↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Deep reinforcement learning often struggles with generalization due to the high dimensionality of image-based inputs and the difficulty of capturing long-term dependencies in data. Existing methods, like those based on behavioral metrics, often fall short in handling scenarios with sparse rewards or significant visual distractions. These limitations hinder the ability of RL agents to learn effective policies that generalize well to unseen situations.
To address these issues, the authors propose State Chrono Representation (SCR). SCR uses two encoders: one for individual states and another to capture the relationship between a state and its future states (chronological embedding). A novel behavioral metric is introduced for this embedding, and a ’temporal measurement’ quantifies cumulative rewards. Extensive experiments demonstrate that SCR significantly outperforms existing methods on challenging generalization tasks in DeepMind Control and Meta-World environments, showcasing its effectiveness in handling sparse rewards and visual distractions.
Key Takeaways#
Why does it matter?#
This paper is significant because it tackles the challenge of enhancing generalization in reinforcement learning (RL) with image-based inputs. It introduces a novel approach that effectively incorporates long-term temporal information and accumulated rewards into state representations, leading to improved performance in complex, real-world scenarios. This work is highly relevant to current research trends in representation learning for RL and paves the way for more robust and generalizable RL agents. The proposed method can be easily integrated with existing RL algorithms and is likely to inspire new avenues of research.
Visual Insights#
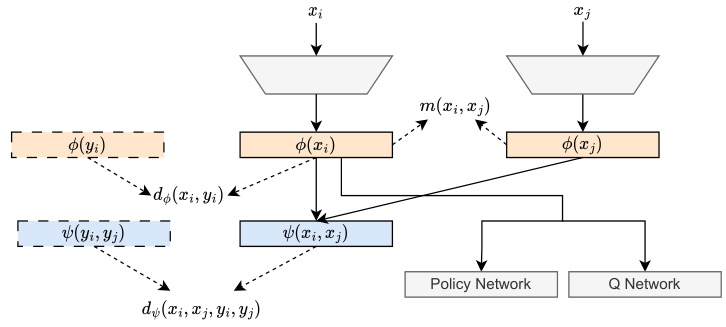
The figure illustrates the architecture of the State Chrono Representation (SCR) method. It shows two key components: a state representation encoder that generates a representation for individual states and a chronological embedding that captures the relationship between current and future states within a trajectory. A novel behavioral metric is learned for both state representations and temporal state pairs. The output state representations are used as input to the policy and Q networks of a deep reinforcement learning agent.

This table presents the mean and standard deviation of the results obtained by different reinforcement learning methods on the DeepMind Control Suite. The experiments were conducted under default settings, with each method trained for 500,000 environment steps. The table compares the performance of SAC, DrQ, DBC, MICo, SimSR, and SCR across eight different tasks within the DeepMind Control Suite, showing the average scores achieved by each algorithm in each task.
In-depth insights#
Chrono State Rep#
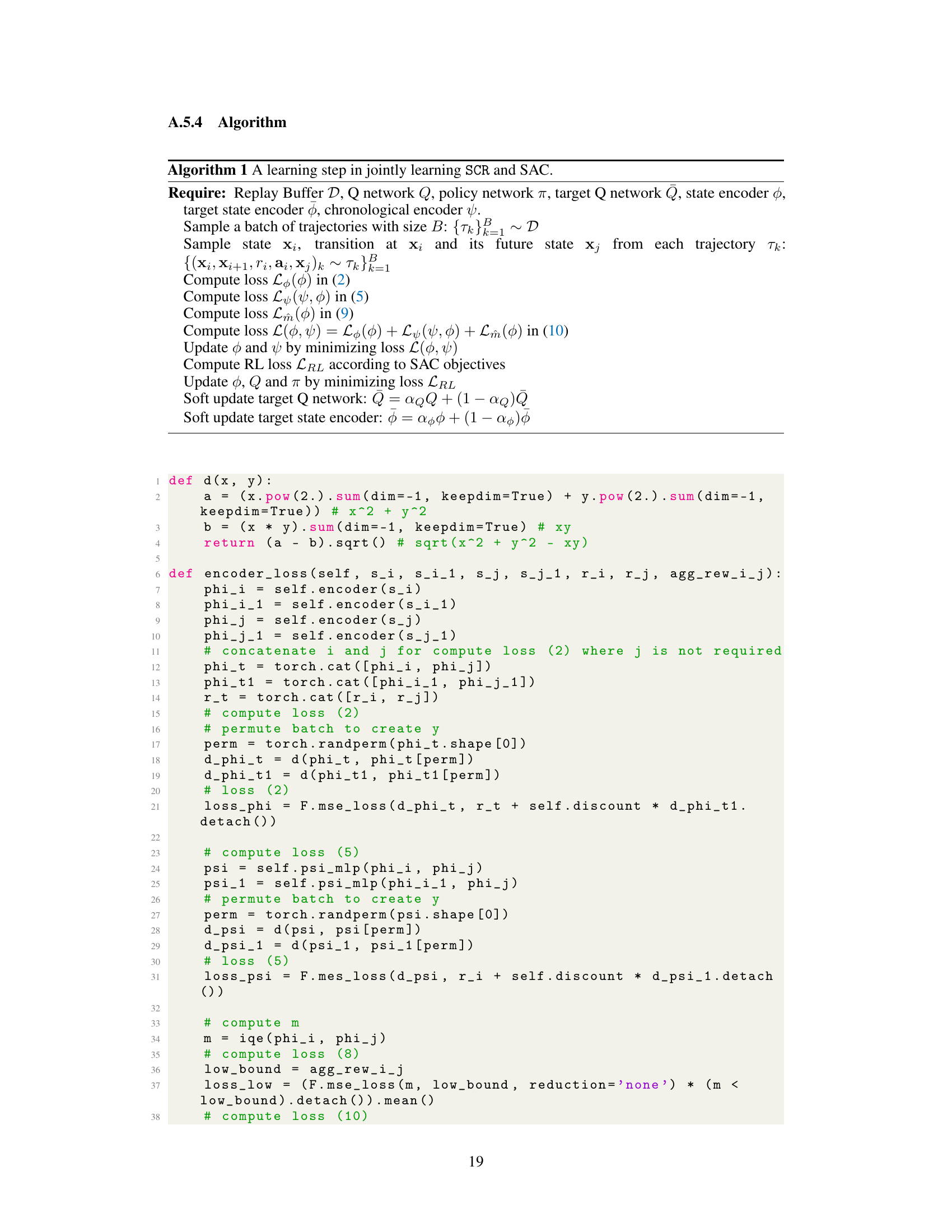
Chrono State Representation (CSR) is a novel approach designed to enhance generalization in reinforcement learning, particularly when dealing with image-based inputs and sparse rewards. The core idea is to augment traditional state representations with explicit temporal information, moving beyond the limitations of one-step updates. By incorporating both future dynamics and accumulated rewards, CSR learns state distances within a temporal framework. This approach effectively captures long-term dependencies and task-relevant features, improving the agent’s ability to generalize to unseen scenarios. A key strength of CSR is its efficiency, avoiding the need for large transition models or complex dynamic modeling, thereby reducing computational costs and enhancing scalability. The use of a novel behavioral metric for temporal state pairs further improves the quality of the representation, enabling more effective policy learning, and resulting in significant performance gains in challenging environments.
Metric Learning#
Metric learning, in the context of the provided research paper, is a crucial technique for enhancing the generalization capabilities of reinforcement learning models, particularly when dealing with high-dimensional image-based inputs. The core idea revolves around learning an effective distance metric in a low-dimensional embedding space, where distances accurately reflect task-relevant similarities between states. This contrasts with traditional approaches that might rely on pixel-wise comparisons, which are susceptible to noise and irrelevant information. The effectiveness of metric learning hinges on the ability to capture crucial behavioral information. Methods such as bisimulation metrics are highlighted, aiming to define distances based on the long-term implications of state transitions and accumulated rewards. However, these methods often face challenges with sparse rewards and the limitations of only considering short-term information. The paper likely proposes an improvement on existing techniques, possibly by incorporating long-term temporal dependencies to address the inherent challenges of these metrics and to better capture long-term behavioral similarities that are crucial to generalization.
Long-Term Info#
The concept of “Long-Term Info” in reinforcement learning (RL) addresses a critical limitation of many existing methods: their focus on short-term, immediate rewards. Many RL algorithms struggle to learn optimal policies in scenarios with sparse or delayed rewards because they lack the ability to effectively incorporate long-term consequences of actions. The integration of long-term information is crucial for generalization, enabling an agent to make informed decisions even when faced with unseen situations or uncertain environments. This often involves mechanisms to capture and represent the cumulative effects of actions over extended time horizons. Effective strategies might use techniques like recurrent neural networks to process sequential data, model-based RL methods to predict future states and rewards, or hierarchical RL to decompose problems into smaller, manageable subtasks. The challenge lies in balancing the computational cost of storing and processing long-term data with the need for efficient learning and decision-making. Approaches must effectively capture relevant long-term patterns while avoiding overfitting or the curse of dimensionality.
Generalization#
The concept of generalization in machine learning, particularly within the context of reinforcement learning (RL), is crucial for creating agents capable of adapting to unseen situations and environments. Effective generalization enables agents to transfer knowledge acquired during training to novel scenarios, improving robustness and reducing the need for extensive retraining. The paper explores how temporal dynamics and reward structures influence generalization. The authors tackle the challenge of ensuring the learned representations are not overly specific to the training environment. By incorporating extensive temporal information, particularly future dynamics and cumulative rewards, the approach aims to enhance the richness and informativeness of the state representation. This is vital because an agent’s ability to extrapolate from past experiences hinges on its ability to encode relevant, long-term patterns within its internal representation. The success of the proposed method hinges on how well it captures these temporal relationships and translates them into a low-dimensional embedding that facilitates effective decision-making. Ultimately, the effectiveness of this approach in improving generalization in RL depends on the ability to effectively distinguish between task-relevant and irrelevant information within complex and dynamic environments.
Future Work#
Future research directions stemming from this paper could explore several key areas. Extending the SCR framework to handle partially observable Markov decision processes (POMDPs) is crucial for real-world applicability, where complete state information is rarely available. This would involve incorporating techniques for belief state representation and planning under uncertainty. Another important avenue is investigating the impact of different reward structures on SCR’s performance, particularly in sparse reward scenarios. A more in-depth analysis of SCR’s generalization capabilities across diverse tasks and environments is warranted. Furthermore, comparing SCR to a wider array of representation learning methods, beyond those included in the current experiments, could provide valuable insights into its strengths and weaknesses. Finally, a thorough investigation of the computational efficiency of SCR and exploring potential optimizations is necessary for scalability to larger and more complex problems.
More visual insights#
More on figures
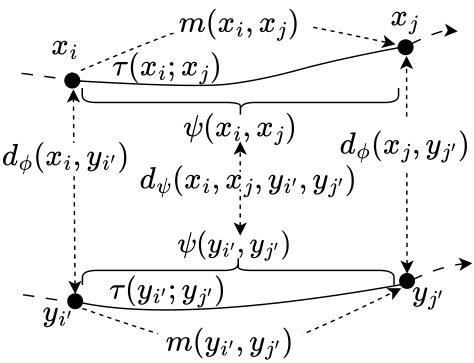
The figure illustrates the overall architecture of the State Chrono Representation (SCR) approach. It shows two key components: a state representation, φ(x), and a chronological embedding, ψ(xᵢ, xⱼ). The state representation φ(x) is generated using a behavioral metric (d) that measures the distance between states based on rewards and dynamic divergence. The chronological embedding ψ(xᵢ, xⱼ) combines the state representations of a current state (xᵢ) and its future state (xⱼ) to capture temporal relationships between them. A novel chronological behavioral metric (dψ) is used to calculate the distance between these chronological embeddings. Finally, a temporal measurement (m) quantifies the sum of rewards between the current and future states, providing an additional piece of information for state representation learning. This whole process involves two state encoders and a policy network.

This figure shows example images from the DeepMind Control Suite environment. Panel (a) displays images from the default setting, showing clean, simple backgrounds and consistent camera angles. Panel (b) shows images from a distraction setting, which introduces significant visual noise including a changing background video, altered robot colors, and variable camera angles. These distractions simulate real-world complexities and make the control tasks significantly more challenging.
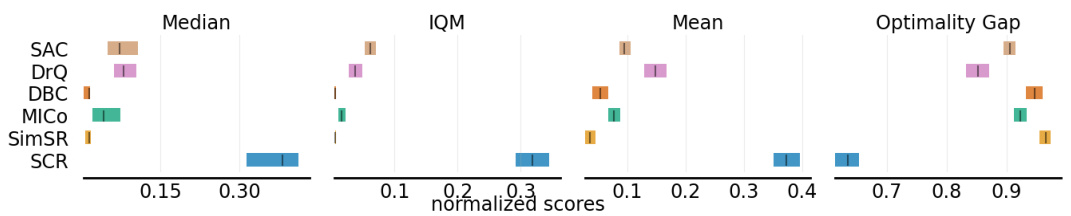
This figure shows a comparison of different reinforcement learning methods across four metrics: Median, IQM, Mean, and Optimality Gap. The comparison is made using a distracting setting, meaning the environment introduces elements that make the learning task more challenging. Each method is represented by a colored box, indicating its performance. The x-axis shows the normalized scores, and the y-axis implicitly represents the different reinforcement learning algorithms. The figure visually summarizes the relative performance of various algorithms under challenging conditions.

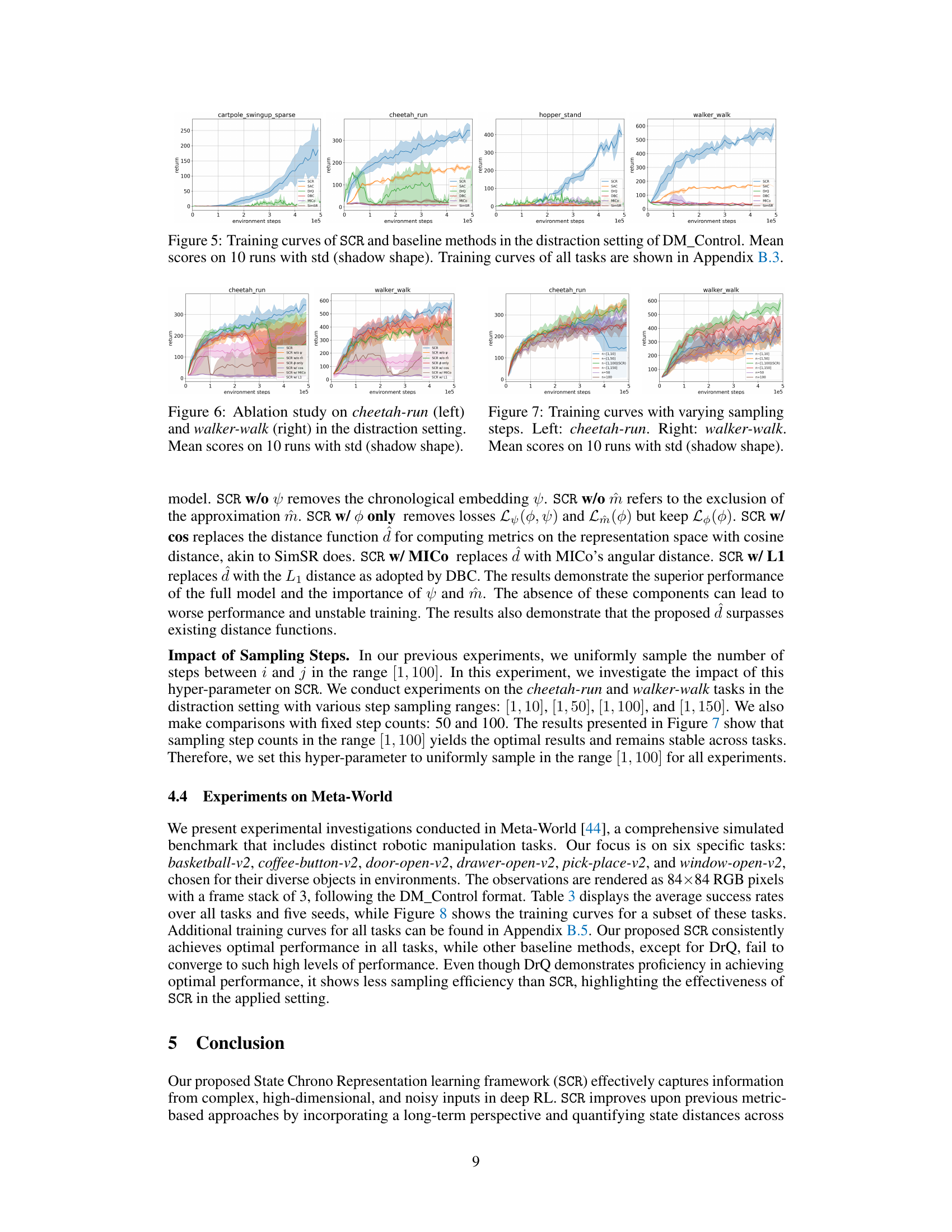
This figure presents the training curves for several deep reinforcement learning methods (SCR, SAC, DrQ, DBC, MICO, SimSR) across four different DeepMind Control tasks in a distracting setting. Each curve represents the average reward obtained over 10 independent training runs, with the shaded area indicating the standard deviation. The distracting setting makes the tasks more challenging by adding background video, changing object colors, or randomizing camera positions. The figure demonstrates the superior performance and generalization of the SCR method compared to the baseline methods, especially for the tasks with sparse rewards, like cartpole_swingup_sparse.
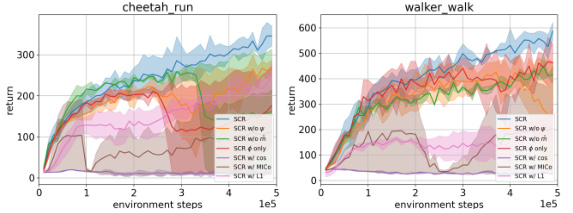
This ablation study in the distraction setting of DeepMind Control Suite shows the training curves for cheetah-run and walker-walk tasks. It compares the full SCR model against versions where components have been removed (chronological embedding, temporal measurement) or replaced (distance function). The shadow shapes represent the standard deviation over 10 runs. This figure demonstrates the relative contribution and importance of each component in SCR’s overall performance.

This figure shows the impact of varying the number of sampling steps on the performance of the SCR model in two DeepMind Control Suite tasks: cheetah-run and walker-walk. The x-axis represents training steps (environment steps), and the y-axis represents the average return (cumulative reward) over 10 runs. Each line represents a different sampling range [1,10], [1,50], [1,100], [1,150] as well as fixed step counts of 50 and 100. The shaded area around each line represents the standard deviation, showing the variability of the results across different runs. The aim of the experiment is to determine the optimal range for sampling steps that balances efficiency and stability during the learning process.

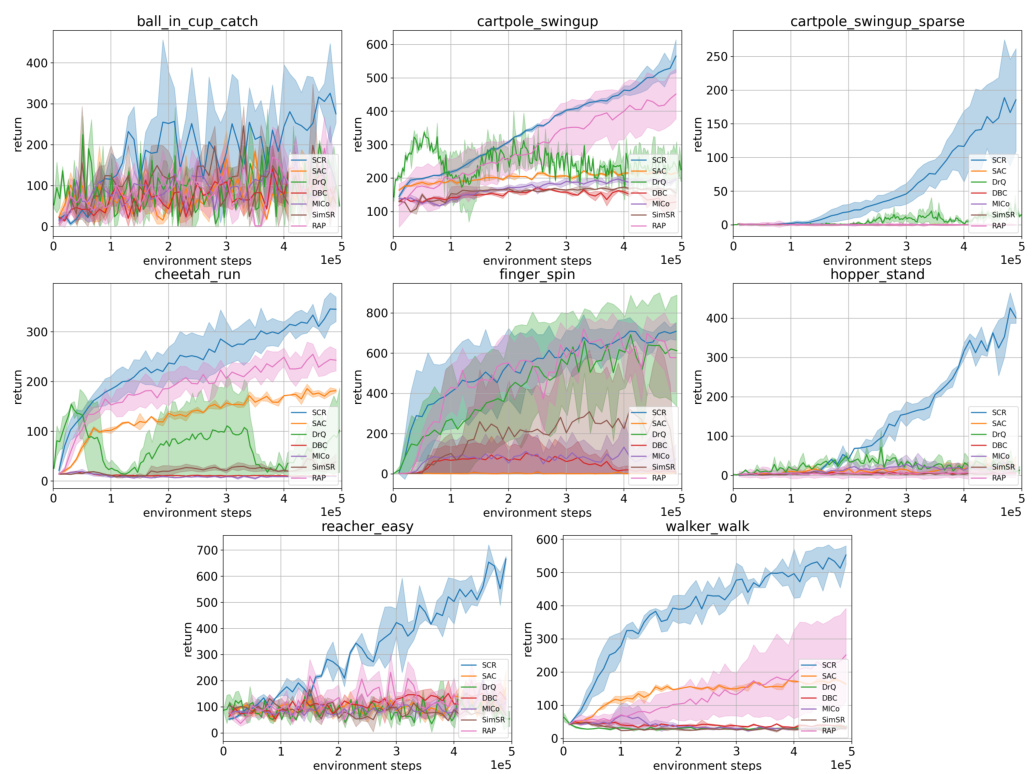
This figure shows the training performance of various reinforcement learning methods (SAC, DrQ, DBC, MICO, SimSR, and SCR) across six different tasks in the Meta-World environment. Each line represents the average success rate over five runs, with shaded areas indicating standard deviation. The results demonstrate that SCR consistently outperforms the baselines in all tasks, showcasing its superior generalization and efficiency.
This figure shows example images from the DeepMind Control suite. (a) shows examples of the default setting, demonstrating the simplicity of the backgrounds and the clarity of the robot. (b) shows examples from the distraction setting, illustrating the added noise and complexity, including a cluttered background video, altered robot colors, and a different camera angle. This highlights the challenges in generalization that the State Chrono Representation (SCR) method aims to address.

This figure shows examples of the DeepMind Control Suite environments used in the paper’s experiments. The left image (a) depicts the default setting of the environment, while the right image (b) demonstrates the distraction setting. The distraction setting makes the control tasks significantly more challenging due to the added background video, changes in robot color, and randomized camera position.

This figure shows the training curves of five different methods on MiniGrid-FourRooms environment. The methods are PPO, PPO+DBC, PPO+MICO, PPO+SimSR, and PPO+SCR. The y-axis represents the average success rate, and the x-axis represents the number of environment steps. The shaded area represents the standard deviation over 5 runs. This figure visually demonstrates the performance comparison of different methods, especially highlighting the effectiveness of PPO+SCR in achieving high success rates.
More on tables

This table presents the results of experiments conducted on the DeepMind Control Suite with a distraction setting. Eight different continuous control tasks are evaluated, and the mean and standard deviation of the scores are shown for each task. The distraction setting includes background video distraction, object color distraction, and camera pose distraction. The results show the performance of various algorithms (SAC, DrQ, DBC, MICO, SimSR, and SCR) under these challenging conditions, with SCR outperforming the others in most tasks.

This table presents the average success rates achieved by different reinforcement learning methods (SAC, DrQ, DBC, MICo, SimSR, and SCR) across six tasks within the Meta-World environment. The success rate is a metric indicating the percentage of successful task completions. The results showcase the superior performance of the proposed SCR method compared to other baselines. The values provided are the means and standard deviations calculated across five different seeds (random initializations).

This table presents the results of experiments conducted on the DeepMind Control Suite, using the default setting with 500K environment steps. It compares the performance of different reinforcement learning methods, including SAC, DrQ, DBC, MICO, SimSR, and SCR. For each method, the mean and standard deviation of the scores are given for eight different tasks. This allows for a comparison of the sample efficiency of the different methods.
This table presents the results of eight different tasks from the DeepMind Control Suite. The results are the average performance (mean ± standard deviation) of several reinforcement learning methods over 10 different runs, each running for 500,000 environment steps. The ‘default setting’ refers to the standard environment configuration without any added distractions. The table allows comparison of various algorithms in a standard setting to assess relative performance.

This table presents the results of experiments conducted on the DeepMind Control Suite with a distraction setting. The results show the mean and standard deviation of scores achieved by various reinforcement learning methods (SAC, DrQ, DBC, MICO, SimSR, and SCR) across eight different control tasks. The distraction setting introduces background video, object color, and camera pose variations to increase the difficulty of the tasks. The table highlights the performance of each algorithm in this challenging scenario, showcasing their ability to generalize to more complex and realistic environments.

This table presents the results of experiments conducted on the DeepMind Control Suite with a distraction setting. The results (mean ± standard deviation) are shown for eight different control tasks, comparing the performance of several reinforcement learning algorithms. The algorithms include SAC (a baseline), DrQ (data augmentation), DBC (bisimulation metric), MICo (another behavioral metric), SimSR (yet another behavioral metric), and SCR (the authors’ proposed State Chrono Representation). The distraction setting makes the tasks more challenging by introducing variations in background video, object color, and camera pose.

This table presents the average success rates achieved by different reinforcement learning methods across six distinct tasks within the Meta-World environment. The results highlight the performance comparison between various methods, showcasing their effectiveness in handling the complexities of robotic manipulation tasks in a simulated environment.
Full paper#