↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Current large language models (LLMs) struggle with real-world tasks due to poor understanding of the physical world, leading to ineffective planning. This often manifests as brainless trial-and-error and hallucinatory actions. This paper tackles this by drawing inspiration from human mental models that provide global prior knowledge and maintain local dynamic knowledge during task execution.
To address these issues, the researchers propose a parametric World Knowledge Model (WKM). WKM is trained using both expert and sampled trajectories and leverages prior knowledge for global planning and dynamic state knowledge for local planning. Experiments using three complex datasets and various LLMs demonstrate that this approach is superior to several strong baselines. Further analysis confirms that WKM effectively alleviates the limitations of LLMs in planning while highlighting its instance-level task knowledge and ‘weak-guide-strong’ capabilities.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on AI agents and planning, particularly those using large language models. It addresses the critical limitations of current LLMs in understanding the physical world, offering a novel solution that enhances the performance and robustness of AI agents. The proposed World Knowledge Model (WKM) and its method has the potential to significantly improve AI agent planning in various applications, pushing the boundaries of current LLM capabilities and opening exciting new avenues of research. The findings, such as the generalizability of instance-level knowledge and the effectiveness of weak-guide-strong approaches, are particularly impactful and contribute to our understanding of how knowledge can be effectively integrated into AI agents.
Visual Insights#
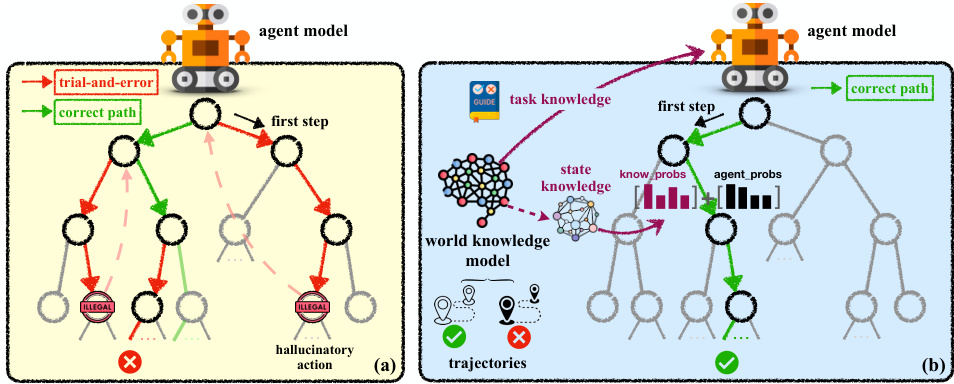
🔼 The figure is a comparison of two different agent planning approaches. (a) shows traditional agent planning, which relies on trial and error and can lead to hallucinatory actions. (b) shows agent planning with a world knowledge model, which leverages prior task knowledge and dynamic state knowledge to guide the agent towards a more efficient and accurate solution.
read the caption
Figure 1: Traditional agent planning vs. Agent planning with world knowledge model.
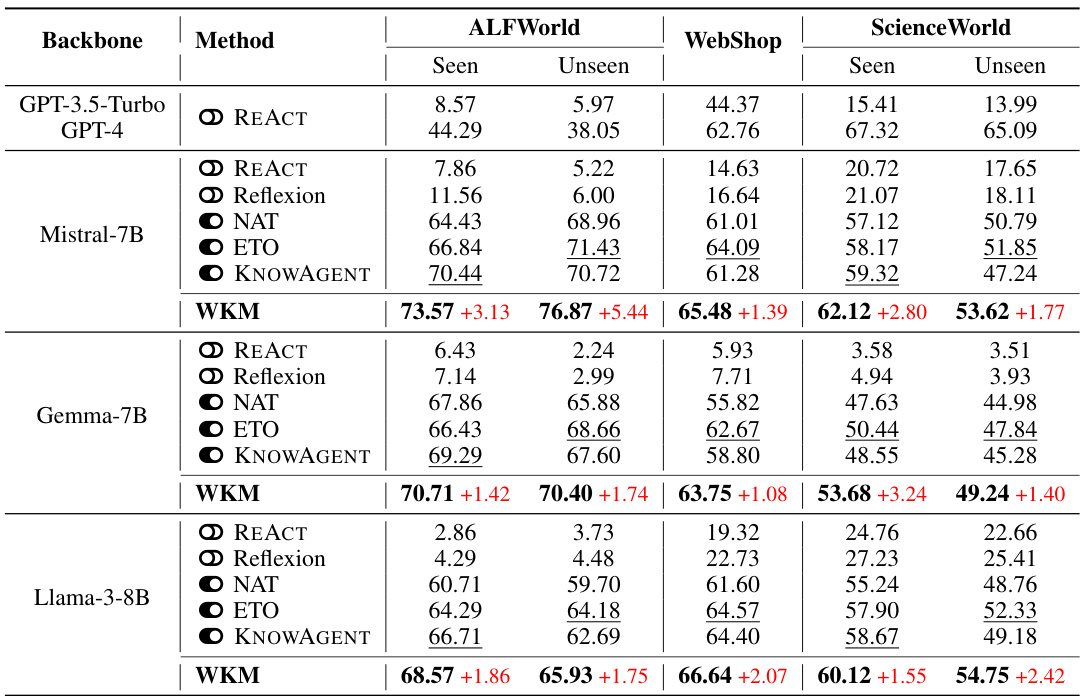
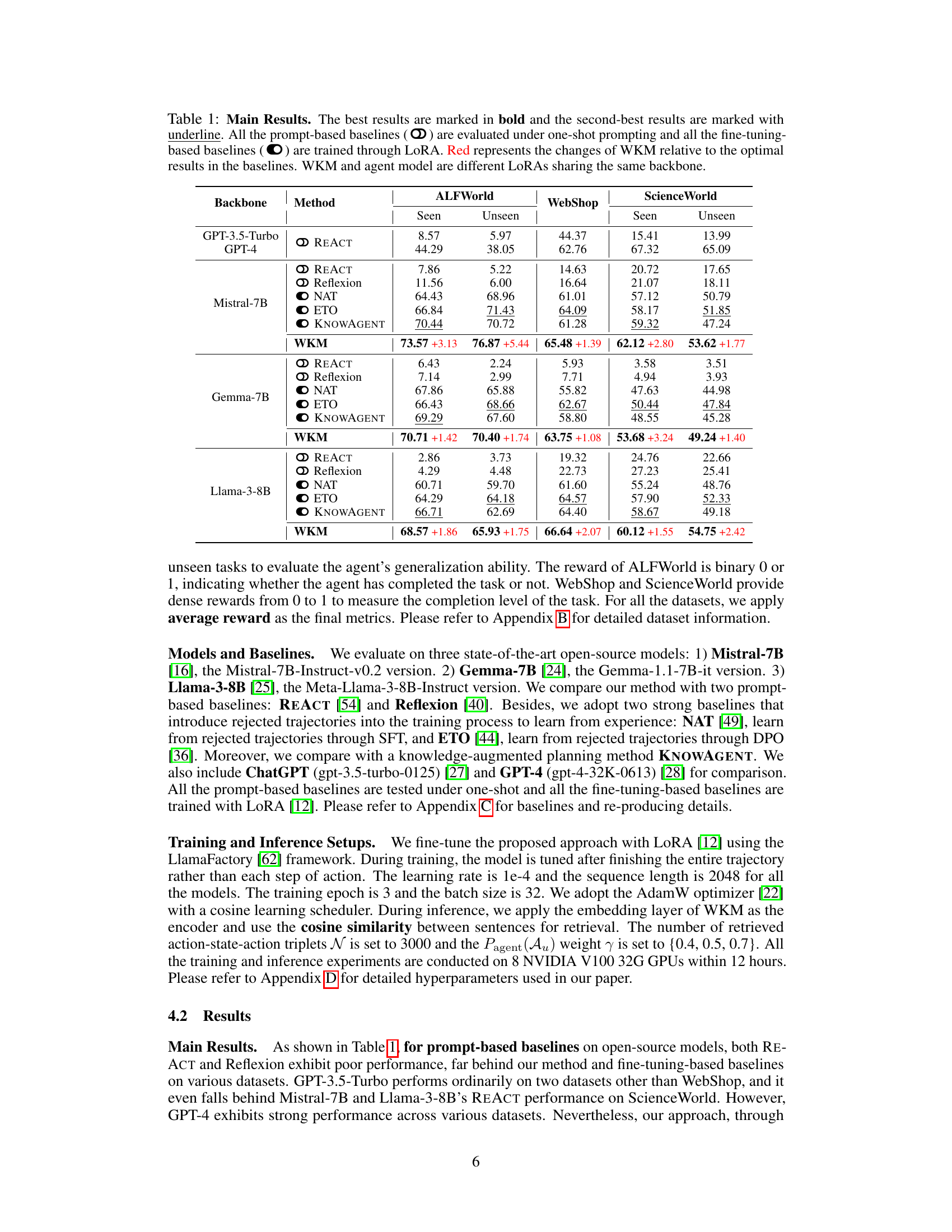
🔼 This table presents the main results of the experiments conducted in the paper, comparing the performance of the proposed World Knowledge Model (WKM) against several strong baselines on three different datasets (ALFWorld, WebShop, and ScienceWorld). The baselines include various prompt-based and fine-tuning-based methods. The table shows the performance (seen and unseen tasks) for each method and dataset, with the best results highlighted. The ‘Red’ values indicate the improvement achieved by WKM relative to the best-performing baseline for each dataset and task type. The table also indicates whether the baseline is prompt-based or fine-tuned using LoRA.
read the caption
Table 1: Main Results. The best results are marked in bold and the second-best results are marked with underline. All the prompt-based baselines (∞) are evaluated under one-shot prompting and all the fine-tuning-based baselines (ㅇ) are trained through LoRA. Red represents the changes of WKM relative to the optimal results in the baselines. WKM and agent model are different LoRAs sharing the same backbone.
In-depth insights#
WKM: World Knowledge#
A hypothetical ‘WKM: World Knowledge’ section in a research paper would likely delve into the architecture and functionality of a World Knowledge Model. This model’s core purpose is to enhance AI agent planning by providing context and grounding beyond the immediate task parameters. The WKM would likely incorporate diverse knowledge sources, potentially including structured knowledge bases (e.g., commonsense knowledge graphs), unstructured data (e.g., text corpora), and even learned representations from agent experiences. The section would need to detail how this knowledge is integrated and accessed during planning: a key aspect would be whether the knowledge is explicitly used in prompts or implicitly guides decision-making via learned embeddings. Further discussion could center on the model’s training methodology: how is the WKM trained, and what data is utilized? The training process would be crucial for determining the model’s scope and accuracy. Finally, the section should address the limitations of the WKM, for example, how effectively it handles ambiguous or incomplete knowledge, and its scalability to complex real-world scenarios. A robust WKM is vital for enabling AI agents to act more intelligently and less erratically.
Agent Planning Models#
Agent planning models are a crucial area of artificial intelligence research, focusing on enabling autonomous agents to make effective plans. Traditional methods often struggle with the complexity of real-world environments and the limitations of handcrafted planning algorithms. Large Language Models (LLMs) have emerged as powerful tools to address these challenges. However, LLMs alone often suffer from a lack of grounding in the physical world, leading to hallucinations and inefficient trial-and-error planning. Parametric World Knowledge Models (WKMs) represent a promising approach to bridge this gap by integrating prior knowledge and dynamic state information into the planning process. The integration of WKMs with LLMs allows agents to synthesize knowledge from both expert and sampled trajectories, effectively guiding global planning and preventing hallucinatory actions in local planning. This approach shows potential for enhanced performance and generalization to unseen tasks, indicating a crucial step towards more robust and adaptable agent planning. Key future directions for research involve exploring the use of multi-modal information, unified WKM training, and dynamic WKM updates to adapt to changing environments.
LLM-based Planning#
LLM-based planning represents a significant advancement in AI, leveraging the power of large language models (LLMs) to generate plans and sequences of actions. A key challenge lies in grounding these plans in the real world, as LLMs often lack a true understanding of physics and real-world constraints. Many approaches attempt to address this by incorporating external knowledge sources or training LLMs on simulated environments, but robustness and generalization remain open problems. The success of LLM-based planning heavily depends on the quality and type of LLM used, the richness of the knowledge base, and the effectiveness of the planning algorithm. Future work should focus on improving the reasoning capabilities of LLMs, enhancing their ability to handle uncertainty and unforeseen events, and developing more effective methods for integrating symbolic and sub-symbolic reasoning to create robust and adaptable planning systems.
Ablation Study Results#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a research paper, “Ablation Study Results” would detail the performance of the model with and without these parts. Key insights would be revealed by comparing the full model’s performance against those with components removed. For instance, a drop in accuracy after removing a specific module indicates its importance. Analyzing the results across different components will reveal the relative importance of each component in the overall system. A well-designed ablation study should also consider interactions between components. The results should be presented clearly, often visually using graphs or tables, to highlight the impact of each ablation. This helps establish a causal relationship between the model’s architecture and its performance, thereby providing strong evidence supporting the model design choices and offering guidance for future model improvements. The discussion section should explain the reasons behind observed changes in performance following ablations, showing a deep understanding of the model’s workings. Ultimately, the ablation study results section strengthens the paper’s claims by providing empirical evidence of the model’s design choices.
Future Work#
The authors outline several promising avenues for future research. Extending the WKM to multi-modal inputs is crucial, as it would enable the model to leverage richer information beyond text for more robust planning. Developing a unified world knowledge model capable of handling various tasks and environments without retraining would represent a significant advance. Integrating more sophisticated planning algorithms, such as Monte Carlo Tree Search, with the current framework to improve the efficiency and effectiveness of planning is also suggested. Furthermore, investigating how dynamically updating world knowledge can improve the agent’s adaptation and response to changing circumstances is a major goal. Finally, there is a need for further exploration into the generalization capabilities of the WKM across diverse tasks and unseen environments to solidify its potential as a truly robust and adaptable world knowledge model.
More visual insights#
More on figures
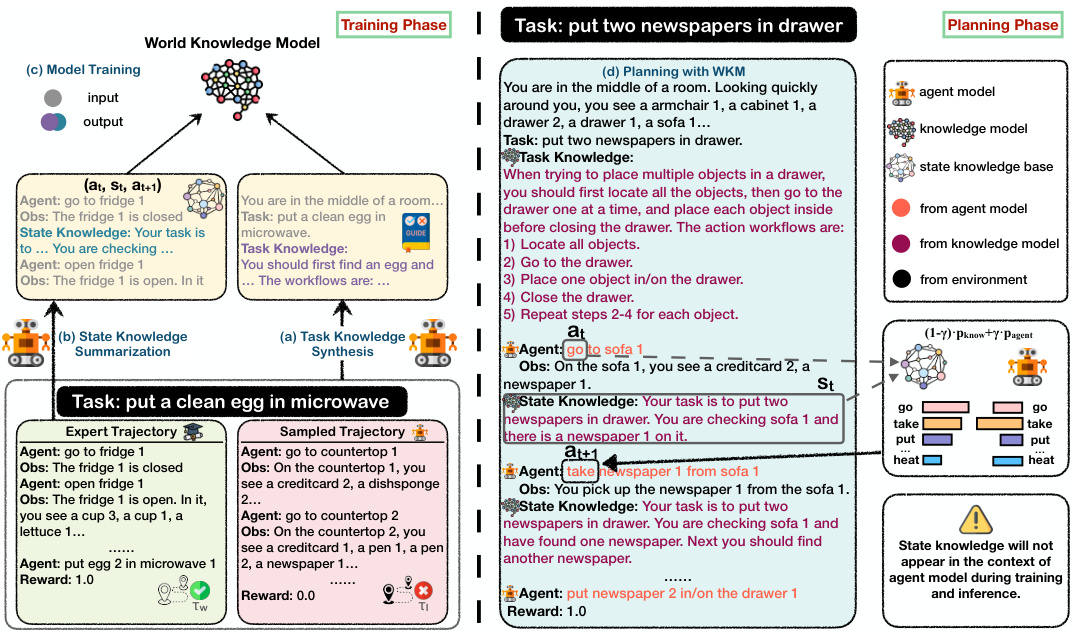
🔼 This figure shows the overall architecture of the World Knowledge Model (WKM). It illustrates the training phase, where the model synthesizes knowledge from expert and sampled trajectories to generate task and state knowledge. The planning phase shows how the WKM guides the agent’s planning process by providing prior task knowledge and dynamic state knowledge, which helps improve the quality of the planning and reduces trial-and-error and hallucinations.
read the caption
Figure 2: Overview of our WKM. We train a world knowledge model on the knowledge synthesized by the agent model itself from both expert and explored trajectories, providing prior task knowledge to guide global planning and dynamic state knowledge to assist local planning.

🔼 This ablation study uses the Mistral-7B model to analyze the impact of different components of the World Knowledge Model (WKM) on the agent’s performance. It compares the average reward achieved when using only expert trajectories, only state knowledge, only task knowledge, both task and state knowledge, excluding rejected trajectories, merging the WKM and agent model into one, and using few-shot prompts instead of a WKM. This helps determine the contribution of each component to the overall performance.
read the caption
Figure 3: Ablation Study on Mistral-7B. w/o all means the vanilla experienced agent model training with pure expert trajectories. w/ state is testing agent model with only state knowledge base constraints. w/ task stands for guiding agent model with only task knowledge. w/ task&state is our WKM with both task knowledge guidance and state knowledge constraints. w/o rejected means synthesizing task knowledge solely through expert trajectories. merge stands for training WKM and the agent model together with one single model. prompt means using few-shot prompts to replace the WKM for providing knowledge.
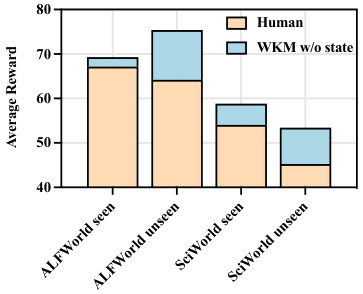
🔼 This figure compares the performance of using dataset-level knowledge (created by abstracting knowledge from WKM into dataset-level knowledge) versus instance-level knowledge (WKM without state information) on ALFWorld and ScienceWorld datasets. The results show that instance-level knowledge generated by the model outperforms human-designed dataset-level knowledge, especially on unseen tasks, highlighting the generalizability of the model’s generated knowledge.
read the caption
Figure 4: Performance of human-designed dataset-level knowledge compared to WKM generated instance-level knowledge.
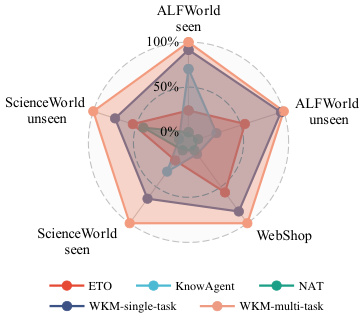
🔼 This radar chart visualizes the performance of different methods across various datasets (ALFWorld seen and unseen, WebShop, ScienceWorld seen and unseen). Each axis represents a dataset, and the distance from the center indicates the average reward achieved by each method on that dataset. The chart compares the performance of ETO, KnowAgent, NAT, single-task WKM, and multi-task WKM, highlighting the superior performance of the multi-task WKM approach across all datasets. It demonstrates the effectiveness of training a unified world knowledge model for improved generalization to unseen tasks.
read the caption
Figure 5: Relative performance of multi-task WKM compared to various baselines.
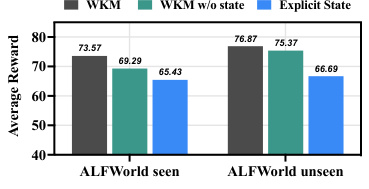
🔼 This figure shows the ablation study of the proposed method using Mistral-7B model. It compares the performance of the model under different configurations, including using only task knowledge, only state knowledge, both task and state knowledge, and without rejected trajectories during training. It also compares a merged model architecture against using few-shot prompts instead of the world knowledge model. The results illustrate the contributions of each component of the proposed World Knowledge Model (WKM) and highlight the impact of using a unified training strategy versus separate models.
read the caption
Figure 3: Ablation Study on Mistral-7B. w/o all means the vanilla experienced agent model training with pure expert trajectories. w/ state is testing agent model with only state knowledge base constraints. w/ task stands for guiding agent model with only task knowledge. w/ task&state is our WKM with both task knowledge guidance and state knowledge constraints. w/o rejected means synthesizing task knowledge solely through expert trajectories. merge stands for training WKM and the agent model together with one single model. prompt means using few-shot prompts to replace the WKM for providing knowledge.

🔼 This figure compares traditional agent planning with agent planning that incorporates a world knowledge model. Traditional agent planning is shown as relying on trial-and-error to find a correct path, often resulting in incorrect or hallucinatory actions. In contrast, agent planning with a world knowledge model uses prior knowledge and dynamic state updates to guide the process and improve the accuracy and efficiency of the plan.
read the caption
Figure 1: Traditional agent planning vs. Agent planning with world knowledge model.
🔼 This figure shows the ablation study of the proposed World Knowledge Model (WKM) on the Mistral-7B model. It compares the performance of WKM against different variants of the model, including one without any knowledge, one with only state knowledge, one with only task knowledge, one with both state and task knowledge, one without rejected trajectories (only using expert trajectories), one that merges WKM and agent model into a single model, and one using few-shot prompts instead of the WKM.
read the caption
Figure 3: Ablation Study on Mistral-7B. w/o all means the vanilla experienced agent model training with pure expert trajectories. w/ state is testing agent model with only state knowledge base constraints. w/ task stands for guiding agent model with only task knowledge. w/ task&state is our WKM with both task knowledge guidance and state knowledge constraints. w/o rejected means synthesizing task knowledge solely through expert trajectories. merge stands for training WKM and the agent model together with one single model. prompt means using few-shot prompts to replace the WKM for providing knowledge.
More on tables
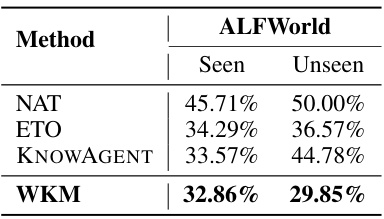
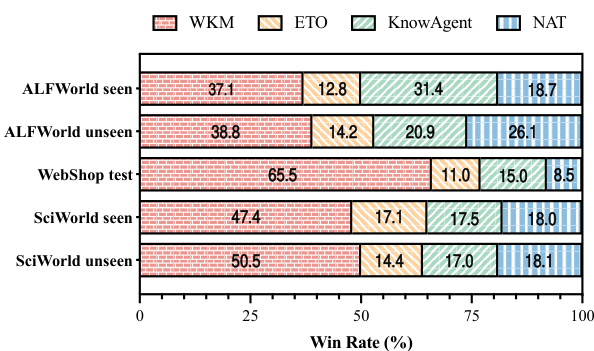
🔼 This table presents the percentage of trajectories that contain invalid actions for different methods (NAT, ETO, KNOWAGENT, WKM) on the ALFWorld dataset, broken down into seen and unseen tasks. An invalid action is an action that is not valid within the context of the task, regardless of whether the trajectory is ultimately successful or not. Lower percentages indicate better performance in avoiding hallucinatory actions.
read the caption
Table 3: Hallucinatory Action Rates on ALFWorld. We calculate the proportion of trajectories containing invalid actions regardless of their correctness.
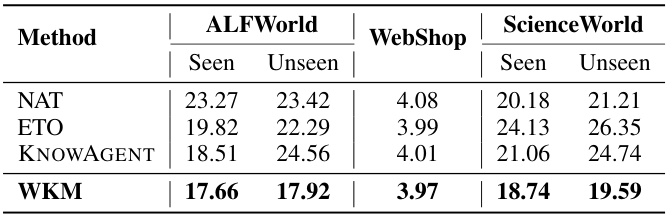
🔼 This table presents the main results of the experiments conducted in the paper, comparing the performance of the proposed World Knowledge Model (WKM) with various baselines across three different datasets (ALFWorld, WebShop, and ScienceWorld). The results are broken down by whether the model was prompt-based (one-shot) or fine-tuned using LoRA, and also by whether the task was seen or unseen. The table shows that the WKM consistently outperforms baselines in various scenarios, highlighting its effectiveness in improving agent planning performance.
read the caption
Table 1: Main Results. The best results are marked in bold and the second-best results are marked with underline. All the prompt-based baselines (∞) are evaluated under one-shot prompting and all the fine-tuning-based baselines (ㅇ) are trained through LoRA. Red represents the changes of WKM relative to the optimal results in the baselines. WKM and agent model are different LoRAs sharing the same backbone.
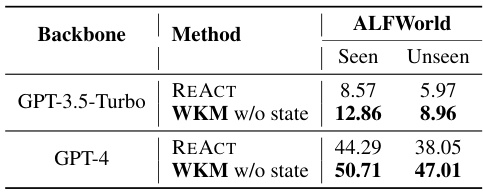
🔼 This table presents the results of using a weaker knowledge model (Mistral-7B) to guide stronger agent models (ChatGPT and GPT-4) on the ALFWorld task. It demonstrates that even a weaker knowledge model can improve the performance of stronger models, supporting the ‘weak-guide-strong’ approach where a lightweight knowledge model guides a more powerful agent model.
read the caption
Table 4: Weak-guide-strong. The knowledge model here is based on Mistral-7B.
🔼 This table presents the main results of the experiments comparing the proposed WKM method with several baselines across three different datasets (ALFWorld, WebShop, ScienceWorld). For each dataset, results are shown separately for seen and unseen tasks, indicating the model’s generalization ability. The table shows performance metrics (average reward) for different models and highlights the best-performing method.
read the caption
Table 1: Main Results. The best results are marked in bold and the second-best results are marked with underline. All the prompt-based baselines (∞) are evaluated under one-shot prompting and all the fine-tuning-based baselines (ㅇ) are trained through LoRA. Red represents the changes of WKM relative to the optimal results in the baselines. WKM and agent model are different LoRAs sharing the same backbone.
🔼 This table presents the main results of the proposed method (WKM) compared to various baselines across three datasets (ALFWorld, WebShop, and ScienceWorld). It shows the performance of different models (using different backbones) under different evaluation setups (seen vs. unseen tasks), highlighting the superior performance of the proposed WKM. The table also indicates whether methods are prompt-based (one-shot) or fine-tuned using LoRA.
read the caption
Table 1: Main Results. The best results are marked in bold and the second-best results are marked with underline. All the prompt-based baselines (∞) are evaluated under one-shot prompting and all the fine-tuning-based baselines (ㅇ) are trained through LoRA. Red represents the changes of WKM relative to the optimal results in the baselines. WKM and agent model are different LoRAs sharing the same backbone.
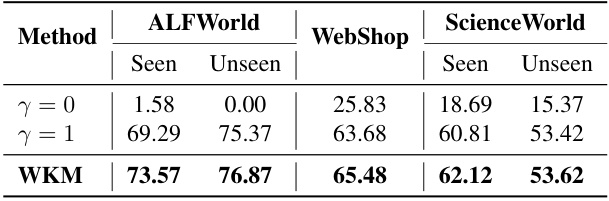
🔼 This table presents the main results of the experiments conducted in the paper. It compares the performance of the proposed World Knowledge Model (WKM) against several baseline methods across three different simulated environments (ALFWorld, WebShop, ScienceWorld) and under both seen and unseen conditions. The table shows average reward, a measure of task completion success. The baselines include both prompt-based methods (using large language models like GPT-4) and fine-tuning-based methods using LoRA. The table highlights WKM’s superior performance compared to other methods, especially on unseen tasks.
read the caption
Table 1: Main Results. The best results are marked in bold and the second-best results are marked with underline. All the prompt-based baselines (∞) are evaluated under one-shot prompting and all the fine-tuning-based baselines (ㅇ) are trained through LoRA. Red represents the changes of WKM relative to the optimal results in the baselines. WKM and agent model are different LoRAs sharing the same backbone.
Full paper#