↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current methods for generating synthetic driving data struggle with limited diversity and the Sim2Real gap. They often overfit to small datasets like nuScenes, hindering their ability to generate images with varied appearances and layouts. This makes it challenging to train robust autonomous driving models capable of handling diverse real-world scenarios.
SimGen tackles these issues by using a novel cascade diffusion pipeline and incorporating data from both real-world driving videos and a driving simulator. The result is a framework that generates diverse driving scenes with high-quality visual appearances and controllable layouts, bridging the sim-to-real gap. This significantly improves the performance of BEV detection and segmentation tasks and opens up new possibilities for safety-critical data generation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in autonomous driving because it introduces SimGen, a novel framework that significantly lowers the annotation cost of training data by generating diverse and realistic driving scenes. This addresses the significant Sim2Real gap and enhances the diversity and controllability of synthetic data, which is highly relevant to current trends in data augmentation and safety-critical scenario generation. SimGen’s cascade diffusion pipeline and the newly introduced DIVA dataset open new avenues for research in generating high-quality synthetic data for various autonomous driving perception tasks.
Visual Insights#
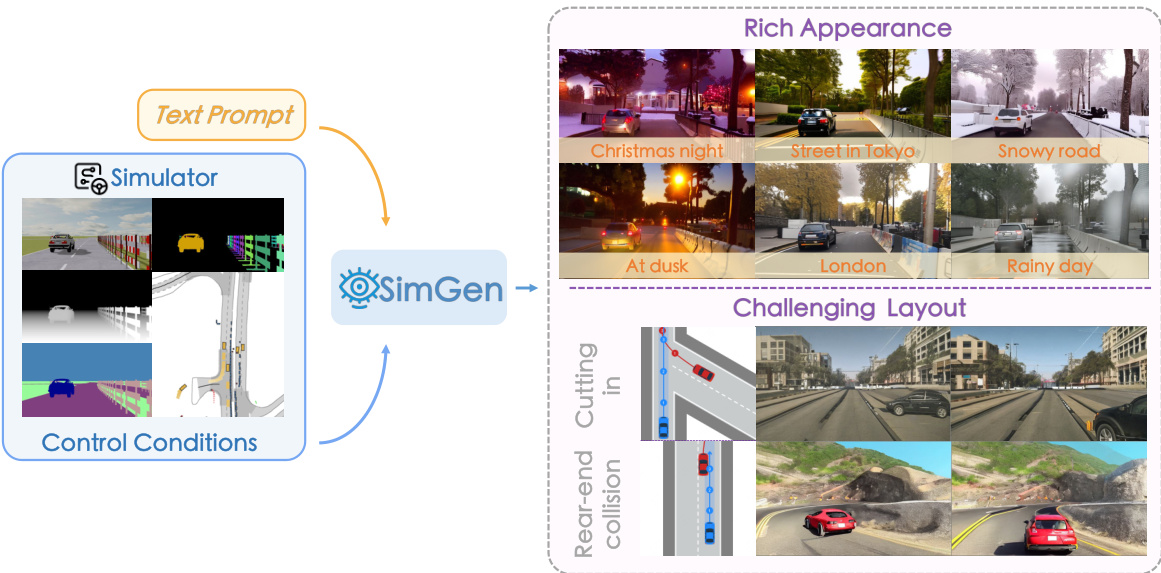
This figure illustrates the SimGen framework. SimGen takes a text prompt and simulator control conditions as input and generates diverse driving scenes. The simulator provides control conditions (such as layout, weather, and time of day), and the text prompt provides additional context. The resulting images showcase SimGen’s ability to generate scenes with rich appearances and challenging layouts, demonstrating its ability to incorporate both real-world and simulated data.
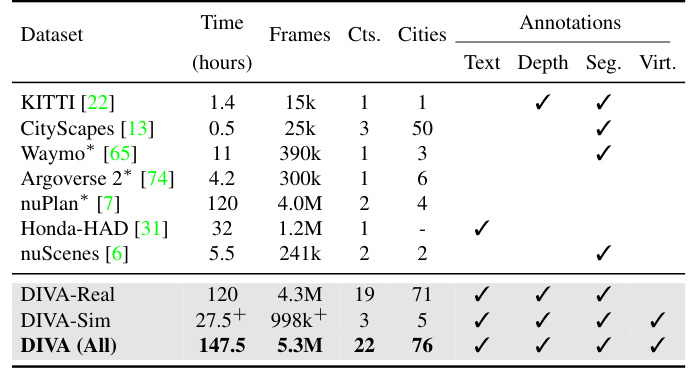
This table compares the DIVA dataset with other relevant autonomous driving datasets. It shows a comparison across several key metrics, including the number of frames (and hours of video), the number of countries and cities represented in the dataset, and the types of annotations available (text, depth, semantic segmentation, and virtual images). The table highlights DIVA’s superior scale and diversity compared to other commonly used datasets like nuScenes, KITTI, and Cityscapes.
In-depth insights#
SimGen Framework#
The SimGen framework is a novel cascade diffusion model designed for generating diverse driving scenes. It leverages both real-world and simulated data, addressing the limitations of models trained solely on limited datasets. The cascade approach involves a first stage that transforms simulated conditions (SimCond) into more realistic ones (RealCond) using a pre-trained diffusion model. Crucially, this transformation happens without additional training on simulated data, mitigating the sim-to-real gap. A second diffusion model then utilizes RealCond, alongside text prompts and optional extra conditions from the simulator, to generate the final driving scenes. This framework is particularly adept at handling conflicts between multimodal conditions, using an adapter to merge various control inputs. The result is a system capable of producing high-quality, diverse driving scenes while maintaining controllability based on text and simulator-provided layout.
DIVA Dataset#
The DIVA dataset, a crucial component of the SimGen framework, stands out due to its large scale and diversity. It cleverly combines real-world driving videos from YouTube (DIVA-Real), offering rich appearance variations and geographical coverage, with synthetic data generated by the MetaDrive simulator (DIVA-Sim), providing precise layout control and enabling the creation of safety-critical scenarios. This dual approach effectively addresses the limitations of solely relying on either real or simulated data, tackling the sim-to-real gap by integrating the strengths of both. The dataset’s diverse annotations, including text, depth, and semantic segmentation, further enhance its value for training and evaluation. The inclusion of safety-critical scenarios, often lacking in real-world datasets, is particularly valuable for advancing autonomous driving research. Overall, DIVA’s comprehensive nature makes it a valuable resource for pushing the boundaries of AI-driven scene generation and enhancing perception models.
Sim-to-Real Gap#
The Sim-to-Real gap is a critical challenge in utilizing simulated data for training real-world AI models, especially in autonomous driving. Simulators, while offering controlled and cost-effective data generation, often fail to perfectly replicate the complexity and variability of real-world environments. This discrepancy manifests in differences in visual appearance (e.g., lighting, texture, weather effects), object characteristics, and driving behaviors. Bridging this gap requires careful consideration of data augmentation techniques. Methods such as domain adaptation aim to reduce the discrepancy between simulated and real data, allowing models trained on simulated data to generalize effectively to real-world scenarios. Data diversity is also crucial; a simulator should provide a wide range of scenarios and conditions to prevent overfitting. Combining real and simulated data is another effective strategy, leveraging the strengths of both: the controllability of simulated data and the realism of real-world data. Furthermore, advancements in rendering techniques are essential for creating photorealistic simulations, minimizing the perceptual differences that can significantly impact model performance. Ultimately, overcoming the Sim-to-Real gap necessitates a multi-faceted approach that addresses both data quality and model generalization.
Ablation Study#
An ablation study systematically evaluates the contribution of individual components within a machine learning model. In this context, it would likely involve removing or altering parts of the SimGen framework (e.g., the cascade diffusion scheme, the unified adapter, specific simulator conditions) and assessing the impact on performance metrics such as FID and AP. The goal is to isolate the effects of each component, and this provides crucial insights into the design choices and relative importance of each module. For instance, removing the cascade pipeline might show a significant drop in performance, highlighting its crucial role in bridging the sim-to-real gap. Similarly, disabling the unified adapter could reveal conflicts between various input conditions, underscoring its importance in harmonizing multiple data sources. By carefully analyzing changes in performance associated with each ablation, the researchers can demonstrate the effectiveness of each component and justify the overall framework design. The ablation study is essential for understanding the SimGen architecture and its ability to generate high-quality, diverse driving scene images.
Future Work#
The authors acknowledge several key areas for future research. Extending SimGen to handle multi-view generation is paramount, as current single-view limitations hinder applicability in bird’s-eye view perception models commonly used in autonomous driving. Addressing the computational cost and slow sampling speed of the diffusion model is crucial for practical deployment. Exploring more efficient diffusion models or developing accelerated sampling techniques is vital. Further investigation into closed-loop video generation, building upon the promising preliminary results, would significantly enhance the model’s capabilities for interactive scenario generation and closed-loop planning. Finally, a thorough examination of the generalization capabilities of SimGen across diverse simulator platforms would demonstrate its robustness and adaptability in real-world applications. This will involve rigorous testing on multiple platforms and further study of the sim-to-real gap.
More visual insights#
More on figures

This figure illustrates the process of constructing the DIVA dataset, which consists of two parts: DIVA-Real and DIVA-Sim. DIVA-Real uses real-world driving videos from YouTube, with a VLM used for quality control and off-the-shelf models for annotation. DIVA-Sim leverages a simulator to generate synthetic data, including digital twins of real-world scenarios and safety-critical situations, using scene records and control policies. The final outputs include various sensor modalities like RGB, depth, segmentation, and top-down views.

This figure illustrates the SimGen framework, a cascade diffusion model for generating driving scene images. It shows how text and scene records (from a simulator) are processed. The simulator renders the scene record into simulated depth, segmentation (SimCond), and extra conditions (ExtraCond). SimCond and text features are fed into CondDiff, transforming simulated conditions into realistic ones (RealCond). Finally, ImgDiff, guided by RealCond, text features, and ExtraCond, generates the driving scene image, with an adapter merging all conditions for unified control.
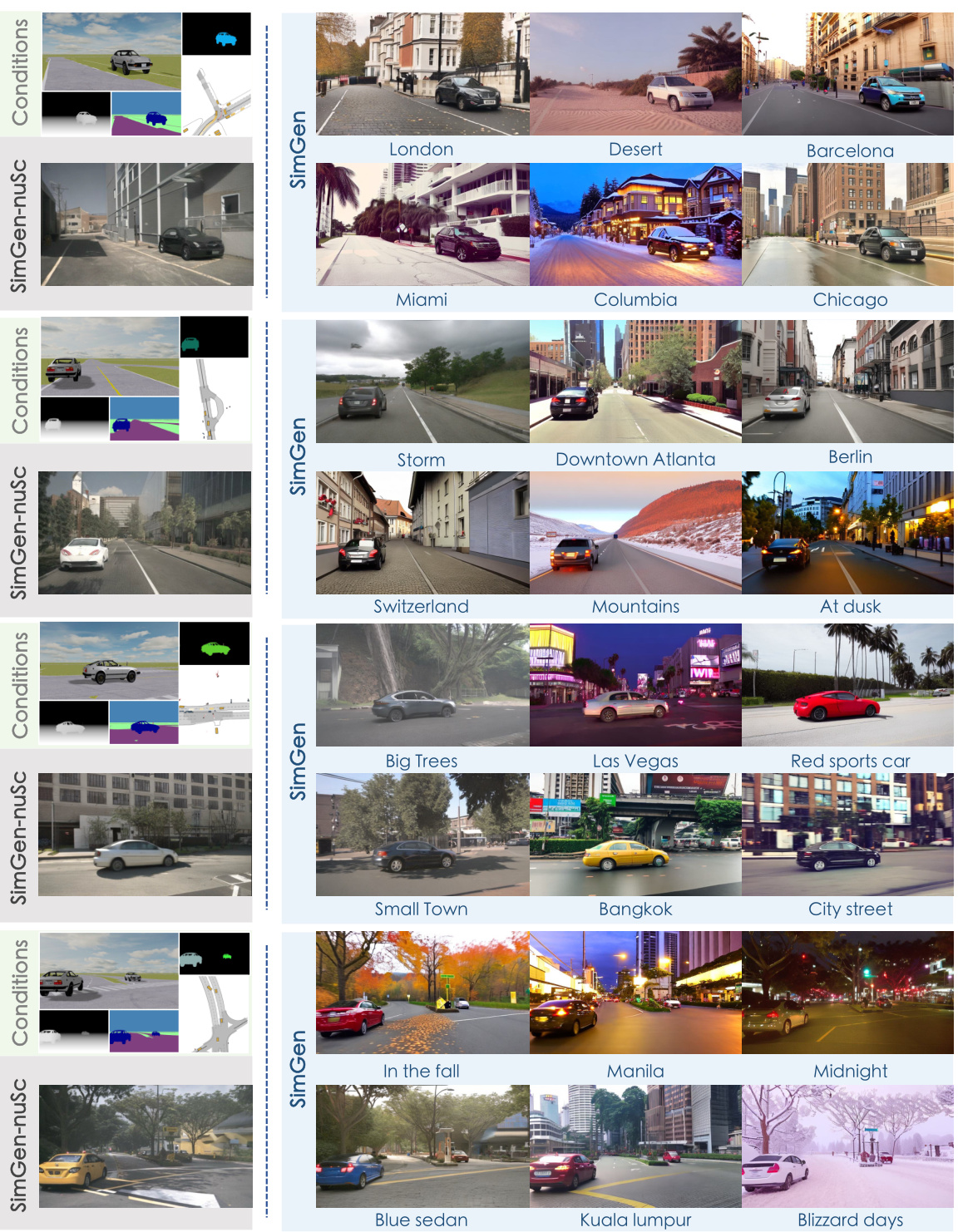
This figure compares the image generation quality and diversity of SimGen trained on the large-scale and diverse DIVA dataset and SimGen-nuSc trained only on the relatively small nuScenes dataset. The figure showcases that SimGen produces more realistic and diverse driving scenes across a variety of weather conditions, geographic locations, times of day and lighting, compared to SimGen-nuSc. Each row shows results for a different set of simulator conditions (layout, depth, segmentation) and text prompts.

This figure showcases SimGen’s ability to generate images of safety-critical driving scenarios. It presents four scenarios: sudden braking, crossroad meeting, merging, and sharp turning. For each scenario, the left side shows simulated images generated from the simulator, while the right side shows the corresponding real-world images generated by SimGen. This demonstrates SimGen’s capacity to produce realistic and diverse driving scenes, including those involving potentially dangerous situations.

This figure shows an ablation study on the impact of different simulator conditions on the image generation quality. It compares the results of using only rendered RGB, depth, segmentation, instance maps, and top-down view (w/o) versus using all of them combined (w/). The results demonstrate that integrating all the simulator-provided conditions improves the generation quality.

This figure shows a diverse set of images from the DIVA-Real dataset, showcasing the variety of scenes, weather conditions, times of day, and geographical locations captured in the dataset. The images illustrate the broad scope and diversity of real-world driving scenarios that the DIVA-Real dataset encompasses, contributing to the robustness and generalizability of the SimGen model.

This figure shows various top-down views of simulated driving scenarios, highlighting safety-critical situations. The yellow rectangle represents the ego vehicle, while other vehicles are involved in potentially dangerous interactions, such as near misses and collisions. These scenarios were generated using the Waymo Open Dataset [65] and an adversarial interaction method [80] within the MetaDrive simulator. The layouts illustrate the diversity of challenging scenarios included in the DIVA-Sim dataset.

This figure visually shows the differences between simulated and real driving scenarios. The top row displays simulated conditions, and the bottom row shows the corresponding real-world conditions. The discrepancies highlight the challenges in creating realistic synthetic data, such as differences in object categories, positions, occlusions, and background details.

This figure compares the image generation results of the proposed cascade diffusion model with naïve approaches. The cascade diffusion model, shown in blue boxes, incorporates a Sim-to-Real condition transformation module (CondDiff) to convert simulated conditions from a simulator into realistic conditions before generating images. In contrast, the naïve approaches, shown in gray boxes, directly use simulated conditions without the transformation step. The comparison shows that the cascade diffusion model generates more realistic and high-quality images, highlighting the effectiveness of the proposed Sim-to-Real condition transformation.
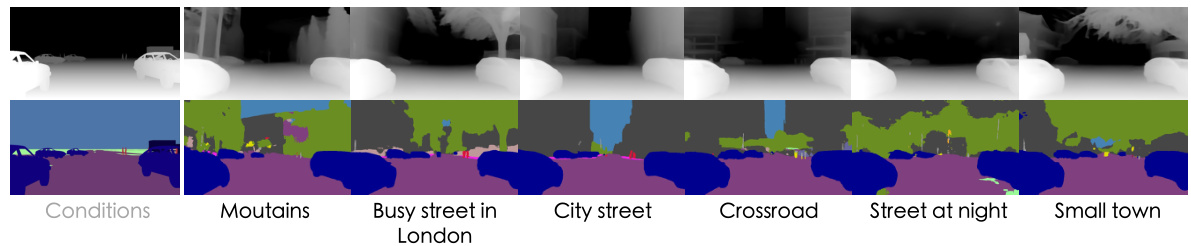
This figure compares the results of the proposed cascade diffusion model with naive approaches for generating images of driving scenes. The proposed method uses a cascade of diffusion models to first transform simulated conditions into realistic conditions before generating the final image. This approach improves the realism and quality of the generated images compared to the naive approaches which directly use simulated conditions. The figure showcases a comparison of generated images across different scenarios using different methods. The blue boxes represent the improved approach while gray boxes represent the naive approaches.

This figure shows a preliminary attempt at closed-loop evaluation using SimGen. Two scenarios are presented: one using the Intelligent Driver Model (IDM) and another using manual control. The IDM approach leads to risky situations like sudden braking or collisions, while manual control shows safer driving behaviors by keeping a safe distance and slowing down. The generated images showcase the potential use of SimGen in evaluating safety-critical driving scenarios.

This figure showcases SimGen’s zero-shot generalization capabilities. It demonstrates the model’s ability to generate diverse driving scenes using depth and segmentation maps from CARLA simulator combined with various textual prompts, even when the model has not been specifically trained on CARLA data.

This figure demonstrates the ability of SimGen to generate diverse driving scenes across various appearances and layouts. It shows comparisons between SimGen trained on the DIVA dataset (which includes both real and simulated data) and SimGen trained only on the nuScenes dataset. The results highlight SimGen’s superior performance in generating realistic and diverse driving scenes compared to models trained on smaller, less diverse datasets.

This figure demonstrates SimGen’s ability to generate diverse and realistic driving scene images under various conditions by comparing its outputs with those from a model trained only on the nuScenes dataset. The results show that SimGen, trained on the DIVA dataset, produces images with higher visual quality and diversity compared to the model trained only on the nuScenes dataset, especially in scenarios not present in nuScenes (e.g., desert, mountain, blizzard).

This figure compares the image generation results of SimGen trained on the DIVA dataset with SimGen-nuSc trained only on the nuScenes dataset. The images are generated under identical simulator conditions and text prompts. The comparison demonstrates SimGen’s improved ability to generate diverse and realistic driving scenarios, compared to models trained on smaller, less diverse datasets.

This figure shows several images generated by SimGen using different text prompts and simulator conditions. It demonstrates SimGen’s ability to generate diverse and realistic driving scenes with varied appearances, lighting conditions, and locations, showcasing its capacity for text-grounded image generation and rich appearance diversity.
More on tables
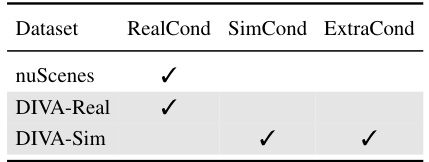
This table shows the different types of conditions used in the SimGen model for generating images. Real/SimCond refers to depth and segmentation maps, which can come from real-world data or be simulated. ExtraCond includes additional information such as rendered RGB images, instance maps, and top-down views, also from either real-world data or simulation. The table indicates which conditions are available for the different datasets used in the training.
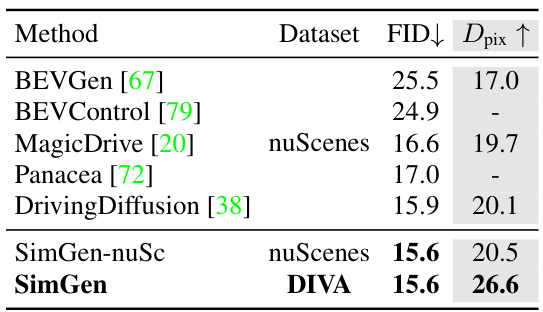
This table compares the performance of SimGen with other state-of-the-art models that were trained exclusively on the nuScenes dataset. The comparison is based on two metrics: Fréchet Inception Distance (FID), which measures image quality, and pixel diversity (Dpix), which measures the diversity of generated images. SimGen outperforms the other methods on both metrics, indicating better image quality and diversity. A model variant SimGen-nuSc, which is trained on only nuScenes, is included for a fair comparison, showing that SimGen’s superior performance derives from using the more comprehensive DIVA dataset.
This table compares the performance of SimGen against other state-of-the-art models for generating driving scenes, specifically focusing on image quality (FID) and diversity (Dpix). The results show SimGen’s superiority in both aspects, particularly its significant improvement in diversity compared to DrivingDiffusion. A model variant trained solely on nuScenes (SimGen-nuSc) is also included for a fair comparison.

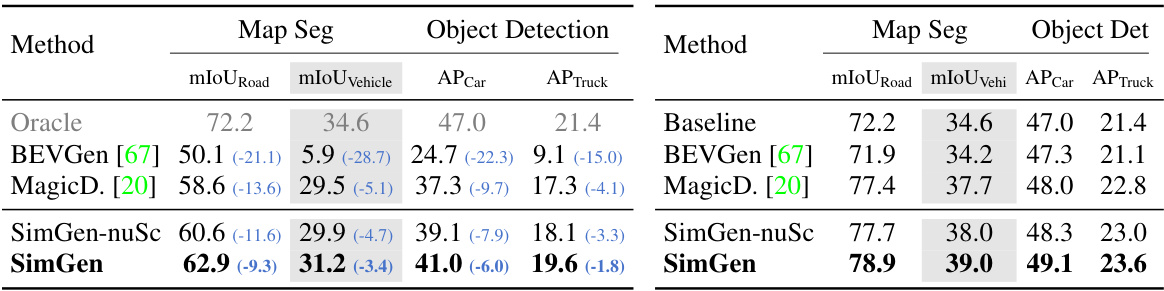
This table presents the results of an ablation study conducted to evaluate the impact of each component of the SimGen model on its performance. The baseline model is compared against variations that incrementally add the proposed components: the cascade pipeline, extra conditions (ExtraCond), and the unified adapter. The results show the FID (Fréchet Inception Distance), a measure of image quality, and APCar (Average Precision for Cars), a metric for controllability. The table demonstrates that each proposed design contributes to improved performance.

This table compares the DIVA dataset with other relevant datasets in terms of scale (number of frames and hours of video), diversity (number of countries and cities), and annotations (text, depth, segmentation, and virtual images). It highlights DIVA’s larger scale and greater diversity compared to existing datasets, which often lack appearance diversity and challenging scenarios.

This table compares the temporal distribution of scenes in the nuScenes dataset and the DIVA-Real dataset. It shows the percentage of daytime, dawn, dusk, and nighttime scenes in each dataset. The DIVA-Real dataset shows a more even distribution across different times of day compared to nuScenes, which is heavily weighted towards daytime.

This table compares the weather condition distribution in the nuScenes dataset and the DIVA-Real dataset. The DIVA-Real dataset shows a much more diverse distribution of weather conditions, including a significant percentage of cloudy and snowy days, unlike nuScenes which predominantly features normal and rainy days.

This table compares the layout diversity of the nuScenes dataset and the DIVA-Sim dataset. It shows the percentage of driving scenarios in each dataset that fall into various categories such as Forward driving, Left/Right Turns, Lane Changes, Intersection Passing, U-Turns and Stops. This highlights differences in the types of driving situations represented in each dataset.

This table compares the performance of SimGen against other models trained exclusively on the nuScenes dataset. It evaluates the generated images’ quality using the Fréchet Inception Distance (FID) and their diversity with pixel diversity (Dpix). Lower FID indicates better image quality, and higher Dpix means more diverse images. SimGen outperforms other methods in both image quality and diversity.
Full paper#



















