↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Federated learning (FL) suffers from the free-rider problem: participants gain benefits without substantial contributions. Existing solutions often assume honesty, which is unrealistic. Adversarial agents might provide false information to avoid contributing, undermining FL’s efficiency.
To address these issues, the authors propose FACT, a novel mechanism that not only eliminates free-riding through a penalty system but also ensures truthfulness by creating a competitive environment. Unlike previous methods, FACT guarantees individual rationality, ensuring agents benefit more from participating than training alone, even when acting selfishly or untruthfully. Empirical results on various datasets demonstrate FACT’s effectiveness in preventing free-riding and reducing agent loss by over 4x.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the significant problem of free-riding in federated learning, a prevalent issue hindering the effectiveness of collaborative machine learning. By introducing FACT, it directly addresses the challenge of untruthful agents, significantly advancing the field and opening new avenues for research in fairness, security, and efficiency of collaborative learning systems.
Visual Insights#
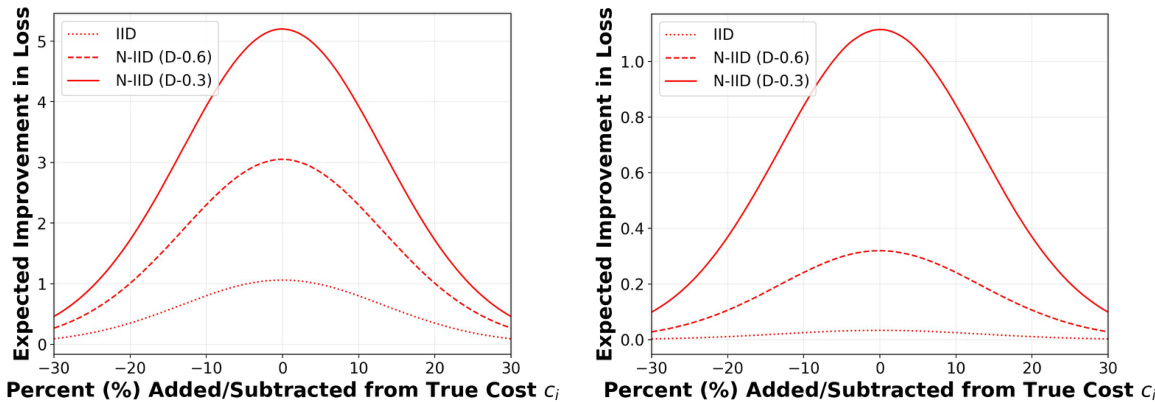
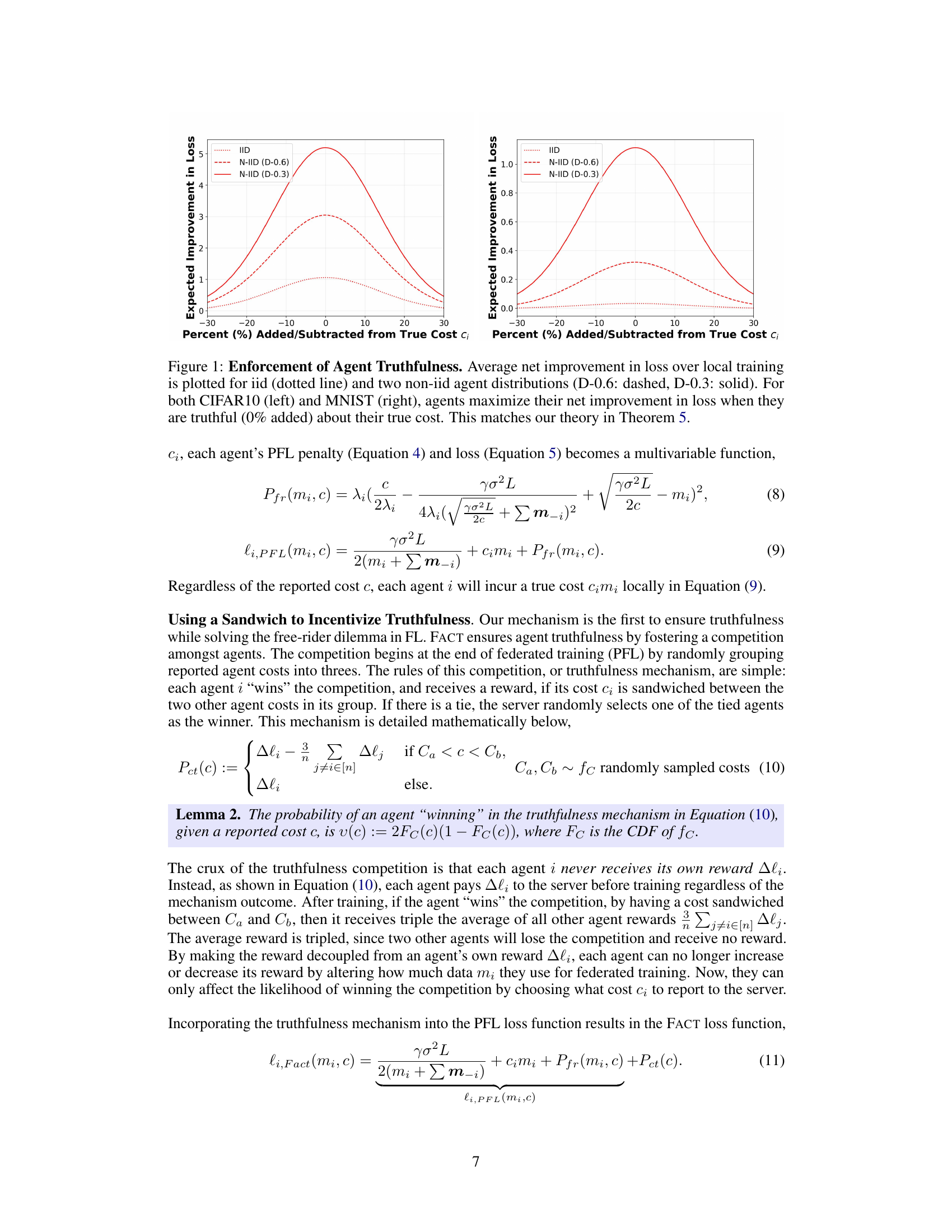
This figure shows the average improvement in loss (compared to local training) for different data distributions and when agents report their costs truthfully or with some percentage added or subtracted from the true cost. The results for CIFAR-10 and MNIST datasets are shown side-by-side. It demonstrates that the maximum improvement in loss occurs when agents report their costs truthfully, aligning with the theoretical findings of Theorem 5 in the paper.

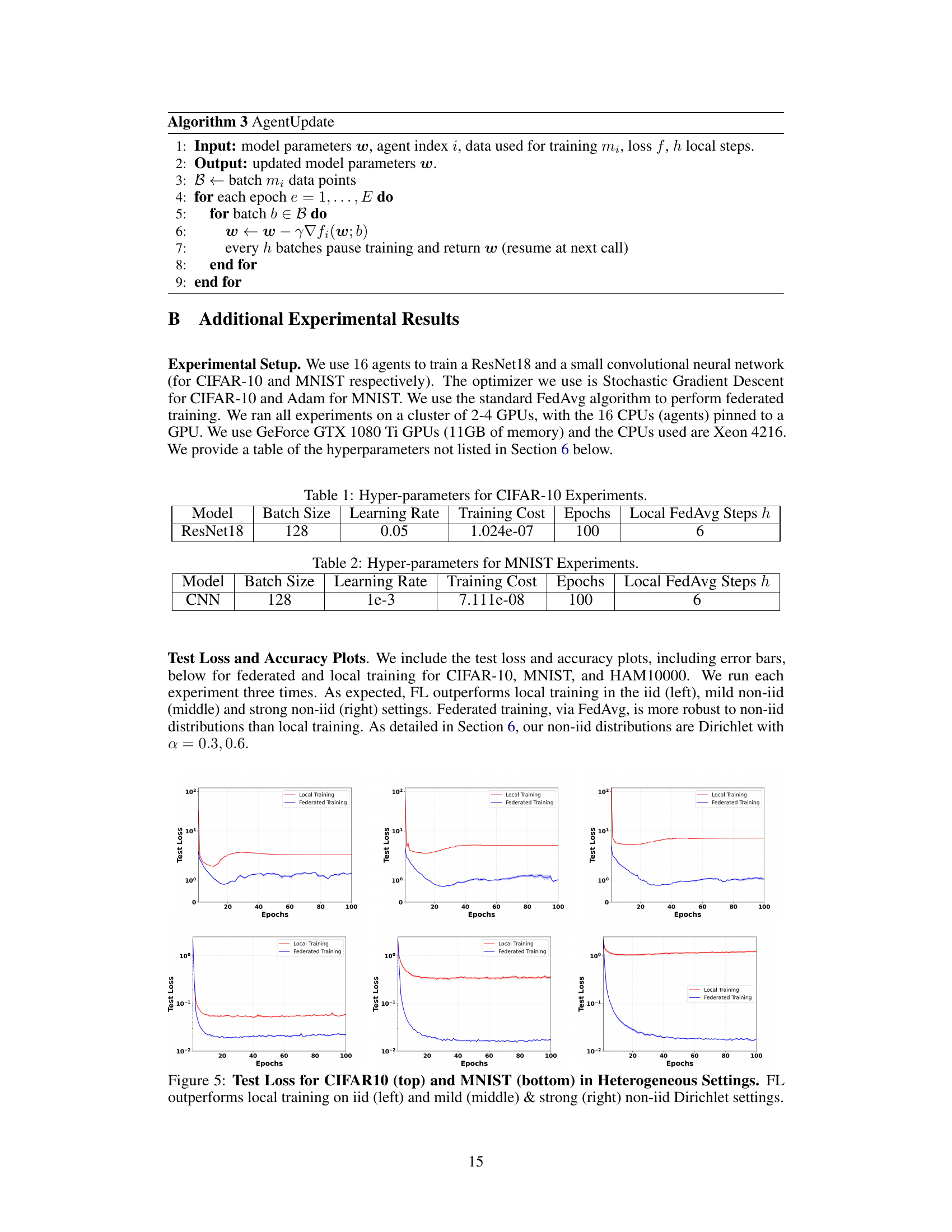
This table lists the hyperparameters used for the CIFAR-10 experiments. It shows the model used (ResNet18), batch size, learning rate, training cost, number of epochs, number of local FedAvg steps, and h (the number of local steps before the model is sent to the server). These parameters are important for understanding and reproducing the results of the CIFAR-10 experiments reported in the paper.
In-depth insights#
Truthful Federated Learning#
Truthful Federated Learning (FL) tackles a critical challenge in traditional FL: the prevalence of untruthful behavior by participating agents. Standard FL mechanisms often incentivize free-riding, where agents contribute minimally yet benefit from the aggregated model. This is problematic for system fairness. Truthful FL addresses this by designing mechanisms that incentivize honest participation. Incentive mechanisms, such as penalties for non-contribution or rewards for accurate data, encourage agents to provide their fair share of data and computation, while game-theoretic approaches model agent interactions and aim to find equilibrium states where truthfulness is a dominant strategy. A key focus is on verifying the truthfulness of reported information from agents. This may involve cryptographic techniques, statistical methods to detect anomalies, or the construction of competitive environments where agents are penalized for lying. The ultimate aim is to create a more robust and fair FL system by ensuring that agents have an incentive to contribute honestly, improving model accuracy and promoting equal distribution of benefits amongst participants.
Free-rider Problem#
The free-rider problem in federated learning is a significant challenge where participating agents can receive the benefits of a well-trained model without contributing sufficiently to the training process. This is a critical issue because it undermines the efficiency and fairness of collaborative learning. Incentivizing participation is essential to mitigate this; however, simply encouraging participation is not enough. Adversarial agents could provide false or low-quality data to reduce their workload, further hindering the system’s efficacy. This necessitates the need for truthful mechanisms that ensure agents provide valid data. Mechanisms designed to eliminate free-riding must be robust against both non-participation and untruthful contributions. The development of effective and robust mechanisms requires careful consideration of agent incentives, data quality, and the computational costs associated with participation. Ultimately, successful solutions need to strike a balance between rewarding honest contributions and penalizing free-riding behavior to maintain the integrity and performance of the federated learning system.
Penalty Mechanism#
A penalty mechanism is a crucial element in addressing the free-rider problem in federated learning. It incentivizes active participation by penalizing agents who contribute minimally to the global model training while still benefiting from the improved model. The design of an effective penalty mechanism requires careful consideration of several factors. Firstly, the penalty should be sufficiently harsh to deter free-riding but not so severe as to discourage participation entirely. This often involves finding a balance between the cost of data contribution and the benefit of improved model accuracy. Secondly, the penalty mechanism must be robust against manipulation. Adversarial agents might attempt to misrepresent their contributions or exploit vulnerabilities in the system to avoid penalties. Therefore, a well-designed system should incorporate mechanisms to detect and prevent such behavior. Finally, the penalty mechanism should be fair and transparent. It is important to ensure that penalties are applied consistently and equitably across all agents, avoiding biases and promoting trust in the system. An effective penalty mechanism is a cornerstone for creating a fair and collaborative federated learning environment. A poorly designed mechanism can disrupt the training process and lead to unreliable results. Therefore, a careful and thoughtful approach is crucial to success.
FACT Algorithm#
The FACT algorithm is presented as a novel approach to address the free-rider problem and ensure truthfulness in federated learning. It tackles the issue of untruthful agents by incorporating a penalty system and a competitive environment, incentivizing agents to provide accurate data. Unlike previous methods, FACT doesn’t rely on complex contracts or alterations to standard federated learning procedures, making it practical and widely applicable. The algorithm’s efficacy is demonstrated through empirical analysis, showcasing a significant reduction in agent loss, proving that it can effectively eliminate free-riding. The key novelty lies in FACT’s ability to work even with untruthful agents, a significant improvement over existing methods that assume honesty. The truthfulness aspect is achieved through a competition mechanism, ensuring that agents’ optimal strategy is to be honest about their costs. However, a limitation is the assumption of non-collusion among agents, which warrants further investigation. Future work could explore the performance of FACT under adversarial attacks or more sophisticated collusion strategies, and assess its scalability to larger federated learning systems.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Extending FACT to non-iid data distributions is crucial for broader applicability, as real-world federated learning scenarios rarely exhibit perfectly identical data across agents. Investigating the impact of agent heterogeneity beyond cost differences, considering varying computational capabilities or data quality, would enhance the model’s robustness. Analyzing FACT’s resilience against more sophisticated adversarial attacks, beyond simple cost misreporting, such as malicious gradient updates, is also important. Finally, developing mechanisms for dynamic agent joining and leaving would enhance the practicality of FACT in real-world deployments where agent participation is fluid.
More visual insights#
More on figures
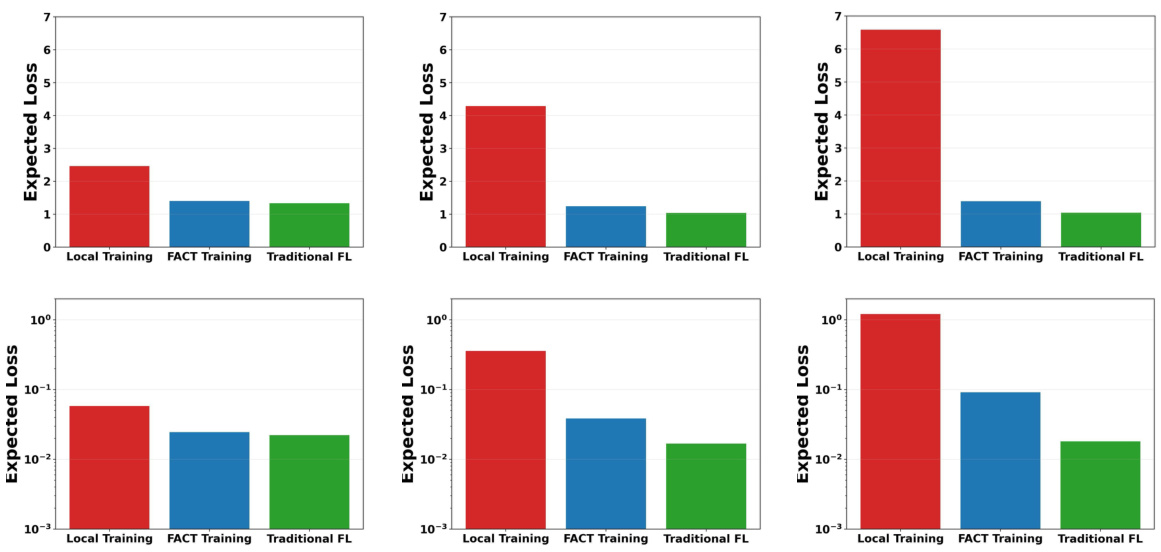
This figure compares the average agent loss for three different training methods: local training, FACT training, and traditional federated learning (FL). It shows the results for both CIFAR-10 and MNIST datasets, under iid (independent and identically distributed) and two non-iid (non-independent and identically distributed) data settings. The results demonstrate that FACT significantly reduces agent loss compared to local training, and achieves better performance than traditional FL, which is known to suffer from the free-rider problem.

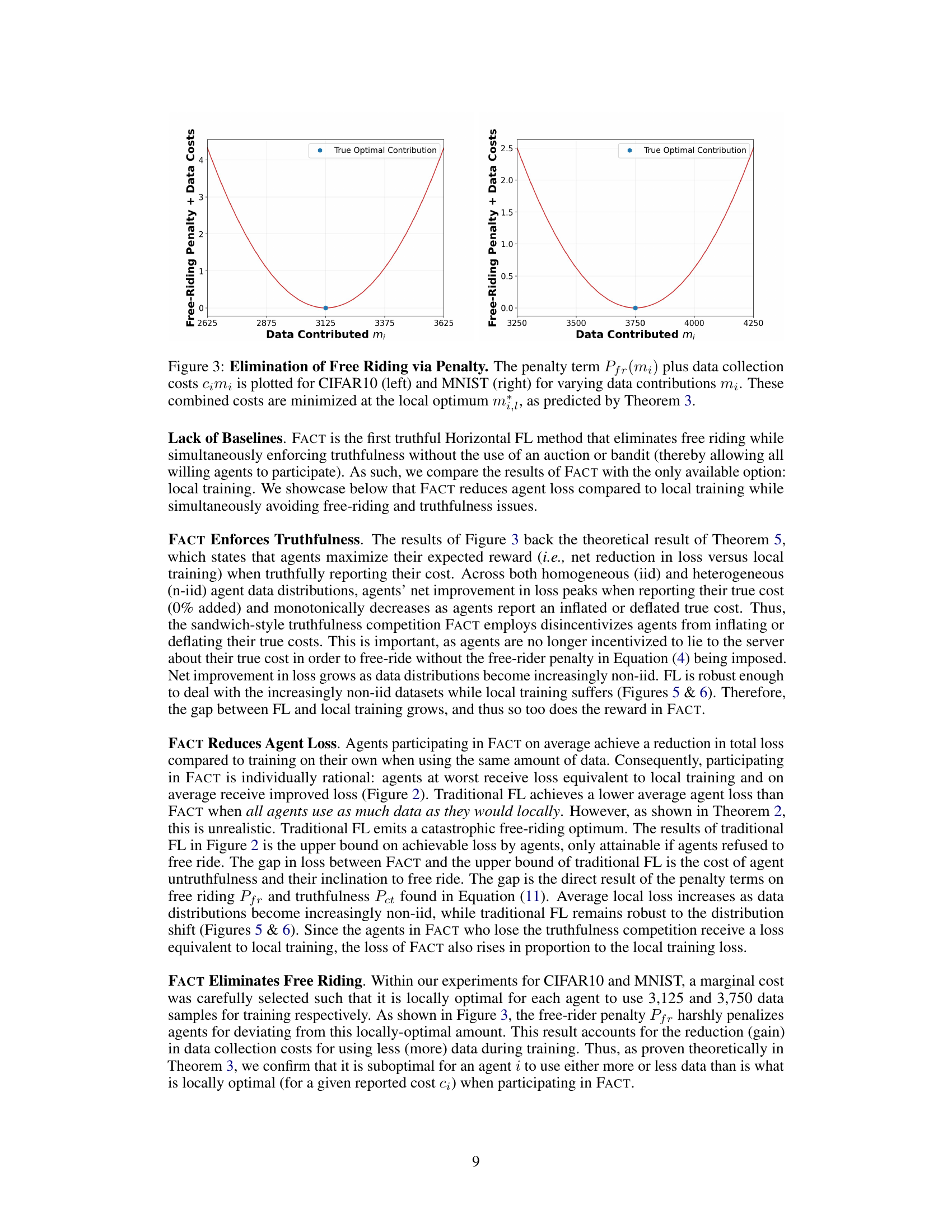
This figure shows the combined free-riding penalty and data costs for CIFAR-10 and MNIST datasets. The x-axis represents the amount of data contributed by an agent (mi), and the y-axis represents the total cost (penalty + data cost). The plot demonstrates that the total cost is minimized when the agent contributes the locally optimal amount of data (m*), which is predicted by Theorem 3 in the paper. This visually confirms that the proposed penalty mechanism effectively discourages free-riding behavior by making it more costly for agents to contribute less than the optimal amount of data.

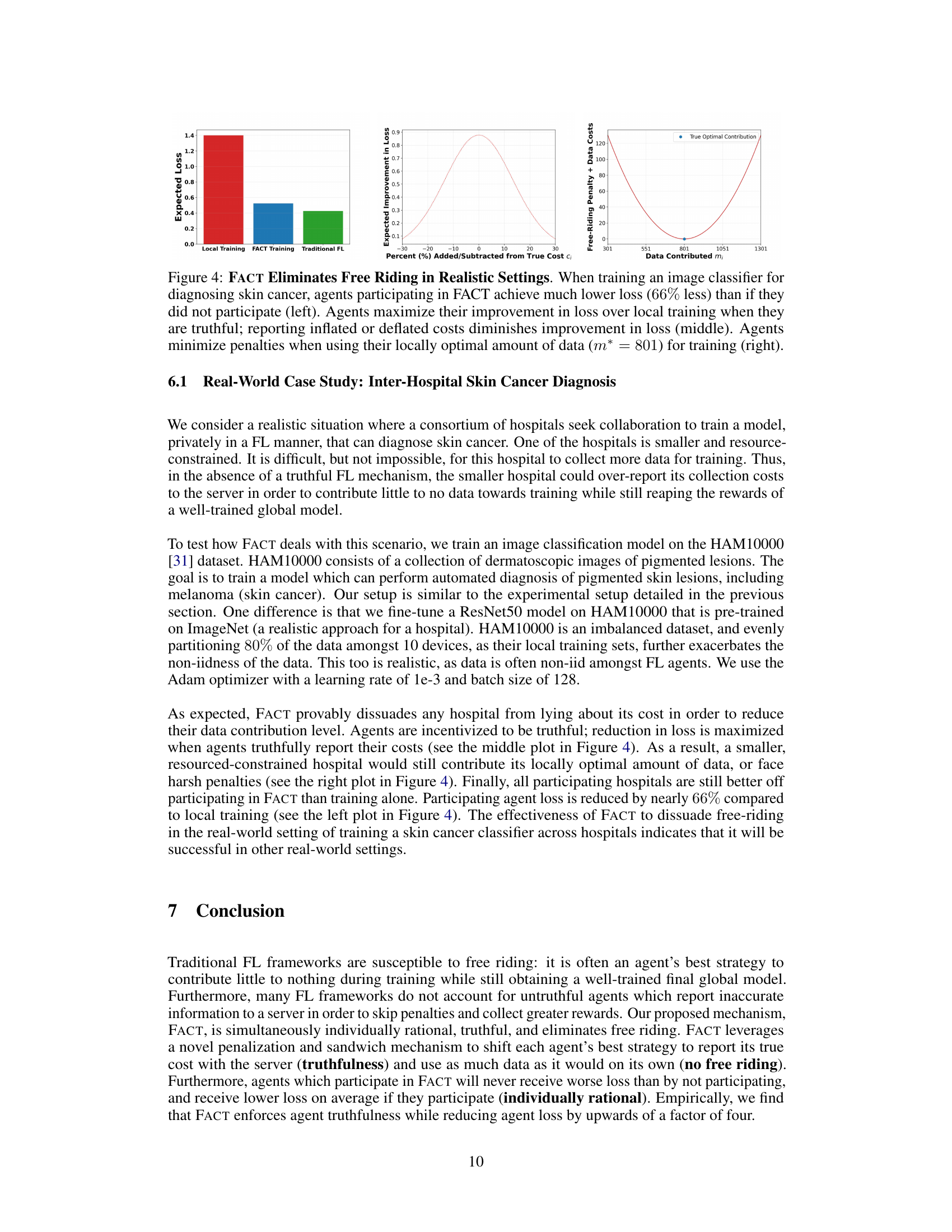
This figure demonstrates FACT’s effectiveness in a real-world scenario of skin cancer diagnosis. The left panel shows that agents using FACT achieve significantly lower loss (66%) compared to local training. The middle panel illustrates the truthfulness mechanism; agents maximize their loss improvement when reporting their true costs. Inflating or deflating the cost reduces the benefit, enforcing truthful behavior. The right panel visualizes the penalty function, demonstrating that the minimum penalty and optimal data usage align, which eliminates free-riding.
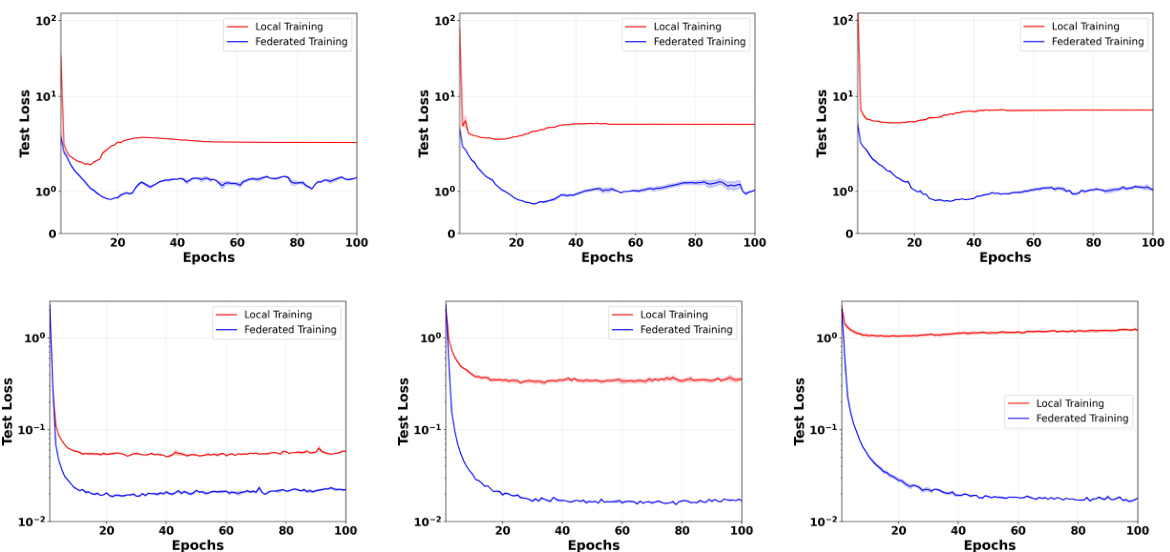
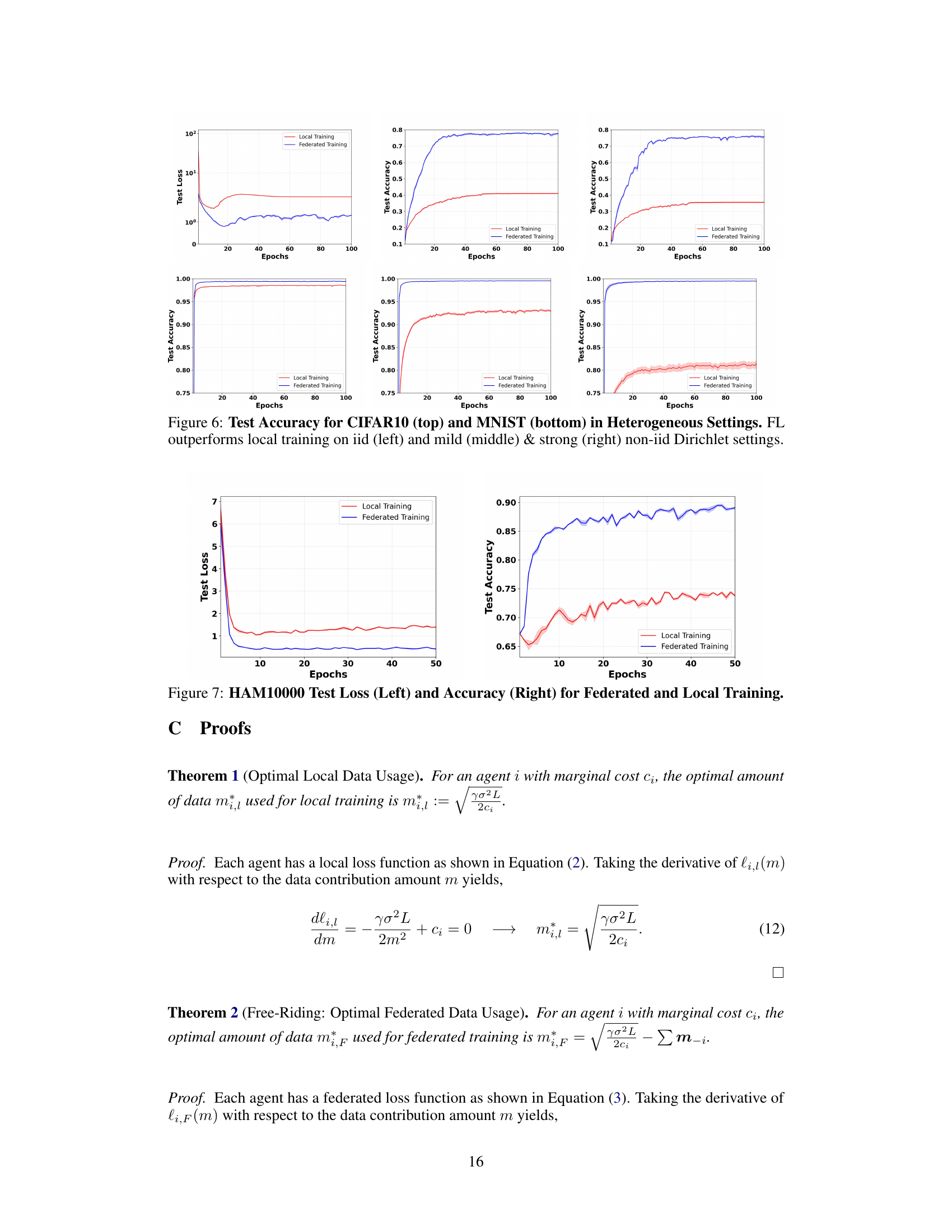
This figure compares the test loss for both federated learning (FL) and local training across three different data distribution settings: IID, mildly non-IID, and strongly non-IID. The non-IID settings use Dirichlet distributions with α = 0.3 and 0.6 to model heterogeneity in data. The results clearly demonstrate the robustness of federated training using FedAvg, consistently outperforming local training, particularly in the non-IID scenarios where data is more unevenly distributed across clients.
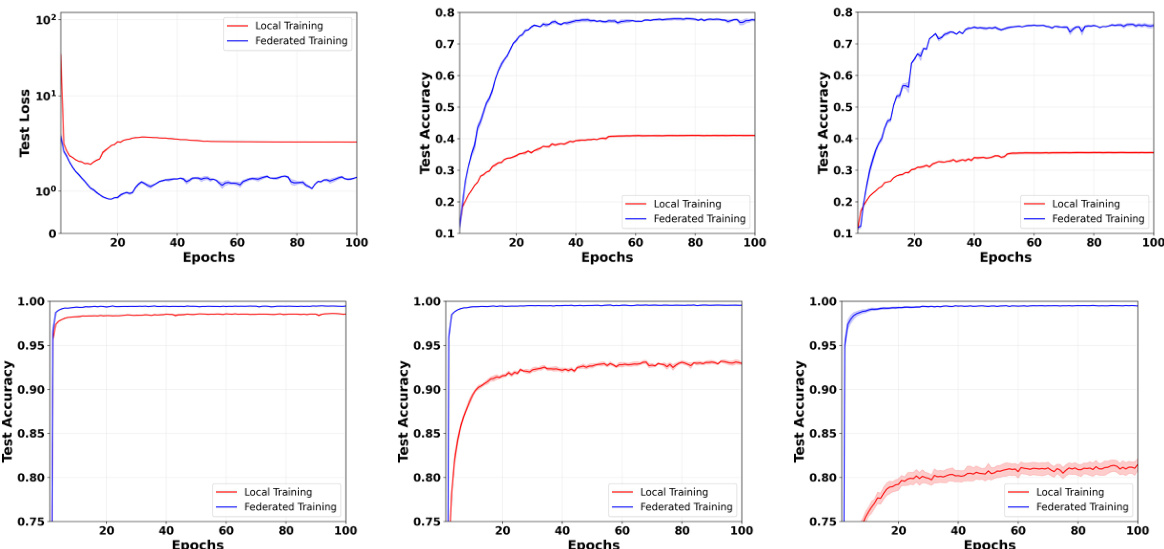
This figure compares the test loss of federated learning (FL) and local training on CIFAR-10 and MNIST datasets under different data distribution scenarios. It shows that federated learning consistently outperforms local training across various settings, including iid (independent and identically distributed) and non-iid (non-independent and identically distributed) data with varying degrees of heterogeneity. The results highlight the benefits of federated learning, especially in non-iid scenarios where data is not evenly distributed across participating agents.

This figure shows the test loss and accuracy for both federated and local training on the HAM10000 dataset. The left plot displays the test loss over epochs, while the right plot shows the test accuracy over epochs. The results show that federated learning outperforms local training for this specific dataset. The error bars around the accuracy represent the variation across multiple training runs.
Full paper#