↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current methods adapt closed Large Language Models (LLMs) to private data, raising concerns about data leakage to third parties, including LLM providers. These methods also underperform compared to using open LLMs. This paper analyzes four recent privacy-preserving methods for closed LLMs, focusing on privacy protection and performance.
This study reveals that existing methods for closed LLMs leak query and sometimes training data. Open LLM-based adaptation methods significantly outperformed these closed LLM methods in accuracy and efficiency while also offering significantly better privacy. The research strongly advocates for adopting open LLMs for privacy-preserving LLM adaptations, emphasizing their superiority in performance, privacy, and cost.
Key Takeaways#
Why does it matter?#
This paper is crucial because it challenges the prevailing trend of using closed LLMs for private data adaptation. By demonstrating that open LLMs offer superior privacy, performance, and cost-effectiveness, it redirects research towards more ethical and practical approaches. This work directly addresses significant privacy concerns related to using closed LLMs with private data and paves the way for more secure and efficient development and implementation of LLMs in privacy-sensitive settings.
Visual Insights#
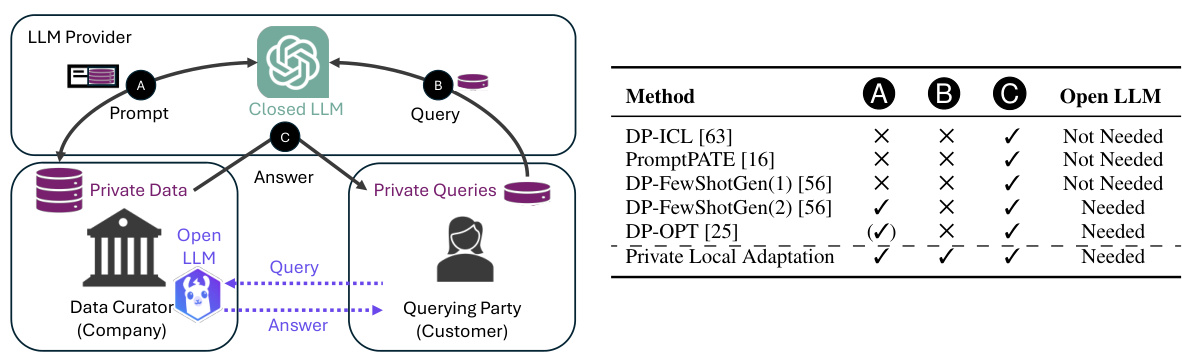
This figure illustrates the three parties involved in using LLMs with private data: the LLM provider, data curator, and querying party. It shows how existing methods for adapting closed LLMs to private data leak information (A, B, and C). It then presents a privacy-preserving alternative using a local open LLM.

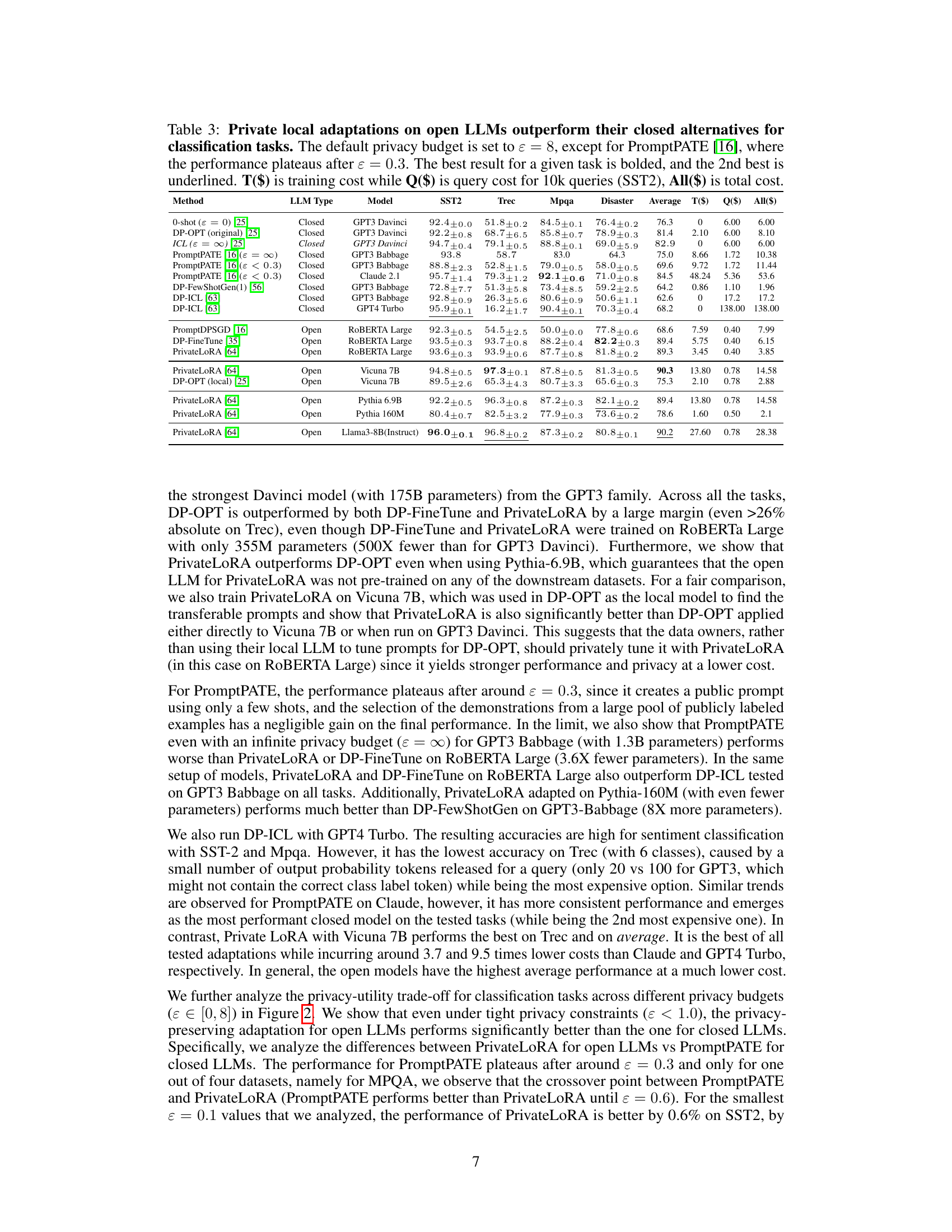
This table compares the privacy, performance, and cost of using two different methods (DP-ICL and PrivateLoRA) to adapt both closed and open LLMs for two tasks (sentiment classification and dialog summarization). It highlights that adapting open LLMs is more private, performs better, and is cheaper than adapting closed LLMs.
In-depth insights#
OpenLLM Privacy#
The concept of “OpenLLM Privacy” invites a critical examination of the inherent trade-offs between open-source large language models (LLMs) and data privacy. While open LLMs foster collaboration and transparency, they also present unique challenges regarding data security and user privacy. A primary concern is the potential for unintended data leakage during training, inference, or both. Unlike closed LLMs, where access is controlled, open LLMs’ code and data are publicly available, increasing the risk of malicious actors exploiting vulnerabilities or extracting sensitive information. However, open LLMs can facilitate the development and implementation of rigorous privacy-enhancing techniques. The accessibility of the code allows for greater scrutiny and community-driven efforts to improve privacy mechanisms, such as differential privacy (DP) methods. This creates a dynamic environment where researchers can collaboratively address the complexities of privacy in LLM development and deployment. Ultimately, the success of “OpenLLM Privacy” hinges on the balance between fostering open collaboration and implementing robust mechanisms to protect sensitive user data, requiring constant vigilance and innovation.
ClosedLLM Leaks#
The hypothetical heading ‘ClosedLLM Leaks’ points to a critical vulnerability in using closed-source Large Language Models (LLMs) for privacy-sensitive tasks. Closed LLMs, by their nature, lack transparency, making it difficult to ascertain what data is retained and how it is used. This lack of visibility creates inherent risks. Any data used to fine-tune or prompt a closed LLM, even seemingly anonymized information, could potentially be vulnerable to leakage. Sophisticated attacks might extract sensitive information about training data or queries, undermining the expected privacy guarantees. Furthermore, the LLM provider itself becomes a point of potential leakage, as they retain complete control over their model and its interactions. This underscores the need for rigorous scrutiny of closed LLMs’ security and privacy practices before deploying them in contexts demanding stringent confidentiality, and highlights the comparative advantages of open-source models where greater transparency is possible.
Adaptation Costs#
The analysis of adaptation costs in this research paper offers crucial insights into the economic implications of choosing between open and closed large language models (LLMs). The study reveals that private adaptation methods for closed LLMs incur significantly higher monetary costs compared to using open LLMs. These costs include expenses related to training and querying the models, particularly highlighted by the significant differences in API access costs between open and closed providers. Closed LLMs exhibit substantially higher query costs, which are directly proportional to the amount of data processed. The paper further emphasizes the cost-effectiveness of private open LLM adaptations, suggesting that they offer superior privacy and performance while significantly reducing overall financial burden. This economic disparity underscores the inherent advantages of open models for privacy-preserving applications, rendering them a more practical and financially viable option for users concerned about both performance and budget constraints.
Prompt Methods#
Prompt methods are crucial for effectively leveraging Large Language Models (LLMs), especially in scenarios involving private data. Privacy-preserving prompt techniques are paramount, aiming to prevent leakage of sensitive information during prompt engineering. These methods often involve careful design of prompts to limit information disclosure while maintaining model performance. Differential privacy (DP) is frequently used to add noise to the prompt generation process, providing provable privacy guarantees. However, challenges exist in balancing privacy and utility, as excessive noise can negatively impact LLM performance. Furthermore, the choice of prompt method significantly impacts cost efficiency, as some methods require computationally expensive ensembles of prompts, whereas other methods, like prompt tuning, are significantly more efficient. The overall effectiveness of different prompt methods also depends heavily on the specific application and datasets used. Open LLMs provide a significant advantage by allowing for private adaptation methods (e.g., prompt tuning), avoiding the inherent query data leakage issues associated with using closed LLMs.
Future Research#
Future research directions stemming from this paper could involve exploring more sophisticated privacy-preserving techniques beyond differential privacy, such as federated learning or homomorphic encryption, to further enhance the confidentiality of private data used in LLM adaptation. Another avenue is investigating alternative prompt engineering methods that minimize data leakage while maintaining high performance, potentially by leveraging techniques from generative models or reinforcement learning. The development of more efficient and robust DP mechanisms specifically tailored for LLMs is also crucial. Finally, a comprehensive comparison of different open-source LLMs with varying architectures and training data is needed to determine the optimal choices for privacy-preserving applications, along with a deeper analysis of the tradeoffs between privacy, performance, and cost. This work lays a foundation for future work.
More visual insights#
More on figures

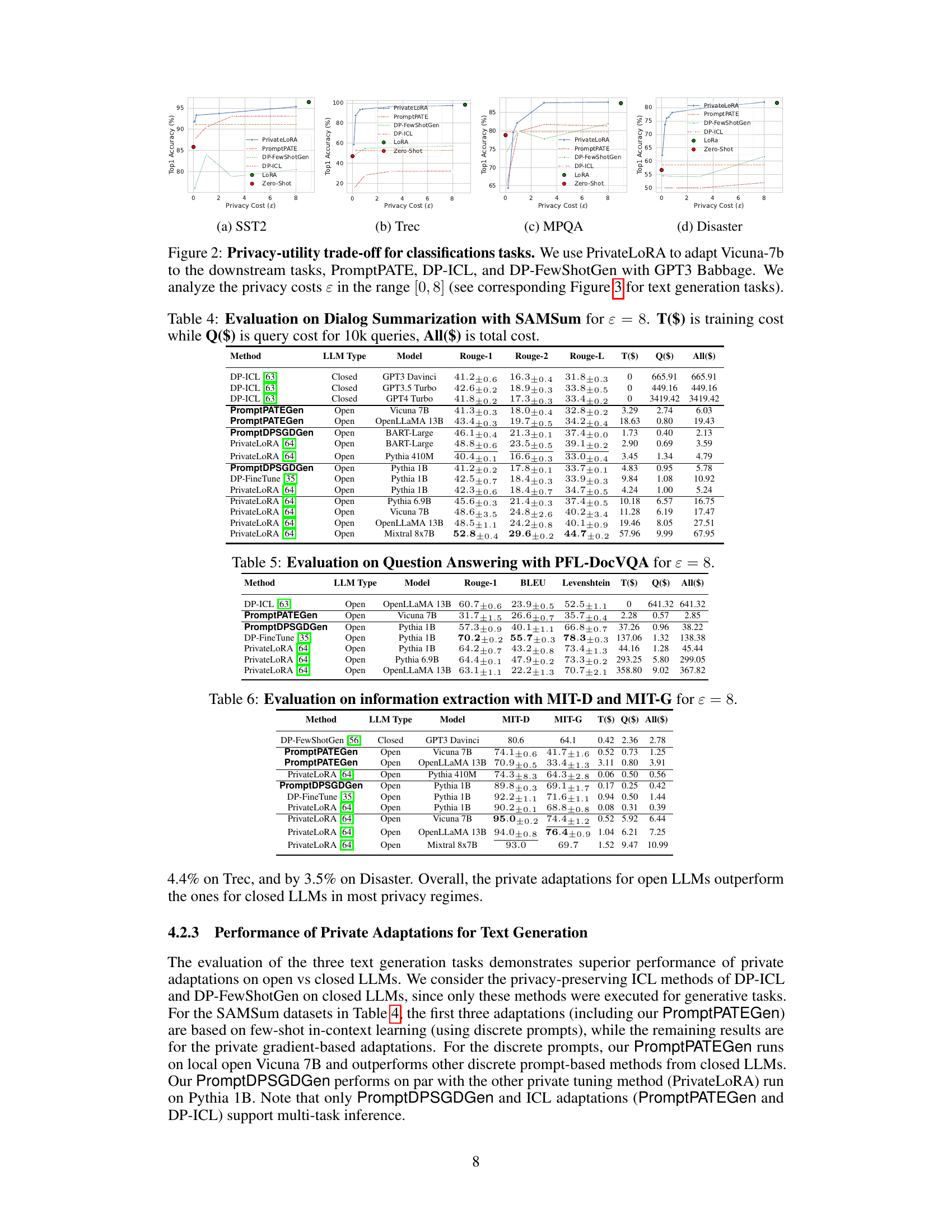
This figure shows the privacy-utility trade-off for four different classification tasks (SST2, Trec, MPQA, and Disaster). It compares the performance of PrivateLoRA (using the Vicuna-7b open LLM) against three closed-LLM adaptation methods (PromptPATE, DP-ICL, and DP-FewShotGen using GPT-3 Babbage). The x-axis represents the privacy cost (epsilon), and the y-axis represents the accuracy. The figure illustrates that PrivateLoRA consistently outperforms the closed-LLM methods across various privacy budgets, demonstrating its superiority in terms of both privacy and utility.

This figure shows the results of an experiment comparing the performance of different methods for private adaptation of LLMs for classification tasks. The x-axis represents the privacy cost (epsilon), and the y-axis represents the accuracy achieved. The figure shows that using PrivateLoRA with an open LLM provides better accuracy at lower privacy costs compared to methods using closed LLMs like PromptPATE, DP-ICL, and DP-FewShotGen. The results for each dataset (SST2, Trec, Mpqa, and Disaster) are shown in separate subfigures.
More on tables
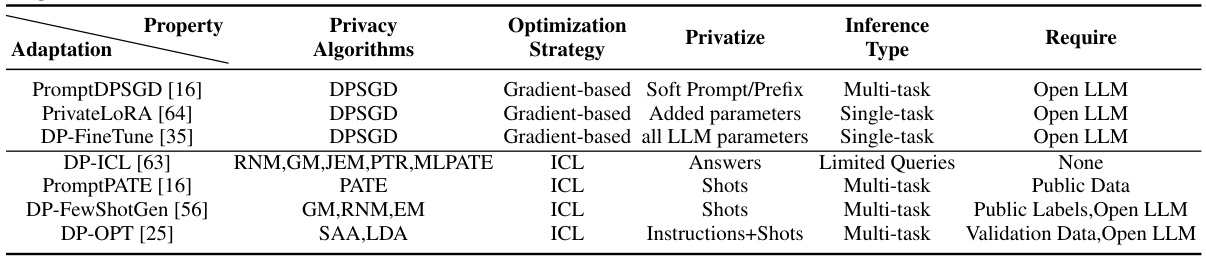
This table compares various private LLM adaptation methods, highlighting their privacy algorithms, optimization strategies, privatization techniques, inference types, and the required resources (e.g., open LLMs). It categorizes the methods based on whether they use in-context learning (ICL) or gradient-based optimization. The table helps readers understand the differences in approaches and their implications for privacy and performance.
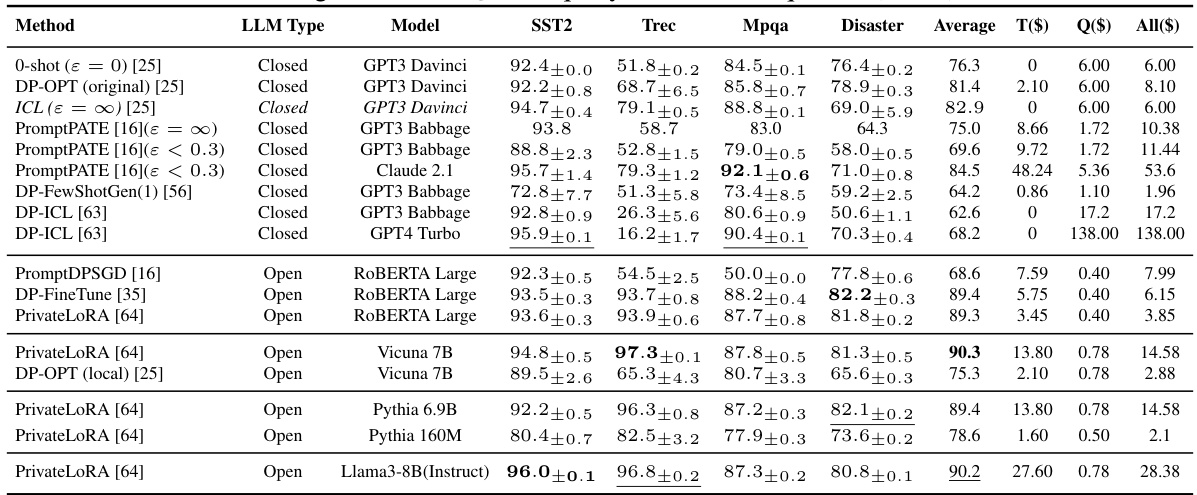
This table compares the privacy, performance, and cost of different private adaptation methods for both closed and open LLMs. It focuses on two tasks: sentiment classification and dialogue summarization, using various LLMs and datasets. The table shows that open LLM adaptations generally offer better privacy, higher performance, and lower costs compared to closed LLM methods.
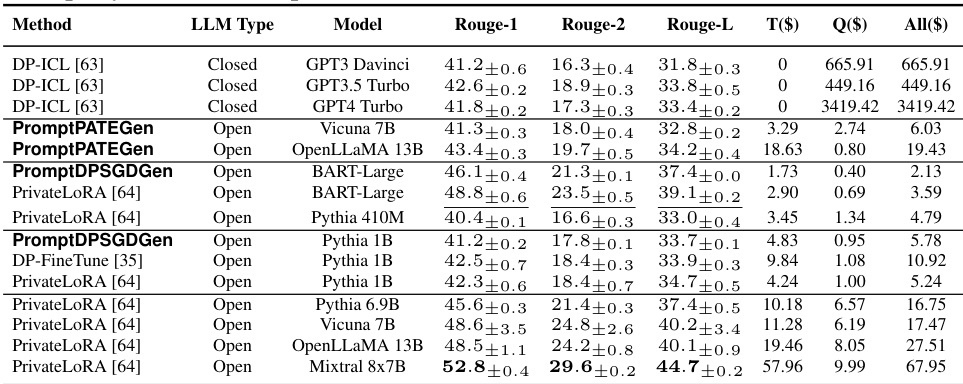
This table compares the privacy, performance, and cost of private adaptations for closed vs. open LLMs. It focuses on two tasks: sentiment classification and dialog summarization, using specific methods (DP-ICL and PrivateLoRA) and various LLMs (GPT4 Turbo, Llama3, etc.). The results show that open LLM adaptations offer superior privacy, performance, and lower costs.

This table compares the performance of various private adaptation methods for both open and closed LLMs on the PFL-DocVQA question answering task. The methods are evaluated based on Rouge-1, BLEU, and Levenshtein scores, along with training and query costs. The ε value represents the privacy budget used. The table highlights the superior performance and lower cost of private adaptations using open LLMs compared to closed LLMs for this specific task.

This table compares the privacy, performance, and cost of private adaptations for both closed and open LLMs on two tasks: sentiment classification (SST2) and dialog summarization (SAMSum). It shows that open LLMs, using PrivateLoRA, offer superior performance and privacy at significantly lower cost compared to closed LLMs using DP-ICL.

This table compares the privacy, performance, and cost of private adaptations for closed and open LLMs. It focuses on two tasks: sentiment classification and dialog summarization, using several different LLMs and methods. The results highlight that open LLMs offer superior privacy, performance, and lower costs compared to their closed counterparts.
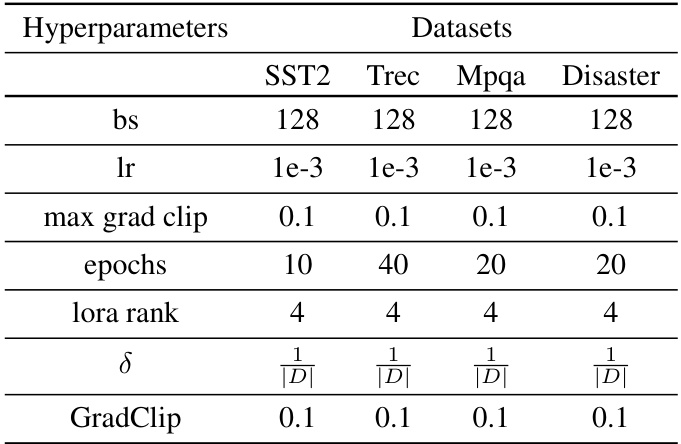
This table compares privacy, performance, and cost of adapting closed vs. open LLMs for two tasks: sentiment classification and dialogue summarization. It shows that open LLM adaptations, using PrivateLoRA, are more private, perform better, and are significantly cheaper than closed LLM methods (DP-ICL).

This table compares the privacy, performance, and cost of private adaptations for both closed and open LLMs. It focuses on two tasks: sentiment classification (SST2) and dialog summarization (SAMSum), using specific adaptation methods (DP-ICL and PrivateLoRA). Key metrics include accuracy, Rouge-L score, training cost, and query cost, highlighting the advantages of open LLMs in terms of privacy and cost-effectiveness.
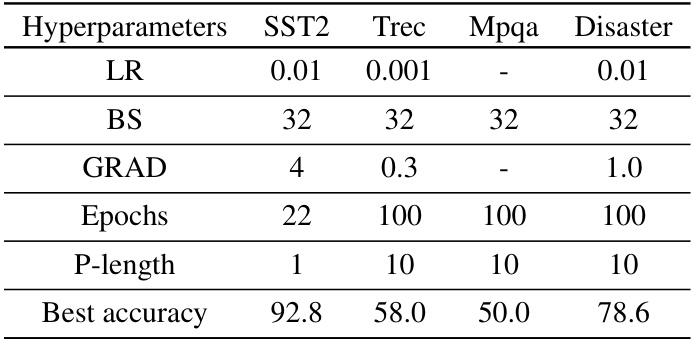
This table compares the privacy, performance, and cost of private adaptations for both closed and open LLMs. It focuses on two tasks: sentiment classification (SST2) and dialog summarization (SAMSum), using various LLMs and adaptation methods. The results demonstrate that open LLM adaptations are more private, achieve higher performance, and have lower costs than closed LLM alternatives.

This table compares the privacy, performance, and cost of adapting both closed and open LLMs for two tasks: sentiment classification and dialog summarization. It shows that adapting open LLMs using PrivateLoRA is significantly more private, performs better, and is cheaper than using the state-of-the-art methods for adapting closed LLMs.

This table compares the privacy, performance, and cost of private adaptations for both closed and open LLMs. It focuses on two tasks: sentiment classification (SST2) and dialog summarization (SAMSum). The table highlights that open LLM adaptations are generally more private, perform better, and are less expensive than closed LLM adaptations.
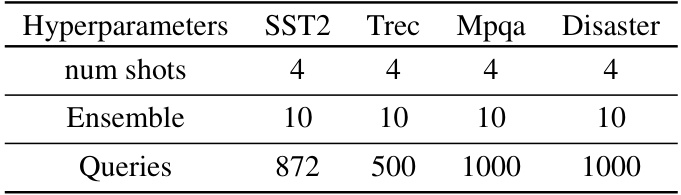
This table compares the privacy, performance, and cost of private adaptations for both closed and open LLMs. It focuses on two tasks: sentiment classification (SST2) and dialog summarization (SAMSum), using various LLMs and adaptation methods. The results demonstrate that open LLMs offer superior privacy, performance, and cost-effectiveness compared to closed LLMs in private adaptation scenarios.

This table compares the privacy, performance, and cost of private adaptations for both closed and open LLMs. It focuses on two tasks: sentiment classification (SST2) and dialog summarization (SAMSum). The table shows that open LLM adaptations are significantly more private, perform better, and are less expensive than their closed counterparts.

This table compares the privacy, performance, and cost of private adaptations for closed and open LLMs. It focuses on two tasks: sentiment classification and dialog summarization. The table highlights that open LLMs offer better privacy, performance, and lower costs compared to closed LLMs.

This table compares the privacy, performance, and cost of using private adaptations for both closed and open LLMs. It focuses on two specific tasks: sentiment classification (SST2) and dialog summarization (SAMSum). The table highlights the data leakage to the LLM provider, the accuracy/ROUGE scores, and the training and query costs for each method. Open LLMs using PrivateLoRA are shown to be more private, performant, and cost-effective compared to closed LLM methods like DP-ICL.

This table compares the privacy, performance, and cost of different private adaptation methods for both closed and open LLMs. It focuses on two tasks: sentiment classification (SST2) and dialog summarization (SAMSum). The table highlights that open LLM adaptations offer superior privacy, performance, and lower costs compared to their closed counterparts.

This table compares the privacy, performance, and cost of adapting closed LLMs (using DP-ICL) versus open LLMs (using PrivateLoRA) for two tasks: sentiment classification (SST2) and dialog summarization (SAMSum). It shows that open LLM adaptations are significantly more private, perform better, and are less expensive.
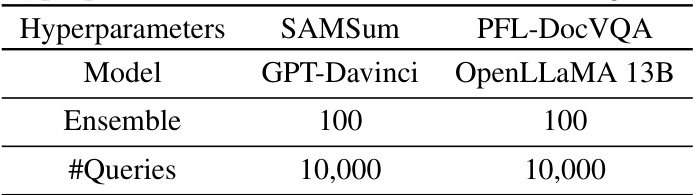
This table compares the privacy, performance, and cost of private adaptations for both closed and open LLMs. It focuses on two tasks: sentiment classification (SST2) and dialog summarization (SAMSum), using specific methods and models for each LLM type. The results highlight that open LLM adaptations generally offer superior privacy, performance, and lower costs compared to closed LLM adaptations.

This table compares the privacy, performance, and cost of private adaptations for both closed and open LLMs. It focuses on two tasks: sentiment classification and dialog summarization, using various LLMs and methods (DP-ICL and PrivateLoRA). The results show that open LLMs offer better privacy, higher performance, and lower costs.

This table compares the privacy, performance, and cost of private adaptations for closed vs. open LLMs. It focuses on two tasks: sentiment classification and dialog summarization, using several LLMs and methods. The results show that open LLM adaptations are superior in all three aspects.
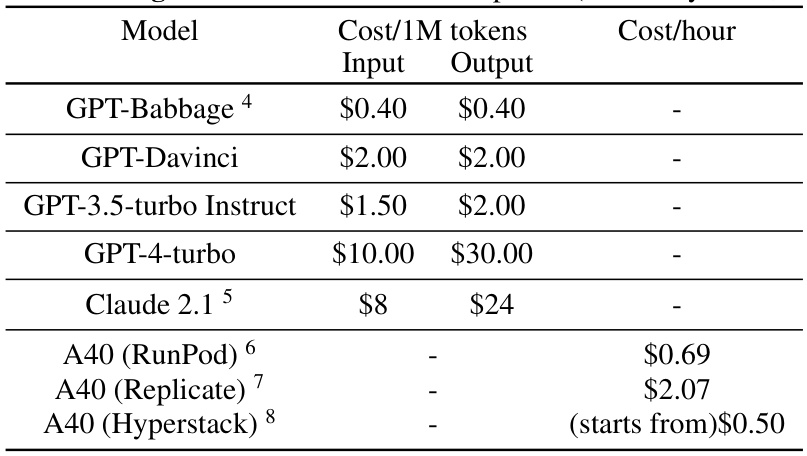
This table compares the privacy, performance, and cost of private adaptations for both closed and open LLMs. It focuses on two tasks: sentiment classification (SST2) and dialog summarization (SAMSum), using several LLMs and adaptation methods. The results highlight that open LLMs offer better privacy, higher performance, and lower costs compared to closed LLMs when considering private adaptations.

This table compares the performance, training cost, and query cost of various private adaptation methods for both open and closed LLMs on four different text classification datasets (SST2, Trec, Mpqa, Disaster). It highlights the superior performance and lower cost of private local adaptations using open LLMs compared to methods using closed LLMs, especially at tighter privacy budgets (lower epsilon values). The ‘Reveals’ column indicates data leakage to the LLM provider. Note that the costs are reported separately for training and 10k test queries.
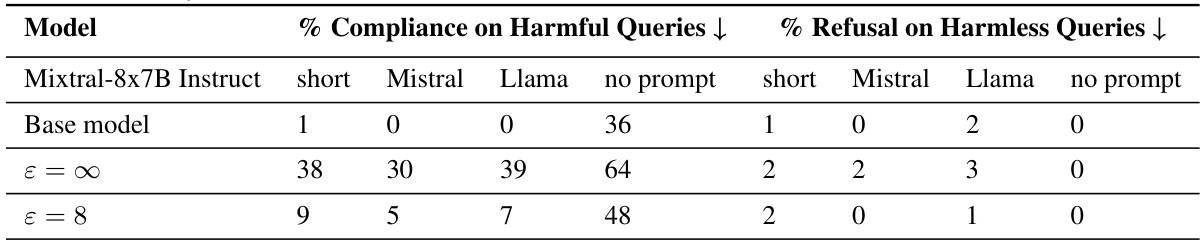
This table compares the privacy, performance, and cost of private adaptations for both closed and open LLMs. It focuses on two tasks: sentiment classification (SST2) and dialog summarization (SAMSum), using various LLMs and adaptation methods. The table highlights that open LLM adaptations generally offer better privacy, higher performance, and lower costs.

This table compares the privacy, performance, and cost of private adaptations for both closed and open LLMs. It focuses on two tasks: sentiment classification (SST2) and dialog summarization (SAMSum), using several different LLMs. Key metrics include accuracy, Rouge-L score, training cost, and query cost. The results show that open LLM adaptations generally offer better privacy, performance, and lower costs.

This table compares the privacy, performance, and cost of private adaptations for closed vs. open LLMs. It focuses on two tasks: sentiment classification (SST2) and dialog summarization (SAMSum), using several different LLMs. Key metrics include accuracy, Rouge-L score, training cost, and query cost. The table highlights that open LLMs offer superior privacy, performance, and lower cost for private adaptations.
Full paper#