↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large language models (LLMs), despite alignment efforts, remain vulnerable to adversarial attacks. Existing attacks, often relying on transferability (an attack effective on one model works on another), have limitations, especially in triggering specific harmful outputs or evading robust safety systems. This restricts their real-world applicability.
The paper introduces GCQ, a novel query-based attack that directly targets the LLM’s API. Unlike transfer attacks, GCQ crafts adversarial examples tailored to the target model. This method achieves higher success rates in producing harmful text and evading safety systems than previous methods. By leveraging only API queries, it removes the need for surrogate models. The results on GPT-3.5 and OpenAI’s safety classifiers showcase GCQ’s effectiveness, prompting a need for improved LLM safety measures.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in AI safety and security because it presents a novel query-based attack that can effectively bypass current language model safety mechanisms. The findings highlight the vulnerability of large language models to adversarial attacks, emphasizing the need for more robust safety measures. The research opens up new avenues for investigating more effective defensive strategies and better understanding adversarial vulnerabilities.
Visual Insights#
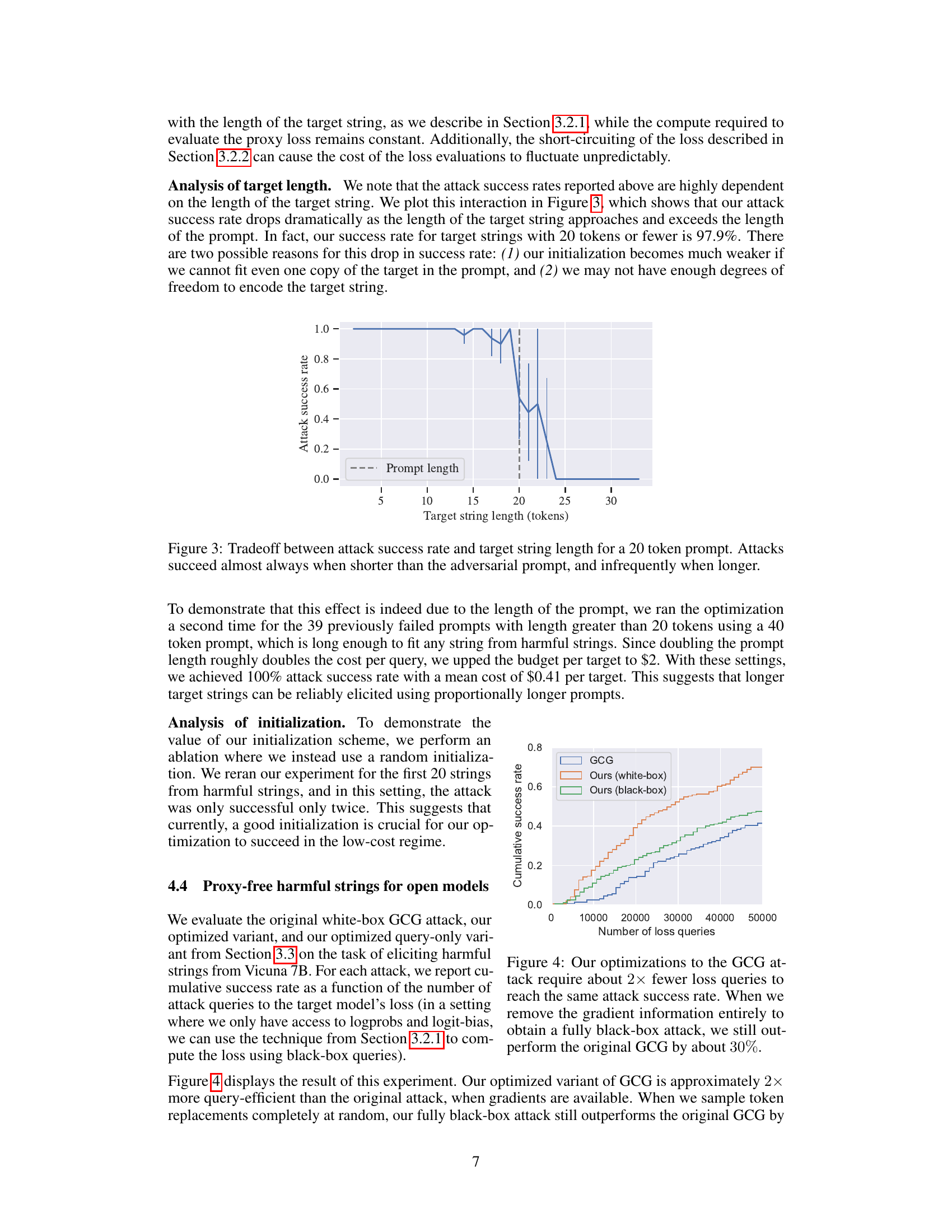
This figure shows the results of white-box and transfer attacks on open-source language models. The left panel (a) displays the cumulative attack success rate for white-box attacks on different sized Vicuna and Llama 2 models, showing Llama 2 to be more resistant to attacks than Vicuna. The right panel (b) illustrates the cumulative attack success rate for transfer attacks within the Vicuna 1.3 model family (7B, 13B, and 33B parameters), revealing that transferability is higher when the source and target models have similar sizes.

This table compares the success rates of different attack methods in eliciting harmful strings from various language models. It contrasts the performance of the proposed Greedy Coordinate Query (GCQ) attack against the existing Greedy Coordinate Gradient (GCG) transfer attack, highlighting the improved effectiveness of GCQ in this specific task. The results are shown for different combinations of proxy models and target models, revealing variations in transferability and attack success rates.
In-depth insights#
Query-based Attacks#
Query-based attacks represent a significant advancement in adversarial machine learning, particularly against language models. Unlike transfer-based attacks which rely on the transferability of adversarial examples crafted on a surrogate model, query-based attacks directly interact with the target model. This direct interaction allows for more targeted attacks, eliciting specific harmful outputs, which is not feasible for transfer methods. The surrogate-free nature of these attacks also broadens applicability to situations where suitable surrogates are unavailable. Optimization techniques like Greedy Coordinate Query (GCQ) enhance query efficiency, reducing the number of queries needed to generate effective adversarial examples. However, challenges remain. The dependence on model queries necessitates careful cost management and may be vulnerable to rate limiting. Proxy models, while improving efficiency, introduce limitations when unavailable, highlighting the need for purely query-based attacks. Despite these challenges, the efficacy of query-based methods in achieving nearly 100% evasion rates against safety classifiers and eliciting targeted harmful outputs from large language models demonstrates their potential as powerful attack vectors.
Adversarial Prompts#
Adversarial prompts represent a significant threat to the robustness and reliability of large language models (LLMs). By carefully crafting malicious input, attackers can bypass safety mechanisms, induce harmful outputs, and even manipulate the model’s behavior in unintended ways. This is achieved by exploiting vulnerabilities in the model’s training data or its underlying architecture. Query-based attacks are particularly effective, as they allow attackers to iteratively refine their prompts based on the model’s responses, enabling the generation of highly effective adversarial examples that significantly outperform transfer-based attacks. The research demonstrates the feasibility of creating such prompts to target even the most robust commercial models, highlighting the crucial need for more effective defenses against this emerging threat. Furthermore, this research emphasizes the need for robust safety measures in LLMs to mitigate the risk of such attacks. Targeted attacks that elicit specific harmful outputs are particularly concerning and highlight the potential for misuse. The implications for safety and security in AI systems necessitate a proactive approach to defense and mitigation strategies.
OpenAI Evasion#
The concept of “OpenAI Evasion” in the context of a research paper likely centers on adversarial attacks against OpenAI’s large language models (LLMs). This would involve crafting malicious inputs, or prompts, designed to cause the model to generate unsafe, biased, or otherwise undesirable outputs. The research likely explores various attack strategies, such as gradient-based attacks (requiring model access) or query-based attacks (leveraging API access), to circumvent OpenAI’s safety mechanisms. A key aspect of such work is likely assessing the efficacy of various evasion techniques against the robustness of OpenAI’s content moderation filters, demonstrating limitations in current safety implementations. Furthermore, the paper probably discusses the implications of successful OpenAI evasion, touching upon issues of model safety, security, and the potential for misuse of LLMs. The core goal is likely to highlight vulnerabilities to improve future safety measures and responsible development of AI.
Limitations#
A thoughtful analysis of the limitations section in a research paper would delve into the scope and depth of the limitations discussed. It would assess whether the authors have adequately addressed the constraints of their methodology, including potential biases, sample size limitations, and generalizability of findings. A strong limitations section not only acknowledges weaknesses but also suggests avenues for future research, showcasing a comprehensive understanding of the study’s context and boundaries. Crucially, it would examine whether the discussed limitations impact the validity and reliability of the results and conclusions drawn, thereby affecting the overall significance of the work. Transparency and honesty in this section are essential for responsible research, enabling the scientific community to fully evaluate the study’s contribution and limitations within a broader research landscape. The clarity and detail of these limitations shape the overall credibility and impact of the paper.
Future Work#
The ‘Future Work’ section of a research paper on adversarial attacks against language models would ideally delve into several crucial areas. Improving the efficiency and robustness of query-based attacks is paramount, potentially exploring novel optimization algorithms or leveraging proxy models more effectively. Expanding the scope of attacks beyond targeted harmful strings to encompass broader manipulation of model behavior and outputs is a promising direction. A deeper investigation into the transferability of adversarial examples across diverse language models is vital. Furthermore, research should focus on developing more sophisticated defenses against such attacks, including robust filtering techniques and improved model architectures. Finally, a comprehensive analysis of the ethical implications of adversarial attacks and potential societal risks is crucial for responsible AI development and deployment.
More visual insights#
More on figures
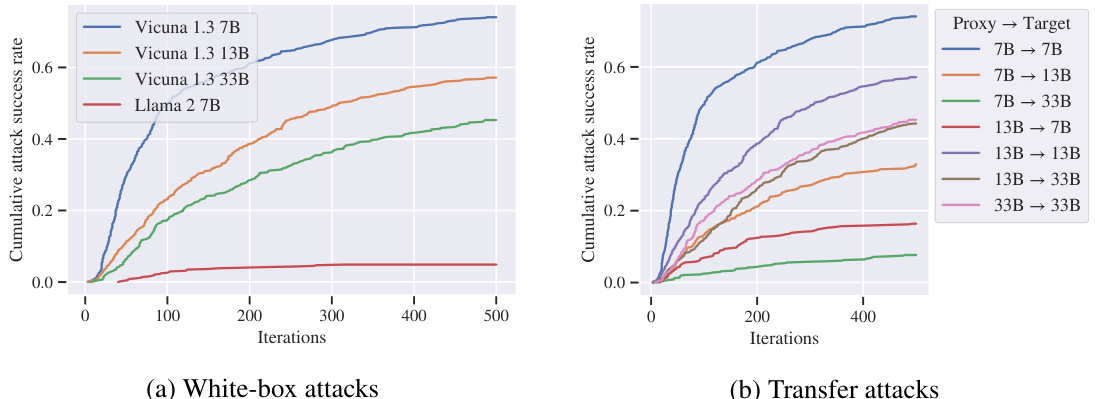
This figure shows the trade-off between cost and attack success rate for generating harmful strings using the GPT-3.5 Turbo model. The x-axis represents the cost in USD, and the y-axis shows the cumulative attack success rate. The solid line represents the performance of the Q-GC attack, demonstrating a rapid increase in success rate with increasing cost. The dashed line shows the baseline success rate achieved by only using the initialization technique, highlighting the significant improvement provided by the Q-GC attack.

This figure shows the relationship between the attack success rate and the cost (in USD) and number of iterations for generating harmful strings using GPT-3.5 Turbo. The plot reveals that the attack success rate increases rapidly with more cost and iterations. It also illustrates the difference between using the full Q-GC attack versus only using the initialization step. The dotted line represents the success rate achieved using only the initialization method. The solid line illustrates the success rate of the Q-GC method.
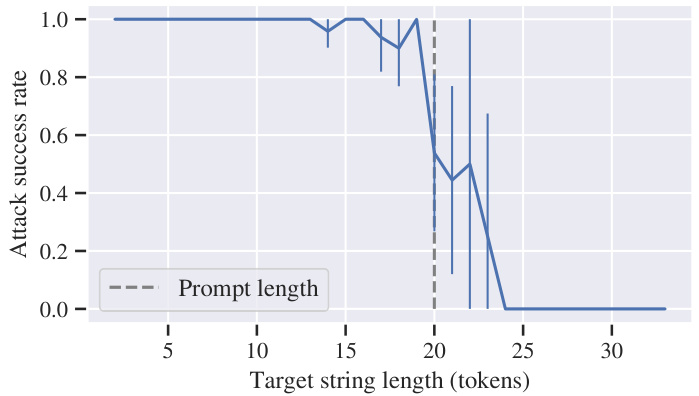
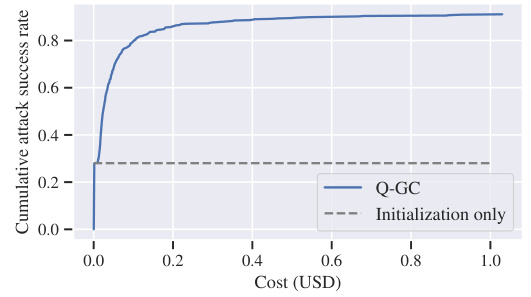
This figure shows the relationship between the attack success rate and the length of the target string when using a 20-token prompt. The x-axis represents the target string length in tokens, and the y-axis shows the attack success rate. The plot demonstrates that the attack is highly successful when the target string is shorter than the prompt, with success rates approaching 100%. However, as the target string length increases and becomes longer than the prompt, the attack success rate drops dramatically to near zero. The dashed vertical line indicates the length of the prompt (20 tokens). This illustrates a limitation of the attack: its effectiveness is significantly reduced when the target string is substantially longer than the prompt length.
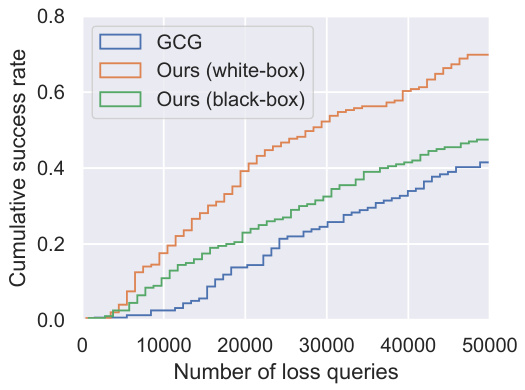
This figure compares the cumulative success rate of three different attack methods against the Vicuna 7B language model as a function of the number of loss queries. The three methods are the original Greedy Coordinate Gradient (GCG) attack, an optimized white-box version of the proposed Greedy Coordinate Query (GCQ) attack, and an optimized black-box version of the GCQ attack. The results demonstrate that the optimized versions of the GCQ attack require significantly fewer queries to achieve a given success rate compared to the original GCG attack, highlighting the efficiency gains of the proposed optimization techniques, particularly in the black-box setting where gradient information is unavailable.
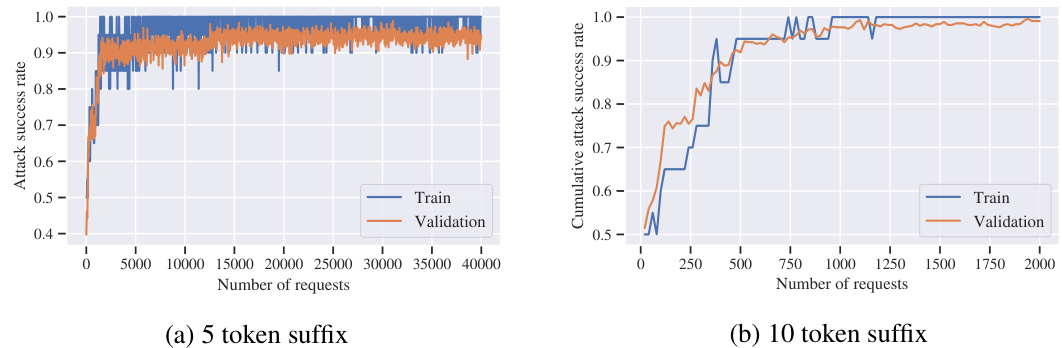
This figure shows the results of universal content moderation attacks using suffixes of 5 and 20 tokens. The x-axis represents the number of requests made to the OpenAI content moderation API, and the y-axis shows the cumulative attack success rate. Separate curves are shown for the training and validation sets, demonstrating the model’s ability to generalize to unseen strings.
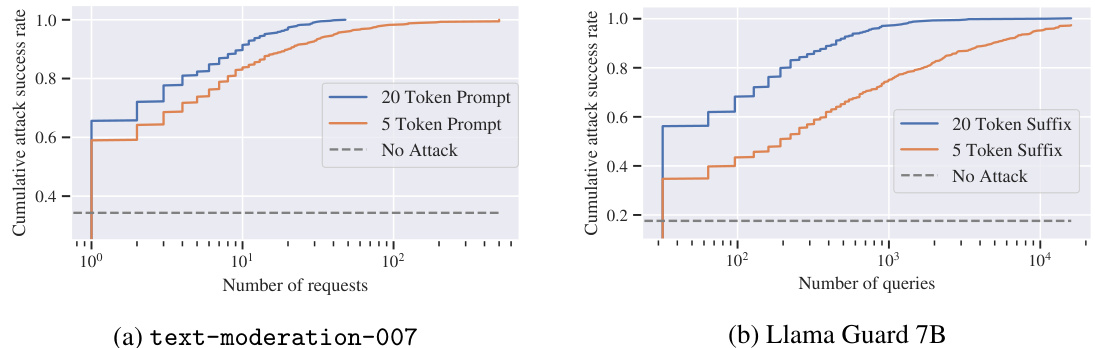
This figure shows the cumulative attack success rate against two content moderation models: OpenAI’s text-moderation-007 and Llama Guard 7B. The x-axis represents the number of queries made to the model, and the y-axis shows the percentage of harmful strings that were successfully evaded (i.e., not flagged as harmful). Two different prompt lengths are compared: 5-token prompts and 20-token prompts. The results demonstrate that the query-based attack is highly effective, achieving near-perfect evasion rates with a relatively small number of queries, even surpassing transfer-based attacks. Note that the scale of the x-axis is logarithmic.

This figure shows the distribution of cumulative log probabilities obtained by sampling the same prompt and target string pair 1000 times using OpenAI’s API. It illustrates the non-determinism of the API, where the same input yields different log probabilities each time it is evaluated. The x-axis represents the cumulative log probability, and the y-axis represents the count of occurrences. The distribution is concentrated around a mean value, but there is significant variance, suggesting that relying on a single API evaluation for optimization may not be robust.
Full paper#