↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Magnetic Resonance Imaging (MRI) faces a challenge in balancing image quality and speed, often requiring undersampled k-space measurements that lead to image artifacts. Current deep learning methods, including diffusion models, aim to reconstruct high-quality images from this undersampled data, but may struggle with generating temporally consistent sequences.
This work introduces a new model, Autoregressive Image Diffusion (AID), specifically designed to address this issue. AID incorporates both undersampled k-space data and pre-existing information to generate sequentially coherent image sequences. The results demonstrate that AID outperforms standard diffusion models in MRI reconstruction, reducing artifacts and improving the overall quality of the reconstructed images.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel autoregressive image diffusion (AID) model for generating high-quality image sequences, particularly relevant for accelerated MRI reconstruction. The AID model outperforms standard diffusion models by leveraging learned dependencies between images, reducing artifacts and improving reconstruction accuracy. This opens new avenues for research in medical image processing and other applications involving sequential image data.
Visual Insights#
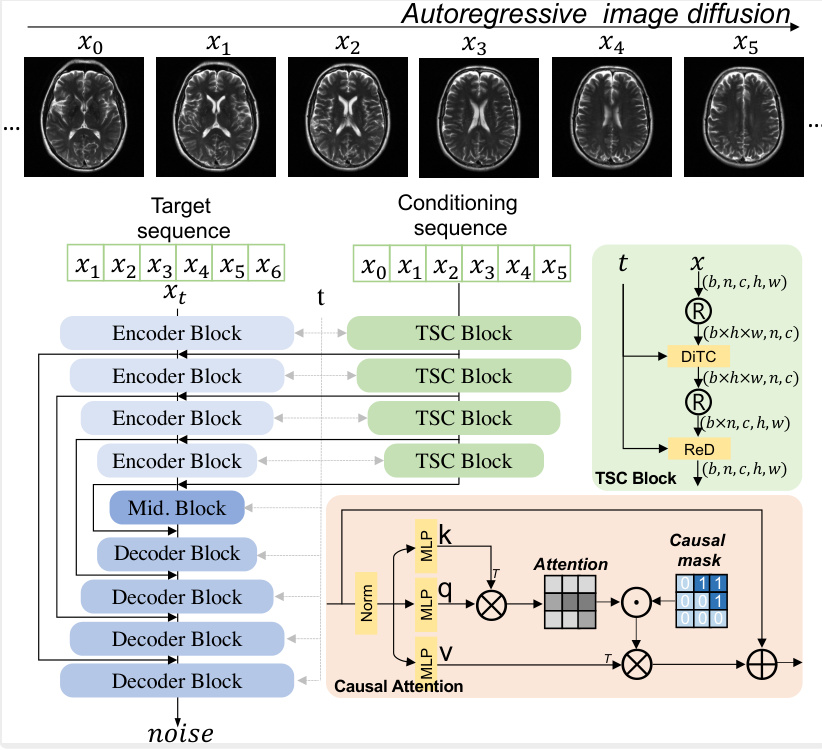
This figure illustrates the architecture of the autoregressive image diffusion (AID) model. The model processes a conditioning sequence of images (X0, X1, X2, X3, X4, X5) to predict the noise for a target sequence of images (X1, X2, X3, X4, X5, X6). The key component is the DiTBlock, which uses a causal attention mechanism to ensure that the prediction for each image in the target sequence only depends on the preceding images in both the target and conditioning sequences. This ensures the sequential coherence of generated images. During training, the network learns to predict the noise added to the target images, while during generation, it iteratively refines noisy images to produce clean samples, effectively reversing the diffusion process. The encoder and decoder blocks in the U-net-like architecture and TSC block handles temporal-spatial conditioning. The figure highlights the flow of information and the role of the causal attention mechanism in generating coherent image sequences.

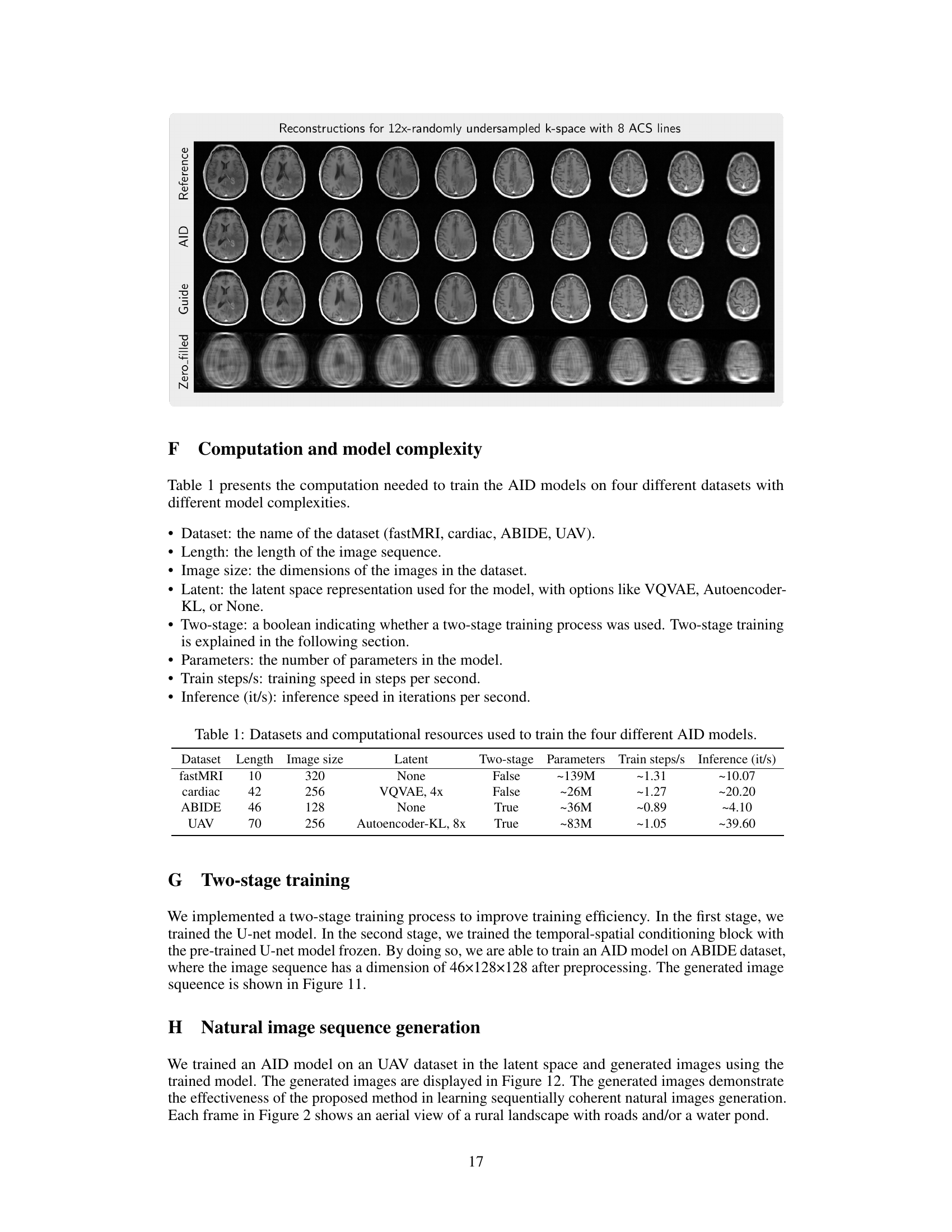
This table details the computational resources and training time required for training four different autoregressive image diffusion (AID) models on various datasets. It shows the dataset used, the length and size of the image sequences within that dataset, the type of latent space representation used (if any), whether a two-stage training process was employed, the total number of model parameters, the training speed in steps per second, and the inference speed in iterations per second. This information helps in understanding the computational cost associated with training and using AID models for different applications and datasets.
In-depth insights#
AID Model for MRI#
The proposed AID (Autoregressive Image Diffusion) model presents a novel approach to MRI reconstruction by leveraging both the power of diffusion models and autoregressive techniques. Its key innovation lies in modeling the dependencies between sequential images, a significant improvement over standard diffusion models that treat each image independently. This approach enables the generation of high-quality, temporally coherent image sequences, particularly beneficial for applications involving dynamic processes. The integration of pre-existing information further enhances reconstruction accuracy and reduces artifacts. The model’s ability to outperform standard diffusion models and mitigate hallucinations highlights its effectiveness in handling undersampled k-space data. Further research could explore its applications in other medical imaging modalities and investigate its potential for improving image quality across a wider range of scanning parameters and sampling patterns. The development of a robust model that addresses these challenges would make a significant contribution to the field of medical imaging.
Autoregressive Diffusion#
Autoregressive diffusion models offer a novel approach to generative modeling by combining the strengths of autoregressive and diffusion models. Autoregressive modeling excels at capturing sequential dependencies, ensuring coherent generation of image sequences. Diffusion models are effective in modeling complex image distributions, providing high-quality samples. The combination generates image sequences with high fidelity and temporal consistency, outperforming standard diffusion methods in applications such as accelerated MRI reconstruction. A key advantage is the ability to incorporate pre-existing information, further enhancing accuracy and reducing artifacts. The autoregressive component learns the relationships between images within a sequence, significantly improving sequential coherence in generated outputs. This approach offers significant potential for various applications involving temporal image data.
MRI Reconstruction#
The section on ‘MRI Reconstruction’ would delve into the core challenge of recovering high-quality images from undersampled k-space data. It would likely detail the Bayesian framework used, explicitly defining the likelihood function (based on the noise model and forward operator) and the prior probability distribution. The paper would showcase how their autoregressive image diffusion (AID) model serves as this prior, significantly impacting reconstruction accuracy. This section would probably discuss the algorithm’s implementation, including how the posterior distribution is sampled (likely using Markov Chain Monte Carlo methods), possibly highlighting the efficiency gains from the AID model. Furthermore, it would analyze the reconstruction’s performance, comparing AID against conventional methods using standard metrics (PSNR, NRMSE) across various undersampling scenarios. The inclusion of both quantitative and qualitative results (visual comparisons of reconstructed images) is highly probable, showcasing AID’s ability to reduce artifacts like aliasing. The discussion would highlight AID’s robustness and trustworthiness, particularly in handling challenging undersampling patterns, where other methods may fail. Overall, this section should provide a detailed explanation of the reconstruction technique, a robust quantitative evaluation of its performance, and compelling visual demonstrations of improved image quality.
Image Sequence Gen.#
The heading ‘Image Sequence Gen.’ suggests a focus on generating sequences of images, likely using a deep learning model. This could involve methods like autoregressive models which predict subsequent images based on preceding ones, maintaining coherence. Alternatively, diffusion models could be adapted; these typically generate a single image, but could be extended to create a sequence through iterative refinement or by modeling the temporal dependencies between frames. The core challenge lies in balancing temporal consistency and image quality. Successful generation would demonstrate the model’s ability to capture complex relationships and patterns within a sequence, potentially having applications in areas like video prediction, animation, or medical imaging where sequential data is crucial.
Future Work & Limits#
The authors acknowledge limitations, primarily the model’s evaluation solely on medical datasets and the absence of broader image dataset comparisons using metrics like FID and Inception Score. Future work should address these gaps by testing on standard benchmarks and incorporating more sophisticated evaluation metrics to assess the generated image quality comprehensively. Further investigation into the model’s scalability for higher-resolution images and the optimization of the k-space acquisition process using the model’s inherent sequential capabilities are also crucial. Finally, thorough exploration of privacy concerns related to generating realistic medical image sequences is needed, including investigation of anonymization techniques and strategies for responsible data handling to ensure ethical and safe deployment. Addressing these limitations and exploring these avenues of research will significantly enhance the model’s applicability and impact.
More visual insights#
More on figures

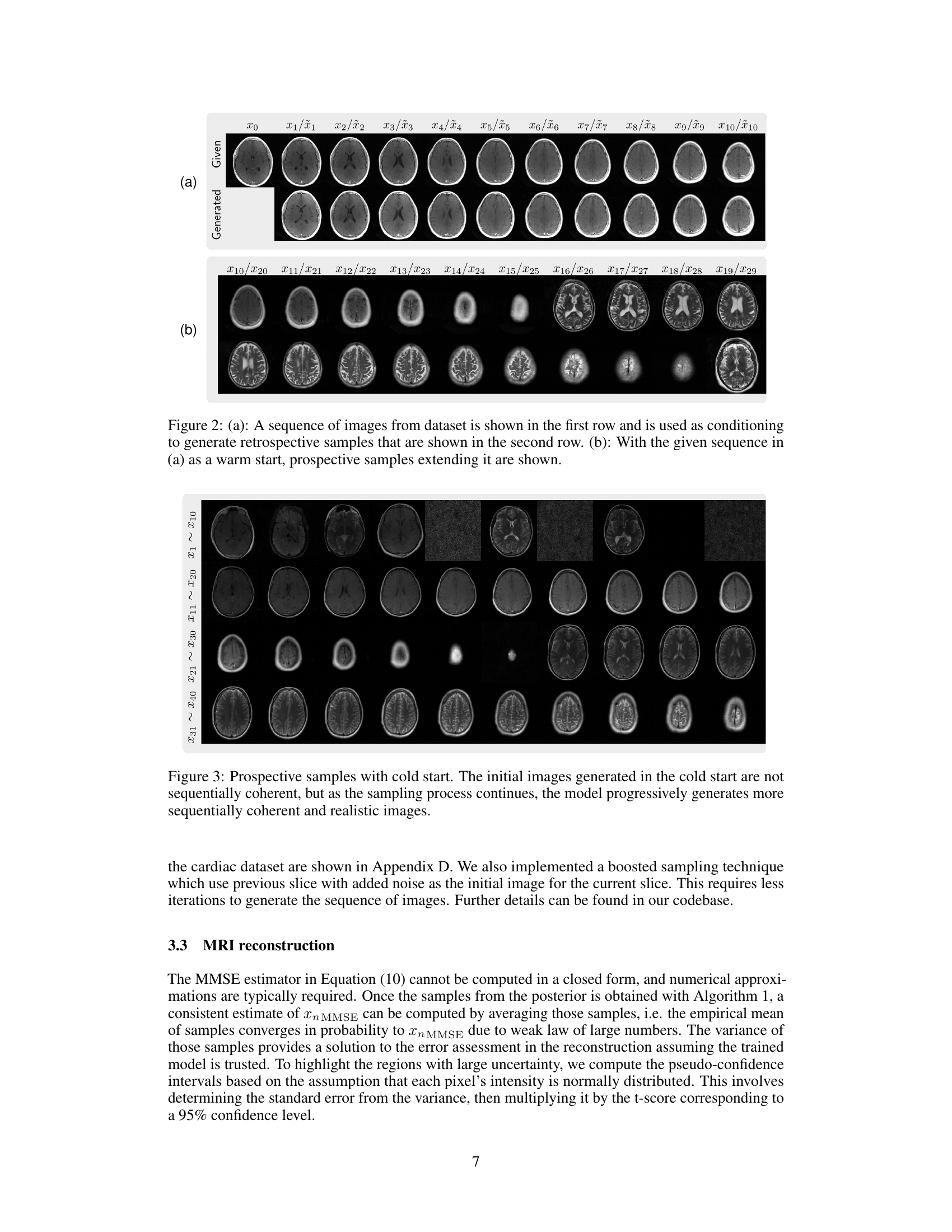
This figure shows the results of two different sampling methods used to generate image sequences: retrospective sampling and prospective sampling. Retrospective sampling starts with a given sequence of images and generates a new sequence based on this initial sequence. Prospective sampling uses a sliding window that updates with each generated image; the earliest image is removed as a new one is added. The top row in each part shows the initial sequence used for generation (a) or the starting window (b). The bottom row shows the generated sequences. The images demonstrate the model’s ability to generate both coherent and consistent image sequences using both methods.

This figure shows the results of two different sampling methods used to generate image sequences. In (a), retrospective sampling is used, which generates a new sequence based on a given sequence. The first row shows the initial sequence, and the second row displays the generated sequence. In (b), prospective sampling is used, which generates a sequence by iteratively updating a sliding window of images. The initial sequence is shown, and the generated sequence is displayed extending this initial sequence. This demonstrates the model’s ability to generate coherent image sequences using both methods, highlighting the differences between the two sampling approaches.

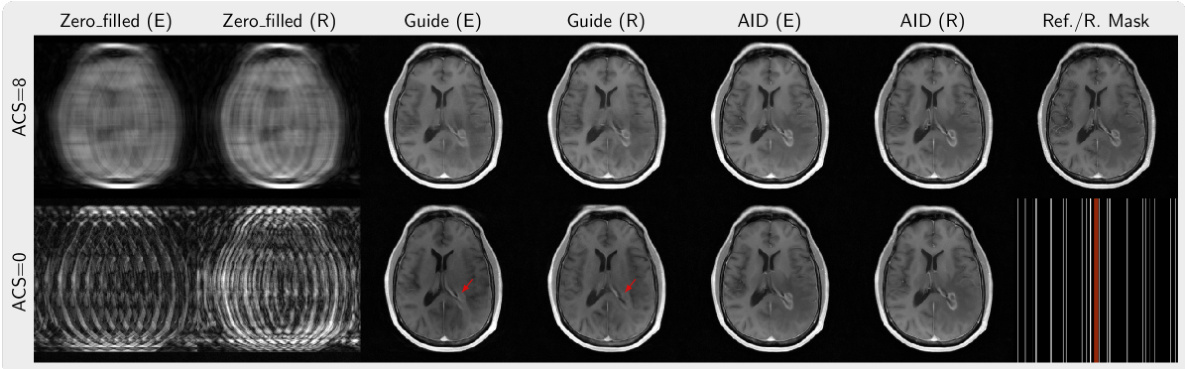
This figure shows the results of an experiment designed to compare the performance of the autoregressive image diffusion (AID) model and a standard diffusion model (Guide) in reconstructing a single-coil image from undersampled k-space data. Panel (a) displays the folded single-coil image resulting from two-times undersampling. Panel (b) presents a comparison of the reconstruction results. The top row shows the results for the AID model, and the bottom row shows the results for the Guide model. The ‘Error’ column shows the difference between the reconstructed image and the reference image (reconstructed from fully sampled k-space data). The ‘Mean+Std’ column displays the mean of the reconstructed images with the confidence interval based on the standard deviation, indicating the uncertainty in the reconstruction. The ‘Mean’ column shows the average of the reconstructed images, and the ‘Reference’ column shows the reference image. The comparison demonstrates that the AID model significantly reduces the errors in the folding artifact regions compared to the Guide model, leading to a more trustworthy reconstruction.

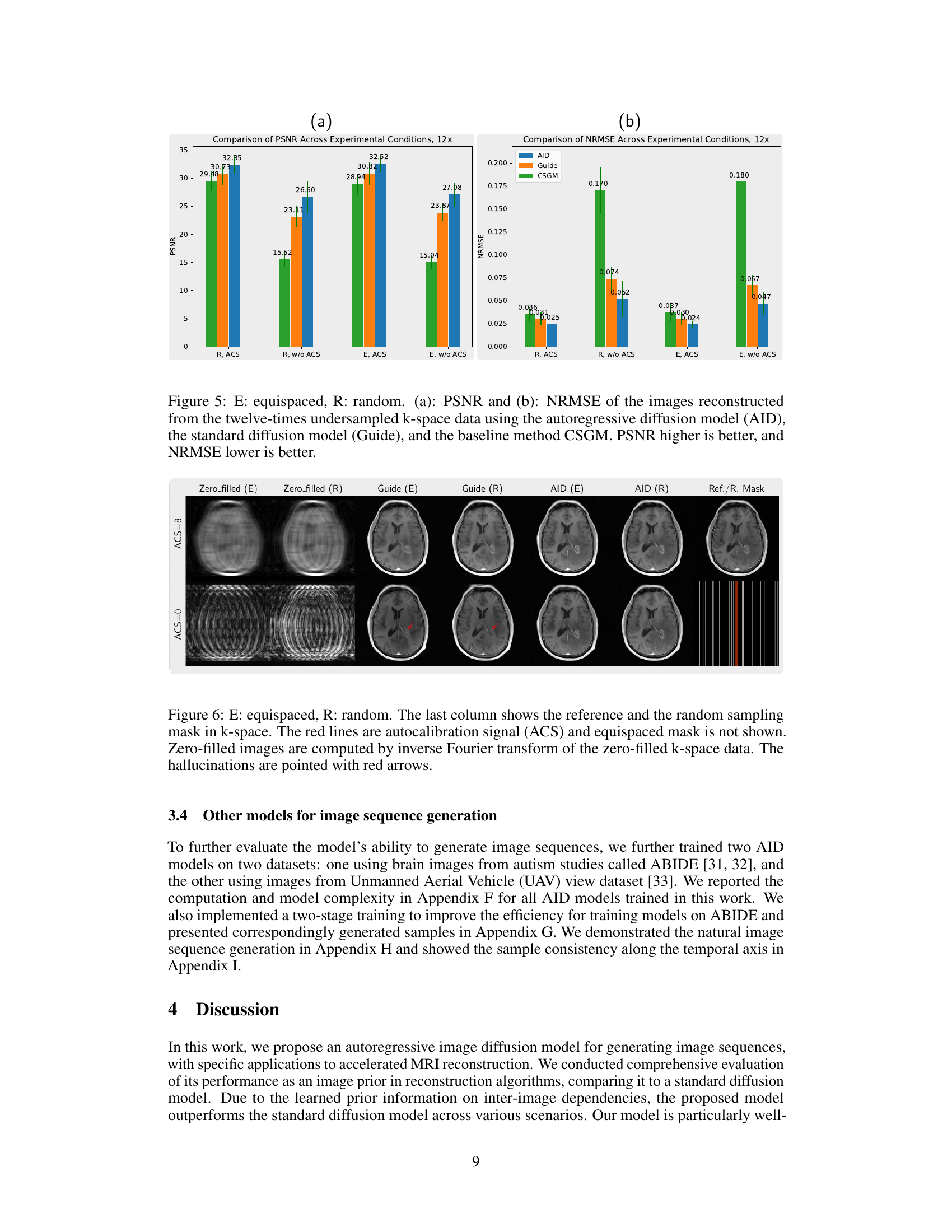
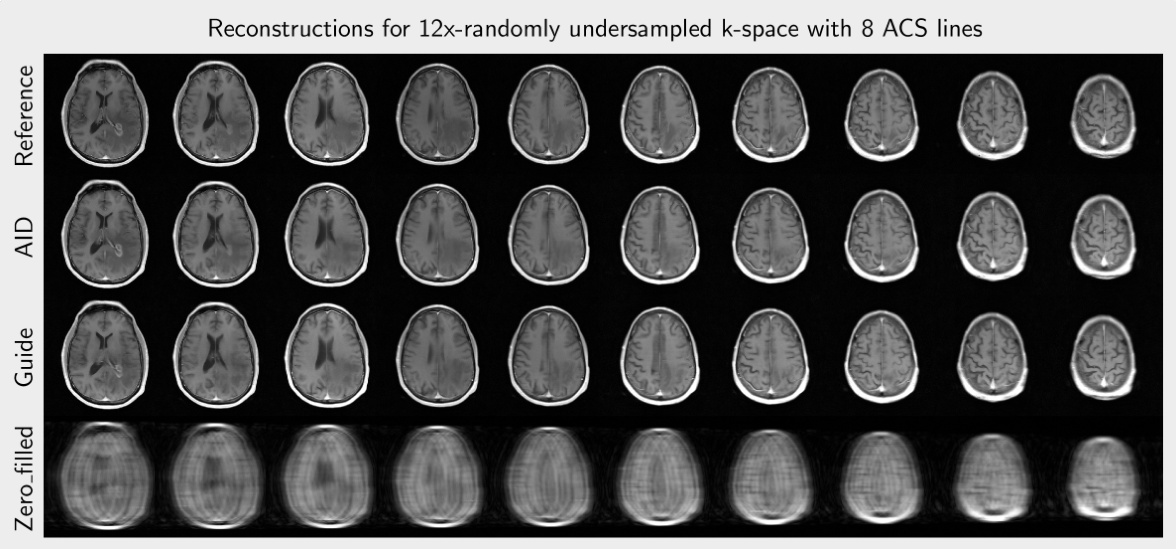
This figure compares the performance of three different models (AID, Guide, and CSGM) in reconstructing images from twelve times undersampled k-space data. Two types of sampling masks were used: equispaced and random, each with and without autocalibration signals (ACS). The results are presented in terms of Peak Signal-to-Noise Ratio (PSNR) and Normalized Root Mean Square Error (NRMSE). Higher PSNR values indicate better reconstruction quality, while lower NRMSE values indicate less error.
This figure compares the performance of three different models (AID, Guide, and CSGM) in reconstructing images from twelve-times undersampled k-space data. Two types of sampling masks were used: equispaced and random, each with and without autocalibration signals (ACS). The results are presented in terms of peak signal-to-noise ratio (PSNR) and normalized root-mean-square error (NRMSE). Higher PSNR values and lower NRMSE values indicate better reconstruction quality. The figure shows that the AID model generally outperforms the other two models across different sampling strategies.
This figure illustrates the architecture of the autoregressive image diffusion (AID) model. The AID model processes a sequence of images. It uses an encoder-decoder structure with a transformer-based block (DiTBlock) that incorporates causal attention to model the dependencies between consecutive images in the sequence. During training, the network learns to predict the noise added to each image in the sequence based on the preceding images. During generation, it uses this learned relationship to iteratively refine a noisy image to produce a clean image, adding each new clean image to the input sequence before processing the next one. This allows generation of coherent image sequences.

This figure illustrates how the signal detected by each coil in an MRI scanner is weighted by its sensitivity profile (spatial sensitivity pattern). The sensitivity profile describes how strongly the coil picks up signals from different locations within the imaged object. This results in variations in signal intensity across the coil images (shown as dark and bright areas). The final, high-quality image (ground truth) is reconstructed by combining these coil images, effectively compensating for individual coil sensitivity differences.

This figure demonstrates two methods for generating image sequences using the autoregressive image diffusion model. (a) shows retrospective sampling, where a new sequence is generated based on a given sequence. The top row displays the given sequence (conditioning sequence), and the bottom row displays the generated sequence. (b) shows prospective sampling, where a sliding window is used, adding newly generated images and removing the oldest ones iteratively. The given sequence acts as an initial condition. The figure highlights the model’s ability to generate coherent and visually similar image sequences using both methods.

This figure shows the results of retrospective sampling from the autoregressive image diffusion (AID) model trained on a cardiac dataset. Retrospective sampling involves using a pre-existing sequence of images to generate a new sequence of images by iteratively refining a noisy image input. The figure displays multiple volumes (sequences) of retrospective images, demonstrating the model’s ability to generate sequentially coherent and realistic images based on the provided conditioning sequences.

This figure shows the quantitative comparison of image reconstruction performance between the proposed autoregressive image diffusion (AID) model and two other methods: a standard diffusion model (Guide) and a score-based generative model (CSGM). The comparison is based on two metrics, Peak Signal-to-Noise Ratio (PSNR) and Normalized Root Mean Square Error (NRMSE), and is performed on data with different sampling patterns (equispaced and random). Higher PSNR and lower NRMSE values indicate better reconstruction quality. The results clearly demonstrate that the AID model outperforms the other two methods across various sampling conditions.
This figure compares the image reconstruction results of different methods (AID, Guide, Zero-filled) from 12 times undersampled k-space data with and without ACS lines using equispaced and random sampling masks. The last column provides the reference image reconstructed from fully sampled data and the corresponding sampling mask used. Red arrows highlight artifacts present in some of the reconstructions.

This figure illustrates the architecture of the Autoregressive Image Diffusion (AID) model. The diagram shows how the model processes a sequence of images. It highlights the key components: the DiTBlock (with causal attention to ensure that each image is conditioned on previous images in the sequence), encoder and decoder blocks, and MLPs. The process of noise prediction during training and iterative refinement during generation is visually represented. The figure also displays the tensor shapes at various stages of the process.

This figure shows a sequence of images generated using the autoregressive image diffusion model trained on a UAV dataset. The sequence demonstrates the model’s ability to generate temporally coherent images by capturing subtle changes in the water surface’s lighting over time. Each frame in the sequence depicts an aerial view of a rural landscape, providing a visual representation of how the model learns and reproduces sequential patterns.

This figure demonstrates the temporal consistency of the image sequences generated by the AID model trained on different datasets. The first two columns showcase sagittal and coronal views of a brain image sequence, highlighting the changes in brain structure. The next column displays the x-t plane of a cardiac image sequence, illustrating the heart’s activity over time. The final two columns show both a generated and a real x-t plane of a UAV image sequence, representing the changes in an aerial landscape over time. The generated sequence is largely consistent with the real one but shows some artifacts.
Full paper#