↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Dashcam videos, while abundant and diverse, present challenges for neural rendering due to common windshield obstructions like reflections and stains. Existing methods, primarily designed for autonomous vehicle data, struggle with these issues, resulting in poor novel view synthesis.
DC-Gaussian tackles this problem by introducing three key innovations: 1) Adaptive Image Decomposition separates the transmission and obstruction images using a learnable opacity map, 2) Illumination-aware Obstruction Modeling handles obstructions under varying lighting conditions and manages reflections, and 3) Geometry-Guided Gaussian Enhancement incorporates geometry priors to improve rendering quality. Experiments show DC-Gaussian significantly outperforms existing methods in terms of fidelity and obstruction removal, demonstrating its potential for applications in autonomous driving and beyond.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and autonomous driving due to its focus on high-fidelity novel view synthesis from challenging dashcam videos. It directly addresses the significant issue of obstructions in such videos, a problem largely ignored by existing methods primarily focused on autonomous vehicle data. The proposed techniques, particularly the adaptive image decomposition and illumination-aware obstruction modeling, open new avenues for improving neural rendering in real-world, less controlled environments, pushing the boundaries of scene understanding and new view generation for broader applications.
Visual Insights#

This figure shows the effectiveness of the proposed DC-Gaussian method in removing obstructions from dash cam videos and generating high-fidelity novel views. Subfigure (a) displays a dash cam mounted in a vehicle. Subfigure (b) shows an original frame from the dash cam video containing obstructions such as reflections and occlusions. Subfigure (c) presents the novel view generated by DC-Gaussian, demonstrating the successful removal of these obstructions while maintaining high image quality.

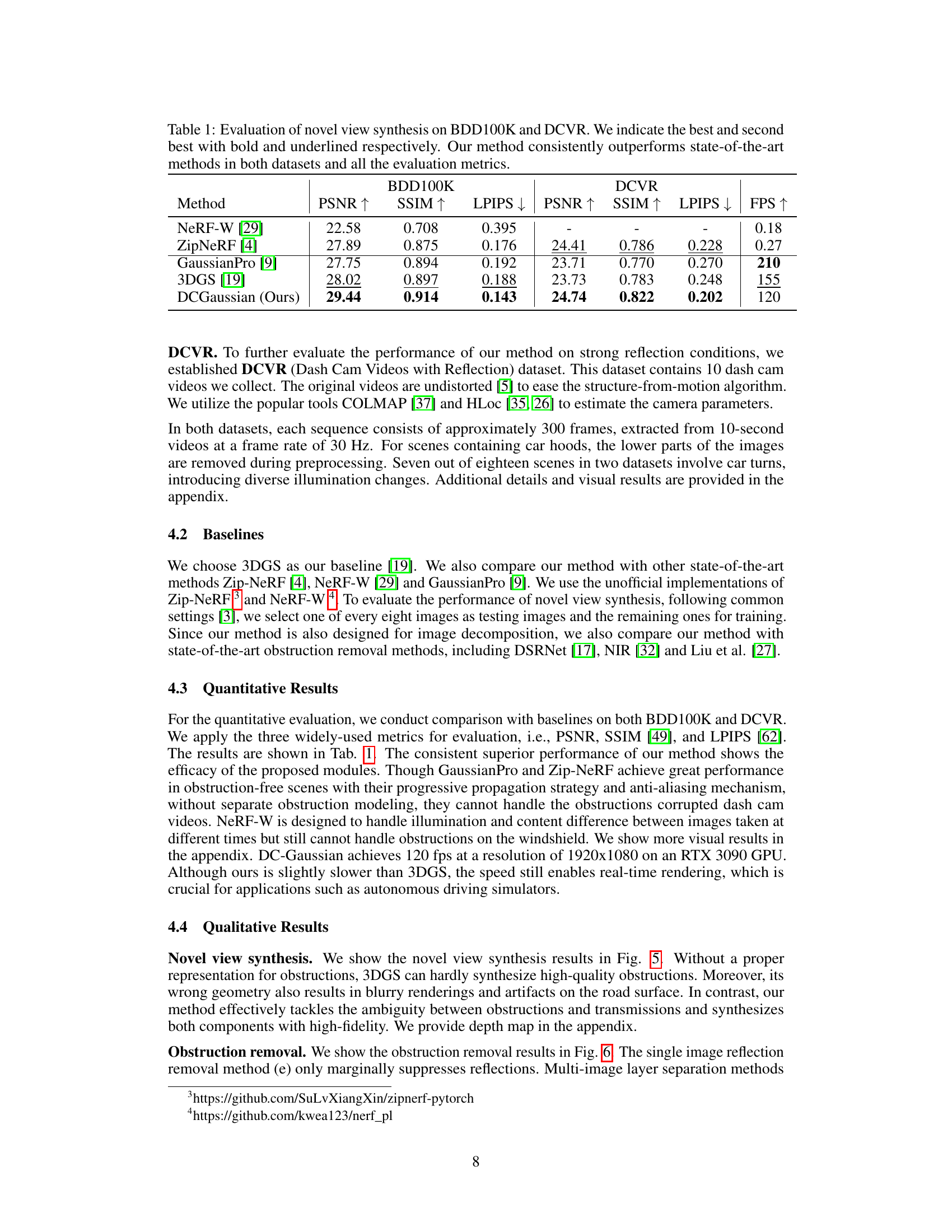
This table presents a quantitative comparison of novel view synthesis methods on two datasets: BDD100K and DCVR. The metrics used for evaluation are PSNR (higher is better), SSIM (higher is better), and LPIPS (lower is better), which assess the quality of the synthesized images. The table also includes the Frames Per Second (FPS) achieved by each method. The results show that the proposed DCGaussian method outperforms existing state-of-the-art methods on both datasets across all evaluation metrics.
In-depth insights#
Dashcam View Synth#
The subheading ‘Dashcam View Synth’ likely refers to a section discussing novel view synthesis techniques specifically tailored for dashcam video. This is a challenging problem due to the unique characteristics of dashcam footage, such as its often lower resolution, variable lighting conditions, and frequent obstructions (e.g., reflections, rain, snow). A key focus would be on obstruction removal or mitigation methods integrated with the view synthesis process, possibly leveraging techniques like image decomposition or inpainting. The research likely explores the trade-offs between real-time performance and visual fidelity, considering the computational demands of 3D reconstruction and rendering for dashcam video. Successful approaches might involve adapting existing neural rendering methods (e.g., NeRF or 3D Gaussian splatting) to handle the specific challenges presented by dashcam data, perhaps by incorporating additional features such as motion estimation or depth information from other sensors. Overall, this section would highlight advancements enabling the generation of realistic, obstruction-free views from dashcam footage, opening possibilities for applications in driver assistance systems, traffic analysis, and accident reconstruction.
Obstruction Removal#
The research paper tackles the challenge of obstruction removal in dashcam videos, a significant hurdle in neural rendering. Existing methods often struggle with the diverse and dynamic nature of obstructions (reflections, occlusions, stains), relying on assumptions that often don’t hold for real-world dashcam footage. The key innovation is an adaptive image decomposition module that separates transmission (the background scene) from obstructions. This approach avoids the limitations of methods imposing strict assumptions, such as out-of-focus or specific lighting cues, often unreliable for varied dashcam contexts. This is achieved by using a learnable opacity map, effectively handling the varying transparency of different obstruction types, ranging from opaque to semi-transparent. Furthermore, the model leverages illumination-aware obstruction modeling, addressing the dynamic intensity changes in reflections caused by varying light conditions. This is accomplished by employing a global-shared hash encoding which incorporates multi-resolution features to accurately model obstruction appearance, while a latent intensity modulation module adjusts reflection intensity based on camera positions. In doing so, the system successfully disentangles the obstructions, enabling a high-fidelity reconstruction of the underlying scene. Finally, a geometry-guided Gaussian enhancement strategy further refines details by incorporating geometry priors, improving the quality of the final rendering.
3DGS Enhancement#
The proposed 3DGS enhancement strategy is a crucial component of the DC-Gaussian method, addressing limitations in standard 3D Gaussian Splatting when applied to dashcam videos. Standard 3DGS struggles with obstructions because it treats them as static objects; the enhancement strategy directly tackles this by leveraging multi-view stereo (MVS) to identify areas less affected by obstructions. This multi-view consistency provides more reliable geometric priors, which are then used to refine the 3D Gaussian representation. The refinement process involves creating depth maps and filtering them to focus on areas with higher consistency. By incorporating this additional geometric information, the approach can significantly improve rendering details and sharpness, thus mitigating the negative effects of obstructions on novel view synthesis. The enhancement not only improves the quality of the rendered image but also enhances the accuracy of the geometric model. This is particularly important for scenes with reflections and occlusions common in dashcam recordings, helping to improve the overall fidelity and realism of the output views.
Illumination Effects#
Illumination significantly impacts the appearance and interpretation of images, especially in outdoor settings like those captured by dash cams. Variations in lighting conditions directly affect the intensity and visibility of reflections and occlusions, making consistent image processing and novel view synthesis challenging. The paper likely addresses this by proposing illumination-aware obstruction modeling, which could involve techniques like adapting model parameters based on detected lighting levels or using illumination-invariant features. This is crucial because a method’s robustness in handling reflections and occlusions depends on its ability to accurately model these obstructions under various lighting scenarios. Failure to account for illumination changes can lead to inaccuracies in depth estimation and geometry reconstruction, resulting in blurry or artifact-ridden synthesized images. The success of the proposed approach likely hinges on its effectiveness in mitigating the adverse effects of varying illumination on visual obstruction identification and subsequent processing.
Future Directions#
Future research directions for DC-Gaussian could explore extending its capabilities to handle multi-sequence video data, leveraging the abundance of dashcam footage available. This would require robust temporal modeling techniques to maintain scene consistency across longer recordings. Additionally, improving performance on dynamic scenes is crucial, perhaps through incorporating more sophisticated motion estimation and object tracking methods. Developing a more robust and versatile obstruction modeling module that generalizes well to diverse obstruction types and lighting conditions is also vital. Furthermore, investigating the integration of additional sensor modalities, such as LiDAR data, could enhance scene representation and improve robustness. Finally, exploring the application of DC-Gaussian to autonomous driving simulators would be valuable, requiring optimization for real-time performance and integration with existing simulator frameworks.
More visual insights#
More on figures

This figure shows the input and output of the proposed method. It demonstrates the ability of DC-Gaussian to remove obstructions (such as reflections and occlusions) from dash cam videos and generate high-fidelity novel views. (a) shows a dash cam. (b) displays an original video frame containing obstructions. (c) presents a novel view rendering produced by the DC-Gaussian model with the obstructions removed.

This figure illustrates the architecture of the DC-Gaussian framework, highlighting the key modules involved in modeling obstructions and generating novel views from dashcam videos. It shows how the framework adaptively handles obstructions with different opacities, leverages static motion priors, and incorporates illumination changes for more realistic reflection synthesis. The process begins with input images processed through SfM, 3DGS initialization, and proceeds through the Illumination-aware Obstruction Modeling, G3 Enhancement, and final rendering stages to produce the output images.

This figure demonstrates the effectiveness of the proposed method in handling varying lighting conditions. It shows image decomposition results (transmission and obstruction) and novel view synthesis under both strong and weak light. The results highlight the method’s ability to accurately model and render reflections with varying intensities, even when reflections are subtle and barely visible to the naked eye.

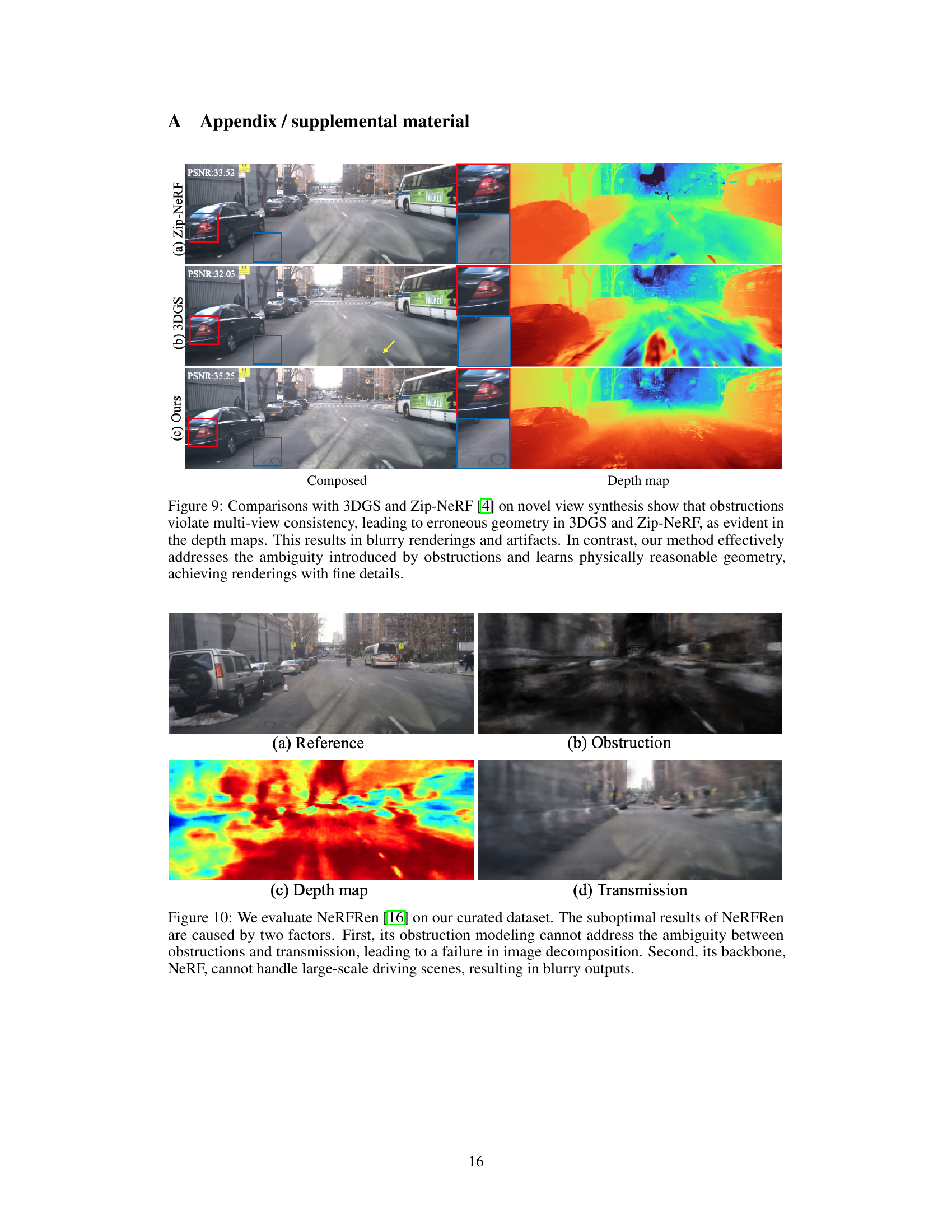
The figure compares novel view synthesis results of the proposed method and 3DGS. It demonstrates that 3DGS produces blurry renderings and artifacts due to obstructions violating multi-view consistency. The proposed method, however, faithfully synthesizes novel views and renders fine details in the transmission, resulting in a significant improvement in PSNR.

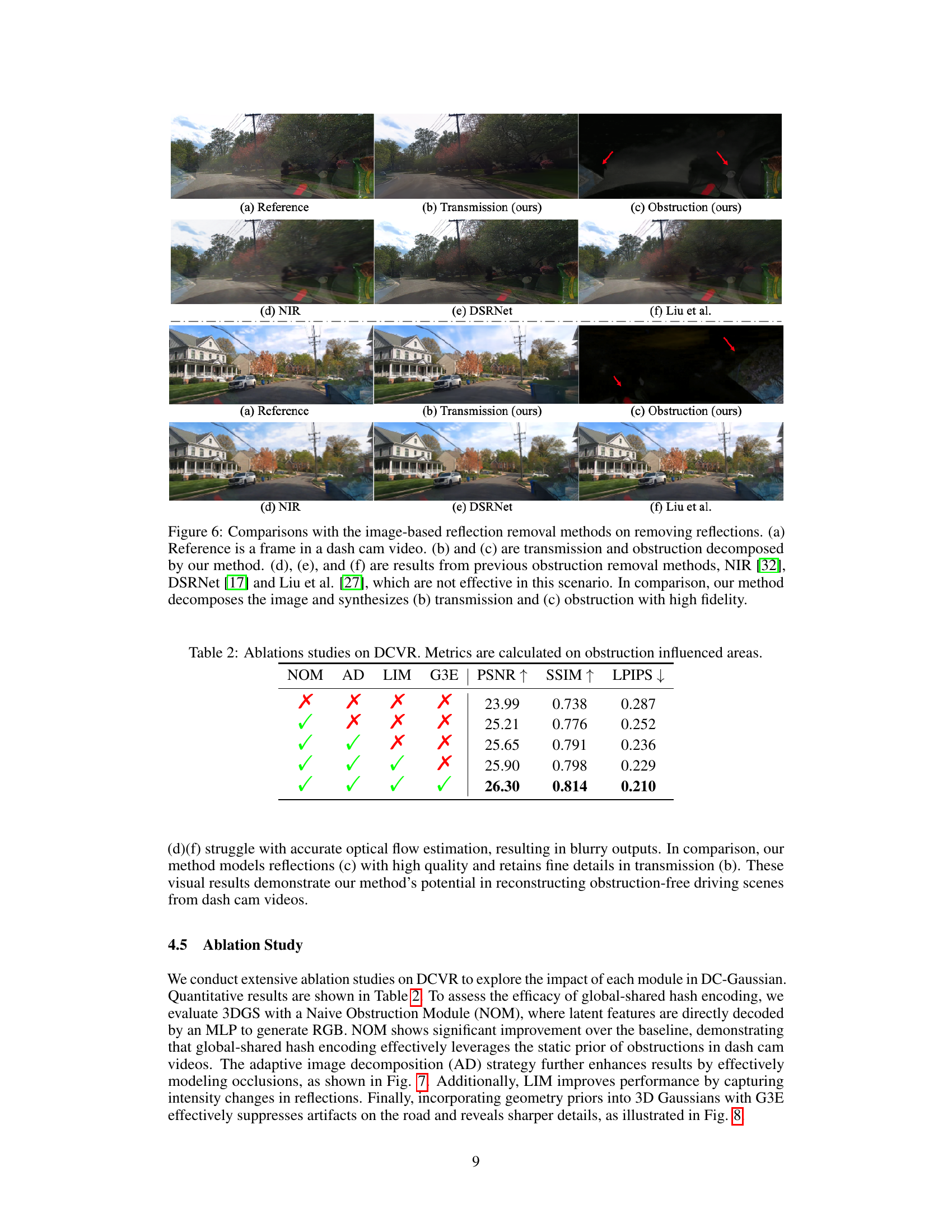
This figure compares the performance of the proposed method against other state-of-the-art single image and multi-image reflection removal methods. The results show that the proposed method is superior in decomposing the image into transmission and obstruction components and achieving higher fidelity in synthesizing these components.

This figure shows the results of an ablation study on the learnable opacity map used in the Adaptive Image Decomposition module of DC-Gaussian. The top row shows a reference image and the results of the transmission image with and without the learned opacity map. The bottom row shows a second example with the same comparison. The rightmost column displays the learned opacity map itself, indicating the areas of obstruction identified by the model. The results demonstrate that the inclusion of the learnable opacity map is essential for effectively identifying and handling obstructions, resulting in significantly improved view synthesis and artifact suppression.

This figure shows an ablation study on the Geometry-Guided Gaussian Enhancement (G3E) module. The left side shows the results with G3E enabled, demonstrating sharper details and suppressed artifacts, particularly noticeable in the zoomed-in region highlighted in red. The right side shows the results without G3E, showing a noticeable reduction in image clarity and the presence of artifacts.

This figure compares the novel view synthesis results of three methods: 3DGS, Zip-NeRF, and the proposed DC-Gaussian method. The results show that 3DGS and Zip-NeRF suffer from blurry renderings and artifacts due to inconsistencies in multi-view caused by obstructions. In contrast, DC-Gaussian produces high-fidelity renderings with fine details by effectively handling the ambiguities introduced by the obstructions.

This figure shows a comparison of the results of NeRFRen on a curated dataset with the ground truth. The results reveal that NeRFRen struggles to accurately represent obstructions because its model can’t handle the ambiguity between obstructions and the transmitted scene. Additionally, NeRFRen’s inability to handle the large scale of driving scenes leads to blurry outputs.

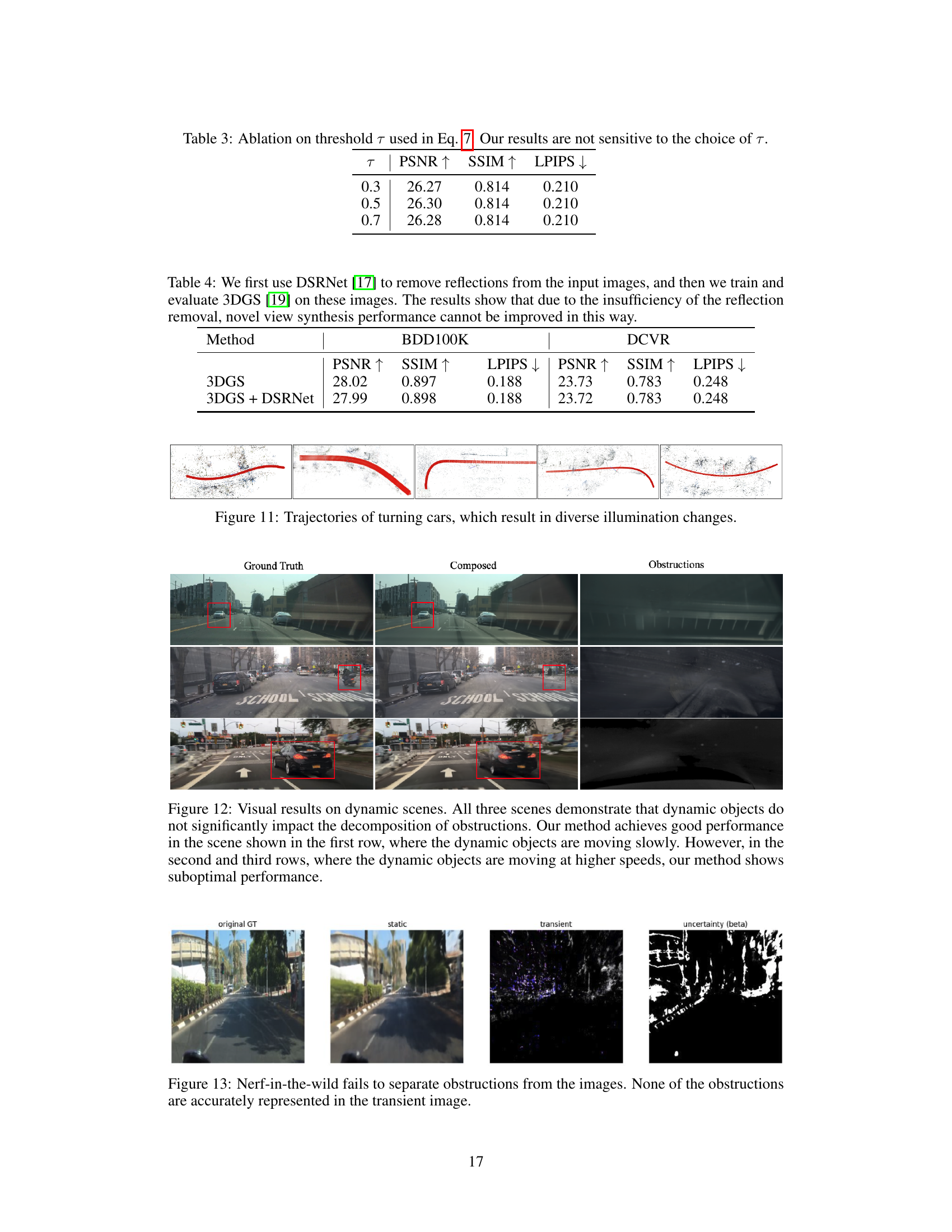
This figure shows trajectories of cars making turns. The varying car positions in the scene cause diverse illumination changes and variations in lighting conditions in each frame. This is important for understanding how the model handles different lighting scenarios during training and testing. The changes highlight the dynamic nature of the dash cam video data and the importance of addressing this aspect in improving 3D scene reconstruction.

This figure compares the performance of the proposed DC-Gaussian method against other state-of-the-art single image reflection removal methods for removing reflections from dashcam videos. The figure shows that the proposed method effectively decomposes the image into transmission and obstruction components, achieving high fidelity in both components, unlike the other methods which are not effective in this scenario.

This figure compares the results of a state-of-the-art NeRF model (NeRF-in-the-wild) with the proposed DC-Gaussian method for separating obstructions from dashcam video images. The figure shows that NeRF-in-the-wild fails to accurately separate static and transient components of the scene, particularly the obstructions on the windshield. In contrast, the DC-Gaussian method is designed to explicitly handle these obstructions, leading to improved separation and clearer representation of the scene.
More on tables
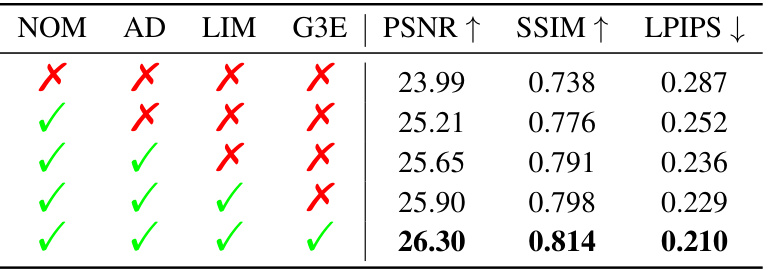
This table presents the ablation study results performed on the DCVR dataset. It shows the impact of each module (NOM, AD, LIM, G3E) on the performance metrics (PSNR, SSIM, LPIPS). The metrics are calculated only on the image regions affected by obstructions. The results demonstrate the contribution of each component in achieving better novel view synthesis and obstruction removal.

This table presents the results of an ablation study on the threshold parameter τ used in Equation 7 of the paper. The study varied τ across three values (0.3, 0.5, and 0.7) and measured the impact on three evaluation metrics: PSNR, SSIM, and LPIPS. The results show that the performance is relatively consistent across the different values of τ, indicating that the method is not highly sensitive to the choice of this parameter.

This table presents a quantitative comparison of the proposed DC-Gaussian method against several state-of-the-art novel view synthesis methods on two benchmark datasets: BDD100K and DCVR. The evaluation metrics used are PSNR, SSIM, and LPIPS, assessing the quality of novel view synthesis. The results demonstrate that DC-Gaussian consistently outperforms other methods across all metrics and on both datasets.
Full paper#