↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Vision-Language Models (VLMs) have shown impressive progress in various tasks, but their spatial reasoning capabilities remain limited, hindering applications in robotics and augmented reality that require precise spatial understanding. Existing VLMs struggle with regional information parsing and accurate perception of spatial relationships, relying mainly on 2D image data.
SpatialRGPT leverages a novel data curation pipeline to learn regional representations from 3D scene graphs and incorporates depth information into visual encoders. This improves the model’s understanding of relative directions and distances between regions. The model’s effectiveness is demonstrated through a comprehensive benchmark, SpatialRGPT-Bench, showing significant performance improvements compared to existing methods. The project also demonstrates applications like region-aware dense reward annotation for robotics, advancing both fundamental research and practical applications.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the limitations of existing Vision-Language Models (VLMs) in spatial reasoning. By introducing a novel framework and benchmark, it opens avenues for improved 3D scene understanding and advancements in robotics and AR applications. The proposed method, SpatialRGPT, and benchmark, SpatialRGPT-Bench, provide valuable tools for researchers to advance the field.
Visual Insights#

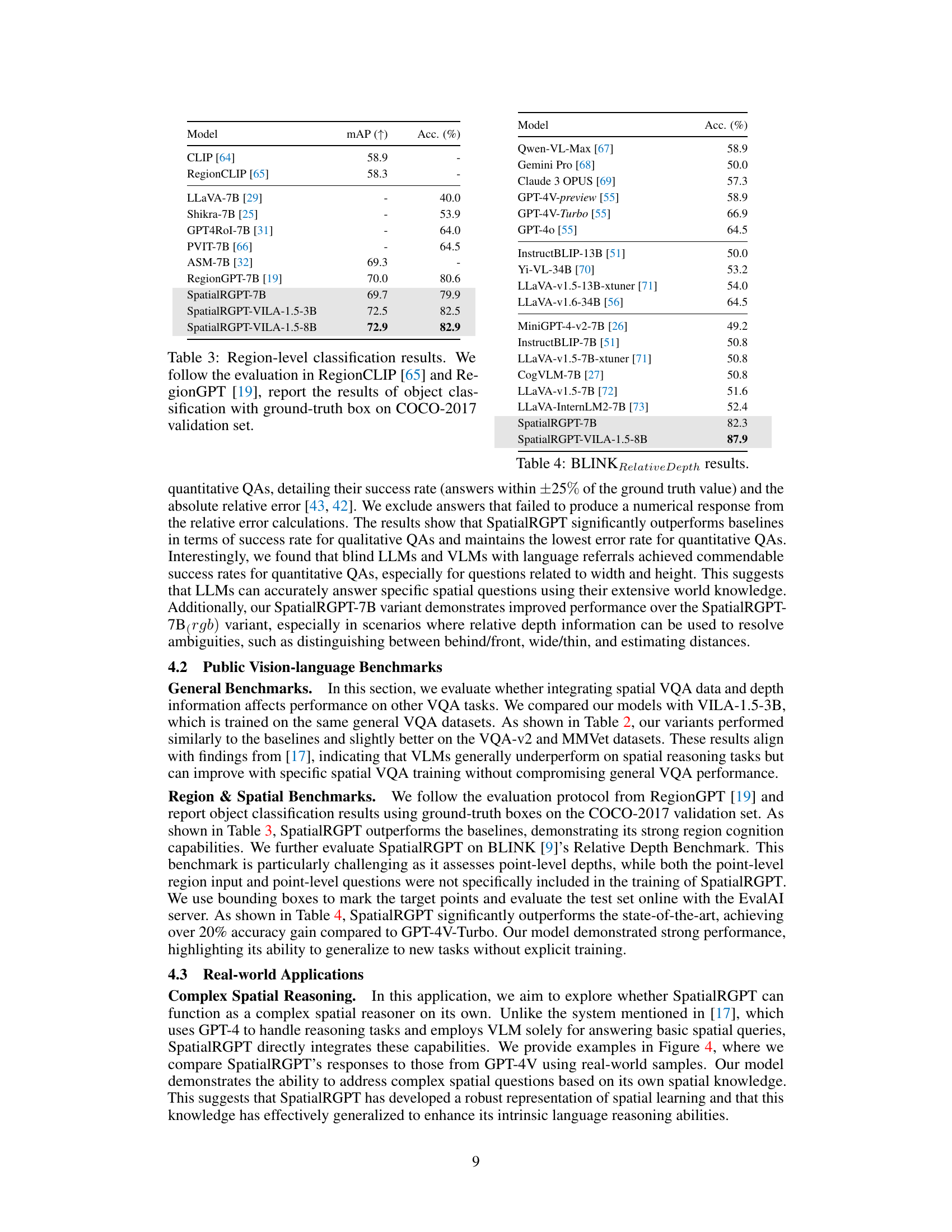
This figure illustrates the 3D scene graph construction pipeline used in the paper. The pipeline starts with image collections, which are filtered to remove unsuitable images. Open-vocabulary detection and segmentation then identify and extract object instances, which are further processed using metric depth estimation and camera calibration to create 3D point clouds. These point clouds are then used to create the final 3D scene graph which includes region masks and spatial relation information. Finally, the scene graph is used to generate region-aware spatial QAs using either template-based methods or an LLM-based approach for training.

This table presents the results of the SpatialRGPT-Bench benchmark, comparing the performance of SpatialRGPT against various baseline models across different spatial reasoning tasks. The upper part of the table shows the success rates for qualitative tasks (e.g., relative spatial relationships), while the lower part displays both success rates and the absolute relative errors for quantitative tasks (e.g., distance and dimensions). The baseline models include blind LLMs (relying on text and language only), VLMs with language referral (leveraging visual and language information), and region-aware VLMs (specifically focused on region-level understanding).
In-depth insights#
3D Spatial Reasoning#
3D spatial reasoning in vision-language models (VLMs) presents a significant challenge, as VLMs traditionally excel at 2D tasks. Existing methods often rely on 2D image data or language descriptions, lacking the inherent 3D understanding needed for complex spatial queries. This paper tackles the problem by proposing novel data curation and model architecture. The data curation pipeline generates 3D scene graphs from single images, incorporating depth information, while the architecture effectively integrates depth into the visual encoder. This allows the model to not only perceive spatial relationships but also accurately estimate distances and directions. The introduction of a region-aware module further enhances performance by enabling the model to focus on specific regions within the image for more precise spatial reasoning. The proposed benchmark, SpatialRGPT-Bench, provides a much-needed evaluation tool for future research in this area. Overall, the approach demonstrates a significant advancement in enabling VLMs to reason accurately about 3D spatial arrangements, which is crucial for applications such as robotics and augmented reality.
Region-Aware VLMs#
Region-aware Vision-Language Models (VLMs) represent a significant advancement in multimodal AI. By moving beyond the limitations of traditional VLMs that treat images holistically, region-aware architectures enable more nuanced spatial reasoning. This is achieved by processing images in a segmented manner, allowing the model to focus on individual regions of interest and their interrelationships. The key advantage is the ability to handle complex scenes with multiple objects and intricate spatial layouts, something which often proves challenging for global image processing models. The incorporation of region-based attention mechanisms and contextual information from neighboring regions leads to a substantial increase in the model’s accuracy and understanding of spatial relationships, particularly in tasks requiring precise localization or detailed descriptions of the scene. Grounding regional information within a broader scene context is crucial for accurate interpretation, which region-aware VLMs successfully address. However, challenges remain in efficiently handling varied region sizes and shapes, robustly identifying relevant regions, and efficiently managing computational costs associated with processing numerous regions. Future research could explore more sophisticated region proposal methods, deeper integration of geometric information, and more efficient architectural designs to enhance the capabilities of region-aware VLMs.
SpatialRGPT Bench#
The proposed SpatialRGPT-Bench is a significant contribution because it directly addresses the lack of standardized benchmarks for evaluating 3D spatial reasoning capabilities in vision-language models (VLMs). Existing benchmarks often focus on 2D spatial relationships or lack ground truth 3D annotations crucial for comprehensive spatial understanding. SpatialRGPT-Bench’s strength lies in its coverage of diverse environments (indoor, outdoor, and simulated) and its focus on ground-truth 3D annotations. This enables a more robust and accurate evaluation of VLMs’ ability to perceive and reason about complex spatial arrangements in 3D space, going beyond simplistic relative location understanding. The benchmark’s use of both qualitative and quantitative VQA pairs further enhances its thoroughness, allowing for a nuanced assessment of model performance. The inclusion of 3D cuboids for object representation, the variety of object classes, and the diversity of spatial questions ensure that the benchmark is sufficiently challenging and can effectively discriminate between different VLM approaches. Overall, SpatialRGPT-Bench provides a crucial tool for advancing research and development in 3D spatial reasoning within VLMs.
Depth Info Fusion#
Integrating depth information effectively is crucial for enhancing a vision-language model’s understanding of 3D spatial relationships. A naive concatenation of depth and RGB features may not be optimal; a more sophisticated fusion technique is often necessary. This could involve designing a separate processing stream for depth data, perhaps leveraging a specialized depth encoder or incorporating depth cues into an existing RGB visual encoder. The choice of fusion method (e.g., early vs. late fusion, attention-based mechanisms) will heavily influence performance, and experiments should explore the impact of these architectural choices. Data quality is paramount: using high-quality depth maps is crucial for reliable training and accurate spatial reasoning, thus impacting the downstream model’s capabilities. Handling depth ambiguity and noise is also important, as depth sensors often produce imperfect measurements. Techniques like depth completion or denoising would improve the robustness of the approach. Finally, evaluating the effectiveness of depth fusion requires careful consideration of the evaluation metrics and a focus on tasks that directly benefit from 3D spatial awareness.
Future Directions#
Future research directions for SpatialRGPT could involve several promising avenues. Improving the accuracy and robustness of 3D scene graph construction is crucial, perhaps by exploring more advanced depth estimation techniques or incorporating multiple sensor modalities. Addressing the limitations of axis-aligned bounding boxes by using oriented bounding boxes or other more flexible region representations would enhance the model’s accuracy in complex scenes. Further research should focus on improving the generalization capabilities of SpatialRGPT across diverse and unseen environments, potentially through transfer learning or domain adaptation strategies. Investigating more sophisticated multi-hop reasoning methods, beyond simple two-hop relations, could unlock more complex spatial understanding. Finally, exploring applications beyond robotics, such as virtual and augmented reality or other domains requiring fine-grained 3D spatial reasoning, could broaden the impact of SpatialRGPT significantly. This includes refining the region-aware reward annotation for applications in more complex robotic manipulation tasks.
More visual insights#
More on figures
This figure illustrates the automatic data curation pipeline used to construct 3D scene graphs from single 2D images. The pipeline consists of several stages: filtering to remove unsuitable images, open-vocabulary detection and segmentation to extract object instances, metric depth estimation to obtain depth information, camera calibration to project objects into 3D space, and finally point cloud processing to construct the 3D scene graph. Each stage is represented by a box in the figure, with arrows showing the flow of data between stages. The figure also shows example images at various stages of the pipeline, illustrating the process of transforming a 2D image into a 3D scene graph.

This figure shows example question-answer pairs from the Open Spatial Dataset. The first row demonstrates template-based questions and answers, which follow a predefined structure. These examples focus on fundamental spatial concepts like relative position and metric measurements. The second row showcases examples generated using a Large Language Model (LLM). These questions and answers are more complex and demonstrate the model’s ability to reason about more nuanced spatial relationships than the simpler template-based examples. The figure illustrates the diversity of the data used to train the SpatialRGPT model and highlights its ability to generate both structured and free-form QA pairs.
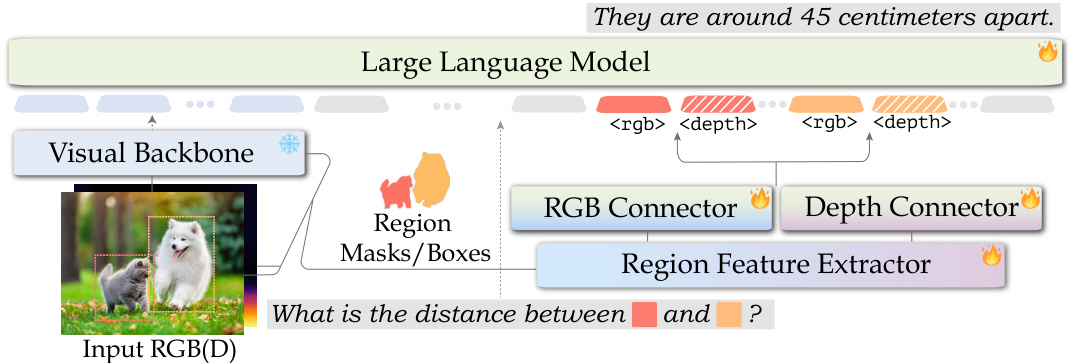
The figure shows the architecture of SpatialRGPT, a multimodal language model that leverages both RGB and depth information for enhanced spatial reasoning. It consists of a visual backbone (processing RGB and depth data), a region feature extractor (to process region masks/boxes), an RGB connector, a depth connector, and a large language model (LLM). The RGB and depth connectors project features into the LLM’s embedding space, enabling the model to reason about spatial relationships within regions using multimodal inputs.

This figure showcases SpatialRGPT’s ability to answer complex spatial reasoning questions. It presents four examples, each with an image and a question-answer pair generated by SpatialRGPT and GPT-4V. The examples demonstrate that SpatialRGPT can handle nuanced spatial relationships that GPT-4V struggles with, including relative positions, distances, object sizes, and even multi-hop reasoning. This highlights SpatialRGPT’s improved ability to interpret complex visual environments.

This figure showcases SpatialRGPT’s ability to perform multi-hop reasoning by answering complex spatial questions that require multiple steps of inference. Each example shows a scene with identified regions and a question that demands understanding of multiple spatial relationships between objects within those regions. The model’s responses correctly identify objects, their locations, and distances, demonstrating its capacity for advanced spatial understanding.

This figure presents a statistical overview of the SpatialRGPT-Bench dataset. The left panel shows a donut chart illustrating the distribution of question categories (relative spatial relationships and metric measurements) and their sources (different datasets used). The right panel displays a bar chart showing the frequency distribution of objects present in the dataset. This visualization helps in understanding the dataset’s composition and balance across various aspects.

This figure shows six example images from the SpatialRGPT-Bench dataset, each with a question and answer pair illustrating SpatialRGPT’s ability to reason about spatial relationships. The images cover diverse indoor and outdoor scenes with different objects, highlighting the variety and complexity of the benchmark.

This figure shows six example images from the SpatialRGPT-Bench dataset. Each image shows a scene with several objects, their segmentation masks, and examples of the kinds of questions and answers that can be generated from these scenes. The top row features RGB images, while the bottom row shows the depth maps generated from those images.

This figure illustrates the automatic data curation pipeline used to construct 3D scene graphs from single 2D images. The pipeline consists of several stages: filtering unsuitable images, open-vocabulary detection and segmentation to extract object instances, metric depth estimation to obtain depth information, camera calibration to project objects into 3D space, and finally, constructing the 3D scene graph by connecting object nodes with edges representing spatial relationships. Each stage is depicted with a visual representation of the process.
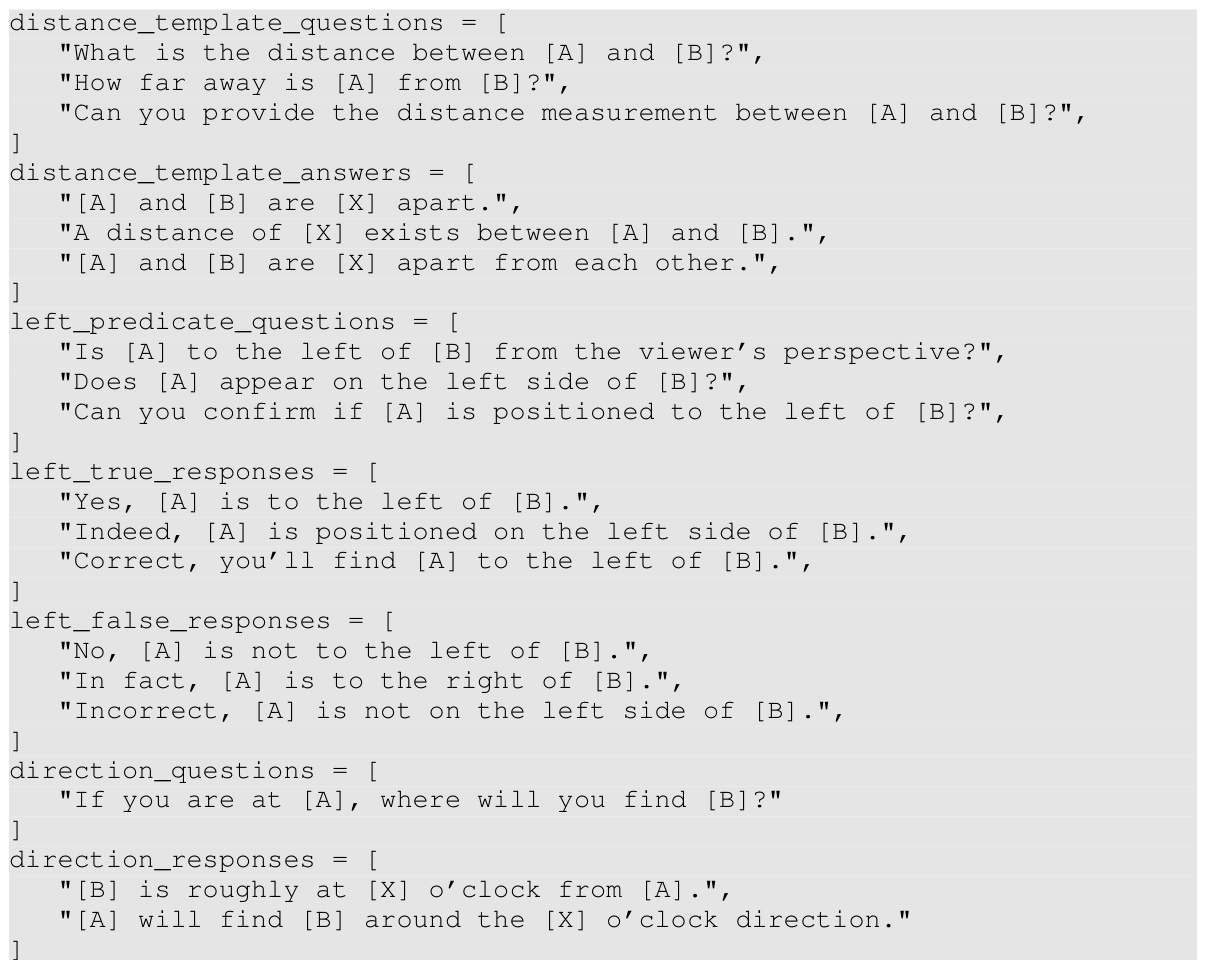
This figure illustrates the data curation pipeline used to automatically generate 3D region-aware annotations from 2D images at scale. The pipeline consists of three main steps: (i) open-vocabulary detection and segmentation to extract object instances, (ii) metric depth estimation to obtain accurate depth information, and (iii) camera calibration to project objects into a 3D space. These scene graphs are subsequently transformed into region-aware spatial QA tasks to provide region-based VLMs with necessary spatial knowledge and enable complex spatial reasoning.

This figure illustrates the data curation pipeline used to generate 3D scene graphs from single 2D images. It shows the steps involved, starting with image filtering to remove unsuitable images, followed by open-vocabulary detection and segmentation to identify object instances, metric depth estimation to project objects into 3D space, camera calibration to align them into a common coordinate system, and finally, the construction of the 3D scene graph itself, which represents the spatial relationships between objects. This pipeline enables the creation of training data for SpatialRGPT, a model designed for enhanced spatial reasoning in vision-language models.

The figure illustrates the data pipeline used to automatically generate 3D region-aware annotations from 2D images at scale. It starts with image filtering, then uses open-vocabulary detection and segmentation to extract object instances and their masks. Metric depth estimation and camera calibration are used to project these objects into a 3D space. The resulting point cloud is processed to construct the 3D scene graph, where nodes represent 3D object instances and edges denote their spatial relationships. Finally, these scene graphs are transformed into region-aware spatial QA tasks.

This figure illustrates the process of automatically generating 3D scene graphs from single 2D images. It begins with filtering to remove unsuitable images, open-vocabulary object detection and segmentation to extract instances, metric depth estimation to determine distances, camera calibration to project into 3D, and finally, processing the point cloud to construct the scene graph. Each step involves specific models and techniques to ensure accuracy and robustness in the 3D representation of the scene.

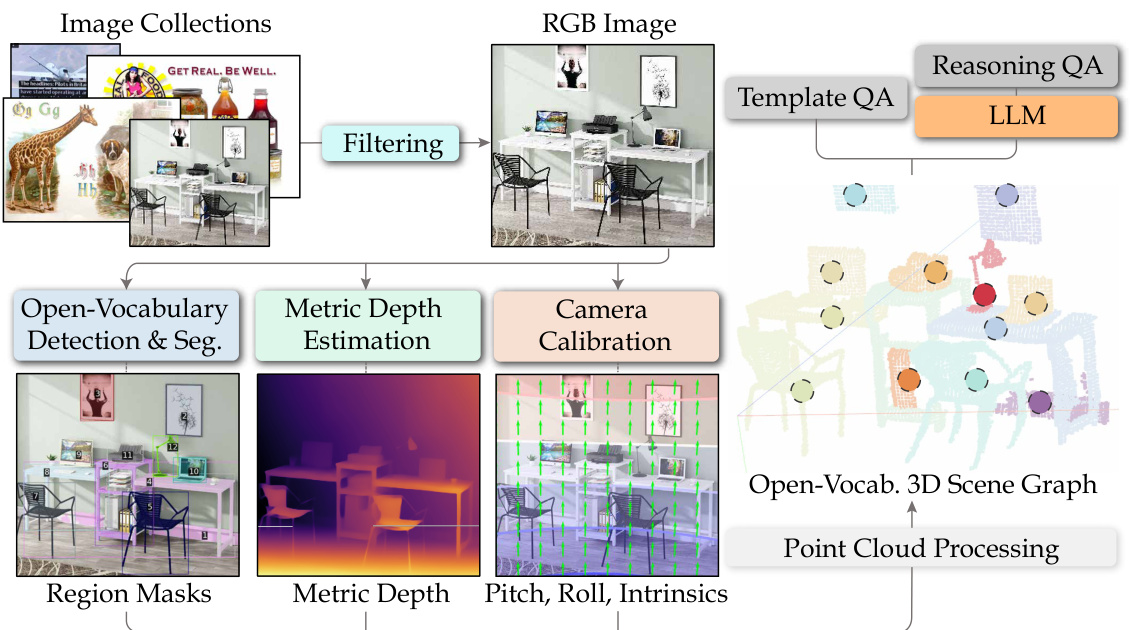
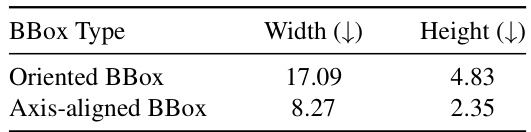
This figure shows a comparison between axis-aligned bounding boxes (AABB) and oriented bounding boxes (OBB). The AABB is a simple rectangular box aligned with the coordinate axes, while the OBB is a more complex box that rotates to better fit the object’s shape and orientation. The figure illustrates how an OBB (purple) more accurately encloses an object (sofa) compared to an AABB (blue). The difference is particularly noticeable in cases where the object is not aligned with the coordinate axes, improving the accuracy of object detection and representation.
More on tables
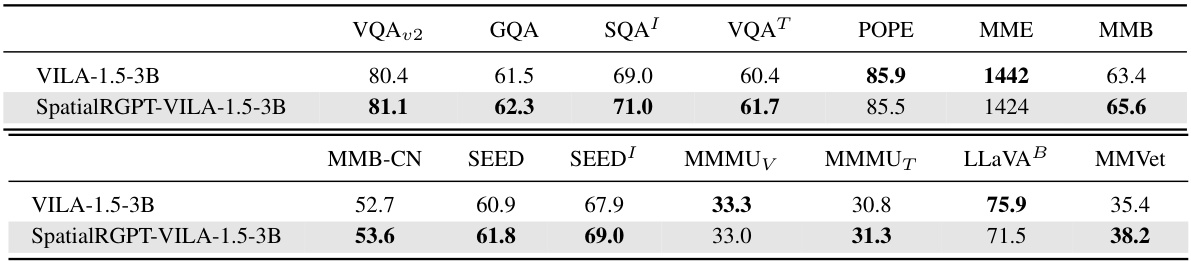
This table compares the performance of SpatialRGPT and a baseline model (VILA-1.5-3B) on several general VLM benchmark datasets. These benchmarks assess various visual and language understanding capabilities, not specifically focused on spatial reasoning. The results show that SpatialRGPT generally achieves comparable or slightly improved performance, indicating that incorporating spatial reasoning capabilities does not negatively affect performance on broader VQA tasks.
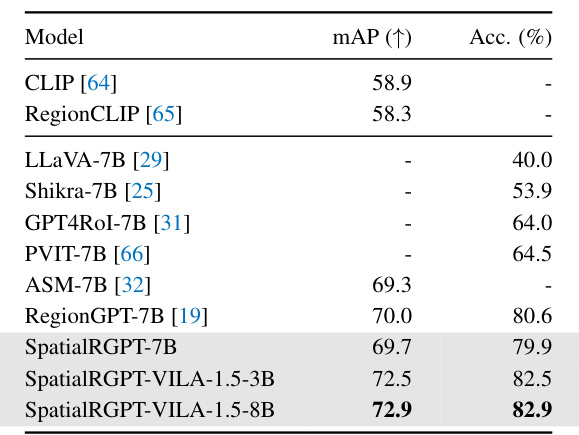
This table presents the results of a region-level object classification task. It compares the performance of several vision-language models, including the proposed SpatialRGPT models, on the COCO-2017 validation set. The evaluation metric is accuracy, and the models are evaluated based on their ability to correctly classify objects within ground-truth bounding boxes.
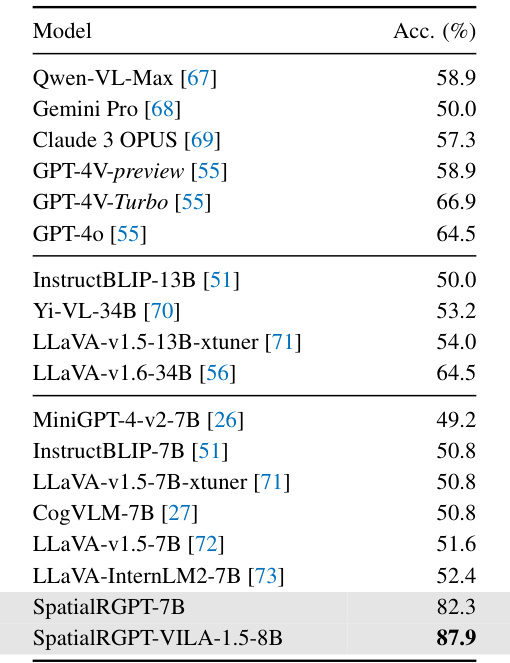
This table presents a comparison of different vision-language models (VLMs) on the SpatialRGPT-Bench benchmark. The benchmark focuses on evaluating the ability of VLMs to perform spatial reasoning tasks, including tasks related to relative directions, distances, and object sizes. The models are categorized into three groups: blind LLMs, VLMs with language referral, and region-aware VLMs. For each model, the table shows both qualitative (success rates) and quantitative (absolute relative error) results for various spatial reasoning tasks.

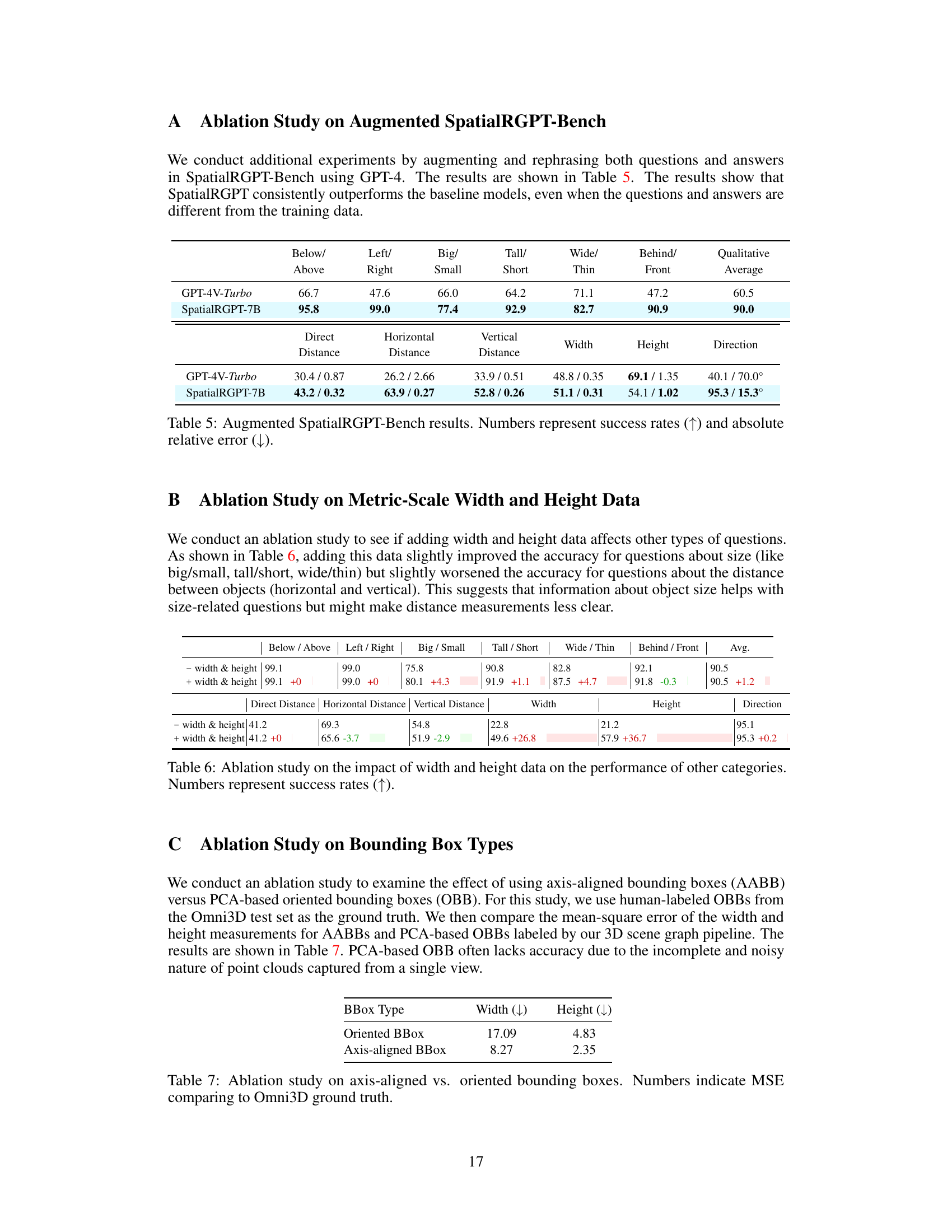
This table presents the results of an ablation study conducted on the augmented SpatialRGPT-Bench. The study evaluated the model’s performance using different questions and answers from the training data to check for generalization. The table compares the success rates (indicated by an upward-pointing arrow) and absolute relative errors (indicated by a downward-pointing arrow) of the GPT-4V-Turbo model and the SpatialRGPT-7B model. The metrics are shown for several spatial reasoning categories (above/below, left/right, big/small, tall/short, wide/thin, behind/front) and for distance measurements (direct, horizontal, vertical). Higher success rates and lower relative errors indicate better performance.

This table presents a comparison of the performance of different Vision-Language Models (VLMs) on the SpatialRGPT-Bench benchmark. The benchmark focuses on evaluating the ability of VLMs to perform spatial reasoning tasks, such as determining relative directions, distances, and object sizes. The table is divided into two sections. The top section shows the success rates of the models for qualitative spatial reasoning tasks, categorized by the type of spatial relationship (e.g., above/below, left/right, big/small). The bottom section displays both the success rate and absolute relative error for quantitative spatial reasoning tasks, including tasks involving direct, horizontal, and vertical distance measurements, as well as measurements of object width, height, and direction. The table highlights the superior performance of SpatialRGPT models compared to other baseline models, demonstrating their enhanced ability to handle spatial reasoning tasks.
This table presents the results of evaluating different models on the SpatialRGPT-Bench benchmark. The top part shows the success rates for qualitative spatial reasoning tasks (e.g., relative position, size comparison). The bottom part shows both success rates and the average error for quantitative tasks (e.g., distances, angles). Three model categories are compared: blind LLMs, VLMs with language referral, and region-aware VLMs. SpatialRGPT consistently outperforms the others.

This table presents the ablation study results on the effect of using different input modalities (mask vs. box) for SpatialRGPT on the SpatialRGPT-Bench benchmark. It shows the success rates and absolute relative errors for various spatial reasoning tasks. The top section displays qualitative results (success rates) for relative spatial relationships (above/below, left/right, big/small, etc.), while the bottom section presents quantitative results (success rates and errors) for metric measurements (direct distance, horizontal distance, vertical distance, width, height, direction). This allows for the evaluation of SpatialRGPT’s robustness to different input types and whether the model’s performance is affected by this variation.

This table presents a comparison of different Vision-Language Models (VLMs) on the SpatialRGPT-Bench benchmark. The benchmark evaluates the models’ ability to perform spatial reasoning tasks, specifically focusing on relative spatial relationships (e.g., above, below, left, right) and metric measurements (e.g., distance, width, height). Three categories of models are compared: blind LLMs with language referral, VLMs with language referral, and region-aware VLMs. The table shows success rates (higher is better) and absolute relative error (lower is better) for each category of model on both qualitative and quantitative spatial reasoning tasks. The results demonstrate that SpatialRGPT significantly outperforms the other models.
This table presents the results of the SpatialRGPT-Bench, a benchmark designed to evaluate the spatial reasoning capabilities of Vision-Language Models (VLMs). It compares the performance of various models, including blind LLMs (that rely only on text), VLMs with language reference (that can access both text and visual data), and region-aware VLMs (that can reason about specific regions in an image). The table is divided into two parts: the top part shows success rates for qualitative tasks (e.g., spatial relationships between objects), while the bottom part presents success rates and relative errors for quantitative tasks (e.g., measuring distances and dimensions). Overall, this table illustrates SpatialRGPT’s effectiveness in improving upon the performance of existing VLMs in spatial reasoning tasks.
Full paper#