↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current LLM-based agents struggle with complex reasoning, lack adaptability, and are difficult to align with human intent. Existing methods often rely on outcome feedback, which is insufficient to improve intermediate steps. They also suffer from uncontrollable reasoning logic or static model capabilities.
The paper presents AMOR, a novel framework addressing these limitations. AMOR leverages open-source LLMs and uses a finite state machine (FSM) for structured reasoning and process feedback. The FSM allows for human supervision at each module, while the process feedback enables effective adaptation to new domains. Extensive experiments show significant performance gains compared to baselines, highlighting the advantages of this approach.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large language models (LLMs) and aiming to build more adaptable and human-aligned AI agents. It introduces a novel framework, AMOR, that tackles the limitations of existing methods by using a finite state machine for reasoning and process feedback for adaptation. This significantly improves performance, offers greater explainability and human control, and opens avenues for future research in LLM-based agent development.
Visual Insights#

This figure illustrates the finite state machine (FSM) based reasoning logic of AMOR. Each box represents a state in the FSM, and each arrow represents a transition between states based on the output of the module executed in the current state. Special tokens, like [NEXT] indicate whether additional steps are needed or if the task is complete. The diagram shows how AMOR proceeds through a series of steps to answer a question, using different modules for tasks such as question decomposition, document retrieval, relevance judgment, passage retrieval, and answer extraction. This FSM structure allows for process-based feedback, enabling human supervision and adaptability.
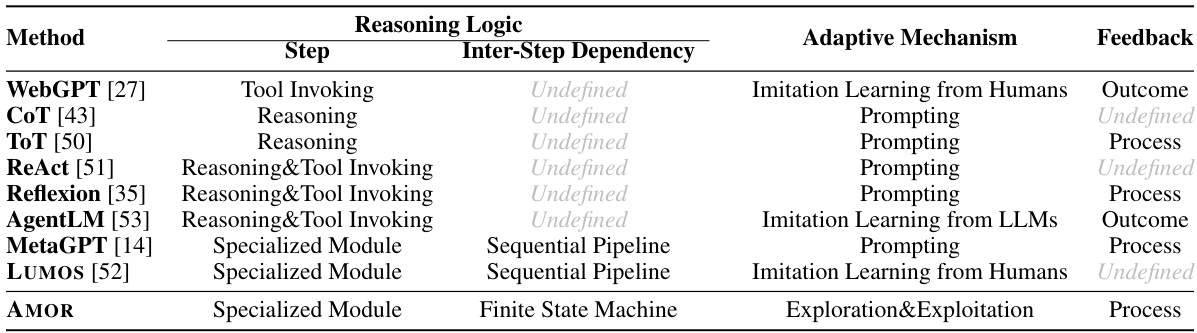
This table compares AMOR with other methods for building language agents, focusing on their reasoning logic, adaptive mechanisms, and feedback mechanisms. It highlights the differences in reasoning approaches (e.g., tool invoking vs. FSM-based reasoning), how agents adapt to new environments (e.g., imitation learning vs. exploration/exploitation), and what type of feedback is used (e.g., outcome vs. process feedback). Appendix A.1 provides a more detailed analysis of these differences.
In-depth insights#
Modular Agent Design#
Modular agent design offers a powerful approach to building complex AI systems by decomposing them into smaller, more manageable modules. This approach offers several key advantages: improved maintainability and scalability, as changes to one module are less likely to affect others; enhanced flexibility and adaptability, allowing for easier integration of new functionalities and adaptation to changing environments; and increased robustness and fault tolerance, as failures in one module are less likely to cause a system-wide crash. However, effective modular design requires careful consideration of several factors including well-defined interfaces between modules to ensure seamless communication, clear module responsibilities to avoid overlap or conflicts, and appropriate mechanisms for managing inter-module dependencies to prevent cascading failures. The optimal level of modularity is also a critical design consideration as overly fine-grained modules can lead to excessive complexity and overhead while overly coarse-grained modules can limit flexibility and reusability. Ultimately, a successful modular agent design balances the benefits of decomposition with the challenges of integration and coordination to achieve the desired level of system performance and maintainability.
Process Feedback#
The concept of ‘Process Feedback’ in the context of adaptable modular knowledge agents is crucial for effective human-in-the-loop learning. It allows for real-time adjustments and refinements to the agent’s reasoning process, rather than simply correcting final outputs. By providing feedback at individual steps (modules) of an FSM, humans can guide the agent towards more robust and accurate reasoning. This targeted intervention is significantly more effective than providing feedback only on the final outcome, as it addresses errors at their source. Process feedback is particularly valuable in complex multi-step tasks, where errors can accumulate across different stages. The granular nature of the feedback allows for systematic debugging and enhancement of specific reasoning modules. This leads to a more efficient and ultimately effective learning process. The ability to incorporate and respond to process feedback is key to building truly adaptable and aligned AI agents that meet the expectations and intentions of their human supervisors. Without it, agents are prone to errors and biases that may be difficult to correct retroactively. By addressing intermediate steps, process feedback significantly improves the agent’s learning efficiency and accuracy.
LLM Fine-tuning#
LLM fine-tuning in research papers often focuses on adapting large language models (LLMs) to specific tasks or domains. This is achieved through various techniques, such as transfer learning, where a pre-trained LLM is further trained on a new dataset relevant to the target application. Another common approach is parameter-efficient fine-tuning (PEFT) methods, which aim to reduce the computational cost and memory requirements of fine-tuning by only updating a small subset of the LLM’s parameters. Instruction fine-tuning is a prevalent technique that involves training the LLM on a dataset of instructions and their corresponding desired outputs, enabling the model to better understand and respond to various instructions and prompts. Researchers often explore different fine-tuning objectives, such as next-token prediction, sequence classification, or reinforcement learning, depending on the specific downstream task. Evaluation metrics for assessing the performance of fine-tuned LLMs often include perplexity, accuracy, precision, recall, and F1-score, among others. Furthermore, data quality and size significantly impact the success of LLM fine-tuning; high-quality, representative datasets are essential to ensure that the model generalizes well to unseen data. The choice of hyperparameters such as learning rate and batch size also plays a crucial role in fine-tuning performance.
Adaptation Methods#
In the realm of artificial intelligence, particularly within the context of language models, adaptation methods are crucial for enhancing the performance and robustness of these systems. Effective adaptation strategies must address the need to improve model generalization, enabling them to effectively handle unseen data and diverse scenarios. This often involves techniques such as transfer learning, leveraging knowledge from pre-trained models on related tasks or domains. Fine-tuning, another common method, involves adjusting model parameters using a smaller, task-specific dataset, allowing for targeted improvements. Reinforcement learning is particularly useful for complex, sequential tasks, where agents can learn optimal strategies through interactions with an environment. However, each of these approaches has specific challenges. Transfer learning can be limited by the relevance of the source task, fine-tuning may overfit to specific data, and reinforcement learning often requires substantial computational resources and careful design. Therefore, selecting the optimal method depends on the specific application, available resources, and desired level of performance. Furthermore, hybrid approaches, combining multiple methods, often offer significant advantages, enhancing the flexibility and robustness of the adapted model.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Extending AMOR’s capabilities to diverse knowledge modalities beyond text corpora, such as incorporating structured knowledge graphs or multimedia data, would significantly broaden its applicability and problem-solving power. Developing methods for automated FSM design would reduce reliance on manual construction, making AMOR more scalable and accessible. This could involve leveraging LLMs to generate FSMs based on task descriptions or learning from existing interaction data. Improving the robustness of AMOR’s reasoning process in handling noisy or ambiguous information is crucial for real-world deployment, focusing on enhanced error detection and correction. Exploring the implications of process feedback for model alignment and trustworthiness is essential, particularly when involving human-in-the-loop interactions. Furthermore, research should investigate the effectiveness of AMOR in handling increasingly complex, multi-step tasks and in adapting to rapidly evolving environments. Comparative studies with other state-of-the-art language agents on more diverse benchmarks would further validate AMOR’s capabilities and highlight its unique strengths and limitations.
More visual insights#
More on figures

This figure is a state transition diagram illustrating the workflow of AMOR. Each box represents a state in the finite state machine, and each arrow represents a transition to the next state based on the results of a specific module’s operation. The modules themselves represent different processes, like question decomposition, document retrieval, or answer extraction. Branch tokens, such as [NEXT], indicate different execution results and guide the transition between states. Essentially, it visualizes how AMOR moves through the process of answering a complex question by breaking it down into simpler modules and making decisions based on each module’s output.

This figure shows a state transition diagram illustrating the workflow of the AMOR model. Each box represents a state in the finite state machine (FSM), and each arrow indicates a transition between states based on the output of a specific module. The modules represent different steps in the reasoning process, such as question decomposition, document retrieval, and answer extraction. The branch tokens, like [NEXT], control the transitions based on the results of each module. This allows for a flexible and adaptive reasoning process controlled by the FSM.

This figure shows the workflow of AMOR, which is based on a finite state machine. Each state represents a step in the reasoning process, and each module represents a specific task or operation. The transitions between states are determined by the output of the modules, which are indicated by branch tokens. For example, the [NEXT] token indicates that more information is needed, and the [FINISH] token indicates that the task is complete. This design allows for human supervision by providing feedback to individual modules.

This figure shows the workflow of AMOR, which is based on a finite state machine (FSM). Each state represents a step in the reasoning process, and each module corresponds to a specific task (e.g., document retrieval, relevance judgment, answer extraction). The transitions between states are determined by the output of the modules, which may include special tokens indicating the next step in the process. The figure visually depicts how AMOR progresses through the different stages of question answering, making its reasoning logic clear and understandable.

This figure shows the workflow of AMOR, which is based on a finite state machine (FSM). Each state represents a specific task or module, and the transitions between states depend on the outputs of the modules. The modules can be either tools or LLMs. The special branch tokens, such as [NEXT] and [FINISH], determine the next state in the FSM.

This figure shows the workflow of AMOR using a finite state machine (FSM). Each state represents a specific step in the reasoning process and each transition is triggered by the result of the corresponding module. There are six main states: Question Decomposition, Document Retrieval, Relevance Judgement, Passage Retrieval, Answer Extraction, and Task Completion. The figure illustrates how the agent moves between states based on the outputs of various modules, which include LLMs and external tools. The use of branch tokens ([NEXT], [FINISH], [RELEVANT], [IRRELEVANT], [ANSWERABLE], [UNANSWERABLE]) facilitates the transition to the next relevant state in the FSM and directs the execution of the appropriate module.
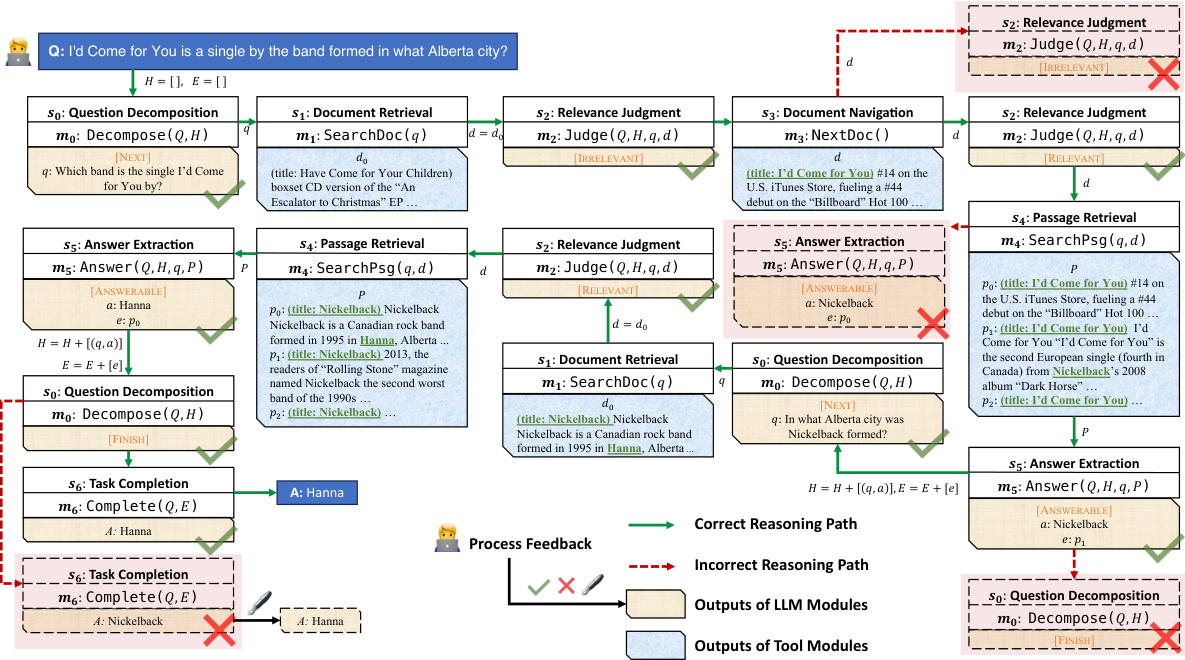
This figure illustrates the workflow of AMOR, showing how it uses a finite-state machine (FSM) to solve problems. Each state represents a step in the problem-solving process, and each transition represents a module execution. Different modules can be involved depending on the current state and the outcome of previous modules. Branch tokens, such as [NEXT], help control the flow.

This figure shows the state transition diagram of the AMOR agent framework. Each box represents a state in the finite state machine (FSM), and each state has a corresponding module that is executed. The modules may produce various outputs, categorized by special branch tokens (e.g., [NEXT], [FINISH], etc.). Based on these tokens, the system transitions to the next state. The overall process details the flow of actions in solving a question by decomposing it into sub-queries, retrieving documents and passages, judging relevance, extracting answers, and finally completing the task.

This figure is a state transition diagram showing how AMOR works. Each box represents a state in the process, and each arrow represents a transition between states based on the output of a module. The modules are responsible for different tasks, such as document retrieval, relevance judgment, and answer extraction. The branch tokens indicate the type of output produced by a module, and this determines which state the agent transitions to next. The diagram shows how AMOR uses these modules and transitions to solve a complex question-answering task through a series of steps.
More on tables

This table compares AMOR with several other methods for building language agents. It highlights key differences in reasoning logic (how the agent makes decisions), inter-step dependency (how steps in the reasoning process relate to each other), adaptive mechanism (how the agent adjusts to new situations), and feedback mechanism (how humans can provide feedback to improve the agent). The table shows that AMOR uses a finite state machine for reasoning, allowing for more control and human intervention, while other methods use less structured approaches.

This table details the automatic annotation process used to generate silver process feedback for the different LLM modules within the AMOR framework. For each module (Decompose, Judge, Answer, Complete), it specifies the module’s output (y) and the corresponding silver feedback (f) generated based on whether the module’s output is correct or needs refinement. The feedback is determined by comparing the module’s output to the ground truth (gold standard). This automatic generation is essential for training the model without requiring manual human annotation for every single instance. The conditions for generating the ‘right’ and ‘wrong’ feedback are clearly explained for each module’s output.

This table describes how the target output and immediate reward are determined for each module in AMOR during adaptation based on outcome feedback. For Decompose, Judge, and Answer modules, the target output remains the same (ỹk = y) and the reward is 1 if the feedback matches the actual answer (fo = Â), otherwise 0. For the Complete module, the target output changes to the actual answer (ỹk = Â) and reward is 1 only if all the evidence passages are included, otherwise 0.
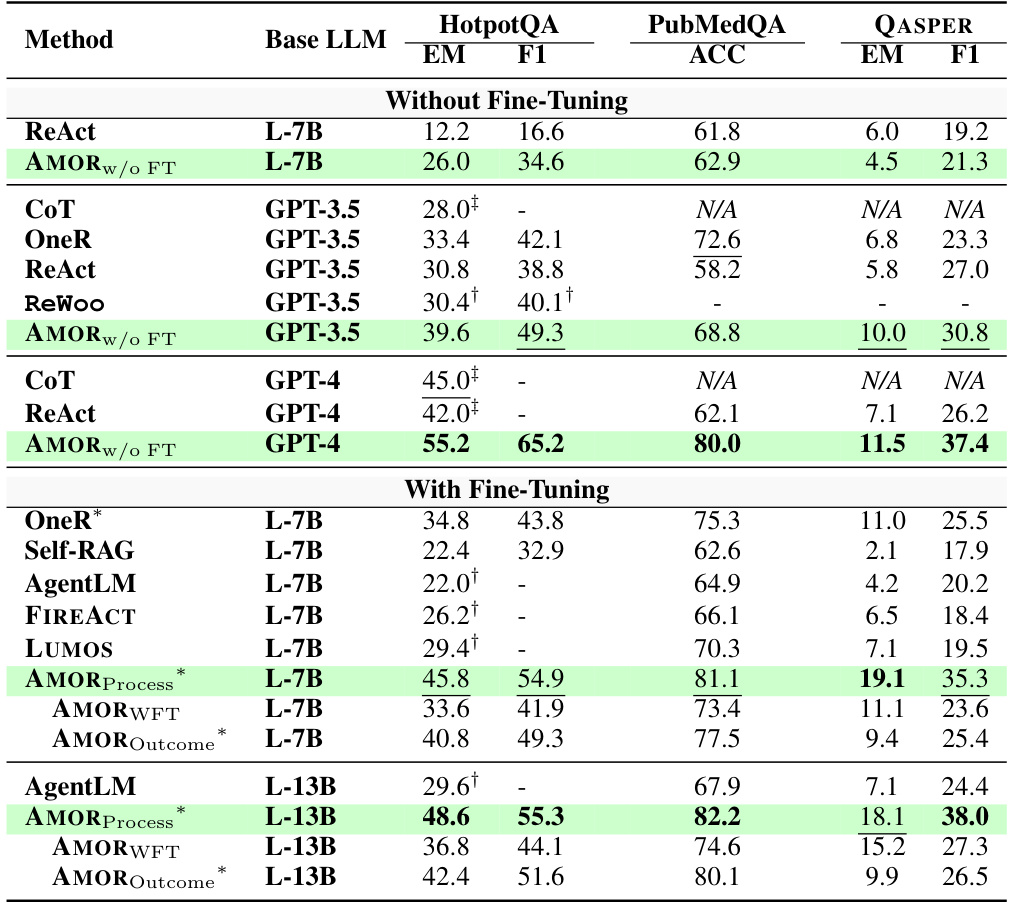
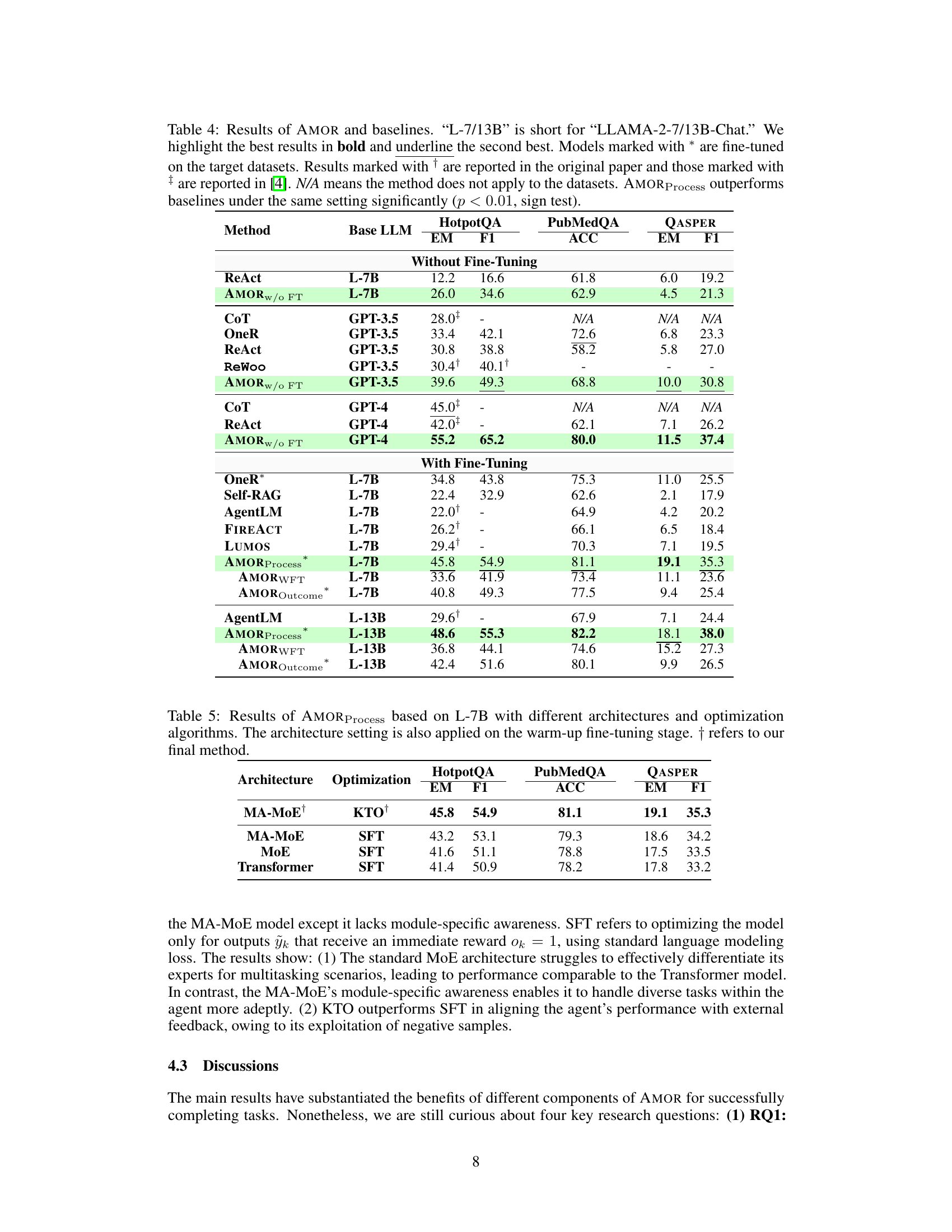
This table presents the experimental results of AMOR and several baselines on three datasets: HotpotQA, PubMedQA, and QASPER. It shows the performance (EM, F1, and ACC) of each method with and without fine-tuning, using different LLMs (L-7B, GPT-3.5, GPT-4, and L-13B). The table highlights the significant improvement achieved by AMORProcess, particularly its advantage over other methods when fine-tuned on the target datasets. Statistical significance (p<0.01) is noted for the superior performance of AMORProcess.
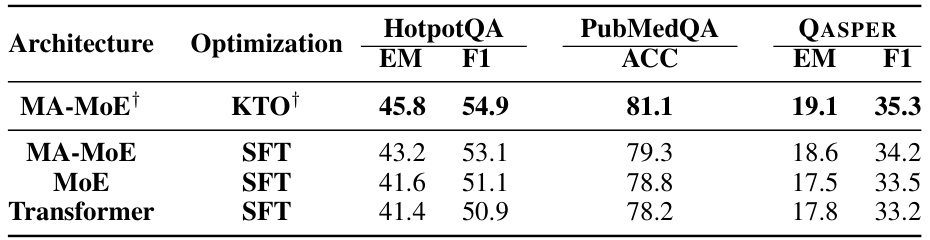
This table presents the results of the AMORProcess model, using the LLAMA-2-7B-Chat language model as a base. The table compares the performance of four different model architectures (MA-MoE, MA-MoE with Supervised Fine-Tuning, MoE with Supervised Fine-Tuning, and a standard Transformer model with Supervised Fine-Tuning). It shows the performance on three question answering datasets (HotpotQA, PubMedQA, and QASPER) in terms of Exact Match (EM) and F1 scores, and accuracy (ACC) for PubMedQA. The table highlights the impact of different architectures and optimization techniques on the overall model performance.
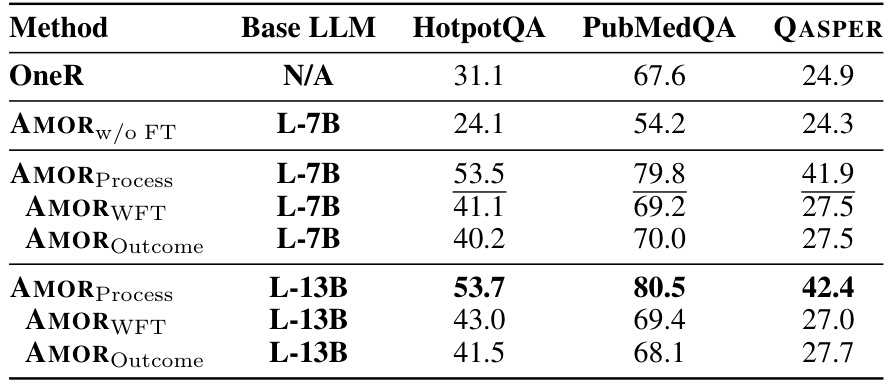
This table presents the performance comparison of AMOR and various baseline methods across three question-answering datasets: HotpotQA, PubMedQA, and QASPER. It shows the performance of different models with and without fine-tuning and highlights the impact of different adaptation strategies (process feedback vs outcome feedback). The results demonstrate the superiority of AMORProcess across all scenarios.

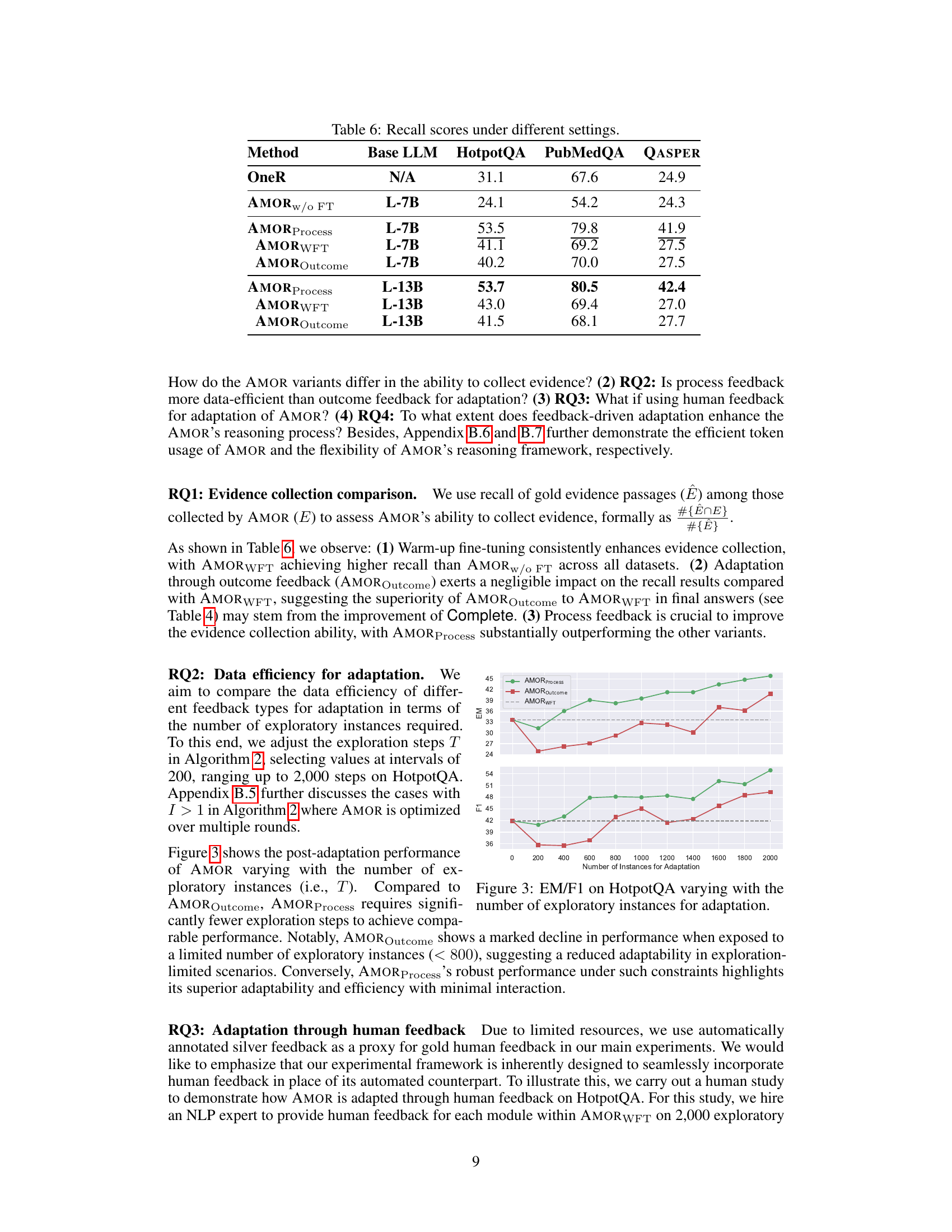
This table shows the results of adapting the AMOR model using human feedback on the HotpotQA dataset. It compares the performance of AMOR using automatic feedback versus human feedback, measured by Exact Match (EM) and F1 scores. The results highlight the impact of human feedback on the model’s performance.

This table presents the accuracy of each of the four LLM modules (Decompose, Judge, Answer, Complete) within three different versions of the AMOR model: AMORProcess, AMORWFT, and AMOROutcome. All models are based on the L-7B language model. The table allows for a comparison of the performance of each module under different training and adaptation conditions, highlighting the impact of process-based feedback on model accuracy.

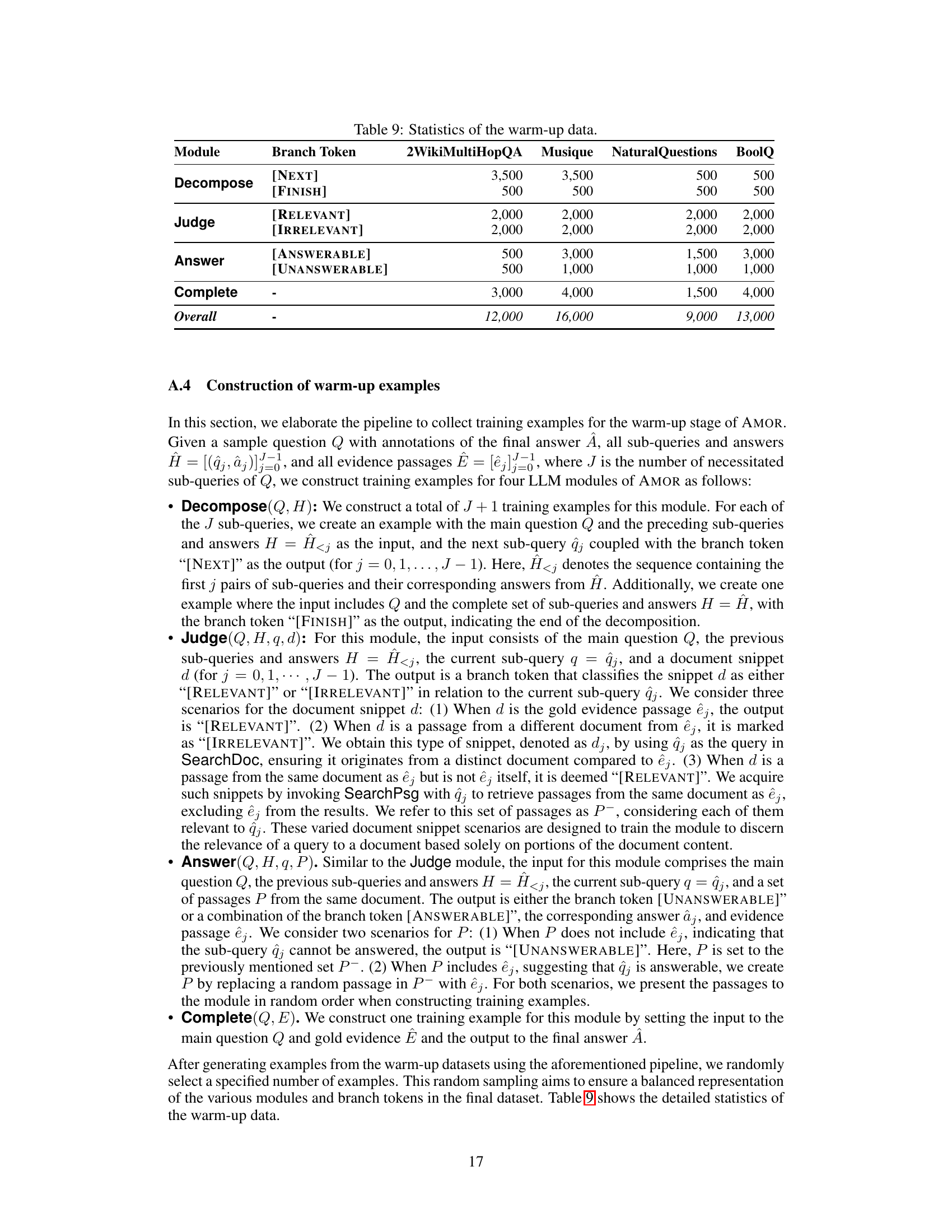
This table shows the number of training examples created for each module and each branch token in the warm-up stage. The data is categorized by four datasets (2WikiMultiHopQA, Musique, NaturalQuestions, BoolQ) and by module (Decompose, Judge, Answer, Complete). Each module has specific branch tokens indicating the outcome of the module’s execution, affecting the next stage in the process. The overall row sums up the total number of training examples generated for each dataset.

This table compares AMOR with several other methods for building language agents, focusing on their reasoning logic, inter-step dependency, adaptive mechanism, and feedback mechanism. It highlights the differences in how these agents approach problem-solving, adapt to new situations, and incorporate human feedback. The table shows that AMOR stands out with its specialized modules, finite state machine reasoning, and process-based feedback.
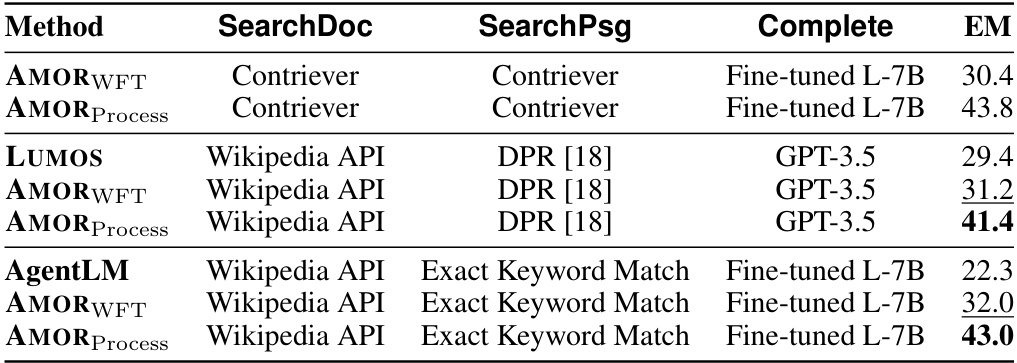
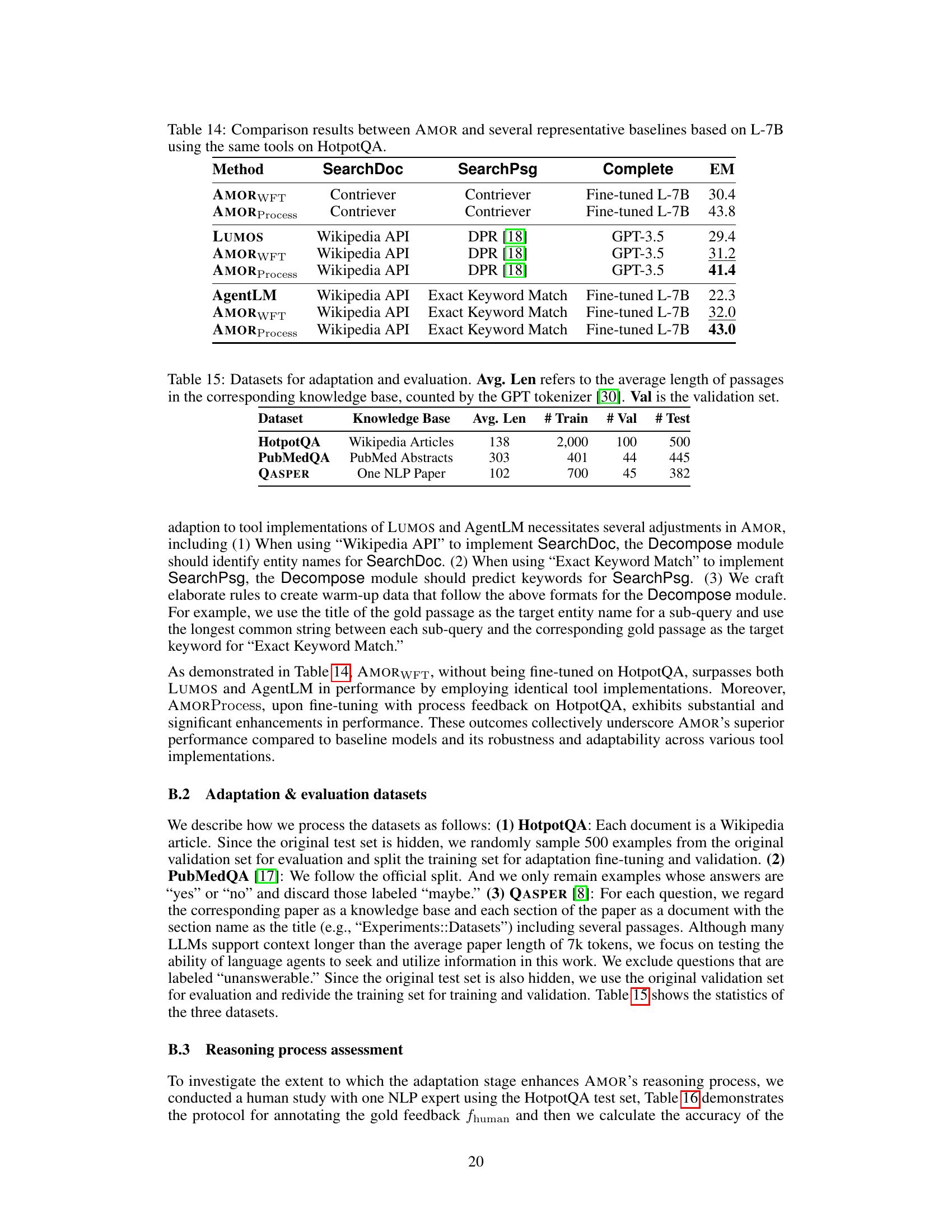
This table compares the performance of AMOR and several other methods (LUMOS and AgentLM) on the HotpotQA dataset. All models use the L-7B language model. The key difference is in the retrieval methods used for SearchDoc and SearchPsg, as well as the final Complete module. AMOR uses Contriever for both retrieval tasks, while LUMOS uses the Wikipedia API and DPR, and AgentLM uses the Wikipedia API with Exact Keyword Matching. The table shows that AMORProcess, with its process feedback mechanism, significantly outperforms the other methods in terms of Exact Match (EM) accuracy.

This table presents the details of three datasets used for adapting and evaluating the AMOR model. For each dataset, it shows the knowledge base used (e.g., Wikipedia articles, PubMed abstracts), the average length of passages in tokens, and the number of training, validation, and test instances.

This table presents the automatic annotation strategy employed to generate silver process feedback for the different Large Language Model (LLM) modules within the AMOR framework. For each module (Decompose, Judge, Answer, Complete), it specifies the module’s output (y) and the corresponding silver process feedback (f) that is automatically generated. The silver feedback is designed to be a proxy for human feedback and is used in the adaptation phase of the AMOR training process. The feedback can be a binary judgment (‘right’, ‘wrong’) or a more refined classification (e.g., [RELEVANT], [IRRELEVANT]). This automatic generation of feedback allows for efficient adaptation of the AMOR agent to specific domains.

This table presents the accuracy of the automatically generated silver feedback for each of the four LLM modules in the AMOR framework. The accuracy is measured against gold-standard human feedback for each module: Decompose, Judge, Answer, and Complete. The high accuracy scores suggest that the automatically created silver feedback is a reliable proxy for human feedback.

This table compares the error rates of three different methods (LUMOS, AMOR without fine-tuning, and AMOR with process feedback) across six categories of errors. The error categories are related to the different steps of the question-answering pipeline, such as question decomposition, retrieval, relevance judgment, answer extraction, and task completion. The table highlights that the method AMORProcess significantly reduces error rates compared to the other two methods.

This table shows the performance of AMOR across three iterations of multi-round adaptation. Each iteration starts with a set of parameters (θi) and explores using either the same questions (same questions column) or different questions (different questions column) in each iteration. The performance metrics (EM and F1) are reported for each round of adaptation (θ1, θ2, θ3). The results show that performance does not change significantly with same or different questions across rounds.

This table compares the average number of steps and tokens used by different language agents (ReAct, AgentLM, AMOR) across three question answering datasets (HotpotQA, PubMedQA, QASPER). The metrics are broken down by agent and dataset, showing the efficiency of each agent in terms of both computation steps and token usage. Note that the definition of ‘step’ differs between the agents; for ReAct and AgentLM, a step represents a unit of thought, action, or observation, while for AMOR, a step corresponds to a reasoning step within a specific module.

This table presents the results of three different versions of the AMOR model on the HotpotQA dataset. The first row shows the performance of the original AMORProcess model. The second row shows the performance after targeted fine-tuning of the Complete module. The third row shows the performance after adding an additional tool called SearchDemo. The results demonstrate that both targeted fine-tuning and adding new tools can improve the performance of the AMOR model.
Full paper#