↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Creating diverse, realistic 3D environments is crucial for advancing robotics and embodied AI research. Existing methods, like manual design, procedural generation, or LLM-based approaches, face limitations in scalability, realism, and spatial reasoning. These limitations hinder the creation of large-scale, interactive environments needed for training embodied AI agents.
ARCHITECT addresses these challenges by leveraging the strengths of pre-trained 2D image generative models and depth estimation. It employs a novel hierarchical 2D inpainting technique that effectively controls camera parameters and depth scale, enabling accurate 3D reconstruction. By iteratively inpainting foreground objects against a photorealistic background, the system generates complex scenes with realistic object placement. This approach leads to highly realistic and interactive 3D environments suitable for embodied AI and robotics applications, outperforming current state-of-the-art methods.
Key Takeaways#
Why does it matter?#
This paper is significant because it presents a novel approach to generating realistic and interactive 3D environments, a critical need in embodied AI and robotics. ARCHITECT’s hierarchical 2D inpainting method offers a more effective and scalable solution compared to existing methods, opening up new avenues for research in scene generation, virtual world creation, and AI-driven simulation. Its zero-shot capabilities and capacity to handle complex scenes are particularly valuable.
Visual Insights#

This figure shows two examples generated by the ARCHITECT model: an apartment and a grocery store. Each example demonstrates the model’s ability to generate complex and realistic 3D scenes with diverse object arrangements and realistic textures. The images highlight the open-vocabulary nature of the model, capable of generating scenes beyond predefined categories.

This table compares ARCHITECT with other methods for generating large-scale 3D scenes. The comparison considers five aspects: whether the method requires training, human effort, interactivity, generation of organized small objects, and open vocabulary scene generation. ARCHITECT is shown to be superior by requiring neither training data nor significant human effort, while also generating interactive scenes with organized small objects and open vocabulary.
In-depth insights#
2D Diffusion Power#
The heading ‘2D Diffusion Power’ likely refers to the capabilities of 2D diffusion models in generating realistic and detailed images, which are then leveraged for 3D scene creation. This approach bypasses the limitations of traditional methods, such as procedural generation or reliance on predefined rules, which often struggle to produce diverse and complex scenes. The core idea is that pre-trained 2D diffusion models have already learned intricate visual patterns and relationships from massive datasets, offering a powerful starting point for 3D generation. By utilizing these models, the system can generate diverse foreground elements within a controlled 3D context, creating richer and more realistic scenes. The ‘power’ lies in the ability to transfer the learned knowledge from 2D to 3D, overcoming challenges in 3D spatial reasoning and enabling the generation of highly detailed and semantically coherent environments. However, a key challenge would be effectively integrating the 2D generated content into a consistent 3D space, requiring robust depth estimation and scene understanding techniques. Further research might explore advancements in these techniques to better harness the full potential of 2D diffusion models for complex 3D scene generation.
Hierarchical Inpaint#
The concept of “Hierarchical Inpaint” in the context of 3D scene generation suggests a multi-scale approach to image inpainting. It likely involves iteratively inpainting at different levels of detail, starting with coarser features like the overall scene layout and gradually refining to finer details such as individual object placement and textures. This hierarchical strategy allows for more effective control over the generated scene, preventing inconsistencies and errors that can arise when inpainting complex images in a single pass. Lower levels can leverage information obtained from higher levels, thus ensuring coherence and realism. For instance, the background might be inpainted first, providing context and geometric cues to guide the placement of foreground objects during subsequent inpainting stages. This method is particularly beneficial for creating complex 3D environments, as it allows for a more manageable and efficient generation process compared to trying to create the entire scene in one go. The framework’s effectiveness depends greatly on the quality and capabilities of the underlying image inpainting model as well as the choice of appropriate segmentation and object recognition algorithms that interpret the inpainted images for 3D scene construction.
3D Scene Synthesis#
3D scene synthesis is a crucial area of research with vast implications for diverse fields. The goal is to generate realistic and complex 3D environments, and current methods face challenges in balancing detail, diversity, and computational cost. Manual design is laborious, while procedural approaches lack flexibility and diffusion models struggle with high-resolution details and complex object interactions. Large language models offer a promising path, but their spatial reasoning capabilities remain limited. A key challenge is to effectively bridge the gap between 2D image generation models (which excel at capturing intricate details and object configurations) and the 3D world. Successfully controlling camera parameters and scale within the 3D rendering process remains essential. Hierarchical and iterative inpainting techniques show potential for achieving greater control and complexity. Ultimately, a robust and efficient 3D scene synthesis method would offer significant value for applications ranging from embodied AI and robotics to virtual and augmented reality, demanding further advancements in the integration of foundation models and novel generative techniques.
Embodied AI#
Embodied AI, a subfield of artificial intelligence, focuses on creating AI systems that are situated within physical bodies and interact with the real world. This contrasts with traditional AI, which often operates in simulated or abstract environments. The key aspect is grounding AI in physical experience, enabling it to learn and reason from sensorimotor interactions. The research paper’s focus on generating realistic and interactive 3D scenes directly addresses a significant challenge in embodied AI: the creation of diverse, complex, and engaging training environments. High-quality, realistic 3D environments are crucial for training embodied agents, allowing them to learn robust and generalizable behaviors. By leveraging 2D image inpainting and hierarchical approaches, the work offers a promising solution to address limitations of existing methods that use rule-based or LLM approaches, which struggle with generating complex 3D scenes. Therefore, this research contributes significantly to advancing embodied AI research by tackling the significant challenge of data generation for realistic environments and, potentially, the development of more sophisticated and adaptable embodied agents.
Future of ARCHITECT#
The future of ARCHITECT hinges on addressing its current limitations and exploring new avenues for improvement. Expanding the diversity of generated objects is crucial, potentially through integrating advanced 3D generative models or incorporating user-provided assets. Improving the efficiency and scalability of the system is essential, particularly given the computational demands of rendering complex scenes. This could involve exploring optimized rendering techniques or distributing the processing across multiple machines. Enhancing the controllability of the generation process, perhaps through more sophisticated prompt engineering or integrating user feedback mechanisms, would also significantly improve the usability and output quality. Finally, investigating new applications for ARCHITECT beyond embodied AI and robotics, such as virtual and augmented reality or architectural design, could unlock its full potential and broaden its impact.
More visual insights#
More on figures

This figure illustrates the overall pipeline of the ARCHITECT framework. It shows the process of generating a complex interactive 3D scene starting from an empty room. The process consists of four main modules: Initializing, Inpainting, Visual Perception, and Placing. The Initializing module sets up the initial scene by rendering an image of an empty room. The Inpainting module then takes the rendered image and inpaints the foreground objects according to a given text prompt. The Visual Perception module extracts semantic information and geometric cues from the inpainted image to understand object arrangement. Finally, the Placing module places the identified objects into the 3D environment according to their positions and other information. This figure also shows that the pipeline is iterative and hierarchical, processing large furniture first before adding small objects for a more detailed and realistic scene.

This figure compares the results of ARCHITECT with other methods (Holodeck, DiffuScene, and Text2Room) for generating household (living room and dining room) and non-household (hospital room, hair salon, video store, casino, children’s room, shoe store) scenes. It visually demonstrates the differences in scene realism, complexity, and the arrangement of objects, particularly small objects. The comparison highlights ARCHITECT’s ability to create more realistic and complex scenes with better organization of objects compared to the other methods.

This figure shows two examples of robot manipulation tasks generated within the 3D scenes created by the ARCHITECT model. The tasks are complex and require nuanced interactions, highlighting the framework’s ability to produce realistic and interactive environments suitable for embodied AI and robotics research. The left panel depicts a robot moving a glass from one table to another in a dining room setting, while the right panel shows a robot picking up bottles and placing them in a shopping cart in a grocery store. These tasks demonstrate the potential for using the generated environments for the development and testing of complex robotic control algorithms.

This figure shows two examples of robot manipulation tasks generated within the 3D scenes created by the ARCHITECT framework. The top row depicts a robot moving a glass from one table to another in a dining room setting. The bottom row shows a robot interacting with a shopping cart and shelves in a grocery store-like environment. These examples highlight the framework’s ability to produce complex and realistic scenes suitable for embodied AI and robotics research.
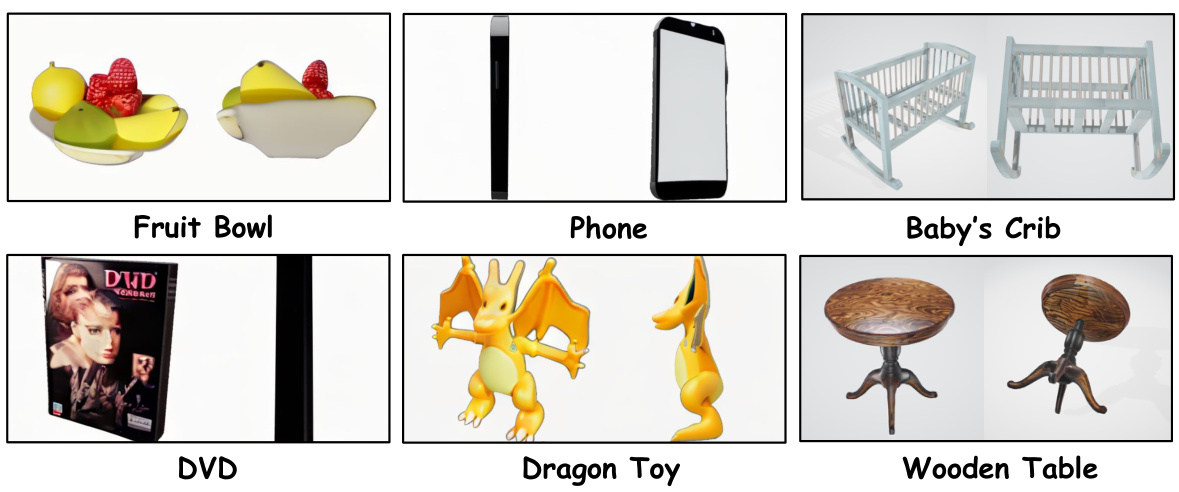
This figure showcases examples of both small objects (fruit bowl, phone, DVD, dragon toy) and large furniture (baby’s crib, wooden table) that were generated using the ARCHITECT framework. It highlights the diversity and level of detail achievable in object generation using the method proposed in the paper.

This figure compares the quality of living room and dining room scenes generated by three different methods: ARCHITECT, Text2room, and Diffuscene. It visually demonstrates the differences in realism, detail, and overall scene composition achieved by each approach. ARCHITECT’s scenes show significantly higher photorealism and better arrangement of objects compared to the other two, showcasing its ability to generate more complex and detailed interior designs.

This figure compares the results of ARCHITECT with other methods in generating various scenes, including living rooms, dining rooms, children’s rooms, casinos, hospital rooms, and hair salons. It visually demonstrates the differences in realism and detail between ARCHITECT and the other methods (Holodeck, Text2Room, and DiffuScene). The comparison highlights ARCHITECT’s ability to generate more realistic and complex scenes with organized small objects and open vocabulary.

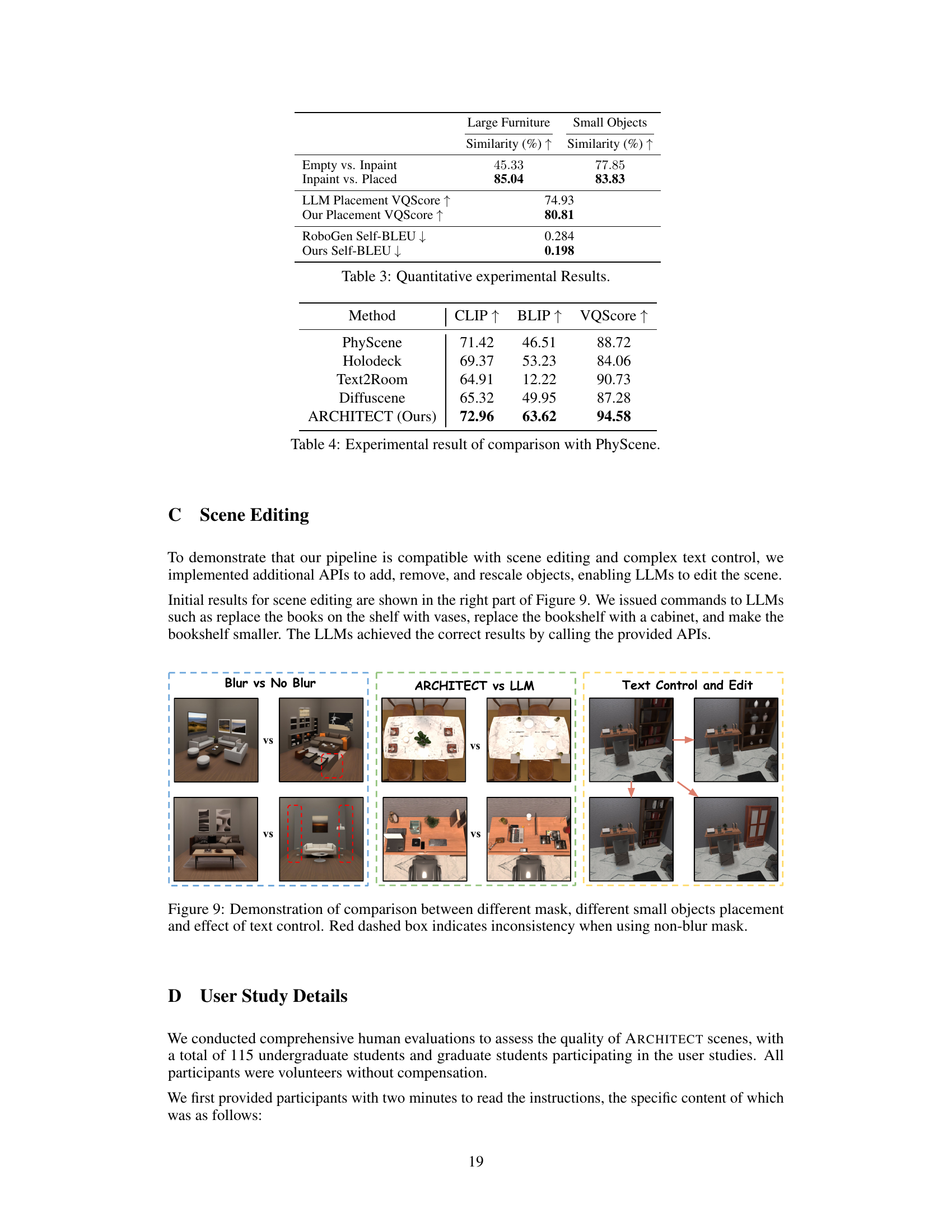
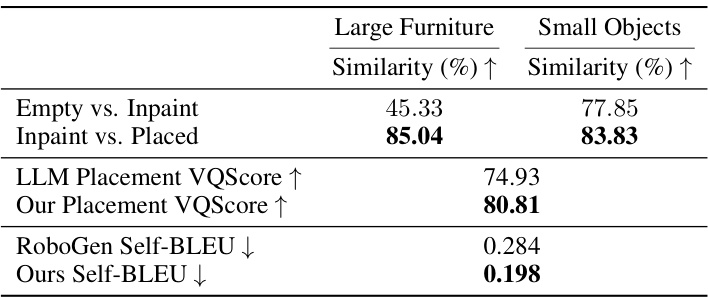
This figure demonstrates three aspects of the ARCHITECT pipeline. The leftmost column compares inpainting results with and without applying a Gaussian blur to the mask before inpainting. The results show that using Gaussian blur leads to more consistent and realistic inpainting. The middle column compares the results of small object placement using ARCHITECT and LLMs. It shows that ARCHITECT is able to generate more realistic and semantically correct small object placements. The rightmost column demonstrates the text-control and editing capabilities of ARCHITECT. It shows that by providing text descriptions, the system can add, remove, and rescale objects within a scene.
This figure showcases the capabilities of ARCHITECT, a generative framework for creating diverse and complex embodied AI scenes. It visually demonstrates the generation of two distinct and highly detailed scenes: an apartment and a grocery store, showcasing the system’s ability to produce realistic and open-vocabulary environments. Each scene displays a variety of furniture and objects, emphasizing both the complexity and variety achievable by ARCHITECT.
More on tables

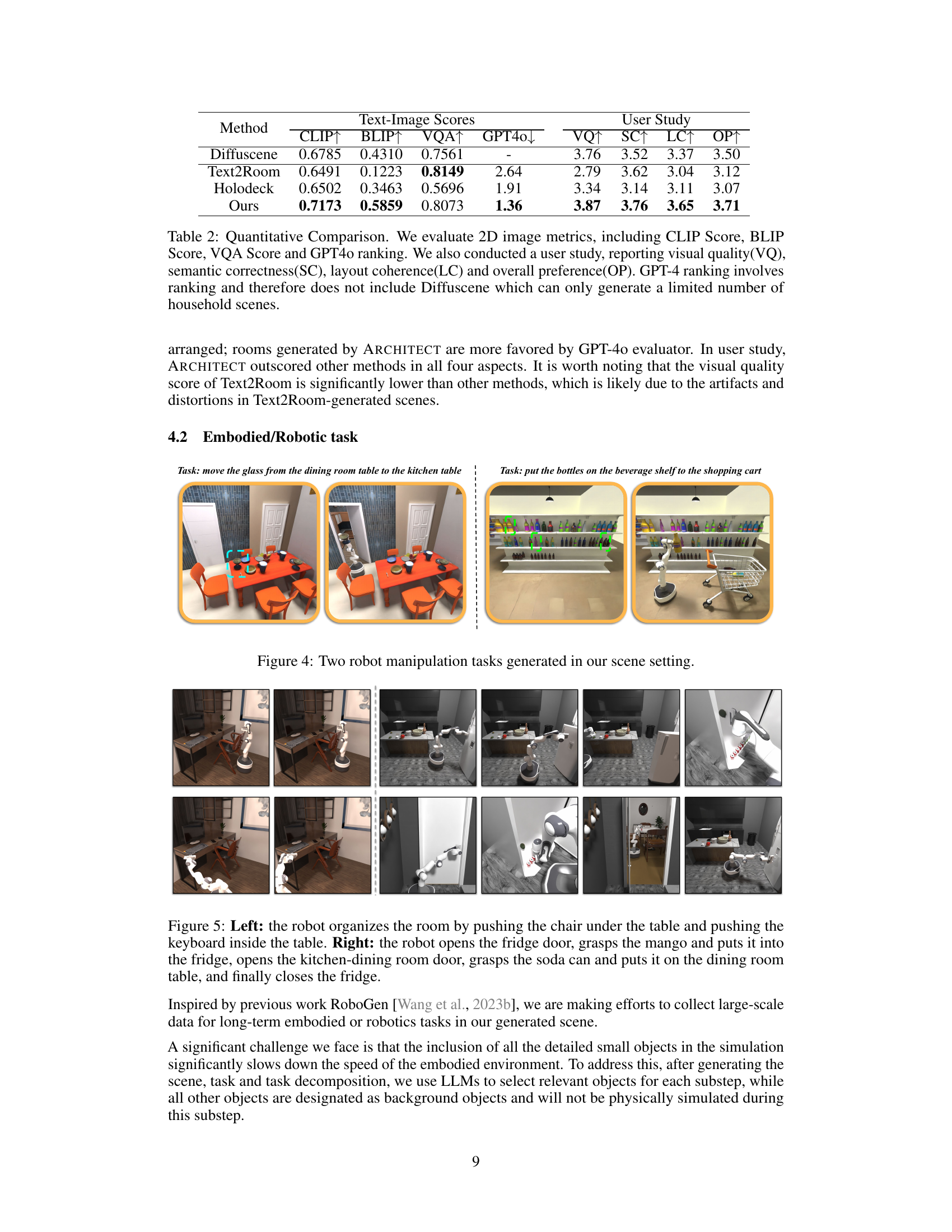
This table presents a quantitative comparison of different methods for generating indoor scenes. It compares the performance of ARCHITECT against several baselines (Diffuscene, Text2Room, and Holodeck) using four metrics derived from text-image comparisons (CLIP, BLIP, VQA scores, and GPT-4 ranking). Additionally, a user study evaluates visual quality, semantic correctness, layout correctness, and overall preference, providing a qualitative assessment to supplement the quantitative results. Note that Diffuscene is excluded from GPT-4 ranking because of its limited scope.
This table compares ARCHITECT with other methods for generating large-scale 3D scenes across five key aspects: whether the method requires training, human effort, interactivity, organized small objects, and open vocabulary. ARCHITECT is shown to be superior in all these aspects, requiring neither training data nor significant human input while achieving high levels of interactivity, detailed object arrangement, and open vocabulary support.

This table presents a quantitative comparison of different methods for generating indoor scenes. The comparison uses several metrics evaluating the visual and semantic quality of the generated images, such as CLIP score, BLIP score, VQA score, and GPT-4 ranking. Additionally, a user study was conducted to assess visual quality, semantic correctness, layout coherence, and overall preference. Note that DiffuScene is excluded from the GPT-4 ranking due to its limited output of household scenes.
Full paper#