↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large language models (LLMs) are powerful but computationally expensive, making interactive inference on consumer devices challenging. Existing speculative decoding methods, while promising, often don’t scale effectively to consumer hardware’s limited memory and bandwidth. This necessitates offloading model parameters to RAM, slowing down inference significantly.
The paper introduces SpecExec, a new speculative decoding algorithm designed for consumer devices with parameter offloading. SpecExec employs a draft model to predict likely next tokens, building a ‘cache’ tree of probable continuations, which are then validated in a single pass by the target model. This drastically reduces the number of target model queries, leading to a substantial speedup. The experiments demonstrate significant improvements in inference speed for large LLMs on consumer GPUs with RAM offloading, even with quantization.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language model (LLM) inference because it demonstrates significant speed improvements in LLM inference on consumer-grade hardware. This addresses a key limitation of current LLMs, making them more accessible and practical for a wider range of applications and users. The techniques presented, particularly the use of speculative decoding with parameter offloading, open new avenues for optimization, allowing researchers to push the boundaries of interactive LLM applications on consumer devices. The findings offer valuable insights into efficient LLM deployment strategies, particularly for resource-constrained environments.
Visual Insights#
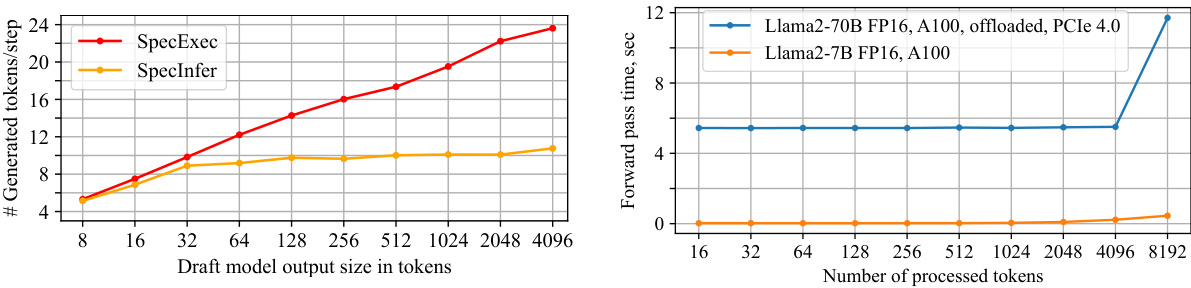
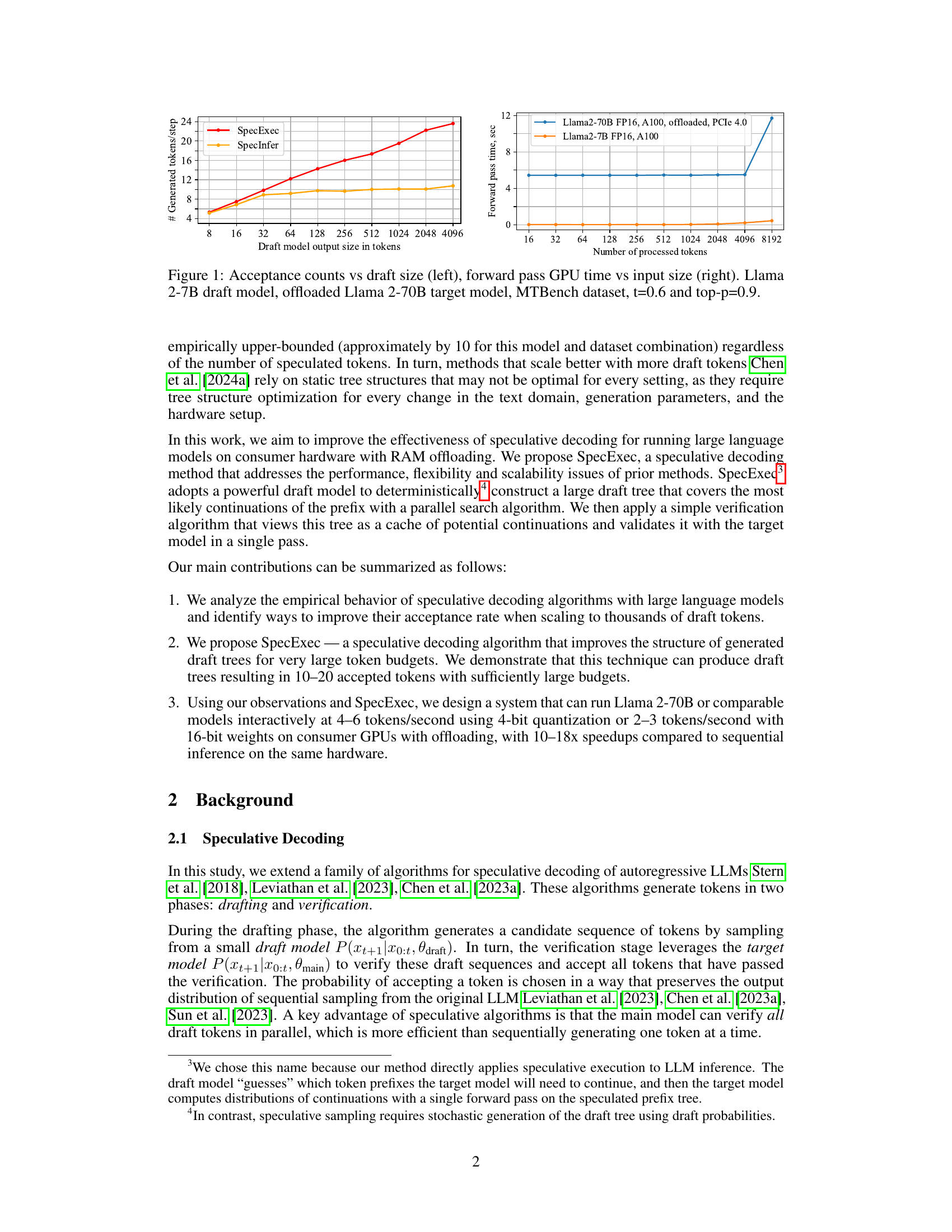
This figure shows two graphs. The left graph displays the relationship between the number of tokens accepted by the target model (Llama 2-70B) and the size of the output from the draft model (Llama 2-7B) during speculative decoding. The right graph illustrates the GPU forward pass time for processing different input sizes on an A100 GPU, comparing Llama 2-7B and an offloaded Llama 2-70B. The experiments used the MTBench dataset with temperature (t) of 0.6 and top-p of 0.9.

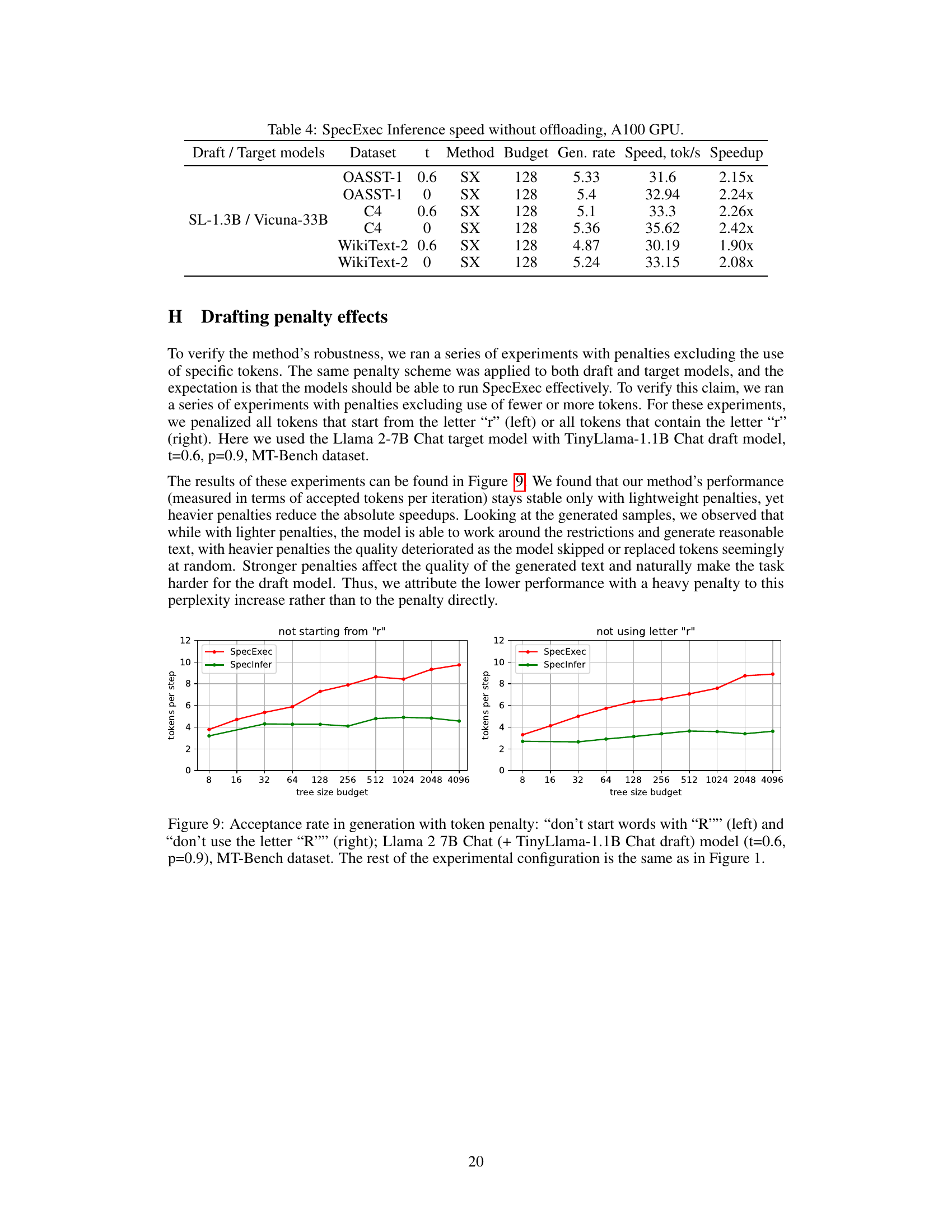
This table presents the inference speed of the SpecExec and SpecInfer methods on an A100 GPU with RAM offloading for various large language models (LLMs). It shows the speed in tokens per second, the generation rate (number of draft model tokens accepted per target model iteration), and the speedup achieved compared to a baseline. The table includes results for different LLMs (Llama 2, Mistral, Llama 3) with and without quantization, and uses two different datasets (OASST, MTBench). The ’t’ column indicates whether temperature sampling was used (0.6 or 0).
In-depth insights#
Speculative Execution#
Speculative execution, in the context of large language model (LLM) inference, represents a paradigm shift in how we approach the computational demands of generating text. Traditional methods process tokens sequentially, leading to significant latency. Speculative execution, however, attempts to circumvent this by predicting multiple potential continuations using a lighter model (the ‘draft model’). This prediction phase runs in parallel, significantly increasing throughput. The computationally expensive target model is used to only verify and select the most probable continuations produced by the draft model, thereby optimizing the process. This approach trades off some accuracy for a massive speed increase. Parameter offloading and 4-bit quantization are key optimizations for deploying speculative execution on resource-constrained consumer devices. The core innovation often lies in intelligently constructing a ‘cache’ of likely token sequences. Instead of random sampling, a deterministic search algorithm (often a modified version of Dijkstra’s algorithm) helps to select the most probable future tokens for pre-computation. This strategy prioritizes efficiency, sacrificing some accuracy, but offering substantial speed-ups in interactive inference scenarios which outweigh this trade-off for many applications. The effectiveness strongly depends on the quality and characteristics of both the draft and target models; poor alignment can hinder performance. Overall, speculative execution offers a promising approach to make LLM inference more efficient and responsive on a wider range of devices.
Parallel Decoding#
Parallel decoding techniques significantly accelerate large language model (LLM) inference by processing multiple token possibilities concurrently. Instead of sequentially generating one token at a time, these methods leverage the power of parallel processing to explore numerous potential continuations simultaneously. This approach dramatically reduces the latency associated with sequential decoding, particularly beneficial for interactive applications requiring real-time responses. While various parallel decoding strategies exist, they often involve tradeoffs between speed and accuracy. Efficient parallel implementations require careful management of computational resources to ensure that the gains from parallelism outweigh the overhead of managing multiple computation threads. Furthermore, the effectiveness of parallel decoding is highly dependent on the specific hardware architecture and the characteristics of the LLM itself, including its size and architecture. Optimization for specific hardware is crucial for achieving optimal performance and minimizing latency. Future research should focus on developing more sophisticated parallel decoding strategies that can further improve speed while maintaining high-quality text generation.
LLM on CPU#
Running LLMs directly on CPUs presents significant challenges due to their limited computational resources and memory bandwidth compared to specialized hardware like GPUs. CPU-based LLM inference is considerably slower, often orders of magnitude slower, than GPU-based inference for large language models. This limitation stems from the need to load model parameters and activations into the CPU’s memory, which can be a major bottleneck. Despite this, exploring CPU inference remains relevant due to its potential for edge deployment and scenarios where GPUs are unavailable. Efficient techniques such as quantization, pruning, and optimized algorithms are crucial to improve performance in the context of CPU-based inference. Research into this area can lead to advancements in mobile or embedded applications where power consumption and computational constraints necessitate solutions for running LLMs on less powerful, energy-efficient hardware. The development of novel inference methods designed specifically for CPU architectures is thus essential for extending the reach of LLMs to resource-constrained settings.
4-bit Quantization#
4-bit quantization is a crucial technique for deploying large language models (LLMs) on consumer devices with limited memory. By significantly reducing the memory footprint of the model parameters, 4-bit quantization makes it feasible to run otherwise intractable models. The paper highlights that while higher bit-depth quantization (e.g., 16-bit) may provide slightly better accuracy, the performance gains from 4-bit quantization, in conjunction with other optimization strategies (such as parameter offloading and speculative decoding), are substantial enough to enable interactive LLM inference on consumer-grade hardware. The trade-off between accuracy and efficiency is a key consideration, and the choice of quantization level should depend on the specific application requirements and the available hardware resources. The researchers demonstrate that even with 4-bit quantization, SpecExec still achieves impressive speeds, proving the practicality and effectiveness of this approach. The success of 4-bit quantization underscores the importance of exploring low-precision techniques for model deployment in resource-constrained environments.
Future Work#
The authors suggest several promising avenues for future research. Improving the efficiency of the SpecExec algorithm is a key goal, especially regarding the handling of very large draft trees. They also highlight the need for further research into quantization techniques, particularly methods that minimize accuracy loss while maintaining speed improvements. Exploring alternative methods for draft tree construction and developing more sophisticated techniques for selecting the most promising token candidates are also mentioned. Finally, extending SpecExec to various architectures beyond consumer-grade GPUs could unlock significant performance gains in different settings, and broadening the range of language models supported would significantly increase its applicability. Overall, the future directions are focused on enhancing the algorithm’s performance, expanding its capabilities, and widening its applicability across a broader range of hardware and language models.
More visual insights#
More on figures

This figure compares the cumulative probability of the most likely tokens generated by the Llama-2 70B Chat model to the cumulative probability of tokens selected by various draft models (Llama-2 7B, Llama-2 13B, TinyLlama 1B, and JackFram 160M). The x-axis represents the number of tokens considered (Top-k), while the y-axis shows the cumulative probability. The results are based on the OASST1 dataset. The figure demonstrates how well different draft models can predict the high-probability tokens of the target Llama-2 70B Chat model.
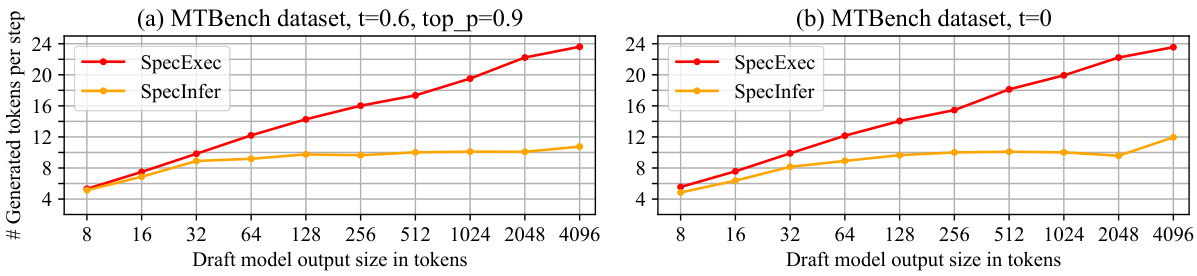
This figure compares the performance of SpecExec and SpecInfer in terms of the number of generated tokens per step, varying the size of the draft model’s output. The x-axis represents the draft model output size (in tokens), and the y-axis shows the number of generated tokens per step. Two subfigures are presented, one for a setting with temperature 0.6 and top_p 0.9, and another with temperature 0. The results demonstrate that SpecExec consistently outperforms SpecInfer, particularly as the draft budget increases, showcasing its efficiency in speculative decoding with larger draft sizes.
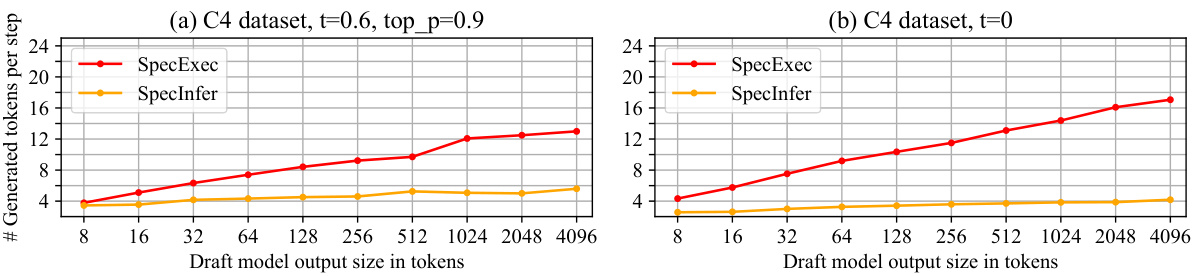
This figure shows the relationship between the number of tokens generated per step and the size of the draft model’s output. It compares the performance of SpecExec and SpecInfer, two speculative decoding algorithms, using Llama 2-7B Chat as the draft model and Llama 2-70B Chat as the target model. The experiment uses the MTBench dataset, and the results are obtained using an A100 GPU. The graph illustrates that SpecExec consistently outperforms SpecInfer, particularly when the draft budget size is large.
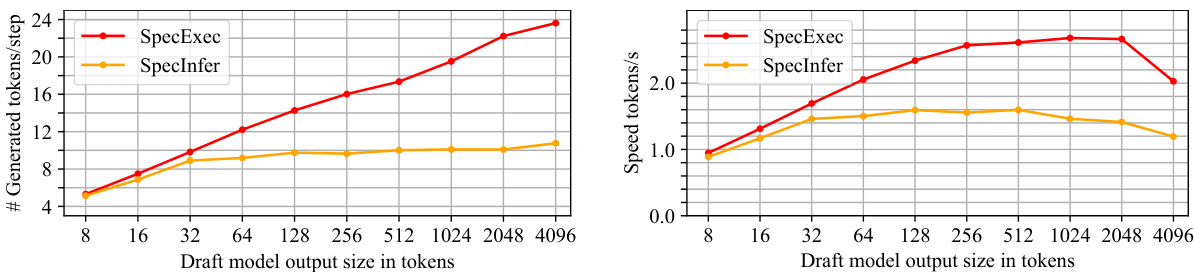
This figure shows the performance comparison of SpecExec and SpecInfer in terms of generated tokens per step and inference speed (tokens per second) with varying draft model output sizes. The experiment uses Llama 2-7B Chat as the draft model and Llama 2-70B Chat as the target model on the MTBench dataset, performed on an A100 GPU. The results demonstrate the effect of the draft budget size on the efficiency of speculative decoding algorithms.
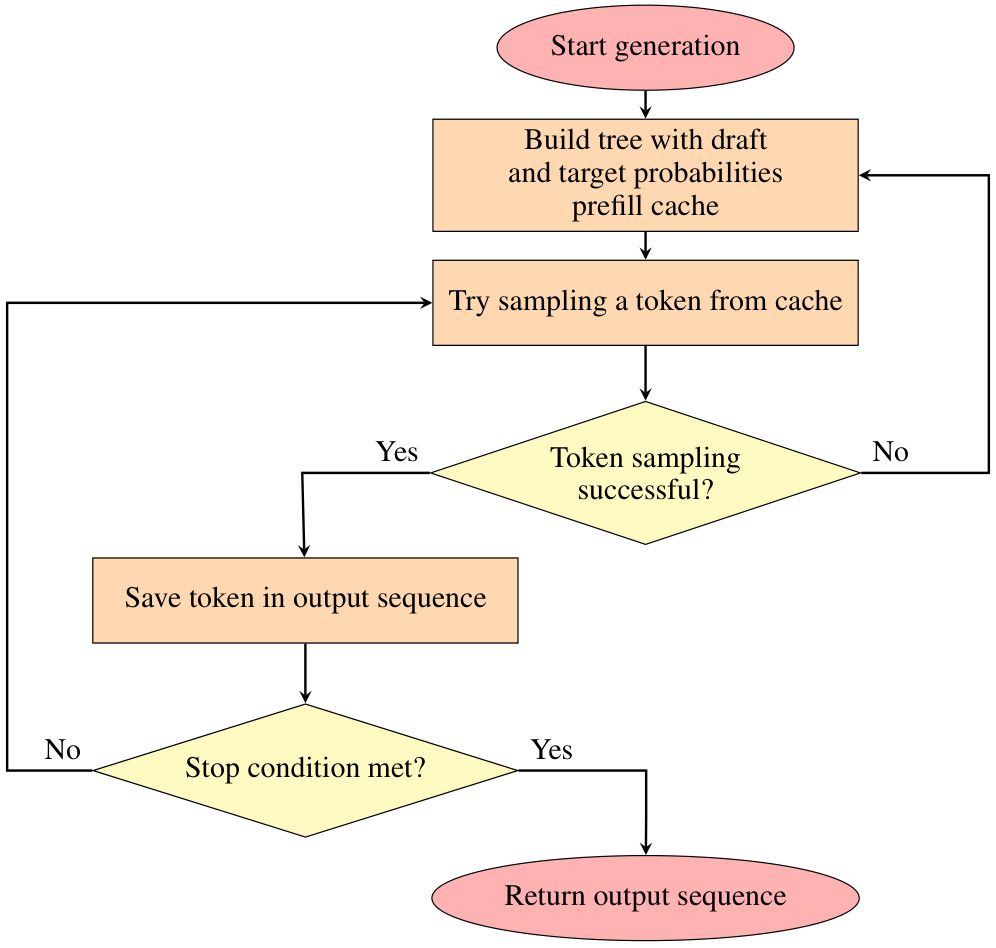
This flowchart shows the steps of the Speculative Execution algorithm. It starts by generating text and building a tree using a draft model and pre-filling a cache of probabilities from the target model. It then attempts to sample the next token from the cache. If successful, the token is added to the output sequence; otherwise, the algorithm recalculates the cache. The process continues until a stop condition is met, at which point the output sequence is returned. This approach aims to improve the speed and efficiency of large language model inference by predicting and caching likely next tokens.

This figure shows the relationship between the number of accepted tokens and the size of the draft model output for four different draft models: Llama 2 13b chat, Llama 2 7b chat, TinyLlama 1.1B Chat, and JackFram/llama-160m. The x-axis represents the draft model output size in tokens, and the y-axis shows the number of accepted tokens. The figure demonstrates that larger draft models generally lead to a higher number of accepted tokens. The results highlight the effectiveness of larger, more capable draft models in SpecExec for improving the acceptance rate during speculative decoding.
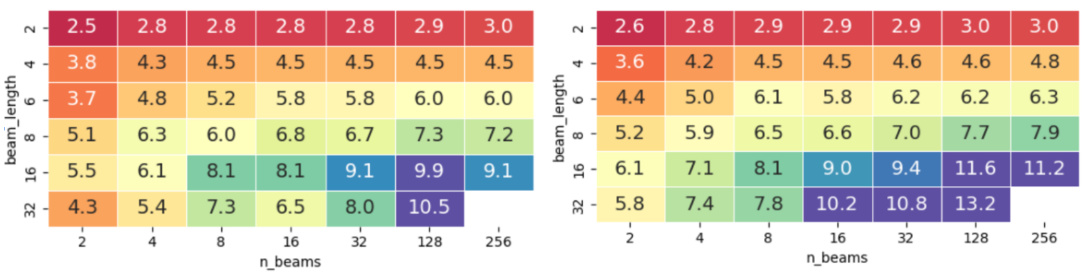
This figure shows the relationship between the draft budget size and the generation rate (number of tokens generated per step) for two different speculative decoding methods, SpecExec and SpecInfer. The experiment uses Llama 2-7B Chat as the draft model and Llama 2-70B Chat as the target model with the MTBench dataset, using an A100 GPU. It demonstrates how the number of generated tokens per step changes as the size of the draft model output increases for each method. The results show how SpecExec outperforms SpecInfer, especially with larger draft sizes. This comparison highlights the performance advantage of SpecExec in handling large draft budgets.

This figure shows the impact of token penalties on the performance of SpecExec and SpecInfer. Two different penalty schemes were tested: one where tokens starting with the letter ‘r’ were penalized, and another where all tokens containing the letter ‘r’ were penalized. The results demonstrate that SpecExec is more robust to token penalties than SpecInfer, maintaining a higher acceptance rate even with heavier penalties.
More on tables
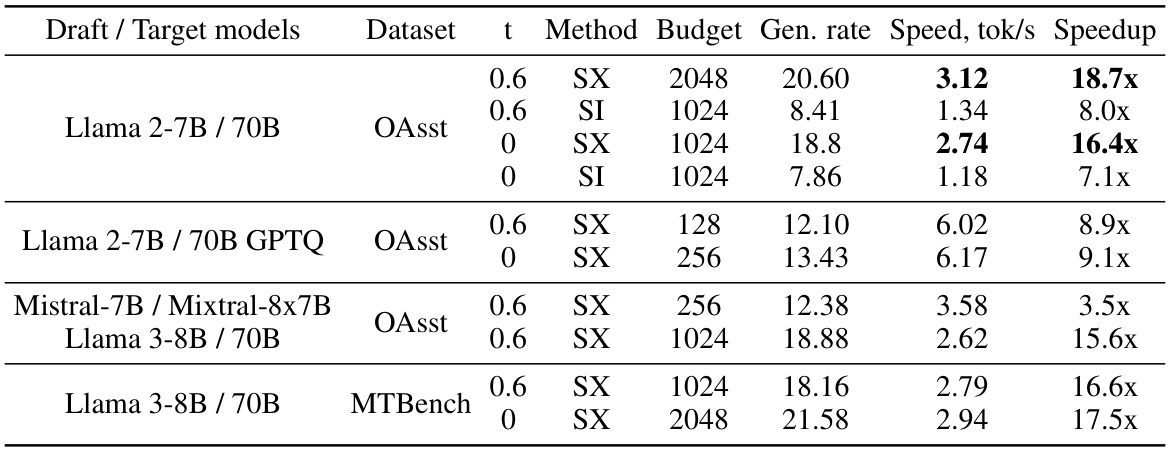
This table presents the inference speed results obtained using Speculative Execution (SpecExec) and SpecInfer methods on an A100 GPU with RAM offloading. The experiments were conducted using several large language models (LLMs) in both Chat and Instruct configurations. The table shows the inference speed (tokens per second), generation rate (average number of draft tokens accepted per target model iteration), the draft model budget size, and the speedup achieved compared to a baseline method (SpecInfer).

This table presents the inference speed of the SpecExec model on various consumer-grade GPUs with offloading enabled. It uses the Llama 2 70B-GPTQ model as the target model and the OpenAssistant dataset for evaluation. The table shows the generation rate (tokens per second) and speedup compared to a baseline (SpecInfer). Different draft models and budget sizes are tested, demonstrating the effects of hardware and parameter choices on performance.
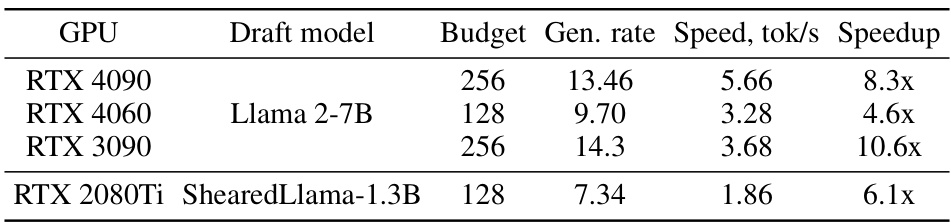
This table presents the inference speed of the SpecExec model on various consumer-grade GPUs using offloading. It shows the impact of different GPUs (RTX 4090, RTX 4060, RTX 3090, and RTX 2080Ti) and draft model choices (Llama 2-7B and ShearedLlama-1.3B) on the generation rate (tokens per second) and speedup compared to a baseline. The budget refers to the number of tokens considered in the draft tree. The table highlights the effectiveness of SpecExec across various hardware configurations, showcasing its potential for interactive LLM inference on consumer-grade devices.
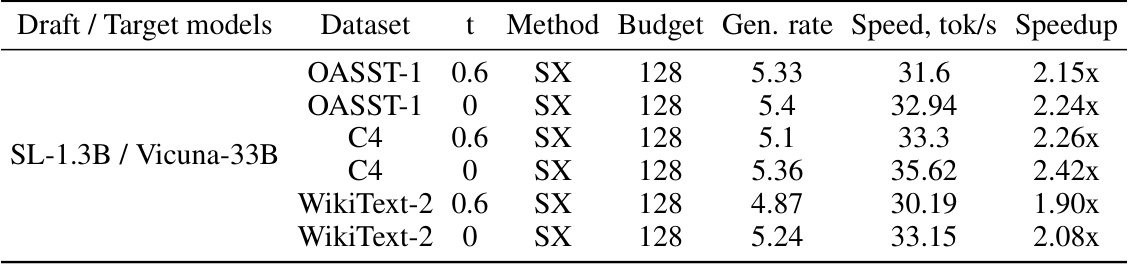
This table presents the results of experiments evaluating the inference speed of SpecExec without offloading, using an A100 GPU. It shows the generation rate (average number of draft model tokens accepted per target model iteration), speed in tokens per second, and speedup compared to a baseline for different models (SL-1.3B / Vicuna-33B), datasets (OASST-1, C4, WikiText-2), and temperature settings (t = 0.6 and t = 0). The budget refers to the maximum number of tokens in the draft tree.
Full paper#