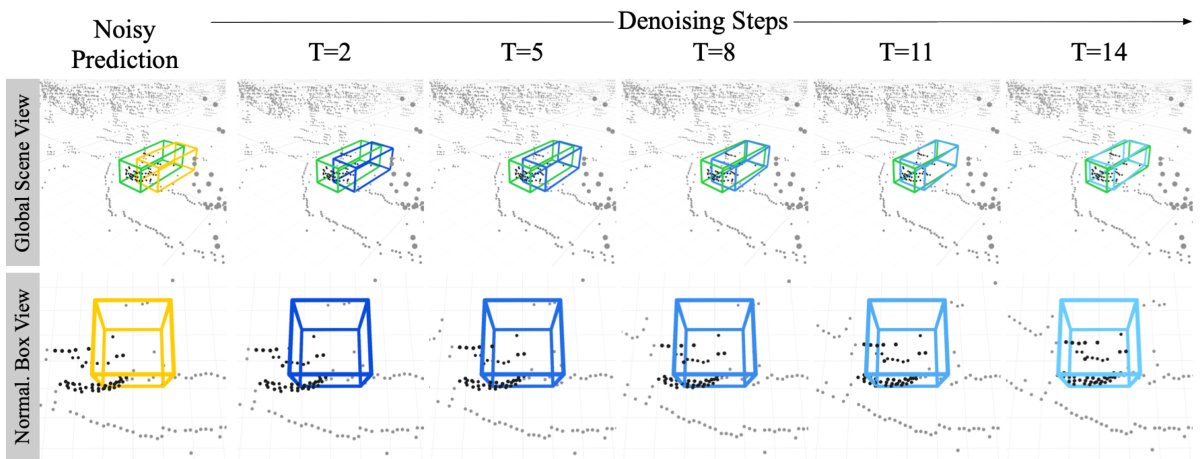
The figure visualizes how DiffuBox refines a noisy bounding box prediction iteratively through denoising steps. It shows both the global scene view and a normalized box view, which removes size bias by transforming the bounding box into a normalized cube. The yellow box represents the initial noisy prediction, blue boxes show the refinement at each step, and the green box indicates the ground truth. The figure demonstrates how the bounding box is gradually corrected to match the ground truth.

This figure shows a qualitative comparison of 3D object detection results on the Lyft and Ithaca365 datasets before and after applying the DiffuBox refinement method. The top row displays point cloud data, while the bottom row shows the corresponding image data. Each column represents a different scenario: no adaptation, DiffuBox applied, statistical normalization (SN), and SN with DiffuBox. Ground truth bounding boxes are green, initial detections are yellow, and DiffuBox refined boxes are blue. The figure highlights how DiffuBox improves localization accuracy by correcting mislocalized or incorrectly shaped bounding boxes while leaving accurately placed boxes largely unchanged.
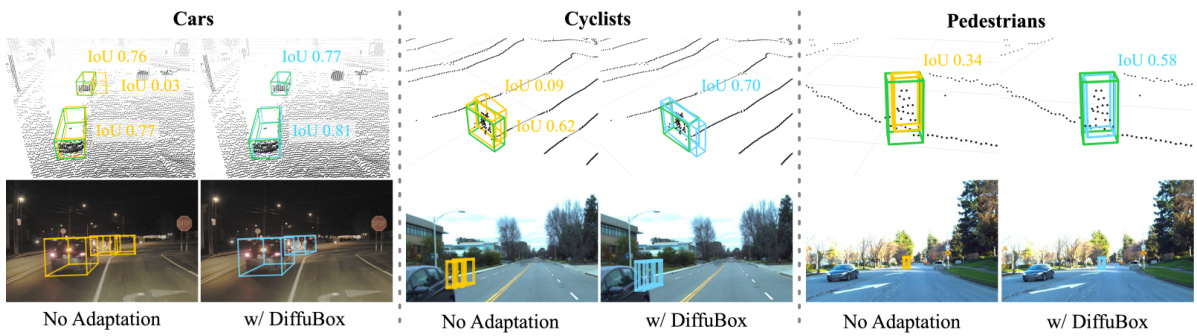
This figure shows four examples of 3D object detection results on the Lyft and Ithaca365 datasets, comparing the performance of an out-of-domain PointRCNN detector with and without DiffuBox refinement. The ground truth boxes are shown in green, the initial PointRCNN detections in yellow, and the DiffuBox-refined boxes in blue. The examples highlight how DiffuBox improves localization by correcting misaligned or incorrectly shaped boxes while leaving correctly predicted boxes largely unchanged.
More on tables
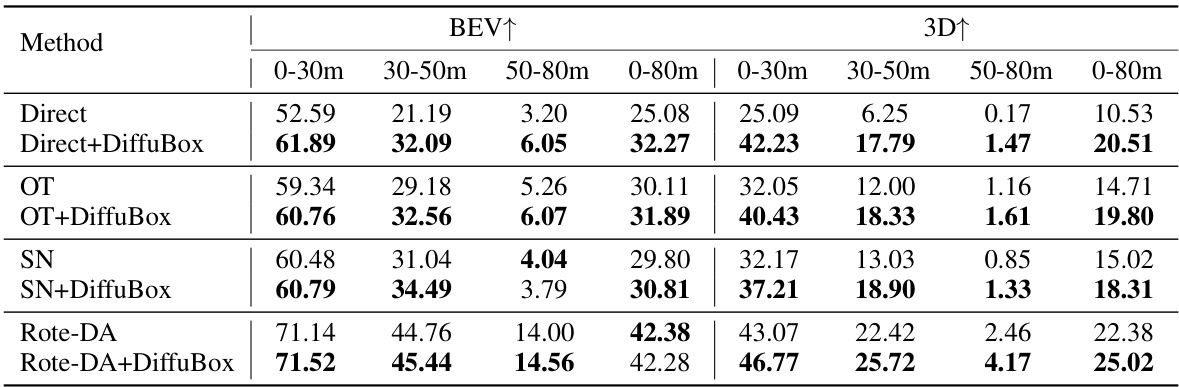
This table presents the mean Average Precision (mAP) at an Intersection over Union (IoU) threshold of 0.7 for car objects, when transferring a model trained on the KITTI dataset to the Ithaca365 dataset. It compares the performance of different domain adaptation methods (Direct, OT, SN, Rote-DA) both with and without the DiffuBox refinement technique. The results are broken down by distance ranges (0-30m, 30-50m, 50-80m) and viewpoint (BEV, 3D). Higher mAP values indicate better performance.
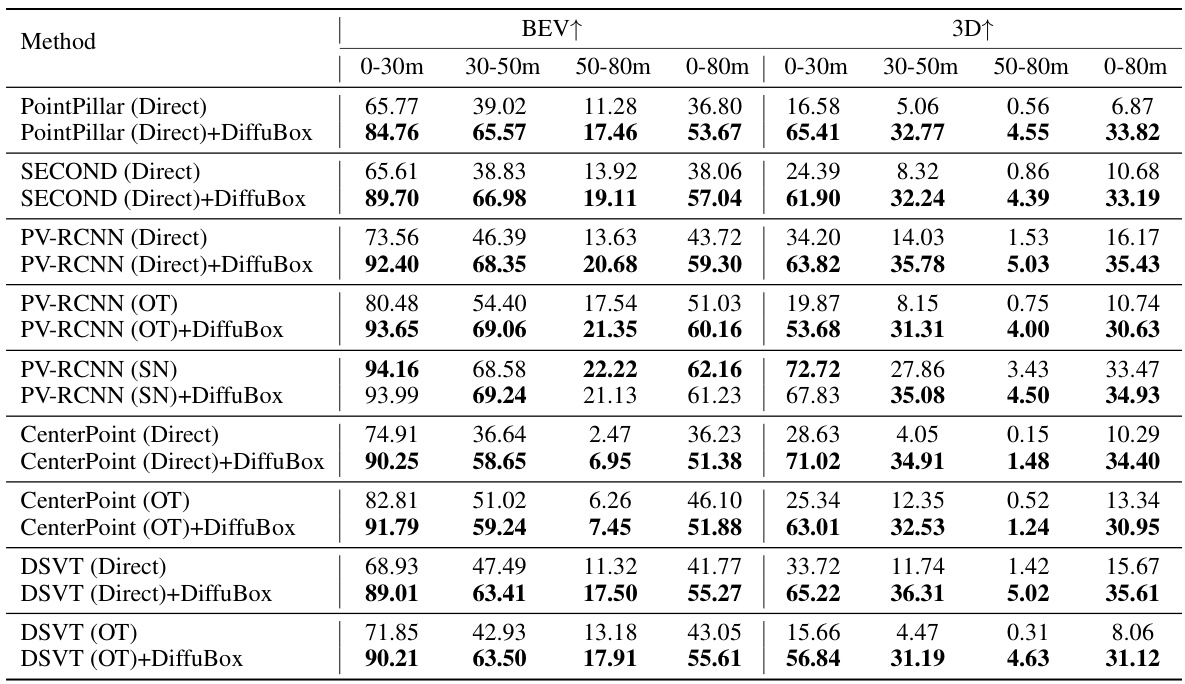
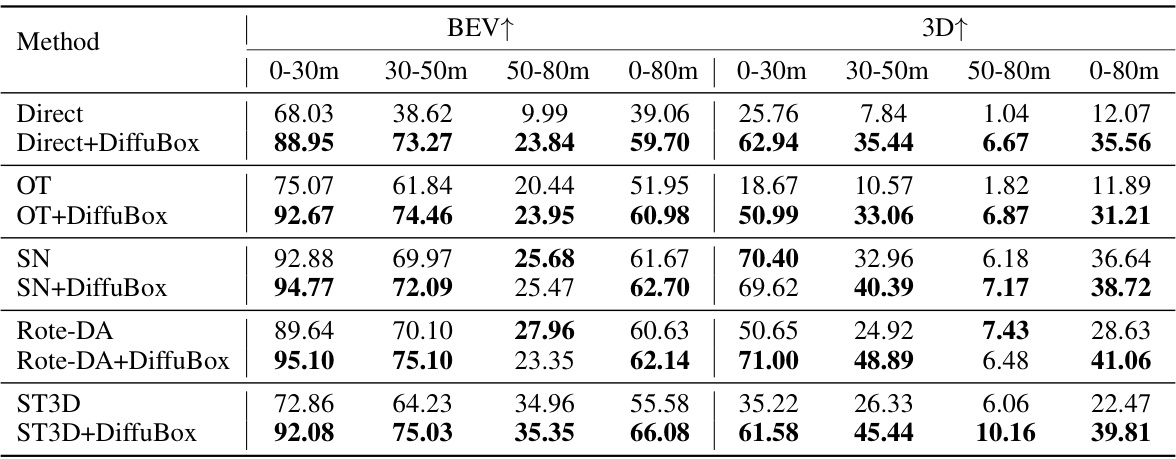
This table presents the mean Average Precision (mAP) at Intersection over Union (IoU) threshold of 0.7 for cars, comparing the performance of different domain adaptation methods on the KITTI to Lyft dataset. The methods include directly applying a KITTI-trained detector (Direct), Output Transformation (OT), Statistical Normalization (SN), Rote-DA, and ST3D. For each method, the mAP is shown for three distance ranges (0-30m, 30-50m, 50-80m) in both Bird’s Eye View (BEV) and 3D. The table also shows the results when DiffuBox is added as a post-processing step to refine bounding boxes.
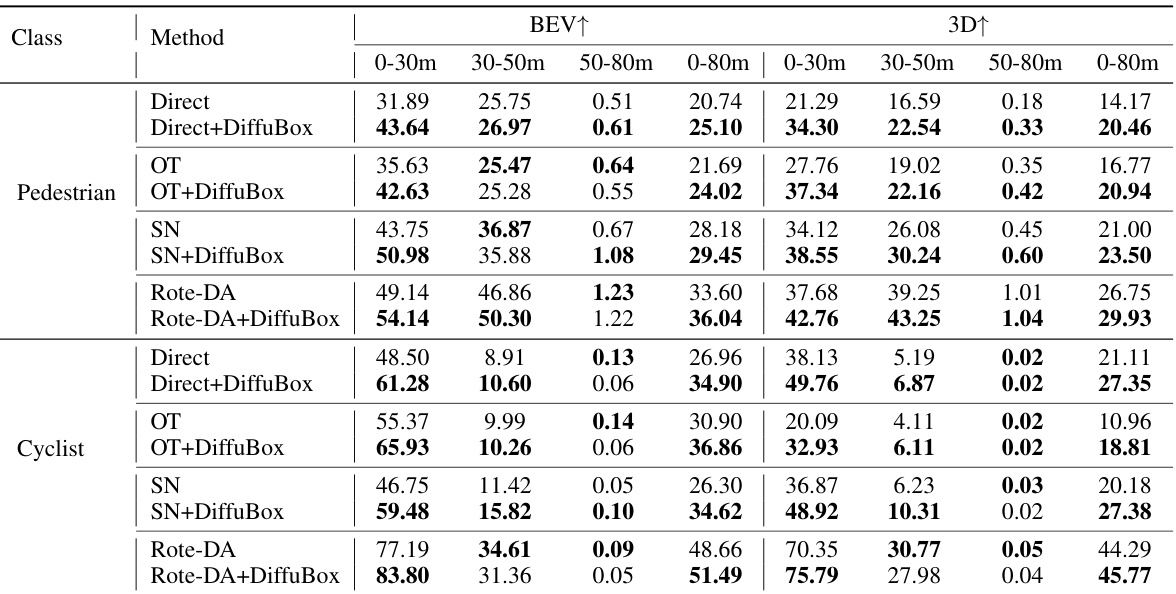
This table presents the mean Average Precision (mAP) at an Intersection over Union (IoU) threshold of 0.7 for car detection, evaluating the performance of DiffuBox in improving domain adaptation from KITTI to Lyft datasets. The table compares different domain adaptation baselines (Direct, OT, SN, Rote-DA, ST3D) with and without the application of DiffuBox. Results are shown for different distance ranges (0-30m, 30-50m, 50-80m, and 0-80m) and in both Bird’s Eye View (BEV) and 3D perspectives. The improvement shown demonstrates DiffuBox’s effectiveness in refining bounding box predictions, particularly benefiting the Direct and OT methods.
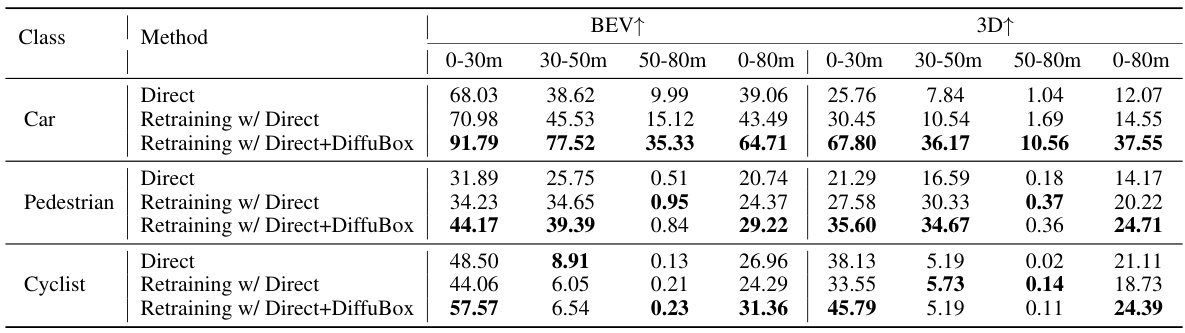
This table presents the mean Average Precision (mAP) at Intersection over Union (IoU) threshold of 0.7 for car detection, comparing different domain adaptation methods on the KITTI to Lyft dataset. The results are broken down by distance ranges (0-30m, 30-50m, 50-80m, and 0-80m) and viewpoint (BEV and 3D). It shows the performance improvement achieved by adding DiffuBox to several baseline methods. The significant gains indicate the effectiveness of DiffuBox in refining bounding box predictions for improved domain adaptation.

This table presents the mean Average Precision (mAP) at Intersection over Union (IoU) threshold of 0.7 for car object detection when transferring models trained on the KITTI dataset to the Lyft dataset. The table compares the performance of various domain adaptation methods (Direct, OT, SN, Rote-DA, ST3D) both with and without the DiffuBox refinement approach. The results are shown for different distance ranges (0-30m, 30-50m, 50-80m, 0-80m) in both Bird’s Eye View (BEV) and 3D perspectives. The table highlights that DiffuBox consistently improves the mAP across all methods and distance ranges, with the most significant improvements observed in the Direct and Output Transformation (OT) methods.
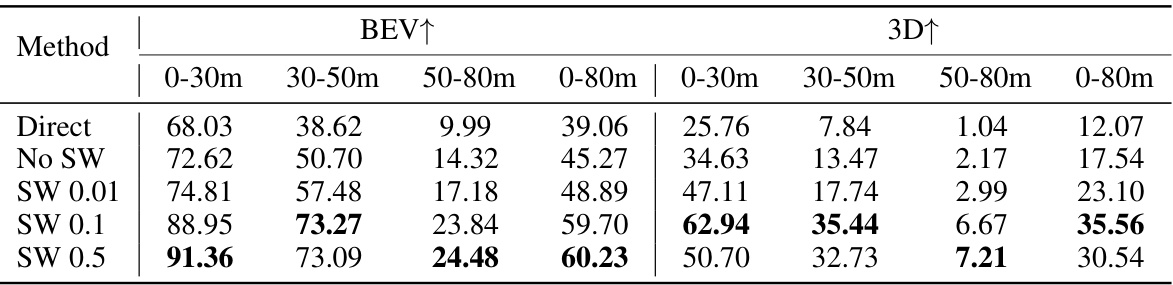
This table presents the results of an ablation study on the impact of shape weight on the performance of DiffuBox. The results show that DiffuBox improves the detector’s output even without using shape weight, indicating that the model is robust. Using shape weight does lead to further improvements, although the gains appear to saturate around a shape weight of 0.1. The table includes mAP@IoU 0.7 values for various shape weights (0, 0.01, 0.1, 0.5) for different distance ranges (0-30m, 30-50m, 50-80m, and 0-80m), split into BEV and 3D metrics.

This table presents the mean Average Precision (mAP) at Intersection over Union (IoU) threshold of 0.7 for the task of 3D object detection on the Lyft dataset using models trained on the KITTI dataset. The results are broken down by distance range (0-30m, 30-50m, 50-80m, and 0-80m) and viewpoint (BEV and 3D). It compares the performance of several domain adaptation methods, both with and without the DiffuBox refinement technique. Higher mAP values indicate better performance. The table highlights that DiffuBox significantly improves performance across various distance ranges and viewpoints, especially when combined with direct adaptation or output transformation methods.
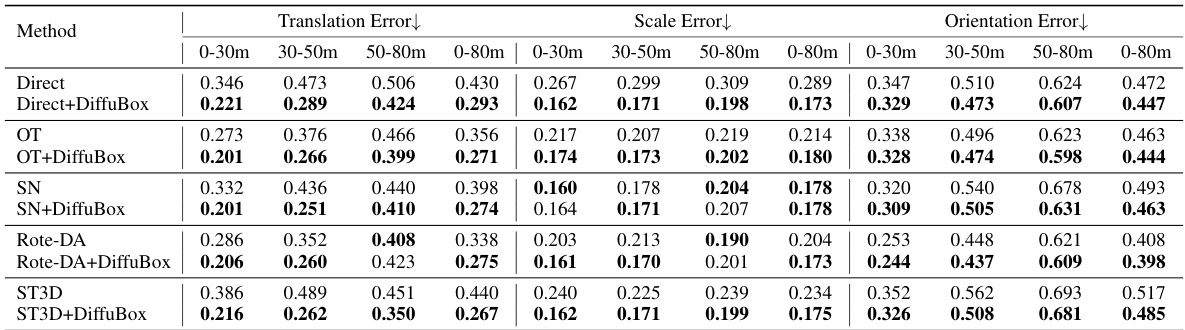
This table presents the mean Average Precision (mAP) at Intersection over Union (IoU) threshold of 0.7 for car detection on the Lyft dataset, when models are trained on the KITTI dataset. The table compares the performance of several domain adaptation methods: Direct (no adaptation), Output Transformation (OT), Statistical Normalization (SN), Rote-DA, and ST3D, both with and without the proposed DiffuBox method. Results are shown for three distance ranges (0-30m, 30-50m, 50-80m) and overall (0-80m) in both Bird’s Eye View (BEV) and 3D perspectives. The table highlights that DiffuBox consistently improves performance across all methods and distance ranges, particularly for the Direct and OT methods.
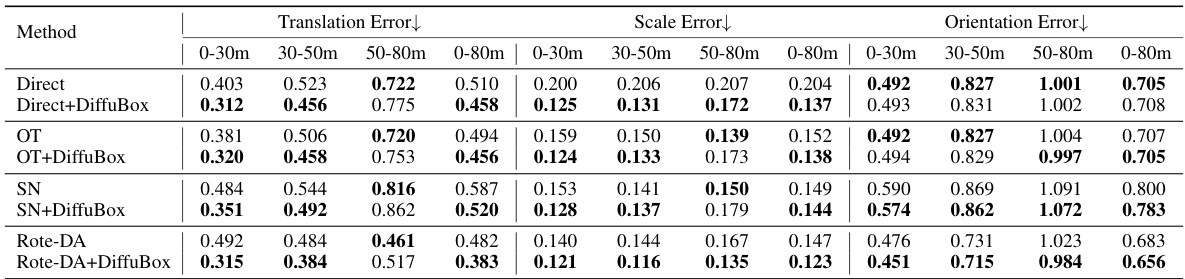
This table presents the mean Average Precision (mAP) at Intersection over Union (IoU) threshold of 0.7 for car objects, comparing the performance of different domain adaptation methods on the KITTI to Lyft dataset. The methods include directly applying an out-of-domain detector (Direct), Output Transformation (OT), Statistical Normalization (SN), Rote-DA, and ST3D. For each method, the mAP is shown for different distance ranges (0-30m, 30-50m, 50-80m, and 0-80m) in both Bird’s Eye View (BEV) and 3D perspectives. The table also shows the results after applying the DiffuBox method to refine the bounding boxes. The results demonstrate that DiffuBox consistently improves the mAP across different methods and distance ranges, especially for Direct and OT detections.

This table presents the mean Average Precision (mAP) at Intersection over Union (IoU) threshold of 0.7 for cars, comparing the performance of the baseline method (Direct) and the proposed method (Direct+DiffuBox) on the KITTI to nuScenes dataset for autonomous driving. The results are broken down by distance ranges (0-30m, 30-50m, 0-50m) and viewing perspectives (BEV and 3D). It demonstrates a significant improvement in performance with the addition of DiffuBox in all categories.
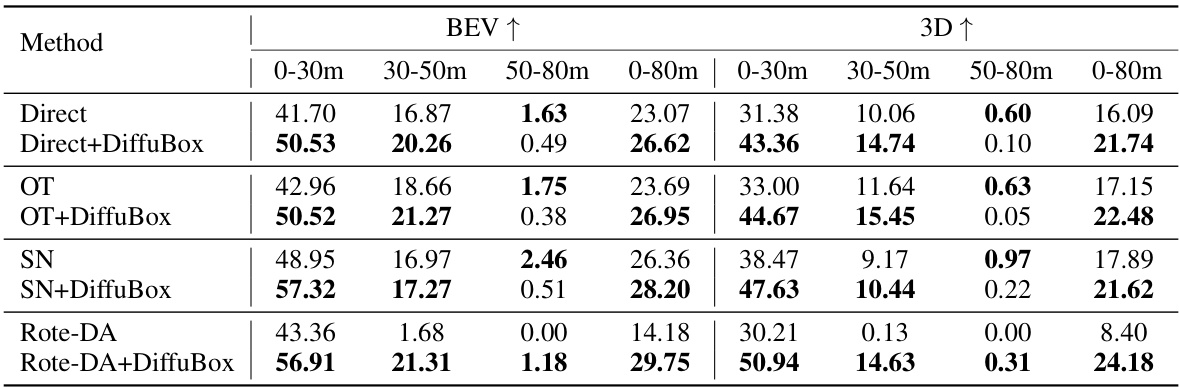
This table presents the mean Average Precision (mAP) at Intersection over Union (IoU) threshold of 0.7 for the task of car object detection. The results compare the performance of different domain adaptation methods (Direct, OT, SN, Rote-DA, ST3D) on the KITTI to Lyft dataset transfer task. The performance is broken down by distance range (0-30m, 30-50m, 50-80m, and 0-80m) and viewing perspective (BEV and 3D). The key takeaway is that DiffuBox consistently improves the mAP across all methods and distance ranges, with the most significant gains observed for the Direct and OT methods.

This table presents the mean Average Precision (mAP) at Intersection over Union (IoU) threshold of 0.7 for cars, when transferring a model trained on the KITTI dataset to the Lyft dataset. It compares the performance of several domain adaptation methods, both with and without the DiffuBox refinement approach. The results are shown for different distance ranges (0-30m, 30-50m, 50-80m, and 0-80m) and in both Bird’s Eye View (BEV) and 3D perspectives. Higher mAP values indicate better performance.
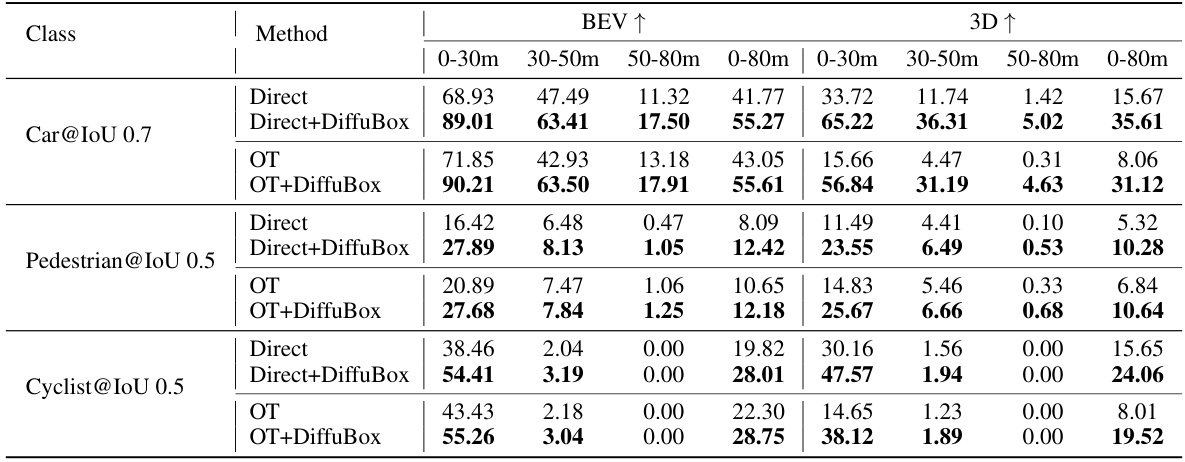
This table presents the mean Average Precision (mAP) at Intersection over Union (IoU) threshold of 0.7 for car detection on the Lyft dataset, using models initially trained on the KITTI dataset. It compares the performance of several domain adaptation methods, both with and without the application of the DiffuBox refinement technique. The results are broken down by distance range (0-30m, 30-50m, 50-80m, and 0-80m) and viewpoint (BEV and 3D). Higher mAP values indicate better performance. The table shows that DiffuBox consistently improves performance across all methods and distance ranges, with the most significant improvements observed for the Direct and Output Transformation (OT) methods.
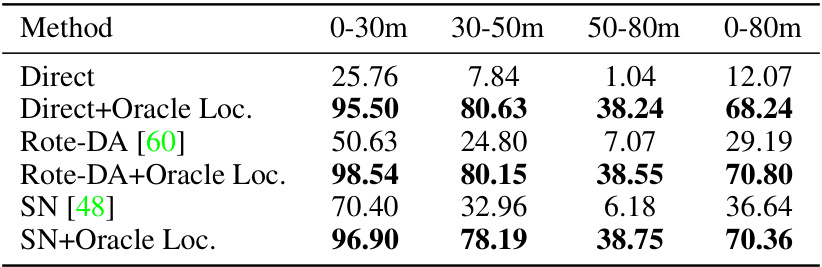
This table presents the mean Average Precision (mAP) at Intersection over Union (IoU) threshold of 0.7 for car object detection results on the Lyft dataset when models are initially trained on the KITTI dataset. It compares different domain adaptation methods (Direct, OT, SN, Rote-DA, ST3D) with and without the application of DiffuBox. The results are broken down by distance range (0-30m, 30-50m, 50-80m, and 0-80m) and presented for both Bird’s Eye View (BEV) and 3D perspectives. Higher mAP values indicate better performance. DiffuBox consistently improves the results across all methods and distance ranges, particularly for the Direct and OT methods.
Full paper#