↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Reinforcement learning (RL) has shown great promise, but its high sample complexity makes real-world applications challenging. A common approach is to train in a simulator, then transfer the policy to the real world (sim2real). However, this direct sim2real transfer often fails due to inconsistencies between simulated and real environments. This paper addresses this critical limitation.
This research introduces a novel approach: instead of directly transferring a policy that solves a task in simulation, it proposes transferring a set of exploratory policies trained in the simulator to guide exploration in the real world. Coupled with practical methods like least-squares regression and random exploration, this approach achieves provably efficient learning in the real world, significantly outperforming direct sim2real transfer and learning without a simulator. Experiments on robotic simulators and a real-world robotic task validate the theoretical findings, showcasing significant practical improvements.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the sim-to-real gap challenge in reinforcement learning, a major hurdle in applying RL to real-world robotics. By proving that transferring exploratory policies from simulation to the real world offers significant gains, it provides a principled approach to this problem. This opens up new avenues for research in more efficient sim2real transfer, benefiting researchers in robotics and other fields. The provably efficient method presented could lead to faster, safer deployment of RL in complex environments.
Visual Insights#

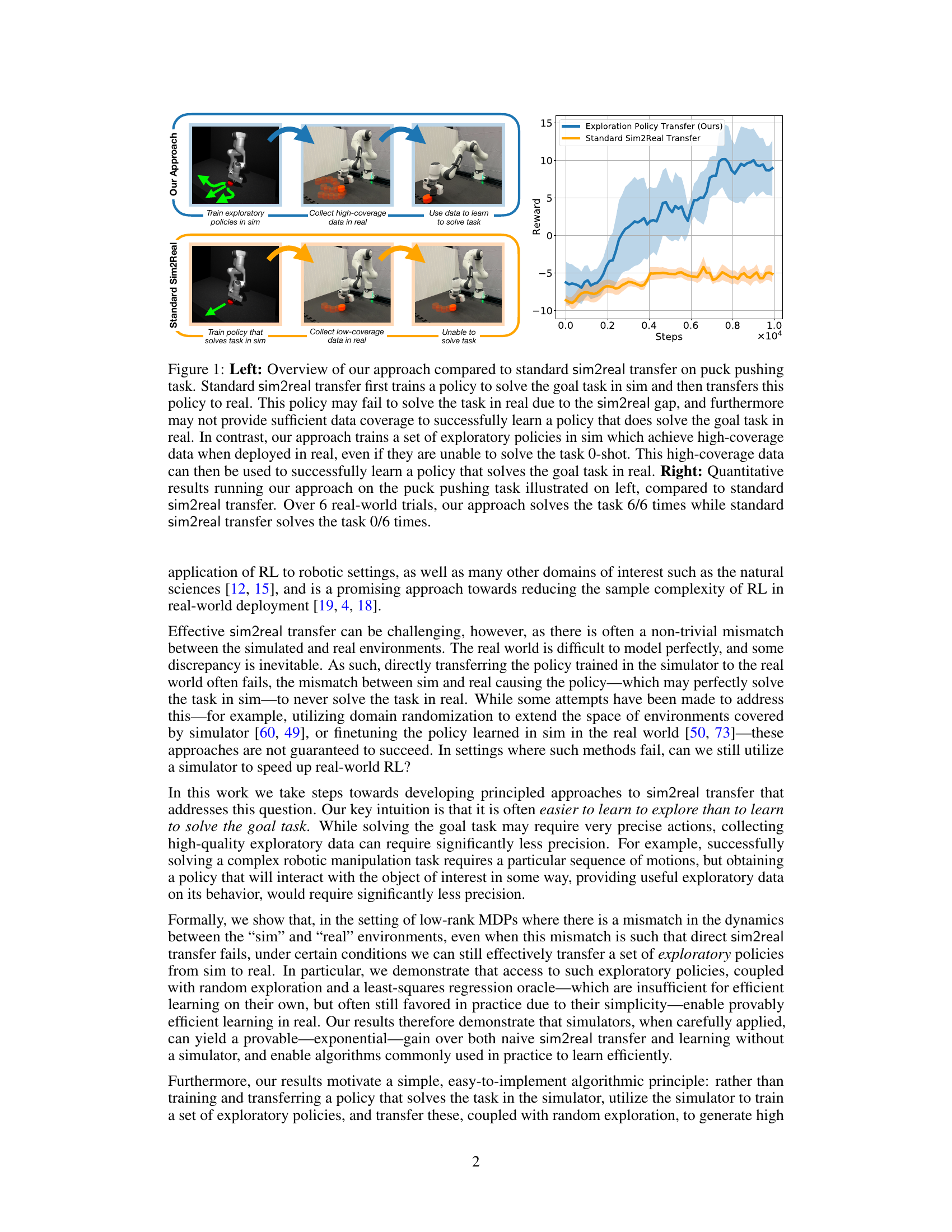
This figure compares the proposed approach with standard sim2real transfer for a puck pushing task. The left panel illustrates the methods. Standard sim2real transfer trains a policy in simulation and directly transfers it to the real world, which may fail due to the sim2real gap and insufficient data coverage. The proposed approach trains exploratory policies in simulation to collect high-coverage data in the real world, even if they don’t solve the task initially. This data is then used to learn a policy that successfully solves the task in the real world. The right panel shows quantitative results for six real-world trials, where the proposed method successfully solves the task in all trials, while standard sim2real transfer fails in all trials.

This table lists the hyperparameters used in the TychoEnv sim2sim experiment. It includes values for reward balance (alpha in OS algorithm), learning rate, Q update magnitude, discount factor (gamma), batch size, steps per episode, replay buffer size, and the number of training steps (N) performed in the real environment. These settings are crucial for reproducibility and understanding the experimental setup.
In-depth insights#
Sim-to-real Transfer#
Sim-to-real transfer, a cornerstone of reinforcement learning (RL), aims to bridge the gap between simulated and real-world environments. The core challenge lies in the discrepancy between the simulated and real dynamics, which often leads to policies trained in simulation failing to generalize effectively in the real world. This paper tackles this problem by shifting the focus from directly transferring a task-solving policy to transferring exploratory policies learned in simulation. This approach is theoretically grounded in the setting of low-rank Markov Decision Processes (MDPs), demonstrating a provable exponential improvement over naive sim-to-real transfer and learning without simulation. The key insight is that learning to explore is often easier than learning to solve a complex task. By generating high-quality exploratory data in the real world using policies initially trained in simulation, coupled with simple practical approaches like least-squares regression, efficient learning becomes achievable. The paper’s experimental validation showcases significant practical gains, particularly in robotic applications where sample collection in the real world is expensive. This work highlights the potential of leveraging simulation to learn exploration strategies, rather than task-solving policies, offering a promising pathway to improve sample efficiency in real-world RL.
Exploration Policies#
The concept of ‘Exploration Policies’ in reinforcement learning centers on strategically guiding an agent’s interactions with an environment to gather diverse and informative experiences. Unlike exploitation, which focuses on maximizing immediate reward using current knowledge, exploration prioritizes discovering novel states and actions. Effective exploration is crucial for overcoming the sim-to-real gap, as it facilitates the creation of robust policies that generalize well from simulation to the real world. The core idea revolves around training a set of exploratory policies in a simulator, where data acquisition is cheap, and then transferring these learned policies to the real environment for data collection. These policies aim to maximize data coverage, even if they don’t directly solve the main task. The collected real-world data is then leveraged to learn a high-performing policy, effectively bridging the simulation-reality gap. Provable guarantees for this approach often exist within specific MDP settings (e.g., low-rank MDPs), highlighting its theoretical soundness and practical potential.
Low-Rank MDPs#
Low-rank Markov Decision Processes (MDPs) are a crucial modeling assumption in reinforcement learning, offering a balance between model complexity and the ability to learn efficiently. Low-rankness implies that the transition dynamics can be effectively represented by a low-dimensional feature space, drastically reducing the number of parameters needed to capture the environment’s behavior. This is particularly advantageous for real-world scenarios where data is scarce and computationally expensive to obtain. The assumption of low-rankness enables the design of provably efficient reinforcement learning algorithms that can overcome the curse of dimensionality, allowing for scaling to complex problems. However, identifying suitable low-dimensional feature representations remains a challenge, and the effectiveness of low-rank MDP methods hinges on choosing features that accurately reflect the underlying system dynamics. Mismatches between the simulator and the real-world environment can significantly impact the performance of these methods if the low-rank structure is not preserved across domains. Furthermore, the assumption of low-rankness might not always hold in practice, and algorithms need to be robust to deviations from this idealization. Finally, the selection of appropriate function approximation techniques for handling low-rank MDPs plays a critical role in determining the algorithm’s effectiveness and efficiency.
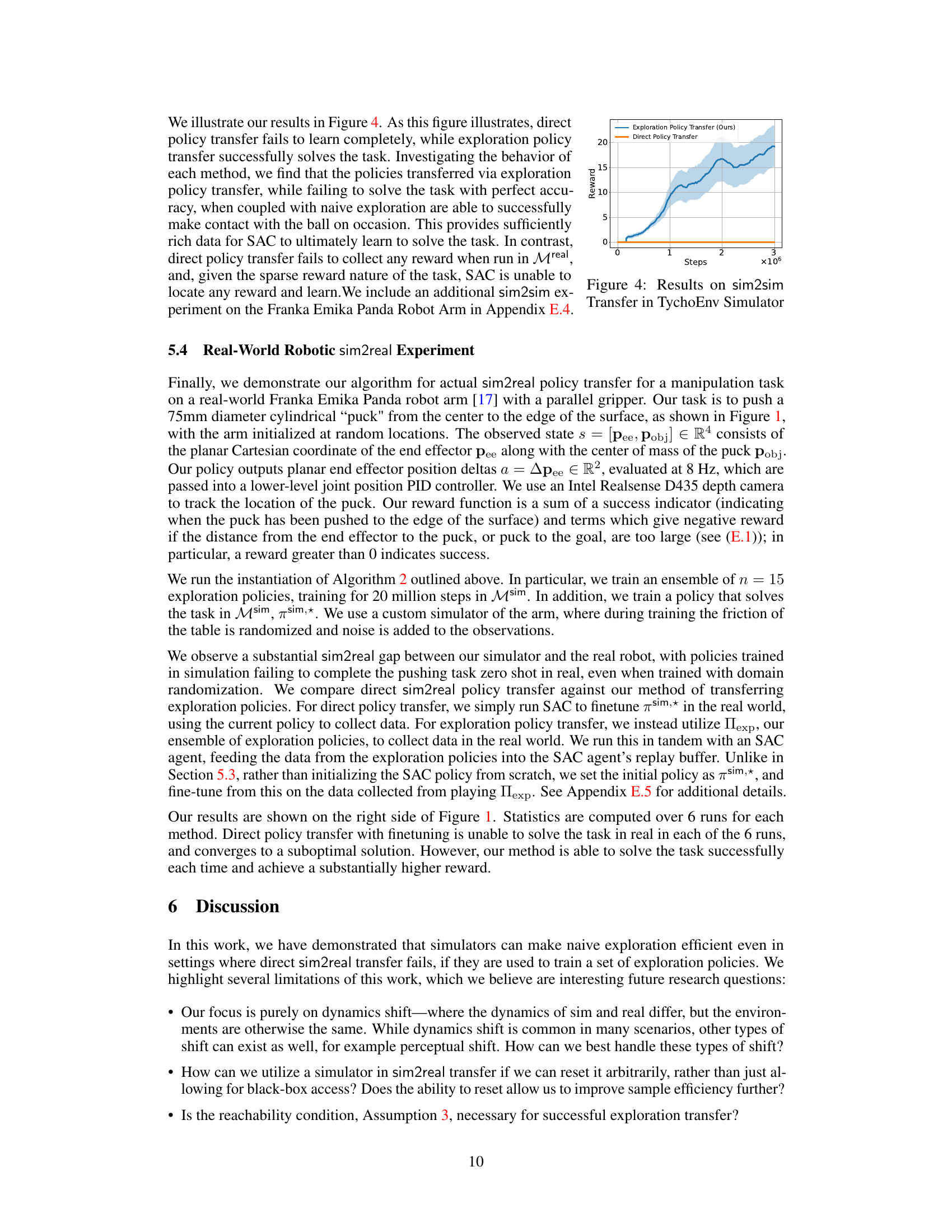
Robotic Experiments#
A hypothetical section on “Robotic Experiments” in a reinforcement learning research paper would likely detail the experimental setup, methodologies, and results. The experiments would aim to validate the theoretical claims about sim-to-real transfer, comparing the performance of policies learned with and without leveraging simulation for exploration. Key aspects would include the robotic platforms used (e.g., Franka Emika Panda arm, 7-DOF Tycho robot), the tasks performed (e.g., puck pushing, reaching, hammering), and metrics used to assess success (e.g., success rate, reward, sample efficiency). The description of each task should be comprehensive, including details on the environment, sensors, actuators, and control interfaces. The authors would present a rigorous comparison between different sim-to-real strategies, such as direct policy transfer and the proposed exploration policy transfer approach. Results would demonstrate the efficacy of the proposed approach in real-world scenarios, showcasing improvements in sample efficiency and overall task performance. The discussion would address potential limitations and challenges, such as the inherent complexities of real-world robot control and the difficulty in creating perfect simulation environments. Finally, the experiments section should clearly state how results support the main contributions of the paper, concluding that exploration policy transfer offers a substantial improvement for real-world RL applications.
Future Directions#
The “Future Directions” section of this research paper would ideally explore several key areas. Extending the theoretical framework beyond low-rank MDPs is crucial, investigating its applicability to more complex real-world scenarios with higher dimensionality and non-linear dynamics. Addressing different types of sim-to-real gaps is important; the paper focuses on dynamics mismatch, but future work should consider perceptual or reward mismatches. Developing more efficient algorithms for exploration policy transfer is also vital, potentially by leveraging advanced optimization techniques or more sophisticated exploration strategies. The current algorithm relies on a least-squares regression oracle; exploring alternative, potentially more powerful oracles would enhance efficiency. Empirical validation on a broader range of robotic tasks and environments is needed to further solidify the findings and assess the generalizability of the approach. Investigating the interplay between exploration policy transfer and other sim-to-real techniques, such as domain randomization or domain adaptation, could lead to significant improvements. Finally, a thorough investigation into the practical limitations and robustness of the proposed method in noisy or uncertain environments is essential before wider adoption.
More visual insights#
More on figures

This figure shows a comparison of three different reinforcement learning approaches on a didactic combination lock task. The left panel illustrates the structure of the combination lock problem, highlighting the state transitions and rewards. The right panel presents the results, comparing the performance of Exploration Policy Transfer (the authors’ proposed method), Direct Policy Transfer (a standard baseline), and Q-learning with naive exploration (another standard baseline). The graph shows the average reward achieved over time, demonstrating that the Exploration Policy Transfer approach significantly outperforms the baselines in learning to solve the combination lock problem.

The figure compares the proposed approach with standard sim2real transfer methods on a puck pushing task. The left panel illustrates the key differences: standard sim2real transfer trains a policy in simulation and directly transfers it to the real world, which may fail due to the sim-to-real gap and insufficient data coverage. In contrast, the proposed method trains exploratory policies in simulation to gather high-coverage data in the real world, enabling efficient learning of a successful policy. The right panel presents the quantitative results from 6 real-world trials. The proposed method achieves perfect success (6/6), while standard sim2real transfer fails completely (0/6).

The figure illustrates the difference between standard sim2real transfer and the proposed approach. Standard sim2real transfer trains a policy in simulation and directly transfers it to the real world, which often fails due to the sim-to-real gap. The proposed approach trains exploratory policies in simulation to collect high-coverage data in the real world, enabling efficient real-world learning. The right panel shows quantitative results demonstrating that the proposed method successfully solved the task in all 6 trials, whereas standard sim2real transfer failed in all trials.

This figure compares the proposed approach with standard sim2real transfer in a puck-pushing task. The left panel illustrates the methods: standard sim2real transfer trains a policy in simulation and directly transfers it to the real world, which often fails due to the sim-to-real gap. In contrast, the proposed approach trains exploratory policies in simulation to collect high-coverage data in the real world, even if these policies don’t initially solve the task. This data is used to learn a real-world policy that successfully solves the task. The right panel shows quantitative results, demonstrating the proposed approach’s success rate of 6/6 compared to 0/6 for standard sim2real transfer.

The figure shows a comparison between the standard sim2real transfer approach and the proposed approach for solving a puck pushing task. The standard approach directly transfers a policy trained in simulation to the real world, which often fails due to the sim-to-real gap. In contrast, the proposed approach trains exploratory policies in simulation to gather high-coverage data in the real world, even if the policies do not initially solve the task. This high-coverage real-world data enables efficient learning of a policy that solves the task in the real world. The figure includes a qualitative illustration (left) and quantitative results (right) demonstrating the significant improvement achieved by the proposed approach.

This figure compares the proposed sim2real transfer approach with a standard sim2real transfer approach on a puck-pushing task. The left panel illustrates the two approaches: Standard sim2real directly transfers a policy trained in simulation to the real world, which often fails due to sim2real gap and insufficient data coverage. The proposed method trains exploratory policies in simulation that, when deployed in the real world, collect high-coverage data, enabling efficient real-world policy learning. The right panel quantitatively shows the results of six real-world trials, where the proposed method solved the task in all trials, while standard sim2real failed in all.

This figure compares the authors’ approach to standard sim2real transfer methods on a puck-pushing task. The left panel illustrates the two approaches: standard sim2real (training a policy in simulation and directly transferring it to the real world, which may fail due to the sim-to-real gap), and the authors’ proposed method (training exploratory policies in simulation to gather high-coverage data in the real world, then using that data to learn a policy that solves the task). The right panel shows quantitative results from six real-world trials demonstrating that the authors’ method successfully solved the task in all trials, while standard sim2real failed in all trials.

This figure compares the proposed exploration policy transfer approach with the standard sim2real transfer method for a puck pushing task. The left panel illustrates the two approaches. The standard sim2real method trains a policy in simulation and then directly transfers it to the real world, which often fails due to the sim-to-real gap and insufficient data coverage. The proposed method trains exploratory policies in simulation that are then used in the real world to gather high-coverage data, which then allows for learning a successful policy in the real world. The right panel shows quantitative results demonstrating the superior performance of the proposed approach. Over six real-world trials, the proposed approach successfully solved the task in all six cases, while the standard sim2real method failed in all six.
More on tables

This table lists the hyperparameters used for training and fine-tuning the TychoEnv robotic simulator. It includes values for reward balancing (alpha in OS algorithm), learning rate, Q update magnitude, discount factor (gamma), batch size, steps per episode, replay buffer size and the total number of training steps in the simulator (Mreal). The table details the specific settings used in the Tycho sim2sim experiments detailed in section 5.3 of the paper.
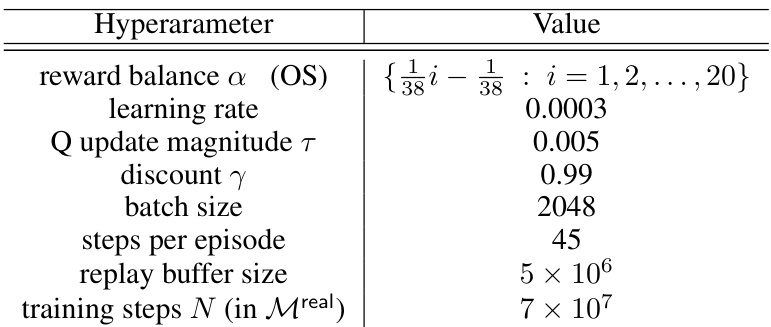
This table lists the hyperparameters used for training and fine-tuning the Tycho robotic simulator. It specifies the reward balance (alpha) for the OS algorithm, learning rate, Q-update magnitude (tau), discount factor (gamma), batch size, steps per episode, replay buffer size, and the total number of training steps in the real environment (Mreal). The reward balance alpha is varied across a range of values to find the optimal balance between reward and exploration.

This table lists the hyperparameters used in the Franka Emika Panda robot arm experiments, specifically for both the training and fine-tuning phases. It includes values for reward balancing (alpha), reward threshold (epsilon), learning rate, Q-update magnitude (tau), discount factor (gamma), batch size, steps per episode, replay buffer size, and total training steps (N). These settings were used to optimize the performance of the reinforcement learning algorithms in the robotic manipulation tasks.
Full paper#