↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Weakly supervised point cloud semantic segmentation struggles with insufficient supervision signals, hindering accurate scene understanding. Existing methods rely on heuristic constraints, often neglecting the inherent distribution of network embeddings. This paper addresses this gap by focusing on how to mathematically characterize the feature space and enhance this intrinsic distribution under weak supervision.
The proposed Distribution Guidance Network (DGNet) uses a mixture of von Mises-Fisher distributions to guide the alignment of weakly supervised embeddings. DGNet comprises two branches: a weakly supervised learning branch and a distribution alignment branch. Through an iterative optimization process, DGNet ensures that the network embeddings align with the defined latent space, leading to significant performance improvements over existing methods across various datasets and weakly supervised settings. This approach provides a mathematically sound foundation for improving weakly supervised point cloud segmentation.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the limitations of weakly supervised point cloud semantic segmentation, a critical area in 3D computer vision. By introducing a novel distribution-guided network, it significantly improves accuracy and offers a new perspective on handling limited annotations, thereby advancing research and applications in areas like autonomous driving and 3D scene understanding.
Visual Insights#
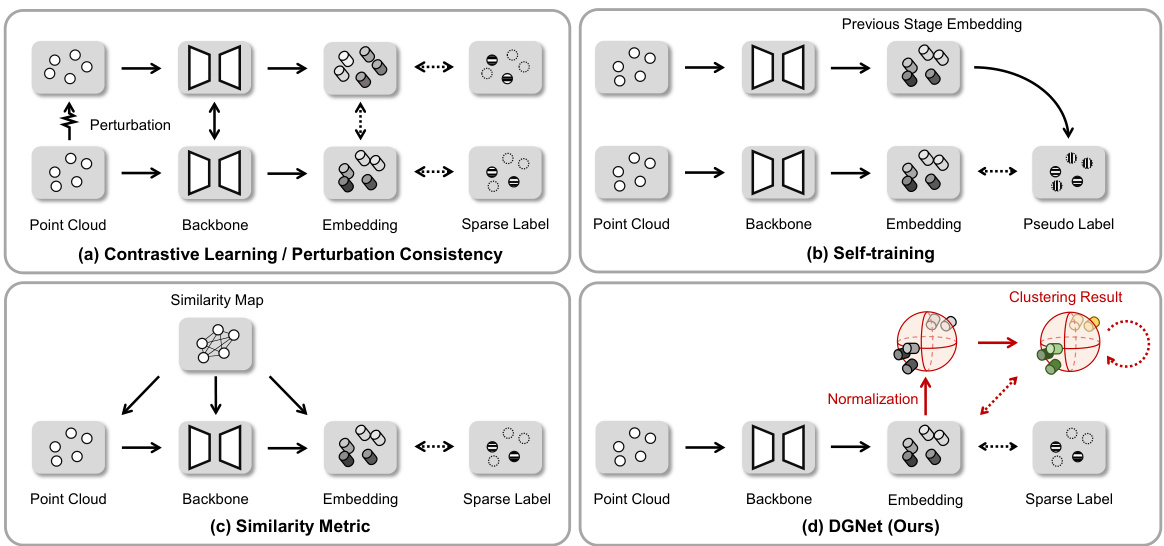
This figure compares four different weakly supervised point cloud semantic segmentation methods, including contrastive learning/perturbation consistency, self-training, similarity metric, and the proposed Distribution Guidance Network (DGNet). Each method is illustrated with a diagram showing the flow of data through the network and the type of loss function used. The figure highlights the differences in how these methods leverage sparse annotations to guide the learning process. DGNet, in particular, is shown to utilize a distribution alignment branch to refine the feature embeddings, leading to improved segmentation performance.
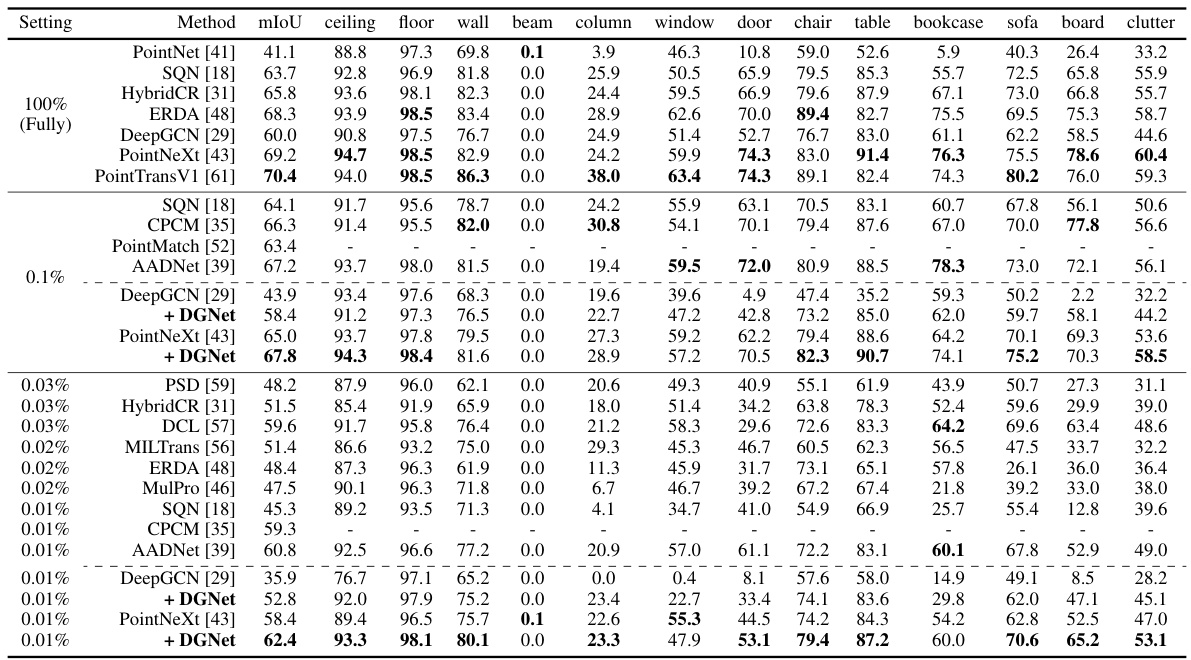
This table presents a quantitative comparison of various weakly supervised semantic segmentation methods on the S3DIS Area 5 dataset. Different methods are evaluated at various label rates (100%, 0.1%, 0.03%, 0.02%, 0.01%), showing the mIoU (mean Intersection over Union) scores for each class (ceiling, floor, wall, beam, etc.). The table highlights the superior performance of DGNet, especially at lower label rates.
In-depth insights#
Weakly Supervised Seg#
Weakly supervised semantic segmentation presents a significant challenge in computer vision, aiming to achieve accurate segmentation with minimal labeled data. This contrasts with fully supervised methods that require extensive, pixel-level annotations. The core difficulty lies in the scarcity of supervisory signals, hindering the learning process. Approaches often employ techniques like pseudo-labeling, self-training, and contrastive learning to leverage unlabeled data. However, these methods often struggle with noisy pseudo-labels and ambiguous feature representations. Effective strategies must carefully manage the balance between utilizing unlabeled data and mitigating the impact of noisy or incomplete supervision. A promising direction is to incorporate prior knowledge or inductive biases, possibly through probabilistic modeling of feature distributions, to guide the learning process and improve robustness. Research in this area is crucial for expanding the applicability of semantic segmentation to scenarios where large annotated datasets are unavailable or impractical to obtain. Future work should focus on developing more sophisticated methods for handling uncertainty and noise while effectively leveraging the potential of unlabeled data.
MoVMF Distrib#
The heading ‘MoVMF Distrib’ likely refers to a section discussing the Mixture of von Mises-Fisher (MoVMF) distributions. This is a powerful statistical model ideally suited for representing data points on a unit hypersphere, a common scenario in high-dimensional spaces like those encountered in point cloud feature embeddings. The choice of MoVMF is likely motivated by its ability to capture the complex, multi-modal structure inherent in point cloud data, where different clusters of points might exhibit distinct directional preferences. The section would delve into the mathematical formulation of the MoVMF model, explaining its parameters and how they relate to the underlying data structure. Crucially, it would also probably elaborate on how this distribution is used within a larger framework, possibly for feature space modeling, unsupervised or weakly supervised learning, and how the parameters of the MoVMF are learned or estimated from the data. This might involve techniques like Expectation-Maximization (EM) algorithms, often used to estimate parameters for mixture models. The effectiveness of using MoVMF would be justified, potentially by comparing it to alternative distribution models. Overall, this section is vital for understanding the core methodology, as it provides the mathematical foundation for the proposed approach and its capacity to handle point cloud feature space modeling effectively. Understanding the MoVMF distribution is central to appreciating the methodological advancements described in the paper.
DGNet Arch#
The hypothetical “DGNet Arch” section would detail the architecture of the Distribution Guidance Network, likely showcasing its two main branches: the weakly supervised learning branch and the distribution alignment branch. The weakly supervised branch would process point cloud data with sparse annotations, producing initial semantic embeddings. Critically, the design would need to address the challenge of limited supervision, potentially employing techniques like truncated cross-entropy loss to prevent overfitting. The distribution alignment branch would be crucial, taking these embeddings and enforcing alignment with a mixture of von Mises-Fisher distributions (moVMF). This alignment, perhaps achieved through an iterative Expectation-Maximization (EM) algorithm, ensures the feature space reflects the moVMF’s structure, enhancing the model’s ability to generalize from limited data. The architecture diagram would illustrate the flow of data and the interaction between the two branches, likely highlighting how the distribution alignment branch refines the weakly supervised embeddings. Details of specific network components (e.g., backbone network, segmentation head) and their configurations would be presented, along with a discussion on the rationale behind the chosen architectural choices and their impact on the overall performance.
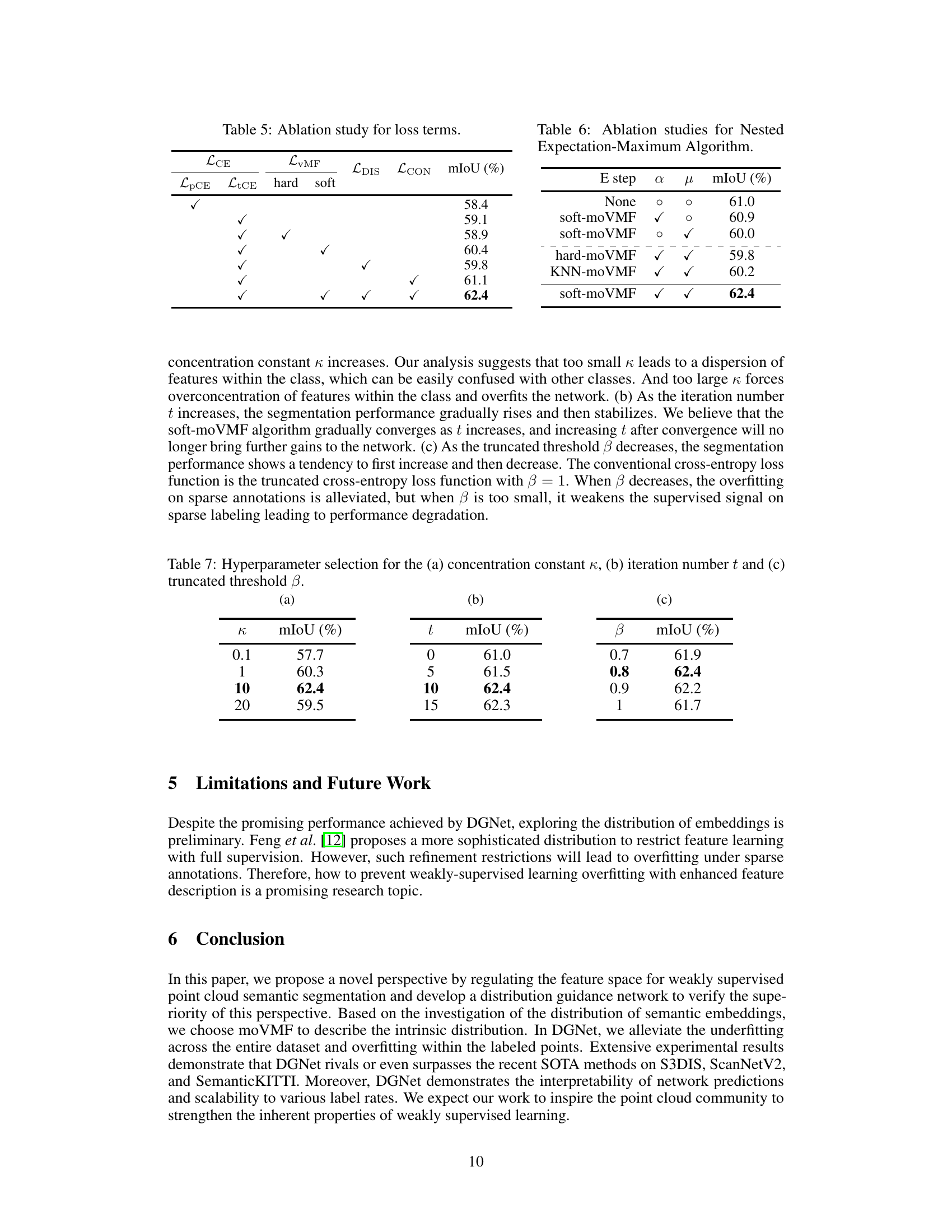
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In this context, it would involve gradually disabling parts of the proposed Distribution Guidance Network (DGNet), such as the distribution alignment branch, specific loss functions (LVMF, LDIS, LCON), or the choice of distance metric and distribution modeling. The results would reveal the impact of each component on the overall performance, measured by metrics like mIoU (mean Intersection over Union). A successful ablation study will demonstrate the effectiveness of each component of the DGNet and validate design choices. For example, removing the distribution alignment branch might lead to a significant drop in performance, showcasing its crucial role in aligning feature embeddings to a more informative distribution, enhancing weak supervision. Analyzing the impact of individual loss functions provides insights into their relative importance and interaction. Furthermore, the ablation study would compare different choices made in the design, like the effect of using Euclidean distance vs. cosine similarity, providing strong evidence to support the selection of the von Mises-Fisher distribution. The study would ultimately reinforce the model’s robustness and highlight its key strengths. The detailed results from this ablation study would be essential in justifying the design of DGNet and in comparing its performance with other state-of-the-art methods.
Future Work#
The paper’s discussion on future work could significantly benefit from expanding on the limitations of the current moVMF-based approach. Addressing the computational cost associated with the expectation-maximization algorithm, particularly for large-scale point clouds, is crucial. Exploring alternative, potentially more efficient, methods for distribution alignment would strengthen the proposal. The current focus on moVMF warrants further investigation into other distributions suitable for capturing the diverse characteristics of point cloud feature spaces. Investigating the sensitivity of DGNet to noise and outliers is vital, since real-world point cloud data is often imperfect. Furthermore, research exploring the applicability of DGNet to other weakly supervised tasks beyond semantic segmentation, such as object detection or instance segmentation, could broaden its impact. Finally, a thorough analysis of the model’s generalization capabilities across different domains and datasets would enhance the overall robustness of the findings.
More visual insights#
More on figures
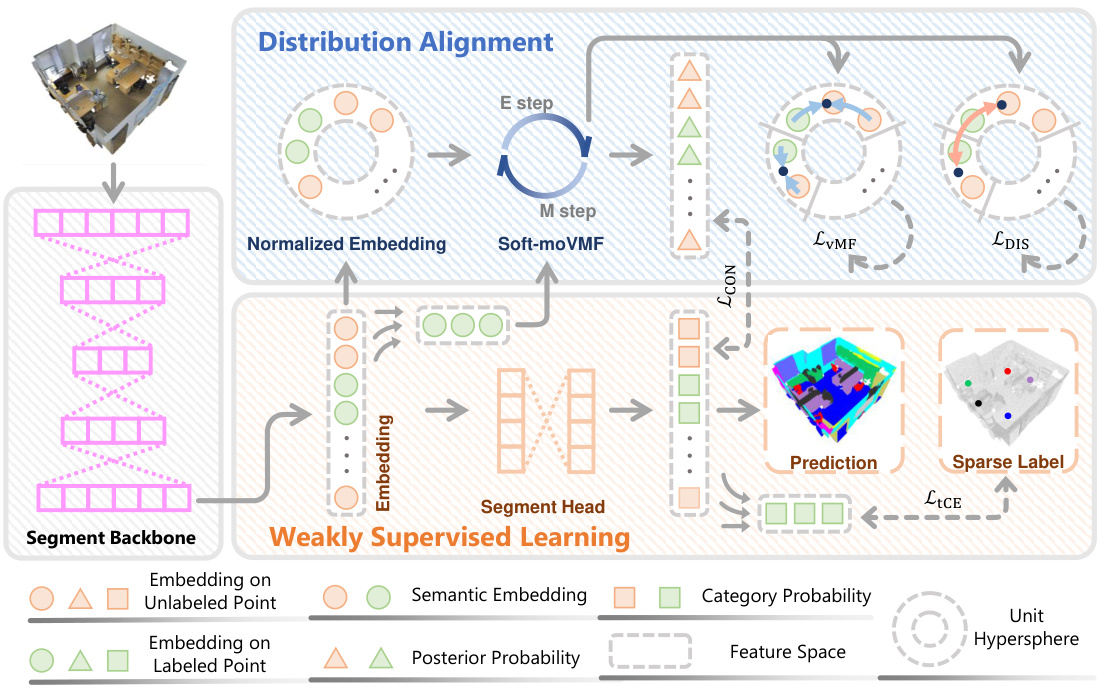
The figure illustrates the architecture of the Distribution Guidance Network (DGNet), which consists of two main branches: the weakly supervised learning branch and the distribution alignment branch. The weakly supervised learning branch takes sparse annotations as input and learns semantic embeddings from the point cloud data. This branch also provides robust initialization for the distribution alignment branch. The distribution alignment branch dynamically aligns the embedding distribution to the mixture of von Mises-Fisher distributions (moVMF). This is achieved using a nested Expectation-Maximum (EM) algorithm, which alternates between updating the network parameters and the moVMF parameters. The moVMF parameters help in characterizing the latent feature space and enforcing alignment. Three loss functions are used to guide the training: cross-entropy loss (LICE) for the weakly supervised learning branch, vMF loss (LVMF) for aligning the embedding distribution to moVMF, and discriminative loss (LDIS) for ensuring distinct decision boundaries between the different categories. A consistency loss (LCON) is also used to impose consistency between the segmentation predictions from the weakly supervised branch and the posterior probabilities from the distribution alignment branch.

This figure shows a pipeline of the proposed DGNet architecture. First, a point cloud is fed into the DGNet which consists of two branches: the weakly supervised learning branch and the distribution alignment branch. The weakly supervised learning branch generates a prediction for the point cloud. Simultaneously, the distribution alignment branch provides a probabilistic explanation of the prediction by calculating posterior probabilities. The posterior probabilities show the probability of each point belonging to a specific class, providing insights into the prediction’s confidence.
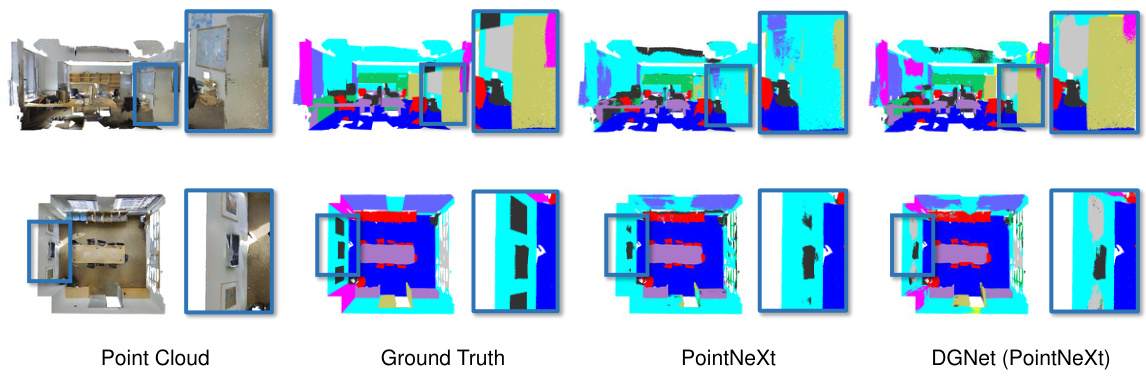
This figure presents a qualitative comparison of the segmentation results obtained using PointNeXt (a baseline method) and DGNet (the proposed method) on the S3DIS Area 5 dataset. The comparison is performed using a 0.01% label rate, indicating a very sparse annotation setting. The figure shows several point cloud scenes from S3DIS Area 5, alongside their respective ground truth segmentations, PointNeXt segmentations, and DGNet segmentations. Each scene includes a region highlighted with a blue box, highlighting specific areas where the visual difference between the two methods is significant. This visual comparison aims to demonstrate the improvements in segmentation accuracy achieved by DGNet, even under extremely sparse annotation conditions.
More on tables
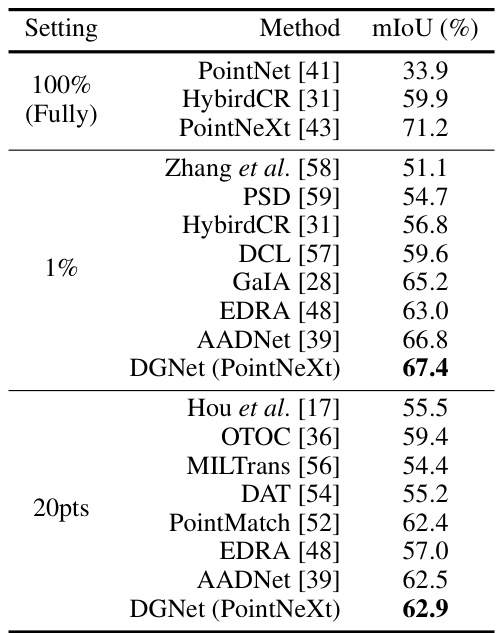
This table presents a quantitative comparison of different methods on the ScanNet dataset, showing the mean Intersection over Union (mIoU) achieved by each method under different supervision settings (100%, 1%, and 20 points). The table highlights the performance of DGNet (using PointNeXt as the backbone) compared to state-of-the-art methods. It shows the improvement in mIoU that DGNet achieves over baselines across different supervision levels.
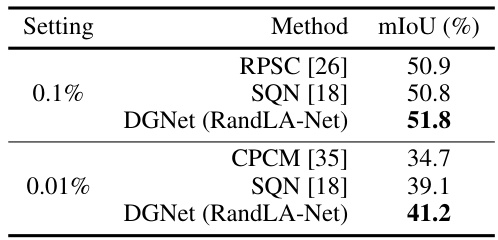
This table presents a comparison of the mean Intersection over Union (mIoU) scores achieved by different methods on the SemanticKITTI dataset. The comparison is done under two weakly supervised settings: 0.1% and 0.01% label rates. The table shows that DGNet (using RandLA-Net as the backbone network) outperforms other methods in both settings, demonstrating its effectiveness in weakly supervised semantic segmentation of outdoor point clouds.
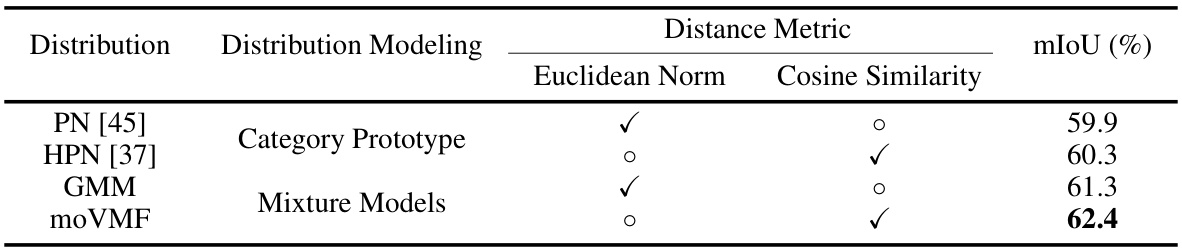
This table presents the ablation study results on the selection of feature distribution description and distance metric in the distribution alignment branch of the proposed Distribution Guidance Network (DGNet). Four different combinations are compared: Category Prototype with Euclidean Norm, Category Prototype with Cosine Similarity, Gaussian Mixture Model (GMM) with Euclidean Norm, and Mixture of von Mises-Fisher distributions (moVMF) with Cosine Similarity. The results demonstrate that moVMF with Cosine Similarity achieves the best performance (mIoU of 62.4).
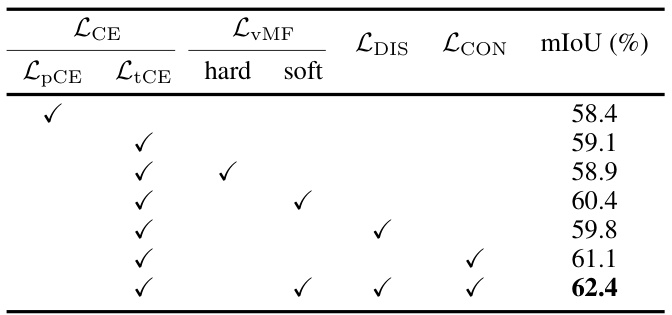
This table presents the results of an ablation study conducted to evaluate the impact of different loss terms on the performance of the proposed model. The study examines the contribution of partial cross-entropy loss (LPCE), truncated cross-entropy loss (LICE), hard von Mises-Fisher (vMF) loss, soft vMF loss, discriminative loss (LDIS), and consistency loss (LCON). The results are reported in terms of mean Intersection over Union (mIoU), a common metric for evaluating semantic segmentation models.
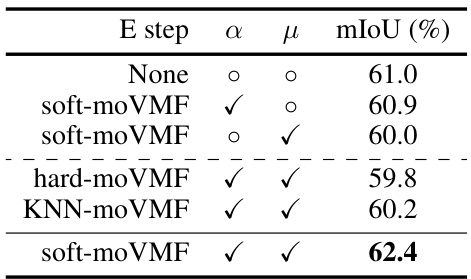
This table presents the ablation study for the Nested Expectation-Maximum Algorithm used in the paper. It shows the results of different configurations, including whether the E-step (expectation) was used for the soft-moVMF (mixture of von Mises-Fisher distributions) and/or whether the M-step (maximization) was used for the parameters α (proportion of each von Mises-Fisher distribution) and μ (mean vector of each distribution). The results demonstrate that the soft-moVMF algorithm with both E-step and M-step optimization provides the best performance, achieving a mIoU (mean Intersection over Union) of 62.4%.
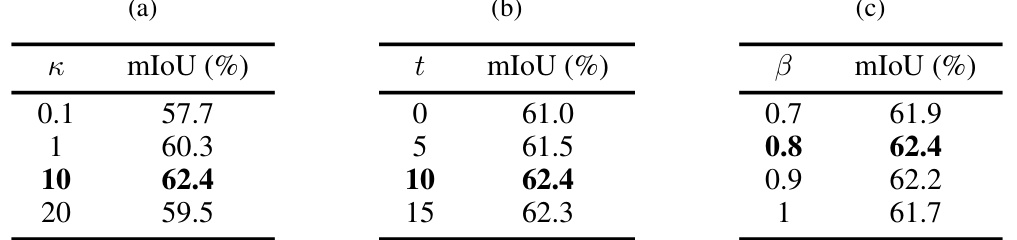
This ablation study investigates the impact of each individual loss term (partial cross-entropy loss, vMF loss, discriminative loss, and consistency loss) and their combinations on the overall segmentation performance. It shows that the truncated cross-entropy loss and all three additional loss terms contribute to performance improvement in DGNet.

This table presents a comparison of the mean Intersection over Union (mIoU) scores achieved by the PointNeXt baseline and the DGNet (PointNeXt) method across different label rates (10%, 1%, 0.1%, 0.01%, and 0.001%). It demonstrates the performance of both methods under various levels of data sparsity, highlighting the impact of weakly supervised settings on the models’ ability to accurately segment point cloud data.

This table presents the results of a sensitivity analysis performed on the DGNet model using the S3DIS Area 5 dataset. The analysis focuses on evaluating the model’s performance under varying numbers of labeled points, while maintaining the same label rate. The experiment was repeated five times for each setting (0.1% and 0.01% label rates), altering the locations of the labeled points. The table displays the model’s performance (mIoU) for each trial, along with the mean and standard deviation across all trials, showcasing the model’s robustness and consistency.
Full paper#