↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large-scale visual pretraining has shown remarkable progress but faces challenges due to the high cost and time required for manual data annotation. Contrastive pretraining methods offer a scalable alternative, but often overlook region-specific details within images. Image captioning is an effective approach to visual pretraining, but existing methods often focus on holistic image understanding.
LocCa addresses these issues by incorporating location-aware tasks into image captioning. It uses a multi-task encoder-decoder architecture to predict bounding boxes and generate location-dependent captions. Experiments show LocCa significantly outperforms standard captioners on downstream localization tasks like referring expression comprehension, while maintaining comparable performance on holistic tasks. This work highlights the potential of location-aware natural language interfaces for more efficient and effective visual pretraining.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and natural language processing. It introduces a novel and efficient visual pretraining method, significantly improving downstream localization task performance while maintaining comparable results on holistic tasks. This opens avenues for further exploration of natural language interfaces in visual pretraining and improves existing image captioning models.
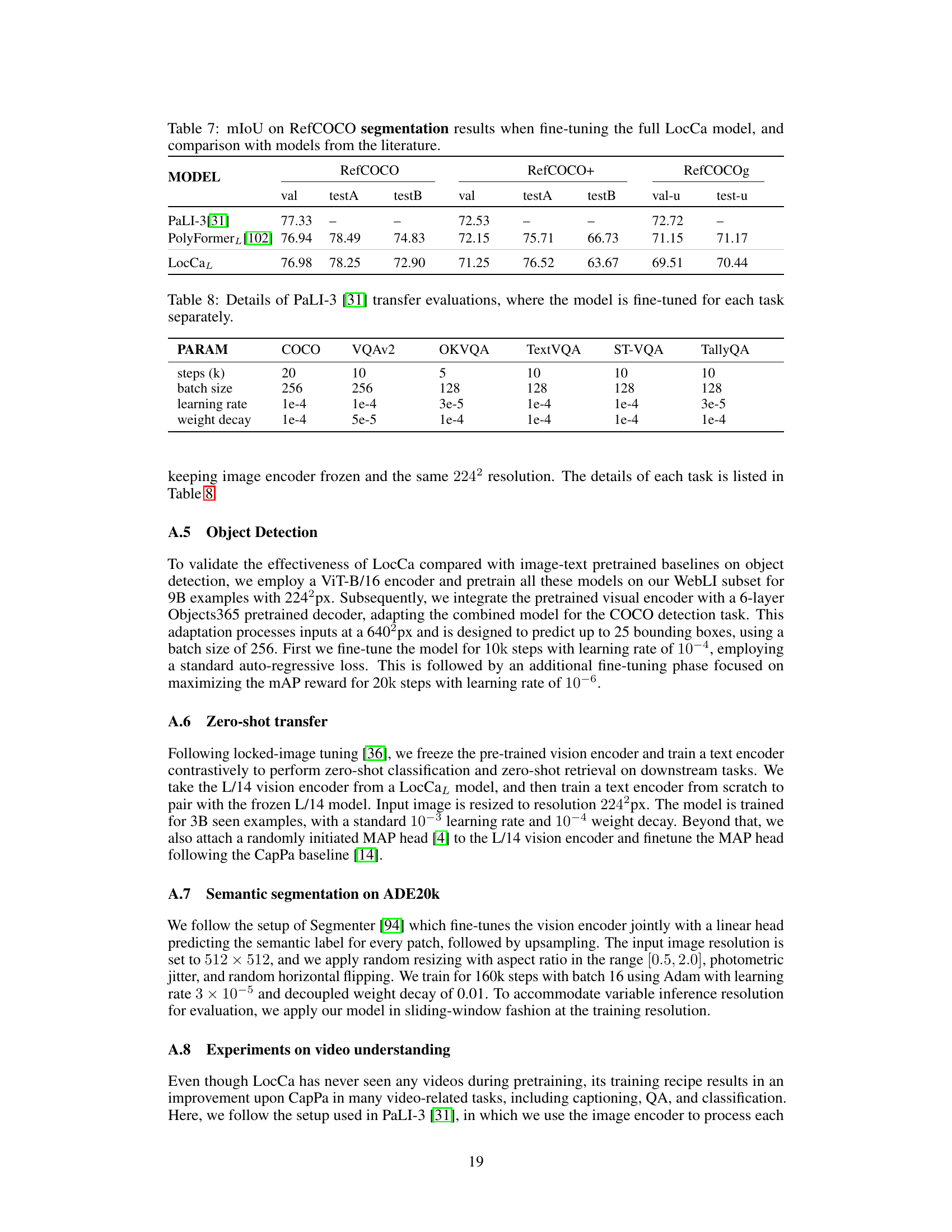
Visual Insights#
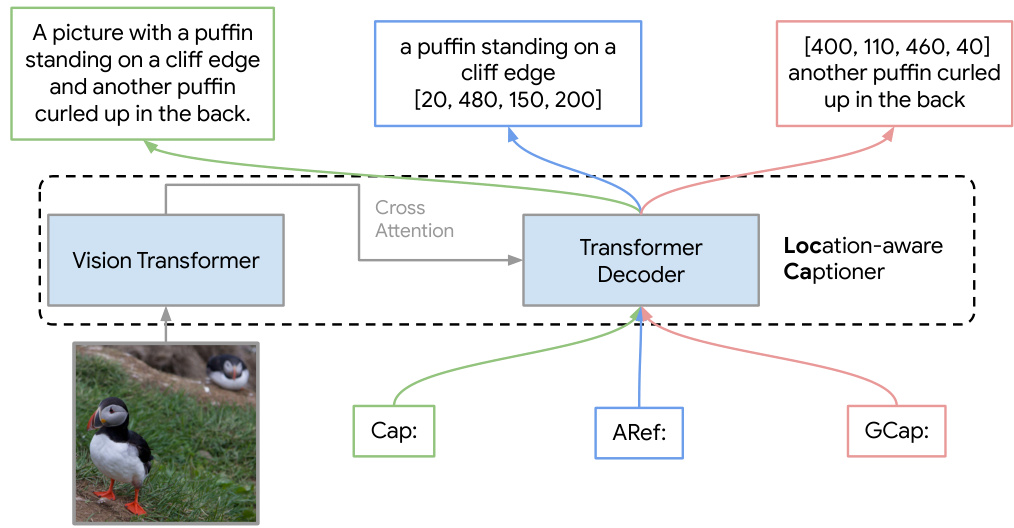
The figure illustrates the architecture of LocCa, a novel visual pretraining paradigm. LocCa uses a vision transformer (encoder) to process image pixels and generate visual tokens. These tokens are then fed into a transformer decoder, which performs three tasks: standard captioning (Cap), automatic referring expression (ARef), and grounded captioning (GCap). The multi-task learning approach allows the model to extract rich information from images and improve downstream performance on both holistic and location-aware tasks.
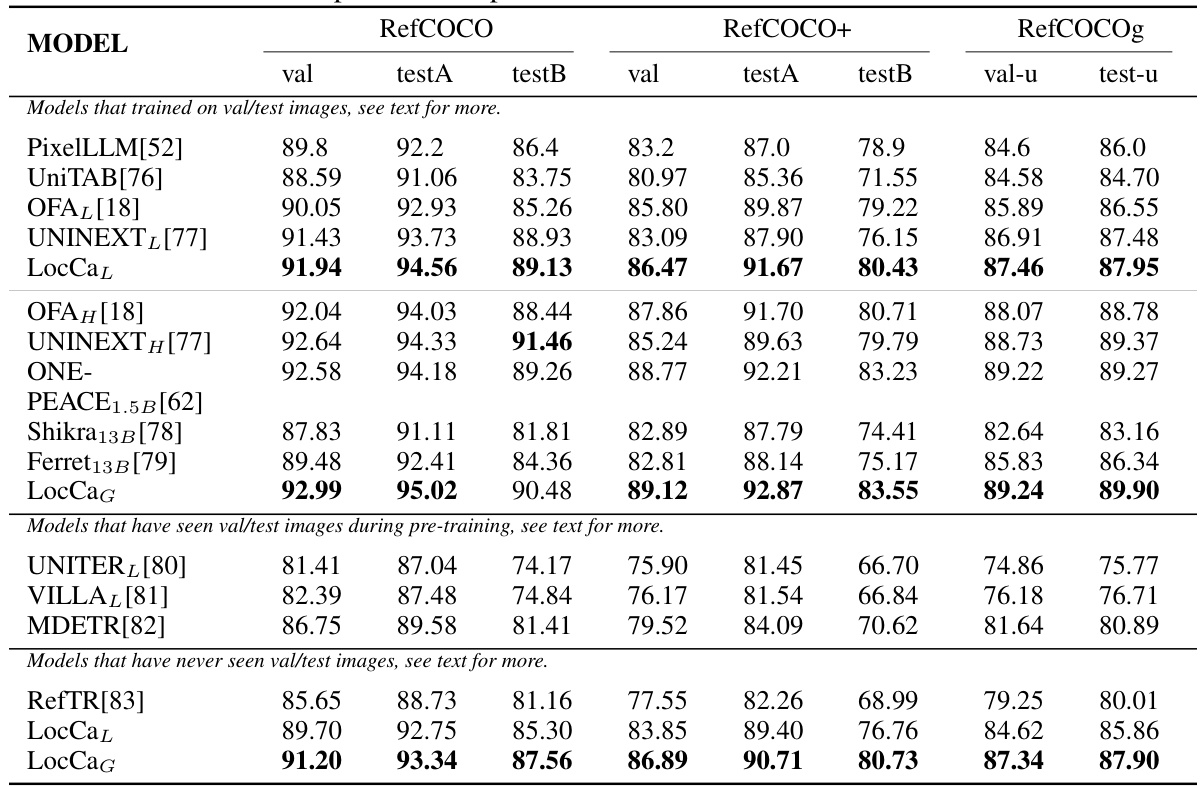
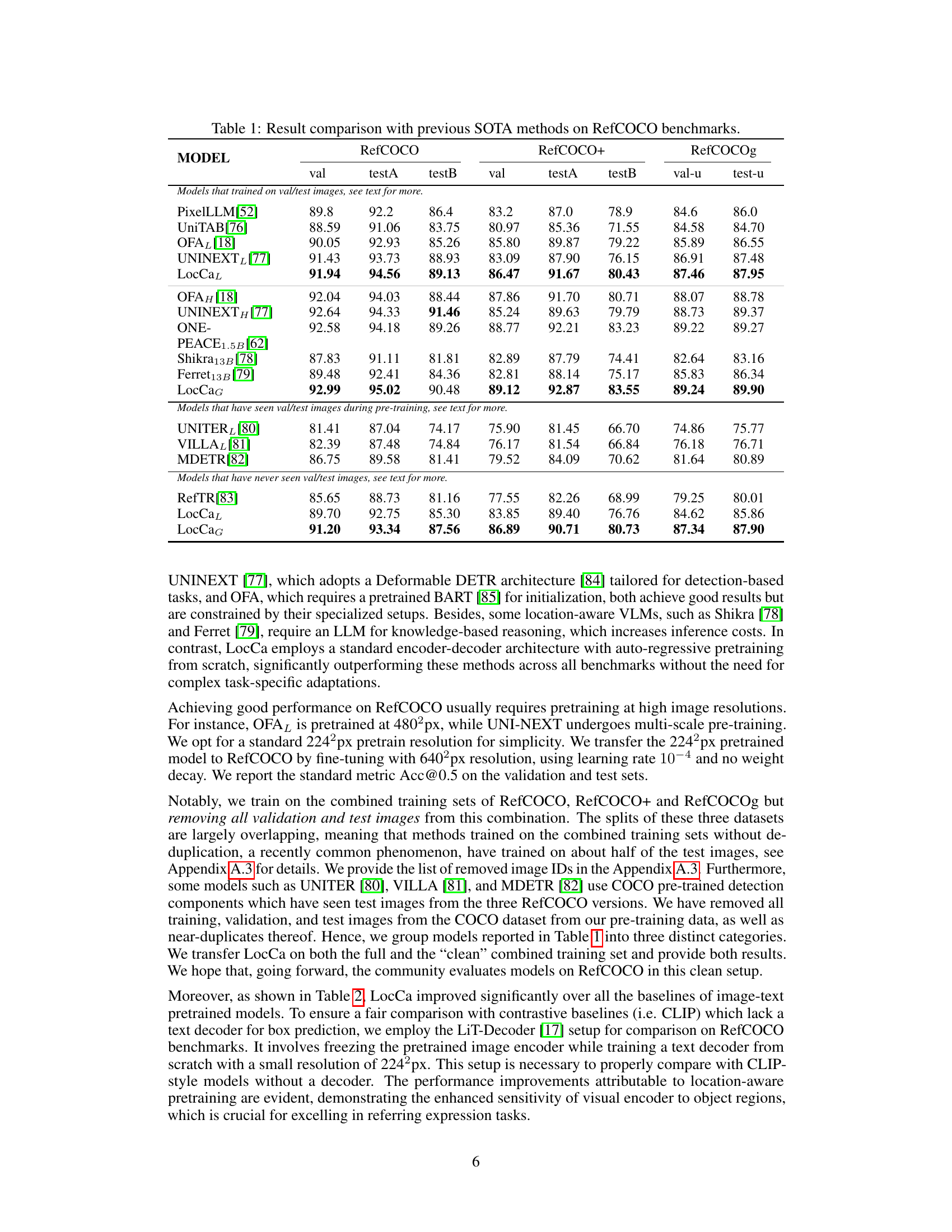
This table compares the performance of the proposed LocCa model with state-of-the-art (SOTA) methods on three RefCOCO benchmarks: RefCOCO, RefCOCO+, and RefCOCOg. The benchmarks evaluate performance on referring expression comprehension tasks. The table is divided into sections based on whether the models were trained on images that were also present in the validation/test sets. LocCa achieves state-of-the-art results on all three benchmarks.
In-depth insights#
LocCa: Pretraining#
The heading ‘LocCa: Pretraining’ suggests a focus on a novel visual pretraining method. LocCa’s core innovation likely involves integrating location-aware tasks into the image captioning process. This contrasts with standard captioning which typically focuses on a holistic image understanding, overlooking region-specific details. LocCa’s multitask learning approach, involving bounding box prediction and location-dependent captioning, likely enables the model to extract richer, more precise information from images during pretraining. The benefits are expected to transfer to downstream tasks. Improved performance on localization tasks is a key outcome, positioning LocCa as a potentially superior model for applications requiring fine-grained visual understanding, such as object detection and referring expression tasks, while maintaining competitiveness on more general image understanding benchmarks. This approach offers a more efficient and flexible alternative to traditional contrastive learning techniques.
Location-Aware#
The concept of ‘Location-Aware’ in computer vision research signifies a significant shift from holistic image understanding to a more granular and precise analysis. It focuses on leveraging spatial information within an image to enhance model performance on downstream tasks. Instead of treating an image as a single entity, location-aware methods dissect it into regions, associating each with relevant features and contextual data. This approach is particularly useful for tasks requiring precise localization, such as object detection, referring expression comprehension, and visual question answering, where understanding the spatial relationships between objects is crucial. The incorporation of location awareness often involves multi-task learning, where models are trained to simultaneously predict locations and relevant textual descriptions or labels. This enhances the model’s ability to capture rich information about both the spatial context and semantic content of the image, resulting in improved accuracy and robustness. The effectiveness of location-aware methods highlights the importance of incorporating spatial reasoning capabilities into visual models, thereby bridging the gap between raw pixel data and high-level semantic understanding.
Multitask Learning#
Multitask learning (MTL) is a subfield of machine learning that focuses on training a single model to perform multiple tasks simultaneously. The core idea is that by learning shared representations among tasks, MTL can improve the efficiency and generalization ability of individual models. This is particularly relevant in computer vision where various tasks, such as image classification, object detection, and segmentation, often share underlying visual features. Sharing knowledge through MTL can reduce the need for large, task-specific datasets, leading to significant cost and time savings. However, careful consideration is needed to avoid negative transfer, where performance on one task hinders another. Appropriate task selection and model architecture are critical for successful MTL, with approaches like parameter sharing or multi-branch networks offering different ways to facilitate efficient joint learning. Effective MTL strategies often enhance generalization and robustness, leading to better performance on novel or low-data scenarios, making it a powerful tool for real-world applications and resource-constrained settings.
Downstream Tasks#
The ‘Downstream Tasks’ section of a research paper is crucial for demonstrating the effectiveness of a proposed model or method. It evaluates the model’s performance on a range of tasks distinct from those used during training, revealing its generalization capabilities and real-world applicability. A strong ‘Downstream Tasks’ section will include a diverse set of tasks, carefully chosen to highlight the model’s strengths and address its potential weaknesses. It should also clearly define evaluation metrics, ensuring that the results are both meaningful and comparable. The choice of downstream tasks should be justified, aligning with the model’s intended applications and the overall research goals. Furthermore, robust statistical analysis and error reporting are essential for establishing the significance of the findings, demonstrating that the improvements in performance are not merely due to chance. A well-structured and in-depth ‘Downstream Tasks’ section is not merely a descriptive section, but rather a compelling argument for the model’s value and potential impact.
Future Directions#
Future research could explore several promising avenues. Improving zero-shot capabilities is crucial, especially for segmentation tasks where pixel-level annotations are lacking. Exploring alternative training paradigms beyond image captioning and contrastive learning could unlock new potential. Investigating the impact of different model sizes and architectures on LocCa’s performance across various downstream tasks would reveal crucial scalability insights. Finally, a thorough examination of LocCa’s robustness to noisy data and its generalization across diverse modalities (beyond image-text) will determine its real-world applicability and limitations. Addressing these key areas will further enhance LocCa’s effectiveness and solidify its position as a leading visual pretraining paradigm.
More visual insights#
More on figures

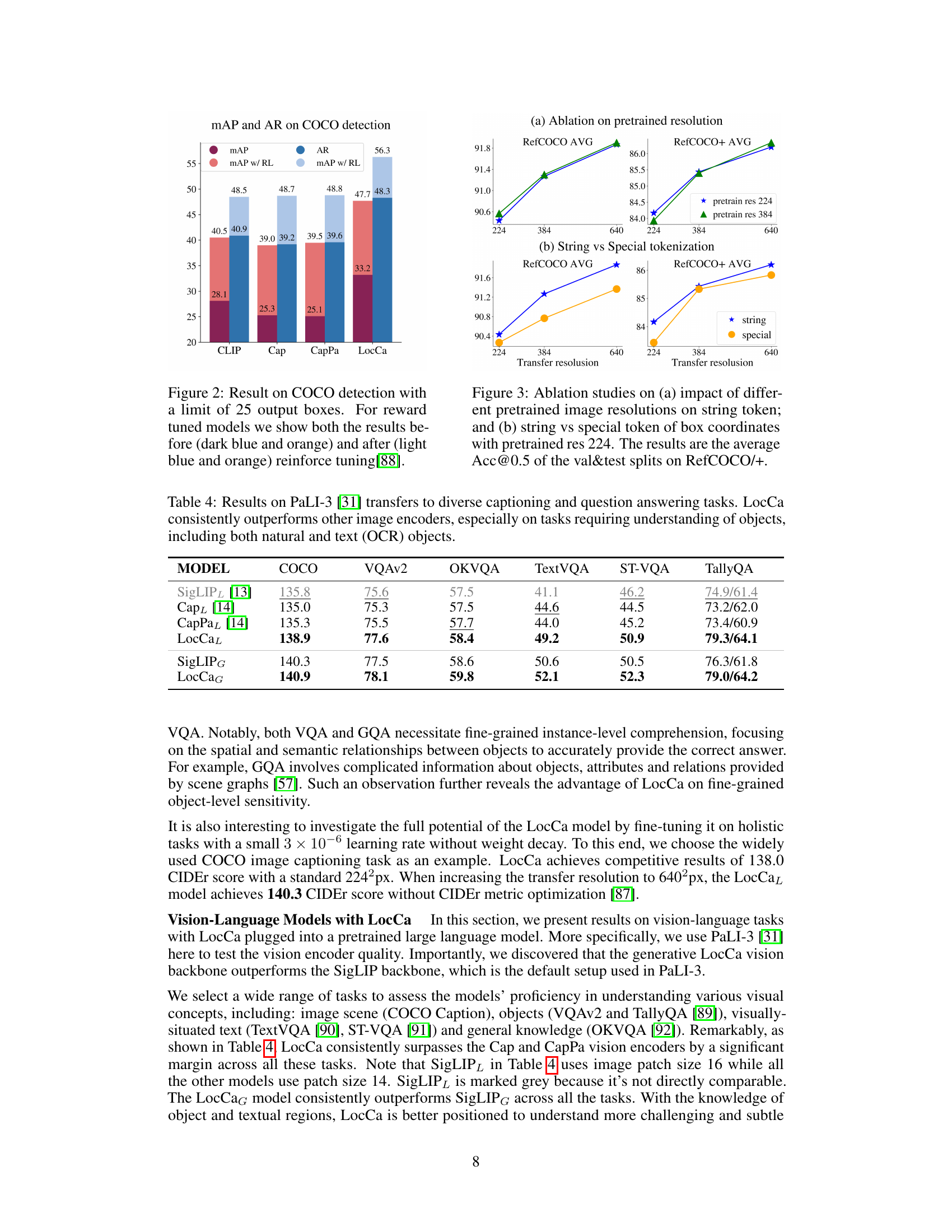
This figure shows the results of COCO detection experiments with a maximum of 25 output boxes. It compares the performance of different models, including CLIP, Cap, CapPa, and LocCa, both before and after reinforcement learning is applied. The bars represent the mean average precision (mAP) and average recall (AR) metrics. LocCa demonstrates superior performance compared to the other models, particularly after the reinforcement learning.
This figure provides a high-level overview of the LocCa architecture. It shows the image pixels as input to a vision transformer, which generates visual tokens. These tokens are then fed into a transformer decoder, which is trained to perform three tasks simultaneously: standard captioning (Cap), automatic referring expression generation (AREF), and grounded captioning (GCAP). The decoder’s multi-task capability is a key feature of LocCa.
This figure provides a high-level overview of the LocCa architecture. It shows the model’s components: a vision transformer (encoder) that processes image pixels and produces visual tokens; and a transformer decoder that takes these tokens as input along with task-specific prefixes and generates outputs (captions, bounding boxes). Three tasks are used during pretraining: Cap (standard captioning), AREF (automatic referring expression), and GCAP (grounded captioning). These tasks encourage the model to learn richer image representations.

This figure provides a high-level overview of the LocCa architecture. It shows the main components: a vision transformer (encoder) that processes image pixels and generates visual tokens, and a transformer decoder that uses these tokens along with task-specific prefixes to generate captions and bounding box coordinates for three different pretraining tasks: Cap (standard image captioning), AREF (automatic referring expressions), and GCAP (grounded captioning). The cross-attention mechanism between the encoder and decoder is highlighted, showing how visual information is integrated into the caption generation process.

This figure shows the architecture of LocCa, a novel visual pretraining paradigm that incorporates location-aware tasks into captioners. It consists of a vision transformer (encoder) that processes image pixels and produces visual tokens, and a transformer decoder that takes these tokens as input, along with task-specific prefixes, to generate captions and predict bounding boxes. Three tasks are used for pretraining: Cap (standard image captioning), AREF (automatic referring expression), and GCAP (grounded captioning). The multi-task decoder allows for efficient training on various tasks.
More on tables

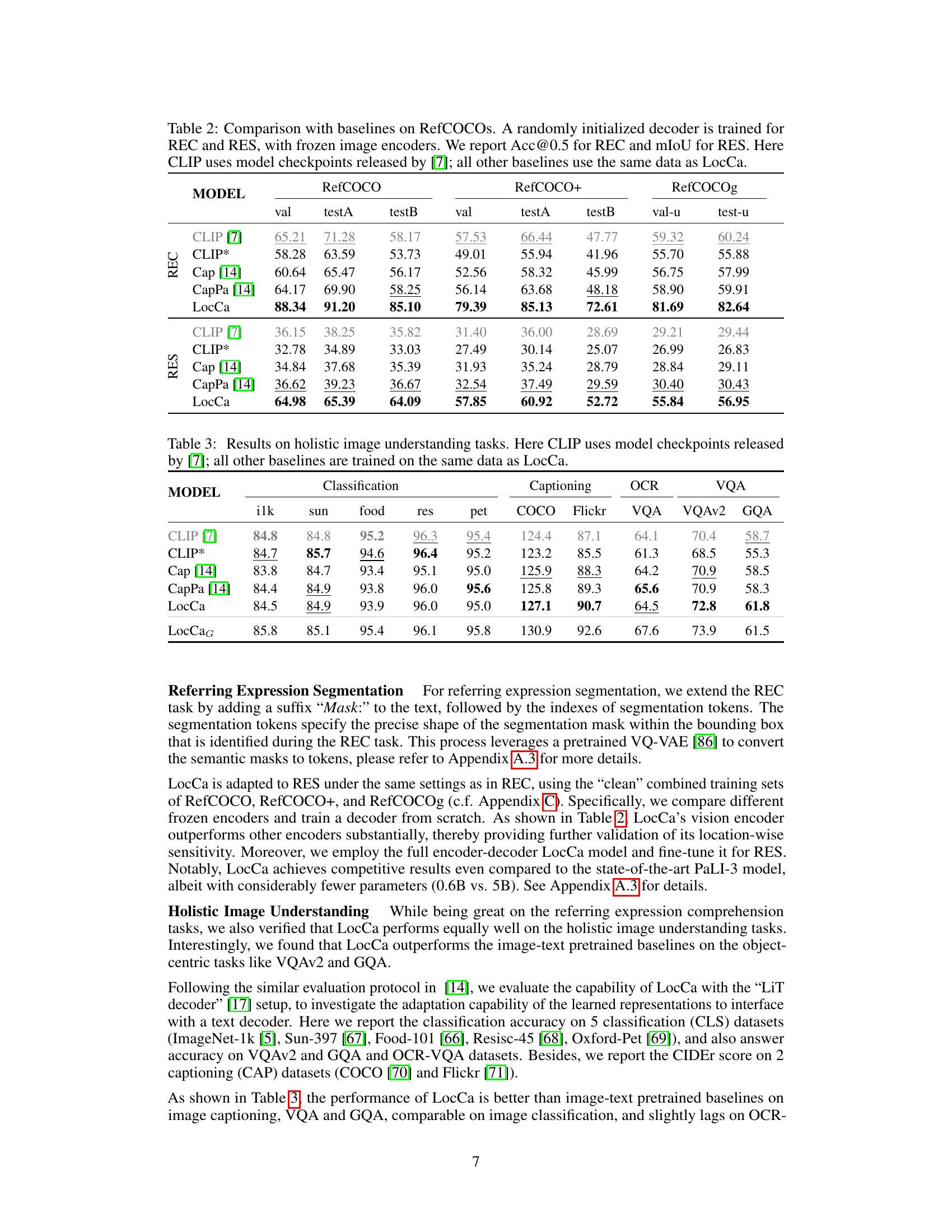
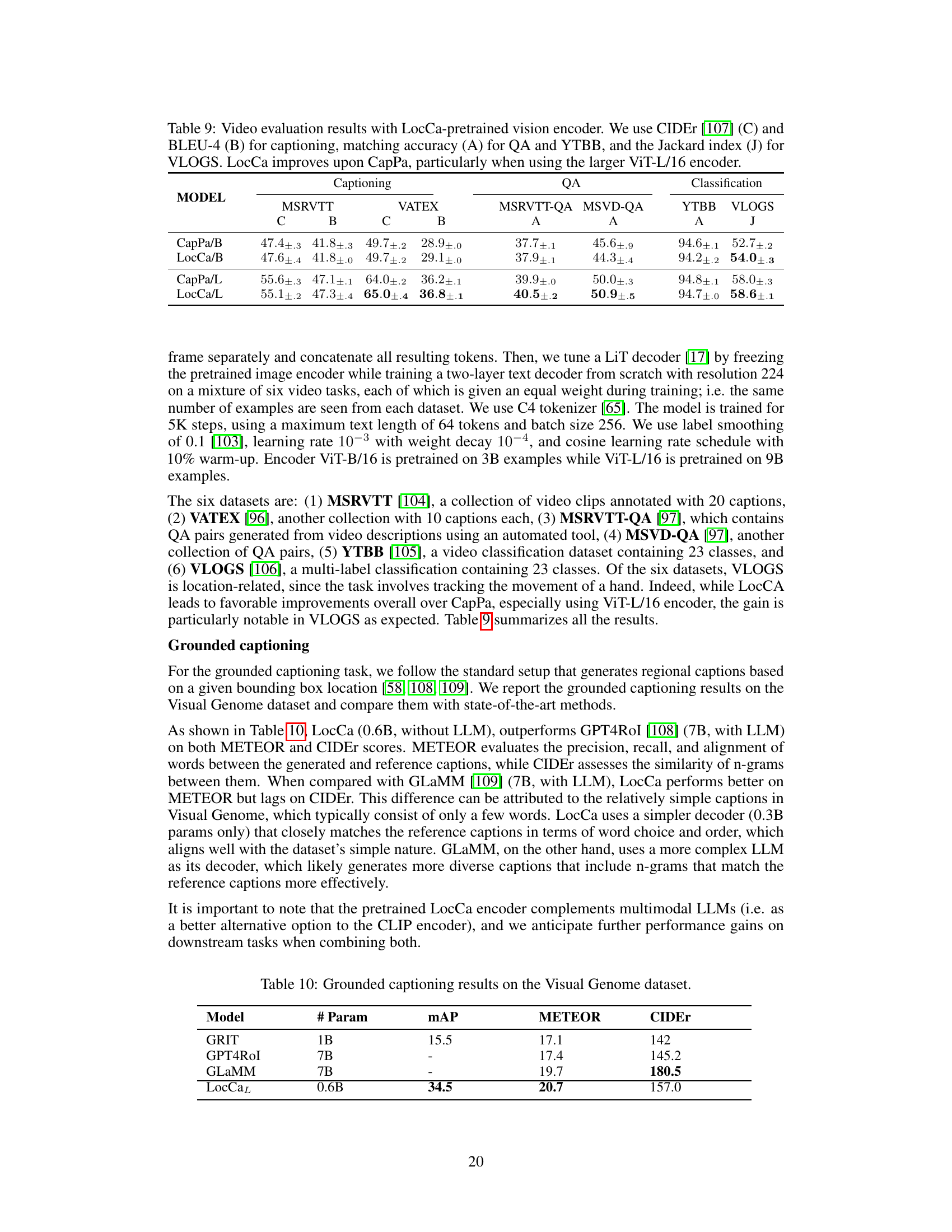
This table compares the performance of LocCa against several baseline models on the RefCOCO, RefCOCO+, and RefCOCOg datasets for both Referring Expression Comprehension (REC) and Referring Expression Segmentation (RES). The baseline models include different versions of CLIP and Captioners. The table highlights LocCa’s superior performance, particularly when considering that its decoder was randomly initialized and the image encoders were frozen. Acc@0.5 represents accuracy at a threshold of 0.5, and mIoU is the mean Intersection over Union.
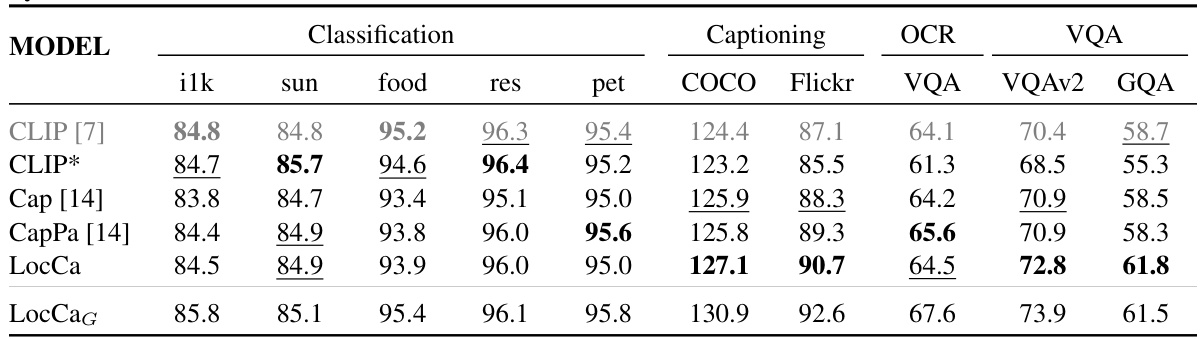
This table presents the quantitative results on holistic image understanding tasks for various models, including CLIP, Cap, CapPa, and LocCa. The tasks evaluated are image classification on six datasets (ILK, SUN, Food, RES, PET, COCO), image captioning on COCO and Flickr datasets, OCR-VQA, VQA, and VQAv2, and GQA. The table allows for comparison of LocCa’s performance against several baseline models in a holistic image understanding context.

This table presents the results of transferring the LocCa model to various downstream tasks using the PaLI-3 framework. It compares LocCa’s performance to several baselines (SigLIPL, Cap, CapPaz) across six different tasks: COCO captioning, VQAv2, OKVQA, TextVQA, ST-VQA, and TallyQA. The results demonstrate that LocCa consistently outperforms the baseline models, particularly on tasks that necessitate understanding objects (both natural images and OCR text).
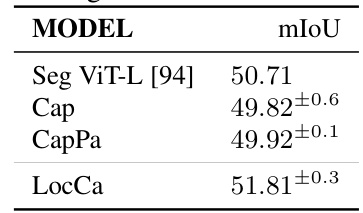
This table presents the results of fine-tuning different vision backbones (Seg ViT-L, Cap, CapPa, and LocCa) with a linear head for semantic segmentation on the ADE20k dataset. The main metric reported is the mean Intersection over Union (mIoU), which measures the accuracy of the segmentation. The table shows that LocCa outperforms other methods, suggesting its effectiveness in learning detailed visual representations.

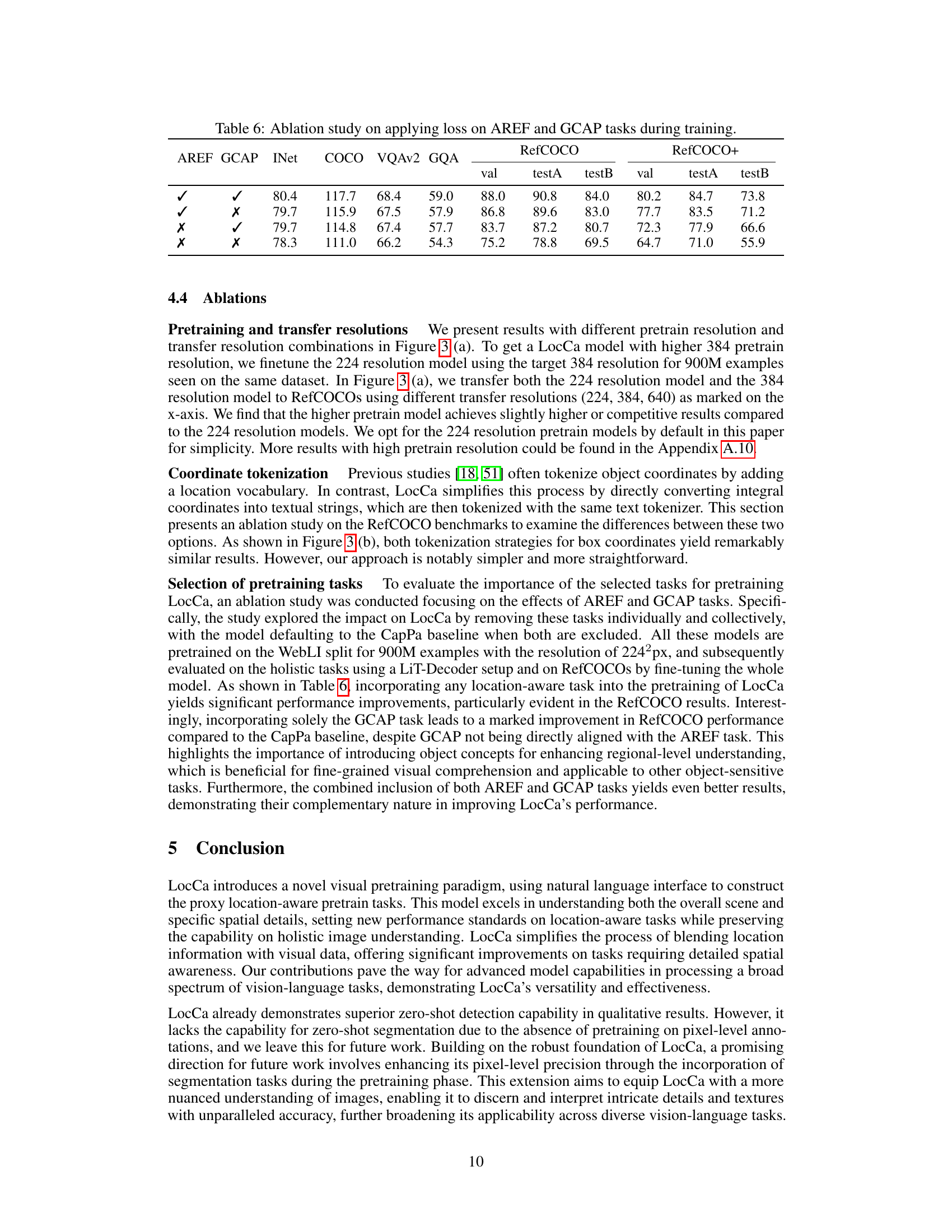
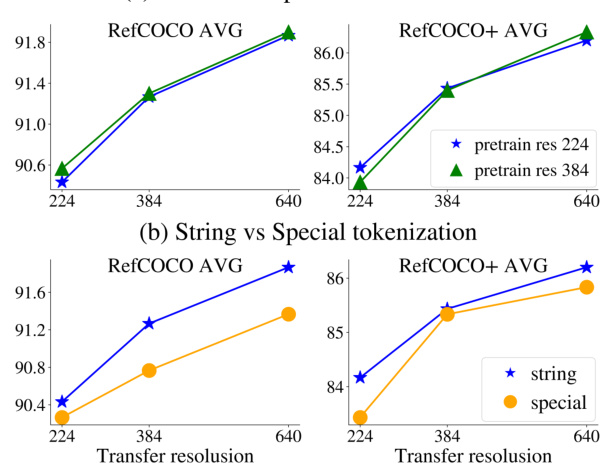
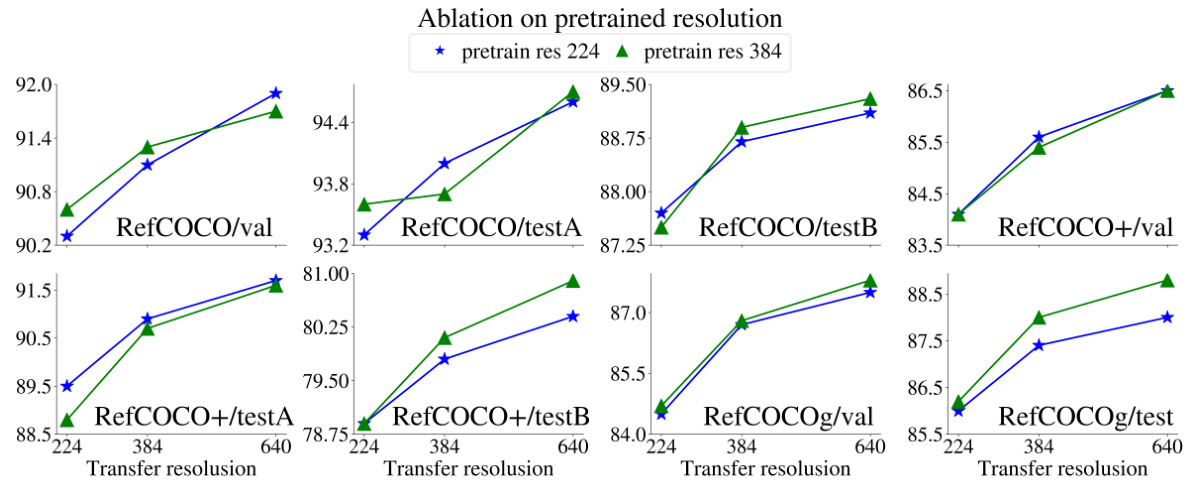
This table presents the ablation study results focusing on the impact of applying loss on AREF and GCAP tasks during the training process. It shows the performance of the LocCa model across various tasks (ImageNet classification, COCO captioning, VQAv2, and GQA) and metrics (RefCOCO and RefCOCO+) under different combinations of applying or not applying loss on AREF and GCAP. This allows analyzing the individual and combined effects of location-aware tasks on the model’s overall performance.

This table compares the performance of the proposed method, LocCa, against other state-of-the-art (SOTA) methods on three RefCOCO benchmarks: RefCOCO, RefCOCO+, and RefCOCOg. It shows the validation and test results (Acc@0.5) for each method on each benchmark, highlighting LocCa’s superior performance. The table also categorizes methods based on whether they’ve seen validation/test images during pretraining. This provides context for the comparison by indicating factors influencing results.

This table details the hyperparameters used for fine-tuning the PaLI-3 model on various downstream tasks. It shows the number of training steps, batch size, learning rate, and weight decay used for each task (COCO, VQAv2, OKVQA, TextVQA, ST-VQA, TallyQA). The image encoder was frozen during fine-tuning, and the resolution remained at 224x224.
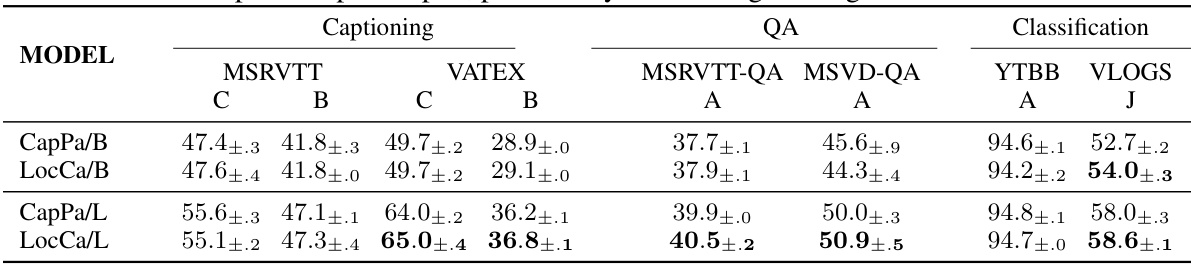
This table presents the results of video evaluation tasks using the LocCa-pretrained vision encoder. It compares the performance of LocCa and CapPa across several video-related tasks, including captioning (using CIDEr and BLEU-4 scores), question answering (using accuracy), and classification (using accuracy and Jaccard index). The results are presented separately for two different encoder sizes (ViT-B/16 and ViT-L/16), demonstrating the impact of encoder size on performance.

This table compares the performance of LocCa with several baseline models on the RefCOCO, RefCOCO+, and RefCOCOg datasets for referring expression comprehension (REC) and referring expression segmentation (RES). It highlights LocCa’s superior performance, especially when using a randomly initialized decoder and frozen image encoders. The results demonstrate the effectiveness of LocCa’s approach, even when compared against models that utilize pretrained components or different training methods.

This table compares the performance of LocCa with state-of-the-art (SOTA) methods on three RefCOCO benchmark datasets: RefCOCO, RefCOCO+, and RefCOCOg. The results are shown for both validation and test sets (testA and testB). It highlights LocCa’s performance relative to other models that have (or have not) seen the validation/test data during pre-training, distinguishing between different training regimes and model architectures.
Full paper#