↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current conditional diffusion models leverage classifier-free guidance (CFG) for high-quality image generation. However, extending CFG to unconditional models has proven challenging, resulting in suboptimal image quality and unintended side effects. Existing heuristic-based approaches haven’t fully addressed these issues.
This paper introduces Smoothed Energy Guidance (SEG), a novel approach that leverages the energy-based perspective of self-attention. SEG reduces energy curvature through Gaussian kernel adjustment, controlling the generation process without relying on training or conditions. This method offers a Pareto improvement over previous approaches, yielding better image quality while significantly minimizing side effects. The paper also introduces an efficient query blurring method, making SEG computationally feasible.
Key Takeaways#
Why does it matter?#
This paper is important because it offers a novel approach to guiding diffusion models without relying on classifier-free guidance or heuristic methods. This is significant because it addresses the limitations of existing techniques and opens up new avenues for research in unconditional image generation, improving the quality and reducing undesired artifacts. The proposed method, SEG, is also computationally efficient, making it practical for real-world applications.
Visual Insights#

This figure shows a comparison of image generation results between the vanilla Stable Diffusion XL (SDXL) model and the proposed Smoothed Energy Guidance (SEG) method. The left side (a) displays examples generated by the vanilla SDXL model without any guidance (unconditional generation), while the right side (b) presents examples generated using the SEG method. The results showcase SEG’s ability to generate plausible and high-quality images, even in the absence of input conditions, by improving on the quality of unconditional image generation.

This table presents a quantitative comparison of the proposed Smoothed Energy Guidance (SEG) method against three other methods: vanilla Stable Diffusion XL (SDXL), Self-Attention Guidance (SAG), and Perturbed Attention Guidance (PAG). The comparison is based on unconditional image generation and uses three metrics: Fréchet Inception Distance (FID), Learned Perceptual Image Patch Similarity (LPIPS) using VGG and AlexNet. Lower FID and LPIPS scores indicate better image quality. The table shows that SEG achieves a Pareto improvement over existing methods, offering better image quality with fewer side effects.
In-depth insights#
SEG: Energy Diffusion#
The heading ‘SEG: Energy Diffusion’ suggests a novel approach within the field of diffusion models, likely focusing on enhancing the efficiency and quality of image generation. SEG probably refers to a specific method, perhaps involving a smoothed energy function to guide the diffusion process. This approach might address limitations of existing methods like classifier-free guidance by reducing unwanted side effects often associated with high guidance scales. The method may leverage the energy-based perspective of self-attention mechanisms, potentially by manipulating the energy landscape to produce smoother, more controlled attention weights. This could lead to a Pareto improvement, enhancing both image quality and reducing artifacts. A key aspect could involve the use of Gaussian kernel smoothing to control the energy landscape’s curvature. The technique might be computationally efficient, even for large inputs, via a query blurring method. Overall, the research appears to target improvements in unconditional and conditional image generation, potentially achieving better results than existing techniques in both quality and the reduction of side effects.
Attention Curvature#
The concept of “Attention Curvature” is intriguing and suggests a novel perspective on analyzing attention mechanisms. Curvature, in a geometric sense, relates to how sharply the energy landscape of the attention mechanism changes. A high curvature indicates sharp changes in attention weights with slight changes in input, potentially leading to unstable or unpredictable behavior, while low curvature implies smoother transitions, potentially promoting more robust and generalized attention. The paper likely investigates how this curvature affects the quality and diversity of generated samples. High curvature might result in overfitting to training data, leading to less diverse and potentially lower-quality outputs, while lower curvature might encourage exploration of a wider range of possibilities, resulting in higher-quality and more varied results. The authors likely propose methods to control or reduce the attention curvature, perhaps by manipulating the parameters of the attention mechanism itself or by employing regularization techniques. This control mechanism could allow for a trade-off between stability and diversity. The analysis of attention curvature could be applied to other areas in machine learning involving attention mechanisms, highlighting the broader implications and utility of this work.
Gaussian Blurring#
Gaussian blurring, a fundamental image processing technique, plays a crucial role in the paper by attenuating the curvature of the energy landscape associated with self-attention mechanisms in diffusion models. This is achieved by applying a Gaussian filter to the attention weights, effectively smoothing the attention map. The impact is twofold: it reduces the variance of the attention weights, leading to a more uniform distribution of attention, and it decreases the lse value, which is directly related to the energy of the system. This smoothing effect makes the attention prediction less sensitive to extreme values and noise, leading to higher quality and more stable image generation. By controlling the standard deviation of the Gaussian kernel, the level of smoothing can be precisely adjusted, offering a fine-grained control over the balance between sharpness and stability in the generated images. The method efficiently manipulates the attention weights without incurring quadratic complexity, making it computationally practical for large-scale models. This novel application of a classic image processing technique demonstrates its potential in enhancing the performance of complex deep learning models.
Unconditional Guidance#
Unconditional guidance in diffusion models presents a significant challenge, as traditional methods like classifier-free guidance (CFG) rely on class labels or text prompts. The core difficulty lies in directing the generation process without providing explicit conditions. Approaches attempting unconditional guidance often resort to heuristics manipulating attention mechanisms or modifying the energy landscape of the model. While these methods offer some improvements, they frequently suffer from suboptimal generation quality and unintended side effects, such as blurring, color shifts, or structural distortions. The need for a principled, condition-free approach that avoids these pitfalls is evident. This is a crucial area of ongoing research, as successful unconditional guidance would significantly broaden the applicability of diffusion models, enabling tasks like generating diverse, high-quality images without any external inputs or conditions.
Ablation Study#
An ablation study systematically removes or alters components of a model to assess their individual contributions. In the context of a diffusion model for image generation, this might involve removing or modifying elements like the attention mechanism, the Gaussian blur, or the classifier-free guidance. The goal is to isolate the impact of each component and understand its effect on the overall performance, such as image quality and the presence of artifacts. For example, removing the Gaussian blur might show if it’s crucial for suppressing noise or artifacts, improving image quality, and reducing undesired side effects. By varying the degree of Gaussian blurring, the study reveals the sensitivity of the model to this parameter and reveals an optimal level. The ablation study results would provide quantitative measures, like FID or LPIPS scores, alongside qualitative analysis comparing generated images with and without the different modifications. It is crucial for demonstrating the efficacy and necessity of each proposed component. The study’s robustness is evaluated by considering various conditions, such as text prompts and/or ControlNet integration, further showcasing the generalizability of the improvements offered.
More visual insights#
More on figures

This figure presents a qualitative comparison of the proposed Smoothed Energy Guidance (SEG) method against three other unconditional guidance approaches: vanilla Stable Diffusion XL (SDXL), Self-Attention Guidance (SAG), and Perturbed Attention Guidance (PAG). The figure visually demonstrates the differences in image quality, detail preservation, and artifact reduction between the methods. Each row shows the results from a different image generation task, comparing the outputs of the four methods for each task. This provides a visual evaluation of SEG’s effectiveness relative to existing methods in producing high-quality, artifact-free images, even with strong guidance.

This figure demonstrates the effectiveness of SEG in text-conditional image generation. It shows how the quality of the generated images improves as the standard deviation (σ) of the Gaussian filter increases, ranging from σ = 1 to σ approaching infinity. The text prompts used are: ‘a jellyfish playing the drums in an underwater concert’ and ‘a high-resolution satellite image of a bustling shipping port, countless colorful containers’. The figure visually compares the output across different σ values with the vanilla SDXL output (σ → 0), showcasing how SEG enhances image quality and detail while maintaining coherence with the textual descriptions.

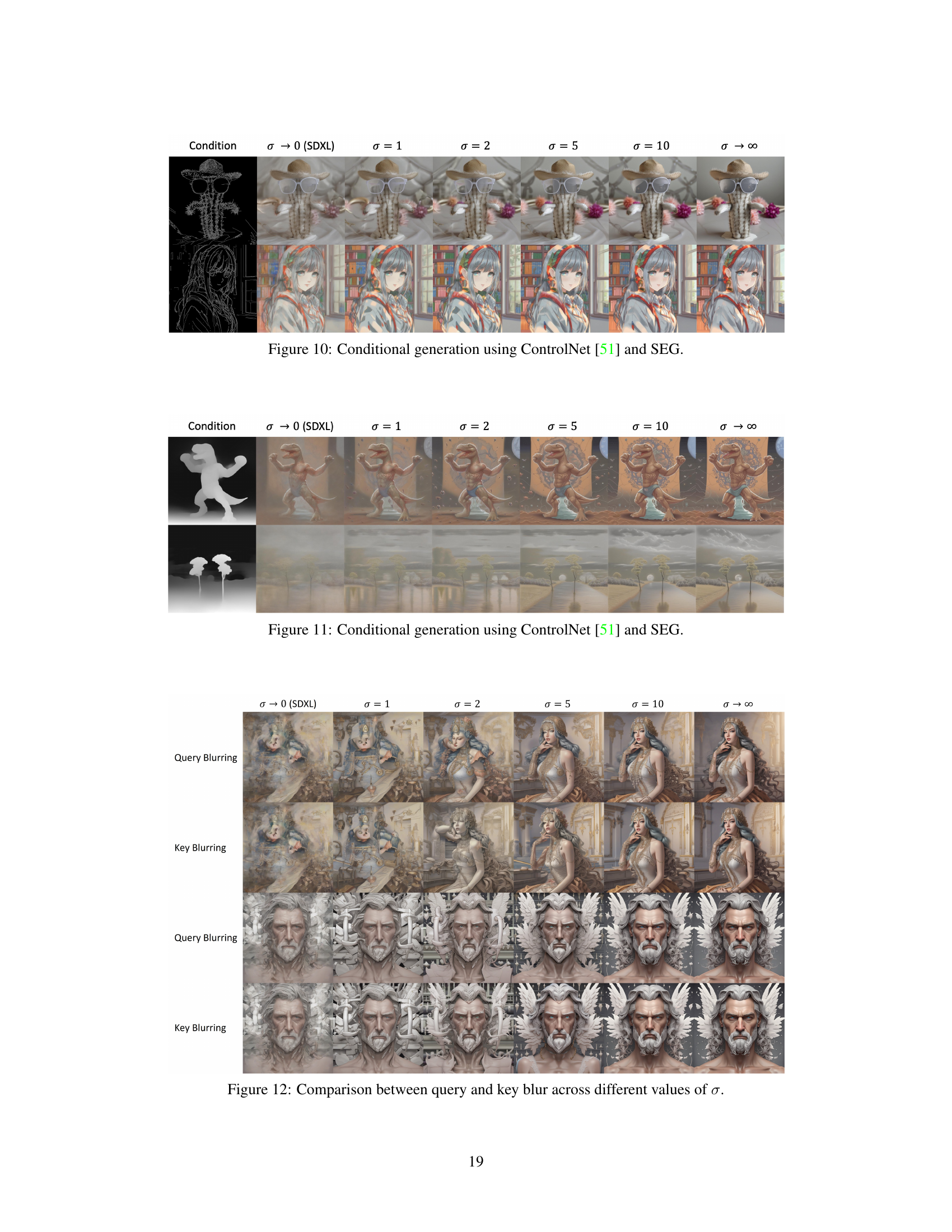
This figure shows the results of conditional image generation using ControlNet [51] and the proposed SEG method. Different rows represent different ControlNet conditioning inputs (e.g., canny edge detection, depth map, etc.), while columns illustrate results at various Gaussian blur standard deviation (σ) values, demonstrating how SEG affects the output at various levels of smoothing. This illustrates the versatility of SEG and how it can complement other control mechanisms for image generation.

This figure presents a qualitative comparison of the image generation results obtained using Smoothed Energy Guidance (SEG), vanilla SDXL, Self-Attention Guidance (SAG), and Perturbed Attention Guidance (PAG). It visually demonstrates SEG’s ability to produce higher-quality images compared to the other methods, exhibiting sharper details, improved coherence, and a greater adherence to the prompt’s specifications. The comparison highlights SEG’s advantage in generating images with more realistic textures and overall composition.

This ablation study explores the effect of varying the guidance scale parameter (\seg) and the standard deviation of the Gaussian filter (σ) on the performance of Smoothed Energy Guidance (SEG). The left panel shows FID scores, while the right panel shows CLIP scores for different combinations of \seg and σ. This helps to determine the optimal settings for SEG to balance sample quality and computational efficiency. Notably, increasing σ tends to improve sample quality without causing saturation, supporting the idea that σ is the better parameter to control image quality.

This figure illustrates the pipeline of Smoothed Energy Guidance (SEG). Panel (a) shows the standard self-attention process with its associated energy landscape. Panel (b) depicts the SEG modification, applying a Gaussian blur to the attention weights (controlled by σ), resulting in a smoother energy landscape. Panel (c) provides a conceptual visualization of how SEG combines the original and blurred predictions (using a guidance scale parameter), demonstrating that a high guidance scale may lead to less natural samples.

This figure presents a qualitative comparison of the image generation results produced by four different methods: vanilla Stable Diffusion XL (SDXL), Self-Attention Guidance (SAG), Perturbed Attention Guidance (PAG), and the proposed Smoothed Energy Guidance (SEG). Each row shows the results for a particular image generation task or prompt, with each column representing a different method. The goal is to visually demonstrate the improved image quality and reduced side effects obtained using SEG compared to the other methods, particularly when dealing with higher guidance scales.

This figure presents a qualitative comparison of the image generation results obtained using four different methods: vanilla SDXL, SAG, PAG, and SEG. The comparison highlights the differences in image quality, detail, and adherence to the given prompts, illustrating SEG’s superior performance in producing sharper, more detailed images that better match the prompt descriptions. It visually demonstrates the advantages of SEG over existing unconditional guidance approaches.

This figure demonstrates conditional image generation using ControlNet and the proposed Smoothed Energy Guidance (SEG) method. It showcases how SEG enhances the quality of images generated by ControlNet when provided with various conditioning inputs (e.g., different values of the standard deviation parameter σ). The results illustrate the effectiveness of SEG in improving image quality and detail while maintaining consistency with the provided conditions.

This figure shows the results of conditional image generation using ControlNet and the proposed SEG method. It demonstrates SEG’s ability to enhance image quality when combined with ControlNet, across different standard deviations (σ) of the Gaussian blur in SEG. The top row shows the ControlNet input, and the bottom row shows the corresponding generated image.

This figure compares the effects of applying Gaussian blur to either the query or key matrices in the self-attention mechanism of a diffusion model. It shows how varying the standard deviation (σ) of the Gaussian blur affects image generation. Different σ values result in varying degrees of blurring, demonstrating the impact on image details and overall appearance. The top two rows showcase results for one image prompt, while the bottom two rows show results for a different prompt. This illustrates that the method’s effect is not image-specific and depends on the σ parameter.

This figure shows a comparison of applying Gaussian blur to either the query or key matrix in the self-attention mechanism of a diffusion model. Different standard deviations (σ) of the Gaussian blur are used, ranging from 0 (no blur) to 10 and infinity. The results demonstrate how the choice of blurring method and the standard deviation affects the output images.

This figure shows the results of text-conditional image generation using the proposed Smoothed Energy Guidance (SEG) method. It demonstrates SEG’s ability to generate high-quality images while adhering to the provided text prompts. The figure showcases several examples with different prompts and varying levels of Gaussian blur (σ), highlighting SEG’s control over the generation process.
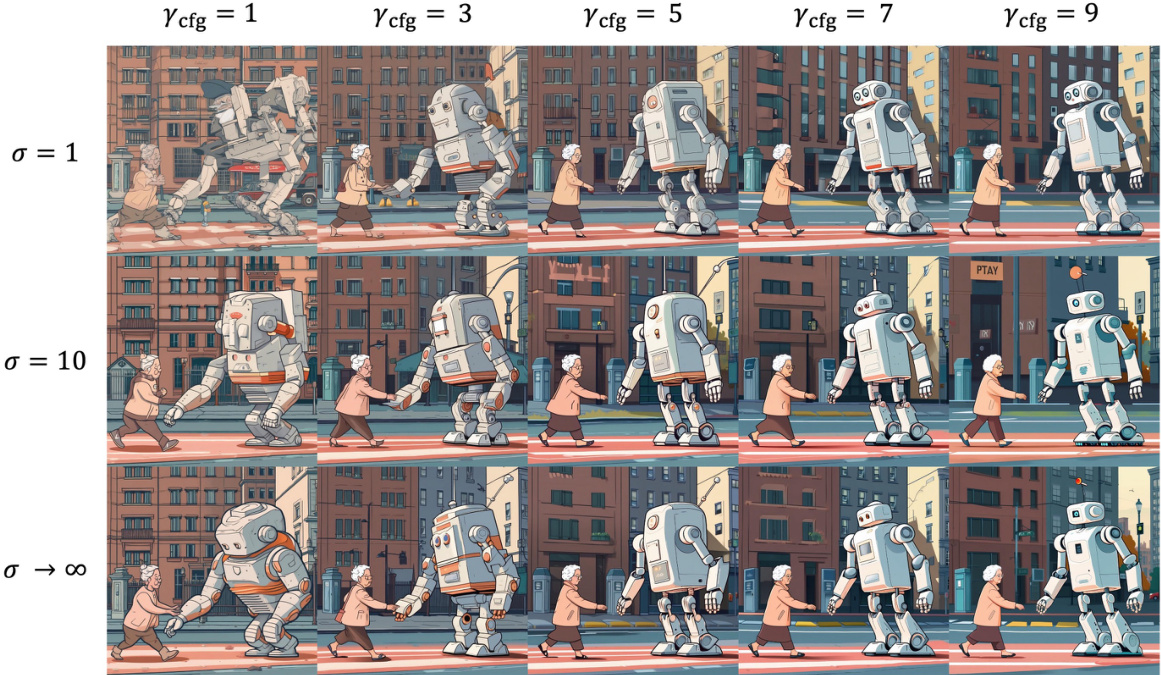
This figure shows the results of an experiment combining Smoothed Energy Guidance (SEG) with classifier-free guidance (CFG). The SEG guidance scale is fixed at 3.0, while the CFG scale varies (1, 3, 5, 7, and 9). The prompt used for image generation is: ‘a friendly robot helping an old lady cross the street.’ The images demonstrate that SEG enhances image quality across different CFG scales without the saturation and structural changes observed with CFG alone. This suggests that SEG improves the quality of images generated by diffusion models without significantly altering the overall content or structure.

This figure shows the results of an experiment combining Smoothed Energy Guidance (SEG) with Classifier-Free Guidance (CFG) for conditional image generation. The prompt used was: ‘a skateboarding turtle zooming through a mini city made of Legos.’ The SEG guidance scale (γseg) was fixed at 3.0, while the CFG guidance scale (γcfg) was varied across multiple levels (1, 3, 5, 7, 9). The standard deviation (σ) of the Gaussian blur in SEG was also varied (σ = 1, σ = 10, σ → ∞). The images demonstrate how SEG enhances the quality of images generated with CFG, across various CFG scales and σ values, without introducing saturation or significant changes in the image structure.

This figure shows the results of an experiment combining Smoothed Energy Guidance (SEG) and Classifier-Free Guidance (CFG) on generating images of puppies playing soccer with a ball of yarn. The SEG guidance scale (\seg) is fixed at 3.0, while the CFG scale (\cfg) varies across columns (1, 3, 5, 7, 9). Rows represent different values for the Gaussian blur parameter (σ) used in SEG: 1, 10, and ∞ (representing no blur). The experiment aims to show the impact of varying CFG strength combined with different levels of energy smoothing from SEG on image generation.

This figure shows the results of an experiment combining Smoothed Energy Guidance (SEG) with classifier-free guidance (CFG) in image generation. The SEG guidance scale (\seg) is fixed at 3.0, while the CFG scale (\cfg) is varied across multiple rows, from 1 to 9. The columns show samples generated using different values of σ (standard deviation of the Gaussian filter for blurring attention weights): σ = 1, σ = 10, and σ → ∞. The purpose of the experiment is to demonstrate how SEG enhances image quality at various CFG scales without causing saturation or significant changes in the overall image structure. The prompt used is: ‘a family of teddy bears having a barbecue in their backyard.’

This figure shows an experiment combining Smoothed Energy Guidance (SEG) with classifier-free guidance (CFG). The SEG guidance scale (\seg) is held constant at 3.0, while the CFG scale (\cfg) is varied. The prompt used is: ‘a friendly robot helping an old lady cross the street.’ The results demonstrate that SEG enhances image quality across various CFG scales without causing saturation or major structural alterations. The images illustrate the improvements in detail and overall quality achieved by SEG.

This figure visualizes the impact of varying both the guidance scale (γseg) and the standard deviation (σ) of the Gaussian blur on unconditional image generation. Each row represents a different γseg value (1, 2, 5, 10, 100), and each column showcases results obtained using different σ values (1, 2, 5, 10, ∞). It demonstrates how these two parameters affect image quality and the diversity of generated outputs in an unconditional generation setting.
Full paper#