↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Interactive scene reconstruction is challenging due to inaccurate motion recovery in complex scenes with multiple objects, especially when requiring natural language control. Existing methods typically use joint modeling approaches, which are inefficient and struggle with high-dimensional interaction spaces.
LiveScene overcomes these challenges through a novel scene-level language-embedded interactive radiance field. By decomposing the scene into local deformable fields and using an interaction-aware language embedding, LiveScene achieves state-of-the-art results in novel view synthesis and interactive control, significantly improving parameter efficiency. The paper introduces two new datasets, OmniSim and InterReal, further contributing to advancements in the field.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances interactive scene reconstruction, tackling the challenge of accurately reconstructing and controlling multiple objects in complex scenes. It introduces novel techniques such as high-dimensional factorization and interaction-aware language embedding, which improve efficiency and enable natural language control. The datasets introduced are also valuable resources for the research community.
Visual Insights#
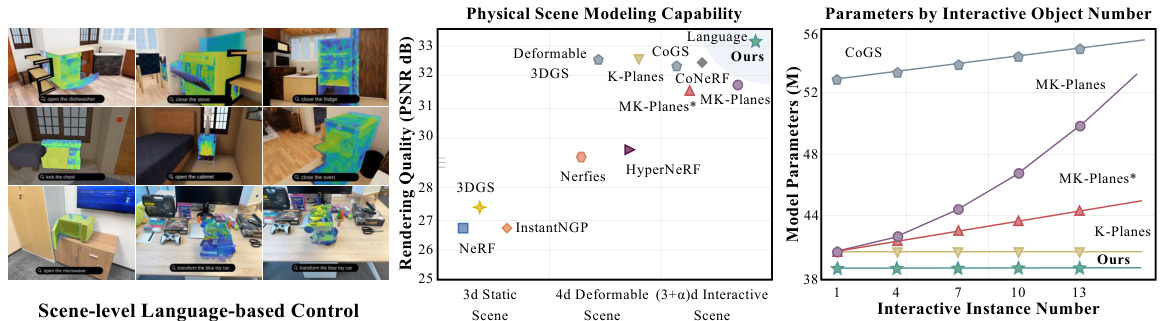
This figure demonstrates LiveScene’s capabilities in scene-level reconstruction and control using language. The left panel showcases an example of language-interactive articulated object control within the Nerfstudio framework, highlighting the system’s ability to manipulate objects using natural language commands. The right panel presents a comparison of LiveScene’s rendering quality and parameter efficiency against other state-of-the-art methods on the OmniSim dataset. The graph shows that LiveScene achieves superior PSNR (Peak Signal-to-Noise Ratio) values, indicating higher rendering quality, while maintaining significantly fewer model parameters, even as the number of interactive objects increases. This illustrates LiveScene’s efficiency in handling complex scenes with multiple interactive elements.

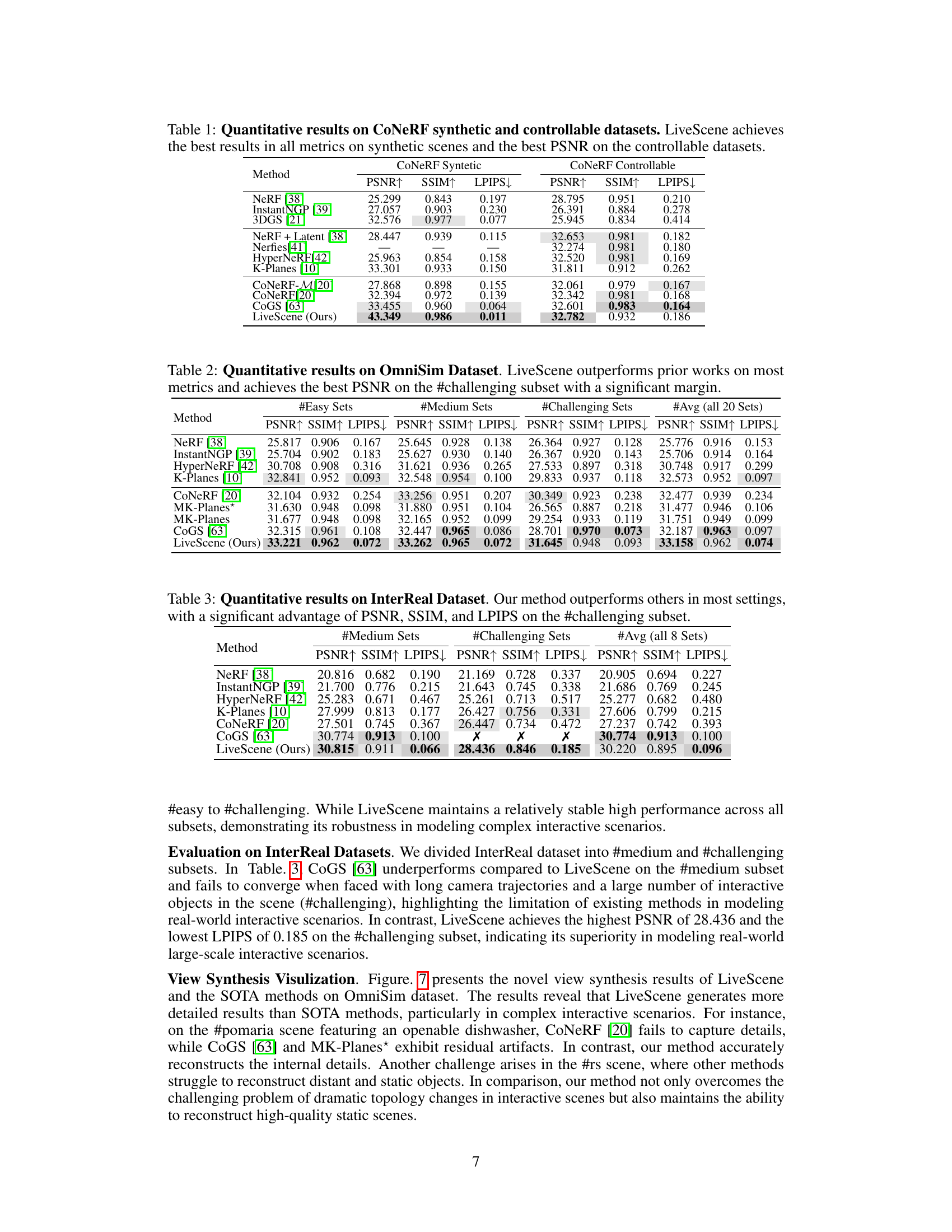
This table presents a quantitative comparison of LiveScene against several state-of-the-art methods for novel view synthesis on the CoNeRF Synthetic and Controllable datasets. The metrics used are PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), and LPIPS (Learned Perceptual Image Patch Similarity). Higher values for PSNR and SSIM indicate better visual quality, while a lower LPIPS value indicates better perceptual similarity to the ground truth. The results demonstrate that LiveScene significantly outperforms other methods, achieving the best performance across all three metrics on the synthetic dataset and the best PSNR on the controllable dataset.
In-depth insights#
Lang Emb Inter X#
The heading ‘Lang Emb Inter X’ suggests a research area focusing on the intersection of language embedding and interactive systems. Language embedding, in this context, likely refers to techniques that represent natural language semantically, enabling machines to understand and generate human-like text. The term ‘Interactive’ signifies systems that respond dynamically to user input, creating a responsive and engaging experience. ‘X’ represents the specific application domain where these two concepts intersect. This intersection could yield powerful applications in various fields. For example, in robotics, it could enable robots to understand complex natural language instructions and respond accordingly. In virtual reality, it might power more intuitive and natural interfaces. The possibilities extend to human-computer interaction in general, creating more natural and user-friendly interfaces. A key challenge in this research area is the development of robust and efficient methods for bridging the gap between the abstract representation of language and the concrete actions or responses of an interactive system. Further research should explore different techniques for grounding language models in the context of interactive systems, focusing on methods for handling ambiguity, uncertainty, and real-world constraints.
Multiscale Factor#
The concept of a “Multiscale Factor” in the context of a research paper likely refers to a technique that addresses the challenge of handling data or phenomena across multiple scales simultaneously. This could involve decomposing a complex system into smaller, more manageable components which are then individually processed and aggregated. A key advantage would be enhanced computational efficiency when working with very large datasets, as it avoids the need to process the entire dataset at the highest resolution. Data structures like multiresolution grids or wavelets could be used to represent the data at different scales. The approach likely also includes strategies for handling interactions between scales, perhaps by using a hierarchical model that passes information from coarser scales to finer scales. The effectiveness of this multiscale factor would depend on the specific problem, and it might need to be carefully designed to strike a balance between computational cost and accuracy.
OmniSim Dataset#
The OmniSim dataset, a key contribution of the LiveScene paper, is a synthetic dataset designed for evaluating interactive scene reconstruction and control. Its strength lies in its ability to provide a large-scale and diverse set of scenes with numerous interactive objects, unlike previous datasets which often focused on single objects or limited scene complexity. The realistic rendering of OmniSim, achieved using OmniGibson, allows for evaluating novel view synthesis quality and parameter efficiency in challenging scenarios. The inclusion of ground truth data like RGBD images, camera poses, object masks, and interaction variables allows for comprehensive benchmarking, pushing the boundaries of current interactive scene reconstruction models. The variety of interactive motions available (articulated motion, complex rotations and translations) makes OmniSim ideal for evaluating robustness and generalization capabilities. While synthetic, its meticulously constructed nature offers a controlled environment for rigorous evaluation, which is crucial in advancing interactive scene understanding in robotics, VR/AR, and other related fields.
Ablation Study#
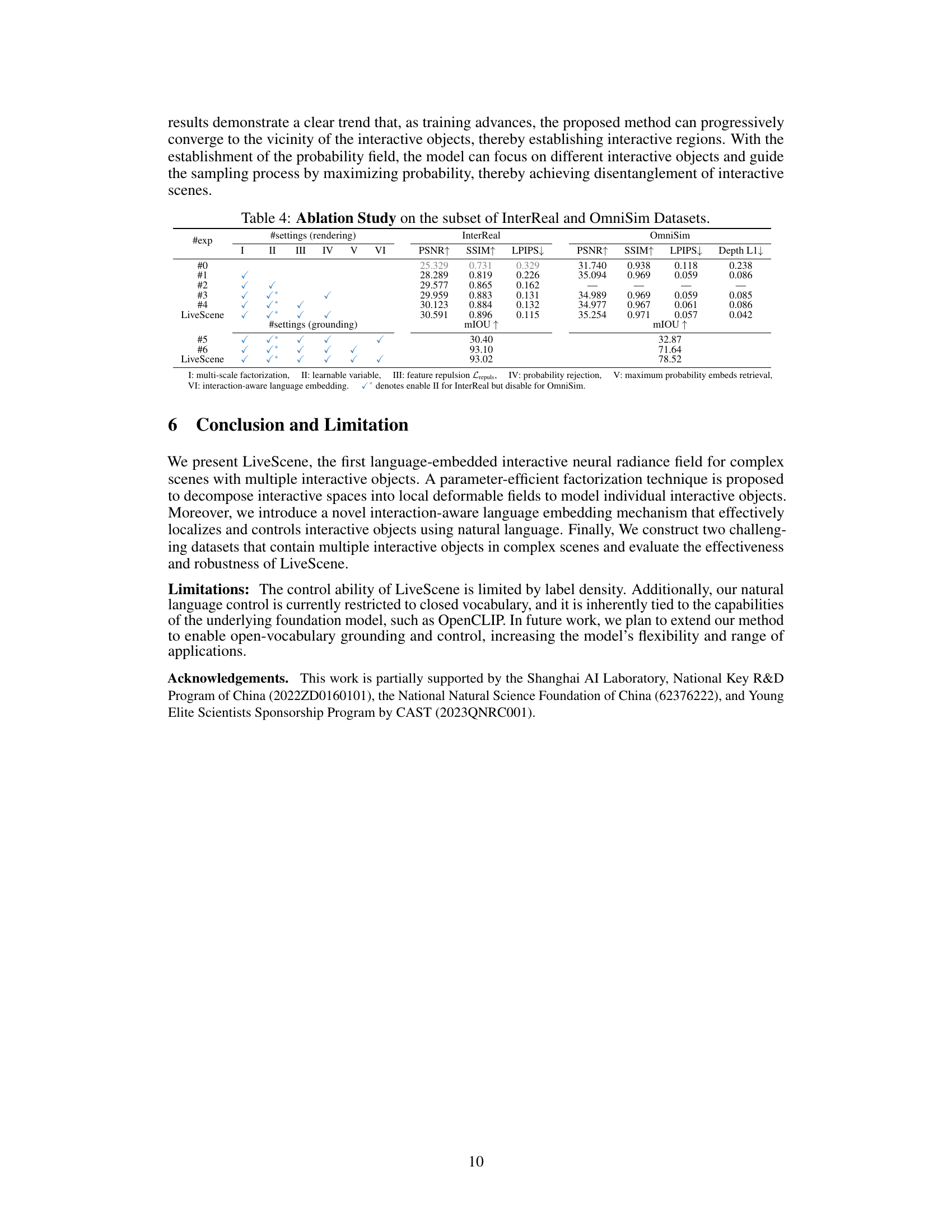
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a paper on interactive scene reconstruction, this would involve removing key features like the multi-scale interaction space factorization, the interaction-aware language embedding, or the probability rejection method. The results would reveal the impact of each component on metrics such as PSNR, SSIM, and mIOU. A well-executed ablation study demonstrates the importance of each feature and provides strong support for the proposed methodology. By showing that removing any part significantly degrades performance, the study validates the design choices. The study should also investigate the interplay between components, assessing whether the benefits of one feature are amplified or diminished in the absence of others. This could reveal synergistic effects or highlight potential redundancies in the model architecture. Ultimately, a thorough ablation study strengthens the paper by providing concrete evidence of the effectiveness and necessity of each proposed component, leading to a more robust and convincing argument for the overall model’s superiority.
Future Work#
The paper’s omission of a dedicated ‘Future Work’ section is notable. However, the conclusion subtly hints at potential avenues for future research. Extending the natural language control to open vocabulary interactions is a crucial next step, moving beyond the current closed vocabulary limitations. This requires investigating more robust language embedding techniques and potentially incorporating larger language models. Similarly, addressing the dataset limitations by creating more diverse and larger-scale interactive scene datasets is vital. This will enhance the generalizability and robustness of the proposed LiveScene model. Further research should also focus on improving the efficiency and scalability of the model, making it suitable for even more complex scenarios and larger scenes. Finally, exploring novel applications of LiveScene in diverse fields such as robotics, virtual reality, and augmented reality should be prioritized, extending beyond its current capabilities.
More visual insights#
More on figures
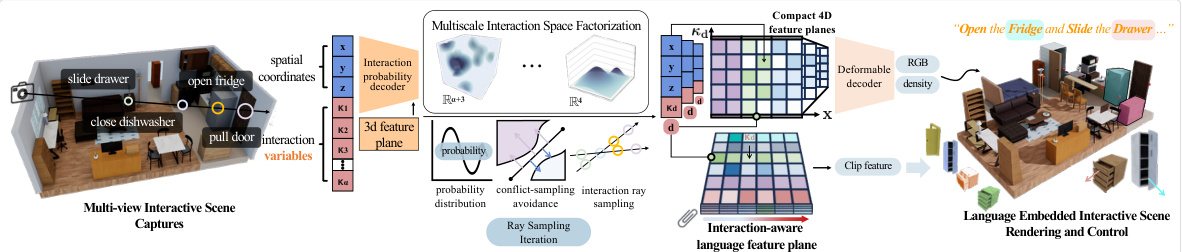
This figure provides a detailed overview of the LiveScene architecture. It shows how the system takes a camera view and control variables as input and uses a series of steps to generate a 3D scene representation with interactive objects. The process involves sampling 3D points within local deformable fields, rendering these points to create the interactive objects’ motions, and using an interaction-aware language embedding to localize and control individual objects. This allows for natural language control of the scene.
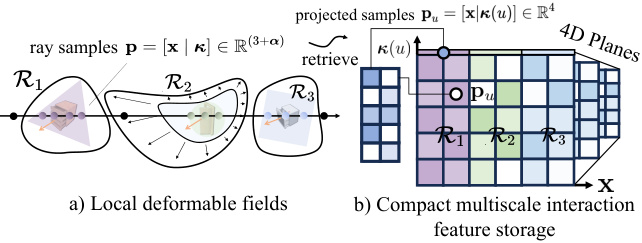
This figure illustrates the concept of hyperplanar factorization used in LiveScene for efficient storage of high-dimensional interaction data. It shows how the complex interaction space is decomposed into multiple local 4D deformable fields, one for each interactive object region. High-dimensional interaction features from each region are then projected onto a compact 4D space, allowing for efficient storage and processing. The multiscale feature planes further compress this data. The left side shows the local deformable fields and how ray sampling interacts with them. The right side visualizes the compact storage method.
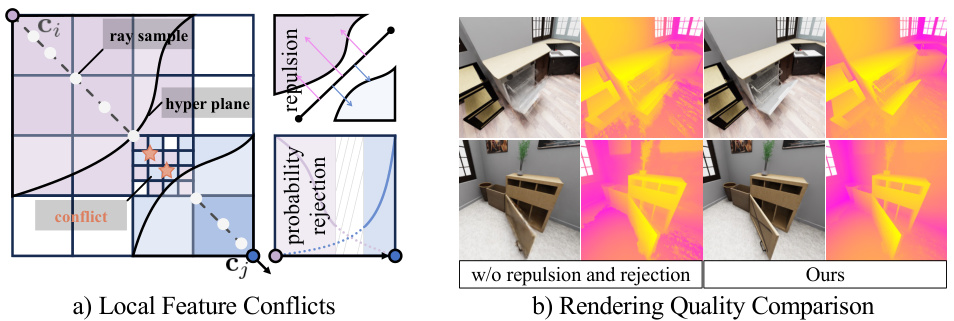
This figure shows a comparison of the rendering quality with and without the proposed repulsion and probability rejection methods. In (a), it illustrates the boundary sampling conflicts that may occur during training when optimizing the interaction probability decoder with varying masks. This can lead to blurred boundaries in the local deformable field, causing sampling conflicts and feature oscillations. In (b), it shows the rendering quality comparison, demonstrating the effectiveness of the proposed methods in alleviating these conflicts and achieving higher rendering quality.

The figure shows an overview of the OmniSim and InterReal datasets. OmniSim is a synthetic dataset generated from OmniGibson, showing various indoor scenes with multiple interactive objects and their states. InterReal is a real-world dataset captured from real scenes, also featuring multiple interactive objects and diverse actions. Both datasets contain RGB images, depth maps, segmentations, camera poses, interaction variables, and object captions, providing rich information for training and evaluating interactive scene reconstruction and control models. The image showcases examples of scenes from both datasets.

This figure compares the novel view synthesis results of LiveScene against other state-of-the-art methods on the CoNeRF Controllable dataset. The top row shows a toy robot interacting with a vehicle. The middle row shows a person’s face, and the bottom row shows a car. The ground truth images (GT) are shown first, followed by results generated using HyperNeRF, CoNeRF, CoGS, and LiveScene (Ours). The figure demonstrates that LiveScene produces significantly higher-quality images with sharper details and more accurate color representation than the other compared methods.

This figure compares the novel view synthesis results of LiveScene against state-of-the-art methods (CoNeRF, MKPlanes*, CoGS) across three scenes from the OmniSim dataset. The scenes (’#rs’, ‘#ihlen’, and ‘#pomaria’) showcase different levels of complexity in terms of interactive object arrangements. Each row represents a specific scene with the ground truth (GT) image followed by the results of each method. Colored boxes highlight individual interactive objects. The visualization demonstrates LiveScene’s superior ability to accurately reconstruct complex interactive scenes, especially in challenging scenarios.

This figure compares the performance of LiveScene with and without two key components: multi-scale factorization and interaction-relevant features. The top row shows a scene (#1) where multi-scale factorization significantly improves both RGB rendering quality and geometry reconstruction accuracy. The bottom row illustrates a scene (#6) where the lack of interaction-relevant features causes LiveScene to struggle when objects share similar appearances. This demonstrates the effectiveness of these components in handling complex interactive scenes.

This figure visualizes the learning process of the probability fields within LiveScene, demonstrating how the model progressively learns to identify and focus on interactive objects over 1000 training steps. The heatmaps show the probability field at various stages, starting from a diffuse state and gradually converging towards the locations of the interactive elements. This highlights the model’s ability to learn and precisely localize interactive areas in complex scenes.
More on tables
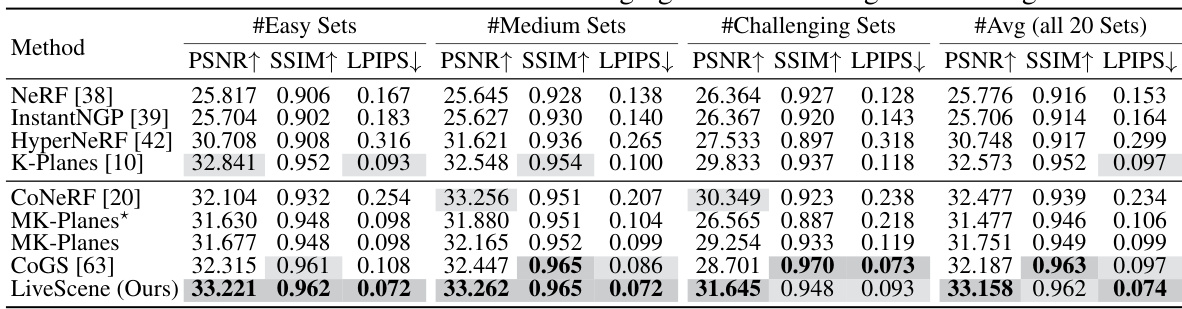
This table presents a quantitative comparison of different methods for 3D scene reconstruction on the OmniSim dataset, categorized by difficulty levels: #Easy, #Medium, and #Challenging. The metrics used are PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), and LPIPS (Learned Perceptual Image Patch Similarity). LiveScene demonstrates superior performance across all metrics, especially on the most challenging subset.
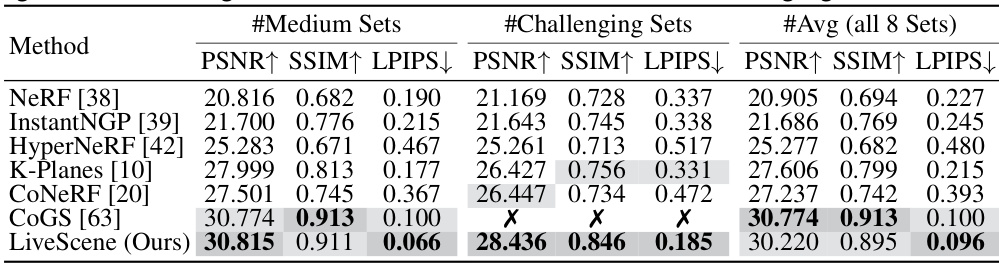
This table presents a quantitative comparison of LiveScene against several state-of-the-art methods on the InterReal dataset. The dataset is categorized into subsets based on the complexity of the scene’s interactive elements (‘medium’ and ‘challenging’). The comparison uses three metrics: Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). Higher values for PSNR and SSIM indicate better visual quality, while a lower LPIPS score indicates better perceptual similarity to the ground truth. LiveScene demonstrates superior performance, particularly in the more challenging scenes.
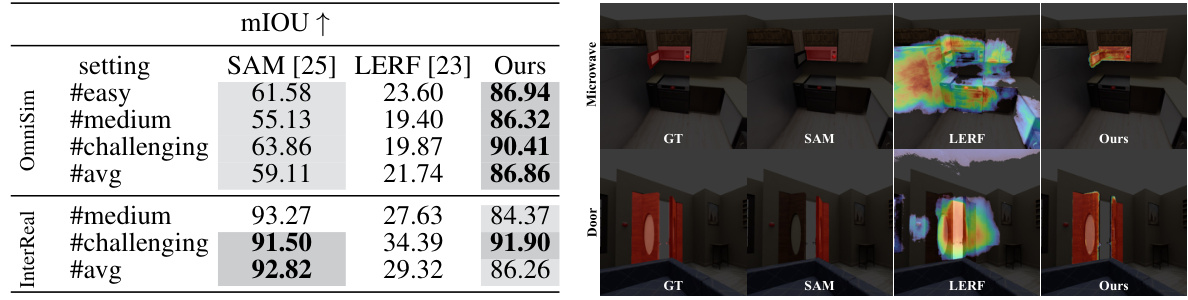
This table presents a comparison of language grounding performance among different methods on the OmniSim dataset. The metric used is mean Intersection over Union (mIOU). The table shows that the proposed method, LiveScene, significantly outperforms existing methods (SAM and LERF) across various scene complexities (’easy’, ‘medium’, ‘challenging’). The right-hand side of the table includes qualitative visualizations to illustrate the superior boundary precision achieved by LiveScene.
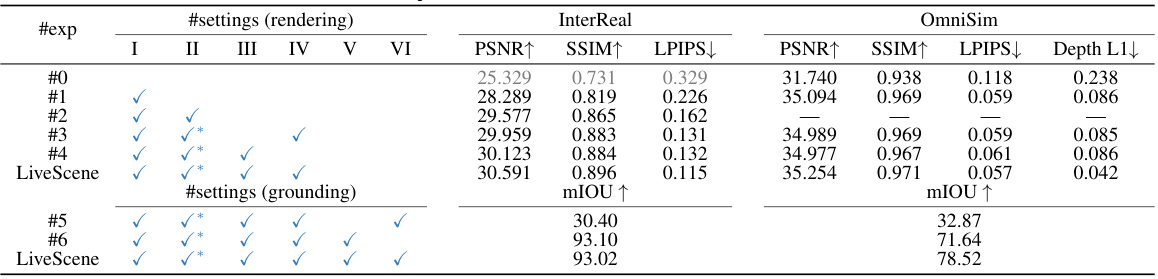
This table presents the ablation study results, comparing different configurations of LiveScene on both InterReal and OmniSim datasets. It shows the impact of key components such as multi-scale factorization, learnable variables, feature repulsion, probability rejection, maximum probability embedding retrieval, and interaction-aware language embedding on the model’s performance in terms of PSNR, SSIM, LPIPS, and mIOU metrics. This allows for a detailed understanding of the contribution of each component to the overall performance of the model.
Full paper#