↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
High-fidelity 3D human reconstruction from a single image is a fundamental yet challenging task in computer vision. Existing methods often rely on multiple images, time-consuming optimization, or compromise on reconstruction quality. These limitations hinder broader applications.
HumanSplat tackles this challenge by integrating a novel-view synthesizer (2D multi-view diffusion model) and a latent reconstruction transformer with human structure priors. This unified framework directly predicts Gaussian Splatting properties, avoiding per-instance optimization. The hierarchical loss focusing on crucial details like faces ensures high-fidelity results. Extensive experiments demonstrate superior performance compared to existing methods in terms of speed and realism.
Key Takeaways#
Why does it matter?#
This paper is important because it presents HumanSplat, a novel and efficient method for high-fidelity 3D human reconstruction from a single image. This addresses a significant challenge in computer vision and has broad applications in various fields such as social media, gaming, and e-commerce. The method’s generalizability and speed surpass existing state-of-the-art techniques, opening new avenues for research in single-image 3D reconstruction and related applications.
Visual Insights#
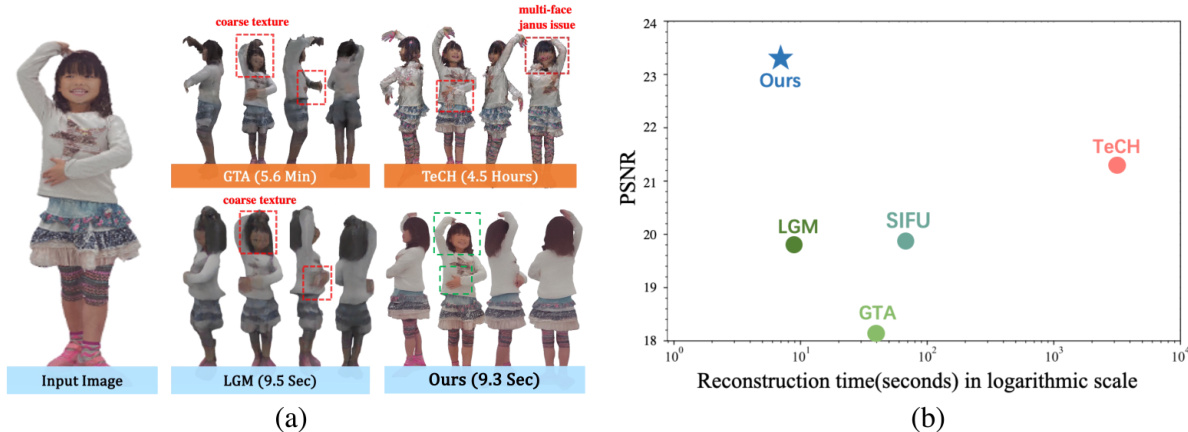
This figure shows a comparison of the proposed HumanSplat method with other state-of-the-art single-image human reconstruction methods. Part (a) presents qualitative results, demonstrating HumanSplat’s superior rendering quality and faster speed compared to LGM, GTA, and TeCH. Part (b) provides a quantitative comparison of the methods on the Twindom dataset, showing HumanSplat achieves the best PSNR score with the shortest reconstruction time.

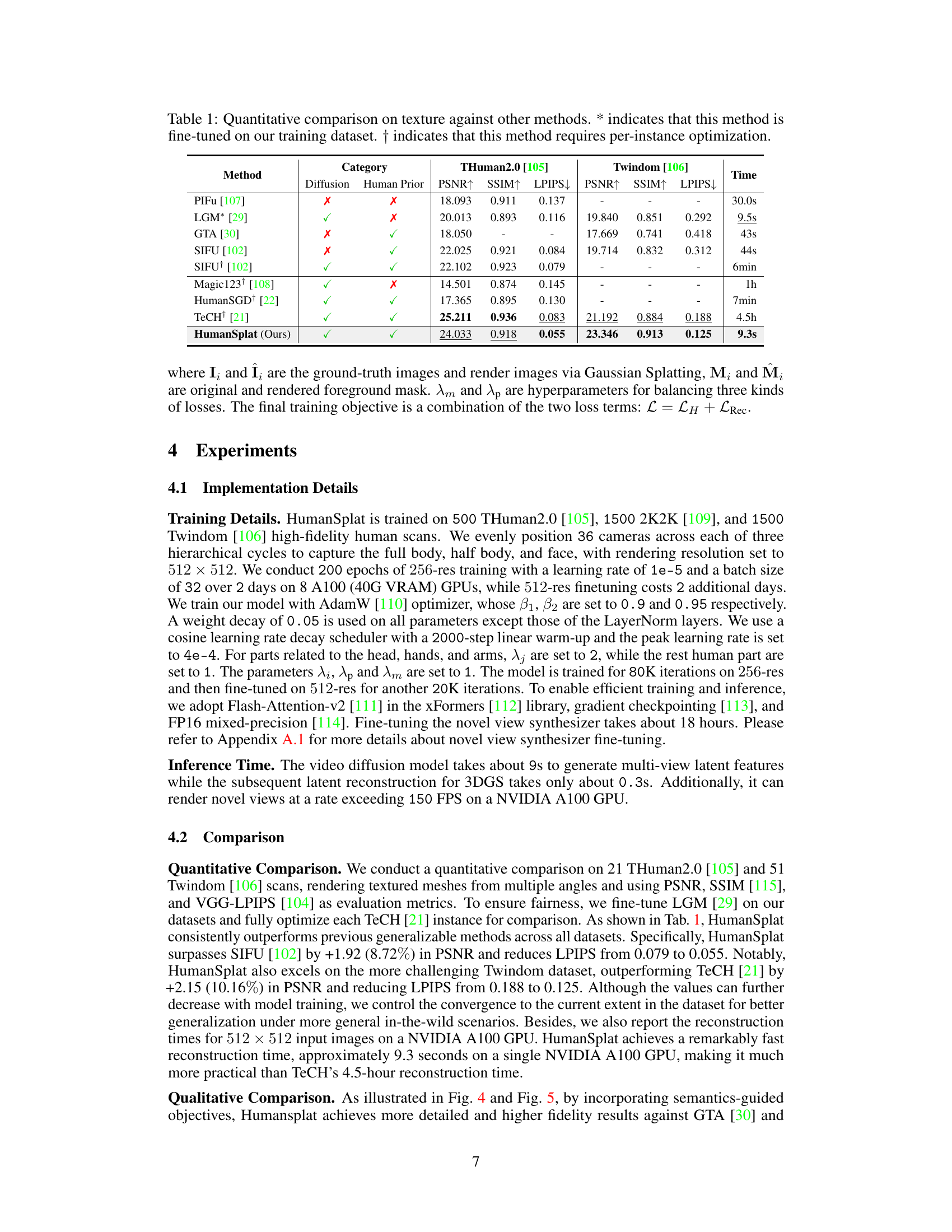
This table presents a quantitative comparison of the proposed HumanSplat method against several state-of-the-art methods on two benchmark datasets: THuman2.0 and Twindom. The comparison focuses on texture quality and is evaluated using PSNR, SSIM, and LPIPS metrics. The table also indicates whether methods were fine-tuned on the training dataset and whether they require per-instance optimization. Higher PSNR and SSIM scores, and lower LPIPS scores, indicate better texture quality.
In-depth insights#
Single-Image 3DGS#
Single-image 3D Gaussian Splatting (3DGS) presents a significant challenge and opportunity in 3D human reconstruction. Traditional 3DGS methods typically rely on multiple views to capture sufficient geometric and textural information for accurate reconstruction. A single image, however, drastically reduces the available data, making accurate 3D modeling difficult. This limitation necessitates innovative approaches to effectively infer the missing information, such as leveraging strong priors about human anatomy and appearance. The key would be to develop robust methods for hallucinating unseen parts of the body and clothing and to refine the splatting parameters using a combination of 2D image features and learned 3D priors. Success in single-image 3DGS would lead to more efficient and practical human reconstruction applications, paving the way for wider adoption in virtual and augmented reality, gaming, and other industries where high-fidelity 3D human models are needed. A key focus should be on creating a method that is both accurate and generalizable across different individuals, poses, and clothing styles.
Diffusion Model Use#
The utilization of diffusion models in the research paper presents a powerful technique for generating high-fidelity, multi-view images of humans from single input images. The core innovation lies in leveraging a fine-tuned multi-view diffusion model as an appearance prior, effectively hallucinating unseen parts of the human body. This model is not just a component but an integral part of a unified framework that cleverly integrates geometric priors and latent representations. The generated latent features are further refined by the latent reconstruction transformer, which adeptly combines them with human structure priors. The model cleverly integrates structure and appearance using a transformer framework. This synergy ensures high-quality texture modeling and robust 3D reconstruction. This approach addresses a significant limitation in existing single-image human reconstruction techniques, which often struggle with complex clothing and require extensive optimization. By directly inferring Gaussian properties from the diffusion latent space, the model achieves both generalizability and high-quality reconstruction, setting a new benchmark for the field.
Structure Priors Help#
The incorporation of structure priors significantly enhances the accuracy and robustness of 3D human reconstruction from a single image. Structure priors, such as those derived from parametric body models (like SMPL), provide a strong skeletal framework to guide the reconstruction process. This is particularly crucial when dealing with single-view data, where significant portions of the human body may be occluded or otherwise unseen. By integrating these geometric constraints with learned representations, the model is less susceptible to hallucinating unrealistic or inconsistent shapes. The use of structure priors also reduces the ambiguity inherent in under-constrained problems, leading to more stable and reliable results, thus reducing per-instance optimization or multi-view input requirements. Importantly, the effectiveness of structure priors is augmented by techniques such as projection-aware attention, which ensures that the prior information is effectively integrated with the learned features. This combination of geometric priors and intelligent integration mechanisms results in more accurate, detailed, and visually compelling human reconstructions compared to approaches that rely solely on learned representations.
Hierarchical Losses#
The concept of “Hierarchical Losses” in the context of 3D human reconstruction suggests a multi-level approach to training a model. It likely involves a loss function that operates on different levels of detail or abstraction, such as low-level features (e.g., pixel-wise differences) and high-level features (e.g., semantic segmentation). This approach can improve the accuracy and fidelity of the final reconstruction. By incorporating both low-level details and high-level structural information, the model learns to generate results that are both photorealistic and semantically correct. The use of weights or different emphasis on specific levels of the hierarchy could enable the model to focus on crucial details in visually sensitive areas, such as faces and hands, while ensuring overall consistency. A hierarchical loss function could also facilitate learning more complex relationships between different parts of the human body, and thus improve generalization performance. This multi-scale approach is commonly used to address the challenges of under-constrained problems where a single level of representation is insufficient. Therefore, the use of a hierarchical loss function is well-suited for 3D human reconstruction where the reconstruction task is quite challenging from a single input image.
Future Enhancements#
Future enhancements for single-image human reconstruction should prioritize improving the handling of complex clothing and diverse body shapes. Current methods often struggle with loose or intricate clothing styles, hindering accurate mesh generation. Addressing this requires exploring advanced techniques like incorporating more sophisticated garment modeling and potentially leveraging generative models trained on broader datasets featuring diverse clothing and body types. Another area for improvement is enhancing the robustness of the system to variations in pose and viewpoint. The model should be more resilient to noisy or low-resolution inputs and better handle extreme poses or occlusions. Finally, future work should focus on boosting efficiency to facilitate real-time or near real-time performance. This may involve exploring more efficient network architectures, optimized training procedures, or perhaps the use of specialized hardware acceleration. A focus on improved generalization is critical; the model should be less reliant on specific datasets and more adaptable to unseen data, paving the way for wider practical applications.
More visual insights#
More on figures

This figure illustrates the overall architecture of the HumanSplat model. It shows three main stages: (a) A novel-view synthesizer (a fine-tuned multi-view diffusion model) that generates multi-view latent features from a single input image. (b) A latent reconstruction transformer that integrates these latent features with human geometric and semantic priors to predict the Gaussian splatting properties. (c) Semantics-guided objectives that refine the model’s output for higher-fidelity reconstruction and rendering.
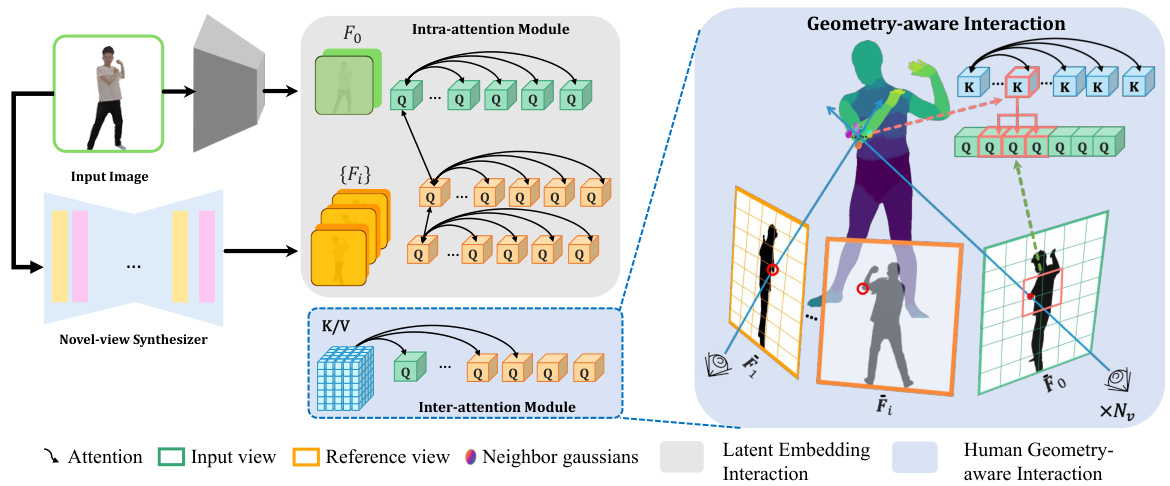
This figure illustrates the architecture of the Latent Reconstruction Transformer, a key component of the HumanSplat model. It shows how multi-view latent features (from a novel-view synthesizer) and human geometric priors are integrated. The process begins with dividing the latent features into patches and processing them through an intra-attention module to capture spatial correlations. Then, a geometry-aware interaction module incorporates human geometric priors using a novel projection-aware attention mechanism. This mechanism improves efficiency and robustness by focusing attention within local windows of the 2D projection of the 3D geometric prior. Finally, the processed features are used to decode the attributes of 3D Gaussians for the final 3D representation.

This figure compares the qualitative results of the proposed HumanSplat method against three other state-of-the-art methods (TeCH, GTA, and LGM) on three datasets (THuman2.0, Twindom, and in-the-wild images). The comparison is based on visual quality and focuses on the reconstruction of human faces and clothing. HumanSplat shows better quality in most cases, while TeCH occasionally has clearer results but suffers from identity preservation issues.

This figure presents a qualitative comparison of the proposed HumanSplat model against the LGM* method. It showcases the ability of HumanSplat to generate high-fidelity 3D human reconstructions from single images, even in challenging scenarios. The images demonstrate HumanSplat’s robustness to diverse poses, body types, clothing styles, and viewpoints. The results highlight the superior performance of HumanSplat in terms of detail preservation and overall reconstruction quality compared to LGM*. The in-the-wild images show HumanSplat successfully reconstructs complex poses and clothing details, which the other method struggles with.

This figure presents a qualitative comparison of the proposed HumanSplat method against the HumanSGD method on in-the-wild images. It showcases the results of both methods on several examples, highlighting HumanSplat’s superior ability to reconstruct realistic human models with detailed clothing and body shapes, even when dealing with complex poses or less-than-ideal image quality. The figure demonstrates the advantages of HumanSplat in terms of accuracy and visual fidelity.

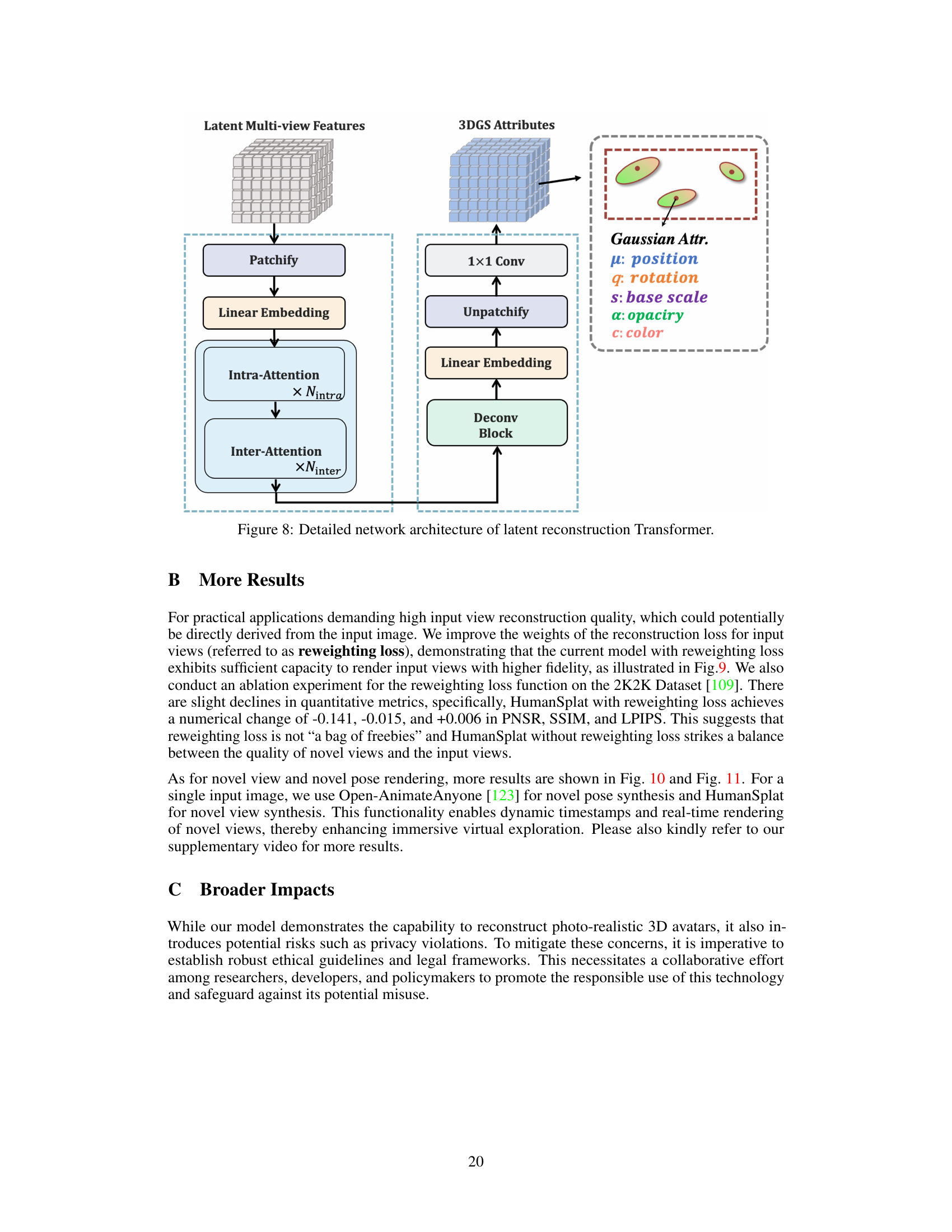
This figure illustrates the detailed architecture of the latent reconstruction Transformer, a key component of the HumanSplat model. It shows the flow of information from latent multi-view features to the final 3D Gaussian Splatting (3DGS) attributes. The process involves patchifying the input features, applying linear embedding, and using intra-attention and inter-attention modules to capture spatial and cross-view relationships. The attributes of the 3D Gaussians—position, rotation, scale, opacity, and color—are then predicted through a deconvolution block. This transformer efficiently integrates geometric and latent features to reconstruct high-fidelity human representations.
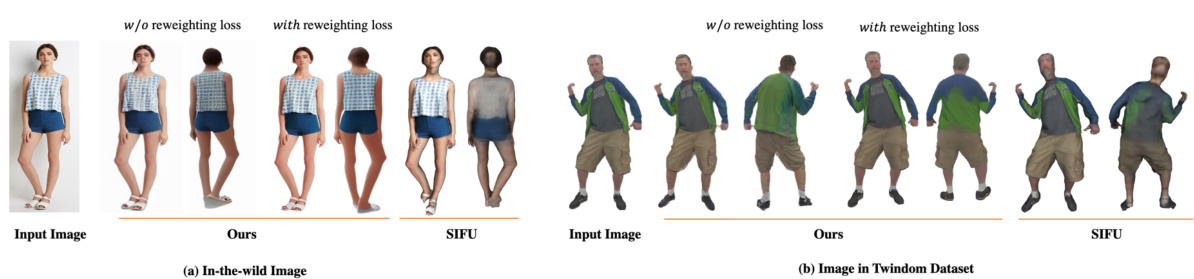
This figure presents an ablation study to evaluate the effect of the reweighting loss on the HumanSplat model. It compares the results of three different models: the original HumanSplat model, the HumanSplat model trained with reweighting loss, and the SIFU model. The results show that the HumanSplat model trained with reweighting loss produces better results than the original HumanSplat model and the SIFU model, especially in terms of texture quality.

This figure shows the qualitative comparison results of HumanSplat on the diversified evaluation datasets. The left column shows the input image, and the right columns show the novel view rendering results of HumanSplat. It demonstrates the capability of the model to generate high-fidelity novel views from single images.

This figure shows qualitative results of 4D Gaussian Splatting on in-the-wild images. It demonstrates the model’s capability to generate novel views and poses of humans. The figure is organized into four rows. Each row shows a sequence of images, starting from an input image and transitioning through various novel views and poses. The results highlight the model’s ability to accurately reconstruct human appearance and handle diverse clothing styles and body poses, demonstrating its potential for applications in fields like virtual reality, gaming, and fashion.
More on tables

This table presents the ablation study results for different design choices of the HumanSplat model, evaluated on the 2K2K dataset. It compares the performance with various configurations, such as different reconstruction spaces (pixel space vs. latent space using VAE), the impact of geometric prior initialization (using ground truth SMPL parameters, estimated SMPL parameters, or no SMPL parameters at all), and different projection methods (projection-only versus using a window of size 2). The metrics used are PSNR, SSIM, and LPIPS, reflecting the quality of the generated 3D Gaussian Splatting representations.
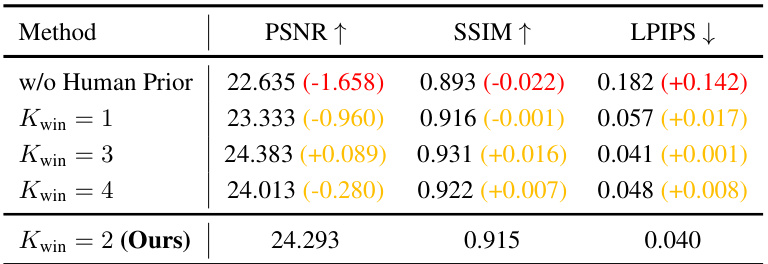
This table presents the results of ablation studies conducted on the 2K2K dataset to evaluate the impact of different design choices in the HumanSplat model. It compares the model’s performance (PSNR, SSIM, LPIPS) across three key aspects: (a) Reconstruction Space: Evaluates whether reconstructing in pixel space or latent space is more effective. (b) Geometric Prior Initialization: Assesses the influence of using Ground Truth SMPL parameters versus estimated parameters. (c) Different Projection Methods: Compares the performance when using different methods for projecting 3D tokens onto the 2D feature grids during the geometry-aware interaction.
Full paper#